基于深度確定性策略梯度的智能車匯流模型
2020-01-16 07:32:18吳思凡徐世杰
計算機工程 2020年1期
吳思凡,杜 煜,徐世杰,楊 碩,杜 晨
(北京聯合大學 a.智慧城市學院; b.機器人學院; c.北京市信息服務工程重點實驗室,北京 100101)
0 概述
車流匯入是實際行駛中的常見情況,也是目前智能車研究中的熱點問題。由于智能車的決策系統不能較好地應對車流匯入的情況,因此多數解決方案是等待主路行駛車輛通過后再執行下一步動作,如何在適當的時機匯入始終是研究者關注的重點。
隨著機器學習在智能車領域的不斷發展,一些機器學習算法也逐漸被應用于解決車流匯入問題。文獻[1]建立了基于分類回歸樹的無人車匯流決策模型,但該模型需要數據標注,并且只能根據瞬時數據進行決策,不具備有效預測周圍環境的能力。文獻[2]建立了基于貝葉斯網絡的匯入行為預測模型,該模型屬于規則化模型,當環境中出現特殊情況時,匯入成功率較低。文獻[3]采用非參數支持向量機(Support Vector Machine,SVM)方法預測各種匯入行為,雖然此方法相比于其他機器學習模型匯入成功率更高,但仍然是監督學習,其學習過程是靜態過程,不能實現與環境的交互。
為彌補機器學習在智能車領域應用中存在的不足,研究者提出強化學習的概念。目前該技術已被成功應用于人工智能[4-5]、棋牌游戲[6]和分析預測[7]等方面,其中最為典型的代表為TD[8]、Q-learning[9]和SARSA[10],但這些算法都是針對離散狀態和行為空間的馬氏決策過程,即狀態的值函數或者行為的值函數采用表格的形式存儲和迭代計算[11]。如果狀態值太多,會出現占用內存增大的情況,導致效率降低。為此,研究者進一步提出解決方案。文獻[12-13]將卷積神經網絡與Q學習[14]算法相結合,建立了深度Q網絡(Deep Q-Network,DQN)模型[15]。文獻[16]以DQN算法為框架搭建智能車匯入模型,獲得了較高的匯入成功率,但該算法仍然采用離散動作空間,不能直接應用于連續空間,無法應對智能車實際速度控制變化。文獻[17]提出一種用于解決連續動作預測的深度強化學習算法DDPG,該算法可以在連續動作空間中運行,解決動作離散化會丟失動作域結構信息的問題。
