基于粗糙集-模糊C均值聚類的Elman神經網絡農村需水量預測
2020-02-24 07:36:28吳佳懋
科學技術與工程 2020年1期
關鍵詞:影響
李 偉, 李 艷, 吳佳懋
(海南大學土木建筑工程學院, 海口 570100)
精準的用水量預測是城鄉供水一體化體系中一項重要的基礎工作[1]。目前,中國推進從需求側作為出發點研究水資源調配,需水量預測便成為學者研究重點。準確預測下一時間節點用戶用水量不但對水力系統規劃和提高經濟效益有積極作用,也是中國水資源需求側管理需要實現的重要目標。農村用水量由于其影響因子眾多且影響程度不均,預測方法及改進手段的選擇直接決定了預測的精準程度。
農村用水量預測的方法很多。趙偉國[2]按四平農村地區分析計算未來需水量,然后分析其未來水的供求態勢;朱連勇等[3]建立了阿拉爾墾區需水量預測模型,在選取農業用水灌溉定額、工業用水重復利用率、城鎮生活人均日需水量、農村生活人均日需水量作為模型輸入,農業、工業、城鎮生活、農村生活需水量作為輸出的基礎上利用 RBF 神經網絡,將2001—2007年用水量數據作為訓練樣本,用2008—2009年用水量數據對模型進行檢驗,結果表明 RBF 神經網絡模型用于該區需水量預測是可行的;李小建等[4]通過問卷調查獲得第一手資料,根據生活用水量、畜禽飼養用水量、企業用水量、管網漏失和未預見水量4項指標建立農村用水量預測綜合模型,并在軟件ARCGIS 9.0中實現此模型,分析了鎮平縣農村需水量和缺水嚴重程度的空間差異及其原因。這些方法在一定程度上提升了農村用水量預測的精度,但在提取關鍵影響因素時,直接對備選因子進行取舍或者直接將因子綜合出新的因子,忽略了影響因子單一影響和組合影響對于預測的重要性。
現以農村各個村落為研究對象,對農村各村進行用水量預測,為城鄉供水管網規模確定、城鄉水資源調度、和農村管網漏損的自動監測提供數據支撐。系統的介紹粗糙集-模糊C均值聚類Elman神經網絡算法模型,且采用粗糙集-模糊C聚類 Elman神經網絡模型對保亭縣保城鎮周邊農村各村年用水量進行預測,最后進行誤差計算并與 Elman神經網絡預測結果對比驗證預測模型的有效性。
1 模糊C均值聚類
模糊C均值(FCM)是一種軟聚類方法,允許一條數據屬于兩個或多個聚類,主要是用隸屬度去將數據點分類,隸屬度越大代表數據點和聚類中心的距離越近。FCM基于以下目標函數的最小化:
(1)
式(1)中:m是大于1的實數;uij是在聚類J中的xi的隸屬度;xi是D維測量數據的第i個數據;Cj是D維的聚類中心;dij=|xi-cj|是第i個聚類中心與第j個數據點之間的歐幾里得距離。
模糊劃分是對上述目標函數的迭代優化進行的,通過式(2)更新成員關系uij和集群中心cj:
(2)
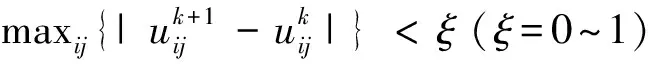
Step1 用值在[0,1]的隨機數初始化隸屬度矩陣U。
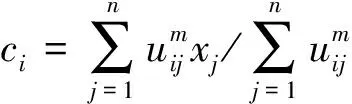
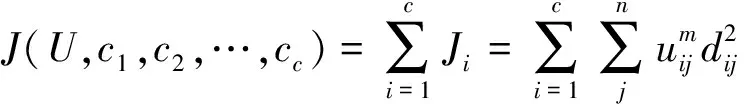
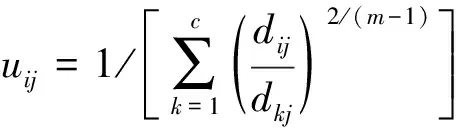
2 Elman神經網絡和粗糙集理論
人工神經網絡 (artificial neural network, ANN) 是一種模擬人腦神經系統信息處理機制的網絡系統,是由現代神經生物學研究的基礎上發展起來的。既具有處理數據的一般計算能力,又具有處理知識的邏輯思維、學習和記憶能力。Elman神經網絡是一種遞歸神經網絡,因其在隱藏層中增加了承接層作為延時算子而使系統具有了適應時變特性。
