跨境電商系統用戶數據庫智能訪問方法優化
2020-02-24 07:36:02劉彩霞
科學技術與工程 2020年1期
劉彩霞
(鄭州工業應用技術學院信息工程學院,鄭州 451150)
近年來,計算機科學逐漸發展,在社會需求的推動下,跨境電商在中國發展迅速,跨境電商為通過電子設備與網絡進行的商業模式,在電子商務高速發展的今天,其涵蓋范圍非常廣泛,是一種很好的發展方向[1-2]。現階段,跨境電商系統中的用戶量逐漸增多,跨境電商系統需從數據庫中對數據進行提取,然后把讀取的數據在網頁中顯示[3]。需研究一種有效的數據庫智能訪問方法,從海量跨境電商數據中獲取有效信息特征,利用關鍵詞查詢與語義索引完成數據庫智能訪問優化,對增強數據庫集成有重要價值[4-5]。
當前常用的數據庫智能訪問方法包括基于統計信息分析方法、基于信息流減法聚類的數據庫訪問方法和基于關鍵詞的有向圖模型建立的數據庫訪問方法[6]。基于統計信息分析方法通過信息子空間建模與數據關聯屬性采集,依據查詢接口完成數據庫優化訪問,然而計算量大,在數據庫訪問中受關鍵詞影響大,訪問時查準性較差;基于信息流減法聚類的數據庫訪問方法通過聚類法完成對數據庫中重要信息的聚類,依據語義調控目標函數實現數據庫調度,增強訪問性能,然而該方法在進行特征聚類時在很大程度上會陷入局部最優,造成數據庫訪問時收斂性能差。基于關鍵詞的有向圖模型建立的數據庫訪問方法,受到數據庫知識存儲單元耦合性的影響,數據庫訪問準確性低。
針對以上問題,通過語義關聯指向性特征提取進行跨境電商系統用戶數據庫訪問,為了解決其不適于大規模用戶訪問,結合多維索引樹編碼對其進行優化。
1 跨境電商系統用戶數據庫智能訪問方法
1.1 跨境電商系統數據庫模型
為了提高跨境電商系統用戶數據庫訪問能力,對跨境電商數據庫模型進行建立。跨境電商數據信息管理實體模型主要包括三個定量域[7],依次為客戶端定量域V、V中控制定量域U,記模糊搜索集合為S(U),定量值u在定性概念S中隨機實現時,u對S的信息分類聚類特度為穩定隨機數,則u在定量域V中的分布稱作模糊搜尋集合S(U)。不同模糊搜尋集合被稱作有限數據集,以此建立跨境電商系統數據庫模型[8]。
假設V是神經網絡信任數據的拓撲定量域,S是V中的定性概念,在定量值u為定性概念的依次隨機實現時,所有特征點u針對S的確定度ε(u)∈[0,1]均為穩定隨機數。
按照隨機線性映射完成數據格式轉換,獲取各跨境電商隨機數序列分量,即
uk+1=4uk(1-uk)
(1)
式(1)中,k代表跨境電商數據庫訪問任務數量。
利用上述過程獲取跨境電商數據庫模型,為數據庫智能訪問提供模型依據。