本文采用深度確定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法建模,將智能車匯流問題轉化為序列決策問題進行求解,并通過仿真實驗與文獻[16]模型進行對比,驗證該模型在實際應用中的可行性和高效性。
1 基于DDPG算法的匯流模型
DDPG算法是研究者在Actor-Critic(AC)[18]算法框架的基礎上,使用DQN的經驗回放[19]方法和構造雙網絡結構的方法對確定性策略梯度(DPG)算法改進的一種深度強化學習算法,其用于解決連續動作空間下的馬氏序列決策問題。
在DDPG算法中,確定性策略被描述為在狀態st下采取的確定動作值at,動作值函數被描述為在狀態st中采取at之后的預期回報,分別使用參數為θμ和θQ的深度神經網絡來表示確定性策略a=π(s|θμ)和動作值函數Q(s,a|θQ)。
對Critic網絡而言,eval估值網絡通過θQ數化的函數逼近,使用最小化損失來更新參數,如式(1)所示。
L(θQ)=Est~ρβ,at~β,rt~E[(Q(st,at|θQ)-yt)2]
(1)
其中:
yt=r(st,at)+γQ(st+1,π(st+1,θμ))|θQ′)
(2)
eval估值網絡采用TD-error(梯度下降)進行更新:
(3)
對Actor網絡而言,eval估值網絡通過動作值函數將狀態映射到指定動作來更新當前策略,狀態回報定義為未來折扣獎勵總回報:
(4)
本文通過Silver策略梯度的方法[20]對目標函數進行端對端的優化,從而以獲得最大總回報為目的更新Actor網絡參數,如式(5)所示。
(5)
DDPG算法采用經驗回放方法對Actor-Critic雙網絡結構中的目標網絡參數進行更新,通過將四元組(st,at,rt,st+1)存儲在記憶庫中,指定時間間隔,調用記憶庫中的數據對目標網絡參數進行更新:
θQ′←τθ+(1-τ)θQ′
(6)
θμ′←τθ+(1-τ)θμ′
(7)
其中,τ代表更新參數。
