基于BiLSTM-Attention唇語識別的研究
2020-04-09 04:48:53劉大運房國志駱天依魏華杰王倩李修政李驁
計算技術與自動化 2020年1期
關鍵詞:深度學習
劉大運 房國志 駱天依 魏華杰 王倩 李修政 李驁

摘? ?要:為了解決唇語識別中唇部特征提取和時序關系識別存在的問題,提出了一種雙向長短時記憶網絡(BiLSTM)和注意力機制(Attention Mechanism)相結合的深度學習模型。首先將唇部20個關鍵點得到的唇部不同位置的高度和寬度作為唇部的特征,使用BiLSTM對唇部特征序列進行時序編碼,然后利用注意力機制來發掘不同時刻唇部時序特征對于整體唇語識別的不同權重,最后利用Softmax進行分類。在公開的唇語識別數據集GRID和MIRACL-VC上與傳統的唇語識別模型進行實驗對比。在GRID數據集上準確率至少提高了13.4%,在MIRACL-VC單詞數據集上準確率至少提高了15.3%,短語數據集上準確率至少提高了9.2%。同時還與其他編碼模型進行了實驗對比,實驗結果表明該模型能有效地提高唇語識別的準確率。
關鍵詞:唇語識別;雙向長短時記憶網絡;注意力機制;深度學習;時序編碼
中圖分類號:TP391? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?文獻標識碼:A
Research on Lip-reading Based on BiLSTM-Attention
LIU Da-yun1,FANG Guo-zhi2?覮,LUO Tian-yi3,WEI Hua-jie1,Wang Qian1,Li Xiu-zheng1,Li Ao1
(1. School of Computer Science and Technology,Harbin University of Science
and Technology,Harbin,Heilongjiang 150080,China;
2. School of Measurement and Control Technology and Communication Engineering,
Harbin University of Science and Technology,Harbin,Heilongjiang 150080,China;
3. School of Automation,Harbin University of Science and Technology,Harbin,Heilongjiang 150080,China)
Abstract:In order to solve the existing problems in lip feature extraction and temporal relation recognition during the research of lip-reading,a deep learning model based on bi-directional long short-term memory(BiLSTM) and attention mechanism(Attention) is proposed. Firstly,the height and width of the different positions of the lip obtained from the 20 key points of the lip are taken as the characteristics of the lip. Secondly,the BiLSTM model is utilized to encode temporal information. Thirdly,the attention mechanism is used to explore different weights of lip sequential features at different times toward the overall lip language recognition. Finally,we use Softmax classifier to classify. Compared with the conventional lip-learning models at the current lip language recognition database GRID and MIRACL-VC,we find the recognition accuracy rate is more than 13.4% higher than that on GRID. In the MIRACL-VC word database,the accuracy rate increased by at least 15.3%,and the accuracy rate in the phrase database increased by at least 9.2%. At the same time,compared with other coding models,the experimental results show that this model can effectively improve the accuracy of lip-reading.
