一種適合城市混合道路行駛工況的構(gòu)建方法
2019-12-26 02:53:36彭漢銳周桂添李菁元
天津科技 2019年12期
關(guān)鍵詞:汽車
彭漢銳,周桂添,顏 燕,李菁元,呂 赫
(1.廣州本田汽車有限公司 廣東廣州 510000;2.中國(guó)汽車技術(shù)研究中心有限公司 天津 300300;3.中汽研汽車檢驗(yàn)中心(天津)有限公司 天津 300300)
0 引 言
汽車行駛工況(Driving Cycle)是汽車工業(yè)一項(xiàng)共性的核心技術(shù),可用于確定車輛污染物排放量、燃油消耗量、新車型技術(shù)開發(fā)和評(píng)估等[1]。研究表明,每個(gè)城市、地區(qū)的行駛工況都有各自的特點(diǎn)[2-4]。
國(guó)內(nèi)外學(xué)者對(duì)如何構(gòu)建本地汽車行駛工況進(jìn)行了大量的研究,提出的構(gòu)建方法主要有短行程法、聚類法和馬爾科夫法 3種。短行程法以短行程為基本單元,對(duì)所有短行程進(jìn)行隨機(jī)組合,隨機(jī)組合后的短行程構(gòu)成候選工況,對(duì)候選工況使用特征參數(shù)評(píng)價(jià)的方法,選取特征參數(shù)最接近實(shí)驗(yàn)數(shù)據(jù)的候選工況為代表性行駛工況。運(yùn)動(dòng)學(xué)片段通常采用隨機(jī)選擇、最佳增量等方式進(jìn)行選擇,如香港、悉尼、曼谷、合肥等城市的汽車行駛工況[1,5-7],其不足在于無(wú)法區(qū)分道路類型(城市行駛工況中包含多種道路類型)。聚類法一般基于主成分方法(PCA)對(duì)選取的能反映車輛運(yùn)行特征的部分參數(shù)進(jìn)行分析,解析這些特征參數(shù)的主成分,再通過(guò)聚類分析,構(gòu)建不同類型的行駛工況。文獻(xiàn)[8-11]以分類法分別構(gòu)建德黑蘭、上海、北京、普納等城市的行駛工況。但在劃分類別的過(guò)程中,是以各類別中的怠速、加速、減速、巡航工況所占時(shí)間比例,人為劃分最終的分類,無(wú)法確保構(gòu)建的行駛工況能代表實(shí)際道路的汽車行駛工況。馬爾科夫模型法將汽車行駛工況看作一個(gè)馬爾科夫過(guò)程,把汽車行駛過(guò)程抽象為離散的馬爾科夫過(guò)程,實(shí)際行駛工況被劃分為加速、減速、勻速和怠速 4種模型事件[12-14]。運(yùn)用馬爾科夫模型合成目標(biāo)行駛工況,構(gòu)建精度較高,其缺陷在于只能對(duì)整體數(shù)據(jù)進(jìn)行分析,無(wú)法針對(duì)不同道路類型的行駛工況分別進(jìn)行構(gòu)建。
隨著城市規(guī)模和路網(wǎng)的日益擴(kuò)張,城市道路的構(gòu)成比傳統(tǒng)的城區(qū)道路更加復(fù)雜,不僅包含由短行程片段反映的傳統(tǒng)城市中心區(qū)域,還包含大量長(zhǎng)行程片段的城市快速路、環(huán)線路等。針對(duì)此變化情況,本文提出一種基于 K均值聚類法與馬爾科夫模型法相結(jié)合的工況構(gòu)建方法,該方法能較好適應(yīng)當(dāng)前城市混合道路行駛工況的構(gòu)建。為使采集的數(shù)據(jù)真實(shí)反映城市混合道路汽車的行駛特點(diǎn),本文利用5輛不同型號(hào)輕型車按照各自目的,以自主駕駛法進(jìn)行數(shù)據(jù)采集。所提方法既能區(qū)分出不同道路類型的行駛工況,又保證工況的構(gòu)建精度,滿足目前城市混合道路行駛工況的構(gòu)建,對(duì)于探索當(dāng)前城市汽車行駛工況的構(gòu)建具有重要意義和實(shí)用價(jià)值。
