一個輕量級分布式機器學習系統(tǒng)的設計與實現(xiàn)
2020-01-16 08:24:30宋匡時張士波
計算機工程 2020年1期
宋匡時,李 翀,張士波
(1.中國科學院 計算機網(wǎng)絡信息中心,北京 100190; 2.中國科學院大學 計算機科學與技術(shù)學院,北京 100190)
0 概述
隨著互聯(lián)網(wǎng)信息處理技術(shù)的迅速發(fā)展,社會生活越來越多地依托于互聯(lián)網(wǎng)平臺服務,互聯(lián)網(wǎng)因此積累了大量實體與行為數(shù)據(jù)。機器學習作為一種從數(shù)據(jù)中挖掘模式特征和模式關聯(lián)的重要工具,在應用于精準推薦、文本相關性判別、語音識別、人臉識別等場景時能夠創(chuàng)造巨大的社會價值與商業(yè)利益。
同時,互聯(lián)網(wǎng)技術(shù)的高速發(fā)展也對機器學習模型訓練的速度要求越來越高。一方面,在產(chǎn)業(yè)應用中,更快的模型訓練意味著能提升模型時效性,更快捕捉到短期用戶行為喜好的變化,也能解決超大模型訓練問題;另一方面,在一些前沿研究領域中,神經(jīng)網(wǎng)絡架構(gòu)搜索(Neural Network Architecture Search,NAS)需要隨機采樣大量不同超參數(shù)以及神經(jīng)網(wǎng)絡架構(gòu)的訓練效果作為NAS的訓練樣本。對于模型訓練加速問題,目前主要有2種解決方式:一種是通過等價數(shù)學變換、稀疏量化、低精度訓練方法降低計算的復雜度;另一種是組合若干個計算節(jié)點的資源,實現(xiàn)可擴展的模型存儲與訓練加速,最大化計算硬件的利用率,代表性的工作有參數(shù)服務器理論[1]與環(huán)拓撲All-Reduce[2]。在異步梯度下降方面,文獻[3]證明了凸函數(shù)無鎖并行隨機梯度下降的收斂性,文獻[4]證明了與SSP半同步的異步梯度下降的收斂性;在All-Reduce方面,研究者提出了層次化All-Reduce與大批量訓練加速方法,并使用PCIe/NVLink[5]、多網(wǎng)卡、RDMA[6]提高物理通信效率。之后又出現(xiàn)大量大規(guī)模機器學習的研究[7]。
目前大規(guī)模機器學習成為機器學習算法與分布式系統(tǒng)的交叉研究領域,機器學習系統(tǒng)也正向細分領域高定制化的方向發(fā)展。現(xiàn)有的主流機器學習系統(tǒng)大多由國外一線互聯(lián)網(wǎng)公司開發(fā),如Google的Tensorflow[8]、Facebook的PyTorch[9]以及Amazon的MXNet[10],其側(cè)重面向高性能設備的機器學習任務,對不同硬件指令做了大量的適配優(yōu)化工作,不可避免地造成項目依賴復雜、調(diào)試困難、對內(nèi)存資源消耗較高以及在多機擴展尤其是資源受限集群的分布式機器學習任務上穩(wěn)定性不足的問題,在涉及高定制化、計算資源受限設備情況下,二次開發(fā)與定制非常復雜且不可控,新增、修改與定制化功能也十分困難,這催生了眾多研究機構(gòu)與公司針對自身需求開發(fā)各類高定制化機器學習與深度學習系統(tǒng)[11],設計滿足基本生產(chǎn)環(huán)境要求的輕量級、低資源占用、容錯措施靈活的高性能機器學習系統(tǒng)成為迫切需要。
