基于深度學習的無人機土地覆蓋圖像分割方法
2020-03-09 07:35:36劉文萍宗世祥駱有慶
農業機械學報 2020年2期
劉文萍 趙 磊 周 焱 宗世祥 駱有慶
(1.北京林業大學信息學院, 北京 100083; 2.北京林業大學林學院, 北京 100083)
0 引言
土地覆蓋動態變化是全球變化過程中的重要因子[1],土地覆蓋分類是研究土地覆蓋動態變化的基礎[2-3],包含準確分類數據的土地覆蓋圖同時能夠為農業監控、城鄉規劃、生態服務研究以及土地政策制定等工作提供關鍵信息,具有重大的現實意義[4-9]。
編制土地覆蓋圖所需數據的傳統獲取方法以人工實地調查為主,該方式需要耗費大量的人力物力,周期長,且無法獲得準確的地理分布情況[2]。隨著空間技術和計算機技術的不斷發展,利用隨機森林[10]、支持向量機[11]、決策樹[12]、卷積神經網絡[13-16]等算法對衛星遙感影像進行圖像分析,在土地覆蓋數據獲取研究中取得了一定的成果,但是衛星遙感影像成本高、時效性差,且分辨率較低,不足以反映地物細節,嚴重影響土地覆蓋類型的識別精度,得到的數據不能滿足編制精細土地覆蓋圖的要求。
近年來無人機低空遙感技術發展迅速,因其機動靈活、成本低廉、成像分辨率高的優點,已成為獲取高分辨率遙感數據的重要手段[17],并在土地資源調查、監測與分類領域得到廣泛研究和應用[2,18-23]。然而無人機圖像的處理方法大部分沿用了處理衛星遙感圖像的思路,其工程量巨大,傳統圖像分析的方法甚至需要人工選取特征參數。
語義分割方法的出現和發展為高分辨率圖像分割與分類提供了新的思路。2014年LONG等[24]提出用于語義分割的全卷積神經網絡(Fully convolutional networks, FCN),該方法自動完成特征提取,并對圖像中所有像素點逐一進行分類,在Pascal VOC 2012圖像分割數據集[25]上平均交并比(Mean intersection-over-union, MIoU)為67.2%,遠優于基于滑動窗口的方法。此后基于FCN框架的語義分割技術發展迅速,在Pascal VOC 2012圖像分割數據集上各項評價指標均有大幅提升[26-32],其中融合編解碼結構的DeepLabV3+模型將MIoU提升至89%,該模型能夠準確分割不同區域并分類,得到高質量的分割圖。但是與大型通用圖像數據集不同,無人機高分辨率復雜土地覆蓋圖像前景不明確,部分圖像類間差異小、類內差異大,直接應用DeepLabV3+模型,得到的結果分割精度較低、分類噪聲較大。
本文采用深度學習技術,對語義分割模型DeepLabV3+進行改進,應用在包含多種土地利用類型的無人機高分辨率復雜土地覆蓋圖像上,以分割不同土地覆蓋類型的區域。通過訓練得到有效的分割模型,并進行實驗,驗證其性能。
