基于機器學習的太赫茲光譜分析與識別
2019-11-18 05:11:20楊四剛陳宏偉
無線電工程 2019年12期
關鍵詞:分類
周 月,孫 霽,楊四剛,陳宏偉,徐 坤
(1.北京郵電大學 信息光子學與光通信國家重點實驗室,北京 100876;2.清華大學 電子工程系,北京 100084)
0 引言
太赫茲時域光譜(THz-TDS)是近年來逐步發展成熟的光譜分析技術,已經逐漸成為前沿多學科交叉領域的重要技術手段之一[1-3]。大多數的有機大分子、蛋白質分子以及生物分子在太赫茲頻譜范圍內具有豐富的光學信息。位于太赫茲波段范圍內的光子能量很低,可以避免生物分子結構遭到電離破壞;另外,太赫茲波對非極性材料具有良好的穿透性,為無損檢測創造了有利條件。以上優點為太赫茲時域光譜技術在生物分子的定量定性分析和無損檢測領域的研究奠定了基礎[4-5]。目前,THz-TDS檢測技術已經被廣泛地應用于爆炸物檢測[6-7]、毒品藥品檢測[8-9]、生物醫學[10-11]、文物保護[12]以及農作物監測[13]等領域。
轉基因技術是利用基因工程和分子生物學,通過改變生物的DNA,進而改變生物遺傳特性的技術。全球99%的轉基因作物由美國、加拿大、阿根廷和中國種值,每年種植轉基因作物的種類和數量都持續增長[14]。這些轉基因農產品被用來飼養動物或者壓榨油料,減低了社會生產成本,滿足了人類的生活生產需求。轉基因技術在增加農作物產量,提高農作物抗病等作用的同時可能會引起過敏等危害。轉基因作物帶來的潛在問題,例如對環境的影響、宗教倫理的挑戰以及生態安全等尚未明確。因此,針對轉基因作物的檢測技術的研究具有重要意義,為農產品安全和質量的檢測提供重要的技術支持[15]。
基于蛋白質檢測的方法被用于大多數的轉基因生物檢測,但是基于蛋白質檢測的方法耗時較長且成本高昂[16]。太赫茲時域光譜檢測技術結合機器學習識別方法具有快速、高效以及高準確性的優點,擁有較高的研究價值和應用潛力。2015年,Liu等人基于太赫茲光譜,構建了一個改進的支持向量機算法(Support Vector Machines,SVM),可以有效地鑒定出轉基因和非轉基因棉花種子,為轉基因作物的定性識別提供了一種無損、快速、可靠的方法[17]。2016年,Liu等人利用太赫茲時域光譜成像技術對轉基因稻米進行了太赫茲圖像的提取。利用隨機森林(Random Forest,RF)算法對獲得的太赫茲圖像進行了分類識別,準確率達到了96.67%[18]。2017年,Lian等人測量了四種轉基因玉米和一種非轉基因玉米標準品的太赫茲譜,隨后利用主成分分析算法(Principal Component Analysis,PCA)對光譜數據進行了降維,然后采用PCA結合支持向量機的方法,成功的識別出所有標準品樣本,準確率達到92.08%[19]。