Key words:lip-reading;bi-directional long short-term memory;attention mechanism;deep learning;sequential coding
唇語識別集自然語言處理與機器視覺于一體,其研究的主要內容是從視頻圖像中識別出講話人所說的內容。近年來,唇語作為人類表達信息的重要載體,唇語識別技術獲得了廣泛的關注,已經被廣泛應用到案件偵破、安檢、輔助語音識別等[1.2.3]領域。
同語音識別相比,唇語識別存在更多困難。不同說話人在不同時刻和不同環境下,即使說話內容完全相同,其唇動信息也存在巨大差異。視覺特征的提取對于唇語識別來說尤為關鍵,明顯的特征應該具有類內一致性和類間差異性,一定程度上簡化后續的識別過程以及提升識別準確率。Petajan等人[4]在1984年首先提出了唇語識別系統,將提取到的唇語特征序列與數據集中全部特征模板進行相似度檢驗,相似度最高的詞作為預測輸出。Goldschen等人[5]在Petajian的唇語識別系統之上結合了語音識別中的建模方法對唇部特征進行了建模分析。Lan[6]等人用主動外觀模型的外表參數和形狀參數作為特征,從唇語視頻每幀圖像的嘴唇區域提取特征。Song[7]考慮到隱馬爾科夫模型(Hidden Markov Model,HMM)的雙向隨機過程和唇語序列識別過程的相似性,發現當HMM模型隱藏狀態數為5時效果最佳。徐銘輝等人[8]將唇動序列的形狀特征和圖形特征做為唇部特征,最后使用半連續HMM模型實現了唇語識別。Zhao等人[9]提出了一種基于時空局部二值的特征表示方法,采用支持向量機(Support Vector Machine,SVM)對短語進行分類識別。Pei等人[10]通過對無監督隨機森林流形對齊的研究,提出了新的節點分裂標準,以避免學習過程中森林等級不足。近期馬寧等人[11]將Schmidhuber和Hochreiter[12]提出長短時記憶單元(Long Short-Term Memory,LSTM)應用到唇語識別中,解決了唇語信息多樣性的問題。
上述模型雖然在唇語識別上取得了一定的效果,但是依舊存在一些問題。傳統的特征提取方法,特別是主動形狀模型,只是用了4個點來描述唇部特征,并沒有抓住唇部的更多細節,因此使用唇部的20個關鍵點計算出唇部不同位置的高度和寬度。LSTM雖然解決了HMM存在的問題,但是在唇語識別中未來信息對當前信息也存在一定影響,LSTM并沒有考慮這些,因此使用了雙向長短時記憶網絡(Bidirectional Long Short-Term Memory,BiLSTM),充分考慮到過去信息和未來信息對當前信息的影響。由于不同時刻的唇部時序特征對于識別的貢獻程度不同,在BiLSTM層后加入注意力機制(Attention Mechanism)。
1? ?基于BiLSTM-Attention的唇語識別模
型
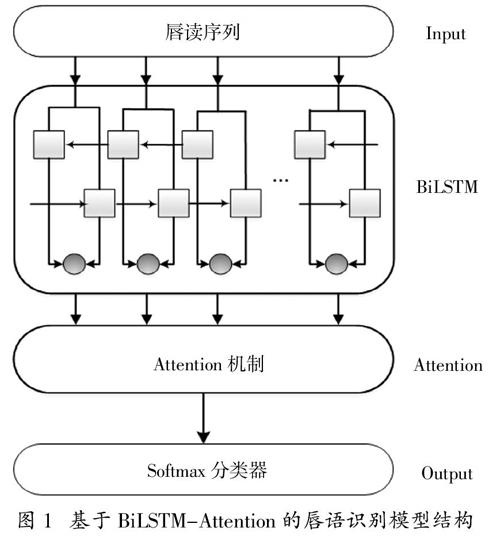
基于BiLSTM-Attention的唇語識別模型如圖1所示。該模型主要由四個部分組成:
(1)利用改進的主動形狀模型提取唇部特征;
(2)利用BiLSTM模型對唇部特征序列進行時序編碼;
(3)引入Attention機制發掘不同時刻唇部時序特征的重要程度;
(4)利用分類器進行特征分類。
圖 1? ?基于BiLSTM-Attention的唇語識別模型結構
1.1? ?輸入層
傳統的唇部特征提取方式是提取出唇部的4個關鍵點來模擬唇部的形狀,然而其提取的關鍵點太少導致其不能很細膩地刻畫出唇部的特征從而影響識別的準確率,因此在此基礎之上我們做了改進。首先使用dlib庫提取出唇部的20個關鍵點,然后根據這20個關鍵點計算出唇部不同位置的高度和寬度,將得到的高度和寬度作為唇部的特征。
通過對每一個視頻的每一幀進行如上的處理,可以得到每一個視頻的唇部特征序列S:
S = [w1,w2,…,wi,…,wn]? ? ? ? (1)
其中n為特征序列的長度,wi代表第i幀的唇部特征。
然后將唇部特征序列S送入到BiLSTM中進行時序編碼。
圖2? ?唇部的20個關鍵點
1.2? ?BiLSTM
為了解決傳統循環神經網絡(RNN)梯度消失的問題,1997年Hochreiter和Schmidhuber等人[8]提出長短期記憶模型(Long Short-Term Memory,LSTM)。LSTM模型由一系列相同的時序模塊單元連接而成,每個模塊包括:遺忘門ft、輸入門it、輸出門ot和記憶單元Ct。LSTM中重要公式如下:
ft = σ[wf·(ht-1,xt) + bf ]? ? ? ? (2)
it = σ[wi·(ht-1,xt) + bi ]? ? ? ? (3)
■t = tanh(wc·[ht-1,xt + bc)? ? ? ?(4)
■t = tanh(wc·[ht-1,xt + bc)? ? ? ?(5)
ot = σ[wo·(ht-1,xt) + bo ]? ? ? ?(6)
ht = ot* tanh(Ct)? ? ? ?(7)
其中wf、wi、wo、wc為LSTM模型的權重矩陣,bf、bi 、bo 、bc 為LSTM模型的偏移量,ht為t時刻的隱藏狀態。
LSTM已經廣泛地運用在唇語識別領域,然而LSTM僅考慮到過去信息對當前信息的影響,在實際的唇語識別過程中,同樣需要充分考慮未來信息對當前信息的影響。例如在唇讀數據集中句子“Nice to meet you.”時,僅憑借單詞“Nice”判斷出下文單詞“to”的準確率很低。只有同時兼顧“to”的上下文信息“Nice”和“meet”,才能全面捕獲對唇語識別有價值的唇部特征序列,提高唇語識別準確率,因此采用BiLSTM對上下文信息進行處理更為恰當。
BiLSTM是將時序相反的兩個LSTM網絡連接到同一個輸出,運用前向隱含層結點和后向隱含層結點,分別捕獲上下文信息。兩個隱含層的結果共同作用,輸出最終結果。
圖3? ?雙向長短時記憶網絡結構
BiLSTM通過引入第二層LSTM網絡來擴展單向的網絡結構,在應用到唇語識別時,兩層LSTM網絡在相反的時間順序上連接相同的唇部特征序列輸入。其中一層神經網絡編碼當前時刻和之前時刻的唇部特征信息,另一層神經網絡則編碼該時刻的下文信息,得到一組相反方向的隱含層結點信息。向前和向后的隱含層之間并不存在信息流,但它們都連接到同一個輸出層,使得輸出層輸入序列的每個點都包含完整的過去和未來的上下文信息。這種相互獨立的雙向LSTM網絡結構,保證了我們更加充分地利用唇動序列的特征信息對當前信息進行準確判斷,識別的準確率相比于單向的LSTM網絡顯著提高。
本部分將改進的主動形狀模型提取到的唇部特征序列利用BiLSTM進行時序編碼,得到唇部的時序特征向量,送入到Attention機制。
1.3? ?Attention機制
人類在觀察某一個物體時,往往著重于觀察物體的某個特定區域,并適當忽略一些不重要的區域,以此來快速準確的獲得當前目標的主要信息。趙富等[13]將這種Attention機制運用在文本情感分類中,更多地關注對情感分析有價值的部分,提高了情感分類的準確度;馮興杰等[14]在研究句子相似度的過程中引入了Attention機制,將更多的精力集中在句子中的關鍵單詞上,有效的提高了智能客服系統的辨識能力。
在唇語識別過程中,同樣面臨著唇讀上下文不規則停頓、讀音相似等原因造成的識別準確率低的問題。實驗時,提取到的唇部特征序列對于唇語識別準確率的影響程度往往有所差異,一個單詞的關鍵信息往往隱含在某一段連續幀中,因此有必要引入Attention機制將這些重要信息進行提取。
例如一個人在唇讀“She sells sea shells on the seashore.”這句話時,不同單詞在很多幀上有相同的唇型。這些相同的唇部特征往往不能良好的區分單詞之間的差異,能夠區分他們的特征信息集中在那些唇型不相同的幀上。因此將Attention機制引入其中,對不同單詞的特征幀分配更多的注意力,提高了唇語識別準確率。與此同時,位于句中停頓處的幀對于唇語識別準確率同樣存在一定程度的影響。將這些停頓時產生的幀分配較少的注意力,優化了識別過程。
Attention機制通常分為時間注意力機制和空間注意力機制,本文用到的是時間注意力機制。Attention機制的基本結構如圖4所示。
圖4? ?注意力機制網絡結構
在Attention機制中,根據不同時刻的唇部時序特征的重要程度設計注意力機制:
ut = tanh(ww Ht + b)? ? ? ? (11)
at = softmax(utT,uw)? ? ? ? (12)
vt = ■at Ht? ? ? ? (13)
其中,ut為隱藏層單元,at為注意力向量,Ht為BiLSTM的輸出,vt為Attention機制的輸出向量。
通過概率權重分配的方式,對唇語視頻中不同時刻的唇部時序特征分配不同概率權重,使得一些更重要時刻的唇部特征能夠得到更多的關注,從而進一步提高唇語識別的準確率。
1.4? ?分類層
將Attention機制的輸出Ci送入Softmax分類器進行分類,輸出為:
y = softmax(wiCi + b)? ? ? ? (14)
本實驗中每個輸入序列對應輸出是一種條件概率:
p(b|a1,a1,…,an) = p(b|An)? ? ? ? (15)
p(b|An) = ■? ? ? ? (16)
p(b|An)是用于計算An屬于每一類輸出結果的條件概率,R是數據集,包含訓練的單詞和短語的全部視頻。
2? ?實驗結果分析
