基于決策樹(shù)的堆芯物理參數(shù)預(yù)測(cè)研究
2020-02-25 05:48:24周劍東謝金森曾文杰陳珍平趙鵬程劉紫靜
原子能科學(xué)技術(shù) 2020年2期
周劍東,謝金森,*,曾文杰,于 濤,陳珍平,趙鵬程,謝 芹,劉紫靜,謝 超
(1.南華大學(xué) 核科學(xué)技術(shù)學(xué)院,湖南 衡陽(yáng) 421001;2.湖南省數(shù)字化反應(yīng)堆工程技術(shù)研究中心,湖南 衡陽(yáng) 421001)
隨著反應(yīng)堆中子輸運(yùn)和擴(kuò)散方程計(jì)算方法的改進(jìn),以及計(jì)算機(jī)性能的提升,反應(yīng)堆核設(shè)計(jì)方法也在不斷發(fā)展,以達(dá)到更高的設(shè)計(jì)精度要求[1],如直接基于柵元尺度進(jìn)行堆芯一步法輸運(yùn)計(jì)算。然而,在現(xiàn)有的大型計(jì)算機(jī)水平下,由于計(jì)算耗費(fèi)仍較大,目前工程領(lǐng)域核設(shè)計(jì)采用的仍是基于組件均勻化計(jì)算與堆芯擴(kuò)散計(jì)算的兩步法。從計(jì)算時(shí)間的角度看,依據(jù)現(xiàn)有的計(jì)算方法及硬件條件,單個(gè)組件的一次輸運(yùn)計(jì)算所需的時(shí)間已可控制在s到min量級(jí)[2]。但在面對(duì)堆芯優(yōu)化設(shè)計(jì)問(wèn)題時(shí),隨著組件設(shè)計(jì)變量及目標(biāo)函數(shù)數(shù)量的增加,及進(jìn)一步的輸運(yùn)-燃耗計(jì)算等問(wèn)題相互耦合,問(wèn)題的難度也會(huì)呈指數(shù)增長(zhǎng),堆芯方案搜索的規(guī)模將達(dá)到成千上萬(wàn),堆芯優(yōu)化設(shè)計(jì)過(guò)程所需的計(jì)算時(shí)間也會(huì)急速增加。Cadenas等[3]使用CASMO-4/SIMULATE-3評(píng)估單個(gè)設(shè)計(jì)組件是否滿足運(yùn)行要求需要5~6 h;而使用DRAGON-4/DONJON-4[4-5]程序?qū)?個(gè)組件-堆芯方案的計(jì)算時(shí)間約6.53 h;若上述計(jì)算采用蒙特卡羅程序,計(jì)算時(shí)間則更長(zhǎng)。因此,在工程實(shí)際堆芯設(shè)計(jì)中,更多的是憑借設(shè)計(jì)人員的經(jīng)驗(yàn)與物理理論,先預(yù)設(shè)少量方案再進(jìn)行逐個(gè)計(jì)算及人工篩選。
