基于特征關聯的服裝圖像特征描述研究?
2019-11-29 05:14:34謝玉玲
計算機與數字工程 2019年11期
龔 安 謝玉玲
(中國石油大學(華東)計算機與通信工程學院 青島 266580)
1 引言
據中國電子商務研究中心給出的數據顯示,僅2017 上半年中國電子商務交易額就達13.35 萬億元[1];服飾類商品在整個網絡購物市場中交易最多,截止2015 年,我國服裝網購市場交易規模達7457億元[2]。而圖像作為商品的信息載體,規模和數量也隨之呈現高速發展的態勢。服裝圖像描述是直接輸入服裝圖片,自動生成對服裝圖像的自然語言描述。
近年來,圖像描述生成技術無論是流程化方法還是端到端的方法都取得了迅猛發展,大都基于深度卷積神經網絡和循環神經網絡的結合。微軟Fang 等[3]利用多實例學習(Multiple Instance Learning,MIL)的弱監督方法,訓練視覺檢測器來提取一副圖像中由卷積神經網絡(Convolutional Neural Networks,CNN)獲取的特征單詞,然后學習一個統計 模 型 用 于 生 成 描 述。Kiros 等[4]利 用CNN 和LSTM 對圖片進行編碼,再利用提出的方法SC-NLM(Structure-Content Nearal Language Model)預測句子結構進行解碼。受機器翻譯的啟發谷歌Vinyals 等[5]設計了一個從編碼到解碼的圖像描述生成器,實現這個系統模型的是DCNN 和RNN 的結合。Karpathy 等[6]通過多通道嵌入設計image-sentence embedding 模型能夠將句子描述內容片段和圖片局部區域對應起來,然后引入BRNN(Bidirectional Recurrent Neural Network)架構來生成圖片描述。同樣在2015年的CVPR會議上Donahue 等[7]實現一個端到端的圖像LRCNs(Long-term Recurrent Convolutional Networks)模型直接在可變長度的圖像序列輸入和可變長度的文字輸出之間建立映射關系。Xu等[8]則將注意力機制引入LSTM模型,以提取到圖像中更需關注的目標特征。目前在技術和性能方面處于領先地位的除了谷歌在TensorFlow 上開源的自動圖像描述系統“Show and Tell”[5],還有Li-Feifei 團隊[6]設計的方法也是CNN到RNN的描述過程。