本文以兩種轉基因油菜種子(Mon88302和GT73)和一種非轉基因油菜種子為研究對象。首先提取了三種油菜種子的太赫茲光譜。其次通過計算得到樣本的太赫茲吸收譜。最后利用樸素貝葉斯算法(Naive Baiyes,NB)、基于樸素貝葉斯的自適應提升算法(Naive Baiyes-AdaBoost,NB-daboost)和主成分分析結合隨機森林算法(PCA-RF)、主成分分析結合支持向量計算法(PCA-SVM)對樣本的太赫茲吸收譜進行了分類識別,對分類效果進行了分析研究。
1 實驗部分
1.1 實驗系統
實驗系統采用自行搭建的太赫茲時域光譜儀對樣品進行太赫茲光譜提取。實驗裝置原理如圖1所示。中心波長為1 560 nm,重復頻率為100 MHz,脈沖寬度為100 fs,平均功率為72 mW的飛秒光纖激光器作為太赫茲脈沖產生和探測的激勵光源。飛秒光源為線偏振光,因此,半波片和偏振分束器的組合在分束的同時,可以控制探測光和泵浦光的功率分配。反射鏡為的反射率大于97%。其中反射鏡4和反射鏡5成90°放置于電動位移平臺上,組成機械延遲線。斬波器為鎖相放大器提供參考頻率。光纖準直器負責將自由空間傳輸的飛秒激光耦合進入光電導天線的尾纖當中。太赫茲發射器產生的太赫茲脈沖由兩組90°離軸拋物面鏡負責進行收集和準直。兩組離軸拋物面鏡之間的焦點處為待測樣品擺放位置。穩壓電源為直流偏置+100 V,負責為太赫茲發射器提供直流偏壓。太赫茲探測器的輸出信號連接鎖相放大器,由鎖相放大器進行信號處理和儲存。最后通過計算機進行數據處理,獲得待測樣品的太赫茲時域光譜。
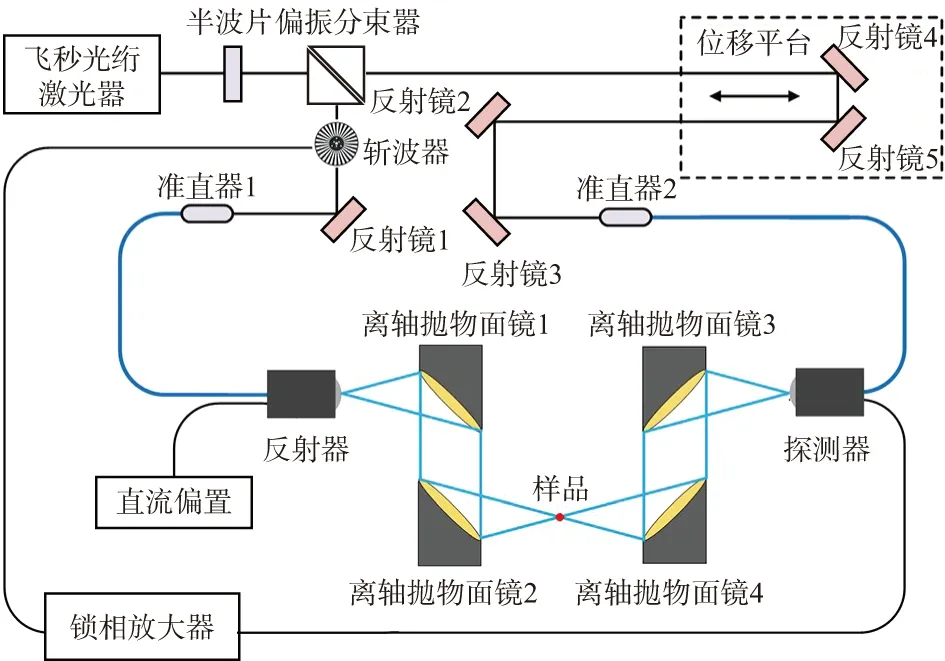
圖1 實驗裝置原理
圖2是THz-TDS的光譜,其中插圖是光譜儀的時域脈沖波形。
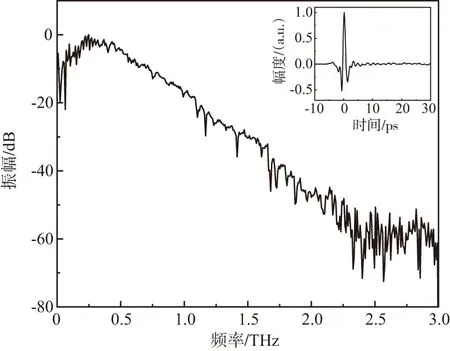
圖2 THz-TDS光譜和時域波形(插圖)
從圖2中可以看到,光譜儀有效帶寬為2.5 THz,峰值動態范圍60 dB。在實際測量過程中,室內溫度保持在23℃。樣品倉中充入干燥的空氣,使倉內的濕度保持在5%以下。減小空氣中水汽對測量效果的影響。
1.2 樣品制備
實驗中的菜籽樣品包含3種類別,其中Mon88302和GT73為轉基因油菜種子,剩余一種Non-GMO為非轉基因油菜種子。轉基因GT73和Mon88302以及非轉基因Non-GMO油菜種子樣本均購買自孟山都公司。由于油菜種子出油率較高,難以直接壓片成型。因此實驗用對太赫茲吸收很小,且刻圓槽的高密度聚乙烯板作為樣品的檢測窗口。高密度聚乙烯板厚度0.5 mm,圓槽直徑1 mm。將待測樣品充分研磨,通過填充壓實高密度聚乙烯窗口實現樣品的均勻定型。整個制作過程中保持樣品的干燥以減小水分對測量結果的干擾。
