基于MCNN的鐵路信號設(shè)備故障短文本分類方法研究
2019-12-18 06:30:08周慶華李曉麗
鐵道科學(xué)與工程學(xué)報 2019年11期
周慶華,李曉麗
基于MCNN的鐵路信號設(shè)備故障短文本分類方法研究
周慶華,李曉麗
(蘭州交通大學(xué) 電子與信息工程學(xué)院,甘肅 蘭州 730070)
鐵路運營維護中產(chǎn)生了大量非結(jié)構(gòu)化的文本數(shù)據(jù),針對這些文本信息,提出一種基于Word2Vec+MCNN的文本挖掘分類方法。首先采用Word2Vec訓(xùn)練故障詞向量;其次豐富詞向量矩陣信息,使網(wǎng)絡(luò)模型從多方位的特征表示中學(xué)習輸入句子的故障信息;最后使用多池化卷積神經(jīng)網(wǎng)絡(luò)模型作為故障分類的方法,得到更多全面的隱藏信息。通過與傳統(tǒng)分類器以及其他類型的多池化卷積神經(jīng)網(wǎng)絡(luò)模型實驗對比,得出本文的模型可以更好地達到分類效果,具有較高的分類準確率。
故障分類;信號設(shè)備;Word2Vec;卷積神經(jīng)網(wǎng)路

隨著信息技術(shù)以及存儲介質(zhì)的高速發(fā)展,人們所接觸的文本信息正在逐步遞增,在處理這些人工記錄的文本信息時,所消耗的時間和精力也越來越多。尤其是鐵路方面,鐵路信號系統(tǒng)在運營維護中產(chǎn)生海量故障數(shù)據(jù),這些故障現(xiàn)象描述等都以非結(jié)構(gòu)化的文本形式記錄,維修人員在處理故障時仍然依靠經(jīng)驗以及專家知識處理,這種方式經(jīng)常由于交流不當、延誤事故處理時間而導(dǎo)致重大安全隱患。這些故障文本記錄數(shù)量龐大,無論是電子版還是紙質(zhì)版在存儲上都帶來了不必要的負擔,并且維修維護以及管理人員都沒有對這些海量數(shù)據(jù)重視起來,未能合理利用,造成資源的堆積浪費。鐵路信號設(shè)備是行車安全的重要保障,在鐵路大數(shù)據(jù)應(yīng)用平臺下,使用文本挖掘技術(shù)分析故障文本,對故障信息準確分類,這既能對故障處理做到及時預(yù)判,又能對維護信號設(shè)備提供技術(shù)支撐,也為管理人員在存儲故障信息時提供便利。趙陽等[1]將文本挖掘技術(shù)運用在車載設(shè)備故障診斷中,楊連報等[2]對這些不平衡文本數(shù)據(jù)進行信號設(shè)備智能故障分類,利用文本挖掘技術(shù)處理鐵路信號設(shè)備故障診斷取得了些許成就。對于文本分類,傳統(tǒng)的分類方法有向量空間法、樸素貝葉斯和支持向量機算法[3]等。這些方法在文本分類中都取得了不錯的成果,但是由于部分數(shù)據(jù)維數(shù)過高、數(shù)據(jù)稀疏,往往不能正確表示,丟失大量詞語的語法信息和相關(guān)的語義信息。近年來,深度學(xué)習蓬勃發(fā)展,在自然語言處理中也得到了很好應(yīng)用。Mikolov等[4?5]利用Word2Vec工具在語料庫上進行訓(xùn)練,得到了短文本中詞的分布式表示。Mikolov等[6]提出提取多粒度主題的方案,可更好地描述短文本語義信息。Kim[7]將卷積神經(jīng)網(wǎng)絡(luò)應(yīng)用于句子模型的構(gòu)建中。Socher等[8]提出基于遞歸自編碼的半監(jiān)督學(xué)習模型,有效學(xué)習短文本中多詞短語及句子層次的特征向量表示。