1 基礎(chǔ)理論
1.1 運(yùn)動(dòng)學(xué)片段
汽車行駛過(guò)程中,受道路交通條件的限制,存在著多次怠速、加速、巡航和減速的狀態(tài)。通常將一個(gè)怠速開始到下一個(gè)怠速開始前的片段定義為一個(gè)運(yùn)動(dòng)學(xué)片段,如圖1所示。車輛的行駛過(guò)程可以看成多個(gè)運(yùn)動(dòng)學(xué)片段的組合,因此通過(guò)分析每個(gè)運(yùn)動(dòng)學(xué)片段的行駛特征參數(shù),可以分析出該車輛的行駛特征。
1.2 主成分分析
為了評(píng)估每個(gè)運(yùn)動(dòng)學(xué)片段的行駛特征,選用如表1所示的 15個(gè)特征參數(shù)來(lái)描述運(yùn)動(dòng)學(xué)片段,以保證特征信息不丟失。但是過(guò)多特征參數(shù)的選用必然導(dǎo)致信息重疊,采用主成分分析法可以探索哪些特征參數(shù)是評(píng)估行駛特征的主要參數(shù),從而達(dá)到降維的目的。
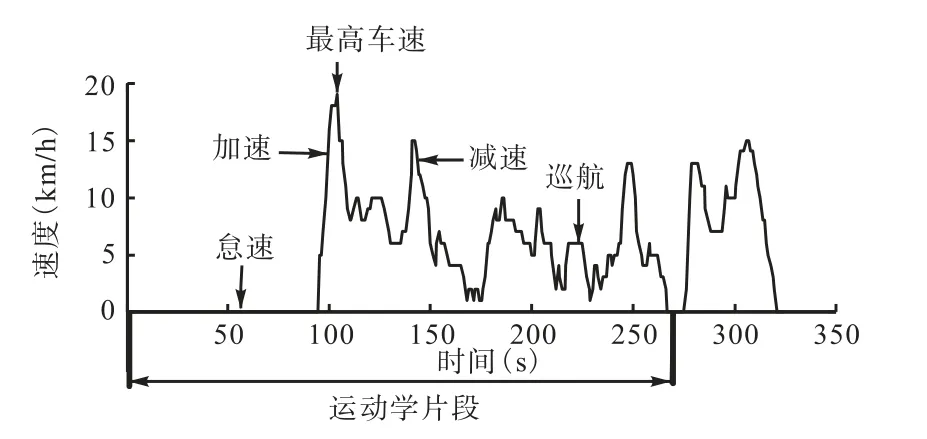
圖1 運(yùn)動(dòng)學(xué)片段Fig.1 Kinematic fragments

表1 用于分類的15個(gè)特征參數(shù)Tab.1 15 characteristic parameters for classification
1.3 K均值聚類分析
聚類分析(Clustering Analysis)是將某個(gè)對(duì)象集劃分為若干組的過(guò)程;K均值聚類分析能使相同類內(nèi)具有較高的相似度,而不同類間的相似度較低。
具體過(guò)程為:
①針對(duì)n個(gè)樣本按照某種原則選取K個(gè)樣本作為初始聚類中心(z1,z2,…,zK)。
②歐式距離可以很好地計(jì)算各類間整體距離,即不相似性。應(yīng)用歐式距離將任意樣本 xi分配到距離它最近類的中心,其中歐式距離的計(jì)算公式如下:

③重新計(jì)算每個(gè)類別中樣本的平均值,用此平均值作為新的聚類中心。
④重復(fù)以上步驟,至聚類中心不再發(fā)生變化。
1.4 馬爾科夫過(guò)程
汽車的行駛過(guò)程可以看作離散的馬爾科夫過(guò)程,記為Zτ(τ=1,2,…,T),Zτ代表每個(gè)模型事件τ,狀態(tài)空間是收集了相似的模型事件編入事件組的集合。對(duì)于模型事件τ和所有的狀態(tài) S1,S2,…,Sτ,當(dāng)前時(shí)間下 Sτ的概率只與前一狀態(tài) Sτ-1有關(guān),離散的馬爾科夫過(guò)程在一定時(shí)間下具有穩(wěn)定性和齊次性,若明確了當(dāng)前時(shí)刻的取值,則過(guò)去時(shí)刻的取值不會(huì)影響未來(lái)時(shí)刻的取值。對(duì)于從任意狀態(tài)r到狀態(tài)s有:


對(duì)于一個(gè)固定的馬爾科夫過(guò)程,根據(jù)最大似然函數(shù)得到狀態(tài)的轉(zhuǎn)移概率方程:

式中:Nrs為時(shí)間為τ-1時(shí)狀態(tài) r轉(zhuǎn)移到時(shí)間為τ時(shí)狀態(tài)s的事件數(shù)。
1.5 工況構(gòu)建方法的處理流程
以馬爾科夫模型構(gòu)建汽車行駛工況時(shí),普遍做法是應(yīng)用最大似然估計(jì)法實(shí)現(xiàn)汽車行駛數(shù)據(jù)的狀態(tài)劃分,通過(guò)分析行車數(shù)據(jù),可以發(fā)現(xiàn)整個(gè)行車過(guò)程基本是在加速狀態(tài)、減速狀態(tài)、巡航狀態(tài)、怠速狀態(tài)間不斷切換。因此本文在構(gòu)建工況時(shí),直接采用這 4種狀態(tài)對(duì)源數(shù)據(jù)進(jìn)行劃分,簡(jiǎn)化工況構(gòu)建流程。具體構(gòu)建流程如圖2所示。

圖2 工況構(gòu)建流程Fig.2 Construction process of driving cycle
2 汽車行駛工況的構(gòu)建
2.1 數(shù)據(jù)采集
將數(shù)據(jù)采集車載終端(圖3)與車輛的OBD接口相連接,在汽車行駛過(guò)程中以 1Hz的頻率采集包括車速、發(fā)動(dòng)機(jī)轉(zhuǎn)速、扭矩百分比、瞬時(shí)油耗、發(fā)動(dòng)機(jī)負(fù)荷、GPS定位等參數(shù)信息。
通過(guò)信息化數(shù)據(jù)平臺(tái)對(duì)車輛進(jìn)行實(shí)時(shí)監(jiān)測(cè),確保采集數(shù)據(jù)的連續(xù)性和正確性。為使采集的數(shù)據(jù)真實(shí)反映城市混合道路汽車的行駛特點(diǎn),本文利用 10輛不同型號(hào)輕型車按照各自目的,以自主駕駛法采集數(shù)據(jù),采集的數(shù)據(jù)包含一周內(nèi)各個(gè)時(shí)間段共 572864s的有效行駛數(shù)據(jù)。車輛的行駛路線(圖4)涵蓋福州市區(qū)各主干道、環(huán)城快速路以及環(huán)線高速,能夠充分反映福州市城區(qū)混合道路的交通情況。

圖3 終端安裝效果圖Fig.3 Terminal installation
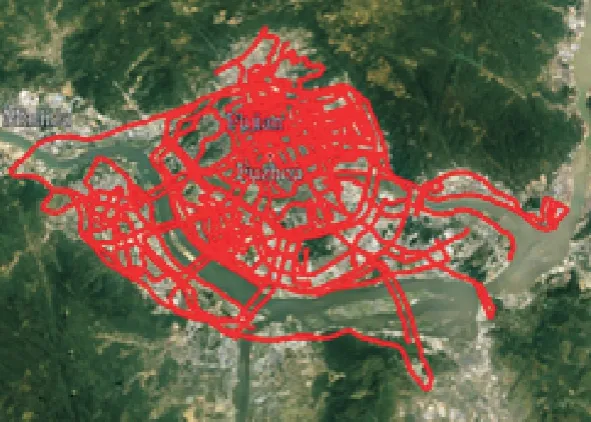
圖4 路線覆蓋圖Fig.4 Route coverage map
2.2 試驗(yàn)數(shù)據(jù)分析
為了真實(shí)反映實(shí)際道路的汽車行駛工況,對(duì)采集到 572864s的數(shù)據(jù)進(jìn)行分析。由于試驗(yàn)車輛為正常道路上行駛的汽車,其最大加速度一般不大于2.5m/s2,造成采集試驗(yàn)數(shù)據(jù)中出現(xiàn)加速度大于2.5m/s2的原因是汽車振動(dòng)導(dǎo)致 GPS漂移,使得數(shù)據(jù)精度受到影響,因此在數(shù)據(jù)前期處理過(guò)程中將加速度大于 2.5m/s2的數(shù)據(jù)點(diǎn)剔除,處理后的數(shù)據(jù)通過(guò)切分可以得到 2860個(gè)運(yùn)動(dòng)學(xué)片段,并計(jì)算出各運(yùn)動(dòng)學(xué)片段的15個(gè)特征變量。