因為Elman神經網絡的無限逼近作用,其在預測分析中被廣泛應用,然而在數據量巨大和影響因子眾多的情況下,模型的泛化能力會被降低,并且Elman神經網絡在峰值點的預測結果偏差較大,因此引入粗糙集理論對Elman神經網絡模型進行修正。
粗糙集理論是繼概率論、模糊集、證據理論之后的又一個處理不確定性的數學工具,是當前國際上人工智能理論及其應用領域中的研究熱點之一。粗糙集的特點是:①能處理各類數據,包括缺失的數據以及帶有很多變量的數據;②能處理數據的不精確性和模棱兩可,包括確定性和非確定性的情況;③能求得知識的最小表達和知識的各種不同層次;④能從數據中剝離出概念簡單,易于操作的模式;⑤能產生精確而又易于檢查和證實的規則。
粗糙集理論的核心思想就是對數據進行有效的分類并提取出對決策有關的“有用”數據。具體實現過程如下:
以Elman神經網絡模型輸出的預測值為基礎,根據式(3)~式(5)提取條件屬性集C={a,b,c},根據專家經驗確定決策屬性集D=g0gggggg,從而構成完整的信息系統。然后分別對屬性集C和D進行等頻劃分離散化處理得到決策表,采用粗糙集屬性約簡算法對決策表進行處理即可得到最小決策規則,從而確定尺度因子S,實現粗糙集對Elman神經網絡模型的修正。
(3)
b=sgn(kt+1-kt)
(4)
(5)
式中:kt+1、kt分別表示預測函數在t+1時刻兩側的斜率;Yt為t時間單位內預測值;Y″t為t時間單位內實際值;M為數據點總數。
3 粗糙集-模糊C均值聚類Elman神經網絡
將模糊C聚類理論和Elman神經網絡結合,考慮農村用水量數據影響因子眾多和影響程度不均的特性,首先按隸屬度將數據點進行模糊C均值聚類,并用主成因分析法綜合出若干影響因子,把綜合出的影響因子并入原有影響因子構成影響因子組,再分別與每類村落用水量數據進行相關性分析提取關鍵因素,最后分別將每類村落預處理的用水數據和關鍵影響因素作為 Elman 神經網絡的輸入進行訓練并預測,最后為了克服 Elman 神經網絡在逼近非線性函數時,兩側斜率過大的峰值點預測誤差較大,引入粗糙集進行修正,提高預測精度。
如圖1所示,粗糙集-模糊C均值聚類Elman神經網絡預測詳細步驟如下:
(1)數據預處理。
(2)提取模糊C均值聚類的特征向量。
(3)設置參數并進行模糊C均值聚類。
(4)主成因分析綜合出新的成分并與原始影響因子構成影響因子組。
(5)分別與每類數據進行 Pearson 相關性分析提取每類關鍵影響因素。
(6)數據歸一化,將每類數據與其關鍵影響因素調整到0~1,這一步驟可確保 Elman 神經網絡順利進行。
(7)Elman 神經網絡預測,將歸一化的數據作為輸入,設置訓練目標最小誤差、訓練次數、現實頻率和學習速率,在輸出結果后可調整神經元個數以達到最優效果。
(8)預測結果反歸一化并輸出。
(9)將輸出的預測值來構建條件屬性集,根據專家經驗選出的尺度因子構建決策屬性集,通過等頻劃分的離散方法對集合進行離散化處理形成決策表,通過最小決策規則確定尺度因子,進行預測值修正。
4 案例分析
4.1 數據收集
選取海南省保亭黎族苗族自治縣保亭縣周邊16個村落2010—2017年共8年用水數據進行預測。
4.2 模糊C均值聚類
圖2所示為2010—2017 年村落年用水總量,可以看出每個村落的用水量趨勢變化,并且村落與村落之間的規模差異較大。若將 16 個村落一起進行預測,必定會降低模型的泛化能力。因此,在進行預測之前首先要對村落進行分類。

