基于Python的視頻信息挖掘
2019-12-13 01:08:40宋永生
現代計算機 2019年31期
宋永生
(江蘇工程職業技術學院,南通 226007)
0 引言
視頻由于生動直觀,蘊含的信息量大,近年來逐漸發展成為了主流的知識媒介。政府部門及高校中每年都會拍攝大量的視頻,這些視頻多以文件的形式存放于一臺甚至多臺服務器上。視頻拍攝完畢后,很多人不愿意花時間去寫視頻簡介,沒有做專門的視頻封面或封面不具代表性,甚至連視頻的命名都不規范。隨著時間的推移,服務器上的視頻文件越來越多,而且存放的服務器也越來越多,為后期的視頻檢索及視頻審核帶來很大的困難。往往需要將視頻從頭到尾觀看一遍,才會了解視頻中是否含有敏感詞,該視頻是何內容。視頻中蘊含著大量的信息,這些信息并沒有得到有效的挖掘。如果視頻能夠有一個類似電影海報的封面,通過封面即可對視頻內容有大致的了解,將大大方便視頻的管理。
Python是一種面向對象的跨平臺解釋型高級程序設計語言,其設計哲學是優雅、明確、簡單。Python語言簡潔明了、易讀、便于擴展,具有龐大的標準庫和第三方庫,生態極為豐富。近年來,隨著人工智能的飛速發展,越來越多的人開始使用Python。Python已被納入全國計算機等級考試。
本文嘗試利用Python,提取視頻文件的基本信息,并生成視頻截圖;從視頻文件中抽取音頻信息,利用訊飛開放平臺的REST API,將語音轉為文字。將文字及視頻的基本信息存入視頻信息庫,利用Flask構建視頻信息Web管理系統,人們可以方便地檢索視頻或者審核視頻中是否包含敏感詞。對這些文字還可以做進一步的分析,利用分詞技術進行詞頻統計,形成詞云,根據詞云、視頻截圖及該視頻在管理系統中的Web URL二維碼合成視頻的封面海報。有了封面海報,視頻的內容則一目了然,掃描封面海報上的二維碼,可以查看視頻的詳細信息。
1 視頻信息挖掘平臺總體設計
視頻信息挖掘平臺采用Python 3.5進行開發,集成開發環境選用PyCharm 2018,數據庫選用MySQL 5.7,Web開發框架選用Flask 1.0,視頻截圖選用OpenCV 4.1,音頻信息提取選用moviePy,音頻轉文本選用訊飛的語音轉寫REST API進行實現,分詞選用Jieba,詞云展示選用Wordcloud。
2 數據處理流程
視頻信息挖掘的數據處理流程如圖1所示。視頻封面海報生成以后要寫入視頻信息庫。
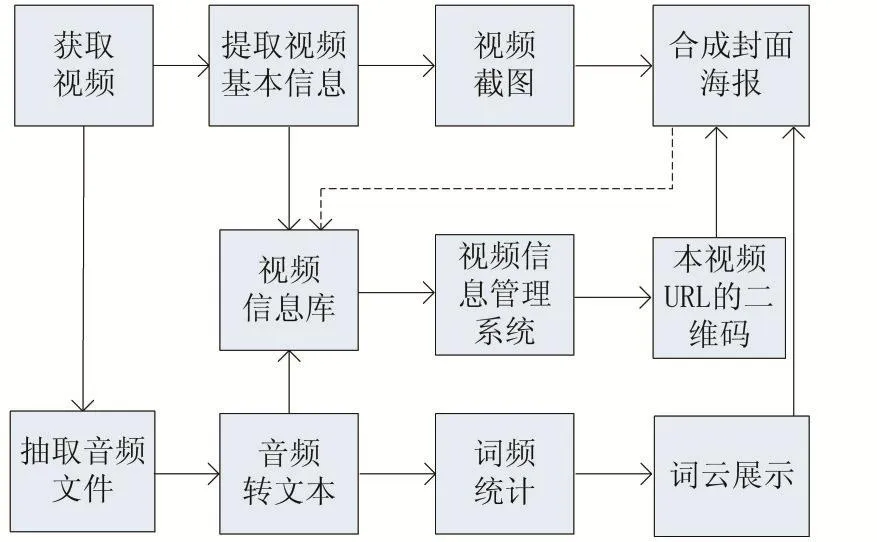
圖1 數據處理流程
3 相關技術
3.1 視頻基本信息提取及截圖
使用OS庫獲取視頻文件的大小、存放路徑、修改時間等信息,利用Socket庫獲取存放該視頻服務器的IP,再利用OpenCV庫獲取視頻的FPS及時長等信息,并進行截圖。OpenCV是一個以BSD許可證開源的跨平臺計算機視覺庫,采用C++編寫,提供了圖像處理領域的很多通用算法[1]。VideoCapture是OpenCV中操作視頻的類,可在構造函數中打開視頻。在while循環中可以用VideoCapture類的read()函數逐幀提取視頻中的圖像,每幀是一幅基于BRG格式的圖像,可以按照一定的幀數間隔對視頻進行截圖。
totalFrameNumber=vc.get(cv2.CAP_PROP_FRAME_COUNT)
#視頻文件總幀數
fps=vc.get(cv2.CAP_PROP_FPS)#獲取幀速
vedio_time=totalFrameNumber/fps#視頻文件的時長
