基于人工智能的心臟疾病診斷
2020-02-06 03:52:52賀文韜
現代商貿工業 2020年2期
賀文韜

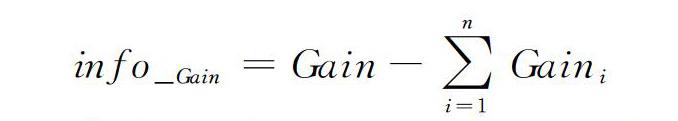
摘 要:隨著科學技術的發展,人工智能已經應用到醫學的各個領域 。根據美國某區域的心臟病病人情況,收集使用年齡,膽固醇水平、血壓、空腹血糖等10項指標數據,基于決策樹方法和隨機森林模型,對其是否患心臟疾病進行檢測,發現隨機森林方法在正確率,召回率,F1值等方面都優于支持向量機方法。因此,隨機森林方法在心臟病診斷方面具有很好的應用。最后,針對心臟病患者模型的因子對心臟病的預防提出建議。
關鍵詞:心臟疾病;多生理參數;隨機森林;決策樹
中圖分類號:TB 文獻標識碼:Adoi:10.19311/j.cnki.1672-3198.2020.02.093
1 背景介紹
在谷歌開發者大會上,首席執行官桑達爾·皮查伊闡述了其最新的人工智能研究有朝一日將如何幫助醫生發現心臟病。目前世界范圍內心臟疾病人的人數逐漸增多。據世界衛生組織統計,在2012年,全球心血管疾病患者為1750萬人,占所有非傳染疾病患者人數的46.2%,因此心血管疾病的預防與治療確實刻不容緩。中國心臟疾病的情況也十分嚴重,國家心血管病中心發布的《中國心血管病報告2012》數據顯示,中國心血管病現患人數已高達2.9億,即在成年人中患病人數約占百分之二十,每年約350萬人死于心血管病,也就約為每10秒就有1人死于心血管病。而人工智能技術可以有效解決部分心血管疾病問題。人工智能方法根據情況設置相關參數,讓電腦學習各種醫學指標和信息,來預測患者的心臟病發病可能性。那么,人工智能方法相當于經驗的醫生,結合患者的檢驗報告和其他信息,可能可以正確預測出病人的患病情況。本論文針對人工智能在心臟病的應用等方面做出研究。
人工智能結合醫療的相關研究最近處于爆發式增長階段。曹敦煜等人通過討論人工智能的價值,前景等闡述了人工智能在心臟病治療的應用。于觀貞等專家通過對醫療活動中較為成功的 AI 研究,系統性的評述闡述了人工智能在臨床醫學中的應用與思考國內外多數研究。董慧康等人圍繞著疾病診斷領域中的心臟病診斷展開研究,通過借助對患者多生理參數的監測,結合先進的數據分析和人工智能方法,采用人群搜索-支持向量機放過發,構建預測心臟病多輔助診斷模型,結果顯示該方法精度較高,提高了心臟疾病診斷的準確性。顏紅梅等人系統是運用人工智能和專家系統的設計原理與方法,模擬醫學專家診斷、治療疾病的思維過程,開發相關程序,幫助醫生解決復雜的醫學問題,作為醫生推斷疾病的重要依據。
給我們提供了很多啟示,但也有不足之處:第一,人工智能在心血管疾病的相關研究較少;第二,多數文獻結果顯示預測的精度不夠高。結合許多醫療和研究機構的經驗,本論文使用年齡,膽固醇水平、血壓、空腹血糖等10項指標來預測患者的心臟病情況,針對人工智能在心臟病的應用等方面對現有問題進行研究并且對已有的成果提出部分不足之處。
2 數據獲取
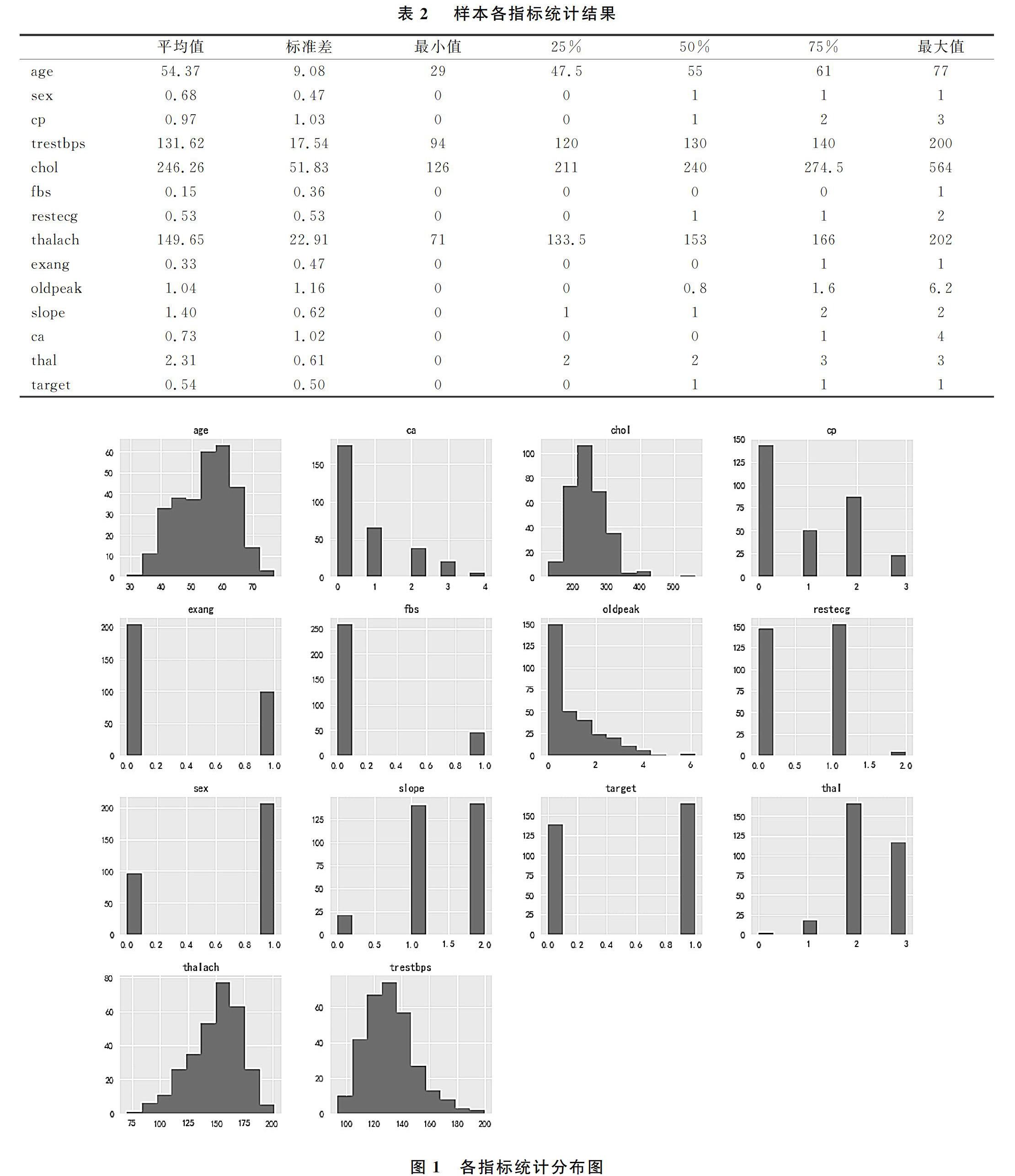
