橋梁健康監測系統中的大數據分析與研究
2020-02-22 03:25:32向陽,杜君
鐵路計算機應用 2020年1期
向 陽,杜 君
(中國中鐵大橋局集團有限公司 武漢橋梁特種技術有限公司,武漢 430205)
橋梁在建成通車后,隨著溫度、濕度、風速等自然氣候環境的侵害,以及日益增加的交通荷載,會導致橋梁逐漸老化、結構性能不斷退化,嚴重時會引起限載通行、關閉交通甚至倒塌的嚴重后果,給人們的生命財產安全帶來危險。因此,很多的橋梁安裝橋梁健康監測系統,橋梁健康監測系統通過安裝在橋梁上的溫度、撓度、索力、濕度、傾角、應變、位移、振動和風速等傳感器實時采集監測數據,將這些數據實時傳輸至后臺服務器,后臺專家系統根據相應的閾值對其進行預警及分析評估。其中,振動、索力等采樣頻率較高,每秒至少采集1次、有的甚至高達上百次。平均一座橋梁上安裝100多個傳感器進行實時監測,傳感器每天采集的數據早就達到GB級別[1-9]。面對橋梁監測傳感器網絡中的高速監測數據流以及數據庫存儲的海量大數據,若在單個服務器上實現數據的存儲及處理分析,傳統的關系型數據庫管理系統已經到達極限,并不能有效地存儲和分析處理這種級別的大數據,現在需要有效、可靠的大數據分析與處理方法,專門快速采集及海量存儲解析這些大量數據。因此,有必要對橋梁健康監測系統中的大數據采集、存儲和分析處理做相應的
研究[10-18]。
1 橋梁健康監測系統中的大數據采集
1.1 橋梁監測傳感器網絡中的高速數據流
數據流的定義:一個由有先后順序關系且個數隨時間不斷增加的元組構成的數據集,如式(1):
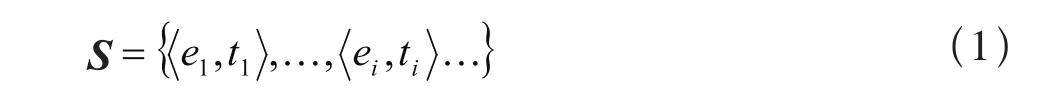
其中,ei是時刻ti出現的序列元素。橋梁健康監測系統傳感器網絡中傳遞的傳感器監測數據即為數據流,這些數據具有如下特點:
(1)傳感器數據流中的數據實時高速傳輸、轉瞬即逝,每個數據只能夠被“看”一次;
(2)傳感器數據流是無限的、源源不斷的;
(3)傳感器數據流中的數據規模很大。
1.2 基于時間片的滑動窗口數據流查詢
面對橋梁監測傳感器網絡中海量數據流的數據查詢,需要多次不斷地采集查詢傳感器,區別于對傳統數據庫的單次或者幾次查詢,屬于一種長期不間斷實時查詢[18]。橋梁監測傳感器網絡中的海量高速數據流可以采用基于時間片驅動的滑動窗口技術,滑動窗口為計算機緩存,保存的是當前時間周期間隙內的最新數據序列。通過這種方式可以實現對橋梁監測傳感器網絡中海量數據流的實時查詢采集。
時間片驅動的滑動窗口的定義:設S[t–T:t]為t時刻傳感器數據流S的滑動窗口,Δt是時間片周期。若是S[t–T:t]于每一個Δt周期的結束時刻產生變化為S[t+Δt–T:t+Δt],則稱S[t–T:t]為時間片驅動的滑動窗口。時間片驅動滑動窗口每隔Δt固定的時間間隔更新一次,實際應用中應按照具體情況設置Δt數據的大小,根據理論要求及實踐規律,T值應大于時間周期Δt。