相比于服裝產品特征的多樣性和消費者購物需求的多變性,2016 年在服裝識別與搜索研究有一定的進展,DeepFashion[9]通過聯合預測衣服的關鍵點處(如領口、袖口、腰間、褲腳等)提取特征,以抵消嚴重形變帶來的影響。但是目前圖像分類、目標檢測和圖像語義分割等處理技術大都還僅僅處在對服裝款式單一的分類(款式和顏色特征)任務上,無法識別出商品屬性上消費者更關注的特性(如面料、風格),對圖片自然語言的描述工作也更多地注重語言的流暢性和結構完整性;這都局限了產品信息的展現,不利于服裝特征的描述和信息的檢索。故本文利用目前趨于成熟的電商平臺提供的豐富描述標題,挖掘文本信息里服裝特征,將深度視覺和自然語言處理結合,按一定的關聯準則整理圖片和文本特征,作為輸入訓練LSTM 模型,生成服裝特征的自然語言描述。這樣不僅可以改進商家手工標注帶來的繁瑣,還可以提高商品的分類準確性和服裝信息的全面性,提高搜索的精度和用戶的購物體驗。
2 獲取文本特征
2.1 文本預處理
文本語料整理自各電商平臺爬取的特定款式服裝店鋪提供的結構化描述語句,按服裝款式類別保存為txt 文件,共12 個。文本預處理是特征關聯中獲取文本特征的第一步,利用Python開發的結巴中文分詞組件。結巴分詞支持三種分詞模式:全模式、精確模式、搜索引擎模式。服裝圖像的特征描述最終用于電商平臺的信息檢索,故本文采用搜索引擎模式,它能在精確模式的基礎上對長詞進行更細粒度的切分,提高分詞的召回率。
其處理過程如下:
1)基于Trie 樹構建款式語句的有向無環圖(Directed Acyclic Graph,DAG)
將圖片的描述語句所有可能成詞的情況構建DAG,一個詞對應于DAG 中的一條邊,初始字符為邊的起點,結束字符為邊的結點,詞頻為邊上權重,圖的流向表示字符頂點順序。
2)動態規劃求解構詞的最大路徑
使用Unigram(一元)的語法模型,最大概率問題轉化求最大路徑,將當前詞出現的概率P(wi)設為自身詞頻J(wi)/N(J(wi)為wi在語料中出現次數,N 為語料總詞數),句子的最佳分詞方案win=(w1,w2,…wn)為最大聯合概率,滿足:
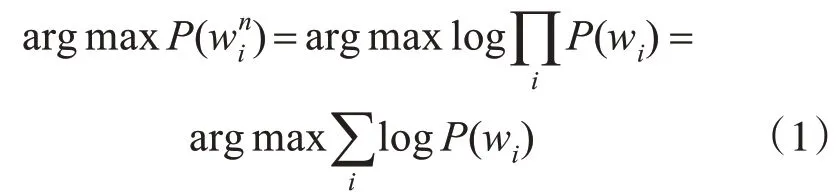
3)HMM識別未登錄詞
將沒有被收錄在分詞詞表中的人名、地名、店鋪名等切分出來,自定義部分停用詞(如時間(2017年)、新款等)以達到過濾效果。
由于店鋪商品描述文本語料數據本身趨于結構化,分詞效果準確率高。以夏天連衣裙為例,顯示分詞后的結果如圖1 所示,空格作為詞間的分隔。