He等[9]采用多種不同類型的卷積和池化,實現(xiàn)對句子的特征表示。基于以上研究,本文針對鐵路故障文本記錄數(shù)據(jù),通過Word2Vec訓(xùn)練大量中文詞向量,構(gòu)建卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,簡稱CNN)模型,實現(xiàn)信號設(shè)備的故障分類。為提高分類準確率,本文提出采用并行的多池化卷積神經(jīng)網(wǎng)絡(luò)模型,確保獲取完整的故障信息,調(diào)整不同的參數(shù),提高分類效果。
1 文本數(shù)據(jù)預(yù)處理
鐵路信號設(shè)備主要包含調(diào)度集中CTC (Centralized Traffic Control)設(shè)備、列車調(diào)度指揮系統(tǒng)TDCS(Train Operation Dispatching Command System)設(shè)備、列車運行監(jiān)控裝置LKJ、車載設(shè)備、聯(lián)鎖設(shè)備、閉塞設(shè)備、道岔、軌道電路、信號機和電源屏設(shè)備[2]。本文按照設(shè)備功能及現(xiàn)象,選取某鐵路局2015~2016年所記錄的故障文本數(shù)據(jù)。根據(jù)目前已獲取的數(shù)據(jù),本文舍棄小類別數(shù)據(jù)以防止出現(xiàn)過擬合現(xiàn)象,基于已有的數(shù)據(jù)將故障類別分為4類,即車載設(shè)備故障、道岔故障、軌道電路故障和信號機故障。
圖1是使用卷積神經(jīng)網(wǎng)絡(luò)模型進行故障分類的流程圖。首先對故障文本使用Word2Vec詞向量化,訓(xùn)練好的詞向量矩陣作為卷積神經(jīng)網(wǎng)絡(luò)的輸入,使用本文提出的多池化卷積神經(jīng)網(wǎng)絡(luò)模型進行信號設(shè)備故障分類。
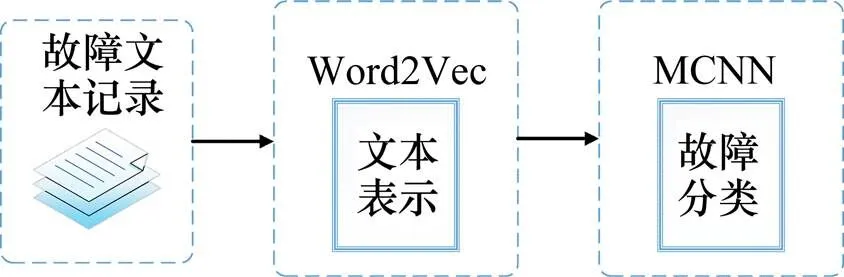
圖1 故障分類流程
1.1 故障詞庫
對于文本處理,首先需要對句子進行分詞。不同的語言文本,處理方法也是不同的。中文分詞便是將一個漢字序列(句子)切分成一個一個單獨的詞[10],句子的表示是否精確,也要看分詞是否準確,分詞精度對后續(xù)應(yīng)用影響很大[11]。
本文使用jieba分詞工具,對文本進行分詞。jieba分詞字典庫中對于鐵路信號設(shè)備故障文檔尚無這樣的標準詞庫,這就需要建立一個自定義的故障詞典庫。剔除“到”和“的”等無意義的虛詞,將對故障描述有意義的詞語保留[13]。詞典包括:“紅光帶、道岔”等詞。
1.2 Word2Vec
故障文本如何表示,關(guān)鍵是構(gòu)建詞向量空間。而Word2vec通過訓(xùn)練,可以把對文本內(nèi)容的處理簡化為K維向量空間中的向量運算,向量空間上的相似度可以用來表示文本語義上的相似度。Word2vec通常采用一個3層的神經(jīng)網(wǎng)絡(luò),輸入層?隱藏層?輸出層[12]。Word2Vec一般分為CBOW (Continuous Bag-of-Words)與Skip-gram 2種模型。