圖1 算法流程圖Fig.1 The algorithm flow chart
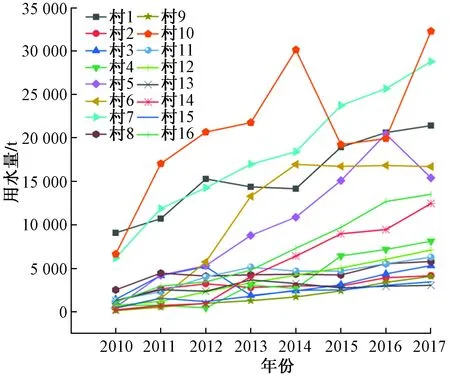
圖2 村落年用水量匯總Fig.2 Summary of annual water consumption in villages
基于村落年用水量特性,提取村落年用水均量、村落年用水均方差和村中有效均戶數作為聚類特征向量。村落年用水均量是可以體現出村落規模,反映數據集中趨勢和一般情況的指標。年用水量的波動情況很大程度上影響了用水總量,村落年用水均方差反映了數據集的離散程度即波動的程度。村中有效均戶數,即每個村平均每年真正使用水的用戶數量。
表1為聚類特征的向量表,將聚類特征向量表作為模糊C均值聚類的輸入。

表1 聚類特征向量Table 1 Cluster feature vectors
根據表2所示設置參數,最后得出模糊C均值聚類的聚類數據圖如圖3所示。按照設定,將數據分為三類,中心黑色的點為聚類中心。

