基于卷積神經網絡特征圖聚類的人臉表情識別
2020-04-09 04:48:53劉全明辛陽陽
計算技術與自動化 2020年1期
劉全明 辛陽陽

摘? ?要:針對卷積層存在的特征冗余問題,提出了一種基于卷積神經網絡的特征圖聚類方法。首先通過預訓練網絡參數提取網絡最后一層卷積層的特征圖,然后對特征圖進行聚類操作,取聚類中心構成新的特征圖集合,以聚類后的特征圖集作為數據集訓練分類器。將有監督的深度學習方法與傳統的機器學習方法相結合,使用特征圖聚類進行特征去冗余讓網絡學習到更有效的特征。去冗余后的特征使用神經網絡分類器在fer2013測試集上達到了71.67%準確率,在CK+測試集上達到86.98%準確率,證明了該人臉表情識別方法的有效性。
關鍵詞:卷積神經網絡;特征冗余;特征圖聚類;表情識別
中圖分類號:TP391.4? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?文獻標識碼:A
Facial Expression Recognition Based on Convolutional
Neural Network Feature Map Clustering
LIU Quan-ming?覮,XIN Yang-yang
(College of Computer and Information Technology,Shanxi University,Taiyuan,Shanxi 030006,China)
Abstract:To solve the problem of feature redundancy in convolution layer,a feature graph clustering method based on convolution neural network is proposed. Firstly,the feature map of the last convolution layer of the network is extracted by pre-training network parameters,and then the feature map is clustered. The clustering center is taken to form a new set of feature graphs,and the clustered feature graph set is used as the training classifier of the data set. This paper combines supervised in-depth learning method with traditional machine learning method,and uses feature graph clustering to remove redundancy so that the network can learn more effective features. After redundancy removal,the neural network classifier achieves 71.67% accuracy on fer2013 test set and 86.98% accuracy on CK + test set,which proves the validity of the facial expression recognition method.
Key words:convolutional neural network;feature redundancy;feature graph clustering;facial expression recognition
人臉表情不僅可以傳達人類情緒,而且還能夠表現人類豐富情感信息。研究發現,信息交流過程中,可通過人臉傳遞的信息量占據了總信息量的55%[1],因此通過人臉表情的識別來獲取信息是一種有意義且可行的操作。心理學家Mehrabian[2]最早提出人類有六種主要情感,每種情感以唯一的表情來反映人的一種獨特的心理活動。這六種情感被稱為基本情感,由憤怒(anger)、高興(happiness)、悲傷 (sadness)、驚訝(surprise)、厭惡(disgust)和恐懼(fear)組成,后又添加了中性共七種表情。人臉表情識別主要是針對這七種表情,通過人臉定位、特征提取和分類識別來自動分辨人臉表情類別。