1 數據集
1.1 數據采集
實驗數據采集于山東省臨沂市郯城縣(118°E,34°N),大疆“御”專業版無人機,搭載3軸云臺,可控俯仰轉動范圍-90°~30°,橫滾0°或90°,角度抖動量±0.02°;相機鏡頭為FOV78.8°(35 mm格式等效),原始圖像分辨率為4 000像素×3 000像素。各區域完整航片拼接圖像如圖1所示。

圖1 航片拼接圖
1.2 數據集建立
為提升模型的訓練速度,降低運算量,將拼接后圖像尺寸裁剪為512像素×512像素,裁剪后圖像共1 296幅。根據《土地利用現狀分類》中12個一級類劃分方式,使用labelme開源標注工具,對裁剪后的圖像逐像素點標注,并按照2∶1的比例隨機劃分為訓練集和測試集,其中訓練集圖像864幅,測試集432幅,數據集有效類別數為8。
2 分割方法
本文提出的分割方法基于DeepLabV3+語義分割模型,并進行了4點改進:①采用加入擴張卷積的深度殘差網絡ResNet[33](以下簡稱ResNet+)作為主干網絡,加速模型收斂,提高實驗精度。②在主干網絡后增加一個聯合上采樣模塊融合多層特征,增強模型編碼器的信息傳遞能力。③調整ASPP模塊,移除全局池化連接并采用較小的擴張率組合,避免精度損失。④解碼器融合更多的淺層特征,提高模型對特征圖包含的空間位置信息的利用能力。原始模型架構如圖2a所示,改進后的模型架構如圖2b所示。

圖2 模型架構
2.1 ResNet+網絡
主干網絡作為模型編碼器的組成部分,主要功能是對特征自動提取。原始模型對Xception[34-35]進行修改,得到Xception+作為主干網絡,主要調整包括:①conv5階段新增8組共24層卷積網絡。②conv5階段的部分網絡層替換為擴張卷積,如表1所示。擴張卷積的作用是增大特征圖感受野的同時,保持特征圖尺寸,避免空間位置信息的損失。以輸入尺寸5像素×5像素為例,標準卷積一步操作如圖3a所示,卷積核尺寸為3×3,步長為2像素,填充值為1像素,感受野尺寸為3像素×3像素,擴張卷積一步操作如圖3b所示,卷積核尺寸為3×3,擴張率為2像素,步長為1像素,填充值為2,感受野尺寸為5像素×5像素。可以看到,擴張卷積能夠在增大感受野的同時保持特征圖尺寸,既不影響特征描述效果,還可保留豐富的空間位置信息,對語義分割模型來說非常關鍵。

表1 Xception網絡與Xception+網絡的結構對比
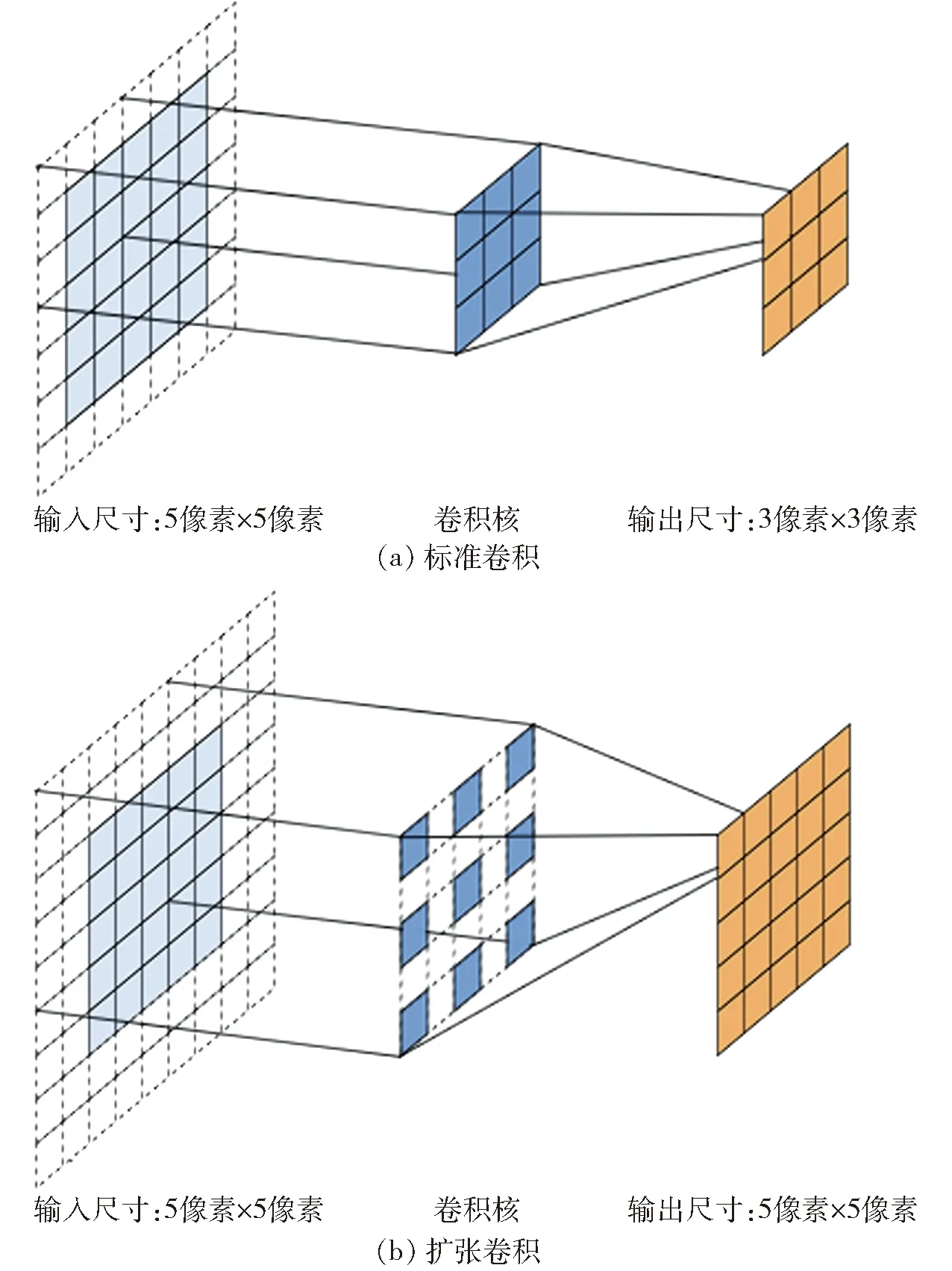
圖3 標準卷積和擴張卷積一步操作
