P2P網絡借貸信用風險度量模型的對比研究
——以“Prosper”和“拍拍貸”為例
2020-01-16 05:34:10西南財經大學法學院鄧春生
中國商論 2019年24期
西南財經大學法學院 鄧春生
1 引言
自2007年拍拍貸在上海成立以來,P2P網絡借貸在我國取得了迅猛發展。與此同時,P2P平臺在信用風險、技術風險、政策風險等因素的作用下,給P2P行業乃至整個金融行業的健康穩定發展帶來了巨大的壓力。為此,政府部門密集出臺了一系列P2P行業相關的監管制度,意圖讓P2P行業的發展回歸理性和健康。密集的監管制度出臺必然會給行業發展帶來一些波動,例如2018年全年我國P2P網貸行業的成交量達到17948.01億元,相比2017年下降36.01%。
目前,國內外眾多學者對P2P網絡借貸借款人的信用風險度量進行了廣泛且深入的研究。針對P2P網絡借貸借款人信用風險度量模型,主要分為以下兩種:(1)統計回歸模型。Lin &Li et al(2016)應用二元邏輯斯回歸方法建立了一個綜合的信用風險評估模型,以便量化每筆貸款的違約風險。Serrano-Cinca &Gutiérrez-Nieto(2016)以預期盈利能力為著眼點,使用多元回歸建立利潤評分系統,進而選擇最優的借款人。Lee &Lee(2012)首先分析了影響信用風險的相關變量,然后利用多項式邏輯市場份額模型對信用風險進行評估。(2)機器學習模型。涂艷等(2018)基于拍拍貸的交易數據,基于機器學習建立的借款人信用風險度量模型,其準確率要高于傳統回歸模型。Xia,Liu &Liu(2017)通過結合成本敏感學習和極端梯度增強方法,提出了一種新的成本敏感提升樹模型,用以提高區分潛在違約借款人的能力。Ma&Sha et al(2018)針對Lending Club的數據,應用現代機器學習算法LightGBM和XGboost進行了信用風險度量風險。Ma,Zhao &Zhou(2018)針對信息不對稱前提下的P2P平臺貸款決策問題,通過借款人的手機/電話通訊數據,利用自適應增強算法(AdaBoost)建立了違約風險預測模型。