基于PageRank 算法的賭博網站靜態檢測技術改進研究
2020-03-05 09:33:32薛宛玥洪磊陳維杰程欣
現代計算機 2020年2期
薛宛玥,洪磊,陳維杰,程欣
(1.江蘇警官學院計算機信息與網絡安全系,南京210031;2.南京市公安局網絡安全保衛支隊,南京210005)
0 引言
網絡時代,因為互聯網的匿名和自由,賭博網站蔓延速度變快,危害變大[1]。尤其在移動互聯網發展迅速的今天,賭博網站借助木馬、釣魚等技術,滲透到正常網站中,吸引人們尤其是青少年進行投彩、下注等行為,嚴重影響我國社會治安和經濟安全。鑒于賭博網站的可復制性強,傳播速度快的特點,準確和高效地識別賭博網站至關重要。
1 現有研究綜述
違法網站自動識別技術已知的有3 大類,黑名單技術、靜態檢測技術和動態檢測技術[2]。基于人工建立和維護網址黑名單的黑名單技術,工作量大,成本高,無法識別新網站;基于爬蟲和決策樹的靜態檢測技術,理論完備,技術成熟,但是主要基于網站的靜態數據,如HTML 文檔等,這類數據易被偽裝,受反爬影響較大,相比黑名單技術對每一個網站寫入一條黑名單,靜態檢測只需要維護相對少量的判斷規則,維護更為方便,但是對于新網站的識別不夠及時和主動;基于利用蜜罐技術主動訪問檢測被訪問主頁攻擊方式的動態檢測技術,難度大,耗時長,對掛馬類違法網站識別效果較好,對博彩類網站識別效果較差。
黑名單檢測人力成本過高且更新維護成本巨大,現階段靜態檢測方法主動性不強、檢測速度有待進一步提高。靜態檢測方法的準確度理論值極高,現階段的瓶頸在于爬蟲與反爬機制的對抗,以及OCR、語音識別的準確度。
新型自動識別方法也有許多,如凡友榮的基于URL 特征檢測的識別方法[3]和張瀚瓏的基于模板檢測的違法網站識別方法[4]。一位是依據不同模版的URL進行聚類和特征提取,一位是依照網站模版的圖像進行識別。
基于PageRank 的網頁識別方法是在已有數據庫的前提(本次測試數據4000 條)下,通過深度爬蟲,基于原有鏈接與新鏈接之間的指向關系(數萬條數據)批量獲取分類結果,相比原有的靜態檢測方法更具主動性,經測試,每次分類可獲取賭博網站數占總量的60%以上。
2 實驗方法及原理
數據來源是前期通過爬蟲獲取的一批賭博網站數據,經過專家判斷后獲得了高質量域名數據集,也就是黑名單。
實驗數據使用域名,而非完整URL。一方面是因為域名和URL 存在包含關系,一個域名可以有多個URL,直接使用域名效率相對更高,制作黑白名單所需要的存儲空間更小,另一方面URL 的命名規則相對容易變化且成本較低,域名注冊需要備案,雖然也可以批量注冊但成本相對較高,即域名相對穩定不易變化。
賭博網站的特點之一是善于偽裝[5],為了不容易被識別為賭博網站,有些賭博網站的主頁看起來就像網址大全、新聞門戶的主頁,其中很多鏈接也會指向正常的服務而非賭博項目,還會有動態更新頁面內容的賭博網站,當你瀏覽時間超過一定時間,其主頁內容才會從看似正常的服務一下變更為賭博網站頁面。賭博網站還具有一個特點,他們沒有自己的轉賬服務,所以一定會指向電子銀行的域名,同理,還可能存在郵箱等通訊服務的域名。
