基于GScRNN 神經網絡的對抗樣本防御方法
2020-03-05 09:33:54牟志殷鋒袁平
現代計算機 2020年2期
牟志,殷鋒,袁平
(1.四川大學計算機學院,成都610065;2.西南民族大學計算機科學與技術學院,成都610041;3.重慶第二師范學院數學與信息工程學院,重慶400067)
0 引言
神經網絡近年來在計算機領域發展迅速,應用范圍廣泛,如人臉識別、情感分析、無人駕駛等都用到了深度神經網絡(DNN),性能甚至可以媲美人工判別。近年來隨著對DNN 技術的深入研究,神經網絡模型的一些問題也暴露了出來,其中就包括模型面對對抗樣本攻擊時表現出的弱魯棒性。
神經網絡模型可以簡化為函數形式f(x)=y,其中x 作為原始輸入,假使在原有輸入x 上添加細微擾動,令x*=x+Δx,使得f(x*)≠f(x),這樣的一種行為被稱為對抗攻擊。這種攻擊行為極大地威脅了基于深度學習誕生的智能系統,對于圖像處理領域而言,攻擊者對于交通指示牌添加人眼不可查覺的修改,可以使得無人駕駛系統做出錯誤的判斷從而引發重大交通事故;對于自然語言處理領域,攻擊者對垃圾郵件、短信通過添加修改刪除字詞等手段,使其規避掉垃圾文本識別系統的檢查,從而散播不良信息到社會網絡空間當中,因此,如何抵御對抗攻擊成為了一個亟待解決的問題,前人做了大量研究和實驗來探索對抗樣本存在的原因,總體上可以概括為如下兩點:
(1)有限的訓練樣本無法涵蓋空間內所有可能性,因此無法通過這樣的訓練樣本訓練處一個包含所有特征的模型。
(2)訓練模型的時候為了獲得更好的分類效果,模型會盡量擴大樣本和分類邊界之間的距離,但也在每一個分類區域中涵蓋了很多不屬于這個類別的樣本空間。
面對上述攻擊問題,Goodfellow 等人提出了對抗訓練的方法,在原有訓練數據集的基礎上主動添加攻擊樣本從而完善神經網絡的邊界;Liao F 等人嘗試用去噪網絡DAE 和DUNET 將對抗樣本還原成原始樣本[1]。Danish 在前人的研究基礎上,利用ScRNN 文本糾錯網絡結合自定義的補償策略來達到還原對抗樣本的目的。ScRNN 能夠識別出輸入文本中疑似經過對抗攻擊處理過的詞匯,通過補償策略將其替換為中性詞從而削弱其對模型輸出結果的影響。但是Danish 提出的補償策略并沒有很好地定義中性詞(Neutral)概念,本文基于詞向量的高斯分布,重新定義中性詞(GSNeutral),并在情感分類等多個任務上取得了優異的結果。
1 基于高斯分布的中性詞定義法
1.1 可行性分析
計算機無法直接識別現實世界中的表達符號,如圖片、文字、語音等,自然語言處理(NLP)致力于研究文字類智能系統。NLP 任務可以簡答地概括為上游任務和下游任務,上游任務將文字進行編碼表達為計算機能夠識別的符號,常見的下游任務包括實體識別、文本分類、摘要提取等等。上游任務是一個詞向量表達的構建過程,一種樸素的做法是使用One-hot 編碼,但會導致輸入空間極度稀疏,Miklov 等人提出改進的Word2Vec 用有限的維度地建立了更高質量的詞向量,Google 公司通過使用mask 技巧,使得雙向訓練稱為可能,構建出了與上下文聯系更緊密的Bert[2]。
