LBSN中基于社區聯合聚類的協同推薦方法
2019-11-15 01:50:02龔衛華裴小兵梅建萍
計算機研究與發展 2019年11期
龔衛華 金 蓉 裴小兵 梅建萍
1(浙江工業大學計算機科學與技術學院 杭州 310023) 2(浙江理工大學信息學院 杭州 310018) 3(華中科技大學軟件學院 武漢 430074)
近年來,隨著各種移動社交應用與位置服務的緊密融合,催生了一種新的異質信息網絡——基于位置的社交網絡(location based social network, LBSN).LBSN通過用戶在位置上的簽到功能把線上虛擬社會與線下物理世界關聯在一起.舉例說明,FourSquare,FacebookPlaces,Yelp等不僅具備傳統社交網絡的社交功能,還能衍生多種與位置相關的服務,比如位置共享、興趣點(point of interests,POIs)推薦、朋友或近鄰推薦等,從目前趨勢來看,面向LBSN的推薦技術已成為推薦系統領域最活躍的研究分支之一.
眾所周知,數據稀疏性一直是影響傳統推薦質量的關鍵難題之一,LBSN中的興趣點推薦和朋友推薦在此面臨著更大的挑戰.一方面是由于LBSN中的用戶-位置簽到矩陣是極端稀疏的,在LBSN中通常包含有數百萬的興趣點,用戶日常活動具有空間局部性,一些熱點位置如景點、餐館等地方容易受到大量用戶的關注,而對于每個用戶所能訪問的興趣點數量又十分有限.另一方面,LBSN中的用戶社交關系也是高度稀疏的,由用戶社交關系形成的社交網絡一般都具有小世界現象和無標度特性,這些規律表明極少量的用戶擁有較多的關系連接,而大量的用戶僅具有少量的關系連接.大量研究發現,深入理解并掌握LBSN中的社區結構是有效緩解數據稀疏性的新途徑,由于現實世界的許多網絡都普遍存在著社區結構特征,該結構所潛在的信息傳播能力、影響力等特性對于改善推薦性能具有重要意義,比如同一社區內有社交關聯的用戶往往會表現出相似的興趣愛好和簽到行為特征,又比如地理位置相近、關注興趣點相同的用戶比較容易聚集成社區群體,并且同一社區內的用戶會對其他用戶的選擇產生一定的影響等.
目前,在傳統社交網絡領域雖然已有許多社區發現成果,但對其拓展的異質網絡結構如LBSN中的復雜社區研究卻非常匱乏.總的來說,現有研究大多將社交網絡從圖聚類或分割角度提出一些以節點為中心或邊為中心的社區發現方法,由此得到的社區結構大致有2類:非重疊的社區與重疊的社區.非重疊的社區認為每個節點或用戶只能屬于一個社區,社區之間沒有重疊.而在重疊社區中,用戶可以隸屬于多個社區,并且可以與多個社區內的用戶關系都十分緊密.相比之下,重疊社區能夠更真實地反映用戶在現實網絡中用戶群體興趣特征與行為規律,從而使得這種結構具有更廣、更準確的推薦范圍和能力.現階段主流的重疊社區發現方法有基于團滲透的方法[1-2]、基于鏈接劃分的方法[3-4]、基于標簽傳播的方法[5-7]、基于局部擴展與優化的算法[8-11]等.然而,這些研究都存在一些局限性:一是無法準確表達社區重疊部分的模糊性;二是這些方法都是針對同構的網絡結構而言,而無法適用于LBSN這種包含多模實體及多維關系的異質網絡.為此,本文的研究動機主要表現在:一方面是針對社區重疊邊界的不確定性問題,我們采用基于非負矩陣分解的模糊聚類方法更加準確地刻畫重疊社區結構特征;另一方面,由于LBSN比傳統社交網絡不僅僅是增加了位置維度,還包含了多種異質關系,因而亟待提出一種新的融合用戶與位置實體及其多維關系的社區發現方法.
本文的主要貢獻包括3點:
1) 提出了基于非負矩陣分解的聯合聚類方法獲得LBSN中緊密關聯的用戶模糊社區與興趣點聚簇結構,有效緩解了朋友推薦和POI推薦中的數據稀疏問題.
2) 融合了LBSN中用戶與位置這2類實體及其多維異質關系,主要包括用戶間的社交關系、用戶-位置簽到關系、地理位置相似關系(即考慮了距離和標簽因素的興趣點特征).