1.2 數據庫智能訪問方法
1.2.1 語義指向性關聯特征提取
依據模糊層次聚類提取語義指向性關聯特征[9],在概念格中完成語義指向性相似度計算。假設跨境電商數據庫語義指向性關聯映射微分形式可描述為
(2)
(3)
式(3)中,a表示邏輯推理函數,在對語義指向性關聯特征進行提取時,利用上下文本映射的方式完成約簡[10],獲取本體I和I′間的類間離散度泛函數關系式,即
a=F(a,t)
(4)
完成語義指向性關聯特征提取,獲取特征定位自變量:
t=[t1,t2,…,tn]
(5)
獲取跨境電商系統數據庫語義指向性關聯特征,依據提取特征實現數據庫智能訪問。
1.2.2 數據庫智能訪問
完成語義關聯指向性特征提取后,實現跨境電商系統用戶數據庫訪問。假設訪問過程中數據信息流用Q(t)進行描述,利用語義關聯指向性特征對跨境電商系統中多源節點進行建立,在大規模數據存儲空間中產生新映射[11]。在數據庫中,數據存儲節點空間軌跡矢量場用Q進行描述,通過特征值與特征向量匹配獲取融合代價ci(t),假設數據庫訪問干擾項用bsi(t)進行描述,通過異步迭代法獲取初始化訪問融合中心離散度,則有:
Qi(t)=Q(t)ci(t)+bsi(t)
(6)
式(6)中,ci(t)用于描述規模為Q(t)數據庫在跨境電商系統數據庫語義本體加速分布融合函數,也就是數據庫訪問語義詞頻信息的響應函數[12]。為了增強訪問準確性,需完成對冗余信息流的特征壓縮,獲取特征壓縮控制函數:
Hi(t)=H(t)c′i(t)+bsi(t)
(7)
式(7)中,c′i(t)用于描述規模為H(t)數據庫訪問過程中多普勒頻移估計[13],通過語義關聯指向性特征遍歷跨境電商系統存儲節點,通過自相關解卷積法獲取數據庫訪問模糊隸屬函數:
l′i(t)=Hi(t)Qi(t)c′qi(t)ci(t)+bqi(t)
(8)
式(8)中:c′qi(t)用于描述逆向文檔搜索傳遞函數;bqi(t)用于描述聯合概率分布。通過上述過程產生語義相似度關系弧可描述為
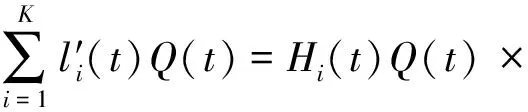
(9)
經處理,獲取訪問控制序列。將輸入關聯指向性特征聚集在一起,將其當成索引變量完成詞頻分類處理,訪問數據的近鄰點,輸入查詢關鍵詞[14],執行輸入的語義序列,獲取的訪問輸出結果Z可描述為
Z=l(t)(keyword,g1)+l(t)(search,g2)
(10)