表2 聚類參數設置Table 2 Cluster parameter setting
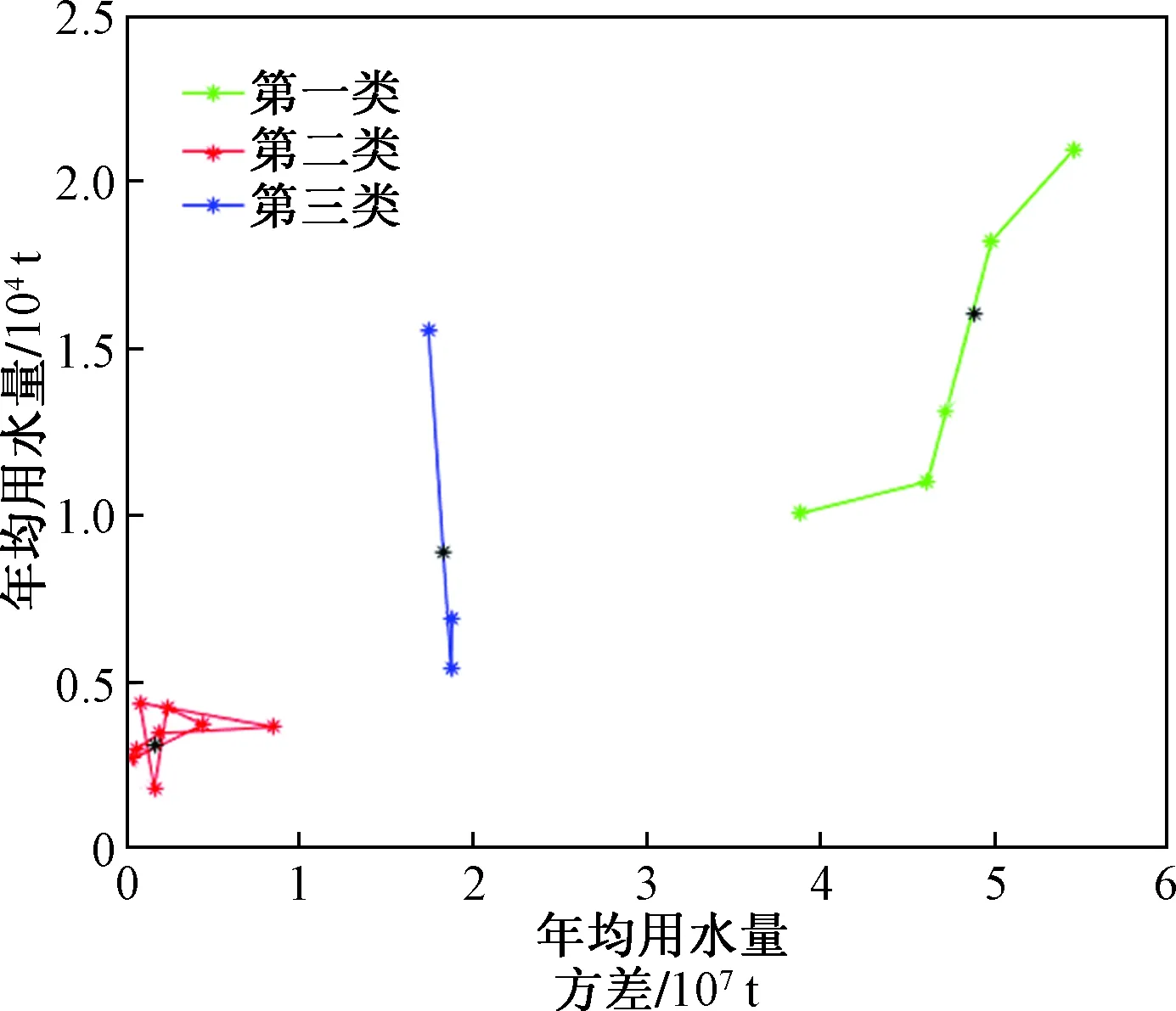
圖3 數據聚類圖Fig.3 Data clustering diagram
根據模糊C均值聚類分類得出聚類結果如圖4所示。第一類有5個村落,分別為村1、村5、村6、村7、村10;第二類有三個村落,分別為村4、村14、村16;第三類有8個村落,分別是村2、村3、村8、村9、村11、村12、村13、村15。

圖4 村落聚類結果Fig.4 The results village clustering
圖4和圖5分別從二維和三維圖上展現了模糊C均值聚類的分類結果。圖4(a)所示為第一類村落,特點為用水量跨度大,波動較大;圖4(b)所示為第二類村落,其增長速度稍放緩,但用水量跨度仍在[0,14 000];圖4(c)所示為第三類村落,增長趨勢最平緩。由圖5可知,從左邊的第一類到右邊的第三類,隨著時間的增長,增長幅度趨近平緩,波動減小。
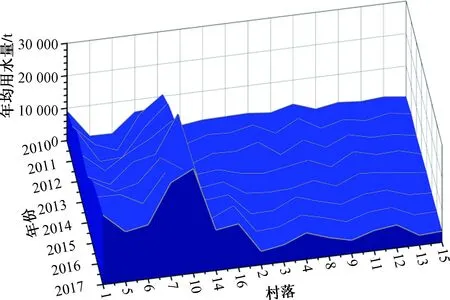
圖5 分類結果三維對比Fig.5 Classification of three-dimensional comparison
4.3 關鍵影響因素提取
4.3.1 數據分析提取影響因素
經過數據分析、相關文獻[5-14]分析以及官方數據分析提取農村用水量影響因素如表3所示。

