基于Word2vec的創新行為自愿性信息披露指數研究
2020-02-06 03:52:52齊萱馬曉慶李巖劉樹海
現代商貿工業 2020年2期
關鍵詞:深度學習
齊萱 馬曉慶 李巖 劉樹海

摘 要:收集了2012-2017年深圳證券交易所中小企業板年度報告,共計3090份有效樣本,從創新意識、創新支持、創新管理、創新實現、創新推廣、創新效果等方面創建中小企業創新行為自愿性信息披露評價指數,利用深度學習技術——Word2vec給出科學的評判方法。然后從披露內容、行業類型、產權性質、地理區域等方面對中小企業板創新行為自愿性信息披露現狀進行分析評價,結果表明:中小企業創新行為自愿性信息6年平均披露程度為50.83%,整體水平雖然不是很高,但是呈現逐年上升的趨勢,未來在創新支持和創新實現方面還有很大的提升空間。
關鍵詞:創新行為;自愿性信息披露;深度學習;Word2vec
中圖分類號:F23 文獻標識碼:Adoi:10.19311/j.cnki.1672-3198.2020.02.057
0 引言
目前,中國已進入經濟發展的新常態,創新驅動已成為加速企業形成新發展方式,提高整體質量和效益的新動力。在新的創新浪潮中,大量中小企業積極致力于技術創新,一些大型企業也不一定投身于所有的技術創新,他們可以購買外部技術,通過中小企業來實現其創新“副產品”的價值。隨著大數據、互聯網等信息技術的不斷發展,企業越來越多的創新內容已經成為投資者評價企業發展的重要決策依據。中小企業較高的技術含量、良好的盈利能力以及快速增長使其成為創新和創業的重要生力軍。中小企業充分披露創新行為信息則有利于其獲得外部資金,推動其投資活動,從而達到資源的有效配置。
基于此,本文從創新意識、創新支持、創新管理、創新實現、創新推廣、創新效果等方面研究中小企業創新行為自愿性信息披露評價問題,本文的貢獻在于:一是創建中小企業創新行為自愿性信息披露評價指數;二是利用深度學習技術給出科學的評判方法。
1 文獻回顧
創新行為信息披露最早可以追溯到Allen(1983)的研究,旨在節約高昂的長期知識保護成本。中國關于企業創新行為信息披露的研究起源于對無形資產研發信息披露的研究。薛云奎(2001)發現中國上市公司R&D費用信息披露不當或不充分,整體披露水平不高。后續學者使用內容分析法建立R&D或創新的信息披露指標,以評估信息披露的程度:韓鵬和彭韶兵(2012)構建R&D信息披露質量評價指標體系,然后利用熵值法測量和分析創業板上市公司2010年度報告中披露的信息質量;王娟和張世舉(2014)從基于知識的無形資產、R&D投入、創新資金來源、創新效益和創新激勵分配等方面評價中國信息技術產業上市公司技術創新信息披露發現:技術創新信息披露質量比新準則實施前有較大提高,但還是存在主動自愿披露積極性不高,重形式輕實質等問題;韓鵬和岳園園(2016)以我國創業板2012-2014年上市公司為對象,將創新行為信息披露分為強制性和自愿性,分析創新行為信息披露的經濟后果;馮科和杜微(2016)以創業板市場為研究對象,將企業創新行為信息分為四個維度:公司戰略規劃、產品自主創新、新增知識產權、創新政策受惠,研究發現創業板上市公司創新信息披露能夠導致股價異動。