式(10)中:g1用于描述跨境電商系統數據庫訪問樣本測試集;g2用于描述訪問詞頻信息訓練集。通過分析,可完成跨境電商系統用戶數據庫智能訪問,但在用戶規模較大的情況下,會影響訪問準確性,針對該問題,采用多維索引樹編碼的方式對其進行優化[15]。
1.3 數據庫智能訪問方法優化
在上述數據庫模型與語義指向性關聯特征提取的基礎上,對數據庫智能訪問方法進行優化。利用多普勒效應在跨境電商數據庫節點競爭窗口值進行滑動評估,通過數據庫模型分析數據結構,完成語義指向性檢索。數據庫節點多維索引樹編碼信息輸入可描述為
(11)
完成對跨境電商系統數據庫特征空間的全局效率尋優,在已知變量初始值的狀態下,設計最小競爭滑動窗口特征向量,在系統節點中完成數據融合[16]。本節建立數據庫索引控制特征函數,確定語義指向性信息流預測收斂需符合的條件為
J′[a(tk+1)]-J′[a(tk)]≤
(12)
式(12)中,Di()用于描述數據庫索引控制特征函數。
在進行特征分區的過程中,利用數據庫語義指向性特征匹配,完成數據庫訪問的信息采樣。則通過自回歸調控模型獲取的數據庫存儲節點模型可描述為
(13)
式(13)中:hi(t)與pi(t)依次用于描述第i個節點訪問數據庫時的時域長度與控制長度;αi與γi用于描述緩沖區的數據調度速率;oi用于描述數據庫訪問響應速率;βi()用于描述第i個存儲斷開的調控函數;τ用于描述時延。
在上述分析的基礎上,通過多維索引樹編碼獲取用戶訪問數據庫時關鍵數據回波相位誤差E0的解析表達式:
(14)
式(14)中,μi與θi依次用于描述待查詢關鍵數據的主動頻譜與被動頻譜。利用自適應匹配,獲取關鍵數據的高階累積量重構對角矩陣:
Φ4c=diag[φ4c1,φ4c2,…,φ4cn]
(15)
依據對角矩陣完成用戶訪問結果匹配,達到智能訪問的目的,實現對跨境電商系統用戶數據庫智能訪問方法的優化。
2 實驗和結果分析
為了驗證本文方法在實現跨境電商系統用戶數據庫訪問中的性能,需要進行仿真實驗分析。仿真實驗環境是Windows 7與SQL Sever 2005,通過Java語言與SQL語言對數據庫智能訪問方法進行編寫。針對跨境電商系統用戶訪問信息進行統計,完成數據庫智能訪問資源索引與調度。
2.1 特征提取性能測試
特征提取為跨境電商系統用戶數據庫智能訪問的關鍵,本節采集數據的時域波形與時頻,將文獻[4]方法和文獻[5]方法作為對比,對特征提取性能進行測試。
首先對跨境電商系統數據結構特征信息進行采樣,采樣時間長度是1 200,時間間隔是12 s,獲取的數據庫訪問時間序列波形用圖1進行描述。
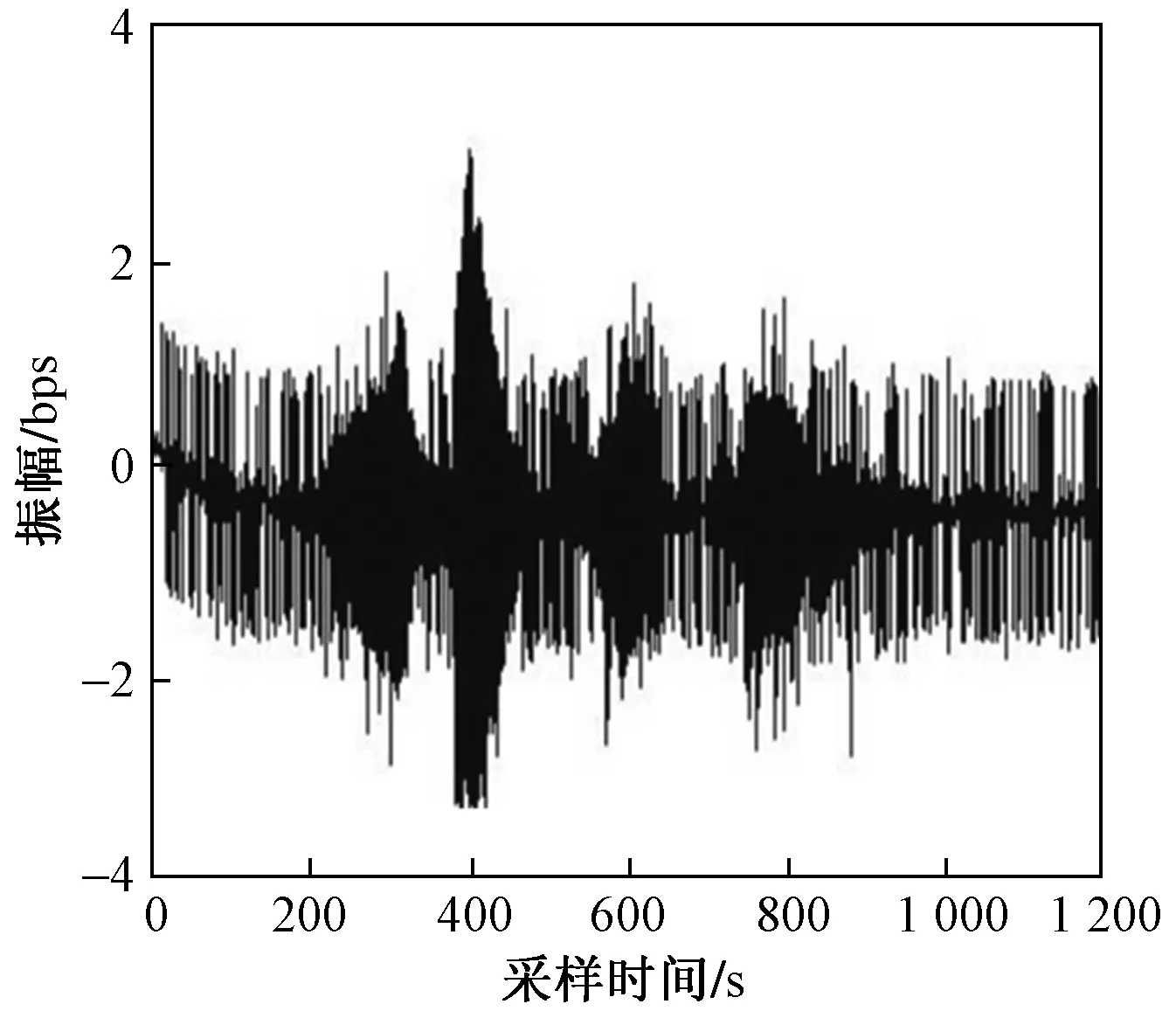
