Vine-GAS-Copula模型的統計推斷
2019-12-23 03:23:40
福建質量管理 2019年22期
(中央民族大學理學院 北京 100081)
一、引言
受經濟全球化、金融一體化以及人類命運共同體的影響,金融市場之間的相互依賴和相互影響與日俱增,對金融市場之間相關性的研究已成為現代金融分析的重要內容。近年來,由于傳統的金融模型無法滿足金融結構的建模需求,一種研究隨機變量間非線性相關結構的統計方法——Copula 函數在經濟金融領域得到廣泛應用。Copula函數理論的出現為分析多元金融時間序列提供了一種新的思維模式,與傳統度量相關性的方法相比,它有以下幾個優勢:首先,Copula函數推導的Spearman相關系數ρ和Kendall相關系數τ等在嚴格單調遞增的情況下保持不變,即在變量存在非線性相關的條件下,該相關性指標也可以應用。其次,Copula函數可以把分布不同的邊緣分布函數連接起來構造聯合分布函數,在實際應用時,我們可以分開討論變量的邊緣分布和變量間的相關性,從而Copula函數可以與時間序列模型獨立的結合,故相比其他金融模型運用更靈活。最后,Copula函數可以有效處理尾部相關問題。Copula理論對金融時間序列的建模多局限于二維的情況下,對于高維情況的使用也僅限于多元高斯Copula函數和多元t-copula函數。而這兩種copula函數都需假定多元金融時間序列的邊緣分布均為正態分布或t分布,因此不能很好地估計序列間的相依結構。Bedford和Cooke(2002)首次采用圖形建模工具中“藤”的層疊結構,將高維Copula函數分解為一系列Pair-Copula函數,更好的描述了多元金融時間序列間的相依結構。
在實際中,隨著科技發展的日新月異,金融市場會根據外部市場環境的瞬息萬變與國家宏觀經濟政策的調整而改變,因而金融市場之間的相關關系會隨著時間的推移而發生變化,即金融市場之間的相關性具有顯著的時變特征。時變相關的Copula模型,其Copula模型的形式是不變的,但模型中的參數是隨時間變化的。構建這種模型關鍵在于要給出Copula函數的相關參數的演化方程,由于許多Copula函數的參數與相關性度量或尾部相關系數有一一對應的關系,因此要構建時變相關的Copula模型,我們可以通過確立Copula函數相關性度量的演化過程來建立其參數的演化方程。在時變 Copula 函數的理論研究方面,已有文獻主要集中于二維時變 Copula 的建模研究,主要是假設Copula函數的參數是時間的某個確定函數,進而對時變參數進行建模,例如Patton(2006)提出二維Copula函數的當前相關性可以通過歷史相關性和兩個變量累積概率的歷史平均值來解釋。此外,也有學者認為Copula函數的參數是時間的未知函數,可以通過非參數估計的方法對時變參數進行建模,例如龔金國和史代敏提出用經驗分布函數-局部極大似然法(ECDF-LML)來估計Copula函數中的時變參數。本文主要借鑒Creal等提出的廣義自回歸得分(GAS)模型的思想,即用似然函數的比例分數來更新時變參數,以此建立參數的時變過程。該理論是一種數據驅動時變參數的理論建模方法,其為非線性時間序列模型引入時變參數提供了統一框架。
二、基于GAS理論的時變Vine-Copula模型
由Sklar定理可知:設F(·)為隨機向量X=(X1,X2,…,Xn)∈Rn的聯合分布函數,Fi(·)是隨機變量Xi的邊緣分布函數,i=1,…,n,則存在一個Copula函數C(·),滿足:
F(x1,…,xn)=C(F1(x1),…,Fn(xn))
當且僅當Fi(·),i=1,…,n連續時,Copula函數唯一確定。
(一)Vine-Copula模型
對于n維隨機向量的聯合分布,由于不同的分解形式會有不同的Pair-Copula結構,為了使選擇的Pair-Copula結構更符合邏輯,Bedford和Cooke(2001,2002)引入了一種圖形建模工具——正則藤(R-vine),包含節點、邊和樹結構。常用的R-vine包括C-vine和D-vine。對于Vine結構的選擇,可以通過計算變量之間的Kendall秩相關系數來確定使用C-Vine建模還是使用D-Vine建模,也可以通過對比建立Vine結構之后模型的AIC值來確定模型最終采用的Vine結構。
C-Vine中,每棵樹有唯一的節點連接其他節點,即主節點之外的其他節點僅連接一條邊。對于n維隨機向量X=(X1,X2,…,Xn),若變量Xi與其他變量的相關性顯著大,即存在關鍵變量Xi能引導其他變量,此時用C-Vine建模較為合適。
n維隨機向量X的C-Vine結構的聯合密度函數為:
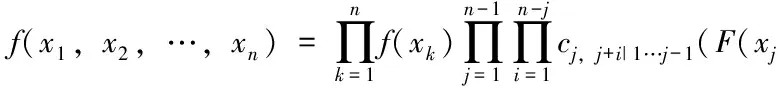