CBOW模型就是通過上下文詞來預(yù)測中心詞。而Skip-gram模型是利用中心詞來預(yù)測上下文詞。一般來說,CBOW模型算法效率高,而Skip-gram模型訓(xùn)練詞向量準確率高。對于進行鐵路信號設(shè)備故障分類時,為提高分類準確率,所以選擇Skip-gram模型。圖2是Skip-gram網(wǎng)絡(luò)模型。
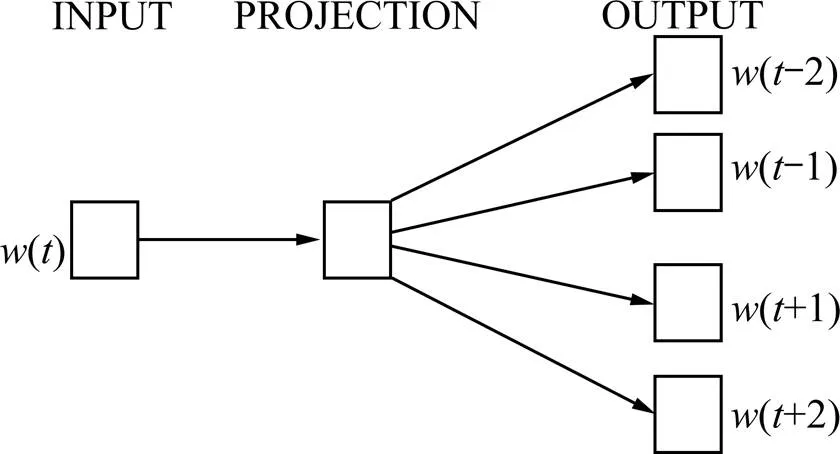
圖2 Skip-gram網(wǎng)絡(luò)模型圖
假設(shè)有一條分好詞的故障句子,產(chǎn)生了一系列詞(1),(2),…,()。Skip-gram模型的目的就是使式(1)的值最大化:
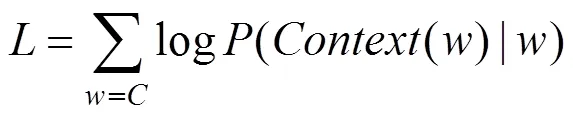
其中:表示窗口的長度,即當前詞()的前面的個詞和后面的的詞。
1.3 詞向量矩陣的生成
將句子經(jīng)過jieba分詞后,就形成了一個由多個詞所構(gòu)成的句子。分詞后的句子={1,2,3,…,m},它們之間都是以一個⊕來連接。長度為的句子就可以表示為:
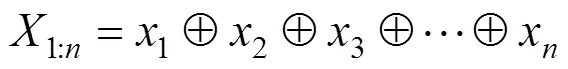
使用Skip-gram網(wǎng)絡(luò)模型,訓(xùn)練出詞向量。例如,“道岔”一詞,詞向量維數(shù)200維(一般維度高的詞向量可以更好地對語義特征進行描述,但同時也增大了過擬合的風險。本文數(shù)據(jù)都是以短文本為主,所以采用200維),對應(yīng)的詞向量[?1.322 135 78×10?1,1.723 149 23×10?2,…,2.073 596 42×10?1]。將所獲得詞向量縱向累加,得到了整句話的表示,也即獲得了詞向量矩陣。根據(jù)句子的最大長度,若為,則組合成一個*的二維矩陣,為詞向量維數(shù)。
2 基于多池化卷積神經(jīng)網(wǎng)絡(luò)故障分類
2.1 卷積神經(jīng)網(wǎng)絡(luò)
卷積神經(jīng)網(wǎng)絡(luò)是目前自然語言處理中應(yīng)用較為廣泛的一種深度學(xué)習結(jié)構(gòu),其網(wǎng)路層數(shù)深,網(wǎng)絡(luò)結(jié)構(gòu)復(fù)雜,存在多層隱藏層[13]。
整個網(wǎng)絡(luò)模型分為4層。
第1層是嵌入層(Embedding Layer)。對于數(shù)據(jù)集里所有的詞,每個詞都可以表示成一個向量,所以就得到了一個嵌入矩陣*(為文本的最大長度,為詞向量的維數(shù)),矩陣中的每一行詞向量代表一個完整的單詞。
第2層是卷積層(Convolution Layer)。對文本數(shù)據(jù)構(gòu)建卷積核時,卷積核的寬度應(yīng)該剛好等于輸入矩陣的寬度。將卷積核通過從上往下的滑動掃描整個數(shù)據(jù),得到卷積輸出。
對于窗口以為長度、為寬度的卷積核,當其作用于句子的第至(+?1)個單詞區(qū)間時,結(jié)果輸出可以用式(3)來形式化表示:
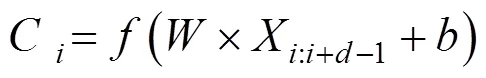
其中:是卷積核的權(quán)重參數(shù);是激活函數(shù);是卷積層的偏置項,∈R,即實數(shù)集,偏置項是一個常量,可以隨著模型的訓(xùn)練自動調(diào)整。最終的卷積輸出可以表示為式(4):
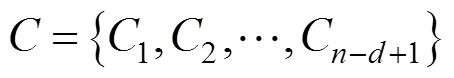