還有學者將語料庫語言學中“共現頻率”運用到自愿性信息披露研究中,即相關關鍵詞出現的頻率越高,說明企業對此相關文本信息的披露意愿越大,表示管理層自愿性披露創新行為信息的傾向越大。Entwistle(1999)使用描述研發信息的句子數來衡量研發信息披露水平,從研發資源、研發產出、研發資金來源、研發后續投入保障等角度選取這些句子。王宇峰(2009)提出企業R&D信息披露的類目,包括:R&D戰略及未來支出、R&D投入、R&D產出、會計問題、會計政策,選取句子數作為分析R&D信息披露的頻率。James和Shaver(2016)的研究則是將含有研究、研發、專利、新科技等方面的詞語搭配作為關鍵詞,從中提取研發信息。王華(2018)考慮到中文語境語義判斷難度,從表達能力和切分難度視角選擇以“詞”為研究對象,構建研發關鍵詞庫,以年報中相關詞頻統計度量研發文本信息披露程度。
由上述可見,創新行為信息多采用指標評價法人工處理信息,文本信息的搜集、整理和分析多歸于人的主觀判斷,客觀性略顯不足,同時也存在著大樣本研究困難等問題。而在目前我國自愿性信息披露普遍意愿不足的情況下,若將這種指標評價直接用于長時期、全行業的樣本,則很難形成整體的有效評分。為此,本文則利用深度學習的神經網絡計算技術自建處理模塊,對中小企業板上市公司年報進行全樣本提取與計算,使得創新行為自愿性信息披露評價更加科學。
2 基于Word2vec的文本挖掘
文本挖掘是要將文本轉化為數據以供后續分析。最典型的方法是基于詞袋的方法(Bag-of-Word,BOW)。所謂“詞袋”就是裝著詞的袋子。該方法就是將一段文本,比如一個句子或一個文檔,用一個裝著詞的袋子來表示。比如說有這樣兩句話,“技術創新帶動產品創新,機制創新促進自主創新”,那么詞袋里就是:[技術,創新,帶動,產品,機制,促進,自主],用數組表現這兩句話就是:[1,2,1,1,0,0,0],[0,2,0,0,1,1,1]。這里每組數據的維度就是詞袋總數,而每項數據值則是各個詞出現的頻率。由此可見,隨著句子增加,數組的維度將會變得巨大,而且會有大量的稀疏空間,即0的出現。為了解決這個問題,詞向量的概念被引入。
詞向量又稱分布式表示(Distributed representation)。它最初是由Hinton在1986年提出的。詞向量的構想是這樣的,將構成文本的每個基本元素即單詞,通過一定的訓練,映射到由全部單詞組成的低維向量空間,每個單詞則形成向量空間中對應的一個點。因此,向量空間中的向量運算可用于處理單詞與單詞之間的關系,例如使用向量空間中兩點之間的距離來表示兩個單詞之間的相似性。使用這種單詞表示方式可以很好地克服詞袋法的文本向量維度過大的缺點,因此兩個單詞含義越相似,向量空間中的距離就越近。這就將處理文本內容的方法轉換為多維向量空間中的向量運算,向量空間上的距離即可表示文本語義相似度。