圖1 4維情況下的C-vine Copula結構分解圖
圖1展示的是在4維情況下的C-Vine Copula的結構分解圖,可以看出,它包含3棵樹Tj,j=1,2,3,每棵樹Tj有5-j個節點和4-j條邊,每條邊都對應一個Pair-Copula函數。圖1對應的聯合密度函數可分解為:
f(x1,x2,x3,x4)=f1(x1)*f2(x2)*f3(x3)*f4(x4)*c12(F1(x1),
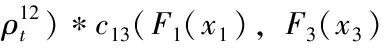

其中:

D-Vine中,每棵樹的任意節點最多連接兩條邊。對于n維隨機向量X=(X1,X2,…,Xn),若變量之間的相關性相差不大,即變量之間相對獨立,此時用D-Vine建模較為合適。
n維隨機向量X的D-Vine結構的聯合密度函數為:

F(xj+i|xi+1,…,xi+j-1)
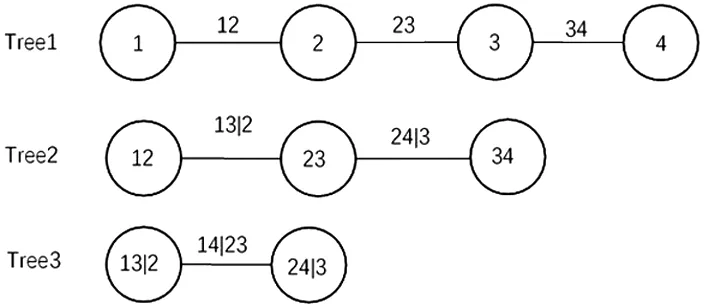
圖2 4維情況下的D-vine Copula結構分解圖
圖2展示的是在4維情況下的D-Vine Copula的結構分解圖,與C-Vine Copula類似,它也包含3棵樹Tj,j=1,2,3,每棵樹Tj有5-j個節點和4-j條邊,每條邊都對應一個Pair-Copula函數。圖2對應的聯合密度函數可分解為:
f(x1,x2,x3,x4)=f1(x1)*f2(x2)*f3(x3)*f4(x4)*c12(F1(x1),
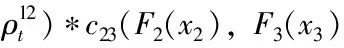

(二)Vine-GAS-Copula模型
本文主要借鑒Creal等提出的廣義自回歸得分(GAS)模型的思想,即用似然函數的比例分數來更新時變參數,以此建立參數的時變過程。該理論是一種數據驅動時變參數的理論建模方法,其為非線性時間序列模型引入時變參數提供了統一框架。
二元Copula GAS(p,q)時變參數的演變模式如下:
其中,αt為Copula函數在t時刻的參數向量,Λ(·)為修正的logistic轉換函數,以保證參數取值落入所屬Copula函數參數的定義域內;ω為截距向量,Ai、Bj為系數矩陣,i=1,…,p;j=1,…,q;c(·)為Copula函數的密度函數,t是得分向量,即Copula對數似然函數關于參數ft的導數;St是比例矩陣,這里定義為Copula對數似然函數關于參數ft的信息矩陣的逆。
對于n維C-Vine Copula的聯合密度函數,有
f(y1,y2,…,yn)=c(F1(y1),…,Fn(yn);θ)·f1(y1)·…·fn(yn)
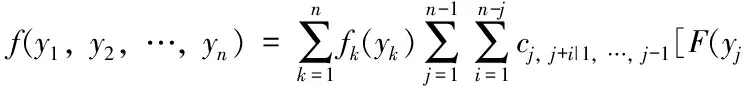
因此,可以得到其對數似然函數:
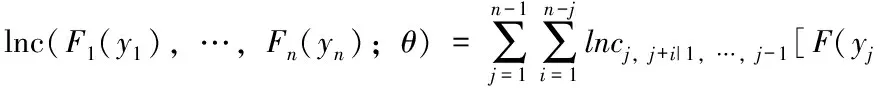
F(yj+i│Ij-1);θj,j+i]
將上式對參數θ(j,j+i)求導,有:
由上式可以得出,求解n維C-Vine Copula聯合密度函數的參數θj,j+i可以等價于求解對應Pair-Copula密度函數的參數,即關于時變θj,j+i的信息可以從包含它的Pair-Copula的似然函數中得到。綜上我們可以得到基于GAS理論的時變C-Vine Copula模型,記為C-Vine-GAS-Copula模型,D-Vine-GAS-Copula模型類似。
(三)Vine-GAS-Copula模型的估計