1.3 樣品光學信息提取方法
實驗采取透射式THz-TDS對樣品的太赫茲光譜進行測量,利用Dorney等人提出的模型最終提取樣品的太赫茲吸收譜。在正入射條件下,被測樣品對于太赫茲信號的復透射函數可以表示為[20-21]:
(1)
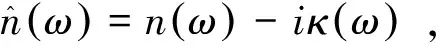
如果僅分析樣品材料在弱吸收近似情況下,以及菲涅耳透射系數取實數時,就可以得到樣品的折射率和吸收系數近似值,即[21]:
(2)
(3)
通過測量到的太赫茲時域光譜數據以及上述公式,可以計算出樣品的折射率和吸收系數。
2 實驗結果與分析
2.1 樣品的太赫茲吸收譜
實驗提取的3種油菜種子的太赫茲吸收譜如圖3所示。
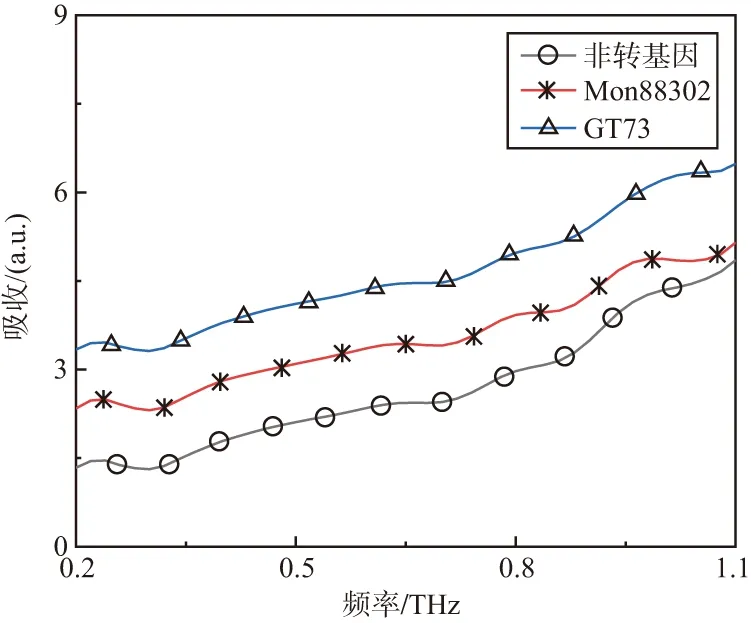
圖3 3種油菜種子的太赫茲吸收曲線
由于油菜種子對太赫茲具有較強的吸收,因此只提取到的太赫茲吸收譜的頻譜范圍為0.2~1.1 THz。從圖3可以看出,3種油菜種子的并沒后明顯的太赫茲吸收峰。3種油菜種子的太赫茲吸收曲線之間的差異也非常小,肉眼難以進行區分。為了達到自動化及準確的區分各類轉基因油菜種子樣本的目的,需要將太赫茲時域光譜與機器學習分類算法相結合。
實驗中總共成功制備了89份樣本,其中兩類轉基因樣本分別為30份,非轉基因樣本29份。由于樣本數量偏小,為了防止識別算法的過擬合,實驗中采用10倍交叉驗證對樣品進行分析。10倍交叉驗證中,初始數據集被隨機劃分為大小基本相同但互不相交的10組數據子集。在訓練和測試過程,中每次選出一組作為測試集,其余各組作為訓練集,依次類推,共進行10次訓練和測試。10倍交叉驗證中,分類準確率是10次迭代準確率的平均值,因此采用10倍交叉驗證的分類結果具有較低的偏倚和方差。
2.2 樸素貝葉斯分類
貝葉斯分類器時在概率框架內進行決策的基本方法之一[22]。在相關概率已知的理想情況下,貝葉斯分類器可以或得最優的識別標記。但是,對于后驗概率,貝葉斯分類器的類條件概率很難通過有限的樣本估計直接獲得。樸素貝葉斯分類算法對已知類別,假設所有的屬性相互獨立,每個屬性獨立對分類結果產生影響,從而避免了貝葉斯分類器的局限性[23]。樸素貝葉斯分類器的表達式為:
(4)
式中,x為樣本屬性;d為屬性數目;c為分類標記。
表1是樸素貝葉斯分類方法的轉基因樣本分類效果。從表1中可以看到,非轉基因油菜Non-GMO、轉基因GT73油菜和轉基因Mon88302油菜的分類準確率分別為80%,97%,77%。各有10%的Non-GMO樣本被誤分類為GT73和Mon88302;有3%的GT73被誤分類為Mon88302;有23%的Mon88302被誤分類為非轉基因油菜Non-GMO。Naive Baiyes分類方法的平均準確率為84.7%。