圖1 夏天連衣裙分詞效果
2.2 提取文本特征
在同一類服裝的款式特征中,部分特征具有普遍性和互為潛在關聯,很多規律有章可循,對應的文本描述詞也是整個語料的高頻詞或共現高頻詞,而僅僅憑借圖像特征提取是無法獲取的,所以文本特征詞的提取是非常重要的步驟,特征的好壞直接影響著語句生成的優劣。
基于研究的領域特點,文本特征的計算分為兩類:權重值高的詞語和與高權詞具有高共現率的密切聯系詞語。權重值由修改的TF-IDF(Term Frequency-Inverse Document Frequency)[10]方法得到,定義了兩個影響因子,權重值代表著詞語的價值。
2.2.1 修正TF-IDF的款式高權重值計算
高權重詞反應了某一服裝款式的普遍特性,例如作為夏天的睡衣,對全棉(或純棉)的布料需求很高。TF-IDF 是信息檢索與文本挖掘中廣泛使用的特征向量化方法,利用加權技術衡量一個關鍵詞對于查詢(可看作文檔)所能提供的信息,TF 考慮詞語在其對應的款式文本文件中出現的頻率,IDF 考慮了詞語在所有文本集中出現的區域集中性。路永和等[11]介紹了傳統及一些改進的TF-IDF 算法。由服裝語料的具體特征,本文修改了兩個影響因子,并對計算公式做了優化,具體如下:
1)對于詞語wi在該文本文件中出現的頻率為J(wi)/N,頻率越高,提供的信息對該文本(款式)越重要。
2)包含詞語的款式文件數,文本文件數為M,m 為包含詞語的文本數,m 越小,即它的范圍小,那么它對該款式價值比較大,是該款式所特有的文本描述。
在這兩種影響因子下,文本Tj下詞語wi的權重值計算公式修改為
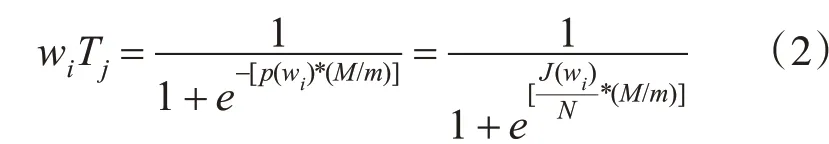
定義了款式文檔相應的高權重值詞集QTj,設置閾值β1,大于等于閾值詞收錄在高權重詞集里,部分款式文件高權重詞的結果如表1所示。
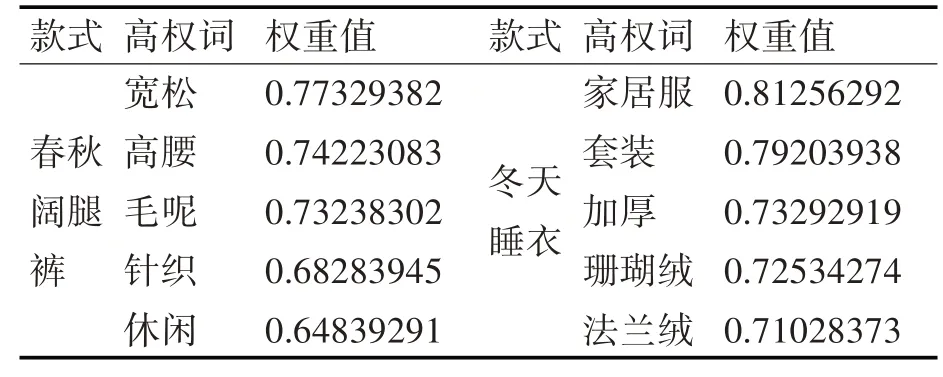
表1 高權詞的結果
2.2.2 共現特征詞的提取方法
與高權詞存在高共現度的詞是潛在密切聯系的詞語,對服裝的特征獲取具有顯著意義。作為服裝三要素的款式、面料、顏色是相互關聯的,面料不僅可以詮釋服裝的風格和特性,而且直接左右著服裝的色彩、造型的表現效果。比如連衣裙布料很多為雪紡,產品的拍攝地選擇海邊的幾率很大,海、度假、沙灘裙的描述同時出現的概率很高,引入條件概率來計算詞與詞之間的關聯度Rel(wi,wj),依次從RTj中選擇一個高權重詞計算與其他詞的條件概率,公式如下:
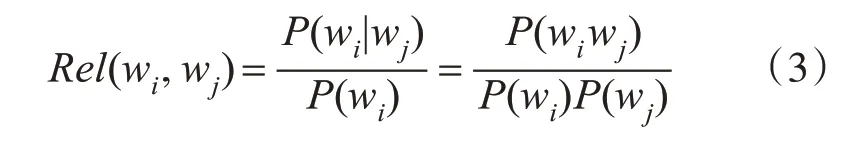
從這個公式不難發現,它的結果體現了共現詞對的相關性程度,具體情況為
1)如果Rel大于1,wi在wj存在的條件下比無條件下出現的概率大,并隨著Rel 值越大,wj帶動wi的出現。
2)如果Rel 小于1,wi的存在抑制了wj的出現。
3)如果Rel等于1,那么wi和wj相互不存在關聯。
將Rel>1 的共現詞對收錄在高共現詞對集合RTj中,得到需要的文本特征:高權重值詞集QTj和高共現詞對集合RTj。利用它們按一定規則與圖像特征進行關聯。
3 基于特征關聯的服裝圖像特征描述
3.1 提取圖像特征
VGG16[12]是公認的較好的深度卷積神經網絡模型,它贏得了2014 世界ILSVRC(ImageNet Large Scale Visual Recognition Challenge)在數據集ImageNet 上目標檢測的冠軍,把VGG16 應用在本文的圖片數據集上訓練。首先使用labelImg 工具對服裝圖片進行基于款式的人工標注,標注的內容是目標對象和對象的ground truth boxes,VGG16 模型默認輸入尺寸224px*224px,其他的參數Minibatch 等于256、bias 為0、高斯分布服從(0,0.01),預訓練權值參數模型提取圖像特征。
3.2 基于LSTM的自然語言描述模型
本文使用LSTM 網絡模型[13]進行自然語言描述,作為一個時間遞歸神經網絡,它包含一個內置的記憶單元來存儲信息和學習長期依賴信息,解決了“梯度消失”和“梯度爆炸”問題,模型在自然語言領域已經取得了很好的效果。利用LSTM 能夠處理不同長度輸入和生成不同長度的序列作為輸出的特點,本文的輸入是特征關聯后的特征向量和圖片標注的自然語言特征描述語句轉化后的向量,輸出是單詞序列{y1,y2,…,yn},學習和訓練LSTM模型的部分參數如表2所示。
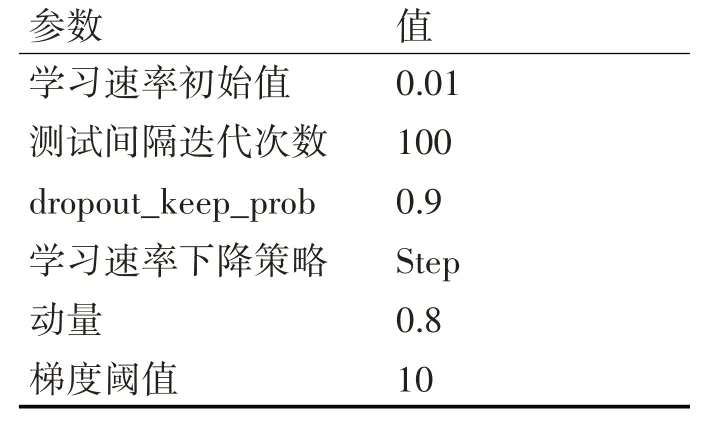
表2 訓練LSTM模型部分參數
3.3 引入特征關聯的算法流程
特征關聯是對服裝圖像的圖片特征和文本特征按一定的規則獲得最優的服裝信息,用于服裝特征的自然語言描述生成,算法步驟如下:
1)圖片預處理:把原始圖片縮放到最小邊S=384px上,然后在整個圖片上提取224*224的片段;