count=1
while True:
_,frame=vc.read()
if frame is None:
break
if count%EX_FREQUENCY==0:
save_path="{}/{:>03d}.png".format(dst_folder,index)
cv2.imwrite(save_path,frame)
index+=1
count+=1
vc.release()
3.2 視頻中分離出音頻
如需從視頻中分離出音頻,可以采用moviePy庫或FFmpeg軟件及ffmpeg-python庫的組合。moviePy是Python的一個視頻編輯庫,可裁剪、拼接、標題插入、視頻合成、視頻處理和自定義效果;FFmpeg既是一款音視頻編解碼工具,同時也是一組音視頻編解碼開發套件,它為開發者提供了豐富的音視頻處理的調用接口。安裝了FFmpeg軟件后,再安裝ffmpeg-python庫,就可以通過ffmpeg-python從視頻中提取音頻。本文選用更為方便的moviePy庫。
video=VideoFileClip('test.mp4')
audio=video.audio
audio.write_audiofile('test.wav')
3.3 音頻轉文字
訊飛開放平臺把語音轉寫功能通過REST API的方式給開發者提供一個通用的HTTP語音接口,基于該接口,可以將5小時以內的長段音頻數據轉換成文本數據,為信息處理和數據挖掘提供了基礎。訊飛開放平臺語音轉寫功能支持的輸入音頻格式有wav、flac、opus、m4a及mp3[2],支持的語種有中文普通話及英語,輸出為JSON格式字符串,含有音頻所對應的文本。
3.4 Flask
Flask是一個小而精的輕量級Web框架,其WSGI工具箱采用Werkzeug,模板引擎使用Jinja2。Flask的核心非常小巧,不包含數據庫的抽象訪問層,可以借助SQLAlchemy實現。SQLAlchemy提供了SQL工具包及ORM工具,也提供了使用數據庫原生SQL的功能,支持多種數據庫后臺。Flask-SQLAlchemy是一個Flask擴展,在SQLALchemy基礎上,簡化了在Flask程序中使用SQLAlchemy的操作。
通過Flask-SQLAlchemy將視頻的基本信息、音頻部分所對應的文本等寫入視頻信息數據庫。借助Flask構建視頻信息管理系統,方便人們檢索和審核視頻。
MyQR是一個能夠產生基本二維碼、藝術二維碼和動態效果二維碼的Python庫。通過MyQR,可以將該視頻詳細信息頁面在視頻信息管理系統中對應的Web URL生成為二維碼。人們只需掃描二維碼,就可以快速訪問該視頻詳細信息的Web頁面。
3.5 詞頻統計
英語中一個單詞就是一個詞,而漢語以字為基本書寫單位,詞語之間沒有明顯的區分標記,需要人為切分[3]。中文文本的詞頻統計,首先需要進行分詞處理。常用的中文分詞工具有Jieba、THULAC、SnowNLP、pynlpir、CoreNLP及pyLTP等。本文的分詞工具選用Jieba,Jieba是利用一個中文詞庫,將需要分詞的內容與詞庫進行對比,找到最大概率的詞組,用戶可以向中文詞庫中添加自定義的新詞,支持精確模式、全模式及搜索引擎模式[4]。
3.6 生成詞云
