基于遷移學習的FDR土壤水分傳感器自動標定模型研究
2020-03-09 08:03:34李鴻儒于唯楚王振營
農業機械學報 2020年2期
關鍵詞:模型
李鴻儒 于唯楚 王振營
(1.東北大學信息科學與工程學院, 沈陽 110819; 2.沈陽巍圖農業科技有限公司, 沈陽 110021)
0 引言
土壤含水率是土壤的重要參數,也是農業灌溉決策、管理中的基礎數據[1-2],準確獲得可靠的土壤含水率在農業生產中極為重要。近年來,隨著傳感器技術的發展,利用頻域反射技術(FDR)對土壤含水率進行測量,獲得了業內的普遍認可,得到了廣泛應用[3-5]。
土壤物理性質多種多樣,不同地區以及同一地區的不同時間土壤性質也會存在差異,使得FDR傳感器在不同土壤中的測量結果不同,因此FDR傳感器在某區域首次使用以及使用一段時間后均需重新標定。對于傳感器的標定方法已有許多學者進行了研究。文獻[6]提出了土壤水分傳感器的三級標定方法,即對土壤水分傳感器的安裝標定、田間標定以及測量數據標定,提高了測量數據的準確性,但標定過程較為繁瑣。文獻[7]證明了FDR系統適用于檢測濕地土壤中的土壤含水率,但校準程序受到土壤性質的限制。文獻[8]分析得出,土壤水分站點數據可用性低,是因為田間標定法在自然條件下幾乎無法得到覆蓋土壤各個濕度區間的均勻樣本數據,導致二次標定參數不合理。綜合以上研究可發現,FDR傳感器標定存在數據采集耗時、費力,可用于標定的有效數據較少,人工操作與參數擬合存在一定誤差等問題。
隨著科技的發展,機器學習技術在土壤含水率建模方面得到了廣泛應用。文獻[9]在室內利用ASD FieldSpec 3型高光譜儀獲取土壤的原始光譜,在進行數據預處理和不同數學變換后,通過最小二乘回歸法、逐步回歸法、嶺回歸法建立了土壤含水率高光譜模型;文獻[10]通過對數據進行歸一化處理和數據融合,能夠根據不同區域進行劃分和在不同作物灌水下限進行相應的運算,從而得到估計精度較高、區域大小可調的多尺度精準灌溉決策信息;文獻[11]提出電容式土壤濕度傳感器大規模校準的半自動化框架,但是不能完全消除數據不確定性帶來的影響。如果將不同地區數據進行統計,使用機器學習方法進行標定,則可解決標定的有效數據較少的問題,但不同地區數據特征存在差異。相關學者使用了遷移學習的解決方法,如文獻[12-13]采用遷移學習方法解決了小樣本下圖像識別準確率低的問題;文獻[14]采用深度遷移學習對柑橘葉片鉀含量進行了精準預測。
針對當前FDR傳感器標定問題,本文以沈陽地區采集到的壤土為研究對象,考慮土壤性質、溫度等因素對FDR傳感器測量結果的影響,利用其他地區已獲取的數據,采用機器學習方法訓練模型,實現不同目標域之間的樣本遷移和融合,建立基于遷移學習的FDR傳感器自動標定模型。
1 數據來源
1.1 研究區概況
研究區位于遼寧省沈陽市(123.4°E,41.78°N,海拔5~441 m),該地區為溫帶半濕潤大陸性氣候,年平均氣溫6.2~9.7℃。
沈陽巍圖農業科技有限公司對FDR傳感器有長期的研究基礎,在全國范圍建有測試站點。為本文的研究提供了沈陽地區6個測試站點的數據,分別為站點11~16,其他地區10個站點數據分別為站點1~10(分別為北京、天津、西安、武漢、廣州、重慶、大連、哈爾濱、銀川、長春)。
本文將沈陽地區各站點作為FDR傳感器目標使用地點,其他地區數據作為參考。沈陽地區供試土壤類型為壤土,土粒密度為2.70 g/cm3,容重為1.2 g/cm3,孔隙度55%,顆粒組成見表1。