3) 在Gowalla和Foursquare(NYC)數據集上的實驗結果表明,本文提出的MRNMF(multi-relational nonnegative matrix factorization)方法同時在朋友與興趣點這雙重推薦上比其他傳統方法具有更優越的推薦性能.
1 相關工作
重疊社區已被發現廣泛存在于各種社交網絡中,現有針對重疊社區結構的研究從采用的模型或方法上主要分為模糊的與非模糊的社區發現算法,其中非模糊的重疊社區發現研究一直是大多數國內外學者關注的熱點方向.如引言中基于團滲透方法的主要思想是將社區視為由一些團(全連通子圖)構成的集合,這些團之間通過共享節點而緊密連接,代表性算法如CPM[2].基于鏈接劃分方法是將鏈接而不是節點作為考慮對象,通過設計適當的劃分策略來獲取鏈接社區結構,典型的算法有DBLC[3]和DBLINK[4].基于標簽傳播方法是一種半監督學習方法,主要是利用已標記節點的標簽信息,通過已標記節點和未標記節點的相似度連邊權重預測未被標記節點的標簽信息,最常見的算法如LPA[5],SPLA[6],LPPB[7]等.基于局部擴展與優化的算法是利用網絡的局部特性不斷挖掘網絡中的社區結構,例如LFM[10],OSLOM[11]等都是該方法的典型代表.不難發現,這些方法的共同缺陷是無法恰當表達重疊節點在多個社區中的隸屬強度,同時也沒有考慮多維關系的融合而得到比較單一的社區結構.
另一種以模糊聚類理論為代表的重疊社區發現研究成果已表明,模糊重疊更符合真實社交網絡的實際情況,該類方法的經典算法如FCM(fuzzy c-means)[12]最早應用于社交網絡的模糊重疊劃分,通過將重疊社區檢測建模成目標函數的最小化問題:
(1)
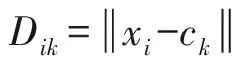
(2)
易知,模糊劃分的要點是允許節點以不同的隸屬度值歸屬于多個社區,然而,由于FCM在聚類中僅考慮了節點距離特征因而丟失了網絡圖結構信息.此后,有一些文獻[13-14]提出了一種結合模塊度函數的FCM聚類方法發現網絡中的重疊社區,但其缺點是社區結果依賴于隨機游走值和模糊因子.
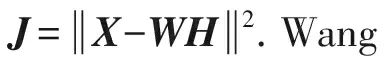
此外,NMF方法也特別適合發現重疊的社區結構,Zhang等人[22]提出基于對稱矩陣分解的SBMF模型發現重疊社區結構,并通過劃分密度方法自動確定合適的社區個數,該模型不僅能夠明確劃分網絡的社區結構,還能提供節點與社區的隸屬強度.文獻[23-24]都提出了基于貝葉斯的NMF方法發現網絡中的重疊社區,采用軟劃分方式有效刻畫節點對多個社區的隸屬程度.還有文獻[25]提出了基于偏好的非負矩陣分解模型PNMF,在重疊社區發現中融入了鏈接偏好信息.
綜上可知,現有大多數傳統的NMF方法基本上都使得被分解的2個低維矩陣具有共同的維度空間,這種矩陣分解方式僅適于發現同構網絡中的單一社區結構,也缺乏有效融合已知先驗知識與多維關系或特征的方法.因此,另一些研究提出了改進的非負矩陣分解方法實現聯合聚類,最早由Ding等人[26]提出了正交非負矩陣三分解的聯合聚類方法,其表示形式如X≈FBZT,其中F表示行聚類的指示矩陣,而Z表示列聚類的指示矩陣.還有文獻[27]也提出有限的非負矩陣三分解方法BNMTF發現重疊社區,其表示形式如X≈UBUT,其中U表示節點對社區的隸屬度矩陣,而B表示社區間的交互矩陣.這些基于NMF的聯合聚類方法雖具有比較理想的異質關系數據處理能力,但遺憾的是,迄今針對多模異質網絡的社區發現研究仍十分缺乏,特別是對LBSN中的復雜社區結構沒有深入的認識與理解.
受上述工作啟發,本文將針對LBSN這種新型的異質網絡提出一種基于NMF的融合多維異質關系的聯合聚類模型,不僅能獲得準確的用戶模糊社區,同時還能得到關聯的興趣點聚簇,該緊密結構有助于提高朋友推薦與興趣點推薦的質量.