2)圖片特征提取:提取的圖片片段輸入3.1 節預訓練的VGG16 網絡進行圖片分類,并提取全連接層(fc7)的特征向量;
3)特征關聯:對VGG16網絡fc7的4096維特征向量進行拆分,獲得相應的特征目標向量,映射到2.2.2 節描述的RTj中,若存在共現詞對,收入到特征向量集合Ci中,然后將圖片類別映射到2.2.1 節描述的QTj中,得到除共現詞對以外相應的款式高權詞集合,按權重值排序收入備選特征向量集合Cr中;
4)對第3)步得到的備選特征集合Cr進行篩選,然后連接到特征向量集合Ci中,使組合后的集合大小與訓練數據集標注的自然語言描述向量維度一致,并一起作為模型輸入,最后學習和訓練基于LSTM的自然語言描述模型;
5)測試階段:使用通過訓練得到的權值向量W,在測試數據集上驗證生成的自然語言描述的評估分數。
4 實驗與結果分析
4.1 實驗數據集
本文實驗數據來源于香港中文大學開放的large-scale 數 據 集DeepFashion[9]和 整 理 自 各 電 商平臺爬取的數據。數據分為兩種:圖像數據和文本語料數據,每張圖片對應一條店鋪爬取的描述語句,和兩條由人工標注的語句。圖像數據12000張,包括按要求選定的部分DeepFashion數據,圖像數據及其描述語句的70%作為訓練集,余下為測試集。訓練數據和測試數據無重復以保證實驗結果的準確性。同時把圖片訓練集的描述語句按款式保存為文本文檔,用來提取文本特征,其中共計款式12 種,各種款式的服裝數據量相當,并統一圖片標注格式。
4.2 評價指標
為了對提出的方法進行更客觀全面的評估,本文的評估指標有兩種:采用自動評價標準中的BLEU(Bilingual Evaluation Understudy)[14]評估和人類判斷[15]評估。人類判斷就是對生成的語句描述與參考的服裝特征描述對比進行錯誤率打分。
BLEU計算標準在圖像標注結果評價中使用很廣泛,用它來分析待評價的特征描述語句和參考的描述語句之間n 元組的相關性,圖片Ii由模型生成的自然語言描述語句是Li,參考標注語句的詞語集合Si={Si1,Si2,…,Sim}(i=1、2、3),本文只評價語句里面的BLEU_1 和BLEU_2 在所有參考語句里面的概率得分,對于Si中的重復詞或者相似詞作為一個詞處理,因為商品的語義描述主要用于檢索,注重對商品特征描述的全面性,BLEU_3 和BLEU_4 這兩種長元組的評分是對語言流暢性的評價。計算出的指標值越高表示描述越接近參考語句。