2.3 主成分分析結(jié)果
在對(duì)特征參數(shù)進(jìn)行主成分分析時(shí),由于采集數(shù)據(jù)量較大,采用 SPSS軟件進(jìn)行分析,各主成分的貢獻(xiàn)率及累積貢獻(xiàn)率見表2。

表2 主成分貢獻(xiàn)率及累積貢獻(xiàn)率Tab.2 Principal component contribution rate and cumulative contribution rate
理論上,進(jìn)行主成分分析時(shí),選取累積貢獻(xiàn)率大于 80%的主成分進(jìn)行后續(xù)的聚類分析,雖然會(huì)有一定的信息損失,但對(duì)最終的結(jié)果影響較小[15]。由表3可知,前 3個(gè)主成分的特征值大于 1,且其累積貢獻(xiàn)率達(dá)到 90.483%,可以代表15個(gè)特征變量的基本信息,因此選取前3個(gè)主成分進(jìn)行分析。

表3 主成分載荷矩陣Tab.3 Principal component load matrix
前3個(gè)主成分的載荷矩陣如表3所示,可看到各主成分與15個(gè)特征變量之間的相關(guān)系數(shù)。由表3中各個(gè)主成分與特征變量相關(guān)系數(shù)的大小可以得出以下結(jié)論:①第 1主成分主要反映片段持續(xù)時(shí)間、片段行駛距離、平均速度、平均行駛速度、最大加速度、加速時(shí)間、減速時(shí)間、巡航時(shí)間、最高車速、速度標(biāo)準(zhǔn)偏差;②第 2主成分主要反映平均加速度、平均減速度、加速度標(biāo)準(zhǔn)偏差;③第 3主成分主要反映怠速時(shí)間。
2.4 K均值聚類分析及結(jié)果
運(yùn)用 K均值聚類分析方法對(duì)所有的運(yùn)動(dòng)學(xué)片段進(jìn)行2類、3類、4類聚類分析;并根據(jù)K均值聚類分析的結(jié)果,運(yùn)用 Silhouette函數(shù)繪制輪廓圖,如圖5所示。橫坐標(biāo)表示 Silhouette值,縱坐標(biāo)表示聚類的類別編號(hào),其中Silhouette函數(shù)的定義如下:

圖5 不同分類Silhouette函數(shù)值的輪廓Fig.5 Outline of different classification Silhouette function values
式中:a為第 i個(gè)運(yùn)動(dòng)學(xué)片段與同類運(yùn)動(dòng)學(xué)片段之間的平均距離;b為向量,其元素是第 i個(gè)運(yùn)動(dòng)學(xué)片段與不同類的類內(nèi)各運(yùn)動(dòng)學(xué)片段間的平均距離。
L(i)的取值范圍為[-1,1],其值越大,說(shuō)明第i個(gè)運(yùn)動(dòng)學(xué)片段分類越合理;當(dāng) L(i)<0時(shí),說(shuō)明第 i個(gè)運(yùn)動(dòng)學(xué)片段分類不合理,還有比目前更好的分類。