2 LBSN的定義與模型表示
LBSN是一種由用戶與地理位置這2種實體及其多維關系復合而成的異質網絡,如圖1所示.在圖1中LBSN分別由用戶層和地理位置層組成,上層為傳統的用戶社交關系網絡,下層為地理位置標簽網絡,上下層之間通過用戶-位置簽到行為建立起異質實體間的聯系.
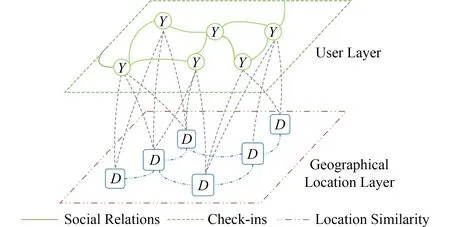
Fig. 1 Structure of composite relational networks in LBSN圖1 LBSN中的復合關系網絡結構
為了描述LBSN的形式化模型,首先給出相關的定義:
定義1.用戶社交關系網絡.在同一用戶層的用戶間社交關系形成的網絡可表示成一個無向圖結構,記為S=(Y,E),其中,Y表示用戶集,E表示用戶社交關系的邊集,即E={(yi,yj)|yi,yj∈Y}.
定義2.用戶-位置簽到網絡.用戶在地理位置上的簽到行為形成的關系網絡可表示成二部圖結構,記為P=(Y,D,T),其中,Y表示用戶集,D表示地理位置集,T表示用戶與位置間的簽到關系集,即T={(yi,dj)|yi∈Y,dj∈D,Y∩D=?}.
定義3.地理位置標簽網絡.地理位置標簽網絡可抽象成一個無向圖,記為G=(D,C),其中,D為地理位置集合,C表示地理位置間的關系邊集,即C={(di,dj)|di,dj∈D}.
在此基礎上,本文進一步給出融合定義1~3的3種關系的異質復合網絡模型即基于位置的社交網絡的形式化定義.
定義4.基于位置的社交網絡.是一種由用戶與地理位置實體及其多維關系構成的異質網絡圖,記為WLBSN=S×P×G=(Y,E)×(Y,D,T)×(D,C)=(Y,D,E,T,C),其中包含了2種實體:用戶集Y與地理位置集D,與對應的3種維度關系:用戶間的社交關系E、用戶與位置的簽到關系T、位置間的相似關系C.
在LBSN的用戶層中,對于給定的用戶集合Y={y1,y2,…,yn},用戶之間的相似性可通過檢測社交關系網絡S中是否具有共同朋友進行評估,于是我們采用Sorgenfrei系數來度量用戶社交相似性:
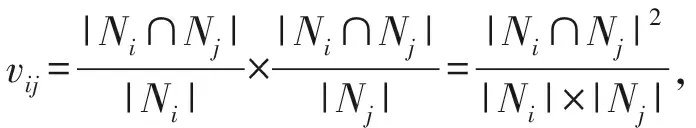
(3)
其中,Ni與Nj分別表示用戶yi與用戶yj的鄰居集合.由此可見,用戶社交關系形成的相似性矩陣可表示為V=(vij)n×n.
對于LBSN的地理位置層,地理空間上分布的位置集合有D={d1,d2,…,dm},各位置間的相似性不僅直接與其空間距離特性相關,還與位置上的語義標簽屬性密切關聯,我們綜合考慮這2種因素給出地理位置相似性的定義:
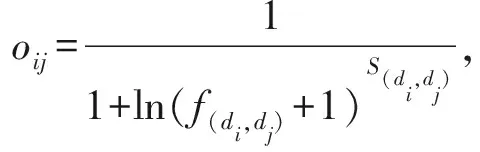
(4)
其中,f(di,dj)表示位置di與dj間的歐氏距離,s(di,dj)∈[0,1]表示位置di與dj的標簽相似性.因此,由地理位置相似關系構成的位置特征矩陣可記為O=(oij)m×m.
3 融合多維異質關系的聯合聚類模型
在第2節所述的LBSN模型基礎上,本文提出一種基于非負矩陣分解的用戶模糊社區發現與興趣點聚簇方法,采用三因子矩陣分解的表示形式如R≈UHL,將用戶-位置關系矩陣R的行和列同時聚類分解為3個矩陣U,H,L.其中,U與L分別為用戶端和位置端的聚類指示矩陣,H為關聯矩陣.該方法的目標是在把原始矩陣映射到低維特征空間過程中既考慮了用戶-位置簽到關系,又融合了傳統的用戶社交關系與地理位置的興趣點特征.