本文提出利用數(shù)據(jù)挖掘技術(shù),通過(guò)組件自變量快速預(yù)測(cè)堆芯的物理參數(shù),實(shí)現(xiàn)方案的快速篩選,提高堆芯設(shè)計(jì)效率。數(shù)據(jù)挖掘技術(shù)首先對(duì)不同算法的訓(xùn)練集訓(xùn)練效果進(jìn)行評(píng)估,挑選合適的數(shù)據(jù)挖掘算法,再基于C4.5模型對(duì)自變量與堆芯參數(shù)做關(guān)聯(lián)分析,最后利用不同算法建立的模型對(duì)測(cè)試集進(jìn)行快速預(yù)測(cè)堆芯參數(shù)并評(píng)價(jià)其精度。
1 數(shù)據(jù)挖掘算法
數(shù)據(jù)挖掘[5]是在海量數(shù)據(jù)中發(fā)現(xiàn)知識(shí)、規(guī)律、新模式、新關(guān)系的過(guò)程,這個(gè)過(guò)程可是全自動(dòng)的,也可是半自動(dòng)的。簡(jiǎn)而言之,數(shù)據(jù)挖掘就是從大量數(shù)據(jù)中提取或“挖掘”知識(shí)[6]。它的基本任務(wù)[7]包括:分類(lèi)與預(yù)測(cè)、聚類(lèi)分析、關(guān)聯(lián)規(guī)則、時(shí)序模式、偏差檢測(cè)、智能推薦等。它的目標(biāo)[7]包括:基于其他屬性的值來(lái)預(yù)測(cè)特定屬性的值、對(duì)數(shù)據(jù)中潛在聯(lián)系的模式進(jìn)行概括與導(dǎo)出。決策樹(shù)是機(jī)器學(xué)習(xí)中的1個(gè)樹(shù)狀預(yù)測(cè)模型,對(duì)訓(xùn)練樣本數(shù)據(jù)集進(jìn)行挖掘后會(huì)產(chǎn)生1棵如二叉樹(shù)或多叉樹(shù)的結(jié)構(gòu),其內(nèi)部節(jié)點(diǎn)表示在1個(gè)屬性上的測(cè)試,而葉子節(jié)點(diǎn)代表最終的類(lèi)別結(jié)果[8]。在解決分類(lèi)問(wèn)題方面,除了決策樹(shù)算法以外還有貝葉斯分類(lèi)(BC)、人工神經(jīng)網(wǎng)絡(luò)算法(ANN)、K近鄰算法(K-NN)、支持向量機(jī)算法(SVM)等[9]可應(yīng)用于該領(lǐng)域。決策樹(shù)算法相較于ANN和SVM在實(shí)現(xiàn)方式上更簡(jiǎn)單,模型更直觀,速度更快;相較于K-NN,決策樹(shù)算法能解決多元分類(lèi)問(wèn)題[9]。
本文使用的算法有C4.5、RepTree、Random Forest、Random Tree。以上4種算法都是基于構(gòu)建決策樹(shù)來(lái)對(duì)數(shù)據(jù)進(jìn)行分類(lèi)分析,各算法處理數(shù)據(jù)的類(lèi)型、建模機(jī)制的選取、決策樹(shù)構(gòu)建方法、分類(lèi)規(guī)則表達(dá)方式[10]等方面的不同導(dǎo)致各有優(yōu)缺點(diǎn),表1列出本文所使用4類(lèi)算法的特點(diǎn)。