本文中使用的Word2vec是由Google的Mikolov在2013年提出的基于神經網絡的深度學習算法。該算法將每個單詞表示為實數值的向量,即所謂的詞向量。Word2vec算法的基本構思是基于Bengio三層神經網絡語言模型的改進。它由兩個模型組成:(1)CBOW模型,它通過上下文預測當前詞;(2)Skip-gram模型,它通過當前詞來預測上下文。本文的目標是利用所給定的創新行為自愿性信息指標來計算各個上市公司的信息披露程度與其的相關性,因此采用Skip-gram模型來進行計算。
顧名思義,Skip-gram就是“跳過某些符號”,例如,句子“技術創新能夠帶動產品創新”有4個3元詞組,分別是“技術創新能夠”,“創新能夠帶動”,“能夠帶動產品”,“帶動產品創新”,我們發現這句話的本意是“技術帶動產品”或“創新帶動產品”。但是,上述四個3元詞組并未反映出此信息。 Skip-gram模型卻允許跳過一些詞,因此它可以形成名為“技術帶動產品”的3元詞組。如果允許跳過2個詞,即2 Skip-gram,則上述句子組成的3元詞組可以用表1顯示。
由表1可以看出:一方面,Skip-gram反映了句子的真正含義,在新組成的18個3元詞組中,有5個詞組可以正確反映例句的真實含義。另一方面,語料庫得到擴展,3元詞組已從原來的4個擴展到18個,擴展后的語料庫可以提高文本訓練的準確性。可以看出,獲得的詞向量可以更好地反映文本的真實含義。
3 基于Word2vec的創新行為自愿性信息披露指標評價——以中小企業板為例
中小企業由于規模小、信用低、資源短缺、風險大等原因致使其融資相對困難,則促使其更有動機主動多披露自愿性創新行為信息以緩解其融資約束、提高投資效率。但是對中小企業管理層而言,在考慮市場進入障礙、企業競爭力以及披露成本和收益等,尚不清楚如何把握創新行為自愿信息的實際披露水平,由此,有必要建立科學的中小企業創新行為自愿性信息披露評估體系進行量化。
3.1 選擇創新行為的自愿性信息披露指標
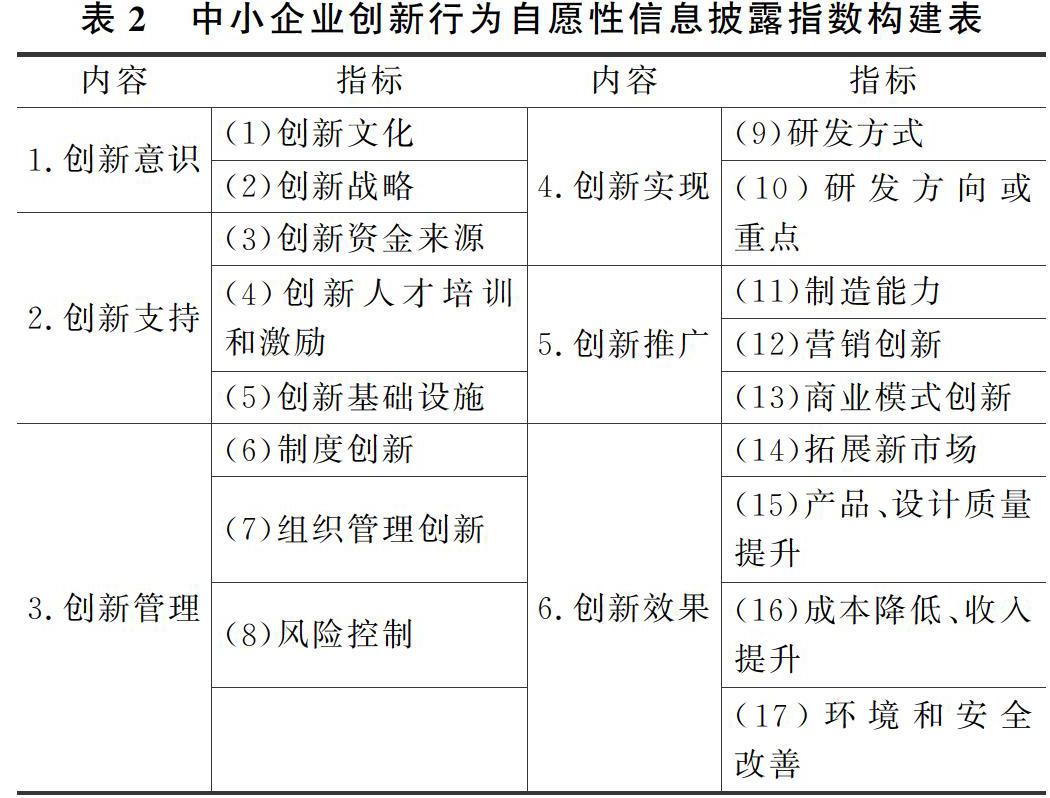
本文主要參考Botosan(1997)研究思路,結合的創新過程視角,構建創新行為的自愿信息披露指標。評估指標包括相互獨立的6項內容和17項細分指標。披露內容涉及中小企業創新意識、創新支持、創新管理、創新實現、創新推廣、創新效果等方面的情況,細分指標用于在年報中定位采集信息點。
3.2 研究樣本及詞頻采集
本文選取2012年至2017 年深圳證券交易所中小企業板上市公司年報,分為 16 個行業類別,剔除金融行業和數據缺失的公司,最終每年獲得515份有效樣本;然后,從有效樣本中篩選和提取創新行為自愿性信息披露相關詞頻,共計481個,如和創新文化相關的詞頻有:首先文化建設、創新思維、技術創新理念、科創立企、創新變革、崇尚創新、創新為先、改革創新、文化引領、特色企業文化,自主創新理念等;然后用Word2vec評估創新行為的17個自愿性信息披露指標的相似性,即中小企業創新行為的自愿性信息披露程度;最后將所有有效樣本的相似度按行業、地區、年份等存儲在 Excel表中。
3.3 基于Word2vec的創新行為自愿性信息披露程度評價的過程