三、實證分析
本文選取2013.5-2019.6富時指數、上證指數、深證指數、道瓊斯指數的日收盤價作為研究對象,并采用對數收益進行分析:
rt=lnpt-lnpt-1
(一)統計檢驗
1.描述性統計
對數收益序列的主要統計特征及直方圖如下所示:

富時上證深證道瓊斯Minimum-9.74363-8.87291-8.60356-9.1253Maximum6.8266515.6036126.2541886.071573Mean0.031520.017189-0.001410.024232Median0.0034620.065040.0360730.071682Variance2.4303272.1469842.9847652.361412Stdev1.558951.4652591.7276471.536689Skewness-0.52817-1.12059-0.84607-1.05486Kurtosis5.4822336.7822054.1217916.381867J-B檢驗1941.793177.151236.9452813.544(p-Value)<2.2e-16<2.2e-16<2.2e-16<2.2e-16

圖3對數收益序列的直方圖
四個序列偏度均小于0,分布均有長的左拖尾。峰度均高于正態分布峰值3,說明具有尖峰厚尾的特征。同時J-B統計量均拒絕服從正態分布假設。
2.時序圖

圖4 對數收益序列的時序圖
四個對數收益序列的時序圖均存在波動聚集性,即四個序列均可觀察到波動的“集群”現象,波動在一段時間內較小,在有的時間段內非常大。
3.ADF檢驗和L-B檢驗

表2 ADF檢驗

表3 Ljung-Box檢驗
四個序列均通過ADF檢驗和L-B檢驗,即序列均為平穩非白噪聲序列,可以進行ARIMA建模。
4.ARCH效應檢驗
根據AIC信息準則確定序列擬合的最優ARMA模型均是ARMA(3,2),對殘差序列進行ARCH效應檢驗:

表4 ARCH LM檢驗
所有序列的殘差都存在 ARCH 效應。故可以建立 GARCH 類模型擬合邊緣分布。
(二)邊際分布的確定
根據AIC信息準則確定序列擬合的最優ARMA-GARCH模型分別為:
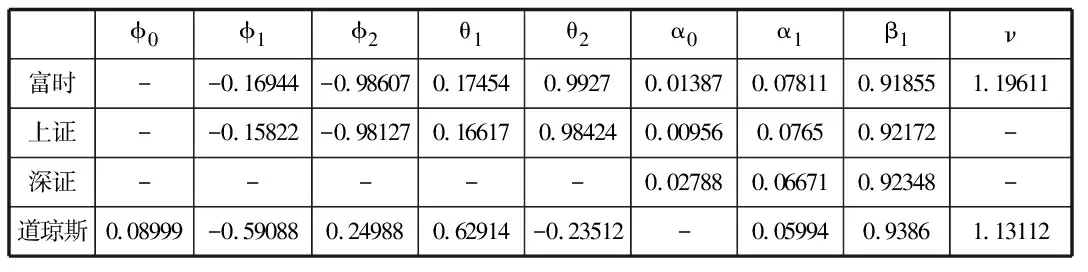
表5 最優ARMA-GARCH模型
對建模后的標準殘差序列進行ARCH效應檢驗,結果拒絕ARCH效應,表明標準殘差序列已無二階相關性,GARCH建模效果良好。
(三)Vine-GAS-Copula模型的建立
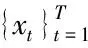
xt=μxt+εxt
εxt=σxtξxt
yt=μyt+εyt
εyt=σytξyt
(ξxt,ξyt)~Cξt(F(ξxt),F(ξyt))
運用Copula模型建立金融時間序列模型,可將研究收益序列之間的條件相關性簡化為研究殘差序列之間的相關性。
1.概率積分變換
對標準化殘差進行概率積分變換,K-S檢驗變化后的序列服從[0,1]上的均勻分布,故可以用來構建 Copula 函數。

