基于知識蒸餾的車輛可行駛區域分割算法研究
2020-01-15 13:23:32周蘇易然鄭淼
汽車技術 2020年1期
周蘇 易然 鄭淼
(同濟大學,上海 201804)
主題詞:知識蒸餾 可行駛區域 圖像分割 卷積神經網絡
1 前言
車輛可行駛區域分割問題是無人駕駛汽車發展的大環境下延伸出的子課題,對可行駛區域進行檢測可以為無人駕駛的決策提供重要依據。
基于計算機視覺的語義分割主要分為以特征檢測為主的傳統方法和以卷積神經網絡為主的深度學習方法。傳統分割方法中,一種是基于圖像閾值的方法,根據人工設計的特征(如灰度值等)得到特定的閾值,然后將圖像中的像素點分類到指定的類別中完成分割,但此類方法只能對一些簡單的圖像進行分割,圖像復雜時,很難找到合適的閾值。另一種傳統分割方法是基于圖像的邊緣信息進行分割,但這類方法很容易受到噪聲的影響,噪聲較大或者邊緣模糊時,分割效果較差。
2014年,Long J[1]等人提出使用全卷積神經網絡(Fully Convolutional Networks,FCN)對圖像進行語義分割,這是卷積神經網絡在圖像分割領域的首次成功應用。Olaf Ronneberger[2]等人提出一種用于醫療圖像分割的U形網絡U-net,該方法最大的貢獻在于提出了將圖像編碼與解碼進行融合的思想。2018年,何愷明[3]從另一個角度對圖片進行語義分割,提出掩膜區域卷積神經網絡(Mask Region-based Convolutional Neural Network,Mask R-CNN)模型。2015年到2018年8月,谷歌先后發表4篇DeepLab系列的語義分割論文[4-7],創新性地提出了空洞卷積(Astrous Convolution)和空洞空間金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)[8]結構,將深度學習方法在語義分割中的應用提升到了新的高度。基于深度學習的方法雖然能夠取得較好的精度,但是由于神經網絡巨大且參數較多,導致分割時間消耗較大,這也成為了該方法的一個短板。
2006年,Caruana[9]等人首次提出利用知識轉移(Knowledge Transfer,KT)來壓縮模型,對強分類器的壓縮模型進行訓練,標記了偽數據,并再現了較大的原始網絡輸出。2014年,Jimmy[10]等首次提出知識蒸餾(Knowledge Distillation,KD)的概念,用于將大而深的網絡壓縮為較小的網絡,其中壓縮模型模仿復雜模型所學習的函數。基于KD的主要思想是通過改進的Softmax函數來軟化大型教師模型的輸出,將大型教師模型的“知識”轉移到小型的學生模型中。而2015年Hinton[11]提出以教師網絡和學生網絡共同的輸出作為目標函數,將教師網絡中有用的信息遷移至學生網絡上進行訓練。2017年,Zagoruyko[12]等人將注意力機制引入知識蒸餾,使用教師網絡訓練的注意力特征圖引導學生網絡訓練。
因此,本文以道路可行駛區域作為研究對象,將知識蒸餾這一模型壓縮方法應用于道路可行駛區域分割,以期使用較小的神經網絡模型得到較高的分割精度。
2 車輛可行駛區域蒸餾分割算法
2.1 知識蒸餾算法
知識蒸餾是一種利用神經網絡中的遷移訓練方式將大型網絡的“知識”轉移到小型網絡中的模型壓縮方法。知識蒸餾算法中引入教師網絡和學生網絡兩種神經網絡,其中教師網絡的參數量巨大、精確度高、特征提取能力強,但參數量巨大導致難以在單片機等移動終端上進行部署,學生網絡參數量較小,但單獨訓練時精確度不高,很難滿足實際道路環境要求。知識蒸餾訓練方式則是使用教師網絡指導學生網絡的訓練,將教師網絡的“知識”通過蒸餾算法傳遞至學生網絡中。知識蒸餾算法引入了一種軟標簽的形式實現教師與學生網絡的知識遷移,與傳統的硬標簽在標注數據時只有“0”和“1”相比,軟標簽用0和1之間的數據來標注圖片,這樣在標注出圖片所屬類別的同時,將類與類之間的距離很好地表示出來。
知識蒸餾模型壓縮算法的原理如圖1所示。學生網絡知識蒸餾訓練過程中,首先訓練一個參數量較多且精度較高的神經網絡,使用該網絡得到訓練集的軟標簽,然后將軟標簽和真實硬標簽一起作為蒸餾訓練的擬合對象,使用參數α來調節損失函數的比重。訓練之后,使用小模型進行部署預測。
知識蒸餾訓練的損失函數LKD(Ws)為:
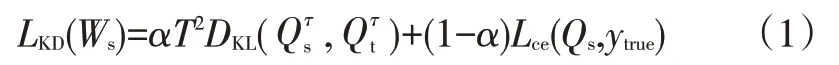
式中,α為兩部分損失函數的權重參數,用于調節兩部分損失值對反向傳播梯度的權重;T為溫度系數;DKL為KL散度損失函數;分別為學生網絡和教師網絡經過改進Softmax函數輸出后的軟化結果;Lce為交叉熵損失函數;Qs為學生網絡經過Softmax之后的輸出結果;ytrue為真實標簽值。
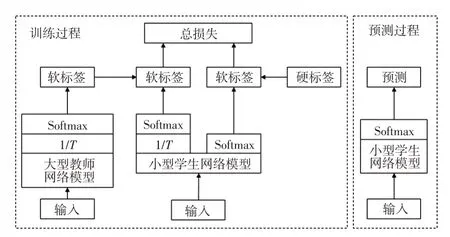
圖1 知識蒸餾訓練模型壓縮算法原理
式(1)由2個部分組成,一是教師網絡和學生網絡的KL散度損失函數,用于計算學生網絡輸出與教師網絡輸出之間的距離,二是學生網絡與真實標簽之間的交叉熵損失值,將這兩部分的加權之和作為蒸餾訓練的損失函數。
正常訓練的Softmax函數為:

式中,zi為第i個神經元的輸出值;Si為zi的Softmax輸出值。
式(2)可以將神經網絡的輸出映射到0~1范圍內,并得到對應的概率值。
在知識蒸餾訓練中,為了得到更加“軟”的標簽,可以在原Softmax函數中引入溫度系數T,得到改進后的Softmax函數:

式(3)中,T的大小可以改變神經網絡輸出結果的分布情況,T越大,概率分布越平坦,軟標簽越“軟”。在知識蒸餾訓練時,及時調整T的取值可以控制損失函數中第1部分的教師網絡和學生網絡輸出結果的軟化程度。
2.2 DeepLabV3+分割網絡
圖2所示為DeepLabV3+網絡的原理結構[7]。圖2a為DeepLabV3的空間金字塔池化網絡結構,該結構使用串行結構進行編碼,將原圖壓縮為1/8的特征圖后再使用空間金字塔池化結構豐富特征,然后將8倍的上采樣映射回原圖。這種結構忽略了淺層的特征信息,分割的損失比較大。圖2b為典型的編碼解碼結構,可以將淺層信息與深層信息充分融合,但是這種方法使得網絡結構更加復雜,難以實現。因此,DeepLabV3+將兩者的優點進行結合,提出基于空間金字塔池化的編碼解碼語義分割網絡結構,如圖2c所示。
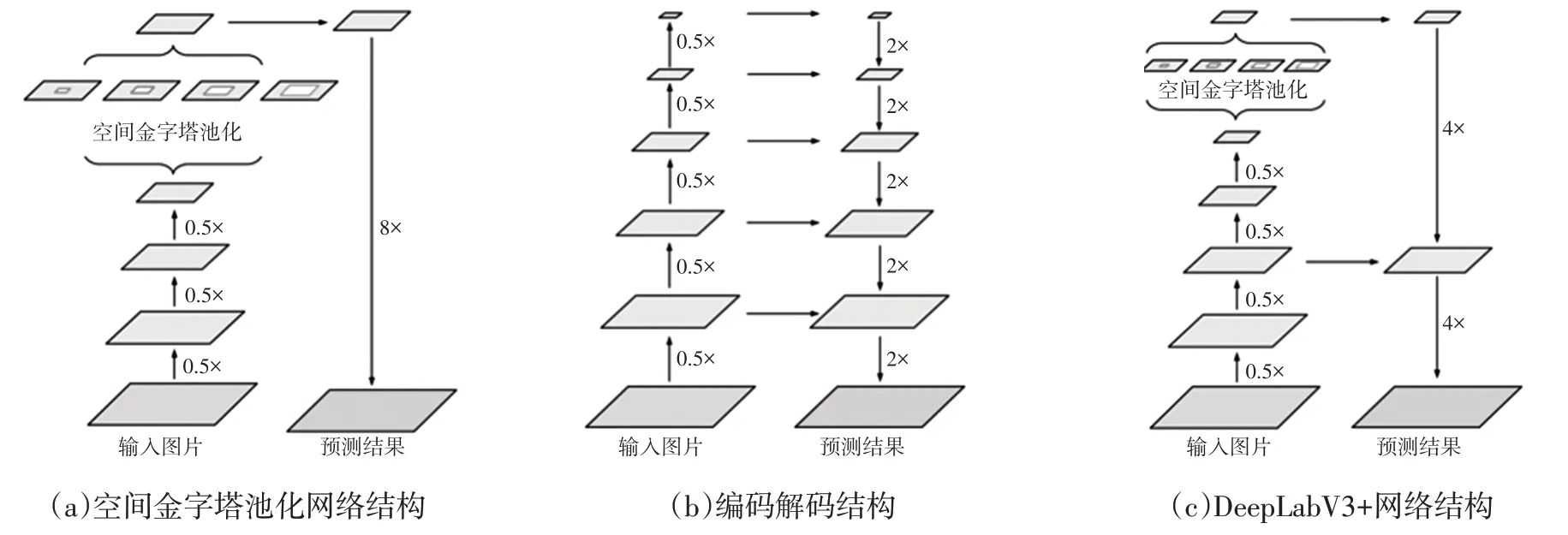
圖2 DeepLabV3+網絡的原理結構
本文使用Resnet18網絡[13]作為DeepLabV3+的主干網絡。Resnet18網絡首先使用1個卷積層和1個池化層將圖片縮小,得到原圖的1/4特征圖,然后經過多個殘差塊不斷對圖片的特征進行處理,最后得到原圖1/32大小的特征圖,再使用全連接層以及Softmax等處理工具進行分類。本文使用該網絡作為DeepLabV3+的主干網絡,同時去除主干網絡中最后一個縮小特征圖的層,輸出為原圖1/16的特征圖。所構建的網絡具體結構如圖3所示,一條特征輸出支路取Resnet18的Block3輸出的特征圖作為編碼的特征圖,之后使用1個1×1的普通卷積和3個3×3的帶孔卷積進行特征提取。其中,3個帶孔卷積的擴張率不同,這樣提取出特征的感受野不同,使得輸出特征的豐富性大幅增加。再將這些特征直接拼接,并使用1×1卷積將特征進行融合,融合后使用4倍的反卷積將特征圖映射至原圖的1/4大小。另一條支路上,直接提取Resnet18中Block1輸出的1/4特征圖,這一特征圖尺寸與第1條支路的特征圖尺寸相同,將2條支路輸出的特征圖進行拼接,組成一個特征圖。這一特征圖結合了主干特征提取網絡的深層網絡和淺層網絡,使網絡得到的圖片特征更加豐富。然后使用3×3的網絡將2個特征融合,最后使用4倍的反卷積,將該特征圖映射回原圖大小,進行像素級語義分割。