本文設計一個輕量級高模塊化并且可擴展的機器學習系統(tǒng),移植并優(yōu)化實現(xiàn)多種主流機器學習與深度學習算法,同時設計參數(shù)服務器與環(huán)拓撲All-Reduce分布式梯度同步方案,對算法模型進行并行訓練加速,以提高數(shù)據(jù)并行訓練的效率與穩(wěn)定性。
1 模塊化分層設計
為滿足輕量級系統(tǒng)的設計要求,本文將系統(tǒng)劃分為計算層、梯度同步層與通信層,層內(nèi)為可獨立拆分的功能模塊與工具模塊,功能封裝為編程對象。圖1展示了系統(tǒng)內(nèi)的主要模塊設計,其服務于算法移植與分布式模型訓練。其中:計算層包括提高并行度的線程池與SIMD指令,用于提高算法模塊計算性能;梯度同步層包括不同同步方式處理邏輯與共享內(nèi)存哈希表、進度動態(tài)控制模塊等;通信層包括網(wǎng)絡I/O模塊、多線程控制、消息隊列等。這樣的分層設計避免了循環(huán)依賴的耦合問題,一個功能調(diào)用僅需引入調(diào)用鏈上必要的模塊,模塊代碼剝離方便清晰,可避免無關內(nèi)存占用。
在精簡外部依賴上,本文選取目前網(wǎng)絡傳輸吞吐量較高、跨平臺且輕量級的網(wǎng)絡框架ZeroMQ作為系統(tǒng)的網(wǎng)絡通信底層,上層則進一步抽象消息發(fā)送隊列、重發(fā)線程、事情循環(huán)等基礎網(wǎng)絡功能,輕量且低資源消耗地為整個系統(tǒng)提供異步非阻塞的高吞吐量消息發(fā)送與接收處理能力。
本文系統(tǒng)在深度學習方面使用基于層與計算單元的模塊化設計模式,優(yōu)點在于能夠集中控制內(nèi)存的占用,功能層次簡單。系統(tǒng)各模塊按照訓練階段劃分,提供對初始化、訓練、梯度同步、預測等階段統(tǒng)一的調(diào)用接口,方便對訓練過程進行控制與干預。
2 算法移植與實現(xiàn)
輕量級設計在降低資源消耗同時也應保持系統(tǒng)的高性能與實用性,本文系統(tǒng)移植并深度優(yōu)化實現(xiàn)了主流機器學習與深度學習算法,可應用于推薦、點擊率預估場景下的群體發(fā)現(xiàn)、行為序列分析、文本內(nèi)容分析等任務。表1列出了目前已經(jīng)移植實現(xiàn)的算法,通過SIMD向量指令、指令流水線、多核多線程、異步文件I/O多重加速最大化單機CPU計算能力,利用內(nèi)存復用與預取節(jié)約內(nèi)存并降低cache miss,用對凸優(yōu)化友好的無鎖多線程計算,大幅提高算法的運行效率。設計中考慮了模塊化與可擴展性,對同類算法進行了統(tǒng)一抽象封裝,很容易就可以將這些算法模塊組合,實現(xiàn)將線性模型與深度模型組合的Neural factorization machines[12]、Wide & Deep[13],以及將變分貝葉斯與深度模型進行組合的Variational AutoEncoder[14]。同時也為數(shù)據(jù)并行訓練提供了梯度同步接口,對梯度內(nèi)存進行了統(tǒng)一管理,便于對梯度進行零拷貝分布式同步。