表1 算法特點(diǎn)Table 1 Algorithm feature
2 數(shù)據(jù)樣本構(gòu)建
2.1 自變量選取
影響反應(yīng)堆核設(shè)計(jì)參數(shù)的因素主要有燃料富集度、可燃毒物、燃料組件排布等。隨著燃料富集度的提升,初始反應(yīng)性越大,對(duì)于反應(yīng)性的控制越會(huì)帶來(lái)巨大的困難,并且在壽期末會(huì)出現(xiàn)燃耗虧損[11],即當(dāng)燃料富集度大于某個(gè)值時(shí),壽期末燃耗不會(huì)繼續(xù)呈線性增加,而會(huì)小于該結(jié)果;可燃毒物在展平堆芯功率的同時(shí),也可能導(dǎo)致壽期虧損即反應(yīng)性懲罰,其中包括毒物基體中硼與釓等核素及子代同位素的殘留吸收、包殼等結(jié)構(gòu)物的吸收以及毒物棒的擠水效應(yīng)[12]。因此本文選取燃料富集度、可燃毒物的類(lèi)型與含量這3類(lèi)設(shè)計(jì)變量作為自變量。參考現(xiàn)有的壓水堆燃料組件設(shè)計(jì)區(qū)間[13],本文選取了富集度在1.8%~5.0%區(qū)間的5種不同燃料開(kāi)展研究,可燃毒物采用Gd2O3+UO2,Gd2O3的質(zhì)量分?jǐn)?shù)為9%與12%,單一組件內(nèi)含可燃毒物的燃料棒為0、4、8、12根,如表2所列,可組合35種不同的燃料組件。
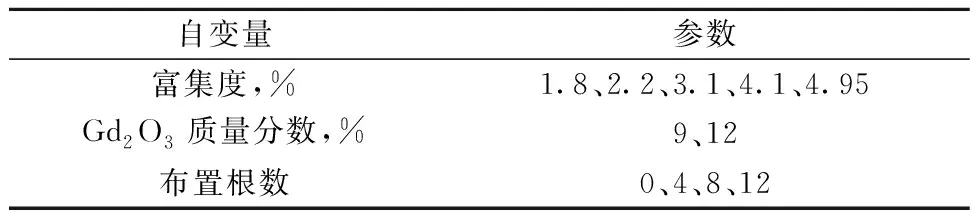
表2 燃料組件自變量Table 2 Independent variable of fuel assembly
本文以國(guó)內(nèi)某核電廠首爐堆芯裝料布置為參考,針對(duì)表2所列燃料組件進(jìn)行計(jì)算。堆芯燃料分3區(qū)布置,分別用A、B、C表示,具體布置如圖1所示。依據(jù)以上自變量,可生成的堆芯方案數(shù)量為353=42 875。為降低樣本量,減少不必要的計(jì)算及節(jié)約時(shí)間成本,根據(jù)該核電廠首爐堆芯方案,約束A區(qū)的燃料富集度最小,C區(qū)燃料富集度最大,B區(qū)燃料富集度介于A、C區(qū)之間,由此可將組件按富集度分為10種不同的情況,而每種富集度的Gd含量及布置有7種。在上述約束下,堆芯方案數(shù)量降至73×10=3 430。
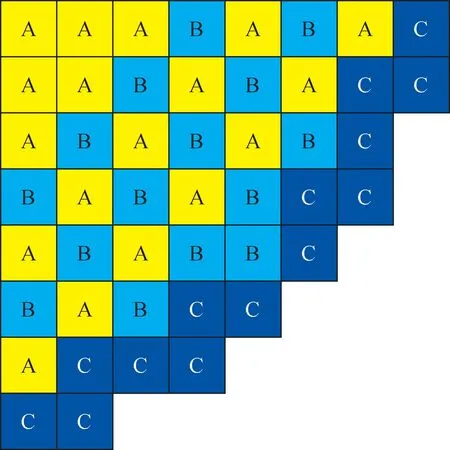
圖1 1/4堆芯布置Fig.1 Quarter core layout
2.2 目標(biāo)函數(shù)選取