表1 樸素貝葉斯算法分類效果
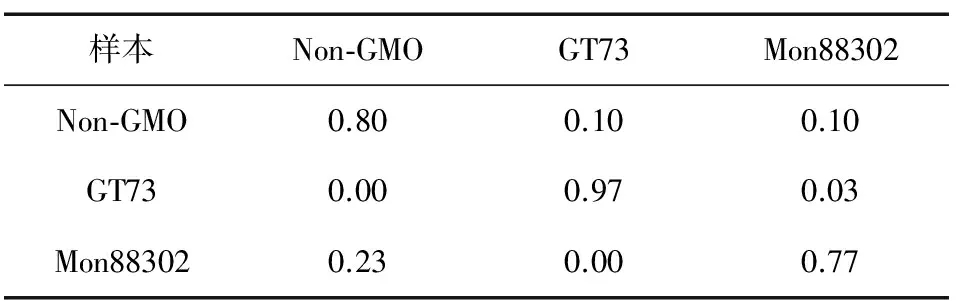
樣本Non-GMOGT73Mon88302Non-GMO0.800.100.10GT730.000.970.03Mon883020.230.000.77
2.3 基于樸素貝葉斯的Adaboost分類
Boosting算法也稱增強算法,可以用于分類問題和回歸問題,由Schapire在1990年首次提出[24]。Boosting是一類通過對多個弱學習器的集成,組合成為強學習器的分類算法。1995年,Freund和Schapire通過改進Boosting算法,提出了自適應提升(Adaptive Boosting,AdaBoost)算法[25]。AdaBoost算法擁有較好的精度,具有很高的實用性。AdaBoost算法的自適應表現在,前一個弱學習器預測錯誤的樣本權重會得到加強,更新權值后,樣本再次被用來訓練下一輪新的弱學習器。在每輪訓練過程中,樣本集合用來訓練新的弱學習器,產生新的權值,像這樣不斷地迭代循環,最終逼近預定的錯誤率。Adaboost算法的學習策略是最小化指數損失函數,當指數損失函數最小時,算法的分類錯誤率也逼近最小。
表2是基于樸素貝葉斯的Adaboost分類方法的轉基因樣本分類效果。從表2中可以看到Non-GMO,GT73,Mon88302的分類準確率分別為90%,100%,100%。各有7%和3%的Non-GMO樣本被誤分類為GT73和Mon88302;GT73和Mon88302樣本沒有出現分類錯誤;基于樸素貝葉斯的Adaboost分類方法的平均準確率為96.7%。
表2 基于樸素貝葉斯的Adaboost分類效果
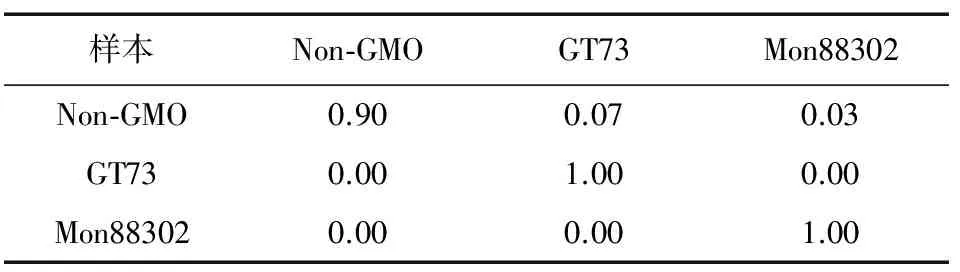
樣本Non-GMOGT73Mon88302Non-GMO0.900.070.03GT730.001.000.00Mon883020.000.001.00
2.4 PCA-RF分類
PCA算法是一種將高維數據集簡化為低維數據集的方法,屬于無監督降維。高維數據集通過PCA可以實現有效的降維處理,降維后的數據集可以有效地反映原始數據集的數據特征。
RF是一種綜合了集成分類器和隨機子空間的算法,是基于決策樹的一種算法,通過集成思想將多顆決策樹進行集成。決策樹是一種樹形結構,針對標簽問題進行“分類”和“決策”,最終的決策結果就是分類結果。
表3展示了PCA-RF方法中轉基因樣本分類效果。從中可以看到Non-GMO,GT73,Mon88302樣本的預測準確率分別為83%,93%,97%。PCA-RF分類方法的平均準確率為91%。有17%的Non-GMO樣本被誤分類為GT73;有3%的GT73被誤分類為Non-GMO;有3%的GT73被誤分類為Mon88302;有3%的Mon88302被誤分類為Non-GMO。
