基于多標簽神經網絡的行人屬性識別
2020-04-09 04:48:53陳桂安王笑梅劉鴻程
計算技術與自動化 2020年1期
關鍵詞:深度學習
陳桂安 王笑梅 劉鴻程


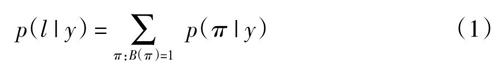
摘? ?要:在多標簽行人屬性識別的問題中,為了充分利用標簽之間的相關性,解決傳統方法識別準確率低和效率慢的問題,提出了一個多標簽卷積神經網絡。該網絡在一個統一的網絡框架下識別行人多個屬性。把行人的多個屬性看作是一個序列,然后構建了一個時序分類模型。提出的方法不僅避免了復雜的多輸入MLCNN網絡,也不需要多次訓練單標簽分類模型。實驗結果表明,本文方法準確率均優于SIFT+SVM和多輸入的MLCNN模型,平均準確率達到了90.41%。
關鍵詞:多標簽分類;神經網絡;行人屬性;深度學習;
中圖分類號:TP391.41? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?文獻標識碼:A
Pedestrian Attributes Recognition Based on Multi-label Neural Network
CHEN Gui-an?覮,WANG Xiao-mei,LIU Hong-cheng
(Shanghai Normal University,Shanghai 200234,China)
Abstract:In the problem of multi-label pedestrian attributes recognition,in order to make full use of the correlation between labels and solve the problem of low recognition accuracy and low efficiency of traditional methods,a multi-label convolutional neural network is proposed,which is in a network. Identify multiple attributes of pedestrians under a unified network framework. We consider multiple attributes of a pedestrian as a sequence and then construct a time series classification model. The proposed method not only avoids the complicated multi-input MLCNN network,but also does not need to train the single-label classification model multiple times. The experimental results show that the accuracy of the proposed method is better than that of SIFT+SVM and multi-input MLCNN model,and the average accuracy rate is 90.41%.
Key words:multi-label classification;neural network;pedestrian attributes;deep learning
分類任務是計算機視覺、模式識別和圖像處理領域的一個基本任務,而多標簽分類任務作為其中的一種也很有研究價值。比如,在監控場景下,常常會用行人的性別、年齡、發色等特征來進行人物檢索[1-2]、人物識別[3-4]、面部驗證[5]和人物再識別[6]等。通常情況下,公共場所的監控攝像頭為了覆蓋比較廣的區域,都會被安裝在較遠的位置,因此獲得的行人分辨率比較低。然而這種情況下的行人屬性因其光照不變性和對比度不變性,仍然有很好的應用價值。
行人屬性分類問題中有三個主要的挑戰。首先,由于多樣的衣服、復雜的背景和不同的鏡頭角度,屬性的類內變化比較大。其次,不同的屬性位于圖片中不同的位置,比如頭發通常位于圖片的上方,鞋位于圖片的下方等,造成了提取特征比較困難。第三,這是一個多標簽的問題,不是單純的多分類,且標簽之間有一定的相關性。因此,很多現有的分類算法都不適用,即便是有一些多分類網絡也有其挑戰性。
多標簽識別問題目前主要是各個標簽分開處理。如:朱旭鋒等[7]提出基于多不變量和多分類器融合的識別方法;李新德等[8]提出基于 Hu 矩、PNN 和 DSmT 融合的方法;Hussein 等[9]提出轉換特征和模糊聚類的飛機識別方法;Zhu 等[10]提出基于優化的 BoW 模型識別方法;Li 等[12]提出 PCNN 模型用于飛機識別。行人屬性識別中一個比較受歡迎的方法是用手工提取特征(sift[12]等)然后用SVM去單獨的分類各個屬性[6,13-15]。但這不能很好的解決上述的三個問題,因為手工提取的特征有有限的表達能力而數據集類內變化太復雜,也不能夠應用內間的相關性信息。Jiangqing Zhu等[16]提出了一個多輸入的多標簽分類網絡(MLCNN)來進行行人屬性識別。受Xiang Bai等[17]在研究場景文字識別所使用模型的啟發,本文使用了一個時序模型來實現行人屬性多標簽分類,該網絡以ResNet50[18]為基礎以及連接時序分類(CTC)[19]的損失函數來輸出序列。該網絡是直接用圖像像素訓練而不是手工特征,并且能識別多個屬性。通過在PETA[13]數據集上進行實驗驗證,取得了良好的識別效果。
1? ?材料和方法
1.1? ?行人屬性數據集
有很多用于監控研究的公開行人屬性數據集,比如VIPeR,PRID,GRID,APiS,and PETA,PETA是最新的數據集,包含65個屬性標簽,一共19000張圖片,分辨率最小為17x39,最大為169x365。19000張圖片中共包含有8705個行人,每個行人用61個二分類屬性標簽和4個多分類屬性標簽打標,部分示例如圖1所示
1.2? ?ResNet