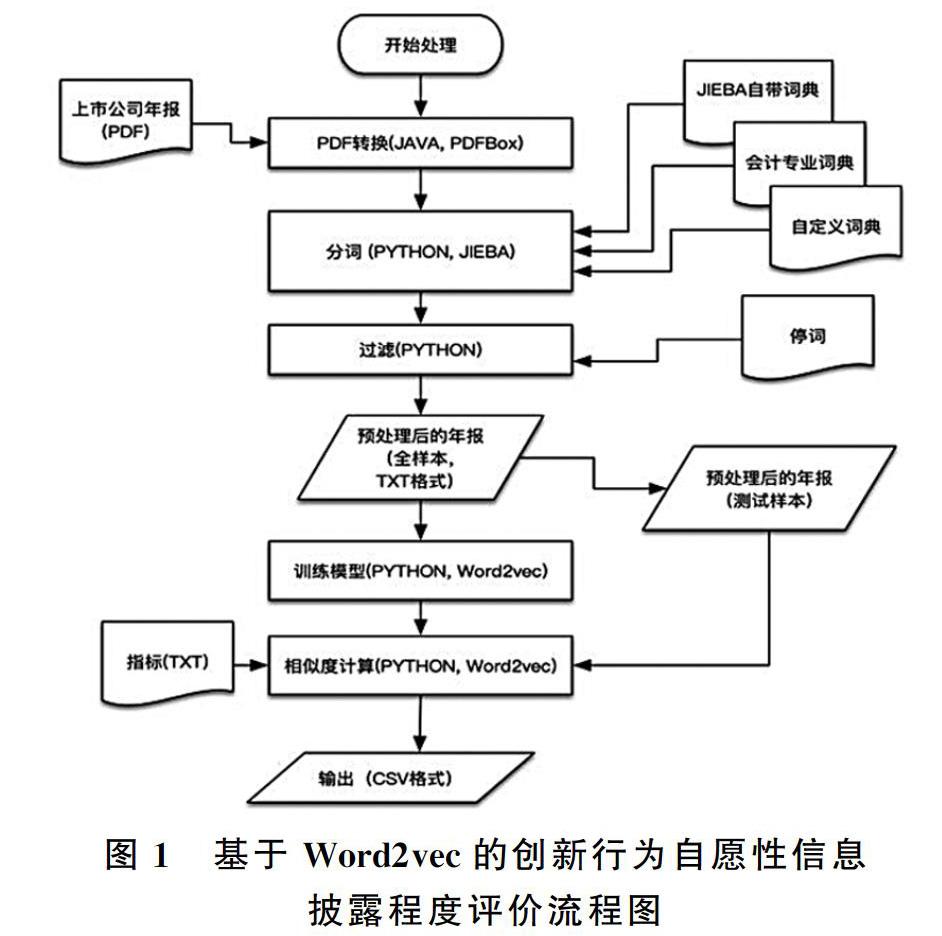
本文利用開源軟件包Word2vec以及其它輔助的開源軟件包,在阿里云的配置為CPU64核內存128G云服務器上進行運算,通過以下五個步驟實現創新行為自愿性信息披露程度的自動評價過程(見圖1)。
步驟一:為了方便后續處理,首先利用JAVA語言調用開源軟件包PDFBox將采集到的中小企業板2013-2017年515家上市公司共計2575份年報PDF版轉換成TXT文本。
步驟二:利用PYTHON語言調用開源軟件包JIEBA將TXT文本進行分詞。在此除了JIEBA自帶的詞典之外,還使用了會計專業詞典以及自定義的詞典以提高分詞的準確率。
步驟三:在分詞之后,利用PYTHON語言構建停用詞表,去掉數字以及多次出現的與評價體系無關的詞頻,即停用詞,如“情況、報告、適用、項目、董事會、獨立、主要”等,經過反復測試,最后本文去掉排名前100個停用詞,以減少機器讀取相關指標信息的干擾,對文本進行過濾。
步驟四:使用上述預處理語料庫制作全樣本,使用PYTHON調用Word2vec并通過Skip-gram模型進行訓練以獲得詞向量模型。對應詞向量形式為W=(V1,V2,…,Vn),其中 W 為對應詞匯,Vi(1≤i≤n)為詞匯 W的第i個特征維度(一般n的值在100-500之間)。Word2vec提供了20個參數來調整訓練過程。不同參數的選擇對生成的詞向量質量及其相應的訓練速度有影響。熊富林(2015)的實驗結果表明:各項指標對應的平均相關度隨著維度的變化而變化,在維度達到250以后趨于平穩。由此本文將Word2vec在中文處理中的維度設置為256。本文使用的Word2vec的參數如表3所示。
步驟五:依據人工整理的481個反映創新行為自愿性信息披露詞頻,分17類指標進行文本相似度計算。利用以上訓練得到的詞向量模型,依次計算每份年報與指標之間的相似度, 即該中小企業創新行為自愿性信息披露的程度并以CSV格式輸出。
3.4 評估中小企業板創新行為自愿性信息披露程度
總體而言,2012-2017年中國中小企業板創新行為的自愿性信息披露整體水平不是很高,但正在逐步上升。在樣本期間內,平均披露程度由2012年的4838%增至2017年5391%(見圖2)。下面分別從披露內容、行業、產權性質和區域等方面分析。
3.4.1 分析中小企業創新行為自愿性信息披露內容
中小企業板2012-2017年創新行為自愿性信息披露整體保持增長態勢,評價結果發現:(1)創新意識上繼續提高。其在頭兩年上升,2014年略有下降,然后在2014-2017的三年期間繼續上升。這表明創新思維等受到重視,在不斷地拓展。(2)創新支持方面雖然穩中有升,但披露程度在六項披露內容里是最低的,由此,中小企業還要通過人才激勵、更新創新基礎設施等措施做好配套的支持創新工作。(3)創新管理表現較好,增長態勢趨于平緩。從2012年54.83%開始增長,2014年下降,后三年持續增長。得益于企業組織管理創新等不斷開展,風險控制不斷完善。(4)創新實現方面前三年處于波動水平,后三年為上升態勢,2017年達到最高52.16%。創新實現依靠著企業的研發方式、制造能力等,通過這些方式使企業快速地發展。(5)創新推廣方面表現最好,六年間大幅度提升披露程度。從2012年到2017年的一直上升,高達62.38%。隨著互聯網、人工智能的普及,營銷創新等的推廣,使企業的品牌形象等綜合實力逐漸增強。(6)創新效果方面整體保持增長態勢,除了2014年稍有下降。說明創新終將給企業帶來良好的經濟效益。