2.1? ?數據集介紹
為了驗證本文模型的有效性,選取了在國際上稍具影響力的唇語識別公開數據集GRID[15]和MIRACL-VC[16]進行實驗。
GRID數據集由34人錄制而成,視頻質量分為普通畫質和高質量畫質。圖像分辨率360 × 288,時長約 3s,幀率約 25 fps。該數據集包括每人唇讀1000條英文句子的視頻。
MIRACL-V數據集由5男10女通過微軟Kinect錄制而成。圖像為分辨率640 × 640的深度圖和彩色圖,語料包含10個單詞和10個短語。該數據集總共包含每人唇讀所有單詞和短語各10遍的視頻圖像,總共包含3000個樣本。
2.2? ?實驗設置
為了和前人的實驗形成對比,在GRID數據集和MIRACL-VC數據集的設置上和馬寧[7]的一樣,在GRID數據集上我們隨機選取15人的唇讀視頻,GRID數據集將說話者所說的每個單詞的開始時間和結束時間進行了標記,只選取數字部分進行識別。在15人的唇讀視頻中,選取14人的樣本進行訓練,1人進行驗證。在MIRACL-VC數據集上,同樣將15人的唇讀視頻進行如上處理。
在神經網絡搭建上,由于使用的Keras深度學習框架進行搭建模型,該深度學習框架在搭建LSTM和BiLSTM時要求其長度固定,因此在GRID數據集和MIRACL-VC的單詞數據集中分別選取最大幀數19和21作為其固定長度,在MIRACL-VC短語數據集上選取最大幀數27作為其固定長度。經過多次調參測試,將BiLSTM的參數設為128。為了加快訓練速度,在注意力機制層后加入BatchNormalization層。
2.3? ?實驗結果
在GRID數據集上,將本文的實驗結果同Lan等人[6]和馬寧等人[11]的實驗結果進行對比。Lan等人[6]分別使用主動外觀模型的外表參數(app),形狀參數(shape)以及采用主成分分析將外表參數和形狀參數相融合(aam_pca)做為唇部特征,然后使用HMM對唇部特征進行訓練。馬寧等人[11]提取了唇部18個關鍵點的坐標然后利用LSTM進行時序編碼。
表1? ?在GRID的實驗結果
可以看到,在GRID數據集上,本文模型的識別準確率比Lan等人的識別準確率至少提高了33.3%。比馬寧等人的識別準確率提高了13.4%。
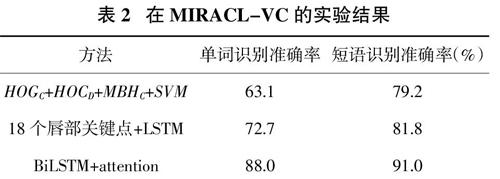
在MIRACL-VC數據集上,我們將本文的實驗結果同Rekik等人[16]和馬寧等人[11]的實驗結果進行對比。Rekik等人[16]同時考慮了RGB圖像序列特征(HOGC)、深度圖像序列特征(HOGD)以及傳統的運動特征(MBHC),然后使用SVM進行訓練。
表2? ?在MIRACL-VC的實驗結果
在MIRACL-VC數據集上,本文模型比Rekik等人和馬寧等人的單詞識別準確率分別提高了24.9%和15.3%,短語識別準確率分別提高了11.8%和9.2%。
2.4? ?和其他編碼模型進行實驗對比
為了進一步驗證我們編碼模型的有效性,在唇部特征提取方面依舊使用改進的主動形狀模型,在時序編碼方面我們將BiLSTM-Attention分別換成LSTM和BiLSTM進行對比試驗。
表3? ?不同編碼模型在GRID的實驗結果
表4? ?不同編碼模型在MIRACL-VC的實驗結果
從表3和表4中可以看出采用BiLSTM-Attention方法在GRID數據集上比LSTM時序編碼的方式提高了6.3%,比BiLSTM時序編碼的方式提高了3.6%。在MIRACL-VC數據集上單詞部分比LSTM時序編碼的方式提高了9.7%,比BiLSTM時序編碼的方式提高了5.9%,短語部分比LSTM提高了8.8%,比BiLSTM提高了7.0%。
step
圖5? ?三種模型在MIRACL-VC短語數據集的loss圖
圖5是MIRACL-VC 數據集短語部分三種模型的訓練loss圖,橫坐標為迭代次數,縱坐標為損失函數的輸出。從圖中看出BiLSTM-Attention方式的loss下降的最快,同時在近100次迭代時BiLSTM-Attention最先收斂,其loss值接近于0,收斂效果最好。
由上述實驗可以看出,模型更好地提取了唇部的特征、既考慮了唇語識別中過去信息對當前信息的影響和未來信息對當前信息的影響,同時考慮不同時刻唇部時序特征對唇部識別的影響程度不同,極大地提高了唇語識別的準確率。
3? ?結? 論
提出了一種BiLSTM-Attention的唇語識別模型。該模型提取了20個唇部關鍵點,能夠細膩地刻畫出唇部特征,同時利用BiLSTM對唇部特征進行時序編碼,BiLSTM相比現有唇部識別模型既考慮了過去信息對當前信息的影響也考慮未來信息對當前信息的影響,最后利用時空上的注意力機制對BiLSTM的輸出分配不同的權重進一步提高了識別的準確率。這種方法在公開的唇語數據集GRID和MIRACL-VC上比現有的唇語識別方法準確率提高了10%左右。結果表明BiLSTM-Attention模型對唇語識別準確率的提高有顯著的作用。同時在實驗部分還有一些需要完善的地方,例如本文使用的語料庫只是英文數據集,未對中文數據集進行實驗,下一步將針對這些問題進行進一步改進。