4.3 實驗方案
本文圖片序列特征提取、描述文本語料訓練和特征關聯,以及自然語言描述模型的訓練均使用深度學習框架Caffe[16]完成,并在高速并行的圖形處理器GPU 上計算以提高訓練的速度。在本文的測試集上,從橫向和縱向上分別評估了多種圖像自動生成自然語言描述的模型,橫向上評估了以往經典模型和本文模型的差距,縱向上評估了在以往模型的基礎上使用本文的特征關聯后的表現;以及本文方法在產生好的特征表現時需要付出的負面代價。
4.4 實驗結果分析
4.4.1 BLEU的評分結果
為了驗證算法的有效性,實驗評估包括Deep-Fashion[9]的服裝圖像目標識別方法(該方法通過聯合預測衣服的關鍵點,學習衣服的局部特征用于檢索,如領口、袖口、腰間、褲腳等),部分流程化方法(Kiros 等[4]的CNN+LSTM 模型)和端到端模型(如Vinyals 等[5]的CNN+RNN 的模型)。實驗結果如表3所示。
通過數據的對比分析可以得出以下結論:
1)從橫向上進行模型的對比發現,在本文VGG16+LSTM 模型上關聯了文本類型的特征后在評測分值上獲得了明顯的提升如表3 中的第6、7行,也以明顯的優勢超過了其他的模型方法,表中的第1、3、5、7行。
2)縱向上,本文特征關聯的思想用在其他模型上進行服裝特征生成能夠獲得效果的提升。如表中前兩組的對比可以顯示BLEU_1、BLEU_2 的評測分值提升明顯。
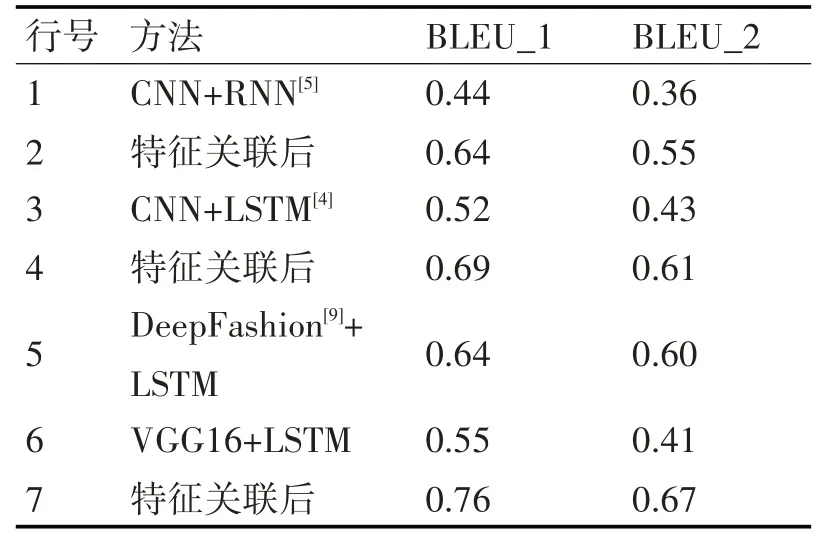
表3 BLEU評估結果
3)利用DeepFashion[9]+LSTM 方法在服裝特征提取上也有著較好的實驗效果,能識別出服裝領口、袖口、腰間、裙擺等部位的細節樣式,認為該方法獲取服裝特征與本文從文本獲取的服裝特征形成互補,可以和本文特征關聯方法結合做進一步的實驗研究。
4.4.2 人類判斷的實驗結果
人類判斷是為了更客觀地評價本文方法。把錯誤率分值分四個等級:[0.90~1.0]分表示描述沒有錯誤,[0.70~0.89]分表示描述中有些小錯誤,[0.40~0.69]分表示描述錯誤明顯(明顯錯誤特征有1~3 個)和[0~0.39]分表示描述與圖片無關。挑選了四張分別在不同錯誤率等級的圖片如圖2 所示,生成相應的語句描述如表4 所示,錯誤率分值由高到低處在四個等級中。統計在特征關聯前后模型在四個錯誤率等級的數據項分別占有的比例如圖3所示。