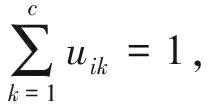
為了使矩陣分解的誤差最小化,我們構造的目標函數為
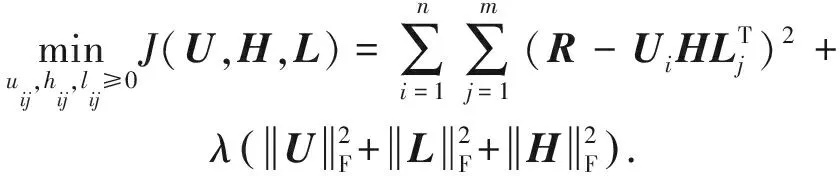
(5)
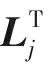
在式(5)表示的非負矩陣分解模型中,用戶對位置的興趣偏好特征由用戶-位置簽到關系矩陣R表示,該矩陣從行聚類和列聚類角度被同時分解成關于用戶端的隸屬矩陣U與地理位置端的隸屬矩陣L,從而以更直觀的形式表明了用戶興趣模型不僅會受到用戶重疊社區結構的影響,還與位置聚簇特征密切相關.本質上看,用戶社區結構源于用戶間內在的社交關系,而位置聚簇結構則依賴于興趣點特征的相似性.
為了進一步考慮多維關系特征的影響,我們在式(5)的基礎上提出一種新的融合社交關系與興趣點特征的矩陣分解模型,整體目標函數為
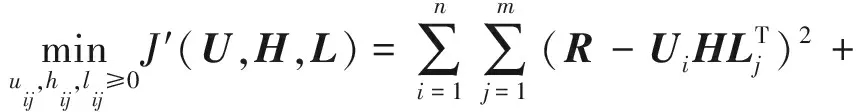
(6)
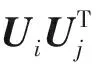
為了求解目標函數的局部最優值,采用隨機梯度下降法(SGD)分別對U,H,L求導可得:
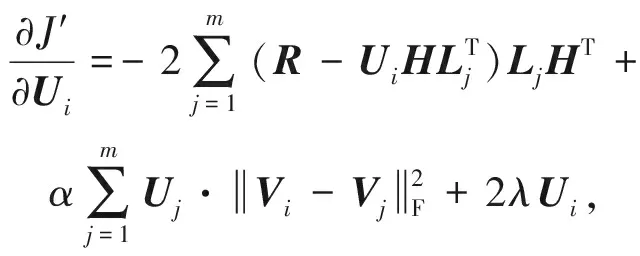
(7)
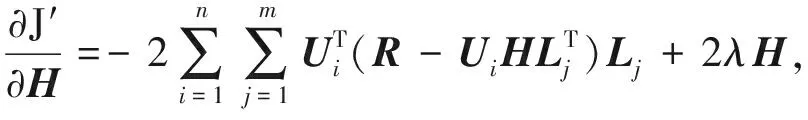
(8)
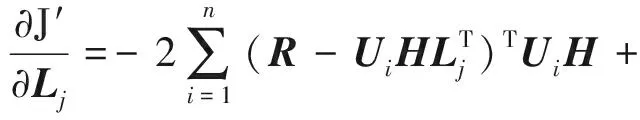
(9)
其中,式(7)與式(9)中的特征矩陣V與O分別由式(3)與式(4)計算而得,然后再根據式(10)~(12)迭代更新矩陣U,H,L的值,符號τ表示梯度下降迭代次數,μ>0表示學習速率.最終目標是使得所求矩陣U,H,L沿梯度下降方向不斷迭代更新直至收斂或設定的閾值為止.
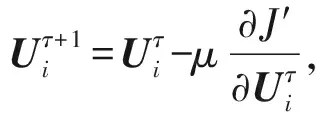
(10)
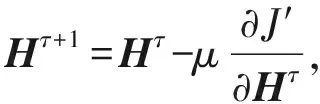
(11)
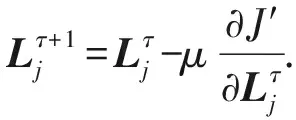
(12)
4 實驗與結果分析
本實驗的運行環境為Intel Core i7-4500U處理器、16 GB內存、Windows 7操作系統,算法采用Python2.7編程實現.下面分別給出了實驗數據集描述、評價指標與實驗結果分析.