結合本文的匯流模型,DDPG神經網絡結構如圖1所示。

圖1 DDPG網絡結構
為探索匯入車流最優動作,篩選出更好的策略,本文通過在隨機采樣過程引入隨機噪聲N,從而獲得at,如式(8)所示。
at=π(st|θμ)+N
(8)
其中,at的范圍限制為[-5.5 m/s2,2.5 m/s2]。
網絡中其他參數設置如表1所示。

表1 DDPG網絡參數設置
2 匯流仿真環境
2.1 道路環境
本文以2017年“中國智能車未來挑戰賽”無人駕駛智能車真實綜合道路環境測試(城市道路)中一段匝道匯入口為對象,構建匯流仿真環境。該路段行車方向由南向北,其中主路分為3個車道,匝道為一個車道。主路實際長度約為700 m,每條車道實際寬度為3.75 m,主路限速為80 km/h,輔路限速為60 km/h。為簡化仿真環境,消除一些無用信息,本文提取70 m主路道路作為仿真環境,如圖2所示,其中匯入路口距初始位置約30 m。其他道路環境參數如表2所示。
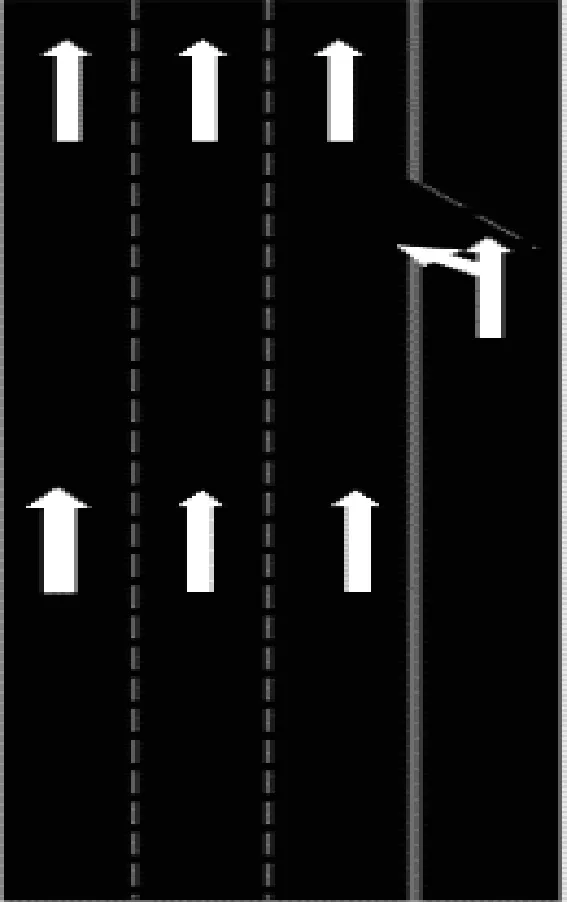
圖2 道路仿真環境
表2 匯流環境參數設定
Table 2 Traffic merging environment parameter setting

環境參數參數值主路長度/m700.00主路限速/(km·h-1)80.00匝道限速/(km·h-1)60.00主路最低限速/(km·h-1)10.80車道寬度/m3.75匯入口寬度/m6.00環境刷新周期/s0.10
2.2 仿真車輛建模
本文以北京聯合大學研發的“京龍六號”作為環境車(主路車)與代理車(匝道匯入車)進行建模,如圖3所示。“京龍六號”自改裝于北汽ex260轎車,車身長度約為4.1 m,車身寬度約為1.8 m,車頂配置32線激光雷達和GPS天線,車頭安裝4線激光雷達和毫米波雷達,后備箱裝有車載導航系統。

圖3 “京龍六號”實車
本文假設環境車輛只在車道3的主路行駛,車道1、車道2沒有車輛行駛,代理車通過匝道入口時,匯入車道3,并且代理車的行駛軌跡按照制定的軌跡行駛,如圖4所示。