本文的數據來源UCI開源數據集,具體參考網址http://archive.ics.uci.edu/ml/datasets/Heart+Disease,針對美國某區域的心臟病檢查患者的體測數據,總共樣本個數為303,包括患有心臟和不患心臟病的樣本。對數據進行分析,結果如表1所示。對表格進行分析,發現樣本中年齡最小29歲,最大77歲,平均值54.37,以老年人居多,性別上以男性居多,膽固醇在二百到三百之間發病率高,心率異常易導致發病,最大心率在150到175間發病率高;最大心跳在150到175間發病率高;血壓在120到140時發病率高,指標為10個,解釋如表1,統計結果如表2和圖1。
3 模型介紹
3.1 決策樹模型
決策樹是人工智能中用來分類的常用方法,包括了幾個重要的關鍵詞:根節點、父節點、子節點和葉子節點等。決策樹在多分類和二分類問題中有很好的應用,可以用多種標準來評價和優選方案,給出最優結果。該方法的特點是: 一方面,由于要解決的問題的目標和標準的不同,比較方案的好壞比較難,因此找不到問題解決的最佳方案;另一方面,解決問題的決策過程中是隨機的,根據問題的滿意度作為標準。
決策樹常常采用貪婪思想的方法對各個因子進行分裂,也就是說,可以尋找找到最優分裂結果,進行決策樹的分裂。評價最優的分裂結果可能有多種方法,最理想的情況是能找到一個屬性剛好能夠將不同類別分開,但是實際情況下,只通過一次分裂很難一步到位,但是我們希望每一次分裂之后剩下的節點的數據盡可能清晰,決策樹使用信息增益或者基尼值作為選擇屬性的依據。
信息可以表示屬性的分裂前和分裂后的數據復雜度和分裂節點數據復雜度,他們之差作為信息增益的變化情況,信息增益的計算公式如下:
其中,式中Gain表示節點的復雜度,信息數值越大,說明復雜度越高。信息增益分裂后的復雜度減小越多,分類效果越明顯。
基尼值也可以表示屬性信息變化的基本情況,基尼值計算公式如下:
式子中年Pi表示第i個類的數量占比。如果只有兩類的情況下,當兩類數量相等時,基尼值等于0.5 ,當節點數據只有一類時,基尼值數值等于0 。這表明,基尼值越大,數據越不純,越需要分類。決策樹構建的基本方法分為三個步驟:
第一步,根據決策樹的輸出結果,將決策樹分為兩類,分別是分類樹和決策樹。分類樹輸出的結果為具體的類別,而回歸樹輸出的結果是確定的數值。在本課題中,因為要將病人分為患病和不患病兩類,所以構建的是分類樹。
第二步,決策樹的構建算法主要有ID3、C4.5、CART三種,其中ID3和C4.5是分類樹,其中ID3是決策樹最基本的構建算法,而C4.5是在ID3的基礎上進行優化的算法。因此,本文選擇C4.5作為基本算法。
第三,對決策樹的優化。復雜的決策樹可能出現過擬合等情況,可能會出現預測結果不準確的情況,因此要對決策樹進行優化,優化的方法主要有兩種:一是剪枝;二是組合樹。
3.2 隨機森林