3 數據集訓練與仿真
3.1 訓練與仿真條件
將知識蒸餾模型壓縮算法用于像素級語義分割,對車輛的可行駛區域語義分割算法進行研究。本文使用的學生網絡是上節中以Resnet18作為主干網絡構造的DeepLabV3+模型,教師網絡是以Resnext29[14]作為主干網絡的DeepLabV3+模型。參照圖3,主干網絡由Resnet18改為Resnext29,Resnext29網絡的參數數量是3 452萬個,幾乎是Resnet18參數數量的10倍。研究使用的數據集為BDD100K中的可行駛區域數據,在一臺配備Intel i7-5930K CPU和NVIDIA Titan X GPU的工作站上進行訓練。
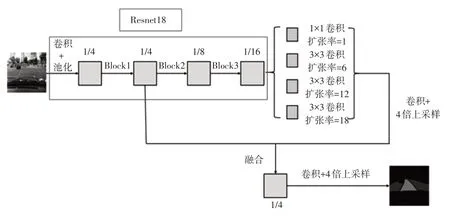
圖3 以Resnet18為主干網絡構建的DeepLabV3+網絡結構
3.2 訓練與仿真結果分析
知識蒸餾模型壓縮算法在圖像語義分割中有2處應用:一處是將DeepLabV3+網絡模型的主干網絡加載預蒸餾訓練后的Resnet18權重參數(序號3);另一處是直接更改DeepLabV3+模型分割訓練的損失函數。使用Resnext29為主干網絡構建的DeepLabV3+模型作為教師網絡,使用Resnet18為主干網絡構建的Deep-LabV3+模型作為學生網絡進行蒸餾訓練(序號4)。本文分別對這2種方式以及2種方式相結合(序號5)的訓練模型進行車輛可行駛區域的分割訓練以及測試。分割結果如表1所示,兩種單獨優化方式均可以提升以Resnet18作為主干網絡構建的DeepLabV3+分割模型的精度,而把2種方式結合起來可以進一步提高分割精度,將直接可行駛區域交并比IOU1提高約2%,間接可行駛區域交并比IOU2提高約4%,整體像素準確率提高約1.5%。
將最終的優化模型(序號5)與優化前的模型(序號2)在BDD100K驗證集上進行分割效果對比,選取夜間、彎道、雙向車道3種不同的交通場景,結果如圖4~圖6所示。結果表明,經過蒸餾訓練,直接可行駛區域和間接可行駛區域的分割結果在細節上均有明顯提升,蒸餾后能夠識別出幾乎所有可行駛區域。
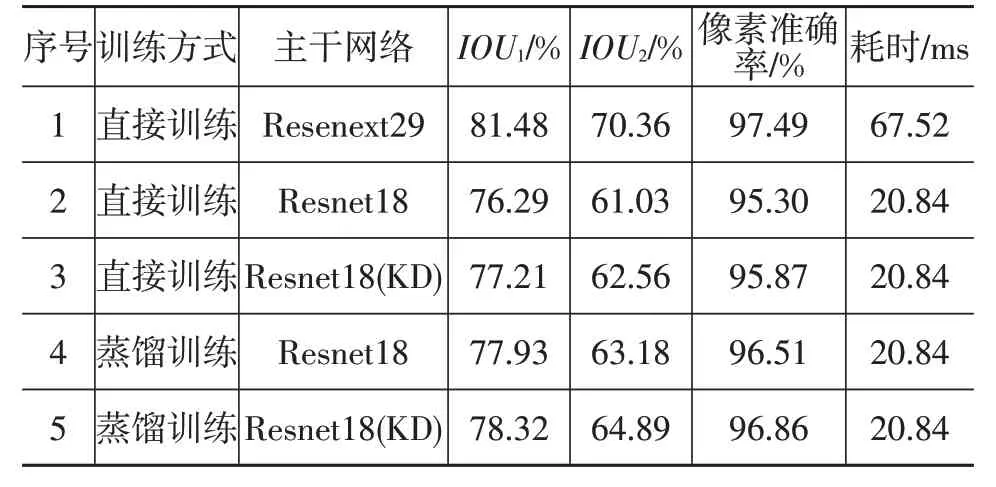
表1 使用蒸餾后Resnet18作為主干網絡的DeepLabV3+可行駛區域分割結果
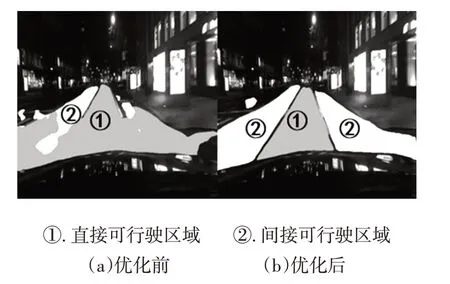
圖4 夜間場景蒸餾訓練前、后道路分割效果