表1 實驗土壤顆粒組成
1.2 干燥法土壤水分測量原理
干燥法也叫稱量法。利用恒溫箱,在溫度為105℃的條件下將土壤干燥至恒定質量,干燥前后土壤質量做差,再與干燥達恒定質量時的干土質量做比值,結果與土壤容重相乘即得到土壤體積含水率θ,采用百分數的形式表示。
1.3 FDR土壤水分測量原理

圖1 傳感器等效電路圖
FDR型土壤水分測定傳感器是一種利用LC電路的電磁振蕩,根據電磁波在不同介質中振蕩頻率的變化來測定介質的介電常數ε,通過一定的對應關系反演出真實土壤體積含水率θv的儀器。傳感器采用串聯LC諧振電路,其等效電路如圖1所示[7]。
根據電路原理,當諧振發生的條件成立時,諧振頻率
(1)
式中L——電感,HC——電容,F
采用新型水鹽一體傳感器,傳感器標定過程中,首先在室內通過專用設備測試各層傳感器在空氣和純水中的頻率,以確定傳感器的基點和極大值,用于對傳感器測試結果歸一化,歸一化頻率定義為[8]
(2)
式中Fn——歸一化頻率
Fa——空氣中傳感器輸出頻率,Hz
Fw——純水中傳感器輸出頻率,Hz
Fs——土壤中傳感器輸出頻率,Hz
研究發現,土壤介電常數與溫度有關,使得FDR測得頻率存在誤差。針對該問題,文獻[15-18]建立了溫度對土壤體積含水率的補償模型,減小了溫度對傳感器測量精度的影響;文獻[19]通過實驗的方式選擇了75 MHz為最佳頻率,消除溫度對頻率的影響。本文考慮在傳感器設計時已加入了溫度補償模型,對此不做深入探究。
傳統人工標定方法的FDR傳感器標定經驗公式為
(3)
式中a、b——標定參數
使用多組真實體積含水率θv與歸一化頻率Fn即可擬合曲線得到參數a、b,從而得到FDR測量的頻率與土壤體積含水率的函數關系式。
1.4 數據采集
采用沈陽巍圖農業科技有限公司研制的新型水鹽一體傳感器對全國16個站點進行長時間數據采集,涵蓋了土壤水分穩定期、緩慢消耗期、大量損耗期及恢復期的不同含水率的土樣。在每個站點分多個土層(土層深度為測試點距地表距離分別為10、20、40、60、80、100 cm)進行測試,測試記錄數據包括站點、土層深度、傳感器輸出頻率(包括Fa、Fw、Fs)以及與輸出頻率對應的真實體積含水率(干燥法測得),測試土壤體積含水率為5%~50%,其中站點1數據如表2所示。
2 研究方法
新型FDR土壤水鹽一體傳感器輸出的原始信號是頻率,傳感器的標定即是在頻率信號、土層深度和土壤含水率之間建立函數聯系。同時考慮到各個測量值與土壤體積含水率之間的相關性,計算其相關性矩陣如表3所示,矩陣中數據表示兩參數間相關性,相關系數取值范圍為[0,1],0表示無相關,1表示強相關。

表2 站點1不同土層數據
由表3可知,體積含水率與其他參數均存在一定相關性,因此在建立模型時采用Fa、Fs、Fw、FDR歸一化頻率Fn、土層深度作為輸入,土壤體積含水率θv作為輸出。
FDR土壤水分傳感器標定時需使用干燥法測體積含水率,代價很高,所以可用于傳感器標定的有效數據較少。因此,本文考慮結合其他地區測量的大量相關數據,使用機器學習方法建模分析。傳統的機器學習方法訓練和測試數據同分布,通過數據分析知,不同地區的數據分布不完全相同,故不能直接使用其他地區數據用于當前地區的傳感器標定模型訓練。為此,本文引入遷移學習的方法,采用TrAdaBoost算法在當前地區少量有效標定數據的情況下結合其他地區數據作為輔助進行模型建立。