Kim &Cho(2019)針對Lending Club中的無標簽數據,結合Dempster-Shafer理論和轉導支持向量機(TSVM)方法對違約風險進行了準確預測。Wang &Jiang et al(2017) 針對發生率分量,應用隨機森林來預測是否違約;針對延時風量,應用隨機生存林來預測何時違約。Malekipirbazari &Aksakalli(2015)針對Lending Club數據,提出了一種基于隨機森林的分類方法用于預測借款人的信用風險狀 態。
眾多的學者已經利用各式各樣的方法對P2P網絡借貸的風險進行了度量分析。但是,沒有免費的午餐定理指出,不存在某一個方法或模型在所有性能上都是最優的。在眾多的信用評分模型中,不可能存在某一個模型在所有信用風險相關數據集上都適用,那么對決策者來說就存在最優決策問題。因此,如何選穩健的評價和選擇魯棒的分類方法就是一個非常重要的問題。為此,本文針對Prosper和拍拍貸兩個數據集,應用了11種分類算法進行對比研究,以期得到對P2P網絡借貸信用風險度量問題最合適的方法類型,也為以后開發綜合性能更優以及對P2P網貸行業符合度更高的度量方法奠定研究基礎。
2 信用風險度量模型簡介
信用風險的評分模式主要是一些分類方法。分類,是有監督學習中的一種,以待分析的目標問題為背景,采用一部分樣本數據建立一個關于類別屬性劃分的分類方法,并利用該方法對同類問題中類別標記未知的樣本進行學習和判斷的過程。現在,讓我們對一些主流的分類算法進行簡單介紹。
2.1 決策樹類算法
決策樹類算法是一種逼近離散函數值的典型分類方法。決策樹算法通過構造決策樹來發現數據中蘊涵的分類規則。(1)C4.5算法:由于C4.5算法生成的決策樹能夠被用于分類,所以C4.5模型通常被用于統計分類。2011年,Witten &Frank (2011)將C4.5模型描述為“一個具有里程碑意義的決策樹算法,可能是迄今為止在實踐中最廣泛使用的機器學習方法”。