基于預訓練模型和詞嵌入的CNN情感分類方法
2020-01-27 02:26:49翟高粵
錦繡·中旬刊 2020年8期
關鍵詞:深度學習
翟高粵
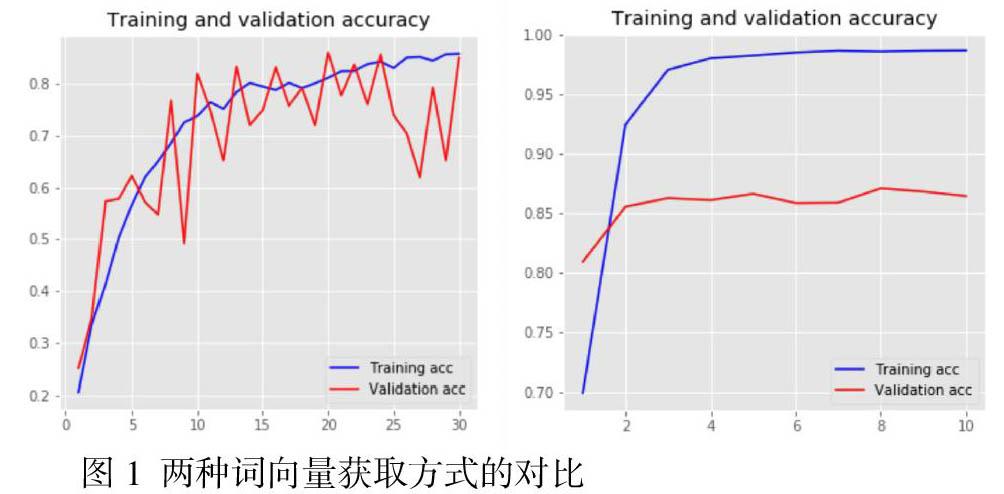
摘要:針對one-hot詞嵌入技術無法表述相關詞之間的語意和關系的問題,提出一種基于預訓練模型的詞嵌入(GloVe)和CNN神經網絡相結合的情感分類方法。首先,讀取要分類的語料并加載中文預訓練詞向量模型;然后使用TensorFlow進行數據預處理,生成訓練集和測試集;最后定義兩種詞嵌入矩陣并構建CNN模型進行對比。實驗結果表明,使用預訓練模型的詞嵌入方法比自定義訓練的方式能進行更好的情感分類
關鍵詞:詞嵌入;深度學習;卷積神經網絡;情感分類
中圖分類號:TP183:文獻標識碼:A
0 引言
情感分析是從自然語言中識別人的態度的一種人工智能方法,現在有很多人通過社交網絡服務、博客、在線評論和社區網站上面發表他們的觀點或看法。由于很多用戶在網絡上表達自己的情感,因此研究人員可以通過分析現實世界中的情感來了解社會輿論。
1 相關概念
1.1 卷積神經網絡(CNN)
CNN模型在計算機視覺處理中獲得了很大的成功。它由輸入層、卷積層、池化層和完全連接層組成。輸入層主要輸入原始像素值的圖像,包括RGB通道。在卷積層中,通過滑動窗口(過濾器)來捕獲像素的局部特征。在池化層中,局部小平移具有不變性的特點,并通過子抽樣的方法減小了參數維數。在全連接層中,把高維度圖像進行平展后進行分類。
1.2 詞嵌入技術(Word-Embedding)
為了數字化輸入的單詞,我們可以使用k個編碼向量(由若干個0和一個1組成)中的1(one-hot)來表示一個單詞,這種方法非常簡單,但無法表達單詞之間的關系。為了能表達單詞之間的關系,我們通常使用詞嵌入方法,這是一種降維技術。詞嵌入方法就是把每個單詞矢量化表示。它由密集且維數較低的k維向量表示。研究表明,語義相近的詞向量在向量空間中距離很近,反之語義差距大的詞向量在向量空間距離較遠。目前,許多關于自然語言處理(NLP)的研究都使用預訓練詞向量。
使用預訓練的詞嵌入,在數據集較小的情況下,難以學習到足夠好的embedding層,選擇一些權威的官方詞嵌入數據庫(比如GloVe)能夠有效解決數據集的問題。GloVe的全稱叫Global Vectors for Word Representation,它是一個基于全局詞頻統計(count-based & overall statistics)的詞表征(word representation)工具,它可以把一個單詞表達成一個由實數組成的向量,這些向量捕捉到了單詞之間一些語義特性,比如相似性(similarity)、類比性(analogy)等。我們通過對向量的運算,比如歐幾里得距離或者cosine相似度,可以計算出兩個單詞之間的語義相似性。
1.3 情感分類
情緒分類的目的是識別給定句子(或文檔)的情緒極性(積極或消極)。傳統分類方法大致可以分為基于詞典的分類方法和基于深度學習的分類方法。基于詞典的方法通過人工的方法來提取語言特征。例如,通過在詞典中標注每個單詞的情感極性就被當作語言特征。另一方面,深度學習方法具有自動地從原始數據中學習表示的能力。基于深度學習的方法自動從原始文本輸入中提取特征,并使用它們對情緒極性進行分類。因此,基于深度學習的方法在情緒分類任務中越來越受到研究人員的歡迎。
2 數據預處理(定義詞嵌入矩陣)
2.1 數據集介紹
本文使用的是IMDB電影評論數據集,該數據集是用于情感分析的國際標準數據集之一。數據集收集了大約50000條的評論,其中訓練集25000條,測試集25000條。對于預訓練詞嵌入,本文使用的是GloVe。
2.2 讀取語料
打開語料文件,把原始語料劃分為訓練數據和測試數據,把文本信息讀取到texts列表中,標簽信息讀取到labels中,其中文本信息需要使用預處理詞嵌入技術進行處理,標簽信息本文使用one-hot進行表示。
2.3 加載預訓練詞向量模型
本文采用的詞向量是一個稠密向量,可以理解為將文本的語義抽象信息嵌入到了一個具體的多維空間中,詞之間語義關系可以用向量空間中的范數計算來表示。
下載GlOve,進行解壓之后的中文預訓練詞向量模型的文件格式是文本文件,首行只有兩個空格隔開的數字:詞的個數和詞向量的維度,從第二行開始格式為:詞 數字1 數字2 …… 數字300,形式如下:
364180 300? [首行]
china 0.003146 0.582671 0.049029 -0.312803 0.522986 0.026432 -0.097115 0.194231 -0.362708
以上364180表示的是詞的個數,300表示的詞的維度,即一個詞用300維的數字進行表示,”中國”使用了300維的向量進行表示。
2.4 使用tf.keras對語料進行處理
tf.keras是tensorflow中集成的keras處理模塊,通過tf.keras可以直接調用keras中的各種功能。本文將使用tf.keras中的Tokenizer對語料文本進行處理,每個向量等于每個文本的長度,這個長度在處理的時候由變量MAX_SEQUENCE_LEN(最大句子長度)做了限制,其數值并不表示計數,而是對應于字典tokenizer.word_index中的單詞索引值,這個字典是在調用Tokenizer時產生。
長度超過MAX_SEQUENCE_LEN的文本序列會被截斷,長度小于這個值的文本序列則需要補零來達到這個長度,可以使用tf.keras中的pad_sequence()就是用零來填充向量序列。例如:對[1,2,3,4,5,6,7,8],[6,7,8,9],用maxlen=6進行長度的截斷,結果如下:
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