1.3 K線圖
K線圖又稱蠟燭圖,由股市的開盤價和收盤價以及股市的最高價和最低價這4個數據組成,用于統計分析股價的漲跌趨勢,普遍運用于股票證券市場。K線圖中的矩形實體有2種,其中,紅色實體是陽線,綠色實體為陰線。X軸坐標為時間,Y軸坐標為監測數據,將每天的陽線陰線全部畫出即形成K線圖。如果實體表示的時間周期內的結束值大于起始值,即監測值增漲,則實體為紅色陽線,相反則為綠色陰線。如果起始值與結束值大小相同,則為十字線。最高值和實體之間的線被稱為上影線,最低值和實體間的線稱為下影線。根據時間周期大小的不同,繪制小時K線圖、日K線圖和月K線圖等[19]。
面對橋梁監測中實時采集數據流的查詢統計,例如,查詢時傳感器監測的數據超出給定的閾值,則發出警報;統計某段時間內,監測數據的最大值、最小值等。只需要長期保存監測參數在每一個時間周期中的4個數據:起始值、最高值、最低值和結束值,如圖1所示,摒棄了周期中無需長期保留數量龐大的中間值,只保留了4個關鍵數據,具有數據存儲量小的特點,是監測系統中處理海量數據流的一種好方法。同時,用K線圖描述監測參數的方法,能實時形象地反映出監測數據的波動狀況。
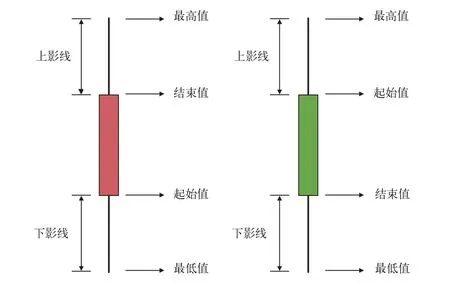
圖1 傳感器網絡中的大數據采集K線圖
1.4 基于K線圖時間片驅動的滑動窗口數據流處理模型
圖2描述了一個基于K線圖時間片驅動的滑動窗口數據流查詢處理模型,用于實現橋梁健康監測中的大數據采集。其具體工作原理流程:傳感器采集的數據流,通過數據緩沖區并添加到時間片滑動窗口,不斷查詢窗口計算結果,自動預警。流查詢處理器讀取采集每個時間片滑動窗口數據流的K線圖關鍵數據(起始值,最高值,最低值,結束值)并上傳云端存入到海量存儲設備,滑動窗口根據實際情況設置時間片周期,當到達固定時間片周期時,更新當前K線圖概要數據,同時拋棄前一個周期的數據,并將最新的數據進行上傳保存。
本文提出的這種基于K線圖時間片驅動的滑動窗口數據流處理模型,是將基于時間片的滑動窗口數據流查詢與K線圖相結合,不僅實現了對橋梁監測傳感器網絡中的海量數據流的實時快速采集,而且還通過K線圖較少的數據個數,快速、形象地反應了橋梁數據流的變化趨勢及波動狀況。

圖2 基于K線圖時間片驅動的滑動窗口數據流處理模型
2 橋梁健康監測系統中的大數據存儲
2.1 橋梁健康監測中的海量數據
橋梁健康監測系統是對橋梁外部環境及結構內力狀態進行實時監測采集,如環境溫濕度、應變、振動和索力等。其中,溫濕度屬于外部環境,變化周期較長,測量周期可以是小時級別,因此數據量較小。但某些結構內力如振動、索力等屬于變化周期較短的參數,采集頻率平均可以達到50 Hz,并要求每天24 h不間斷工作,才能實時反應橋梁的內力狀況。以某單個橋為例,其振動及索力監測點總共達到100個,每個監測點數據采集頻率為50次/s,精確度為16 bit,一天的純數據將近1 GB。同時,隨著監測的橋梁數目的增多,以及對監測數據長年的累積存儲,橋梁監測數據庫的存儲量將會超過TB,甚至達到PB級別。