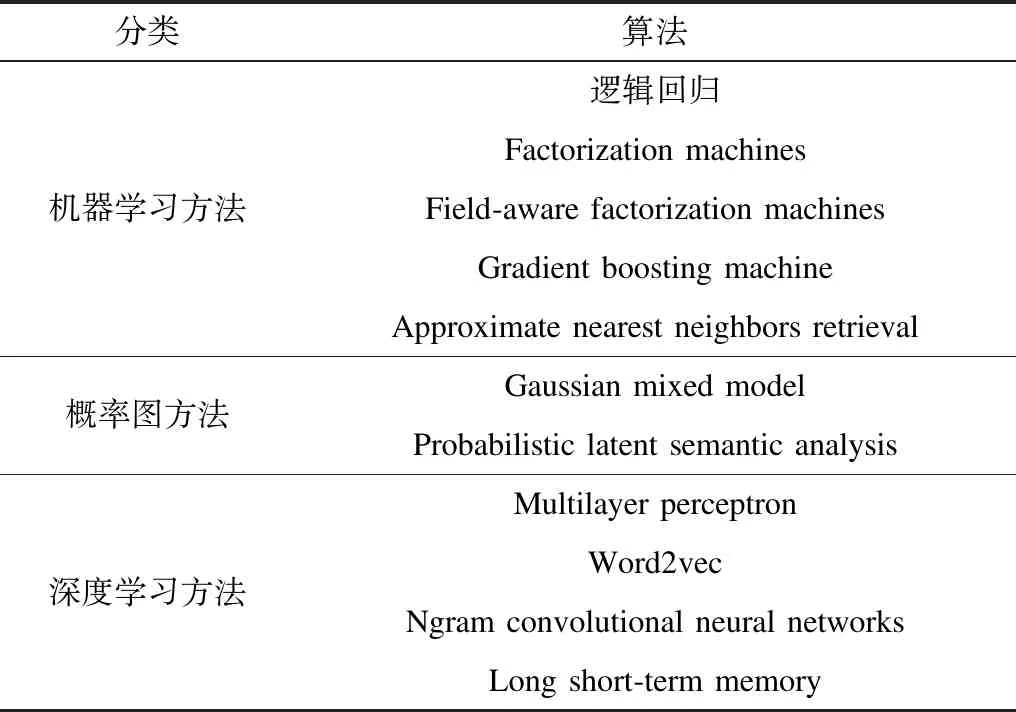
表1 移植實現(xiàn)的主流算法Table 1 Migrated and implemented mainstream algorithms
3 可擴展性系統(tǒng)設計
單機的訓練不能滿足大規(guī)模模型訓練的參數(shù)存儲與訓練加速需求,需要機器學習系統(tǒng)具有較強的可擴展性。本節(jié)介紹針對數(shù)據(jù)并行模型訓練的輕量級、高擴展性系統(tǒng)設計。
3.1 可擴展性設計的性能模型
數(shù)據(jù)并行的機器學習梯度同步方法按集群拓撲結(jié)構(gòu)主要分為主從結(jié)構(gòu)(又分一主多從、多主多從)、樹結(jié)構(gòu)、環(huán)結(jié)構(gòu)。一主多從代表為Map-Reduce[15],多主多從代表為參數(shù)服務器,樹結(jié)構(gòu)代表為MPI All-Reduce,環(huán)結(jié)構(gòu)代表為Baidu提出的通過Ring-base的All-Reduce。
定義1令N為節(jié)點個數(shù),K為待同步的參數(shù)數(shù)量,H為同步梯度數(shù)據(jù)包大小,每個節(jié)點在一次同步中的通信次數(shù)為S,每字節(jié)傳輸?shù)暮臅r為ξ,梯度下降優(yōu)化參數(shù)的耗時為η,每次通信網(wǎng)絡數(shù)據(jù)包傳輸延時θ,則同步梯度過程中的數(shù)據(jù)傳輸耗時由數(shù)據(jù)包傳輸耗時與合并參數(shù)耗時組成,表示為:
Φ=S(Hξ+θ)+Kη
根據(jù)定義1可知,不同網(wǎng)絡拓撲組織方式直接影響H與S的取值,使用Adam[16]、FTRL[17]等不同的梯度優(yōu)化方法則影響η的取值。根據(jù)定義1,不同拓撲結(jié)構(gòu)下同步方案的數(shù)據(jù)傳輸耗時如表2所示。在一主多從情況下,每個節(jié)點只需與主節(jié)點一次通信傳輸全部參數(shù),傳輸耗時以主節(jié)點單網(wǎng)卡串行隊列瓶頸計算共收發(fā)KN個數(shù)據(jù);樹結(jié)構(gòu)用分治的方法降低為lbN;而多主多從是每個節(jié)點都即承擔計算也承擔局部參數(shù)存儲,既要向其他節(jié)點進行w-1次通信傳輸對應的局部參數(shù),也要接收來自其他節(jié)點的局部參數(shù),每個數(shù)據(jù)包大小為K/N;同樣地,環(huán)結(jié)構(gòu)由于基于鄰居節(jié)點的迭代同步方法需要2(N-1)次通信,每個數(shù)據(jù)包大小為K/N。
表2 不同拓撲結(jié)構(gòu)下的參數(shù)同步性能對比
Table 2 Comparison of parameter synchronization performance with different topologies