卷積神經網絡因其強大的特征表達能力和提取能力在圖片分類領域取得了很高的準確率,如今,它的應用延申到了圖像分析的各個領域,本課題采用深度卷積神經網絡的方法,研究行人屬性多標簽分類識別。
加深網絡以獲取更高的準確率的同時也使得網絡變得難以優化,因為它可能引起梯度消失或梯度爆炸的問題,以及越深的網絡反而效果越差的退化問題。
ResNet[18]解決了這個問題,并且獲得了2015年ILSVRC第一名。它通過擬合殘差映射而不是原始映射,以及在層之間添加多個連接。這些新的連接跳過各個層并執行標識,而不增加任何新參數,或簡單的1×1卷積。特別是,該網絡是基于對構建塊的重復使用,網絡的深度取決于使用的構建塊的數量。該模塊由三個卷積塊組成,分別是 1×1卷積塊,3×3卷積塊接著又是1×1卷積塊,并且將第一個卷積的輸入連接到第三個卷積的輸出,每個卷積塊包含一層batch normalization層、激活層和卷積層,如圖2所示。對于我們的問題,我們使用了具有50層的ResNet50。
圖1? ? PETA行人圖片示例
圖2? ? ResNet的基本構建單元
1.3? ?標簽序列概率
采用Graves等人[19]提出的連接時序分類(CTC)中定義的條件概率。該概率是在每幀預測y = y1,…,yT的標簽序列l上定義的,并且它忽略了每個標簽具體的位置。因此,當我們使用這個概率的負對數似然作為目標函數,我們只需要圖像及其相應的標簽序列,避免標記各個序列元素的位置。
CTC的公式簡單的描述如下:輸入是序列y = y1,…,yT,T是序列長度。這里每一個yt∈R[L],是集合L′ = LU‘—上的一個可能分布,L包含所有任務中的所有標簽,‘—表示空格。一個序列到序列的映射函數B是定義在上π∈L′T的。B通過移除相同的標簽和空格將π映射到I,例如B將“-hh-e-ll-oo-”(‘-表示空格)映射為“hello”。然后,一個條件概率定義為所有被B映射到I的π的和:
p(l | y) = ■? p(π | y)? ? ? ?(1)
π的概率是p(π | y) = ■Tt=1ytπt,ytπt表示在t時刻有標簽πt的概率。由于大量的指數求和,直接計公式算式(1)是不可行的,但是可以用[19]中描述的前向-后向算法有效的計算出來。
1.4? ?網絡結構
研究網絡結構如圖3所示:
圖3? ?網絡結構圖
ResNet_input圖片大小為160 × 80 × 3,經過ResNet50卷積提取特征后,ResNet_output大小為5 × 3 × 2048,Reshape輸出大小為30 × 1024,全連接層Dense將Reshape得到的30 × 1024輸出特征進行全連接,輸出大小為30 × 53,其中,30是時間序列的時刻,53是分類數。最后,用全連接層的輸出和真實標記通過CTC公式計算損失并對網絡進行優化。
1.5? ?算法驗證
所使用的數據集是行人屬性數據集PETA。PETA數據集是由10個子集構成如:VIPER,PRID,GRID以及CAVIAR4REID等,因此,PETA是一個包含不同鏡頭角度、光照、分辨率和場景的復雜數據集。
如果相應屬性的樣本量過少則會導致數據不平衡,因此我們忽略了及其不平衡的屬性選擇樣本量大于1500的26個二分類屬性如表1所示。因此每張圖對應26個標簽共53個分類,其中除了26個正反類以外還有一類為CTC中的空格‘-。實驗中把圖片大小調增為180×90,然后用隨機裁剪,隨機翻轉,隨機旋轉等策略擴充數據集,隨機裁剪的大小為160×80,裁剪后的圖片大小與裁剪前的圖片相差不大,一般不會造成圖片信息的損失。
表1? ?26類屬性識別精度對比表,粗體字表示最好的表現
實驗平臺為i5-6500 CPU,NVIDIA GTX 1070 GPU以及16GB內存的服務器。訓練數據為11400張圖片,驗證數據和測試數據各3800張。訓練時,先用ImageNet參數初始化ResNet50,再用PETA數據去訓練。采用隨機梯度下降法(SGD)優化網絡,初始學習率為0.001,momentum為0.9,batch大小為32,訓練50個epoch。
為了驗證本文提出方法的有效性,本文使用了兩個對比模型。第一個是ikSVM[20],使用的特征和[13]中類似,它有2784個維度,包括8個顏色通道,如RGB,HSV和YCbCr,以及在亮度通道上使用Gabor和Schmid濾波器獲得的21個紋理通道。第二個是MLCNN[16],用滑動窗策略把圖片分割成多個小圖,然后輸入到多輸入的神經網絡里自動提取特征,并用此特征進行分類。
2? ?分? ?析
實驗結果如表1,26個屬性中有24個是本文方法的分類準確率更高。本文方法的平均準確率為90.41%,高于ikSVM的81.01%和MLCNN的85.83%。這些結果表明本文的方法在大部分屬性上都優于ikSVM和MLCNN。ikSVM是對每個屬性單獨的訓練分類器,因此在某些屬性上ikSVM的準確率要高一點,MLCNN雖然是對多個屬性聯合訓練,但是多輸入的網絡,其復雜度要高很多,訓練參數也很多,因此訓練難度更大。本文把多屬性當作是一個序列結合CTC loss設計了一個單輸入的時序網絡,使用ResNet50充分發揮深度網絡特征表達能力強的優勢,使得多標簽的分類準確率很高,用ImageNet預訓練參數初始化ResNet50,大大提升了訓練速度。因此,本文方法在大部分屬性分類中取得了更高的表現。
3? ?結? ?論
提出了一個用于行人屬性分類的多標簽分類網絡,該網絡通過CNN自動提取特征,并且能夠預測多個屬性。在PETA數據集上的實驗表明了該網絡在行人屬性分類上有很好的效果。未來的研究目標,在網絡中加入多尺度特征融合以應對數據集中圖片大小相差比較大的問題,進一步提升分類效果。
參考文獻
[1]? ? JAHA E S,NIXON M S. Analysing soft clothing biometrics for retrieval[C]. Biometric Authentication,2014:234—245.
[2]? ? DANTCHEVA A,SINGH A,ELIA P,et al. Search pruning in video surveillance systems:eficiency-reliability tradeoff[C]// IEEE International Conference on Computer Vision Workshops,2012.