3.4.2 分析不同行業中小企業創新行為的自愿性信息披露程度
根據深交所中小企業板的樣本得到14個一級行業,按照行業對2012-2017年創新行為自愿性信息披露綜合實力進行對比評價。限于篇幅,本文主要描述和評價位居前三和后三的行業結果。住宿和餐飲業位居第一,前三年為下降趨勢,后三年為上升趨勢,到2017年達到56.82%。這反映出該行業普遍變動靈活,對創新有快速適應能力和把控力。租賃和商務服務業居第二,前兩年披露程度為上漲,2014年稍有下降,接著從2015年的52.59%一路漲到2017年的53.88%;得益于國家的政策支持及產業結構轉型升級的重要作用,該行業的綜合實力獲得快速提升。信息傳輸、軟件和信息技術服務業位列第三,由于其與新興技術具有較強的關聯性,隨著技術的迅速發展,行業信息披露水平也相應提升:2012年披露程度開始上升,2014年略有下滑,但后三年穩步上升。
最靠后的三個行業是交通運輸、倉儲和郵政業,房地產業和采礦業。三個行業的增長態勢基本相同:前兩年增長、2014年下降后穩定上升。由于三個行業屬于傳統制造業,對自然資源依賴度較高,產業結構轉型和升級難度較大,創新行為難以形成行業核心競爭力。
3.4.3 分析不同產權下中小企業創新行為自愿性信息披露程度
根據上市公司產權性質,本文將2012-2017年中小企業板樣本企業分為國有企業與非國有企業。非國有中小企業創新行為的自愿性信息披露程度發生了很大變化,2012年的披露程度為48.55%,然后開始有下滑,雖2015年有所上升,但2016年下降到最低點22.77%,2017年回升。國有中小企業創新行為的自愿性信息披露程度每年都有所不同,但變化幅度很小,控制在4%之內,2012年為36.53%,雖然在2013-2016年之間自愿性信息披露程度有增有減,但2017年還是上升到了37.58%,見表4。
從表4可以看出,國有中小企業創新行為的自愿性信息披露水平高于非國有中小企業,主要與國有中小企業的企業性質有關。首先,國有中小企業信息披露機制比較完善,主動披露意識強;其次,為了向社會傳遞良好的信號,國有中小企業披露了相對更多關于創新行為的信息。非國有中小企業創新行為自愿性信息披露程度不穩定與其融資困難相關,該類企業資金獲取渠道比較狹窄,致使其投入到創新活動的資金相對不充足,導致其創新實現、創新推廣和創新效果不能達到預期,進而影響到披露程度。
3.4.4 分析中小企業不同地區創新行為的自愿性信息披露程度