詞云是以詞語為單位,根據其在文本中出現的頻率設計不同大小以形成視覺上的不同效果,對文本數據中出現頻率較高的關鍵詞在視覺上的突出呈現,對關鍵詞進行渲染,形成類似云一樣的彩色圖片,讓人一眼就可以領略文本數據的主旨。若想快速了解小說、電影劇本等的主要內容,就可以通過繪制詞云圖,通過關鍵詞的可視化就可以直觀地展示出來,非常方便。Wordcloud是一個根據文本生成詞云的Python庫。
4 實驗分析
本文選用的服務器配置為8核CPU,32GB內存,4TB磁盤,100Mbps帶寬,操作系統選用CentOS 7.5 64位,安裝 MySQL 5.7 及 Python 3.5、Pip 9.0、OpenCV 4.1、Pillow 6.0等,音頻信息提取選用moviePy庫,音頻轉文本選用訊飛的語音轉寫REST API進行實現,分詞庫選用Jieba,詞云展示庫選用Wordcloud。Web開發框架選用Flask 1.0,采用Gunicorn 19.8做wsgi容器來部署Flask程序,Web服務器選用Nginx 1.12。
分析視頻選用十九大報告現場的視頻。按照如下步驟進行視頻信息的挖掘:
(1)提取視頻的基本信息,例如存放該視頻服務器的IP、存放路徑、大小、時長、最后修改時間等;設置視頻截圖的間隔幀數,對視頻進行截圖,從中選取幾張具有代表性截圖;
(2)從視頻中提取音頻,調用訊飛開放平臺的語音轉寫REST API將音頻轉化為文本;
(3)將視頻的基本信息及對應的文本等,存入視頻信息數據庫;利用Flask構建視頻信息管理系統,方便進行視頻的檢索及審核,將該視頻詳細信息頁面在視頻信息管理系統中對應的Web URL生成為二維碼圖片;
(4)對轉化得到的文本進行分詞處理及詞頻統計,并以詞云的形式對關鍵詞進行展示,將詞云圖片保存;
(5)通過Pillow包將幾張代表性的視頻截圖、二維碼圖、詞云圖進行拼接,并加上視頻的標題,生成視頻封面海報,如圖2所示。視頻封面海報也要存入視頻信息數據庫。

圖2 視頻封面海報

圖3 視頻詳細信息
通過視頻封面海報可以一目了然的了解視頻的大致內容,并可以使用手機掃描海報右下角的二維碼,查看該視頻的詳細信息,如圖3所示。可以在視頻信息管理系統中,檢索一些敏感詞,對不含敏感詞的視頻,給予審核通過,方便了對視頻的檢索和審核。
5 結語
本文針對目前視頻管理中存在的一些問題,例如由于沒有視頻簡介、視頻無封面或封面不具代表性、命名不規范等,給視頻檢索造成了困難。視頻審核往往需要將視頻從頭看到尾,需要大量的人力物力,視頻信息的挖掘變得非常迫切。本文利用Python調用OpenCV、OS、Socket等庫獲取視頻的基本信息并進行截圖,利用moviePy提取視頻中的音頻,借助于訊飛開放平臺的語音轉寫REST API將語音轉為文字,將視頻基本信息及文字存入視頻信息數據庫,利用Flask構建視頻信息管理系統,方便了視頻的檢索及審核。對生成的文字進行分詞處理及詞頻統計,用詞云展示所生成文字中的關鍵詞,將詞云、視頻截圖及該視頻詳情頁面的Web URL對應的二維碼及視頻標題進行融合,生成視頻的封面海報。人們通過封面海報一眼即可了解視頻的大致內容,掃描封面海報上的二維碼,即可查看該視頻的詳細信息。
本文對生成的文本,僅進行了簡單的詞頻統計,在今后的研究中,對視頻的文本可以進行情感分析等,生成具有特定輪廓的詞云;自動選取具有代表性的截圖,并且可以自行判斷視頻畫面內容是否合規,而不僅僅局限于語音內容的合規審核。
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