通過(guò)DRAGON/DONJON[4-5]程序系統(tǒng)做兩步法組件-堆芯輸運(yùn)燃耗計(jì)算所得參數(shù)作為數(shù)據(jù)挖掘所需的數(shù)據(jù)集。參考核電廠首爐堆芯核設(shè)計(jì)報(bào)告,選取keff在壽期內(nèi)的不均勻系數(shù)偏差(KUCD)、壽期內(nèi)的徑向功率不均勻系數(shù)偏差(RPNCD)、壽期內(nèi)的徑向中子通量不均勻系數(shù)偏差(RFNCD)、堆芯壽期(CL)作為目標(biāo)函數(shù),用于快速評(píng)估燃料組件設(shè)計(jì)方案。其中,KUCD用以表征堆芯在壽期內(nèi)反應(yīng)性波動(dòng)偏離范圍,RPNCD和RFNCD表征堆芯功率與中子通量的不均勻性。假定以上4個(gè)目標(biāo)函數(shù)需滿足以下限制條件:
1) KUCD
(1)
其中:keff,max、keff,av分別為壽期內(nèi)keff的最大值與平均值;下標(biāo)target為設(shè)計(jì)目標(biāo)值。
2) RPNCD
(2)
其中,Pmax、Pav分別為壽期內(nèi)功率密度的最大值與平均值。
3) RFNCD
(3)
其中,φmax、φav分別為壽期內(nèi)中子通量的最大值與平均值。
4) CL
CL≥CLtarget
(4)
其中,CL為以等效滿功率天(EFPD)為單位的堆芯循環(huán)長(zhǎng)度。
以等權(quán)重的方式整合以上4類(lèi)目標(biāo)函數(shù)并用目標(biāo)函數(shù)符合度[14](CPF)來(lái)統(tǒng)一表示,因此CPF的可能取值為0~4。若CPF=4,則代表該堆芯方案滿足所有的核設(shè)計(jì)要求,即可認(rèn)定此類(lèi)燃料組件在堆芯排布方案中是“好的”;若CPF<4則可認(rèn)為方案為“壞的”。
3 結(jié)果分析
3.1 算法分析
將所有案例隨機(jī)分為兩部分,即訓(xùn)練集和測(cè)試集,每組1 715個(gè)案例。通過(guò)C4.5、RepTree、Random Tree及Random Forest算法對(duì)訓(xùn)練集進(jìn)行分類(lèi)回歸分析,并在訓(xùn)練過(guò)程中隨機(jī)挑選該數(shù)據(jù)集中10個(gè)案例做交叉驗(yàn)證[15],并評(píng)估其預(yù)測(cè)精度。
通過(guò)對(duì)訓(xùn)練集構(gòu)建訓(xùn)練模型,C4.5生成葉子節(jié)點(diǎn)數(shù)102個(gè),RepTree生成的葉子節(jié)點(diǎn)數(shù)為133個(gè),Random Forest則生成了100棵決策樹(shù),Random Tree生成的葉子節(jié)點(diǎn)數(shù)為949個(gè)。結(jié)果表明C4.5算法對(duì)整體預(yù)測(cè)精度最高,Random Tree最低,而對(duì)構(gòu)建模型歷時(shí)最短的是Random Tree,耗時(shí)最長(zhǎng)的是Random Forest,將各算法對(duì)CPF各值的預(yù)測(cè)精度的平均值作為該算法的整體精度,其結(jié)果列于表3。基于數(shù)據(jù)挖掘構(gòu)建混淆矩陣(圖2),矩陣每列代表CPF的預(yù)測(cè)值,每行則代表CPF的實(shí)際值,由此可知,對(duì)角線的值越大即算法構(gòu)建模型越精確。由圖2可知,C4.5對(duì)訓(xùn)練集的預(yù)測(cè)精度要優(yōu)于其他算法的。