參考文獻
[1]? ? PETAJAN E,GRAF H P. Automatic lipreading research:historic overview and current work[J]. Multimedia Communications and Video Coding,1995:265—275.
[2]? ? 任玉強,田國棟,等. 高安全性人臉識別系統中的唇語識別算法研究[J]. 計算機應用研究.2017,34(4):1221—1225.
[3]? ?WECHSLER H,PHILLIPS J P,BRUCE V,et al. Face recognition:from theory to applications[M]. Washington DC:Springer Science & Business Media,2012:16—17.
[4]? ? PETAJAN E D. Automatic lipreading to enhance speech recognition (SpeechReading)[M]. University of Illinois at Urbana-Champaign,1984.
[5]? ? GOLDSCHEN A J,GARCIA O N,PETAJAN E D. Continuous automatic speech recognition by lipreading[M]//Motion-Based Recognition Springer Netherlands,1997:321—343.
[6]? ? LAN Y,HARVEY R,THEOBALD B J,et al. Comparing visual features for lipreading[C]. Proceeding of International Conference on Auditory-Visual Speech Processing,2009:102—106.
[7]? ? 宋文明. 基于HMM與深度學習的唇語識別研究[D]. 大連:大連理工大學,2017.
[8]? ? 徐銘輝,姚鴻勛. 基于句子級的唇語識別技術[J]. 計算機工程與應用,2005(08):86—88.
[9]? ? ZHAO G,PIETIKAINEN M,HADID A. Local spatiotemporal descriptors for visual recognition of spoken phrases[C]// Hcm 07 International Workshop on Human-centered Multimedia,2007.
[10]? PEI Y,KIM T,ZHA H. Unsupervised random forest manifold alignment for lipreading[C]. ICCV,Sydney,Australia,2013,129—136.
[11]? 馬寧,田國棟,周曦. 一種基于long short-term memory的唇語識別方法[J]. 中國科學院大學學報,2018,35(1):109—117.
[12]? SCHMIDHUBER J,HOCHREITER S. Long short term memory[J]. Neural Computation,1997,9(8):1735—1780.
[13]? 趙富,楊洋,蔣瑞,等. 融合詞性的雙注意力Bi-LSTM情感分析[J].計算機應用,2018,38(S2):103—106,147.
[14]? 馮興杰,張樂,曾云澤. 基于多注意力CNN的問題相似度計算[J]. 計算機工程,2019,45(09):284—290.
[15]? COOKE M,BARKER J,CUNNINGHAM S,et al. An audio-visualcorpus for speech perception and automatic speech recognition[J].The Journal of the Acoustical Society of America,2006,120:2 421—2424.
[16]? REKIK A,BEN-HAMADOU A,MAHDI W. A new visual speech recognition approach for RGB-D cameras[C]. International Conference Image Analysis and Recognition.Springer International Publishing,2014:21—28.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