優秀的詞向量直接影響著下游文本任務的結果,因此本文對于詞向量的構建采用了Bert,直接使用開源社區訓練好的Bert 模型應用到詞嵌入層。人在理解一段文本中某個詞語時,不僅僅依托于這個詞語自身的意義,還與其上下文有著緊密的關系[3]。Bert 自身通過雙向訓練賦予了其更加豐富的上下文語義,相比于Word2Vec,Bert 本身就具備一定的對抗防御能力,因此在本文提出的方法里,使用Bert 用作上游任務的詞向量構建。
歐美書寫體系中以英文為代表,為了檢測其中的書寫錯誤,前人做了大量的工作,其中ScRNN 作為一種典型的半監督網絡,可以有效地發現輸入文本中的拼寫錯誤,并且根據經驗模型進行一定程度的矯正,對錯誤的書寫發現有著很大的幫助。可以看出,對于發現輸入文本中的可疑段落,目前已經有相關技術可以實現。
1.2 算法描述
自然語言處理的上游任務可以歸納為一個構建詞向量表達的過程,原始輸入樣本在文本任務中為句子s,通過分詞以及停用詞可以將其分割成若干個詞匯,得到有若干Token 組成的輸入序列s( )t ={t1,t2…tn},序列經過神經網絡模型的詞嵌入層Embedding,每一個單詞Token 得到其對應的詞嵌入表達e(token)。在詞向量構建過程完成后,可以得到字典Vn*m,其中n 是訓練語料中所有Token 的個數,m 是詞嵌入層指定的維度,即每個Token 可以表達為一個m 維度的向量{v1,v2…,vm}。
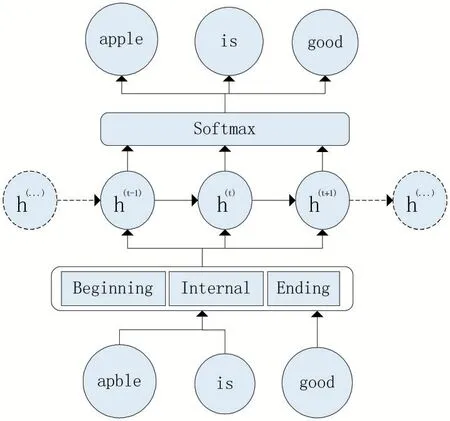
圖1 ScRNN網絡結構圖
高斯分布作為自然界最常見的連續概率分布,在許多領域都有著重要作用,本文提出一種新的方法根據高斯分布來重組中性詞。通過上述詞向量訓練的過程得到字典Vn*m,進行統計分析該字典中m 個維度的分布。假使其中一個維度i 上(1 ≤i ≤m)每個單詞的分量為{ v1,i,v2,i,…,vn,i},對該分量上的所有值做求和運算得到,依此方法遍歷計算每個維度上的和,得到一系列值{v1,v2,…,vm},計算上述所有值的均值,根據均值μ 和高斯分布構造出連續密度函數,中性詞根據構造出的高斯概率分布確定中性詞在每個維度上的值,得到中性詞

圖2 字典的詞向量矩陣表達
根據對詞向量的維度統計得到了一個更加合理的中性詞word*,下面將闡述如何將其運用到ScRNN 網絡中,以及如何進行對抗攻擊的防御。對于英文文本,對抗攻擊可以通過更改單詞中某個字符達到目的,但是更改后的單詞極有可能是一個并不存在的單詞,如apple 修改為apble,這樣的單詞稱為UNK,ScRNN 網絡可以做到識別出UNK。在識別出一個UNK 后,用上述中性詞word*將其替換,其目的就是極大地削弱這個單詞的傾向性,防止其對神經網絡模型的輸入造成誤導。
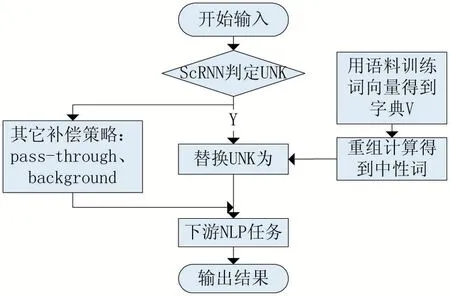
圖3 GScRNN整體流程圖
2 實驗分析
2.1 對比指標
為了更好地評判實驗結果,現需要給出對比指標的定義。在機器學習的研究中,準確率(Accuracy)是一個評判模型優劣的最常見的指標,本文依然會采用該指標,根據SMSSpamCollection 已經打好的標簽和本文模型預測結果來計算準確率,準確率越高意味著模型性能越好。