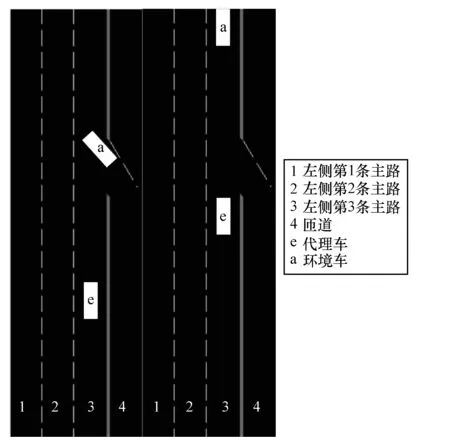
圖4 匝道環境示意圖
2.3 約束條件
根據對匯流情況的研究,本文將匯入狀態分為加速和減速2種狀態,采用與文獻[14]相同的狀態四元組空間進行描述:s=(車輛橫向間距,車輛縱向間距,代理車車速,環境車車速),橫/縱距離=環境車輛重心到代理車輛重心的距離(假設車輛的密度是均勻的),其中車輛橫向距離、縱向距離由雷達數據所得,動作空間a用來描述車輛在行駛過程中瞬時加速度。加速度采用“京龍六號”實車測量數據,范圍為[-5.5 m/s2,2.5 m/s2]。為使車輛在保證安全的情況下盡快匯入主路,采取單步懲罰-0.1。車輛碰撞條件為當車輛橫向距離小于2.2 m,縱向距離小于安全值,安全值計算公式為:
(9)
其中,v1為環境車車速,v2為代理車車速,D為最小反應距離,D取值2.0 m。環境車車速和代理車車速由車輛傳感器數據測得。
3 仿真與結果分析
本文將車輛匯入模型轉換為在代理車(匝道車)與環境車(主路車)狀態完全可觀察下通過DDPG算法采取適當的匯入動作問題。在每步(時間間隔為0.1 s)代理車通過傳感器接收觀測值s(包括車輛橫向間距、車輛縱向間距、代理車車速、環境車車速),采取動作a(加速匯入/減速匯入),并獲取獎勵r,經驗池數據為(s,a,r,s_),其中s_表示下一步狀態值。
模型建立后,本文根據現實過程中主路車輛行駛狀態,即加速行駛、減速行駛、勻速行駛對模型進行訓練。根據主路車輛行為,代理車輛采取相應的對策。實驗環境采用python3.6進行環境模型建立,使用Tensorflow搭建神經網絡框架進行回合訓練,最大回合數為5 000回合。同時,為加快訓練速度,對于強化學習算法每個回合探索的最大步驟進行限制,限制值為200步。
3.1 訓練與測試結果分析
訓練主要驗證在車輛匯入時代理車輛是否學習到應對環境車輛車速變化所采取的匯入對策。通過每100回合記錄在訓練過程中匯入成功率描述該模型在應對不同環境車速時采取策略是否可行。
應對現實過程中主路車輛速度變化,本文將環境車速度變化分為勻速行駛、勻加速行駛和勻減速行駛3種主路車速度變化狀態,環境車速度分為以下3種情況(車輛初始位置距匯入口30 m處)。