表3 影響因素匯總Table 3 Summary of influencing factors
4.3.2 影響因子降維處理
農村用水量是多影響因素的復雜系統,在用水量預測研究中,多影響因子作為變量是普遍存在的,在經過影響因子的提取后得到了大量可能影響農村用水量的影響因子。但是,影響因子過多,無疑會增加預測的難度和復雜性。為了克服直接進行相關性分析對影響因子的篩選造成忽略其余影響因子對村年用水量的影響,采用主成因分析法綜合出若干影響因子,所得出的影響因子和原有的影響因子作為最終的影響因子組。主成因分析法具有可消除評價指標之間的相關影響、可減少指標選擇的工作量的優點。除此之外,主成因分析法反映了該主成分包含原始數據的信息量占全部信息量的比重,克服了某些評價方法中認為確定權數的缺陷。
應用 IBM SPSS 軟件實現對新影響因素的提取,主成因分析結果提取兩個成分如下:
(6)
式(6)中:yt(t=1,2)為提取的成分,具體值由成分系數表確定;ai(i=1,2,…,10)為主成分方差貢獻率,ai越大表示主成分反映綜合信息的能力越好,可以根據其大小來提取主成分,xi為原有的10個影響因子。
將影響因子組的12個影響因子分別與三類村年用水數據中的擬合線進行Pearson相關性分析,相關性系數如表4所示。
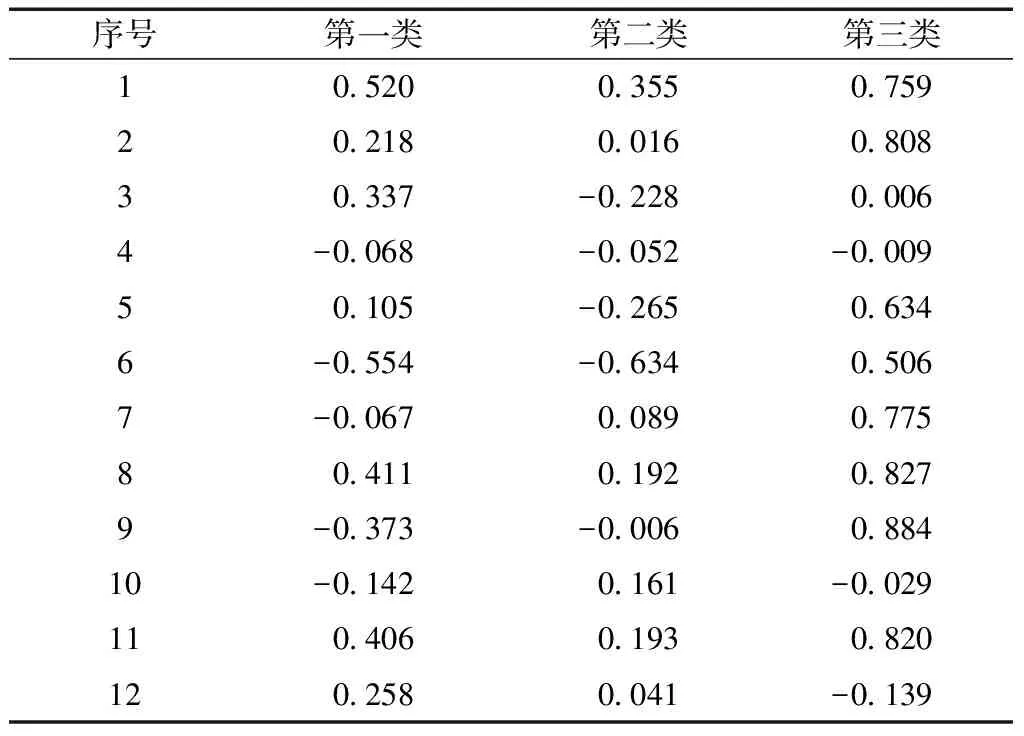
表4 相關性矩陣表Table 4 Correlation matrix
綜上分析,根據相關系數逆序排列,選取每類前4個為提取的關鍵影響因子,如表5所示。

表5 關鍵因素提取Table 5 Extraction of key factors
4.4 Elman神經網絡
將提取的關鍵影響因素與該類村2010—2016年用水量數據作為輸入,算法訓練采用前兩年訓練,隨后一年的數據作為訓練檢驗,以此類推,最后采用2015 年和 2016 年的數據作為預測基礎,對 2017 年村用水量進行預測。預測前將 Elman 神經網絡參數設定如表6所示。