當(dāng)將運(yùn)動(dòng)學(xué)片段按照K均值聚類分析分為3類時(shí),絕大多數(shù)運(yùn)動(dòng)學(xué)片段具有較高的 Silhouette值,因此選取將運(yùn)動(dòng)學(xué)片段分為3類作為最終的分類結(jié)果。
不同類樣本聚類的特征參數(shù)如表4所示,其中,第2類的平均速度較大,為56.361km/h,而怠速時(shí)間比例僅為 8.1%,為保持較高車速行駛的高速道路工況。第3類和第2類的加減速時(shí)間比例相近,加速工況的時(shí)間比例分別為 27%和 30.4%,但由于第 3類出現(xiàn)的怠速情況較第 2類多,其平均車速較低,平均加速度也比第 2類大,代表較暢通的環(huán)城快速路工況。第 1類的平均車速最低,僅為 14.674km/h,且怠速時(shí)間比例和平均加速度均為 3類最大,分別達(dá)到32.6%和 30.531m/s2,代表急加速、較擁堵的市區(qū)道路工況。由此可以說(shuō)明這3類各自代表著不同的汽車行駛狀態(tài)。

表4 各類別特征參數(shù)Tab.4 Characteristic parameters of various categories
2.5 馬爾科夫過(guò)程分析
汽車行駛工況可以當(dāng)作離散的馬爾科夫過(guò)程。換言之,下一時(shí)刻出現(xiàn)怠速、巡航、加速或減速狀態(tài),只與當(dāng)前的汽車行駛狀態(tài)相關(guān),而與前一時(shí)刻的狀態(tài)無(wú)關(guān)。根據(jù)公式(4)分別計(jì)算類別 1、類別 2、類別 3各自加速工況、減速工況、巡航工況以及怠速工況間的轉(zhuǎn)移概率矩陣,計(jì)算結(jié)果見表5。
第 1類工況的平均車速較低,為市區(qū)擁擠道路,因此在加減速工況后轉(zhuǎn)化為巡航工況的概率都最低;第 2類工況則正好相反,路況較好,平均車速最高,怠速比例很低,在加減速狀態(tài)后轉(zhuǎn)化為巡航工況的概率最高;而第 3類平均車速介于第 1類和第 2類之間,在加減速工況后轉(zhuǎn)化為巡航工況的概率也介于二者之間。
2.6 候選汽車行駛工況的構(gòu)建
首先根據(jù)聚類分析結(jié)果分別計(jì)算類別 1、類別 2、類別 3的時(shí)間長(zhǎng)度占總體數(shù)據(jù)時(shí)間長(zhǎng)度的比例;接著,根據(jù)這些時(shí)間比例確定各類在1200s的候選工況中所擁有的時(shí)間長(zhǎng)度;最后,根據(jù)各類別所對(duì)應(yīng)的轉(zhuǎn)移概率矩陣確定汽車行駛狀態(tài),合成相應(yīng)時(shí)間長(zhǎng)度的候選汽車行駛工況。

表5 各類別運(yùn)動(dòng)學(xué)片段轉(zhuǎn)移概率矩陣Tab.5 Kinematic fragment transition probability matrix of various categories