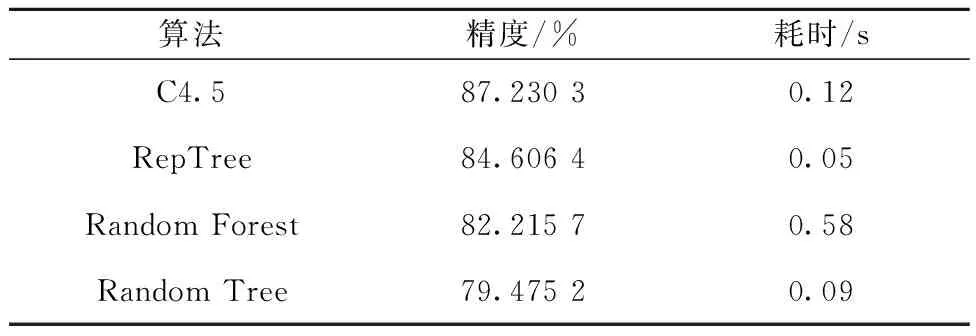
表3 各算法的預(yù)測(cè)精度Table 3 Prediction accuracy of each algorithm
鑒于對(duì)CPF的定義,CPF=4為篩選的臨界點(diǎn),即篩選出所有滿足設(shè)計(jì)要求的堆芯方案,各算法的預(yù)測(cè)精度列于表4。TP Rate為真正率,即被模型預(yù)測(cè)為CPF=4的樣本比率,TP Rate=CPF為4預(yù)測(cè)結(jié)果數(shù)除以CPF實(shí)際為4的結(jié)果數(shù)。同理,F(xiàn)P Rate為假正率,即模型預(yù)測(cè)不為4的樣本比率,F(xiàn)P Rate=被預(yù)測(cè)不為4的樣本數(shù)除以實(shí)際不為4的樣本數(shù)。Precision即精確度,代表著被模型正確預(yù)測(cè)的樣本數(shù)與所有被預(yù)測(cè)為4的樣本數(shù)的比率。由表4可知,Random Forest的預(yù)測(cè)精度最高,其次是C4.5。
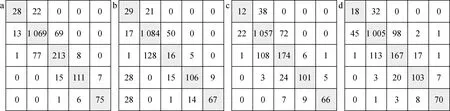
a——C4.5;b——RepTree;c——Random Forest;d——Random Tree圖2 各算法的混淆矩陣Fig.2 Confusion matrix of each algorithm
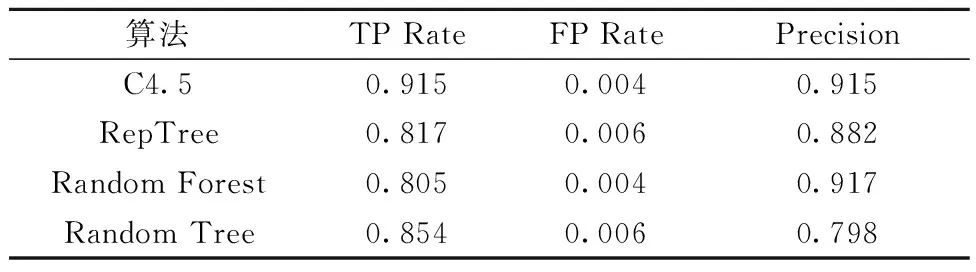
表4 各算法對(duì)CPF=4的預(yù)測(cè)精度Table 4 Prediction accuracy of each algorithm for CPF=4
3.2 關(guān)聯(lián)分析
鑒于3.1節(jié)分析可知,C4.5對(duì)整體CPF的值預(yù)測(cè)精度最高,因此,本節(jié)采用C4.5算法對(duì)各個(gè)自變量做關(guān)聯(lián)分析。通過(guò)對(duì)數(shù)據(jù)進(jìn)行格式轉(zhuǎn)換、數(shù)據(jù)清洗等預(yù)處理操作,調(diào)整自變量即選取不同的特征量以得出CPF的預(yù)測(cè)精度來(lái)關(guān)聯(lián)分析,具體精度列于表5。
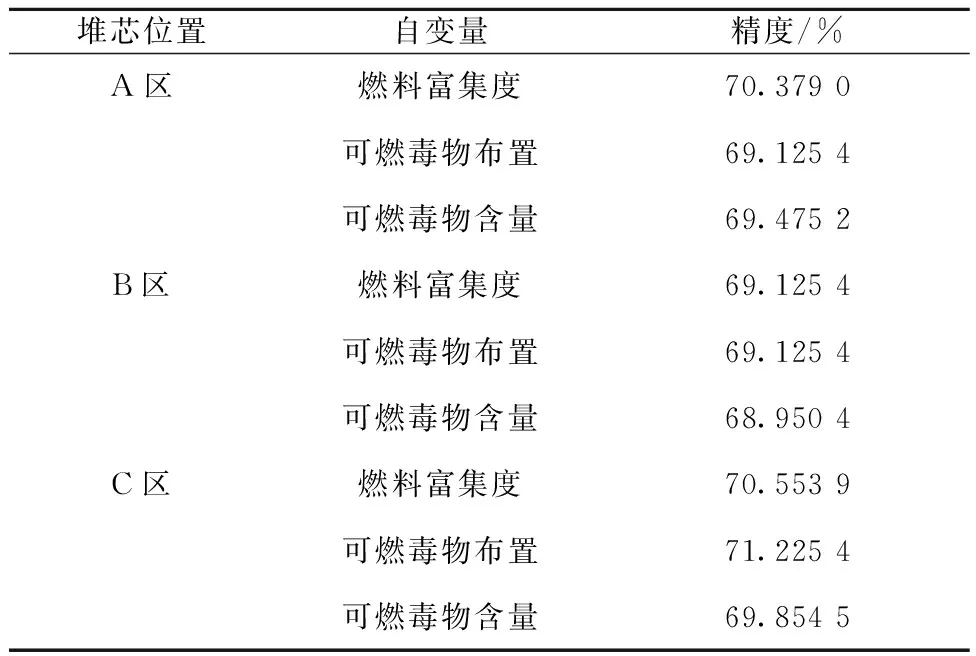