特征提取與分類識別是人臉表情識別的關鍵環節。基于模型的靜態特征提取方法通常采用主動形狀模型或者主動外觀模型來定位人臉的關鍵點位置,然后在關鍵點位置提取幾何或者紋理特征[3]。基于圖像的靜態特征提取方法通常采用Gabor變換[4]、主成分分析[5]、局部二元模式[6]等提取圖像的靜態特征。在分類識別方面,通常采用機器學習建立分類器,對人臉表情特征進行分類,常用的方法有迭代算法(Adaboost)[7]、支持向量機(SVM)、神經網絡[8]和深度學習網絡[9]等。目前基于深度學習的表情識別方法的主要問題在于特征相關度過高或者冗余數據過多,耗費時力且識別精度一般[10]。
特征提取的過程中需要進行特征選擇[11,12]。常用的特征選擇方法是最大化特征與分類變量之間的相關度,即選擇與分類變量擁有最高相關度的變量。但是在特征選擇中,由于特征之間可能是高度相關或相似的,因此多個出色的特征組合并不能增加分類器的性能,這就導致了特征變量的冗余[12]。由Peng et.al提出的一種濾波式的特征選擇方法最小冗余最大相關性(mRMR)[13,14],mRMR的核心思想最大化特征與分類變量之間的相關性,而最小化特征與特征之間的相關性。在神經網絡中通過池化層進行特征選擇并利用層剪枝[15]的方式來壓縮模型,達到壓縮參數[16]和減少計算量目的。文獻[10]提出一種基于特征相關性的特征選擇方法,利用聚類挑選出具有代表性的特征,取得了不錯的分類效果。
提出了一種基于卷積神經網絡特征圖聚類的人臉表情識別方法:先使用一個卷積神經網絡進行預訓練,在預訓練網絡最后一層池化層后添加分類誤差去更好的學習最后一層卷積層的權重參數。通過預訓練的權重參數提取出樣本圖像的最后一層卷積層的特征圖,分別使用SVM和神經網絡分類器對聚類后的特征圖進行分類。我們提出在融合剪枝層的基礎上進行特征圖聚類,通過聚類進行更深層次的特征選擇,以刪除高度相似的人臉表情特征,減少計算量的同時提高模型的效率,并提高人臉表情分類精度。通過實驗比較和分析驗證了本文方法的正確性與有效性。
1? ?網絡設計
主要介紹基于卷積神經網絡特征圖聚類的人臉表情識別使用的預訓練網絡、特征圖聚類方法、分類器以及使用的損失函數,使用特征圖聚類來選取有效特征,利用淺層網絡在保持較少的參數量的同時保證分類準確率。
1.1? ?預訓練網絡
卷積神經網絡主要包括輸入層、卷積層、池化層、全連接層和輸出層[17]。通過輸入層將圖像以張量的形式傳入到網絡中,通過一系列的卷積層進行特征提取,池化層用來進行特征選擇,在網絡中的特征以圖的形式進行映射傳遞。池化層得到有效的特征經過全連接層進行特征組合,將這些具有辨別性的特征用來進行表情分類。預訓練模型網絡框架如圖1所示:
圖1? ?預訓練模型網絡框架
預訓練網絡主要由卷積層,池化層和全連接層這三部分組成,與大多數卷積神經網絡相似,在卷積層后接池化層,網絡后端為全連接層。利用卷積層提取圖像的局部紋理等特征,通過最大池化層進行下采樣[18],分支網絡直接在最后一層池化層后添加一個分類層,該層的神經元個數和主干網絡最后一層相同,防止由全連接層的級聯低維映射和激活函數造成的編碼特征損失,可以讓網絡前層卷積層學習到更好的參數。主干網絡的最后一層使用Soft max層進行分類。
1.2? ?特征圖聚類(Feature-Image-Cluster,FIC)
假設網絡一次訓練一個樣本,在通過最后一個卷積層后會有64張特征圖,對這64張特征圖進行K聚類實現特征降維及有效特征的選取,如式(1)所示。
mapcuuster = K(mapConv,k)? ? ? ? ? (1)
k為類別個數,mapcluster為聚類后的k個類別的聚類中心組成的新的特征圖,mapConv為卷積層生成的原始特征圖,K為聚類操作。