(2)CART算法:CART(Classif cation and regression trees)算法是一種十分有效的非參數分類和回歸方法。CART選擇具有最小GINI系數值的屬性作為分裂屬性,并按照節點的分裂屬性,采用二元遞歸分割的方式把每個內部節點分割成兩個子節點,遞歸形成一棵結構簡潔的二叉樹。
2.2 函數類算法
(1)RBF(徑向基)神經網絡模型:RBF神經網絡是使用徑向基函數作為激活函數的人工神經網絡,其中徑向基函數表示其取值僅僅依賴于離原點距離,即滿足特性的函數。RBF神經網絡通常由三層組成:第一,輸入層;第二,具有非線性RBF激活函數的隱藏層;第三,線性輸出層。(2)MLP(多層感知)神經絡模型:MLP是一類的前饋人工神經網絡,可用于通過回歸分析創建數學模型。由于分類是響應變量是分類時回歸的特定情況,因此MLP也是良好的分類器算法。(3)SVM(支持向量機)算法:SVM(support vector machines)是一種二分類模型,它的目的是尋找一個超平面來對樣本進行分割,分割的原則是間隔最大化,最終轉化為一個凸二次規劃問題來求解。
2.3 貝葉斯算法
(1)NBC(樸素貝葉斯分類)算法:NBC(Native Bayes Classif er)是一種簡單但是非常強大的線性分類器,而且它所需估計的參數很少,對缺失數據不太敏感,方法也比較簡單。(2)BN(貝葉斯網絡)算法:BN(Bayesian Network)也叫貝葉斯信念網絡,借助有向環圖來刻畫屬性之間的依賴關系,并使用條件概率表來描述屬性的聯合概率分布。(3) NBT(樸素貝葉斯決策樹)算法:該算法主要有兩個優點:第一,算法過程非常清晰、直觀、可理解性很強;第二,在計算復雜度不高的前提下能保持較高的分類正確率,有利于在大型數據集中的利用。
2.4 K鄰近(KNN)分類算法