對2012-2017年中小企業板樣本數據按東部、中部、西部和東北部劃分,發現披露水平差距較小,排名具體如下(見表5):東部地區增長最快,從2012年的48.61%上升到2017年的54.79%,增長了11.28%。在樣本期間,總體趨勢在上升,但在2014年略有下降。主要是東部地區鼓勵創新的政策較多,企業的創新行為也越來越多。東北地區排名第二,該地區從2012年的49.09%開始上升,到2014年有下降,之后三年披露程度呈上升趨勢, 2017年達到54.99%。這說明該地區的中小企業較重視企業創新,而且積極地向外界披露企業有關創新的活動。中部地區排名第三,該地區的創新行為自愿性信息披露程度從2012年的48.43%一直上升到2017年53.23%。這說明中部地區企業越來越重視創新,信息披露制度日益完善,企業更加主動地披露有關創新的信息。西部地區排名最靠后,2012年披露程度是47.83%,2013年有所上升,但2014年又開始下降,隨后在后三年呈上升趨勢。這說明該地區自身經濟發展慢,創新意識缺乏,相應的披露制度不規范,導致其披露水平落后于其他地區。
4 基于Word2vec的創新行為自愿性信息披露指標可靠性分析
4.1 Doc2vec模型與Word2vec所得出結果對比
Doc2vec是Mikolov基于Word2vec模型提出的針對句子以及短文的語言模型。Doc2vec本身也有兩種模型,PV-DM和PV-DBOW,分別對應Word2vec的CBOW和Skip-gram。因此本文采用PV-DBOW作為比較。Doc2vec的評價流程與Word2vec完全一致,并選擇同樣的參數訓練模型以便于對比。最后將利用Word2vec計算的結果與利用Doc2vec計算的結果做Pearson相關分析,得到0.956的結果。由此可見,這兩種模型具有高度的一致性。
4.2 人工評判與Word2vec所得出結果對比
為保證評判技術結果的可靠性與準確性,本文隨機抽取52家樣本公司的技術評判結果與人工評判結果進行了對比。人工樣本采用里斯特量表,17個指標分別按照披露程度從0-5分打分,不考慮權重的影響。最后將17個指標的分值做簡單算術平均,取得中小企業創新行為自愿性信息披露得分。計算Pearson相關系數檢驗52家樣本公司的技術評判結果與人工評判結果的相關性。可靠性分析表明,在0.01的顯著水平下,人工評分與技術評分之間的Pearson相關系數為0.907,沒有顯著性差異。由此可以推斷,技術評分與人工評分對上市公司的自愿性信息的評價結果較為一致,技術評分的可信度較高。
5 結論
本文根據中小企業板上市公司創新行為的各項自愿性信息披露指標,提取、收錄和分析年報中是創新行為自愿信息,使用Word2vec進行文本挖掘和分析,判斷中小企業板上市公司創新行為的自愿信息披露水平。通過技術評判結果與人工評判結果的比較,進一步調試評判技術,使其有效性達到可信度。本評判方法相對于人工評分,可以很大程度上提高閱讀冗長年報的精確度和效率,減少遺漏問題,克服人為主觀因素影響,使得中小企業板上市公司創新行為自愿性信息披露質量評價更客觀、高效,為投資者的投資決策提供更科學的依據。但是,由于少部分報告的披露格式、語言風格等與大多數報告明顯不同,這種評判方法在處理少部分報告時會產生一些誤差,此外,未來上市公司報告語言可能會隨著政策變化而改變,這些問題還有待進一步研究加以克服。