拓撲結(jié)構(gòu)數(shù)據(jù)包大小通信次數(shù)數(shù)據(jù)傳輸耗時一主多從K1KNξ+θ+Kη多主多從KNN-1(N-1)KξN+(N-1)θ+Kη樹結(jié)構(gòu)Klb N(Kξ+θ+Kη)×lb N環(huán)結(jié)構(gòu)KN2(N-1)2Kξ(N-1)N+2θ(N-1)+Kη
通過分析表2中傳輸耗時與節(jié)點個數(shù)N的關系可知,一主多從受限于單點瓶頸,傳輸耗時隨節(jié)點個數(shù)呈線性關系,樹結(jié)構(gòu)則呈對數(shù)關系,多主多從與環(huán)結(jié)構(gòu)呈更優(yōu)的倒數(shù)關系。僅從同步參數(shù)的傳輸耗時上分析,多主多從在參數(shù)同步過程中通信次數(shù)是環(huán)結(jié)構(gòu)的一半,但因為參數(shù)分布存儲,前向預測過程同樣需要N-1次獲取參數(shù)的通信,環(huán)結(jié)構(gòu)因為本身保存全量參數(shù)沒有此消耗,所以兩者在先前向后同步梯度的模型訓練任務上總傳輸耗時相近。
在實際的多主多從同步過程中,引入高網(wǎng)絡吞吐量的參數(shù)服務器作為只負責參數(shù)存儲的節(jié)點,通信次數(shù)只與參數(shù)服務器數(shù)量有關,降低了傳輸耗時,且參數(shù)服務器支持異步梯度下降,減少了輪次間的訓練依賴,并行度更高,因此,參數(shù)服務器方案被廣泛用于Tensorflow、PyTorch等成熟框架和可擴展性機器學習訓練任務。相比而言,環(huán)結(jié)構(gòu)的Ring-AllReduce可以充分利用所有計算節(jié)點來追求更高的訓練加速,由于梯度阻塞同步不會對訓練收斂性產(chǎn)生影響,P2P的分布式拓撲避免了熱點問題,因此常被用于計算機視覺等領域大批量訓練數(shù)據(jù)的梯度聚合,在超大GPU集群上僅需分鐘級別即可完成大規(guī)模模型訓練[18]。2種同步方案均有其優(yōu)勢與適合的模型訓練場景,因此,有必要分別設計參數(shù)服務器與環(huán)拓撲同步2種可擴展的模型訓練方式。
3.2 參數(shù)服務器設計
參數(shù)服務器適合于參數(shù)總量超過單機內(nèi)存的稀疏模型分布式訓練場景,本文設計的參數(shù)服務器同步方案如圖2所示,其中包括3個角色:一臺主節(jié)點(Master)負責協(xié)調(diào)集群啟動與廣播集群拓撲,對所有節(jié)點進行心跳檢測,出現(xiàn)節(jié)點異常時從拓撲中去除異常節(jié)點,自動重置拓撲結(jié)構(gòu);多臺參數(shù)服務器通過一致性哈希分布式放置模型總量特征參數(shù),滿足訓練過程中參數(shù)請求與梯度匯報的高吞吐處理需要;多臺計算節(jié)點(Worker)負責讀入訓練數(shù)據(jù)并執(zhí)行模型梯度計算。本文設計了適用于稀疏數(shù)據(jù)與稠密張量2種數(shù)據(jù)類型傳輸?shù)腜ull與Push協(xié)議,Worker在訓練過程中無狀態(tài)地向參數(shù)服務器Pull請求所需特征值后,向參數(shù)服務器Push匯報本輪計算的梯度值,由參數(shù)服務器將梯度信息進行篩選應用于隨機梯度下降優(yōu)化算法、并調(diào)控集群整體訓練進度。