除了精確率之外,引用Danish 等人定義的另一項指標:敏感度(Sensitivity)。由于文本的詞向量空間有著離散的特性,即使通過某些手段獲取到連續的詞向量,但該向量在現實世界中可能并不存在對應的詞匯,因此攻擊者的攻擊空間有限,據此本文希望盡可能的削減攻擊空間,減少能夠引起神經網絡模型誤判的輸入樣本[4]。這種特性定義為敏感度,W 表達詞匯識別器,式(1)中W 可以生成的不同近似值。顯然,SAW,V值越高模型的魯棒性就越弱[5]。

2.2 實驗結果
本文將文本分類作為下游任務來考評模型面對對抗攻擊時的性能,使用公開的短信數據集SMSSpam-Collection。Bert 在多項自然語言處理任務中取得了優異的結果,在嵌入層上使用它構建詞向量。通過字符級別的攻擊手段修改、增加、刪除單詞中某個字符達到攻擊目的,比較不同的防御手段面對上述攻擊可以達到的分類正確率。
實驗對比幾種常見的防御方法:數據增強(DA)、對抗訓練(Adv)以及基于原補償策略的ScRNN 矯正網絡。模型在不同防御方法下的文本分類正確率的如表1 所示,結果顯示Bert 在不使用任何防御方法進行一個普通文本分類任務時正確率高達88.4%,但是在面對存在攻擊樣本的數據集時正確率大幅度下降:替換字符(61.1%)、刪除字符(57.6%)、增加字符(47.2%)。在添加防御方法后,在無攻擊狀態下雖然正確率有小幅下降,如BERT+ScRNN(86.9%),但是在對抗攻擊樣本的攻擊狀態中卻有著更優異的表現(80.2%)。在引入基于高斯分布的重構中性詞后,效果在原實驗結果上提升了1 個百分點(81.8%)。
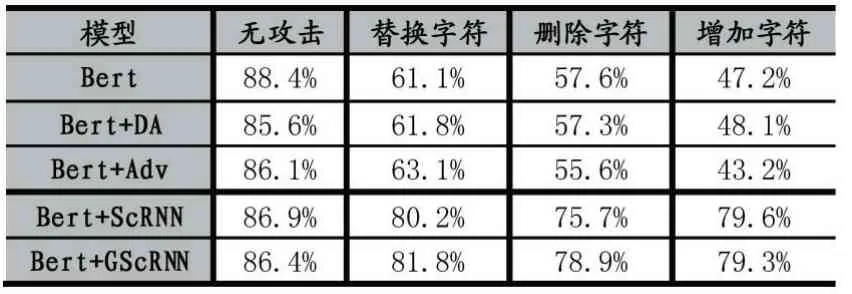
表1 Bert 模型面對不同攻擊時的性能指標
此外,為了評估不同防御方法下模型的敏感度,本文做了進一步實驗,對語料中的詞匯做隨機擾動,記錄其在各個防御方法下的敏感度,由于本文提出了對中性詞的重新定義與計算方法,實驗重點關注,相較于以前人工指出中性詞,新的中性詞定義方法對實驗結果的影響。攻擊后新生成的單詞相較于原詞匯的范式距離可以使用單詞錯誤率(WER)進行衡量,WER 值越大則表示攻擊程度越高,同時由于過高的WER 違背了輕微擾動的前提,需要將其限制在一定范圍之內。作者在同一語料下進行了10 次實驗對比,結果揭示了在語料上WER 與Sensitivity 之間的關系,本文提出的GSNeutral應用到機器學習模型后整體有著更低的敏感度。
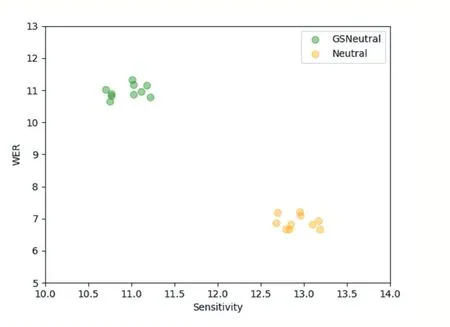
圖4 模型分別應用GSNeutral與Neutral的敏感度對比
3 結語
本文在ScRNN 網絡的矯正UNK 補償策略的基礎上,提出了一種新的中性詞定義方法GSNeutral,根據語料的詞向量概率分布來重新計算每個維度上的向量值,使其整體滿足高斯概率分布,當ScRNN 識別到UNK 時,用上述中性詞進行替換。本文實驗證明該方法相比原ScRNN 在進行文本分類任務時,可以更好地抵擋對抗攻擊,同時定義了用于對抗攻擊領域的新指標敏感度,該指標在使用了本文所述方法之后有所下降,即新的模型有著更低的敏感度,縮小了攻擊者能利用的攻擊空間,提高了模型的魯棒性。但是目前的方法只適用于英文文本,接下來的工作是如何將其延伸到中文的自然語言處理任務中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