圖1 數據庫訪問時間序列波形Fig.1 The time seriesop database access
針對圖1所示的數據測試集,采用本文方法、文獻[4]方法和文獻[5]方法對數據庫訪問語義指向性特征進行提取,獲取特征提取結果用圖2進行描述。

圖2 三種方法對數據時域波形特征提取結果Fig.2 The extraction results of three methods in time domain
分析圖2可以看出,通過本文方法對跨境電商系統數據語義指向性特征進行提取,能夠完成數據語義本體特征指向性聚類,冗余干擾信息被濾除,特征分布聚類性較強,為數據庫智能訪問提供有效依據。而文獻[4]方法和文獻[5]方法提取結果指向性聚類效果不好,對數據庫智能訪問產生不好的影響,降低訪問精度。
在同樣的仿真環境下,獲取跨境電商系統用戶數據時頻分布,用圖3進行描述。
針對圖3中的數據樣本,對大數據語義關聯特征進行提取,不同方法提取結果用圖4進行描述。
由圖4可以看出,采用本文方法進行特征提取,可獲取樣本數據中的有效數據,數據空間聚集性好。傳統方法特征提取結果性能不佳,抗干擾能力不強,進一步驗證了本文方法特征提取的有效性。
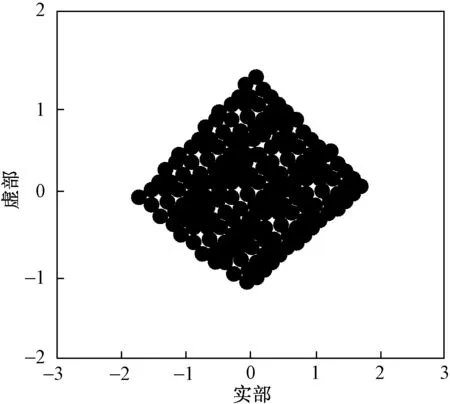
圖3 跨境電商系統用戶數據時頻分布Fig.3 Time-frequency distribution of user data in cross border electricity supplier system
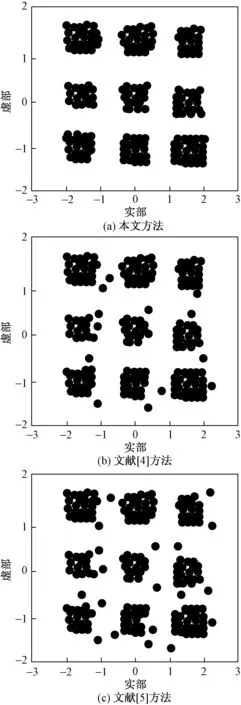
圖4 三種方法對數據時頻特征提取結果Fig.4 The results of three methods for extraction of time and frequency characteristics
2.2 訪問性能測試
通過查全率與查準率對訪問準確性進行測試,計算公式分別如下:
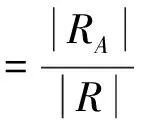
(16)
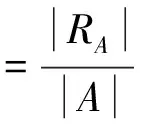
(17)
式中,|R|代表跨境電商數據數量;|RA|代表測試集中和初始訪問相關的數據;|A|代表訪問數據量。
在對跨境電商系統用戶數據庫進行智能訪問時,通常把查全率和查準率當成兩個矛盾指標,查準率會隨查全率的升高而降低,即為了達到查全的目的,很可能會形成一些無用信息。而在查全率增加的情況下,查準率會相應降低。因此需針對不同查全率水平,對查準率進行測試。下面對不同查全率水平下查準率進行處理:
(18)
式(18)中,P(r)代表查全率是r情況下的平均查準率;Nq代表查詢總量;Pi(r)代表查全率是r情況下第i次查詢的查準率。
采用本文方法、文獻[4]方法和文獻[5]方法對跨境電商系統用戶數據庫進行智能訪問,對查全率水平較高情況下的查準率進行比較,結果用表1進行描述。
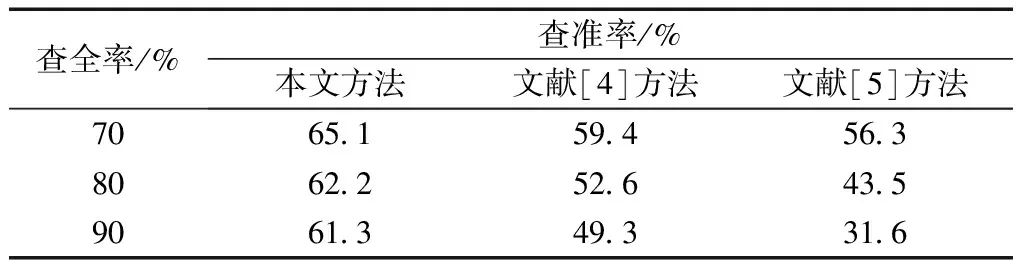
表1 不同查全率水平下三種方法查準率平均值比較結果Table 1 Comparison in average precision of different recall levelsby three methods
分析表1可以看出,在查全率相同的情況下,本文方法查準率明顯高于其他兩種方法,且在查全率升高時,本文方法可令查準率保持在較高的水平,未隨查全率的升高有顯著下降,說明本文方法訪問準確性最高。
3 結論
提出跨境電商系統用戶數據庫智能訪問方法,并對其進行優化。
(1)對跨境電商數據庫模型進行建立,為數據庫智能訪問提供模型依據。
(2)依據模糊層次聚類提取語義指向性關聯特征,在概念格中完成語義指向性相似度計算。
(3)依據提取特征,通過相似度計算匹配實現數據庫智能訪問。該在用戶規模較大的情況下,會影響訪問準確性,針對該問題,采用多維索引樹編碼的方式對其進行優化。利用多普勒效應在跨境電商數據庫節點競爭窗口值進行滑動評估,通過數據庫模型分析數據結構,完成語義指向性檢索。依據對角矩陣完成用戶訪問結果匹配,達到智能訪問的目的,實現對跨境電商系統用戶數據庫智能訪問方法的優化。
(4)實驗結果表明,所提方法訪問準確性高。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
電子制作(2019年15期)2019-08-27 01:12:00
財經(2017年2期)2017-03-10 14:35:35
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
財經(2016年15期)2016-06-03 07:38:02
現代語文(2016年21期)2016-05-25 13:13:44
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
大連民族大學學報(2015年2期)2015-02-27 08:28:11
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