表5 各自變量對(duì)CPF預(yù)測(cè)精度Table 5 Accuracy of CPF prediction for each independent variable
由表5可知,對(duì)于A區(qū),燃料富集度對(duì)CPF的值影響最大,可燃毒物布置對(duì)CPF值的影響較小,又因在設(shè)計(jì)時(shí)A區(qū)燃料富集度相較于B區(qū)、C區(qū)燃料的會(huì)更低,相較于可燃毒物布置及含量,A區(qū)燃料富集度對(duì)堆芯通量、功率的影響更大。以此類(lèi)推,B區(qū)由于富集度的增加,該區(qū)組件對(duì)堆芯的整體影響則來(lái)源于該區(qū)組件燃料富集度以及可燃毒物的布置方式。隨著富集度的繼續(xù)增加,C區(qū)組件可燃毒物布置對(duì)堆芯的CPF值的影響相較于其余兩個(gè)自變量更大,富集度越高,就越依賴于可燃毒物的布置來(lái)展平堆芯的通量及功率分布。整體上,C區(qū)燃料組件的重要性要高于A區(qū)和B區(qū)的,即C區(qū)對(duì)于堆芯整體的不均勻性貢獻(xiàn)更大。
3.3 預(yù)測(cè)分析
提取測(cè)試集中的1 715個(gè)案例,將這1 715個(gè)案例放入4種算法基于訓(xùn)練集生成的模型進(jìn)行快速計(jì)算并比較。CPF=4時(shí)預(yù)測(cè)案例數(shù)與預(yù)測(cè)案例數(shù)中實(shí)際案例數(shù)比較列于表6,表7列出CPF=4的預(yù)測(cè)完備性。由表6與表7可知,4個(gè)算法在對(duì)測(cè)試集1 715個(gè)案例的篩選與預(yù)測(cè)均在0.9 s以內(nèi)完成;并在1 715個(gè)案例中,實(shí)際CPF=4的總案例數(shù)為51個(gè),基于C4.5與Random Forest算法的預(yù)測(cè)完備性最高,均達(dá)到了0.98,但在這兩個(gè)算法中,Random Forest預(yù)測(cè)精度高于C4.5,而Random Forest所需時(shí)間大于C4.5。
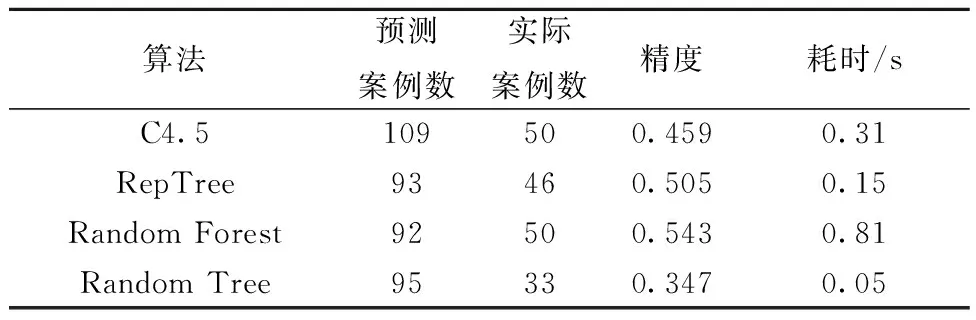
表6 預(yù)測(cè)案例數(shù)與預(yù)測(cè)案例數(shù)中實(shí)際案例數(shù)比較Table 6 Number of actual case in number of predicted case and number of predicted case

表7 預(yù)測(cè)完備性Table 7 Predictive completeness
4 結(jié)語(yǔ)