傳統的單臺服務器存儲方式已經不能滿足橋梁監測日益增長的數據量儲存需求。本文采用HDFS分布式存儲模型,解決海量數據存儲問題。
2.2 HDFS分布式存儲模型
HDFS(Hadoop Distributed File System)是一種Hadoop大數據框架下的分布式文件系統,主要用于大數據的分布式存儲。HDFS實際上是由數百個甚至數千個廉價小型服務器組成的集群,通過眾多服務器一起實現數據的分布存儲,每個數據文件都至少有1個冗余備份,也就是每個數據文件都將至少被存儲2次,如果存數據的某個服務器發生了故障,至少還有1個備份數據,所以,HDFS具有高容錯性。這比單獨使用一臺大型服務器在遇到故障時的成本付出要少得多,現在,如果某個服務器發生故障,只需要付出一臺廉價服務器的成本。
HDFS分布式存儲模型,如圖3所示。
(1)NameNode是一臺中心服務器,在整個集群系統中有且僅有一臺,是唯一用于管理所有的DataNode數據節點的服務器。
(2)每個DataNode節點為一臺數據存儲服務器,用于存儲數據文件以及相應的冗余備份副本,并對數據進行一些讀寫操作。
(3)NameNode節點周期性地實時查詢每個DataNode節點的狀態,掌握每個數據塊存儲的服務器節點的位置等相關信息,并能知道節點是否需要維護。
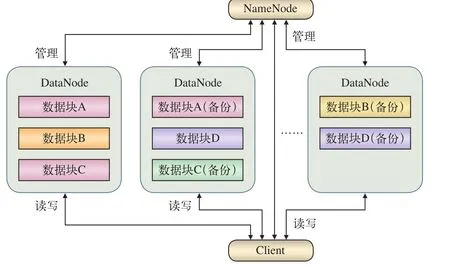
圖3 HDFS分布式存儲模型圖
HDFS分布式存儲模型工作原理:用戶機Client通過向NameNode發送數據讀寫請求,NameNode返回數據塊存儲的DataNode節點位置,Client節點與DataNode節點進行相應的讀寫操作。在整個HDFS集群系統中,NameNode起到核心管理作用。
通過HDFS分布式存儲模型,利用服務器集群分布式存儲的方式有效解決了橋梁健康監測中的海量數據存儲問題。
3 橋梁健康監測系統中的大數據分析處理
3.1 Map/Reduce模型
Map/Reduce模型是一種用于大數據計算處理的軟件模型框架,其關鍵技術是“Map(映射)和Reduce(規約)”。將海量數據分割成多個獨立的輸入數據塊給M臺服務器進行并行處理;每臺服務器通過Map映射函數計算處理自己那部分輸入數據塊,并生成計算結果;R臺服務器通過Reduce規約函數將所有的計算結果進行規約匯總、分析計算,得到最終的處理結果。橋梁健康監測系統中的海量大數據可采用Map/Reduce模型,將海量數據分布在服務器集群中,通過服務器集群進行同時分析處理,相比傳統的單臺服務器分析處理運算,將會大幅縮短運算時間,提高計算效率。