在汽車候選工況的合成過(guò)程中需要遵循以下原則:①根據(jù)汽車行駛狀態(tài)的轉(zhuǎn)移概率矩陣確定起始片段,速度可以是0km/h或者任何速度大小;②下一個(gè)行駛狀態(tài)由轉(zhuǎn)移概率矩陣和當(dāng)前的汽車行駛狀態(tài)確定。根據(jù)上述原則,不斷地判斷下一狀態(tài),直到所構(gòu)建的工況滿足設(shè)定的長(zhǎng)度和精度的要求。
2.7 汽車行駛工況的篩選標(biāo)準(zhǔn)
在汽車行駛工況構(gòu)建過(guò)程中,合成了大量候選工況,為了從這些候選工況中選取具有代表性的汽車行駛工況,一般采用最小性能值 PV(Performance Value)作為篩選代表性工況的標(biāo)準(zhǔn)[11]。本文提出以綜合參數(shù)值 CPV(Comprehensive ParameterValue)作為評(píng)價(jià)標(biāo)準(zhǔn)。該標(biāo)準(zhǔn)包含 6個(gè)特征參數(shù):加速時(shí)間比例、巡航時(shí)間比例、怠速時(shí)間比例、平均速度、加速度標(biāo)準(zhǔn)偏差、平均加速度。上述 6個(gè)參數(shù)在主成分分析中與3個(gè)主成分具有較強(qiáng)的相關(guān)性,能充分體現(xiàn)工況特征。此外還考慮了候選工況與原始數(shù)據(jù)的最大SAFD(Speed- Acceleration Frequency Distribution)差異值。
綜合參數(shù)值CPV的公式如下:

式中:Za表示原始數(shù)據(jù)的加速時(shí)間比例;Zi表示原始數(shù)據(jù)的怠速時(shí)間比例;Zc表示原始數(shù)據(jù)的巡航時(shí)間比例;V表示原始數(shù)據(jù)的平均速度;Aa表示原始數(shù)據(jù)的平均加速度;Astd表示原始數(shù)據(jù)的加速度標(biāo)準(zhǔn)偏差;CSAFD表示候選工況與原始數(shù)據(jù)最大 SAFD差異值;Δ表示合成工況與原始數(shù)據(jù)對(duì)應(yīng)參數(shù)的差異值。其他未說(shuō)明參數(shù)與表1定義一致。
由公式(6)可知,CPV值是候選工況與原始數(shù)據(jù)各代表參數(shù)差異率的代數(shù)和。CPV值越小,候選工況與實(shí)際行駛狀態(tài)相似性越高,反之則相似性越低。
計(jì)算全部候選汽車行駛工況的 CPV值,選取CPV值最小的候選工況作為目標(biāo)行駛工況。根據(jù)最小 CPV值得出 1200s的代表行駛工況(圖6),其中類別1代表市區(qū)道路占45%(540 s),類別2代表市郊道路占 23%(372 s),類別 3代表高速道路占32%(288 s)。
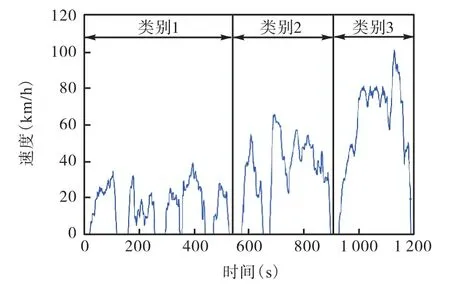
圖6 1200s代表工況Fig.6 Representative driving cycle of 1200s
3 結(jié)果分析
將構(gòu)建的目標(biāo)行駛工況與實(shí)際采集數(shù)據(jù)的特征參數(shù)進(jìn)行對(duì)比,各特征參數(shù)的差異率都維持在 6.5%范圍之內(nèi),具體結(jié)果見表6。進(jìn)一步分析試驗(yàn)數(shù)據(jù)和所構(gòu)建行駛工況的 SAFD的差異率,各速度和加速度的分布區(qū)間上差異率都維持在 5%以內(nèi)(圖7),說(shuō)明所構(gòu)建行駛工況能夠代表實(shí)際道路車輛的行駛特征。