圖2 錯誤率等級的服裝圖片
從圖4 中可看出,特征關聯后的模型,生成的圖像特征在高分段的比例相對于特征關聯前的比例會有所下降,在[0.90~1.0]和[0.70~0.89]兩個分段分別下降了0.04和0.08個百分點,但下降的幅度不大,在[0.40~0.69]的分段提升了0.09 個百分點。由BLEU 的實驗結果分析對比,文本特征挖掘了更多的服裝特征詞,生成的語句描述中融入了較多的服裝特征信息,錯誤率提高是合理的,在只進行圖像識別技術獲取的圖像特征生成自然語言描述時,語句更注重語言的流暢性和結構的完整性,而忽視了服裝的信息呈現,所以相應的錯誤率較低。
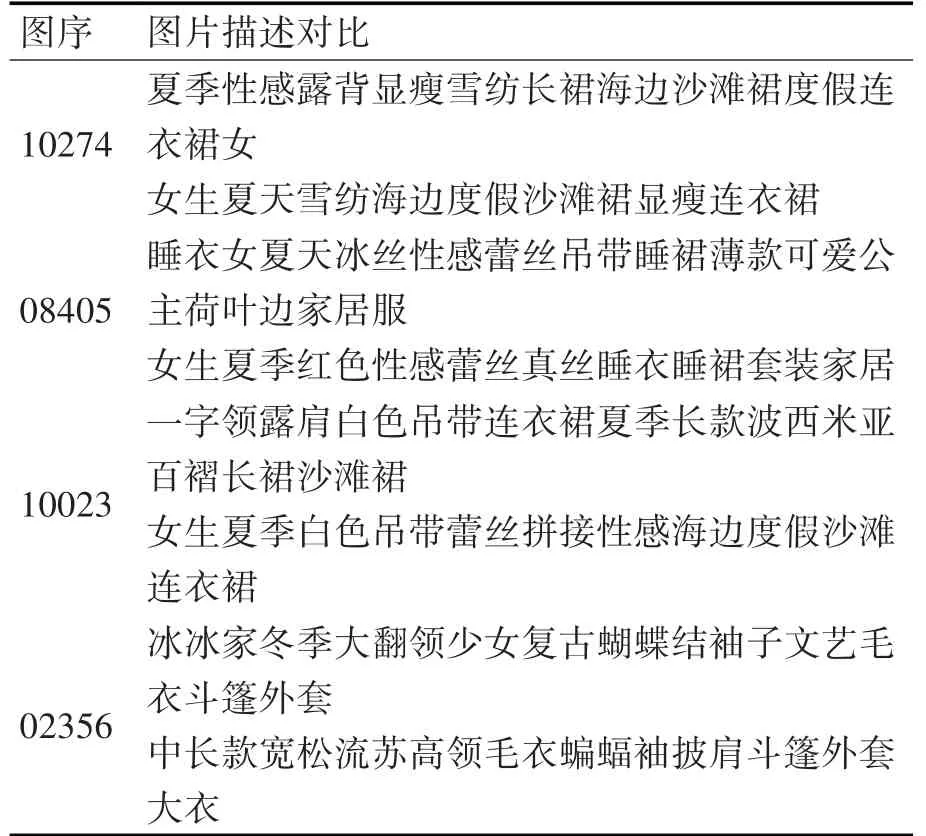
表4 生成特征描述的的錯誤率等級
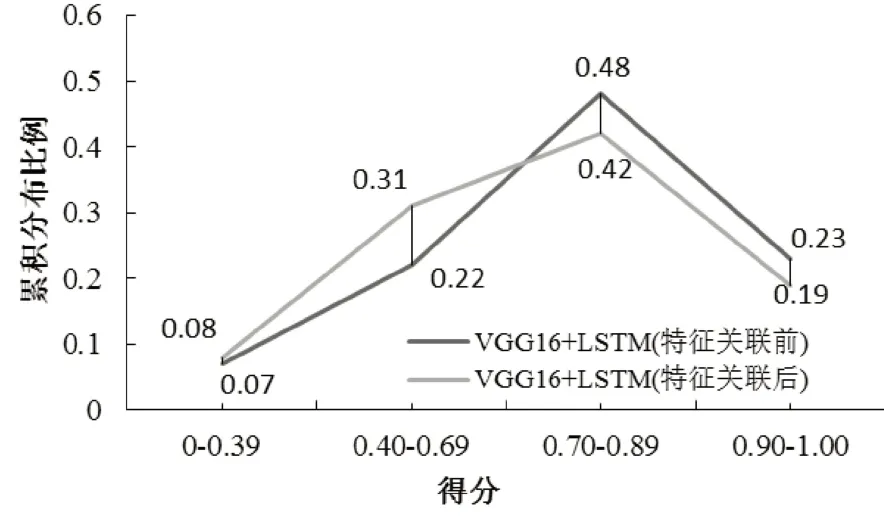
圖3 錯誤率分布比例圖
5 結語
針對目前服裝領域產品特征的多樣性和流行元素的多變性,利用現有的深度技術僅僅從圖像上去獲取服裝的特征單一,極大地限制了服裝信息的呈現,本文從服裝的描述文本語料中進行數據挖掘獲取文本特征,提出特征關聯的方法將它引入到服裝圖像特征的自然語言描述模型中,補充獲取圖片特征的不足。在獲取文本特征時,修正了TF-IDF方法對高權重詞提取,也利用了條件概率的方法獲得高共現詞對,實驗采取了人類判斷和BLEU 的評估標準,結果表明由本文方法提取的文本特征和關聯規則,在自動生成服裝的自然語言描述語句中都能在合理的錯誤率上有效提取服裝特征,更全面地描述服裝信息,從而提高電子商務系統的服裝檢索的準確性,為用戶提供更好的購物體驗。在接下來的工作中進一步對DeepFashion中利用圖像識別獲取服裝多處細節特征的方法和本文從文本中獲取的服裝多方面的屬性特征進行結合做進一步的實驗研究,并在針對服裝商品領域的文本進行相似度的研究,以提高生成服裝特征描述的質量。
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
學苑創造·A版(2018年11期)2018-02-01 06:29:20
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
讀者(2017年5期)2017-02-15 18:04:18
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