決策樹具有泛化能力弱的缺點,有時候預測結果并不精確,即使有剪枝等方法。一棵樹做決策顯然比不上多棵樹同時做決策,這種方法就是隨機森林模型。對于同一批數據,用相同的算法只能產生一棵樹,但是Bagging策略可以產生不同的數據集,包含的數據是隨機的。Bagging策略全程叫作bootstrap aggregation,假設樣本集中含有N個數據點,通過重采樣的方法選出N個樣本。在抽樣的過程中,采用的是有放回的采樣的方法,所以總體的樣本數據的個數一直是N個。在所有樣本上,對這n個樣本建立隨機樹分類器,重復上述采樣和構建決策樹方法m次,那么就獲得了m個分類器。最后根據這m個分類器的投票結果,少數服從多數的原則,最終能決定數據的分類情況。隨機森林的一般步驟是:
第一步,對樣本進行隨機抽樣,隨機選取n個樣本。
第二步,特征的隨機:從所有屬性中隨機選取f個屬性,選擇最佳分割屬性作為節點建立決策樹。
第三步,重復以上m次,即建立了m棵決策樹分類器。
第四步,這m個形成隨機森林,通過每棵樹的結果分析,投票表決決定數據分類情況。
4 結果分析
我們采用7∶3的訓練集和測試集分配樣本數據,根據模型介紹,調試支持決策樹和隨機森林模型。正確率和召回率是評價模型好壞的重要指標,一般定義如下:正確率為提取出的正確信息條數除以提取出的信息條數 召回率為提取出的正確信息條數除以樣本中的信息條數。
模型的正確率越高越好,召回率也越高越好,但事實上這兩者在某些情況下是矛盾的。F1值是加權調和平均。當這個結果較高時,說明方法實驗有效。在本文中兩個模型計算得到的正確率,召回率和F1值,計算時間如表3。
比較分析發現隨機森林方法在正確率,召回率,F1值等方面都優于支持向量機方法。因此,可以采用隨機森林方法輔助心臟病醫療診斷。
5 結論
人工智能在醫療領域有很大的發展,本文運用決策樹和隨機森林等模型,分析了人工智能在心臟病診斷上的優點和不足之處,并給出精確度和準確率。根據我們分析的結果,在心臟病患者做出如下建議:一方面,人民自身不吸煙,維持體重指數正常,有時間多體育鍛煉達標及飲食健康,減少血糖指數等指標減少罹患心血管疾病的危險因素。另一方面,政府可以普及心血管疾病預防知識。尤其對于心血管疾病的治療,中國雖然擁有先進的技術,但是預防宣傳并不到位,這導致國人對心血管疾病的知識嚴重不足。進一步,提出相關政策,如鼓勵戒煙、推廣健康飲食和提倡運動等。可以效仿世界衛生組織,擬定低成本的干預措施來幫助發展中國家預防和控制心血管疾病,如降低暴露在污染的環境中也能促進心血管的健康功能。此外,希望相關醫院進一步發展醫療技術,加強對心臟病和其他慢性病患者的醫療管理,甚至對歸家的患者配備了專門設計的數據采集和患者參與系統,實現最佳疾病管理支持。
參考文獻
[1]于觀貞,劉西洋,張彥春,等.人工智能在臨床醫學中的應用與思考[J].第二軍醫大學學報,2018,39(4):358-365.
[2]基于人群搜索-支持向量機的心臟病多生理參數診斷方法研究[D].天津:河北工業大學,2015.
[3]醫學知識工程生產線與基于人工神經網絡和遺傳算法的醫學決策支持系統的研究[D].重慶:重慶大學,2003.
[4]高奇琦,呂俊延.智能醫療:人工智能時代對公共衛生的機遇與挑戰[J].電子政務,2017,(11):11-19.
[5]方煒煒,楊炳儒,楊君,等.基于隱私保護的決策樹模型[J].模式識別與人工智能,2010,23(6):766-771.
[6]劉永春.基于隨機森林的乳腺腫瘤診斷研究[J].電視技術,2014,38(15):253-255.