但是Xception+作為主干網絡,存在以下問題:① Xception+相比原始Xception,網絡層數大幅增加,有較高比例的網絡層無法加載ImageNet預訓練模型的參數,只能進行隨機初始化,嚴重影響模型收斂速度。②Xception+和Xception中均存在大量的可分離卷積,這樣的設計能夠提升運算效率,但是應用在無人機土地覆蓋圖像上,對模型精度損害較大。
本文對ResNet網絡進行修改,替換conv5階段的部分標準卷積為擴張卷積,得到ResNet+作為主干網絡,如表2所示。ResNet+中不存在可分離卷積,并且擴張卷積層之外的所有網絡層,均能加載ImageNet預訓練模型參數,進行有效初始化,大幅提升了DeepLabV3+模型的精度和收斂速度。但是主干網絡中加入擴張卷積,會增加模型后續階段的計算成本,因此本文只研究在conv5階段加入擴張卷積的情況,最終主干網絡各個階段的特征圖f1、f2、f3、f4、f5尺寸分別為原始輸入圖像尺寸的1/2、1/4、1/8、1/16和1/16,如圖2b所示。

表2 ResNet網絡與ResNet+網絡的結構對比
2.2 編碼器加入聯合上采樣模塊
在圖像分析中,聯合上采樣旨在利用已有圖像作為先驗,將其結構化的細節信息傳遞給目標圖像。本文在主干網絡之后引入一個聯合上采樣模塊,傳遞多個不同特征圖的信息至主干網絡的輸出特征圖,有效增強了模型編碼器信息傳遞能力,可利用更多結構化信息,提高分類與分割精度;模塊還對輸入的部分特征圖進行采樣率為2的上采樣,如圖2b所示,聯合上采樣模塊接收特征圖f3、f4、f5作為輸入,分別采用卷積核尺寸為3×3的卷積層進行處理,將f3和f4的通道數降低為512(與f5相等);模塊還分別對f4和f5進行一次采樣率為2的上采樣,然后將3個經過處理的特征圖進行逐通道拼接,得到一個新的特征圖,用于后續操作。
2.3 調整ASPP模塊
原始模型編碼器中,ASPP模塊結構如圖2a所示,該模塊由擴張率分別為1、8、12、16的4個擴張卷積和1個全局池化連接組成,用以捕獲不同尺寸的目標。但是不同于通用數據集圖像,本文數據集中土地覆蓋圖像經過裁剪后,各土地利用類型區域在圖像中所占面積較為接近,尺寸變化幅度小,如圖4所示。

圖4 通用數據集圖像和土地覆蓋圖像裁剪對比
原始模型中該模塊的擴張率組合{1,8,12,16}和全局池化連接降低了分割的精度。本文對原始的ASPP模塊進行調整,如圖2b所示,采用較小的擴張率組合{1,2,4,8},并移除全局池化連接,以改善模型在本文土地覆蓋圖像上的分割效果。
2.4 解碼器的改進