表3 輸入輸出之間的相關系數
2.1 數據預處理與分析
2.1.1數據預處理
在數據建模前首先需進行數據清洗,去除異常數據。箱型圖不受異常值的影響,能夠準確穩定地描繪出數據的離散分布情況,利于數據的清洗。本文采用箱型圖的方法,處理結果如圖2、表4所示。針對異常值識別結果,剔除不符合框圖要求的數據,剔除輸入數據Fa在85.07~88.64 Hz外、Fw在58.55~64.85 Hz外、Fs在63.73~76.58 Hz外的數據。

圖2 輸入輸出數據的箱形圖

表4 輸入輸出數據排序
2.1.2數據分布分析
為驗證訓練數據和測試數據是否滿足同分布,以站點1~10數據為訓練數據,站點11~16數據作為測試數據進行分析,結果如圖3、4所示。由圖3、4可知,訓練數據和測試數據不滿足數據同分布,不能使用傳統機器學習方法直接訓練,故采用遷移學習方法。

圖3 站點1~10訓練數據概率密度分布
2.2 基于遷移學習的自動標定模型

圖4 沈陽地區站點11~16源域概率密度分布
采用集成學習算法——基于實例的TrAdaBoost遷移學習算法。TrAdaBoost[20-21]是戴文淵提出的一種基于實例的遷移學習算法,是一種從歷史數據中提取實例的方法,即將一部分能用的帶標簽歷史數據,結合帶標簽新數據(可能是少量),構建出比單獨使用帶標簽新數據訓練更精確的模型,適用于分類領域。本文模型的輸出為體積含水率,是連續型變量,應采用回歸模型,為此對TrAdaBoost算法進行改進,將該算法原為面向分類問題的基學習器AdaBoost,改為面向回歸問題的XGBoost。該算法所涉及的數據集包括輔助訓練數據、源域數據、目標域數據,其中輔助訓練數據是指大量相關數據;源域數據是指少量與測試數據同分布的數據;目標域數據是指測試數據,即實際應用時的無標簽數據。
基于其他地區10個站點數據(站點1~10),沈陽地區6個站點數據(站點11~16)為依據進行數據分析,將站點1~10的數據作為輔助訓練數據(Xb,共589條數據,其中站點1為棕壤土、站點2為潮土、站點3為紅粘土、站點4為黃棕壤土、站點5為紅壤土、站點6為黃壤土、站點7為潮土、站點8為黑土、站點9為灰鈣土、站點10為黑鈣土),站點11~16分別作為FDR傳感器目標使用地點,取其80%數據為源域數據(Xa)進行遷移學習訓練得到標定模型,剩余20%數據作為目標域數據驗證集測試模型誤差。在實際應用時,源域數據的采集要求在不破壞土質的情況下涉及10、20、40、60、80、100 cm土層,體積含水率在0%~20%、20%~30%、30%~50%均有數據,樣本量最多為輔助訓練數據樣本的10%,樣本量最少為20個,否則遷移學習算法將退化為基學習器效果。
2.2.1基學習器算法——XGBoost模型
將輔助訓練數據進行數據處理后,以Fn、土層深度作為輸入,體積含水率作為輸出,利用XGBoost作為基學習器對其進行訓練。
XGBoost[22]是一種基于集成學習的用于處理稀疏數據的樹學習算法。它的優點在于使用最少的集群資源擴展到更大的數據的端到端系統。
該算法的偽代碼為:

Fork=1 tom:
GL← 0,HL← 0
Forjin sort (I, byxjk) do
GL←GL+gj,HL←HL+hj
GR←G-Gj,HR←H-HL
end
end
輸出:分裂后的得分score
2.2.2目標域——面向回歸的TrAdaBoost算法
TrAdaBoost算法是采用AdaBoost作為基學習器的分類算法,為適應本文的回歸模型,將基學習器改為XGBoost。在TrAdaBoost算法中對權重進行迭代更新時采用誤分類樣本誤差率
(4)

對于回歸模型,修改誤差率計算式為
(5)
式中ht(xi)——回歸器的預測值
c(xi)——真實值
max|ht(xi)-c(xi)|——訓練集上樣本的最大誤差
改進后的TrAdaBoost算法既保留了XGBoost可降低過擬合、自動學習缺失樣本的分裂方向等優點,又彌補了XGBoost不能進行知識遷移的缺陷。改進后的算法偽代碼如下:
輸入:源域數據Xa,輔助訓練數據Xb,合并的訓練數據集T={Xa∪Xb},基學習器(Learner)XGBoost,迭代次數N。
(1)初始化
①初始化權重向量
其中