因為賭博網站具有上述兩個特點,所以在后續的爬取過程中會獲取一大批白名單網站域名,如www.baidu.com、www.58com、www.163.com 等。導致爬取的域名黑白名單混雜在一起,白名單指的是所有的非賭博網站,但絕大部分是提供搜索、轉賬、播放等正常服務的網站域名。雖然使用傳統的方法可以實時對黑白名單加以更為準確地區分,但是在爬取完成后使用基于PageRank 算法原理改進靜態檢測方法可以實現批量區分。
基于PageRank 算法原理,可以根據域名指向關系獲取重要程度(PR 值)排名,再以特定閾值將白名單與目標網站區分開,一方面為區分目標網站提供新的可能方法,另一方面,為有效擴充白名單提供了輔助方法。
賭博網站還具有集團性的特點,賭博網站也像很多公司一樣有自己的Logo,有的賭博網站是比較小眾的,根系也不發達,它的識別一般成本比較高,因為受眾少也更難發現,而大部分為人知曉的賭博網站則比較龐大,成百上千個子域名都是可能的,可以將一個名稱的或者多個名稱不同但網站模版[6]相同的認為是一個集團,另外,比較大型的賭博集團不同時期的網站模板也不盡相同。
在實驗過程中,沒有對原始域名數據劃分集團,發現存在直接計算PR 值,黑白域名區分度不高的情況。于是利用博彩網站存在的集團性使用社區發現算法再結合PageRank 排序,將兩種規律相結合,提高了分類的準確度,形成基于PageRank 算法原理和聚類方法的靜態檢測方法。
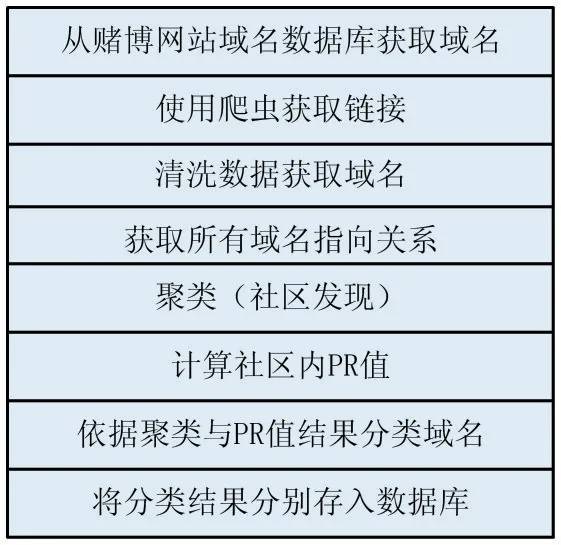
圖1 基于PageRank改進的靜態檢測流程
2.1 PageRank算法原理
PageRank 算法原本是Google 提出的網頁排名算法,其基本思想是根據網頁的出入鏈關系計算網頁在網絡中的重要程度,用PR 值表示,PR 值越高,表示網頁越重要,其排名也會相對靠前,其具體算法如下:
假設存在網站A,B,C,…,Z(N),其中,B,C,D,…網站存在指向A 的鏈接,B,C,D,…網站的總外鏈數為L(B),L(C),L(D),PR 值分別為PR(B),PR(C),PR(D),…,則A 的PR 值計算公式如下:
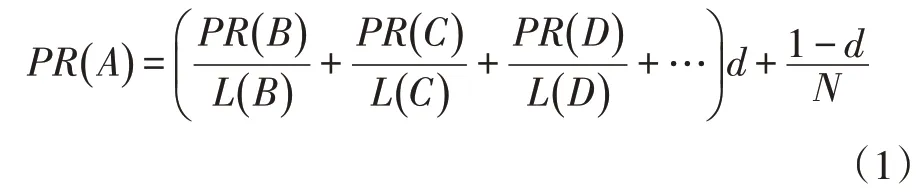
其中,d 表示隨機跳轉概率,表示從某網站不經過鏈接而是地址欄跳轉訪問A 的概率,通常取0.85。
與PageRank 的原始試驗對象有所區別,賭博網站識別實驗中使用的節點并非頁面,而是域名。眾所周知,每個域名可以包含多個頁面。但是,賭博網站域名的指向關系類似于互聯網上的網站鏈接關系,用域名取代網頁作為節點,用域名間的指向取代網頁之間的超鏈接,則可以用PR 值表示某域名在賭博網站指向關系網中的“重要程度”。
在數據爬取和分析階段,已經發現實驗中提供正常服務的白名單網頁的出現次數明顯高于目標域名,猜想如果對域名使用PageRank 算法排序,白名單網站域名與賭博網站域名PR 值也會有明顯的區別,白名單網站域名的“重要程度”也會比賭博網站域名的重要性大。
考慮到實際生活中訪問賭博網站和訪問正常網站時訪問方式的不同,例如,正常訪問百度,絕大部分人應該是在地址欄中直接輸入地址。而網絡賭民輸入的應當是某個主站或者跳轉站或者自己喜歡、認為可以給自己帶來“好彩頭”的域名,然后,接下來所有的訪問幾乎都是在點擊跳轉鏈接,可以認為幾乎完全是通過點擊跳轉實現的,后續將隨機跳轉概率d 調整為0.99與通常的0.85 進行了對比,發現d=0.99 的確效果更好。