圖2中圖(a)為訓練樣本圖;圖(b)為網絡最后一層卷積層的特征可視化圖,從圖中可以發現有部分特征圖相似;圖(c)為對最后一層卷積層的64張特征圖聚類后得到的每一類聚類中心;圖(d)為聚類后的屬于某一類的特征圖,從圖中可以發現第一行的第1,2,3張,第二行的第3,4張,第三行的第4張,第四行的第1張相似,它們表示的特征具有相似性。通過聚類只選取每一類的聚類中心用于分類。
圖2? ?特征圖聚類過程
1.3? ?分類器
分別采用SVM分類器和Soft max神經網絡分類器(FC)進行分類結果分析,將聚類后的特征圖作為分類器的輸入,SVM分類器使用前先采用PCA對特征進行降維,然后采用RBF核的SVM進行分類;Soft max神經網絡分類器主要由全連接層構建,輸入的是特征圖的聚類中心圖,通過全連接層連接到輸出,最后一層全連接層使用的激活函數是soft max,所以也稱Soft max層,通過Soft max層將輸出變為屬于各個類別的概率。
1.4? ?損失函數
在預訓練網絡中我們使用分支網絡的分類誤差和主干網絡的分類損失引導訓練。
1)分類誤差:是指圖像的類別標簽和預測值之間的誤差。如式(2)所示:其中zj表示分類層中第j個神經元的激活值,m代表神經元的個數,即圖像類別。
L (classification)(y,z) = -log(e■/■e■)? ? ? ? ? (2)
2)分類損失
可以將基于深度學習的表情識別作為一個多分類問題,設計卷積神經網絡結構。作為一個用于多分類的卷積神經網絡結構,自然離不開soft max激活函數。使用soft max激活函數實現從特征空間到[0,1]概率空間的映射,得到每一個像素分類得分的概率,然后使用交叉熵指導網絡訓練。將通過分類層得到的輸出作為交叉熵的輸入,計算得到分類損失。分類損失公式如式(3)所示,假設樣本類別數為n,則分類層有n個輸出向量,Si是分類層的輸出向量S的第i個值,表示樣本屬于第i個類別的概率,y是一個1*n的向量,而且只有一個1值其余則都為0,Lsoft max表示的是分類損失。
Lsoft max = -■yilogSi? ? ? ? ? (3)
預訓練網絡的總損失如式(4)所示,包含兩部分。全連接層的低維映射和非線性映射會產生的分類誤差,將這些低維映射進行級聯則會損失分類精度。通過建立分支網絡,在最后一個池化層后添加一個分類層,并計算分類誤差來解決問題。
L = L (classification) + Lsoft max? ? ? ? ? (4)
2? ?實驗
實驗通過在具有GPU的1080ti顯卡的電腦上搭建TensorFlow框架來構建網絡模型并訓練,各個模型的訓練參數如表1所示。
表1? ?訓練參數
2.1? ?預處理數據集
使用fer2013數據集和CK+數據集來訓練網絡進行實驗分析。
Fer2013人臉表情數據集由35886張人臉表情圖片組成,其中,訓練集28708張,驗證集和測試集各3589張。每張圖片是由大小固定為48*48的灰度圖像組成,共有7種表情,分別對應于數字標簽0-6,具體表情對應的標簽和中英文如下:0(anger)生氣;1(disgust)厭惡;2(fear)恐懼;3(happy)開心;4(sad)傷心;5(surprised)驚訝;6(neutral)中性。
CK+人臉表情數據集由920張人臉表情圖片組成,本文隨機選取734張為訓練集,剩下186張為測試集,我們將每張圖片是由大小固定為48*48,共有8種表情,具體表情對應的標簽和中英文如下:(anger)生氣;(contempt)輕視;(disgust)厭惡;(fear)恐懼;(happiness)開心;(sadness)傷心;(surprise)驚訝;(neutral)中性。
使用網絡進行原始樣本的訓練,得到預訓練權重,將其作為網絡初始化權重提取最后一層卷積層的特征圖,對提取到的特征圖進行聚類得到新的特征圖作為分類器的訓練集。由于處理數據量較大,為了方便處理數據,將提取到的特征圖保存為CSV格式。
如圖3(a)所示對fer2013數據集七個表情類下每個樣本提取的最后一層卷積層聚類后的特征圖,每個類別下都有多個樣本(橫行),每個樣本下有多張特征圖(縱行),數據保存為CSV格式。本文通過實驗分析采用K=40的聚類,所以每個樣本下都有40張特征圖。圖3(b)為將聚類后的特征圖保存為CSV格式文件后的標簽值和像素值。第一列label是數據樣本對應的標簽,后面列pixel0-pixel5759表示(12*12*40)個像素的像素值。12*12表示的是聚類后每張特征圖的大小,40表示的是聚類后每個樣本下有40張特征圖。對于CK+數據集的處理與fer2013數據集的處理方式相同。