解碼器主要功能是對特征圖進行上采樣,擴大特征圖尺寸以得到最終的圖像分割結果。如圖2a所示,解碼器將主干網絡中含有豐富空間位置信息的淺層特征圖f2和ASPP的輸出特征圖f6進行融合,輸出一個與原始圖像輸入尺寸相同的分割圖。原始解碼器結構較為簡單,沒有充分利用編碼器各個階段輸出的特征圖信息。
為此本文對原始解碼器進行改進,改進后的解碼器如圖2b所示,輸入為淺層特征圖f1、f2、f3以及ASPP的輸出特征圖f6。首先分別對這4個特征圖進行一個卷積核尺寸為3×3的卷積操作,將4個特征圖的通道數分別降為48、48、64和256;然后將處理后的特征圖f2、f3和f6進行上采樣,使其尺寸與f1一致;四者進行逐通道拼接,再經過一次采樣率為2的上采樣,輸出一個與原始輸入圖像尺寸相同的分割掩碼圖。
3 實驗與結果分析
3.1 實驗環境與模型訓練
實驗在Ubuntu18.04LTS 64位系統下進行,基于Pytorch開源深度學習框架并使用NVIDIA GEFORCE GTX 1080ti顯卡加速。模型訓練階段采用動量為0.9的隨機梯度下降算法進行優化,初始學習率為0.001,以4幅圖像為一個批次進行120次完整迭代,學習率從第100次迭代開始減小為0.000 1,使用交叉熵損失函數,訓練過程中進行了簡單的數據增廣:首先以50%的概率對單幅圖像及其標注圖像同時進行水平翻轉;再以同樣的概率,對單幅圖像進行隨機高斯濾波處理。
3.2 評價指標
為了客觀合理地評價模型在無人機土地覆蓋圖像上的分類與分割精度,本文使用像素準確率(Pixel accuracy, PA)和平均交并比作為評價指標,指標的數值越大,模型的效果越好。
3.2.1像素準確率
像素準確率能夠表示像素點分類的精度,用圖像中分類正確的像素點數量與像素點總數的百分比來表示,計算式為
(1)
式中pii——像素點i被預測為i的數量
pij——像素點i被預測為j的數量
C——數據集中不同土地利用類型的數量,本文為8
3.2.2平均交并比
平均交并比是語義分割模型的標準度量指標,定義為
(2)
通過計算每一類真實值像素集合和預測值像素集合的交集和并集的比值,得到每一類別的交并比后,計算所有類的平均值即為平均交并比,該指標在實驗中能夠較好地反映模型在不同利用類型的土地區域上分割的準確性和完整性。
3.3 實驗結果分析
不同組成的模型在無人機土地覆蓋圖像測試數據集上的實驗結果如表3所示。模型1為原始DeepLabV3+模型,主干網絡為Xception+,在測試集上PA為80.51%,MIoU為55.73%;模型2在模型1的基礎上替換主干網絡為ResNet+,PA和MIoU分別提升了11.46個百分點和12.50個百分點;模型3在模型2的基礎上加入聯合上采樣模塊,PA和MIoU分別比模型2提升了1.55個百分點和10.25個百分點;在模型3的基礎上調整ASPP模塊后得到模型4,PA和MIoU有小幅提升,分別為93.60%和79.50%;最終應用改進后的解碼器得到模型5,PA和MIoU分別提升至95.06%和81.22%,相比原始DeepLabV3+模型即模型1,兩個指標分別提升了14.55個百分點和25.49個百分點。