第3層是池化層(Max-Pooling Layer)。池化層主要是將卷積出來的特征向量進行處理,是不同長度的句子經(jīng)過卷積之后,特征向量變成定長的表示[14]。通常采用最大池化策略得到每一個卷積輸出向量的最大值,即得到了文本的特征表示[15]。將這些最大值連接,作為全連接層的輸入。這里的最大池化策略就是采用最大池化函數(shù),如式(5)所示:

第4層是全連接層。一般通過softmax函數(shù)得到每一個文本的分類。softmax函數(shù)如式(6):
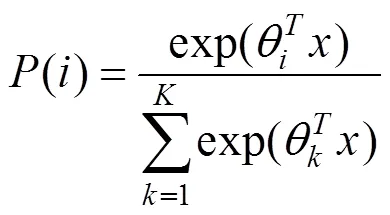
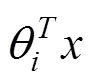
2.2 多池化卷積神經(jīng)網(wǎng)絡(luò)模型的故障分類
本文提出一種多池化的卷積神經(jīng)網(wǎng)絡(luò)模型,記為MCNN,以此更精確地進行故障分類。將每條故障記錄中特定的故障特征詞進行標記,讓模型充分利用對故障分類有重要作用的詞語,重點學(xué)習這些詞語的特征信息。重點標記的詞主要是對故障判別影響比較大的詞,例如故障現(xiàn)象描述:“接車線內(nèi)無機車車輛占用,控制臺顯示接車線軌道電路紅光帶,導(dǎo)致進站信號機不能開放”,對這句話以一個字符串序列的形式,對當中的“軌道電路”、“紅光帶”、“信號機”詞做標記,突出句子重點信息。通過向量化的操作,將標記的詞映射為一個維向量Tag,即Tag∈R,對沒有標記的記為0。同時,確定標記詞的位置。同一個詞出現(xiàn)的位置不同,所包含的信息也就不同。計算句子中第個標記詞的位置值[15],采用式(7):
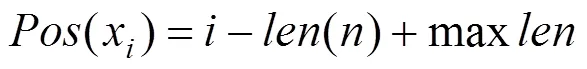
其中:Pos為標記詞在句子中的位置;為標記詞在句子中的位置;()為句子長度;max為輸入的句子最大長度[15]。將每個位置值映射到一個維向量,即Pos∈R ,其中,os為第個位置值的向量。本文對于句子的輸入設(shè)定一個最大長度max,對于長度小于max的句子用0向量補全。
本文以詞為單位,根據(jù)圖3所示,輸入層以詞向量矩陣1,詞向量與標記矩陣組成的組合矩陣2,詞向量,標記矩陣以及位置矩陣所組成的組合矩陣3,具體見式(8)~(10)所示。通過這3種矩陣,使得模型的輸入層更為多樣化,使得特征之間的聯(lián)系更為緊密,并且能更精確、更全面地捕獲到故障特征信息。
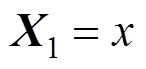
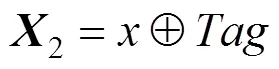
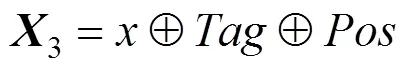
卷積層通過并行卷積操作獲得句子組合語義信息,經(jīng)過不同的卷積操作生成不同的特征,保留了詞與詞之間的聯(lián)系。
池化層中,傳統(tǒng)的CNN在池化操作中,對每個特征向量只能含一個最大值表示該句子的一個事件,而在故障診斷中,一個句子中可能含有2個或多個故障干擾詞語,所以本文通過多池化層來處理該問題。根據(jù)不同窗口大小的濾波器所得的特征向量,在進行池化時,采用并行的三池化方式,選擇最大池化函數(shù)和平均池化函數(shù)的組合方式。和傳統(tǒng)的CNN相比,MCNN在不丟失最大池化值的基礎(chǔ)上可以保留更多有價值的信息。其中,平均池化函數(shù)公式如下:
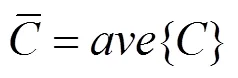