(2)權重迭代更新
對于t=1,2,…,N:
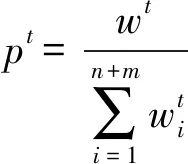
②調用Learner,根據合并后的訓練數據T以及T上的權重分布pt,得到一個回歸器ht
③根據式(5)計算ht在Xb上的誤差率

⑤重新調整權重
⑥得到最終的回歸器
(3)輸出最終的回歸器
對于輔助訓練樣本來講,預測值和標簽越接近,權重越大;而對于源域數據則相反,預測值和標簽差異越大,權重越大。需要找到輔助樣本中和源域數據分布最接近的樣本,同時放大源域樣本loss影響(增加源訓練數據中錯誤率大的樣本的權重,同時減小輔助訓練數據中錯誤的權重),那么源域樣本預測值與標簽盡量匹配,輔助樣本在前面處理的基礎上篩選出最匹配(權重大的)的部分。
3 實驗結果與分析
將站點1~10數據作為輔助訓練數據,站點11~16分別作為源域數據,進行傳感器標定模型訓練與測試。對每個站點進行標定時,取該站點80%數據作為源域數據,共60條數據;剩余20%數據作為測試集,共15條數據。
根據傳感器標定結果,由傳感器輸出頻率計算得土壤體積含水率為測試值,認為干燥法得到的土壤體積含水率為真實值,使用平均百分比誤差(MAPE)評估模型輸出結果的準確率。
為防止過擬合,在計算測試值時,在源域數據和測試集上采用k折交叉驗證。不重復地隨機將源域數據劃分為k個部分,k-1個部分用于訓練,剩余部分用于測試,重復該過程k次,得到k個模型對模型性能的評價,基于評價結果可以計算平均性能,此方法對數據劃分方法敏感度相對較低,每次迭代過程中每個樣本點只有一次被劃入訓練集或測試集的機會。本文使用k=5,即每個部分為站點數據的20%。
為驗證使用遷移學習進行初步模型校準的必要性,在站點11~16分別使用基學習器訓練得到初步標定模型,并用遷移學習得到最終的標定模型,對比初步標定模型與最終的標定測試準確率,結果如表5所示,基學習器模型列為初步標定模型的準確率,自動標定模型列為使用遷移學習對初步標定模型校準后的準確率。表5結果顯示,僅使用基學習器模型,準確率僅為65%左右,不能滿足傳感器標定要求;而使用遷移學習算法對模型進行校準后的準確率提升到了99%左右,已可滿足傳感器標定要求。故使用遷移學習的自動標定模型是有效且必要的。

表5 標定測試準確率
針對每個站點每個土層80%數據使用人工標定方法計算FDR傳感器標定參數,使用剩余20%數據計算人工標定傳感器測量準確率,每個站點準確率為該站點測試準確率平均值,結果如表5所示。與本文方法進行對比發現人工標定方法準確率為90%左右,而本文方法平均準確率達到99.1%,充分說明本文算法的有效性。
4 結論
(1)針對FDR傳感器有效標定數據量少的問題,提出了基于遷移學習的FDR土壤水分傳感器自動標定模型,僅需少量數據對模型進行校準即可使得模型輸出結果滿足要求。該算法克服了傳統人工標定數據采集費時、費力的問題,減少了對標定數據的需求。
(2)改進了TrAdaBoost算法,更新了訓練模型回歸誤差率的計算方式,并采用k折交叉驗證有效防止了過擬合問題。
(3)將本文方法與基學習器方法的實驗效果進行對比,結果顯示,在使用遷移學習進行模型校準后,大大提高了模型測試準確率,說明了基于遷移學習的自動標定模型的有效性。
(4)使用本文方法,傳感器在土壤體積含水率測試時,得到平均絕對誤差均小于2%,符合農業測量土壤含水率小于±5%的規范要求。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