將合成的福州市綜合行駛工況(FZDC)與國(guó)外主要標(biāo)準(zhǔn)循環(huán)工況進(jìn)行對(duì)比,從表7中可以看出,合成的行駛工況有自己的特點(diǎn)。例如加速時(shí)間比例與國(guó)外輕型車測(cè)試循環(huán)(WLTC)較為接近,卻明顯高于國(guó)內(nèi)測(cè)試采用的NEDC測(cè)試循環(huán),而在平均車速方面,則與NEDC以及美國(guó)城市工況(UDDS)較為接近,且平均加速度也近似。這些特征表明,即使平均車速和平均加速度接近,但是加減速、巡航、怠速的比例卻各異,主要因?yàn)槟壳拔覈?guó)城市道路交通條件要比其他國(guó)家復(fù)雜,路況及駕駛習(xí)慣等影響汽車行駛的因素太多,也更加說(shuō)明各個(gè)城市的代表行駛工況并不具有普遍適用性。
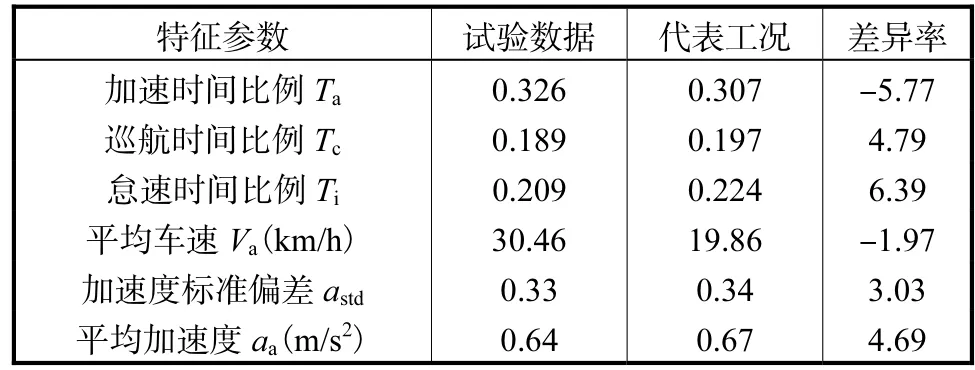
表6 特征參數(shù)差異率對(duì)比Tab.6 Comparison of characteristic parameter difference rates
4 結(jié) 論
①本文以福州市城區(qū)混合道路乘用車的實(shí)際行駛數(shù)據(jù)為研究對(duì)象,通過(guò)主成分分析方法實(shí)現(xiàn)特征變量矩陣的降維,采用 K均值聚類分析方法進(jìn)行聚類分析,利用 Silhouette函數(shù)篩選最終聚類結(jié)果,減少人為類別判定過(guò)程中的誤差,并從采集到的城市混合道路實(shí)時(shí)行駛數(shù)據(jù)中區(qū)分出不同道路類型。
②基于馬爾科夫模型法合成各類汽車行駛工況,按各個(gè)類別的比例構(gòu)建最終行駛工況,提出以6個(gè)特征參數(shù)和 SAFD差異值的綜合參數(shù)篩選代表性的目標(biāo)行駛工況。所構(gòu)建的福州市綜合行駛工況和試驗(yàn)車輛采集數(shù)據(jù)的SAFD差異率能控制在5%以內(nèi),說(shuō)明該方法合成的代表工況能夠很好表達(dá)城市混合道路工況的總體特征。
猜你喜歡
人民交通(2020年22期)2020-11-26 07:36:44
小學(xué)生優(yōu)秀作文(低年級(jí))(2020年4期)2020-07-24 08:31:08
汽車與安全(2019年9期)2019-11-22 09:48:03
汽車與安全(2019年8期)2019-09-26 04:49:10
汽車與安全(2019年5期)2019-07-30 02:49:51
汽車觀察(2019年2期)2019-03-15 06:00:06
汽車與新動(dòng)力(2018年2期)2018-05-09 00:31:56
兒童時(shí)代·快樂(lè)苗苗(2017年7期)2018-01-24 18:28:45
作文大王·低年級(jí)(2016年4期)2016-04-18 00:24:37
決策探索(2014年21期)2014-11-25 12:29:50