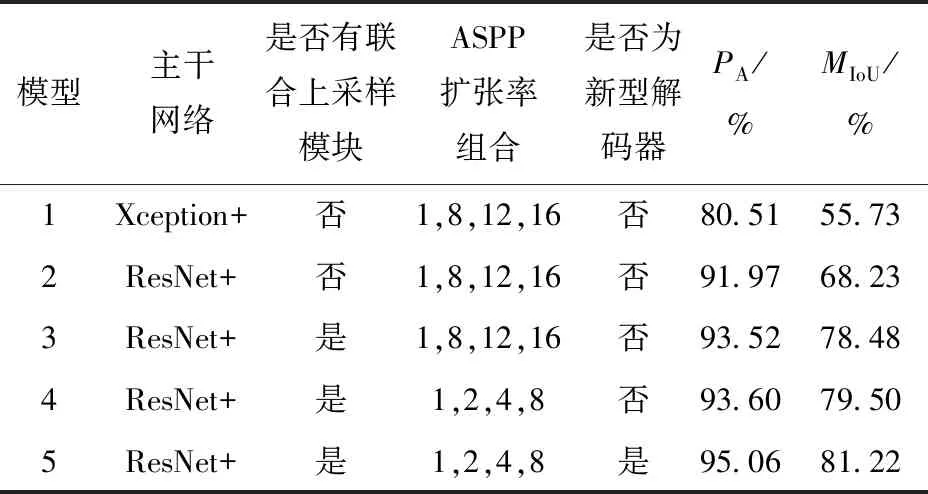
表3 不同模型在測試集上的實驗結果
另外,采用相同的數據集和參數分別訓練了FCN-8S模型和PSPNet模型,與本文提出的方法進行對比,結果如圖5所示。可以看到,常用的FCN-8S模型收斂速度較慢,相同迭代次數的情況下效果最差;原始DeepLabV3+由于使用Xception+作為主干網絡,兩個指標波動較大,但與PSPNet接近;本文模型的兩個指標均為最高,且收斂速度快,對無人機土地覆蓋圖像數據集的分割與分類效果最好。
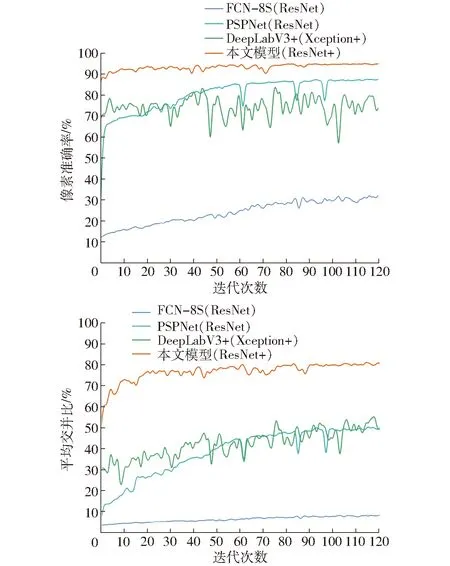
圖5 測試集上像素準確率和平均交并比隨迭代次數的變化
3.4 分割結果與分析
本文利用多個模型在包含432幅圖像的測試數據集上進行實驗,部分分割結果如圖6所示。可以看到,本文方法在復雜的土地覆蓋圖像上分割和分類精度都較高,而且對無人機圖像拼接過程造成的小幅圖像變形具有較高的魯棒性。
盡管模型取得了較好的效果,但是實驗中也出現了一些低質量的分割結果,如圖7所示。由圖7a可知,當原始圖像發生大范圍的變形時,模型分割結果會受到嚴重干擾。圖7b中的白框區域中樹木遮擋了部分道路,造成分類錯誤。圖7c的白框區域中,耕地的農作物行間種植了較多樹木,導致模型的低質量分割結果。

圖6 PSPNet、DeepLabV3+和本文模型的分割效果對比

圖7 低質量的模型分割結果
4 結論
(1)針對現有土地覆蓋數據獲取方法成本高、精度低、工程量大等問題,應用深度學習技術,提出一種面向無人機高分辨率復雜土地覆蓋圖像的語義分割方法。該方法能夠對不同土地利用類型的區域進行分割并分類,得到質量較高的土地覆蓋數據,用于編制精細土地覆蓋圖。
(2)該方法基于DeepLabV3+語義分割模型并進行改進,編碼器中將主干網絡替換為ResNet+,增加聯合上采樣模塊,調整ASPP模塊,解碼器中融合更多淺層特征。結果表明,本文提出的方法像素準確率為95.06%,平均交并比為81.22%,相比原始DeepLabV3+模型像素準確率提高了14.55個百分點,平均交并比提高了25.49個百分點,能夠得到效果更好的分類與分割結果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