[3]? ? JAIN A K,DASS S C,NANDAKUMAR K. Soft biometric traits for personal recognition systems[M]// Biometric Authentication,2004.
[4]? ? DANTCHEVA A,DUGELAY J L,ELIA P. Person recognition using a bag of facial soft biometrics (BoFSB)[C]// IEEE International Workshop on Multimedia Signal Processing,2010.
[5]? ? KUMAR N. Attribute and simile classifiers for face verification[C]// IEEE International Conference on Computer Vision. IEEE,2010.
[6]? LAYNE R,HOSPEDALES T M,GONG S. Towards person identification and re-identification with attributes[C]// European Conference on Computer Vision,2012.
[7]? ? 朱旭鋒,馬彩文.基于多不變量和多分類器融合的飛機識別[J].儀器儀表學報,2011,32(7):1621—1627.
[8]? ?LI X D,YANG W D,JEAN D. An Airplane Image Target′s Multi-feature Fusion Recognition Method[J]. 自動化學報,2012,38(8):1298—1307.
[9]? ? HUSSEIN G T,REDDY S E. Satellite remote sensing image based aircraft recognition using transform features and detect fuzzy clustering[J].International Journal of Engineering Science and Computing,2016:4590—4594.
[10]? ZHU X,MA B,GUO G,et al. Aircraft type classification based on an optimized bag of words model[C]// Guidance,Navigation & Control Conference,2017.
[11]? LI H,JIN X,YANG N,et al. The recognition of landed aircrafts based on PCNN model and affine moment invariants[J]. Pattern Recognition Letters,2015,51(C):23-29.
[12] YAN T W,GARCIA-MOLINA H. SIFT:a tool for wide-area information dissemination[C]// Usenix Technical Conference,1995.
[13] DENG Y B,LUO P,CHEN C L,et al. Pedestrian Attribute Recognition At Far Distance[C]// the ACM International Conference. ACM,2014.
[14]? JAHA E S,NIXON M S. Soft biometrics for subject identification using clothing attributes[C]// IEEE International Joint Conference on Biometrics,2014.
[15] AN L,CHEN X,KAFAI M,et al. Improving person re-identification by soft biometrics based reranking[C]// Seventh International Conference on Distributed Smart Cameras,2014.
[16]? ZHU J,LIAO S,LEI Z,et al. Multi-label convolutional neural network based pedestrian attributeclassification[J]. Image & Vision Computing,2017,58(C):224-229.
[17]? SHI B,BAI X,YAO C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2015,39(11):2298-2304.
[18]? HE K,ZHANG X,REN S,et al. Deep residual learning for image recognition[EB/OL]. https://arxiv.org/abs/1512.03385,2015.
[19] GRAVES A,SANTIAGO F,GOMEZ F. Connectionist temporal classification:labelling unsegmented sequence data with recurrent neural networks[C]// International Conference on Machine Learning,ACM,2006.
[20]? DENG Y,LUO P,LOY C C,et al. Learning to recognizepedestrian attribute[EB/OL]. https://arxiv.org/abs/1501.00901,2015
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