由多池化得到每個特征向量池化后的值,再將這些值連接一同送入全連接層。整個模型以并行化的方式提取特征,最后在全連接層輸出分類結(jié)果。
與傳統(tǒng)的卷積神經(jīng)網(wǎng)絡(luò)相比,MCNN模型在輸入時,以不同的特征組合形式輸入,可以使訓(xùn)練過程獲取更多語義信息,加強特征之間相互聯(lián)系,保證重要信息被提取到。同時,模型在訓(xùn)練過程中也能對多個特征進行參數(shù)調(diào)整,降低網(wǎng)絡(luò)模型訓(xùn)練損耗。卷積后使得模型學(xué)習到更加多樣化的信息。利用池化層對特征信息進行過濾提取時,使用并行的三池化方式,最大池化提取出經(jīng)卷積后的特征矩陣中最大值,平均池化函數(shù)提取出卷積后特征矩陣中的平均值。對這2種池化算法相結(jié)合,以三池化的方式,可以獲取比較全面的特征信息,不至于忽略掉次要信息。
3 實驗分析
3.1 實驗準備
本文實驗的測試環(huán)境是在Windows10系統(tǒng)下進行,使用的CPU是Inter Core i7-8750H 2.2 GHZ,內(nèi)存8 GB,編程語言為Python3.5.4,開發(fā)工具為Pycharm,使用到的深度學(xué)習框架為Tensorflow。使用Python提供的gensim庫,完成文檔的詞向量化。
本文對之前所提取到的故障數(shù)據(jù)總共3 204條,將其中的3 000條作為訓(xùn)練集,204條作為測試集,通過損失率和準確率評價指標對比分析。
3.2 實驗評價標準
本文主要以準確率(Accuracy)作為評價指標。正確率是最常見的評價指標,通常說,正確率越高,分類器越好。分類正確率是分類器正確分類樣本數(shù)與測試數(shù)據(jù)集總樣本數(shù)之比。
3.3 實驗設(shè)計
本文采用Word2Vec+MCNN模型,這里的Word2Vec用到的是Skip-gram模型,對鐵路設(shè)備故障數(shù)據(jù)進行了分類。
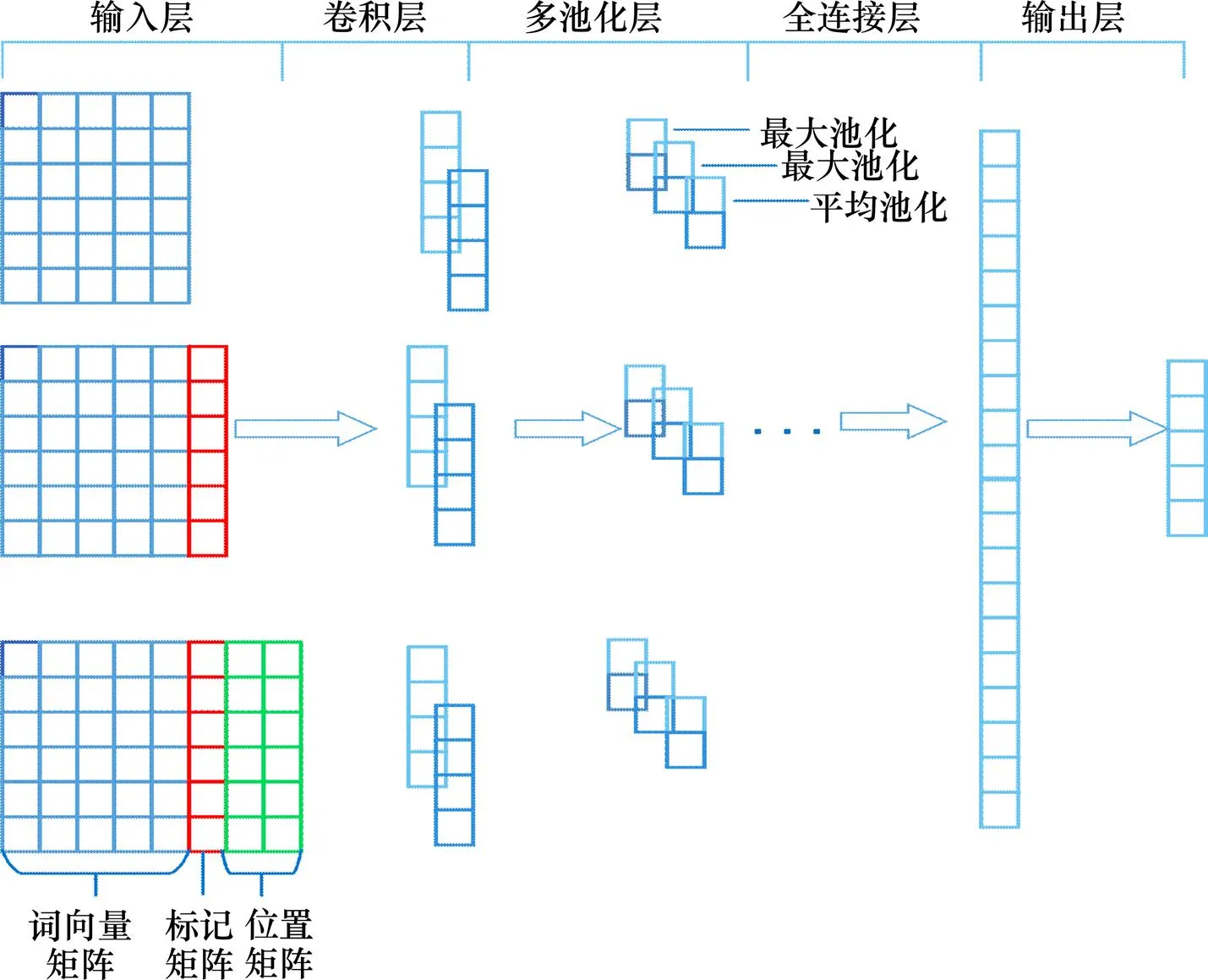
圖3 多池化卷積神經(jīng)網(wǎng)絡(luò)模型結(jié)構(gòu)
關(guān)于卷積神經(jīng)網(wǎng)絡(luò)實驗參數(shù)設(shè)定,卷積核大小選取3,4和5,維數(shù)128維。卷積核數(shù)目選取128。為防止過擬合,使用L2正則化對網(wǎng)絡(luò)參數(shù)進行約束,即在原來損失函數(shù)基礎(chǔ)上加上權(quán)重參數(shù)的平方和,限制參數(shù)過多或者過大,避免模型更加復(fù)雜。同時模型訓(xùn)練過程中引入Dropout策略,即每次迭代中隨機放棄一部分訓(xùn)練好的參數(shù),以防止過擬合。經(jīng)過交叉驗證,Dropout值為0.5,隨機生成的網(wǎng)絡(luò)結(jié)構(gòu)最多,效果最好。Batch值是批處理參數(shù),據(jù)經(jīng)驗取值為64時,可以確保尋找到最優(yōu)解的同時加快訓(xùn)練速度。實驗中,詞向量維數(shù)200維,詞性特征為50維,位置特征為10維,Word2Vec采用默認參數(shù)。
3.4 實驗結(jié)果分析
3.4.1 Word2Vec+CNN模型