堆芯燃料組件排布方案與燃料組件的選擇是反應(yīng)堆核設(shè)計(jì)的重要內(nèi)容,在一定的堆芯排布方案約束假設(shè)下,針對(duì)大量可能的燃料組件設(shè)計(jì)進(jìn)行篩選是一項(xiàng)復(fù)雜、耗時(shí)的工作。利用大量已有的堆芯設(shè)計(jì)方案數(shù)據(jù),通過(guò)數(shù)據(jù)挖掘技術(shù),可實(shí)現(xiàn)對(duì)新燃料組件在堆芯的物理性能及對(duì)堆芯核設(shè)計(jì)參數(shù)影響的快速評(píng)價(jià),這對(duì)于堆芯、燃料組件方案搜索與優(yōu)化具有很強(qiáng)的實(shí)際意義。
本文以某核電廠首爐堆芯方案為參考,以燃料富集度、可燃毒物布置、可燃毒物含量3個(gè)為自變量,應(yīng)用C4.5、RepTree、Random Forest及Random Tree算法,運(yùn)用數(shù)據(jù)挖掘技術(shù)構(gòu)建的模型對(duì)測(cè)試集燃料組件方案進(jìn)行快速預(yù)測(cè),所需時(shí)間均在0.9 s以內(nèi),且C4.5對(duì)訓(xùn)練集的預(yù)測(cè)精度最高。隨后C4.5對(duì)自變量與目標(biāo)函數(shù)進(jìn)行關(guān)聯(lián)分析,得出A區(qū)的燃料富集度與C區(qū)的燃料富集度和可燃毒物布置相較于其他自變量對(duì)結(jié)果影響更大。Random Forest與C4.5對(duì)滿足堆芯要求的預(yù)測(cè)完備性較高,而Random Forest的預(yù)測(cè)精度最高。盡管Random Forest預(yù)測(cè)時(shí)間相較于其他3種算法較長(zhǎng),但是該算法的預(yù)測(cè)所耗時(shí)間可接受。以上工作對(duì)反應(yīng)堆堆芯參數(shù)的快速計(jì)算提供新的可能,可大幅提升方案搜索的效率。同時(shí),數(shù)據(jù)挖掘的技術(shù)可充分利用現(xiàn)有反應(yīng)堆核設(shè)計(jì)的數(shù)據(jù)資源,實(shí)現(xiàn)核能領(lǐng)域大數(shù)據(jù)的應(yīng)用。
猜你喜歡
少先隊(duì)活動(dòng)(2021年2期)2021-03-29 05:40:48
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2019年6期)2019-06-24 03:37:50
藝術(shù)啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
中國(guó)公路(2017年7期)2017-07-24 13:56:38
Coco薇(2017年5期)2017-06-05 08:53:16
電力與能源(2017年6期)2017-05-14 06:19:37
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
中國(guó)衛(wèi)生(2015年4期)2015-11-08 11:16:06