表3 PCA-RF分類效果
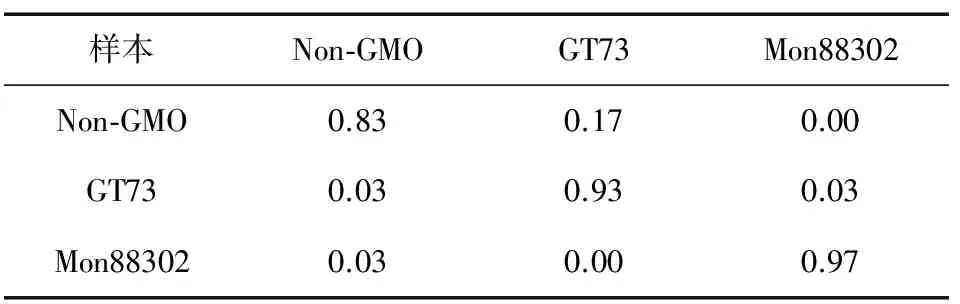
樣本Non-GMOGT73Mon88302Non-GMO0.830.170.00GT730.030.930.03Mon883020.030.000.97
2.5 PCA-SVM分類
SVM是一種通過非線性映射將原始特征映射到較高維度的算法[26]。SVM在許多實踐領域備受關注,如遙感、圖像處理等。SVM起源于分類問題,對于給定的訓練集D,SVM的思想就是找到一個劃分超平面將D中的樣本區分開。
表4展示了PCA-SVM方法的轉基因樣本分類效果。從中可以看到Non-GMO,GT73,Mon88302樣本的預測準確率分別為83%,100%,70%。PCA-SVM分類方法的平均準確率為84.3%。有17%的Non-GMO樣本被誤分類為GT73;有17%的Mon88302被誤分類為Non-GMO;有13%的Mon88302被誤分類為GT73。
表4 PCA-SVM分類效果
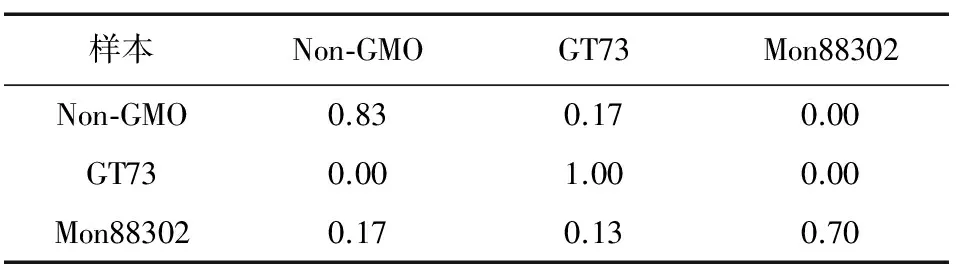
樣本Non-GMOGT73Mon88302Non-GMO0.830.170.00GT730.001.000.00Mon883020.170.130.70
表5對4種分類方法的分類效果進行了總結。從表5中可以看到,在轉基因油菜種子的太赫茲時域光譜識別中,只使用樸素貝葉斯方法分類的準確率只有84.7%。但是結合Adaboost算法后,分類準確率達到96.7%,是4種算法中最高的分類準確率。結果表明,基于樸素貝葉斯的Adaboost算法更適合與轉基因油菜種子的分類識別。
表5 4種分類方法分類效果比較

分類方法平均準確率樣品分類準確率Non-GMOGT73Mon88302樸素貝葉斯0.8470.800.970.77基于樸素貝葉斯的Adaboost0.9670.901.001.00PCA-RF0.9100.830.930.97PCA-SVM0.8430.831.000.70
3 結束語
本文通過太赫茲時域光譜系統研究了2種轉基因油菜種子和一種非轉基因油菜種子的太赫茲時域光譜,分析了其在0.2~1.1 THz頻譜范圍內的太赫茲吸收譜,通過4種機器學習分類方法,對油菜種子樣品進行了檢測識別。實驗結果表明,3種油菜種子的太赫茲吸收譜沒有明顯吸收峰,并且差異不大。借助于機器學習算法可以實現對其的準確分類,其中基于樸素貝葉斯的Adaboost分類算法可以達到96.7%的分類準確率。本文的研究為轉基因作物快速、準確的檢測提供了有益參考。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