2.2 社區發現算法原理
社區發現算法也是一種聚類算法,通過節點之間的連接關系劃分社區,根據社區之間是否有重疊部分可以分為重疊社區和非重疊社區,通常的社區發現算法包括關聯人發現等。
在該實驗中,由于博彩網站具有集團性,可以首先利用爬蟲獲取的新舊域名指向關系劃分社區,社區與集團之間也存在一定的關聯性。可能存在孤立的社團,其集團性質比較單一。也會有節點數量很多的社團,這類社團性質為重疊社區,由于不同集團之間存在業務競爭關系,新鏈接重疊部分大概率為普通公眾業務,如轉賬、郵箱等正常服務。
賭博網站域名大部分為批量注冊,其域名具有相似性。有通過計算URL 文本相對距離進行的賭博網站識別實驗。統一集團某一時間段注冊的域名都具有鮮明的相似性[3],可以利用域名的相似性,直觀地判斷劃分出的小社團是否屬于同一個集團。
實驗中,由于博彩網站社團與常規的網站社團和人際關系社團不同,集團內部大量存在一對一和一對多的鏈接關系,集團之間大量存在多對一的鏈接關系,集團內關系并不復雜,直接使用連通子圖對節點進行聚類也能取得較好的聚類結果。
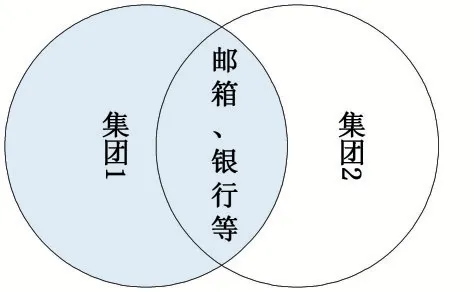
圖2 域名競爭關系
3 實驗結果驗證
利用爬蟲擴大賭博網站域名數據庫時,為批量判定新網站是否是目標網站,將域名作為節點,利用域名的指向關系構成邊,將這樣的連通圖視為一個網絡,利用PageRank 算法計算其中每個節點的PR 值,作為黑白名單劃分的依據。實驗發現只對爬取結果整體計算一次PR 值的效果并不好,整體的PR 值對高頻數據(出現次數多)區分度不大。通過實驗證明利用社區算法可以讓域名的連接情況更加明顯,例如在社區內分別放大節點的PR 值,雖然并不影響域名依據PR 值的排序結果,但是先通過聚類方法劃分大小社區,再對大社區進行PR 值計算,可以大幅提高整體的分類準確率。
3.1 依照PageRank對新鏈接進行聚類的結果
前期經過專家確認的4000 多條高質量博彩網站域名,經過脫敏處理后,形成了原始數據表。
為了后續的處理,利用爬蟲獲取了原始域名指向的新域名,并記錄了相互的指向關系共11000 多條。為了后續能夠對識別結果進行驗證,我們對所有獲得的新域名進行了人工標注,形成了白名單列表用于最終結果驗證。
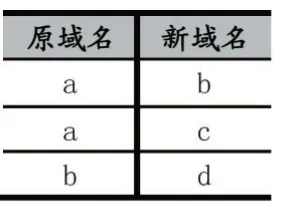
表1 域名指向關系示例
利用表1 的邊關系,使用PageRank 算法,計算節點的PR 值并排序,如表2 所示。
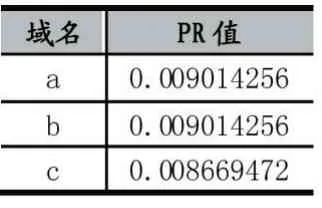
表2 PR 值TOP3 一覽(d 值取0.99)
由于我們的原始數據是質量極高賭博網站,對于不包含公共服務的頁面,應當獲得較小的社團,對于包含公共服務的頁面,會根據多對一的關系聚集成大的社團。根據白名單列表計算每個社團的白名單率并排序,發現一共156 個社團,只有大型社團(此處為上千域名數)才存在白名單,社團越大,白名單率越高。小型社團(此處不足一百域名數)均是純粹的賭博集團。