圖5 彎道場景蒸餾訓練前、后道路分割效果

圖6 對向車道蒸餾訓練前、后道路分割效果
4 實際道路測試
為了更好地仿真該語義分割模型在實際道路環境中的分割效果,對上海市內一些路段進行路況采集。采集車輛為榮威eRX5,視頻采集設備為米家行車記錄儀,如圖7所示。

圖7 道路圖像采集車輛及設備安裝情況
在上海市嘉定區和青浦區等地進行視頻采集,包括曹安公路、嘉松公路等路段。所采集道路情況包括柏油路段和水泥路段等道路,交通情況包括兩車道、三車道、彎道、雙向車道等情況,視線情況包括白天和夜間等。道路視頻采集后,利用本文所構建的語義分割網絡進行分割試驗,以驗證模型的分割實用性,結果如圖8~圖12所示。

圖8 兩車道分割結果

圖9 三車道分割結果

圖10 彎道分割結果
由實際道路測試結果可知,本文所構建的分割模型在兩車道、三車道、彎道、雙向車道等道路場景以及白天和夜間的視線情況下都能準確地分割出2種可行駛區域,表現出了良好的適用性。

圖11 雙向車道分割結果

圖12 夜間道路分割結果
5 結束語
本文針對無人駕駛汽車道路環境的感知問題,提出使用卷積神經網絡對車輛的直接可行駛區域與間接可行駛區域進行像素級語義分割,并將用于圖像分類的知識蒸餾模型壓縮算法應用于圖像語義分割問題,對以Resnet18作為主干網絡的DeepLabV3+分割模型進行優化,將算法的平均交并比提高約3%。最后使用BDD100K驗證集以及實際道路測試對比不同的道路環境下優化前、后的分割結果,驗證了模型分割的實用性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