表6 K-S檢驗
本文采用CML方法估計Copula函數的參數,先用經驗分布函數將原始數據(xt,yt)轉換為均勻分布變量序列(ut,vt),然后用極大似然估計對Copula函數進行參數估計:
2.Vine-GAS-Copula模型
根據標準化殘差之間的關系,本文采用二元時變高斯Copula來描述序列間的相關關系,其時變參數的演變模式為:
其中xt=[Φ-1(ut)]2+[Φ-1(vt)]2,yt=Φ-1(ut)Φ-1(vt)。
根據標準化殘差之間的相關性(表7),道瓊斯指數序列的標準化殘差(V4)與其他變量關系更為密切,符合C-Vine結構特征,應以V4為主節點對第一層進行建模,同樣,根據表8可以發現富時|道瓊斯(V1|4)與其他變量關系更密切,應以V1|4為主節點對第二層進行建模。綜上所述,得到C-Vine Copula結構分解圖:
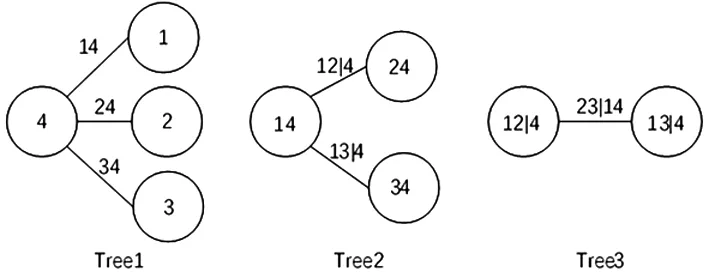
圖6 C-VineCopula結構分解圖

表7 樹1的Kendall秩相關系數

表8 樹2的Kendall秩相關系數
3.求解時變參數方法對比
采用AIC準則法對比求解時變參數的三種方法,由下表可以看出,把時變參數當做常數求值時,參數值相對穩定,其AIC值最大;用patton法求解時變參數時,參數值隨時間的變化明顯,其AIC值略小;用GAS法求解時變參數時,參數值隨時間的變化更明顯,其AIC值最小。
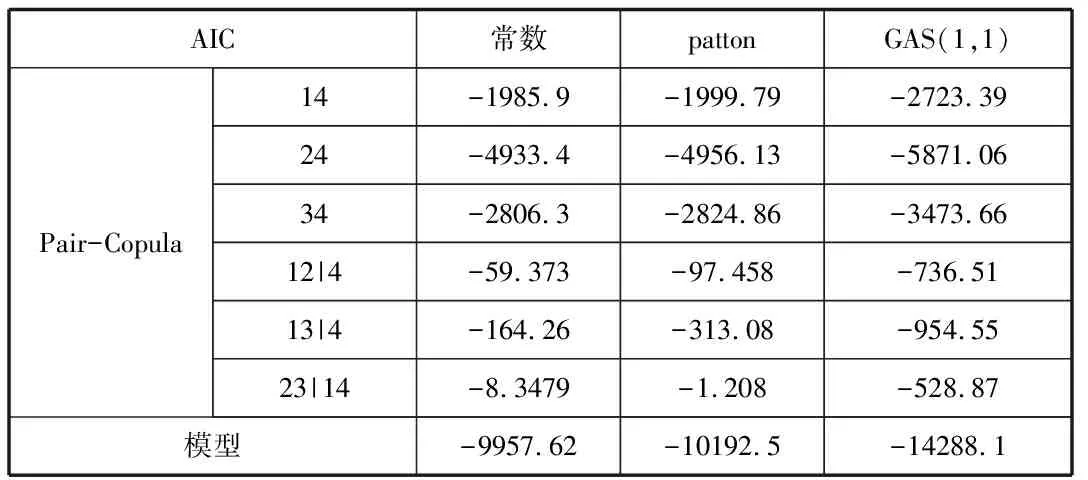
表9 不同時變參數的AIC值
四、研究結論
本文基于Vine-Copula結構與廣義自回歸得分(GAS)理論提出了Vine-GAS-Copula模型,對多元金融時間序列間的相依結構進行建模。實證結果表明,相比較于常值參數Copula模型與patton時變參數Copula模型,Vine-GAS-Copula模型對數據相關結構的擬合程度更好,這在一定程度上表明Vine-GAS-Copula模型可以很好地擬合時變的多元金融時間序列。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
哲學評論(2021年2期)2021-08-22 01:53:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
現代企業(2015年9期)2015-02-28 18:56:50