與PR 值排序相比,其分布并不均勻,但較大部分小型社團分布在PR 值排序后1/2 部分。
但是,對于PR 值排序前1/2 以及大型社團內域名還未能加以區分。嘗試引入社團內PR 值的概念。即對大社團內部的節點篩選出只包含這些節點的邊關系,重新構成域名指向關系網,計算該域名指向關系網內各域名的PR 值,成功擴大第一次計算所得的PR 值。
但是,可能是由于賭博網站的集團性過于明顯,將劃分社區前后的PR 值進行比較,發現PR 值的確被放大了,但是每個域名PR 值排序的先后順序并沒有發生顯著變化,如表3 所示。
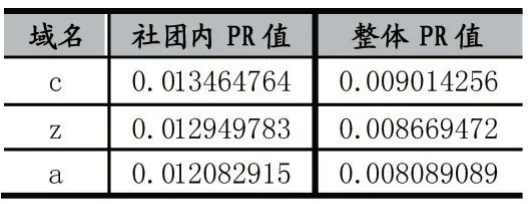
表3 社團內PR 值與整體PR 值對比表
雖然直接選取第一次獲得的整體PR 值排序結果和選取第二次劃分社區后的PR 值排序結果幾乎沒有差別,但是經過比較發現,白名單集中存在于PR 值排名前半部分的規律并沒有發生變化。即對于大社團,重新計算PR 值并加以排序后,后半部分依舊為賭博網站。
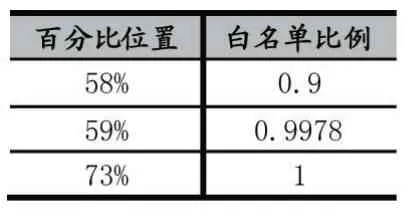
表4 PR 值排序中白名單在不同位置的比例
經過多次計算求平均值,發現98%的白名單都集中在排序后的PR 值列表的前60%,50%的白名單都集中在排序后的PR 值列表的50%-60%之間。
3.2 PageRank控制參數結果比較
d 表示由地址欄直接跳轉到某一界面的概率,通常值為0.85。
由于賭博網站具有一定的隱蔽性導致難以被正常訪問,雖然在日常生活中賭博小廣告無孔不入,但是博彩域名極少具有意義難以記憶,所以應當與正常的網站相區分,訪問方式應當主要利用已有網頁跳轉到新網頁才更符合訪問博彩網站的實際情況,所以隨即跳轉參數d 的值應當適當提高,實驗中用0.99 與通常值0.85 進行對比。
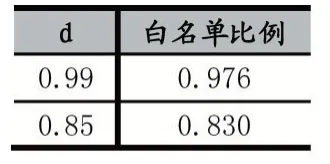
表5 PR 值排序結果中前60%集中白名單比例
實驗發現,d=0.99 時,獲得的PageRank 排行用于分類的效果更好。
4 結語
利用賭博網站的集團性,采用聚類方法將域名依照相互間指向關系劃分為小社團與大社團。根據PageRank 算法原理,利用域名間相互指向關系,計算出域名在賭博網站指向網中的重要性。通過觀察分析,發現白名單網站和賭博網站在PageRank 排名中的分布具有規律性,使得批量分類賭博網站域名與白名單域名具有可行性。
分析賭博網站受眾的特點[7],測試發現當隨機跳轉指數為0.99 時,黑白名單在PR 值排名中的分布性會更為明顯。
在已有賭博網站數據庫條件下,對二層爬蟲所得域名聚類所得小型社團均為純粹的賭博網站。對于大型社團計算PR 值,與整體PR 值排序結果沒有變化,但黑白名單分布規律依舊符合半數規律,即整體白名單域名分布在整體PR 排序列表前半數,社團內白名單域名分布在社團內PR 排序列表前半數。
最后,通過多次試驗,發現通過聚類和計算PR 值相結合的方法,利用黑白名單分布規律,可最終實現單次獲取總數60%以上的賭博網站域名。
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