K鄰近分類算法的基本思想是:輸入沒有標簽(標注數據的類別),即沒有經過分類的新數據;首先,提取新數據的特征并與測試集中的每一個數據特征進行比較;其次,從測試集中提取K個最鄰近(最相似)的數據特征標簽,統計這K個最鄰近數據中出現次數最多的分類,將其作為新的數據類別;類似于生活中的“物以類聚,人以群分”。
2.5 基于規則的算法
(1)CBA(基于關聯規則的分類)算法:CBA(Classification base of A ssociation)算法,即基于關聯規則進行分類的算法,利用了Apriori挖掘出的關聯規則,然后做分類判斷。在某種程度上說,CBA算法也可以說是一種集成挖掘算法。(2)CPAR(基于預測關聯規則的分類)算法:CPAR(Classification Based on Predictive Association Rules)模型整合了關聯規則分類算法和傳統的基于規則分類算法的優點。CPAR算法為避免過度擬合,采用貪心算法生成規則,這一策略比產生所有候選項集的效率要高。
3 評價指標
信用風險度量模型的評價實質上就是對分類模型的評價。為方便說明,引入如下混淆矩陣(confusion matrix),如表1所示。
考慮到對分類方法評估的科學性、全面性和客觀性,我們選用了八個經典的評價指標,定義如下。
(1)正確率(ACC):正確率是指測試集中被正確分類的百分率,是最廣泛使用的分類評估指標之一,即:
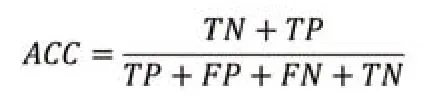
通常來說,ACC越高,分類器越好。
(2)真正率(TPR):指被正確劃分的預測正樣本數的百分率,即:
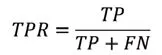
TPR也稱為靈敏度指標,用于衡量分類器對正樣本的識別能力。
(3)真負率(TNR):指被正確劃分的預測負樣本數的百分率,即:

表1 混淆矩陣示意圖
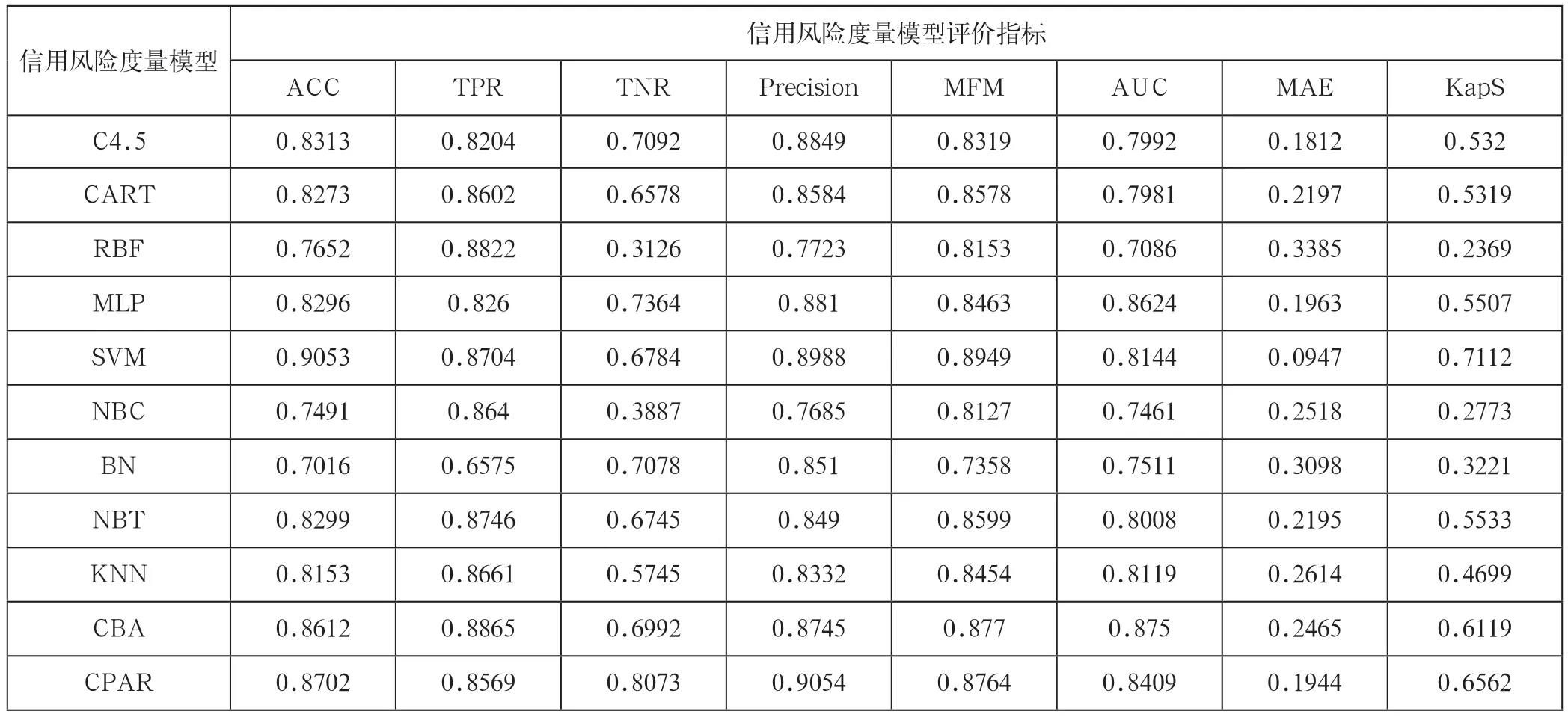
表2 針對Prosper數據集的信用風險度量模型的評價結果
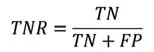