(a)每個類別下的特征圖
(b)CSV文件
圖3
2.2? ?實驗展示
首先分別在fer2013和CK+的訓練集上進行實驗。通過比較不同K值在訓練集上的準確率選擇合適的K值,然后通過在訓練集上混淆矩陣的比較進一步確定本文方法的可行性。最終分別在兩個數據集的測試集上進行驗證。
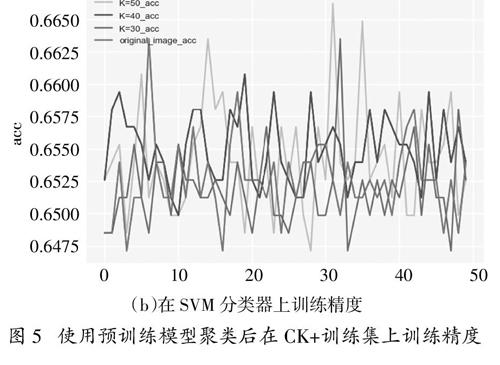
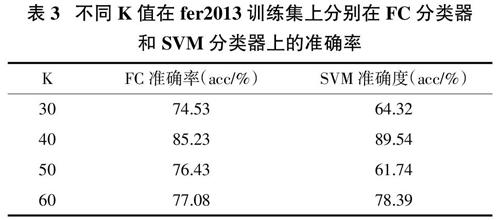
采取不同K值聚類得到的準確率如圖4,5所示,從圖中我們可以發現當K=40時在fer2013訓練集和CK+訓練集上分別使用FC分類器和SVM分類器有一個較高的準確率,圖中的original_image_acc表示的是K=64。表3和表4是分別對兩個數據集使用FC分類器和SVM分類器的準確率值。根據圖和表展示的結果,本文采用K=40聚類進行接下來的實驗。
epoch
(a)在FC分類器上訓練精度
epoch
(b)在SVM分類器上訓練精度
圖4? ? 使用預訓練模型聚類后在fer2013訓練集上訓練精度
(a)在FC分類器上訓練精度
(b)在SVM分類器上訓練精度
圖5? ?使用預訓練模型聚類后在CK+訓練集上訓練精度
表3? ?不同K值在fer2013訓練集上分別在FC分類器
和SVM分類器上的準確率
表4? ?不同K值在CK+訓練集上分別在FC分類器
和SVM分類器上的準確率
如圖6所示為不同策略在fer2013訓練集上的混淆矩陣,從混淆矩陣結果可以看出,本文方法在每個類別上的分類準確率都有所提高。圖6(a)為CNN模型的混淆矩陣;圖6(b)是特征圖聚類后采用FC分類器的混淆矩陣,其中最低分類正確率為0.53,是對第三種類別的正確分類,而最高分類是對第四種表情達到0.87;圖6(c)是特征圖聚類后采用SVM分類器的混淆矩陣,其中最低分類正確率為0.62,是對第六種類別的正確分類,而最高分類是對第七種表情達到0.98。
通過以上在fer2013訓練集混淆矩陣結果,我們確定了本文方法的有效性。分別在fer2013的測試集和CK+測試集上進行驗證,比較本文方法和一般的CNN方法,準確率如表5和表6所示,在fer2013測試集上進行特征圖聚類后使用Soft max神經網絡分類器準確率為71.67%,而CNN方法只有67.94%,SVM分類器由于分類器的局限性導致準確率并沒有大的提升。
(a)CNN
(b)FC分類器
(c)SVM 分類器
圖6 預訓練模型和特征圖聚類在fer2013訓練
數據集上的混淆矩陣圖
表5? ?采取不同策略在fer2013訓練集
和測試集上準確率的比較
表6? ?采取不同策略在CK+數據集上訓練集
和測試集準確率的比較
如表7所示,將本文方法與現有的單模型和集成方法在fer2013測試集進行比較,本文方法在使用相對較淺層的網絡也能夠達到一些先進的單模型方法的精度。從表中可以看出單模型中精度最好的是CPC方法準確率為71.35%,而本文方法也能夠達到71.67%的準確率。
表7? ?與最新的方法在fer2013數據集測試集上準確率比較
3? ?總結
提出一種基于卷積神經網絡特征圖聚類的人臉表情識別方法。對于人臉表情識別首先使用訓練好的參數提取最后一層卷積層的特征,通過聚類得到的特征圖聚類中心作為分類器網絡的輸入,來訓練分類器。通過實驗表明使用特征圖聚類來進行特征去冗余讓網絡學習的特征更有效,使用淺層網絡也能達到深層網絡的分類準確率。實驗在fer2013數據集和CK+數據集都得到不錯的準確率,實驗模型評估結果均證明了該方法的有效性。然而由于考慮到反向傳播訓練參數問題所以分步訓練,不能直接將聚類融合到神經網絡訓練當中,導致我們在數據處理上比較耗時,在接下來的工作當中我們將重點研究深度聚類,實現可融合到深度模型中可訓練的方法。
參考文獻
[1]? ? 陳航. 基于卷積神經網絡的表情識別研究[D]. 南京:南京郵電大學,2018.