為驗證Word2Vec+CNN模型的效果,本文實驗選取傳統(tǒng)的樸素貝葉斯(Naive Bayes,簡稱NB)模型與支持向量機(Support Vector Machine,簡稱SVM)模型作對比。在采取數(shù)據(jù)集相同的情況下,為排除由于特征構(gòu)建方式不同導(dǎo)致實驗結(jié)果無法對比,所以對于傳統(tǒng)模型也都是使用Word2Vec訓(xùn)練詞向量,結(jié)果如表1所示。

表1 不同分類模型的整體平均Loss值及Accuracy值
由表1中可以得出,SVM比CNN模型損失率較低,但是兩者之間差別不是很大,從準確率上來看,CNN 模型比NB模型提高了1.2%,比SVM模型提高了3.9%。表明使用CNN模型可以有效的提高分類效果。由此可見,CNN模型能夠自主地提取并學(xué)習到更多的分類特征,這比傳統(tǒng)的機器學(xué)習模型更有優(yōu)勢,同時也提高了分類性能。
3.4.2 Word2Vec+MCNN模型
實驗中,在進行多池化時,分別采用3個最大池化策略、3個平均池化策略、2個最大池化策略+平均池化混合策略這3種池化方法作對比,具體結(jié)果如表2所示。

表2 不同池化模型的整體平均Loss值及Accuracy值
由表2中可以清晰地看出,多池化卷積神經(jīng)網(wǎng)絡(luò)模型分類效果明顯比傳統(tǒng)的卷積神經(jīng)網(wǎng)絡(luò)模型效果好。從分類準確率上看,Word2Vec+MCNN1比Word2Vec+CNN模型由0.915提高到0.932,整整提高了1.7%,損失率由原來的0.205降到0.184,降了2.1%。同樣地,Word2Vec+MCNN2和Word2Vec +MCNN3都比Word2Vec+CNN模型的分類效果好。對于不同池化模型,對比表1和表2,可以看出,無論哪種形式的多池化卷積神經(jīng)網(wǎng)絡(luò)都要比傳統(tǒng)的分類模型分類效果好,且具有較高的分類準確率,Word2Vec+MCNN1比NB分類模型準確率提高了2.9%,而損失率直接降低了5.3%。對比內(nèi)部不同的池化方式,Word2Vec+MCNN1模型無論是從準確率還是損失率上看都比其他2種池化模型好。
Word2Vec+MCNN1模型能夠得到較高的準確率、較好的分類效果主要原因是:1) 使用Word2Vec訓(xùn)練詞向量。Word2Vec訓(xùn)練詞向量,可以控制特征向量的維數(shù),解決維數(shù)災(zāi)難問題,不會忽略詞與詞在文本中的相對位置關(guān)系,而且還保留了詞與詞之間的語義關(guān)系。2) 使用卷積神經(jīng)網(wǎng)絡(luò)分類。以并行的多通道卷積模式,捕獲到重點信息詞。采用三池化方式,提取到比較全面的信息,不至于把句中次重要的信息忽略。在訓(xùn)練過程中,采用L2正則化和Dropout策略防止陷入局部最優(yōu),避免過擬合現(xiàn)象,同時也得到了較好的分類效果。
4 結(jié)論
1) 鐵路信號設(shè)備是鐵路行車安全的重要保障,使用文本挖掘技術(shù)為維護信號設(shè)備的正常運行提供輔助決策,為管理人員分析存儲提供技術(shù)支撐。本文通過所采集到的鐵路信號文本數(shù)據(jù)對鐵路信號故障設(shè)備進行分類。由于個別設(shè)備故障次數(shù)比較少,所以只對常見的幾種故障設(shè)備進行了分類。