圖2 優(yōu)化傳輸量與收斂性的參數(shù)服務器架構(gòu)
Fig.2 Parameter server architecture for optimizing transmission quantity and convergence
參數(shù)服務器同步方案的瓶頸是其在網(wǎng)絡傳輸高延遲與丟包情況下的無效與重復梯度問題,本文通過傳輸壓縮與約束梯度的方式對此加以改進。
3.2.1 網(wǎng)絡傳輸壓縮
考慮到此場景下為稀疏數(shù)據(jù)傳輸,本文采用稀疏編碼,由特征哈希的編號與浮點數(shù)值的鍵值對表示稀疏參數(shù)與梯度。通過變長整數(shù)壓縮特征編號,同時采用半精度浮點型壓縮傳輸?shù)奶荻戎怠T撛O計考慮到模型梯度值精度與訓練較為魯棒,且混合精度訓練可提升部分任務的效果,在提高傳輸數(shù)據(jù)壓縮率的同時,使模型可以在混合精度下訓練。通信底層借助高效的網(wǎng)絡通信傳輸模塊,滿足節(jié)點高吞吐量的要求。
3.2.2 無效與重復梯度問題
當Worker匯報給參數(shù)服務器的梯度落后于總體訓練輪次產(chǎn)生的無效梯度時,向多個Worker同時匯報相近的梯度方向,重復累計步長偏離最優(yōu)解下降方向,導致參數(shù)服務器的異步梯度下降很不穩(wěn)定。為此,通過Worker匯報給參數(shù)服務器輪次信息,設計了輪次間隔約束,其約束最快與最慢訓練輪次的計算節(jié)點訓練輪次間隔不大于一個閾值,當觸發(fā)輪次間隔約束時阻塞最新輪次Worker的參數(shù)拉取,控制了異步計算進度差異產(chǎn)生的無效梯度數(shù)量。此外,使用一階導的外積無偏估計二階導矩陣的方法DC-ASGD[19],補償延遲梯度。算法1與算法2分別描述了計算節(jié)點與參數(shù)服務器上的算法過程。
算法1計算節(jié)點
repeat
從參數(shù)服務器拉取批數(shù)據(jù)所需參數(shù)wt與step
repeat
計算參數(shù)梯度gm=fm(wt)
if 觸發(fā)輪次間隔約束 then
sleep若干毫秒,等待最慢節(jié)點
until 獲得全部所需參數(shù)
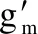
until forever
算法2參數(shù)服務器
輸入學習率η,方差調(diào)控參數(shù)λt,Step最大間隔閾值E
初始化t=0,w0隨機初始化,暫存參數(shù)wbak(m)=w0,計算節(jié)點編號m∈{1,2,…,M}
repeat
if 接收并解壓到gmthen
if step觸發(fā)輪次間隔約束 then
continue
wt+1←wt-η(gm+λtgm⊙gm⊙(wt-wbak(m)))
t ← t + 1
else if 拉取參數(shù)請求 then
根據(jù)step更新輪次間隔約束條件
wbak(m)←wt
壓縮wt發(fā)送給計算節(jié)點m