表6 算法的參數設置Table 6 Parameter setting of the algorithm
在預測中,隱含層神經元對結果的影響也很大。根據經驗,神經元個數的選擇應遵循經驗公式n=2t+1進行選擇,其中t為Elman神經網絡輸入的維度,經調試后依最好的結果最終選定隱含層的神經元個數為80。
4.5 粗糙集修正
神經網絡具有無限逼近的能力,在逼近非線性函數時,兩側斜率過大的峰值點預測誤差較大。村與村之間年用水量差異性大,易產生波動,Elman 神經網絡進行預測時峰值點會呈現不同程度的預測偏差,引入粗糙集對預測出的用水量序列進行修正,提高預測精度。
根據表7所示的條件屬性和表8所示的決策屬性,采用最小決策規則確定尺度因子,對預測值進行修正。

表7 條件屬性Table 7 Conditional attributes

表8 決策屬性Table 8 Decision attributes
4.6 仿真結果對比
使用MATLAB軟件實現粗糙集-模糊C均值聚類Elman神經網絡預測模型并與Elman神經網絡模型的預測結果進行對比分析。經粗糙集-模糊C均值聚類Elman神經網絡預測,每類村莊的用水量分別得出的預測結果如圖6所示。

圖6 粗糙集-模糊C均值聚類Elman神經網絡預測結果及誤差Fig.6 Prediction results and errors of Elman neural network based on rough fet-fuzzy C-means clustering

圖7 算法預測結果對比Fig.7 Comparison in prediction results of the algorithms
圖6和圖7為Elman神經網絡、粗糙集-模糊C均值聚類Elman神經網絡預測相同16個點即16個村莊年用水量預測。由圖7可以看出Elman神經網絡、粗糙集-模糊C均值聚類Elman神經網絡兩個模型的預測趨勢大體是一致的,但突然增大或減小時,Elman神經網絡預測結果的變化幅度較小;從圖7的誤差分析可以看出,經粗糙集-模糊C均值聚類改進效果明顯,誤差范圍從[0,0.6]縮小到[0,0.3]。
4.7 誤差分析
為更加準確地量化比較兩個模型的有效性,引入3個國際上使用較多的誤差指標: 平均絕對百分比誤差(MAPE)、預測值與實際值之間的差值的絕對值的平均值(MAE)和 SMAP (MAPE的一個延伸指標)作為誤差評價指標,其計算方式為
(7)
(8)
(9)
式中:Yt為觀測值;Y′t為預測值;N為數據個數。計算結果如表9所示。

表9 誤差對比分析Table 9 Comparative analysis of errors
經過誤差計算,Elman 神經網絡的MAPE為0.270,而粗糙集-模糊C均值聚類只有0.127,SMAP也從0.082降到了0.041,預測精度提高了一倍。絕對誤差指標也從3 832.32減少到1 325.53,3個指標也同時驗證粗糙集-模糊C聚類Elman 神經網絡比單一Elman神經網絡預測精度更高,優化模型有效。
5 結論
(1)將粗糙集理論和均值聚類理論與Elman神經網絡算法結合進行預測分析。預測結果與單一Elman神經網絡模型進行對比,驗證了該模型在農村需水量預測中的優越性和有效性。
(2)影響農村用水量的因素眾多且各影響因素之間會相互影響,在此無法完整羅列所有影響因素,下一步工作應對需水量的混沌特性進行研究,應用混沌時間序列來消除影響因素考慮的不完備性對需水量的影響。
猜你喜歡
中學生數理化·八年級物理人教版(2022年3期)2022-03-16 05:55:08
當代陜西(2021年2期)2021-03-29 07:41:24
家庭影院技術(2020年10期)2020-12-14 07:54:18
媽媽寶寶(2017年3期)2017-02-21 01:22:28
中國塑料(2016年3期)2016-06-15 20:30:00
通信電源技術(2016年3期)2016-03-26 07:13:38
知識經濟·中國直銷(2016年3期)2016-02-27 16:15:49
現代檢驗醫學雜志(2014年6期)2014-02-02 03:02:04
閱讀與作文(小學低年級版)(2011年3期)2011-01-01 00:00:00