[2]? ? MEHRABIAN A. Communication without words[J]. Psychology Today,1968,2(4):53—56
[3]? ? YI J Z,XIA M,MITSURU I,et al. Facial expression recognition based on feature point vector and texture deformation energy parameters[J]. Journal of Electronics & Information Technology,2013,35(10):2403—2410.
[4]? ? LI Kuan,YIN Jian-ping,LI Yong,et al. Local statistical analysis of Gabor coefficients and adaptive feature extraction for face description and recognition[J]. Journal of Computer Research and Development,2019,49(4):778—784.
[5]? ? LUO Y,WU C M,ZHANG Y. Facial expression feature extraction using hybrid PCA and LBP[J]. The Journal of China Universities of Posts and Telecommunications,2013,20(2):120—124.
[6]? ?CAO N T,TON-THAT A H,CHOI H I. Facial expression recognition based on local binary pattern features and support vector machine[J]. International Journal of Pattern Recognition and Artificial Intelligence,2014,28(06):1456012.
[7]? ? GHIMIRE D,LEE J. Geometric feature-based facial expression recognition in image sequences using multi-class AdaBoost and support vector machines[J]. Sensors,2013,13(6):7714—7734.
[8]? ? KIM B K,ROH J,DONG S Y,et al. Hierarchical committee of deep convolutional neural networks for robust facial expression recognition[J]. Journal on Multimodal User Interfaces,2016,10(2):173—189.
[9]? ? LIU P,HAN S,MENG Z,et al. Facial expression recognition via a boosted deep belief network[C]// 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society,2014.
[10]? 蔣盛益,王連喜. 基于特征相關性的特征選擇[J]. 計算機工程與應用,2010,46(20):153—156.
[11]? 黃輝. 基于ReliefF的多標簽特征選擇算法研究[D].廣州:廣東工業大學,2018.
[12]? 劉強,劉波,康同曦. 基于全局最小冗余的多視角數據分類研究[J].無線互聯科技,2016(18):110—111+136.
[13]? 林培榕. 基于鄰域互信息最大相關性最小冗余度的特征選擇[J]. 漳州師范學院學報:自然科學版,2013,26(04):13—18.
[14] PENG H C,LONG F H,DING C. Feature selection based on mutual information:criteria of max-dependency,max-relevance,and min-redundancy [C]//IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,(27):1226—1238.
[15]? 楊文慧. 基于參數和特征冗余的神經網絡模型壓縮方法[D].西安:西安電子科技大學,2018.
[16]? 陳超. 基于參數與特征冗余壓縮的卷積神經網絡加速算法研究[D]. 廈門:廈門大學,2017.
[17]? 趙澎楨.基于網絡圖片數據庫與深度學習的人臉表情識別[J].中國高新科技,2018(19):107—110.
[18]? 楊斌,鐘金英. 卷積神經網絡的研究進展綜述[J].南華大學學報:自然科學版,2016,30(03):66—72.
[19]? JEON J,PARK J C,JO Y J,et al. A real-time facial expression recognizer using deep neural network[C]// International Conference on Ubiquitous Information Management & Communication. ACM,2016:1-4.
[20]? CHANG T,WEN G,HU Y,et al. Facial expression recognition based on complexity perception classification algorithm[J]. 2018.
[21]? LI D,WEN G,HOU Z,et al. RTCRelief-F:an effective clustering and ordering-based ensemble pruning algorithm for facial expression recognition[J]. Knowledge and Information Systems,2019,59(1):219—250.