end if
until forever
3.2.3 穩(wěn)定性提升
除主節(jié)點負責檢測去除異常節(jié)點并重置拓撲結(jié)構(gòu)的容錯處理外,參數(shù)服務器因在集群中負責參數(shù)存儲、梯度下降優(yōu)化與進度控制而成為重點,其穩(wěn)定性至關重要。本文設計了共享內(nèi)存哈希表,避免因內(nèi)存緊張等原因進程崩潰后丟失本機存儲的參數(shù)數(shù)據(jù);為進一步防止參數(shù)服務器節(jié)點掉電導致整個集群的訓練失敗,通過一致性哈希的虛擬節(jié)點路由,將2個副本備份在2臺不同的參數(shù)服務器節(jié)點上,其中一臺若被檢測離線,則向備份虛擬節(jié)點地址發(fā)送請求,采用定時主備參數(shù)一致性同步的方式,避免頻繁同步對訓練過程造成影響。
3.3 環(huán)拓撲設計
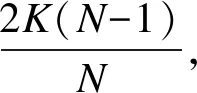
圖3 Ring-AllReduce梯度同步方案Fig.3 Ring-AllReduce gradient synchronization scheme
目前環(huán)拓撲All-Reduce一般采用基于輪次阻塞的方案,如Uber開源的horovod[20]中,為了控制在多臺機器上獨立進程的迭代保持步調(diào)一致,會引入一個根節(jié)點作為協(xié)調(diào)者,當根節(jié)點收到所有進程完成上輪迭代的信息后,廣播開始新一輪迭代。這種方法在控制同步過程的同時增加了網(wǎng)絡通信開銷、屏障阻塞中的資源浪費。
3.3.1 動態(tài)Ring-AllReduce同步方案
為解決上述問題,本文提出一種不引入根節(jié)點,通過P2P通信對分布式訓練進度進行動態(tài)平衡的動態(tài)Ring-AllReduce梯度同步方案。首先通過超時重試機制保證可達性,直到收到回執(zhí)(ACK),確保網(wǎng)絡抖動丟包發(fā)生時消息也能不丟消息;其次將T輪同步迭代過程用更小粒度的2(N-1)×T輪子迭代表示,松弛約束條件使得收到的消息不必在本輪子迭代內(nèi)處理,借助一個消息隊列對收到的子迭代輪次領先的消息進行緩存,在開啟新子迭代時優(yōu)先檢查隊列,若可從隊列里讀到消息則跳過網(wǎng)絡請求直接從消息隊列中讀取,分析時序依賴關系可知最快節(jié)點不會比最慢節(jié)點領先超過N-1個子迭代,實現(xiàn)了動態(tài)同步過程。此方法在沒有輪次阻塞、不破壞同步迭代時序性的情況下,提升了環(huán)拓撲All-Reduce在同步過程中的資源利用率與魯棒性。
3.3.2 梯度融合
本文設計了梯度融合器BufferFusion將多塊梯度內(nèi)存邏輯融合為一塊偽連續(xù)內(nèi)存,使用時將多個梯度內(nèi)存指針注冊到BufferFusion上后,梯度在同步過程中會被作為一塊連續(xù)內(nèi)存操作,批量進行壓縮與網(wǎng)絡傳輸,借助SIMD向量化并行累計梯度并計算均值,將多個Tensor的同步融合為一個操作,進一步降低網(wǎng)絡傳輸成本并提升計算效率。