2) 針對鐵路故障文本記錄數(shù)據(jù),首先使用jieba分詞工具進行分詞,然后采用本文提出的Word2Vec+MCNN模型進行分類,通過NB和SVM傳統(tǒng)分類器以及各MCNN模型的對比,驗證模型的準確性,最終得出Word2Vec+MCNN(max*2+ave)模型更能達到最優(yōu)分類效果。同時也為今后鐵路信號設(shè)備分類提供了新方法和新思路。
[1] 趙陽, 徐田華. 基于文本挖掘的高鐵信號系統(tǒng)車載設(shè)備故障診斷[J]. 鐵道學(xué)報, 2015, 37(8): 53?59. ZHAO Yang, XU Tianhua. Fault diagnosis of vehicle equipment in high-speed railway signal system based on text mining[J]. Journal of the China Railway Society, 2015, 37(8): 53?59.
[2] 楊連報, 李平, 薛蕊, 等. 基于不平衡文本數(shù)據(jù)挖掘的鐵路信號設(shè)備故障智能分類[J]. 鐵道學(xué)報, 2018, 40(2): 59?66. YANG Lianbao, LI Ping, XUE Rui, et al. Intelligent classification of railway signal equipment faults based on unbalanced text data mining[J]. Journal of the China Railway Society, 2018, 40(2): 59?66.
[3] 朱磊. 基于Word2Vec詞向量的文本分類研究[D]. 重慶: 西南大學(xué), 2017. ZHU Lei. Text classification based on word2vec word vector[D]. Chongqing: Southwest University, 2017.
[4] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]// Advances in Neural Information Processing Systems, 2013: 3111?3119.
[5] Chen M, Shen D, Shen D. Short text classification improved by learning multi-granularity topics[C]// International Joint Conference on Artificial Intelligence. AAAI Press, 2011: 1776?1781.
[6] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[C]// [2014?02? 10].http://arxiv.org/pdf/1301.3781.pdf.
[7] Kim Y. Convolutional neural networks for sentence classification[C]// Proceedings of the 2014 Conference on Empirical Mathods in Natural Language Processing. Stroudsburg: ACL, 2014: 1746?1751.