1)代理車輛初速度定為12 m/s(43.2 km/h)~15 m/s(54 km/h)內某個隨機值,環境車初速度為12 m/s(43.2 km/h)~15 m/s(54 km/h)內某個隨機值,訓練結果如圖5所示。
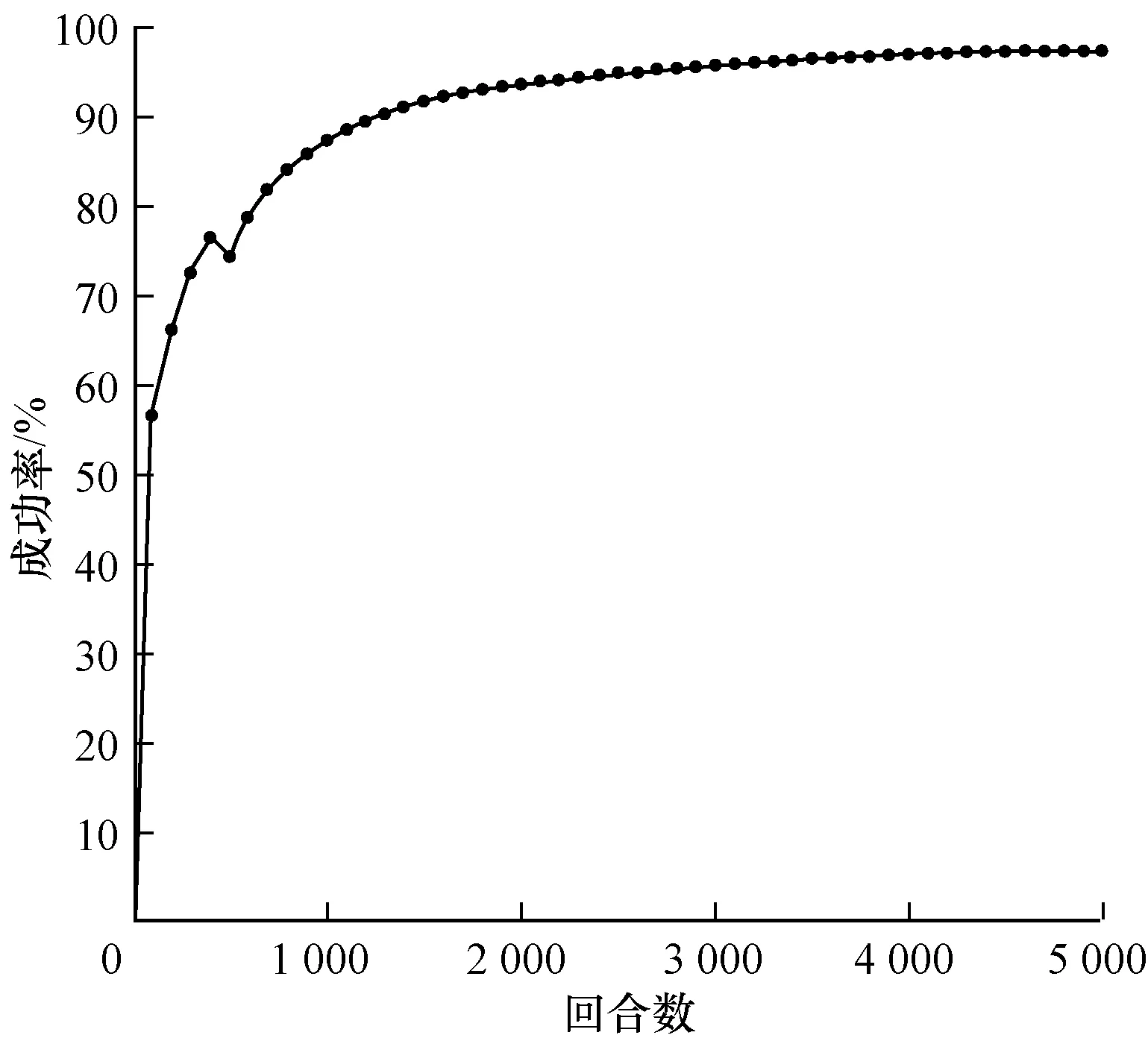
圖5 環境車勻速行駛匯入成功率
Fig.5 Merging success rate of main-road vehicle at a constant speed
2)代理車輛初速度定為12 m/s(43.2 km/h)~15 m/s(54 km/h)內某個隨機值,環境車初速度為12 m/s(43.2 km/h)~15 m/s(54 km/h)內某個隨機值,且加速度選取(0,2.5 m/s2]內某個隨機值,訓練結果如圖6所示。
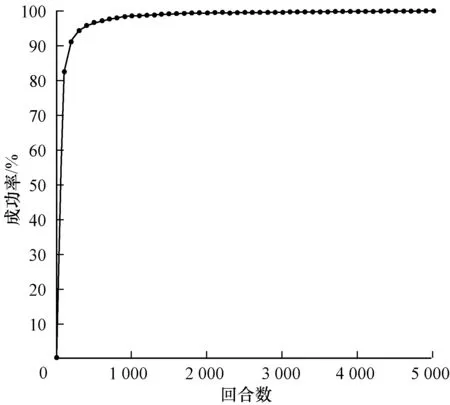
圖6 環境車勻加速行駛匯入成功率
Fig.6 Merging success rate of main-road vehicle with uniform acceleration
3)代理車輛初速度定為12 m/s(43.2 km/h)~15 m/s(54 km/h)內某個隨機值,環境車初速度為12 m/s(43.2 km/h)~15 m/s(54 km/h)內某個隨機值,且加速度選取[-5.5 m/s2,0)內某個隨機值,訓練結果如圖7所示。
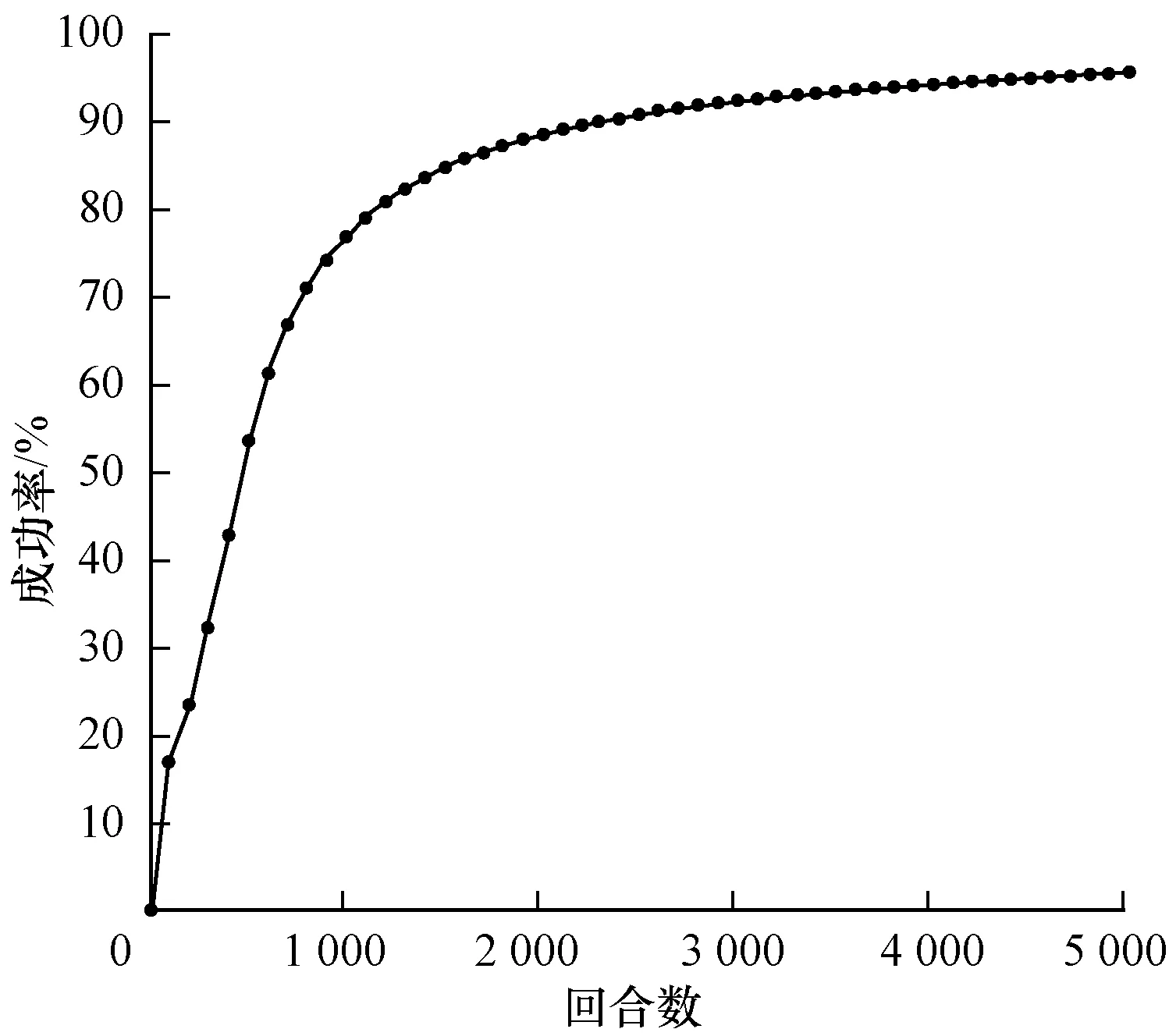
圖7 環境車勻減速行駛匯入成功率
Fig.7 Merging success rate of main-road vehicle with uniform deceleration
在環境車勻速行駛狀態下,車輛碰撞在500回合以后不再發生,模型達到收斂,并最終在5 000回合時成功率達到95%。在環境車做勻加速行駛的狀態下,車輛匯入模型在前100回合時匯入效果已十分理想,并且最終成功率接近100%,在環境車做勻減速行駛的狀態下,在前500回合成功匯入成功率不足45%,經過訓練,在5 000回合時,匯入成功率達到95%。