4 實驗與結(jié)果分析
本文通過設計4組實驗,分別測試系統(tǒng)在稀疏數(shù)據(jù)場景和稠密模型訓練場景下單節(jié)點與多節(jié)點模型的訓練性能與擴展性,以及網(wǎng)絡抖動情況下的穩(wěn)定性。設置實驗環(huán)境為多臺8核、8 GB內(nèi)存、千兆網(wǎng)卡的運算設備,基于高速以太網(wǎng)進行本地網(wǎng)絡連接。
4.1 單機性能對比實驗
為驗證輕量級模塊化設計的計算性能指標,本文對比了目前主流的稀疏模型LibFM與稠密深度模型Tensorflow計算框架在單機CPU下的計算性能。圖4和圖5所示的實驗結(jié)果表明,本文系統(tǒng)相比LibFM在二階交叉隱向量維度為64時達到了15倍的性能加速,CPU上的深度模型訓練相比Tensorflow也有提高,證明輕量級設計與性能優(yōu)化可達預期效果。

圖4 與LibFM系統(tǒng)在計算性能上的對比Fig.4 Comparison with LibFM system in computational performance
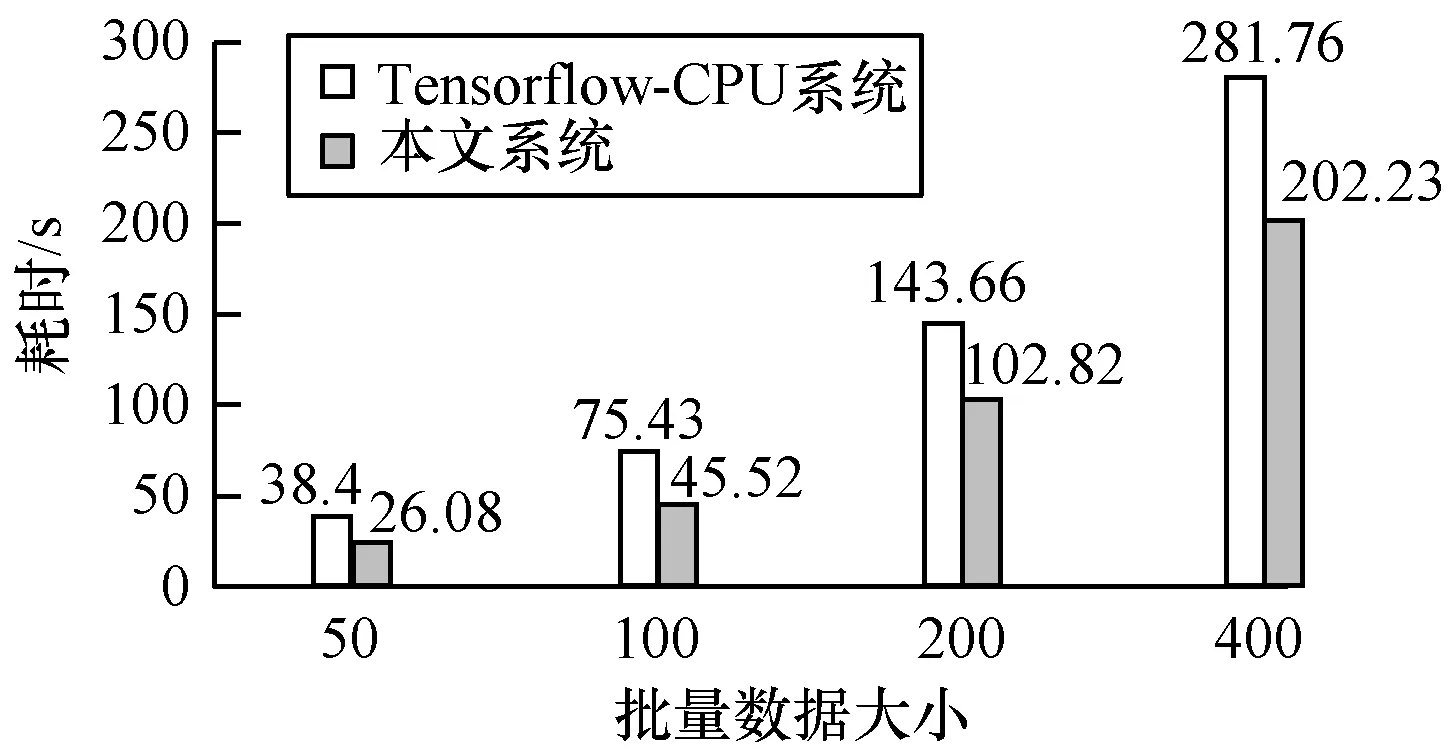
圖5 與Tensorflow-CPU系統(tǒng)在計算性能上的對比
Fig.5Comparison with Tensorflow-CPU system in computational performance
4.2 Wide&Deep模型訓練
Wide & Deep是用于推薦與CTR預估的算法模型,是由邏輯回歸與DNN組合的二分類模型,其DNN輸入為離散特征的Embedding向量,融合了高維稀疏特征與稠密類別特征。借助上文設計的參數(shù)服務器,稀疏參數(shù)與類別稠密特征都通過Pull/Push完成參數(shù)獲取與梯度匯報。實驗采用Avazu數(shù)據(jù)集學習點擊率,設置4個參數(shù)服務器節(jié)點、4個計算節(jié)點,將訓練數(shù)據(jù)拆分4個輸入計算節(jié)點。單機訓練全量數(shù)據(jù)與4個節(jié)點數(shù)據(jù)并行訓練的損失函數(shù)與準確率對比如圖6所示,可以看出,本文系統(tǒng)在4個計算節(jié)點上盡管梯度下降有較強抖動,但都最終達到了與單機相近的準確率與收斂效果,且訓練數(shù)據(jù)吞吐量大幅提高,發(fā)揮了分布式并行的優(yōu)勢。
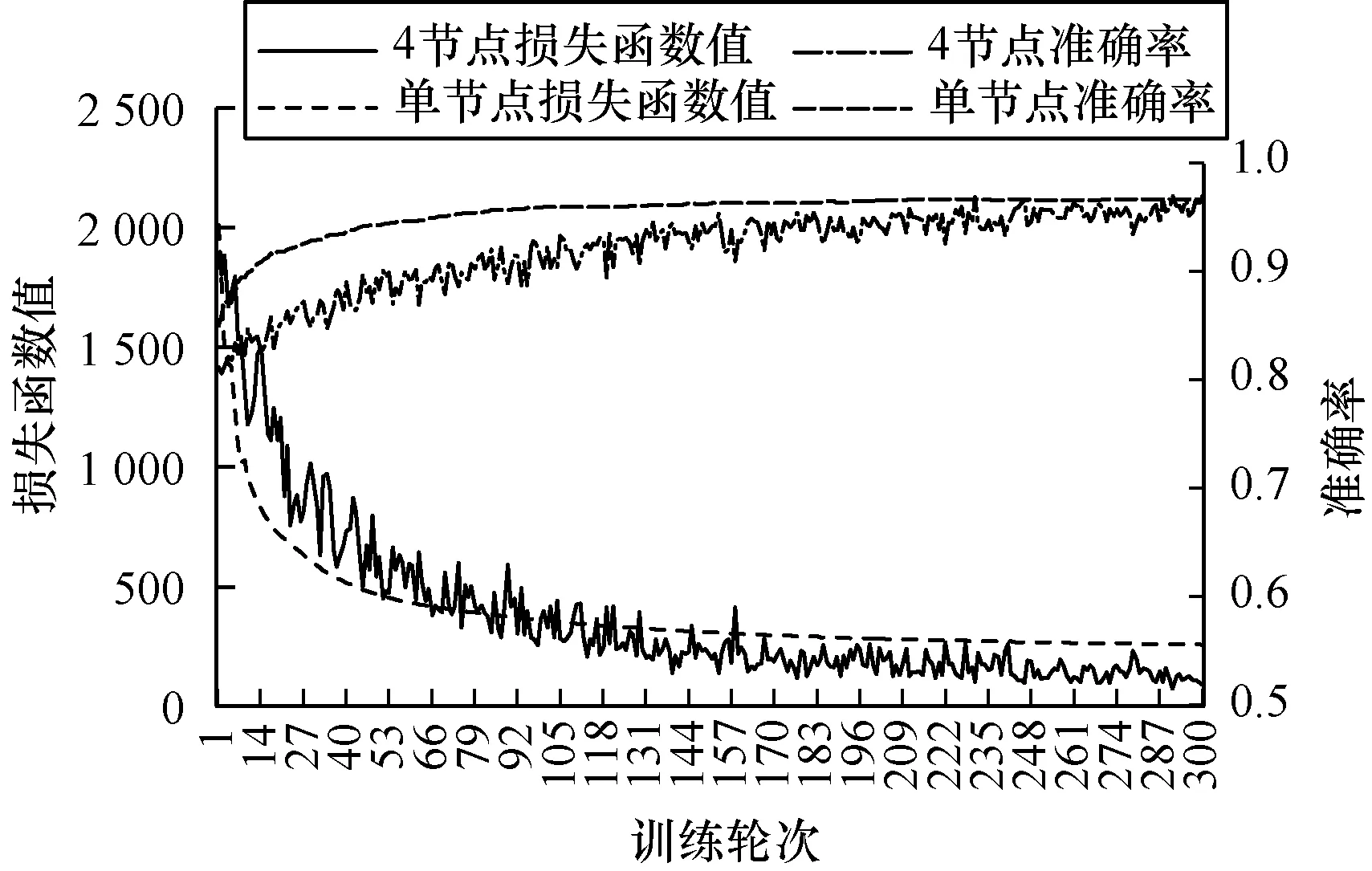
圖6 參數(shù)服務器訓練下的損失函數(shù)與準確率曲線
Fig.6Loss function and accuracy curves under parameter server training
4.3 CNN模型訓練
卷積神經(jīng)網(wǎng)絡CNN是稠密張量組成的深度模型。實驗任務設置為MNIST手寫數(shù)字識別,分別采用4個與8個計算節(jié)點用Ring-AllReduce同步方式訓練一個十分類CNN神經(jīng)網(wǎng)絡。模型由3個卷積層與池化層、2個全連接層組成串聯(lián)而成,輸出十分類概率分布。實驗結(jié)果如圖7和圖8所示,可以看出曲線平滑且快速收斂,多節(jié)點訓練加速效果明顯,在4節(jié)點上達到了3.4倍的加速,而在8節(jié)點模型上達到了6倍的加速。