參考文獻
[1]Allen R.Collective Invention[J].Journal of Economic Behavior and Organization.1983,4(1):1-24.
[2]薛云奎,王志臺.R&D的重要性及其信息披露方式的改進[J].會計研究,2001,(03):20-26+65.
[3]韓鵬,彭韶兵.研發信息披露質量測度及制度改進[J].財經科學,2012,(07):103-110.
[4]王娟,張世舉.企業技術創新信息披露:內容、現狀與改進對策[J].河南科技大學學報(社會科學版),2014,32(02):70-75.
[5]韓鵬,岳園園.企業創新行為信息披露的經濟后果研究——來自創業板的經驗證據[J].會計研究,2016,(01):49-55+95.
[6]馮科,杜微.企業創新信息披露與中國創業板市場的有效性研究[J].新經濟,2016,(16):26-39+4.
[7]Entwistle G M.Exploring the R&D disclosure environment[J].Accounting Horizons.1999,13(4):321-341.
[8]王宇峰,蘇逶妍.我國上市公司研發信息披露實證研究[J].中南財經政法大學學報,2009,(4):108-113.
[9]James S,Shaver J M.Strategic motivations for voluntary public R&D disclosures[J].Academy of Management Discoveries.2016,2(3):290-312.
[10]王華,劉慧芬.產品市場競爭、代理成本與研發信息披露[J].廣東財經大學學報,2018,33(03):52-64.
[11]Hinton G E.Learning distributed representations of concepts[C].Proceedings of CogSci.1986:1-12.
[12]Mikolov T,Sutskever I,C'hen K,et al.Distributed Representations of Words and Phrases and their Compositionality[J].Advances in Neural Information Processing Systems,2013,(26):3111-3119.
[13]Botosan C.Disclosure level and the cost of equity capital[J].Accounting Review,1997,72(3):323-349.
[14]熊富林,鄧怡豪,唐曉晟.Word2vec的核心架構及其應用[J].南京師范大學學報(工程技術版),2015,15(01):43-48.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