TNR也稱為特異性指標,用于衡量分類器對負樣本的識別能力。
(4)精度(Presision):指預測正樣本中實際為正樣本的百分率,是精確性的度量,即:
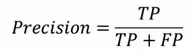
(5)F 1-measure(MFM,平均F測量)值:一個綜合評價指標,指當精度與真正率矛盾時,對精度與真正率的綜合考慮,即:

(6)AUC(Area under curve):是機器學習常用的二分類評測手段,直接含義是ROC曲線下的面積。曲線下面積越大,分類器就越好。
(7)平均絕對誤差(MAE):指分類器的預測值和實際值之間的偏離程度,即:
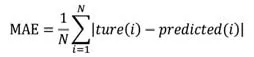
式中,ture(i)和predicted(i)分別表示第i個樣本的真實值和預測值。
(8)Kappa 統計指標(KapS):一種用于衡量分類精度的統計指標,其計算基于混淆矩陣,即:

4 信用評分模型的 綜合評價
針對Prosp er數據集和拍拍貸數據集的11個信用評分模型在8個評價指標下的評價結果分別列在表2和3中。注意,粗體數字表示在某一指標下最優的評價值。
觀察表2和表3,我們有如下結論:(1)在不同的評價指標下,不同的信用評分模型有不同的評價值,且沒有一種信用評分模型在所有的評價指標下都是最優的。主要原因是:不同的評價指標,其評價側重點也不一樣。另外,信用風險的度量主要是一個典型的分類學習問題,那么不同的分類模型其學習的側重點也不一樣,所以不可能存在某一分類模型在所有評價指標上都是最優的。
(2)針對Prosper數據集,以SVM方法構建的信用風險度量模型在ACC、MFM、MAE和KapS這四個指標下是最優的。針對拍拍貸數據集,SVM方法在ACC、Precision、MFM、MAE和KapS這5個指標下表現最優。由此可見,SVM方法具有很強的穩健性。