實驗測試3種不同環境加速度(-1.8 m/s2、0、2 m/s2)下代理車決策行為,測試結果如表3所示。
表3 不同環境車速下的測試結果
Table 3 Test results of main-road vehicle with different speeds

環境車車速代理車決策行為勻速行駛先減速后加速匯入以2 m/s2勻加速行駛減速匯入以-1.8 m/s2勻減速行駛加速匯入
當環境車輛勻減速行駛時,代理車為盡快匯入,采取的策略是不等待環境車通過匯入口后再通過,而是全程加速通過。當環境車在主路勻速行駛時,由于兩車的初始速度幾乎相同,在保證安全的情況下,此時代理車學習到的策略是先減速行駛,在保證一定安全距離后加速匯入。在環境車做勻加速行駛時,此時代理車為了安全匯入,不發生車輛碰撞,學習到的策略是減速匯入,等到環境車通過匯入口后,再匯入車流。
3.2 與文獻[16]模型的實驗結果對比
文獻[16]利用DQN算法通過離散動作空間描述動作變化狀態,使用單一目標網絡儲存參數產生目標Q值,并利用單估值網絡產生單估值Q值,根據兩者差異通過梯度下降更新網絡參數。
對本文模型與文獻[16]模型采用相同的四元組空間描述狀態、環境參數以及網絡訓練參數。加速度變化范圍為[-5.5 m/s2,2.5 m/s2],分別對3種環境車速度變化(勻速、勻加速、勻減速)進行對比,對比結果如圖8~圖10所示。
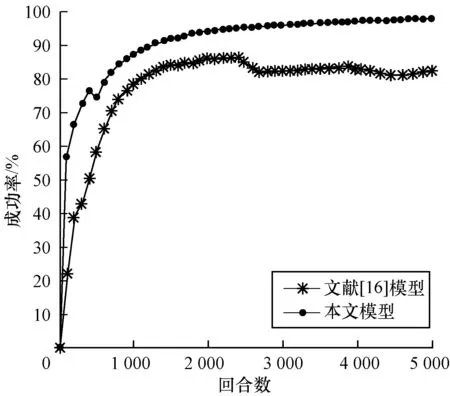
圖8 環境車勻速行駛時的匯入成功率對比
Fig.8 Merging success rate comparison of main-road vehicles at a constant speed
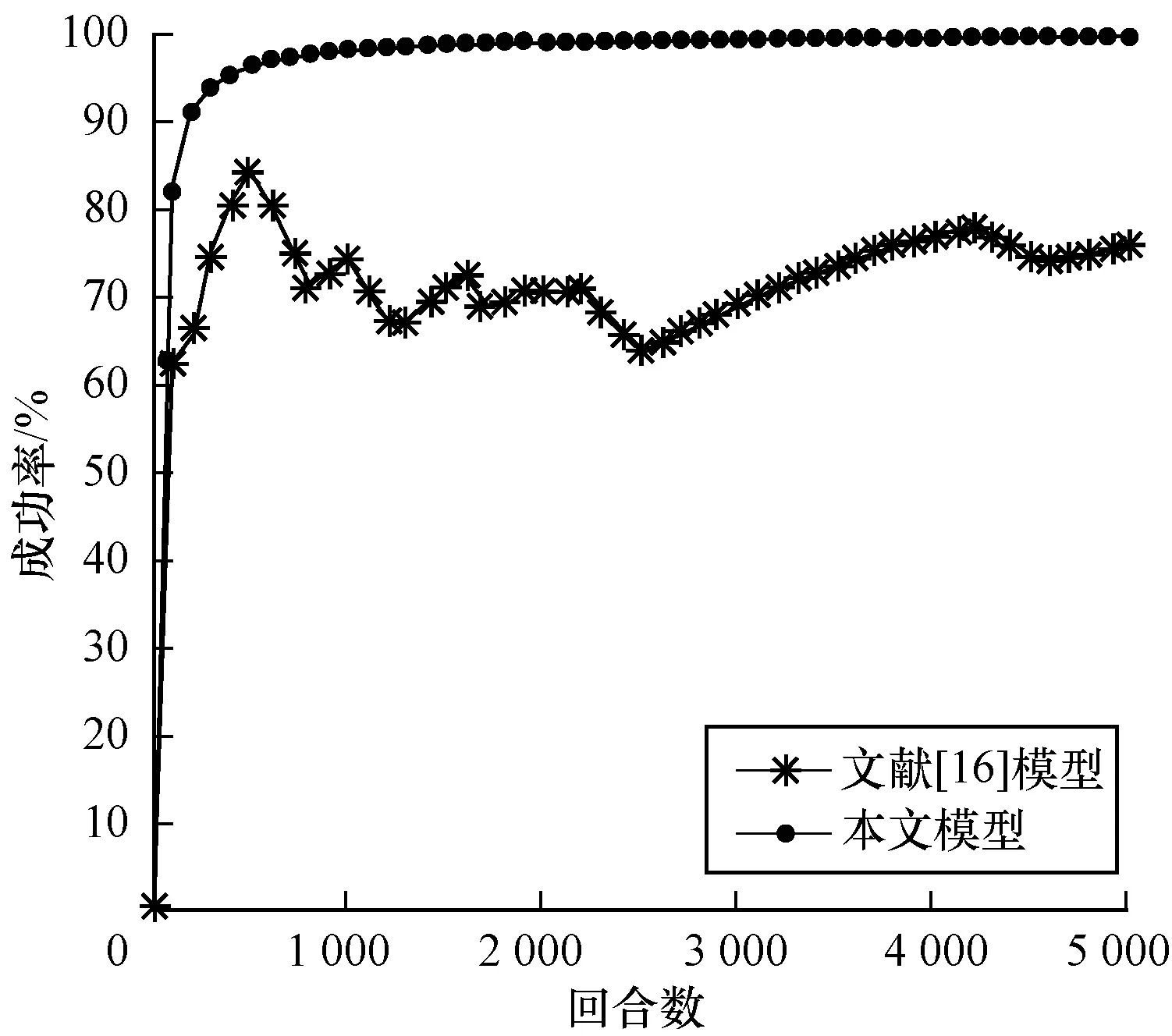
圖9 環境車勻加速行駛時的匯入成功率對比