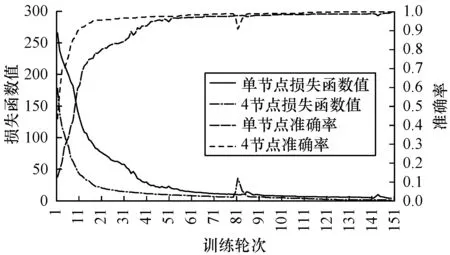
圖7 Ring-AllReduce訓練下的損失函數(shù)與準確率曲線
Fig.7Loss function and accuracy curves under Ring-AllReduce training
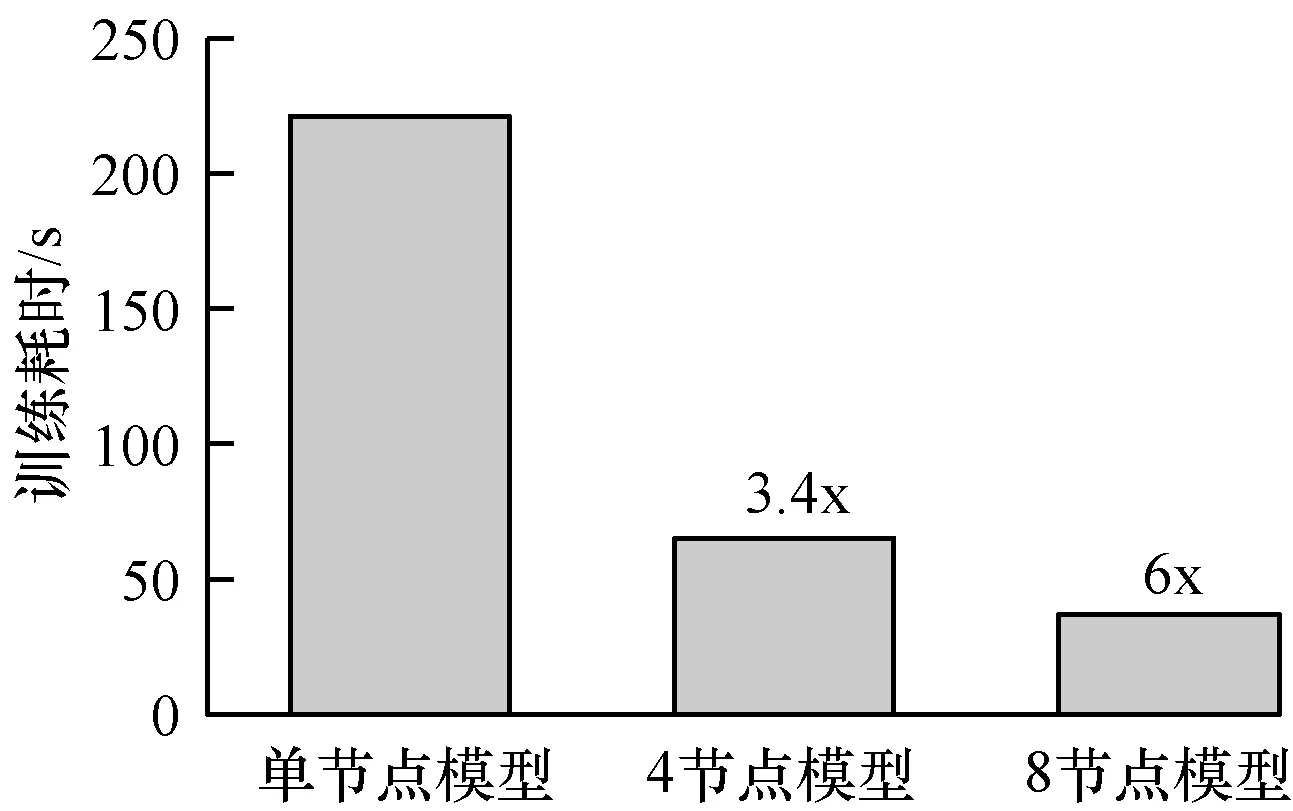
圖8 訓練加速效果
4.4 網(wǎng)絡抖動下的系統(tǒng)表現(xiàn)
在網(wǎng)絡抖動下的實驗中,用隨機自旋模擬更頻繁的網(wǎng)絡抖動,并分別對消息重發(fā)同步與Ring-AllReduce同步2種方案的同步耗時進行比較,結(jié)果如表3所示。實驗結(jié)果表明,隨著同步輪次與待同步的浮點數(shù)個數(shù)的增加,Ring-AllReduce同步擁有最高的同步效率,且隨著同步規(guī)模增大優(yōu)勢更加明顯。其中消息重發(fā)同步在210個浮點數(shù)時性能最差,分析原因是在實驗模擬的網(wǎng)絡抖動環(huán)境下,小規(guī)模浮點數(shù)計算耗時短,導致消息重發(fā)同步中數(shù)據(jù)包重發(fā)變得非常頻繁,無效的網(wǎng)絡通信與I/O占用成為很大的負擔,而動態(tài)Ring-AllReduce同步受網(wǎng)絡抖動與運算耗時差異影響小,在動態(tài)平衡中形成了對最慢節(jié)點的異步等待。
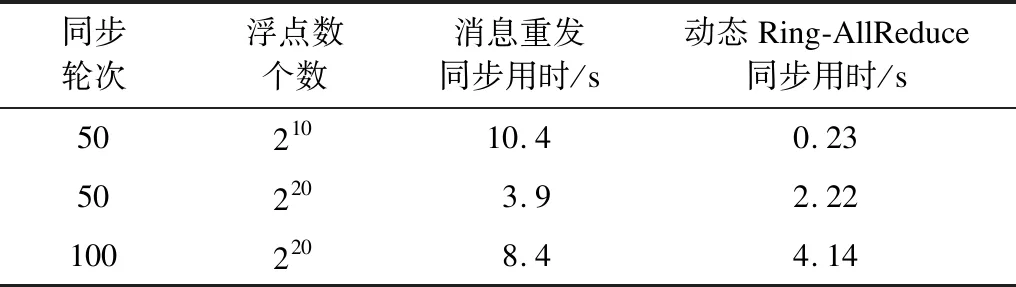
表3 網(wǎng)絡抖動下的同步耗時對比Table 3 Time comparison of synchronization under network jitter
5 結(jié)束語
本文設計一種輕量級模塊化的分布式機器學習系統(tǒng),以滿足大規(guī)模特征分布式訓練高定制化、低耦合與低資源消耗的需求。實驗結(jié)果表明,該系統(tǒng)對于稀疏或稠密模型訓練均有較好的加速性能、擴展性與穩(wěn)定性。筆者已證明SIMD向量指令對模型計算效率具有優(yōu)化效果,并且已將研究內(nèi)容以LightCTR項目的形式開源在Github上[21],后續(xù)將設計深度學習算法在GPU上的SIMT異構(gòu)計算,以及模塊化的多機多卡系統(tǒng),進一步提升本文系統(tǒng)的訓練加速性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
現(xiàn)代裝飾(2020年7期)2020-07-27 01:27:42
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
流行色(2020年1期)2020-04-28 11:16:38
藝術(shù)啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