[8] Socher R, Pennington J, HUANG E H, et al. Semi- supervised recursive autoencoders for predicting sentiment distributions[C]// Conference on Empirical Methods in Natural Language Processing, EMNLP 2011, Edinburgh, Uk, A Meeting of Sigdat, A Special Interest Group of the ACL. DBLP, 2011: 151?161.
[9] He H, Gimpel K, Lin J. Multi-perspective sentence similarity modeling with convolutional neural networks [C]// Conference on Empirical Methods in Natural Language Processing, 2015: 1576?1586.
[10] 李心蕾, 王昊, 劉小敏, 等. 面向微博短文本分類的文本向量化方法比較研究[J]. 數(shù)據(jù)分析與知識發(fā)現(xiàn), 2018, 2(8): 41?50. LI Xinlei, WANG Hao, LIU Xiaomin, et al. A Comparative study of text vectorization methods for microblog short text classification[J]. Data Analysis and Knowledge Discovery, 2018, 2(8): 41?50.
[11] 孫璇. 基于卷積神經(jīng)網(wǎng)絡(luò)的文本分類方法研究[D]. 上海: 上海師范大學(xué), 2018. SUN Xuan. Research on text classification method based on convolutional neural network[D]. Shanghai: Shanghai Normal University, 2018.
[12] 周順先, 蔣勵, 林霜巧, 等. 基于Word2vector的文本特征化表示方法[J]. 重慶郵電大學(xué)學(xué)報(自然科學(xué)版), 2018, 30(2): 272?279. ZHOU Shunxian, JIANG Li, LIN Shuangqiao, et al. Text characterization representation based on Word2vector[J]. Journal of Chongqing University of Posts and Telecommunications (Natural Science Edition), 2018, 30(2): 272?279.
[13] 盧玲, 楊武, 楊有俊, 等. 結(jié)合語義擴展和卷積神經(jīng)網(wǎng)絡(luò)的中文短文本分類方法[J]. 計算機應(yīng)用, 2017, 37(12): 3498?3503. LU Ling, YANG Wu, YANG Youjun, et al. A Chinese short text classification method based on semantic extension and convolutional neural network[J]. Journal of Computer Applications, 2017, 37(12): 3498?3503.
[14] 石逸軒. 基于深度學(xué)習的文本分類技術(shù)研究[D]. 北京:北京郵電大學(xué), 2018. SHI Yixuan. Research on text classification technology based on deep learning[D]. Beijing: Beijing University of Posts and Telecommunications, 2018.
[15] 陳珂, 梁斌, 柯文德, 等. 基于多通道卷積神經(jīng)網(wǎng)絡(luò)的中文微博情感分析[J]. 計算機研究與發(fā)展, 2018, 55(5): 945?957. CHEN Ke, LIANG Bin, KE Wende, et al. Sentiment analysis of Chinese weibo based on multi-channel convolutional neural network[J]. Journal of Computer Research and Development, 2018, 55(5): 945?957.
Research on short text classification method of railway signalequipment fault based on MCNN
ZHOU Qinghua, LI Xiaoli
(School of Electronic and Information Engineering, Lanzhou Jiaotong University, Lanzhou 730070, China)
There are a lot of unstructured text data in railway operation and maintenance. For this text information, this article proposes a text mining classification method based on Word2Vec+MCNN. Firstly, the Word2Vec was used to train the fault word vector. Secondly, the word vector matrix information was enriched to enable the network model to learn the fault information of input sentences from the multi-dimensional feature representation. Finally, the multi-pooling convolutional neural network model was used as a fault classification method to acquire more comprehensive hidden information. Compared with the traditional classifiers and other types of multi-pooling convolutional neural network model experiments, it is concluded that the model can achieve better classification effect and higher classification accuracy.
fault classification; signal equipment;Word2Vec; convolution neural network
U284.92
A
1672 ? 7029(2019)11? 2859 ? 07
10.19713/j.cnki.43?1423/u.2019.11.027
2019?02?21
國家自然科學(xué)基金資助項目(61763025)
周慶華(1971?),女,遼寧沈陽人,副教授,從事機器學(xué)習研究;E?mail:kzlll@foxmail.com
(編輯 陽麗霞)
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
汽車維護與修理(2016年10期)2016-07-10 08:17:41
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
汽車維修與保養(yǎng)(2015年6期)2015-04-17 03:31:50