Fig.9 Merging success rate comparison of main-road vehicles with uniform acceleration

圖10 環境車勻減速行駛時的匯入成功率對比
Fig.10 Merging success rate comparison of main-road vehicles with uniform deceleration
3種環境車速下最終完成訓練時的匯入成功率如表4所示。從中可以看出,DDPG匯入車流模型在3種行駛情況下可以以較高的成功率匯入車流。訓練完成時,成功率都能達到95%以上,說明該模型收斂速度快且穩定。在環境車勻速行駛、加速行駛中匯入成功率分別為97.42%和99.64%,分別超出DQN匯入模型成功率15.5%和23.68%;在環境車減速行駛中匯入成功率為95.34%,超出DQN匯入模型成功率1.02%。
表4 完成訓練時的匯入成功率對比
Table 4 Merging success rate comparison at the end of training%
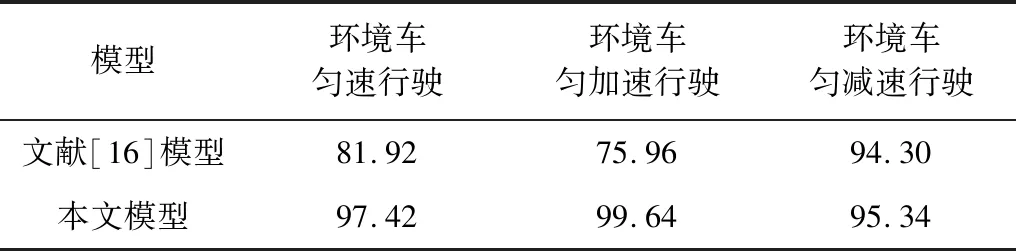
模型環境車勻速行駛環境車勻加速行駛環境車勻減速行駛文獻[16]模型81.9275.9694.30本文模型97.4299.6495.34
4 結束語
本文構建基于連續動作空間DDPG算法的智能車匯流模型,并將其與基于離散空間DQN的模型進行對比。仿真結果表明,該模型的匯入成功率較高。DDPG易于收斂,學習效果穩定,能夠提高智能車在匯入過程中的智能化水平,相比于離散動作空間的DQN算法更適合智能車匯入場景的應用。下一步將優化本文模型,使其具有較強的泛化能力并且適用于多車復雜環境。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2020年6期)2020-02-01 06:28:50
中國生殖健康(2019年11期)2019-01-07 01:28:02
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