3.2 斜拉索索力測量計算方法
由于橋梁斜拉索的銹蝕斷絲等病害容易致使斜拉索索力及其相應的結構內力狀態產生改變,甚至有可能導致橋梁倒塌,因此,需要對橋梁斜拉索的索力進行實時監測。
在每根索的中央斷面處安裝加速度傳感器,傳感器輸出的數據經快速傅立葉變換計算處理后可得到每根索的主頻率。索力可根據公式(2)計算[20-23]:

式(2)中:T為索力;f為拉索的一階頻率;L為索長;W為單位長度索重;g為重力加速度。
3.3 基于Map/Reduce的索力分布式并行處理模型
通過基于Map/Reduce的索力分布式并行處理模型可以實現對索力歷史大數據的統計分析處理功能。例如,統計10年內索力超過指定閾值的次數:(1)通過Map/Reduce中的Map,將橋梁監測的歷史索力數據輸入文件分割成M份,把任務分解成M個子任務,通過服務器集群并行運算分析,提高系統的運算速度,減少分析時間;(2)通過Reduce把M個子任務計算的結果匯總統計,得到最終結果。其中,索力輸入文件格式,如表1所示。
基于Map/Reduce的索力分布式并行處理模型的具體工作流程,如圖4所示。Master節點服務器為整個模型框架的主節點服務器,負責整個系統的運行、管理、分配以及調度,為空閑的worker節點服務器分配Map作業以及Reduce作業。Master主服務器將海量數據分割成M份數據塊,并將其分配給空閑的worker服務器集群,服務器集群并行讀取對應分割的索力數據塊文件,服務器每讀取一條記錄時,一旦超過閾值,就生成一條索力中間鍵值對<key,value>,其中,key為索力編號,value表示超過閾值的次數。Master將記錄的索力中間鍵值對的位置轉發給執行Reduce作業的R個worker服務器節點。執行Reduce規約作業的worker服務器最后讀取所有的索力中間鍵值對,通過服務器集群并行統計,計算出最終結果。當所有的Map和Reduce作業都完成了,Master服務器將Reduce結果返回給用戶程序。
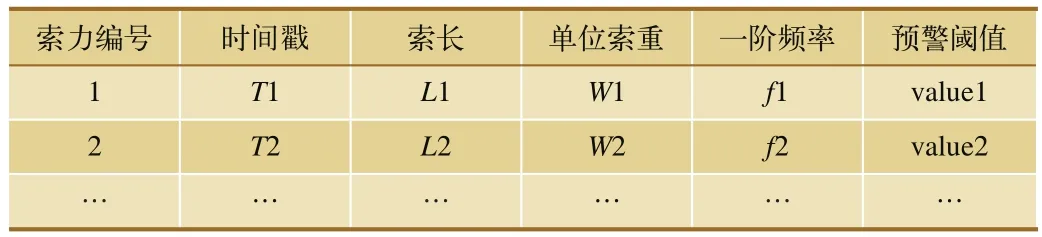
表1 索力數據文件格式
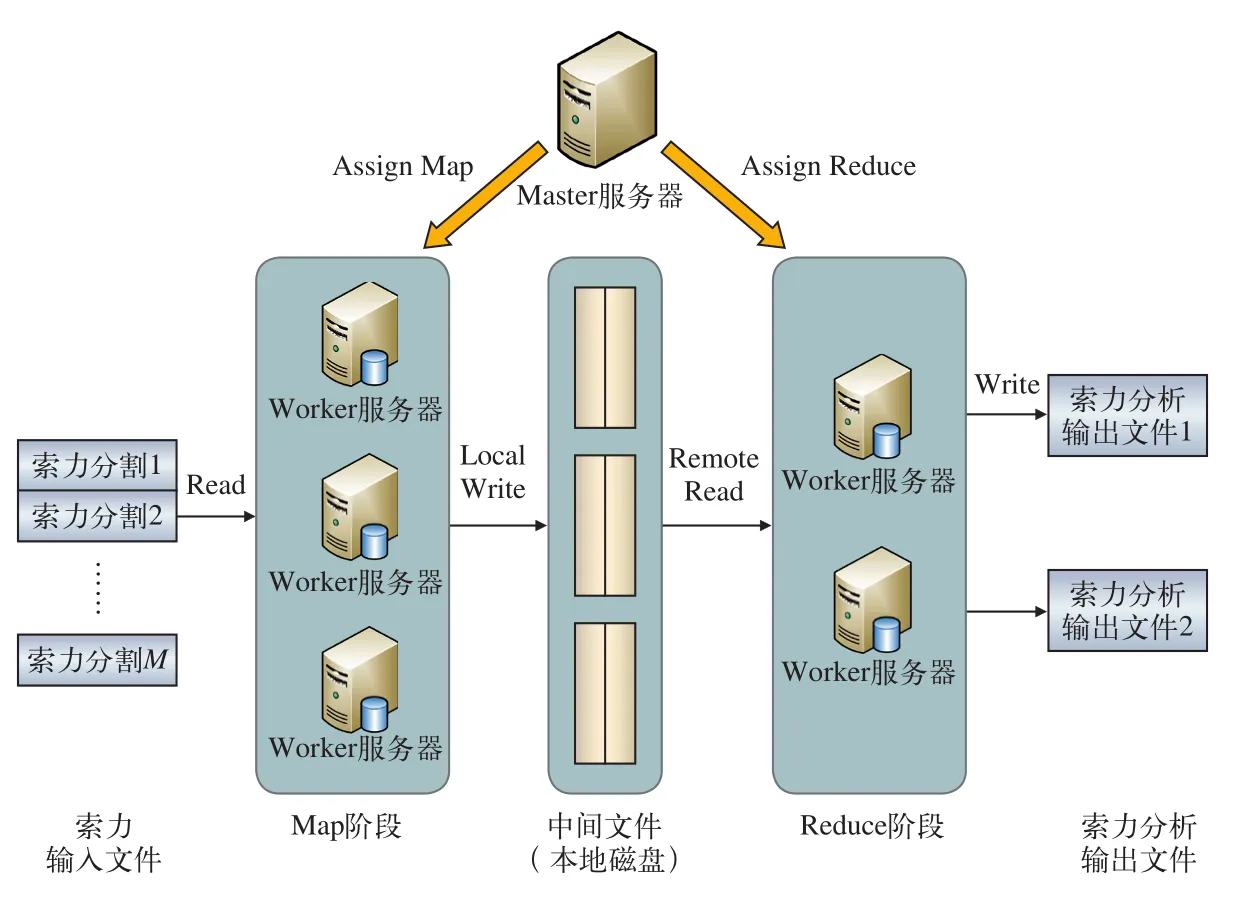
圖4 基于Map/Reduce的索力分布式并行處理工作流程
4 實驗結果分析驗證
4.1 K線圖時間片驅動模型的數據存儲量分析驗證
設監測傳感器的數量為n個,采集頻率為f,每天存儲的數據量為S,存儲一天監測數據的數據量為:

若采用基于K線圖時間片驅動的滑動窗口數據流查詢處理模型,使用k秒鐘K線圖,每k秒存儲起始值、最高值、最低值、結束值這4個數據,那么存儲一天監測數據的數據量為:

式(3)與式(4)中S值的大小取決于在實際的橋梁實時健康監測中,索力、振動等采集頻率一般是20 Hz~100 Hz左右,采用4 s K線圖基本可以滿足橋梁監測的需求,使用本模型,實際存儲的數據量至少可以減少20倍。
4.2 Map/Reduce索力分布式并行處理模型性能測試實驗
實驗采用4臺服務器組建計算集群,每臺服務器配置相同,CPU:Intel雙核1.80 GHz,內存:8 GB。利用Hadoop大數據框架中的Map/Reduce模型,驗證基于Map/Reduce的索力分布式并行處理模型,其中,一臺服務器作為Master管理節點,其余3臺服務器作為worker計算節點。針對不同大小的索力文件,分別采用傳統的單機計算模式與本文的Map/Reduce并行模型進行處理,利用專家分析評估系統,統計索力超過某一閾值的次數,將系統的運算執行時間進行比較,實驗結果,如圖5所示。
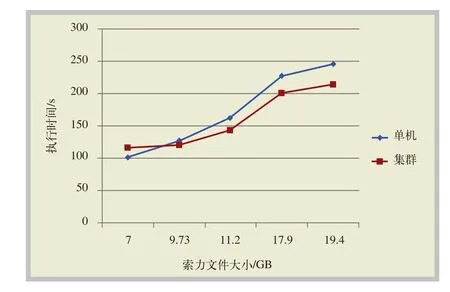
圖5 單機系統與Map/Reduce集群系統執行時間對比
從以上仿真結果可以看出,運行Hadoop平臺需要一定的時間開銷,因此當數據量較小時,集群并行計算的運行時間反而大于單臺服務器執行的時間。但隨著數據量的增大,Map/Reduce集群將索力數據文件分派給多個worker節點進行并行處理,其運算總時間小于單臺服務器的執行時間,隨著索力文件大小的不斷增加,兩者的總時間差距也越來越大。
5 結束語
本文在橋梁健康監測的大數據采集、存儲及分析處理3個方面,提出一種基于K線圖時間片驅動的滑動窗口數據流處理模型,該模型實現橋梁實時監測傳感器網絡大數據的高速采集,通過K線圖模型,不僅形象地反應監測數據的狀況波動,而且減少了數據采集量,優化了云端海量存儲。將HDFS分布式存儲模型應用到橋梁健康監測中,解決了健康監測中海量數據的存儲問題。提出基于Map/Reduce的索力分布式并行處理模型,并將該模型應用于索力大數據分析計算處理,通過搭建基于該模型的分布式計算集群,實現專家系統對索力歷史海量數據的分析評估,減少系統分析時間,提高評估效率。
本文分別對橋梁實時健康監測的大數據采集,大數據存儲,大數據分析3個部分進行了分析與研究,但對于大數據預測還有待進一步的挖掘和分析。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
湖南教育·A版(2019年4期)2019-05-10 03:31:44
小學生學習指導(低年級)(2019年4期)2019-04-22 03:28:24
中國公路(2017年11期)2017-07-31 17:56:30
中國公路(2017年10期)2017-07-21 14:02:37
山東工業技術(2016年15期)2016-12-01 05:31:04
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