為了全面、綜合的評價這位11個信用風險度量模型,我們引入排序均值的概念,并以排序均值的大小來對這11個模型綜合排序。表4展示了Prosper數據集和拍拍貸數據集上的排序均值和綜合排序。
從表4中可以得出:(1)性能優越的信用風險度量模型主要是SVM方法、CBA方法和CPAR方法。(2)信用風險度量模型性能次優的模型主要是CART方法、MLP方法、NBT方法和KNN方法。(3)信用評分性能出現較大差異的方法是RBF網絡,該方法的波動較大;在Prosper數據集中,RBF網絡在指標TPR下表現為最優,但是其綜合排序卻是第10名。
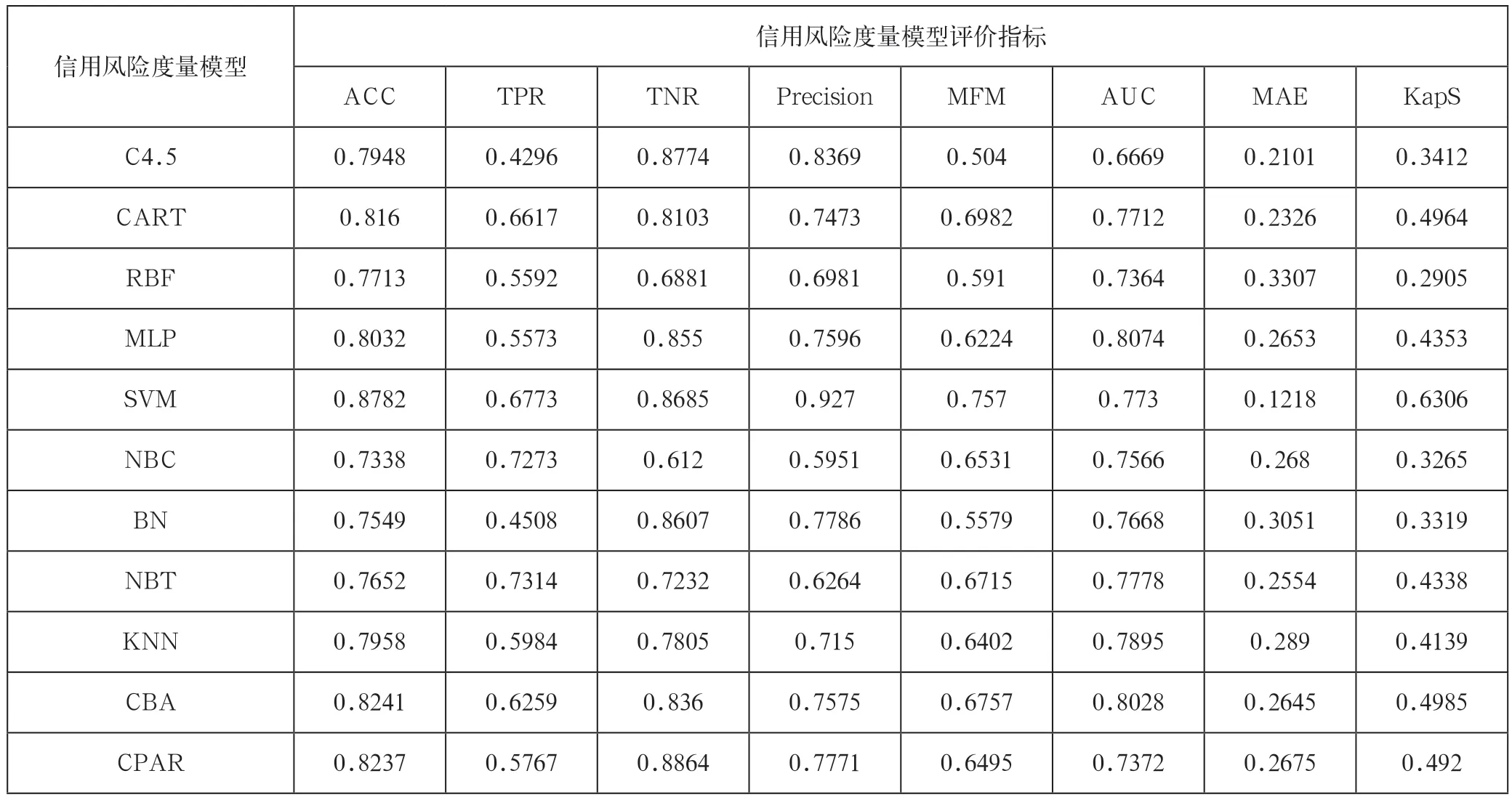
表3 針對拍拍貸數據集的信用評分模型的評價結果
5 結語
(1)不同的信用度量模型在同一個數據集中有不同的表現,同一個信用度量模型在不同的數據集中性能表現也不盡相同。為了讓同一個信用度量模型對不同的數據集都能有一致的評級性能,需要讓數據集足夠的大,讓信用度量模型有充足的訓練數據來學習出最優的參數。為此,我們應建立P2P網絡借貸行業統一的個人/企業信用信息共享系統,以便建立P2P網絡借貸行業統一的信用信息數據集,為建立客觀有效的信用度量模型奠定數據基礎,克服單一平臺進行信用評級存在的數據不全、評價不準等問題。
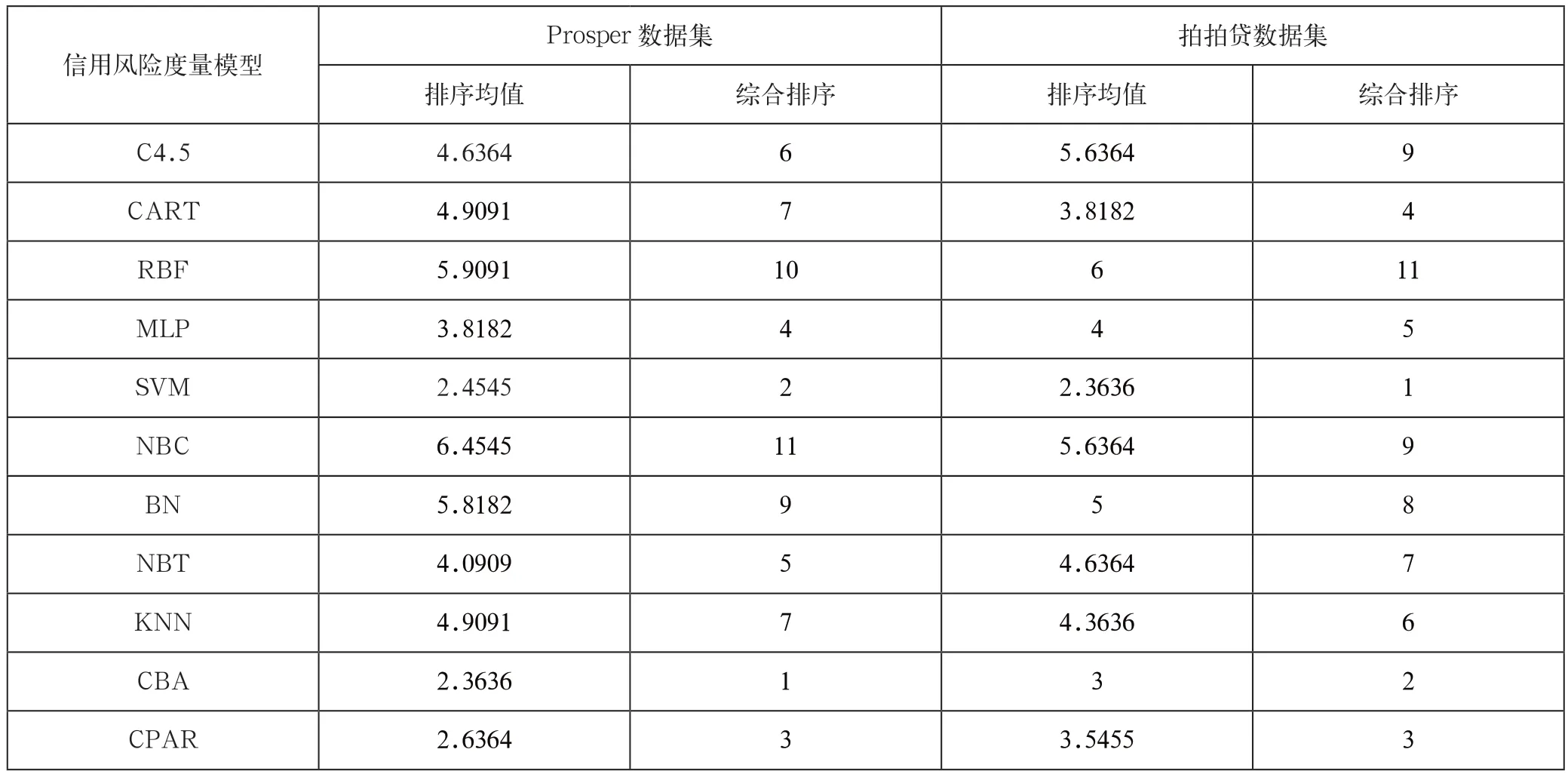
表4 信用風險度量模型綜合評價
(2)根據我們的綜合評估來說,針對所選擇的數據集,在穩健性和魯棒性上表現最優的三個信用度量模型分別是SVM方法、CBA方法和CPAR方法。另外,依據CART方法、MLP方法、NBT方法和KNN方法構建的信用評分模型也有不俗的表現。最后,出現波動比較大的方法是RBF網絡方法。針對該結論,我們應建立P2P網絡借貸行業統一的個人/企業信用評級系統,克服不同的平臺使用不同的度量模型,對同一個借款人得出不同信用等級的問題。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