4.1 實驗數據集與對比方法
我們選取2種真實的數據集Foursquare (NYC)和Gowalla,驗證本文所提方法的聯合聚類效果與推薦性能.實驗前先過濾數據集以移除一些異常數據,對于Foursquare(NYC)數據集,我們篩選出超過2人簽到的地理位置,以及評論數多于5條的用戶及其所擁有的社交關系.在Gowalla數據集中,我們篩選出簽到數超過50的地理位置,以及社交關系超過50條且簽到次數也超過50的用戶.預處理完成后,各數據集中用戶數、位置數以及社交關系和簽到關系等基本信息如表1所示:

Table 1 Basic Information of Two LBSN Datasets表1 2種LBSN數據集的基本信息
從表1中可以看出,數據集Foursquare (NYC)與Gowalla上的用戶簽到密度都非常低,反映了LBSN中的興趣點有較大的稀疏性,而在用戶社交關系上,這2個數據集的社交用戶平均度分別約為9.2和14.1,表明社交用戶間的交互關系比較密切.
為了評價各方法在推薦性能上的差別,我們選取4種代表性的方法進行實驗對比:
1) FCM方法.FCM是一種經典的基于模糊聚類的方法,文獻[12]使用該方法發現復雜網絡中重疊的社區結構.本實驗中FCM方法僅從用戶社交關系維度檢測社交網絡中的重疊社區結構,式(1)中的系數m=2.
2) NMF方法.NMF是由Lee等人[15]提出的一種非負矩陣分解方法,其形如X≈WH,該方法可用來發現社交網絡中的重疊社區結構.本文將用戶社交關系矩陣分解為2個對稱的用戶社區隸屬矩陣,即為X≈HHT.
3) NMTF方法.Ding等人[26]提出了非負矩陣三因子分解的聯合聚類方法NMTF,其表示形式如X≈FBZT,該方法在LBSN的用戶重疊社區發現過程中僅考慮結合了用戶社交關系與簽到關系這2種信息.
4) MRNMF方法.MRNMF是本文提出的社區聯合聚類方法,該方法融合了LBSN異質網中的用戶社交關系、用戶-位置簽到關系以及興趣點特征等多維度因素,MRNMF方法既能發現用戶模糊社區,又能獲得興趣點聚簇.
上述4種對比方法中,FCM方法代表了典型的模糊聚類社區發現方法;NMF方法是傳統的基于對稱非負矩陣分解方法發現重疊社區結構;而NMTF和MRNMF方法雖都屬于另一種代表性的基于非負矩陣三因子分解的聯合聚類方法,但本文的MRNMF方法還通過加入特征項深度融合了多種維度的關系與特征.
4.2 評價指標
實驗將采用50次10-折交叉驗證法,把表1中2種LBSN數據集上的用戶和地理位置隨機分為10份,每次選擇其中的80%作為訓練集,剩下的20%作為測試集,將50次評價結果取平均值得到最終的評估數據.
本文提出的MRNMF模型既能得到用戶重疊社區,又能獲得興趣點聚簇.為了評價該結果在朋友與興趣點上的雙重推薦性能,我們采用準確率Precision@K(P@K)和召回率Recall@K(R@K)這2種廣泛使用的Top-K指標進行實驗比較.另外,為了度量算法的社區劃分質量,本文還將模塊度作為是一種重要的評價指標,針對重疊社區結構的模塊度Q可定義為
(13)
其中,m表示邊數,Gij是網絡鄰接矩陣元素,ki表示節點i的度,Pic表示節點i在社區c中隸屬度系數.式(13)表明,模塊度Q值越大則表示重疊社區的模塊化程度越高.
4.3 實驗結果比較
1) POI推薦效果對比
在POI推薦性能方面,本文比較了4種方法在2種數據集上推薦Top-K個興趣點時的準確率與召回率,結果如圖2與圖3所示,橫軸上的K值表示推薦的Top-K興趣點數量.由圖2與圖3可知,在Foursquare(NYC)和Gowalla數據集上,FCM與NMF方法由于僅對單一社交關系聚類而沒有用戶興趣點信息,使其基本不具備POI推薦能力,隨機推薦實驗中的性能指標都低于0.01,因此這2種方法的POI推薦能力可以忽略不計.對于NMTF與MRNMF方法,當設置相同的位置簇數為30時,兩者都隨著K的增加POI推薦的準確率有所下降,召回率有一定程度的上升.綜合來看,本文的MRNMF方法的POI推薦能力顯著地強于NMTF方法,其原因是MRNMF方法既考慮用戶社交關系和簽到關系,又融入了地理位置上的興趣點特征,在2種數據集上的實驗結果都表明MRNMF方法聚類的位置簇結構能有效地促進POI推薦性能的提高.
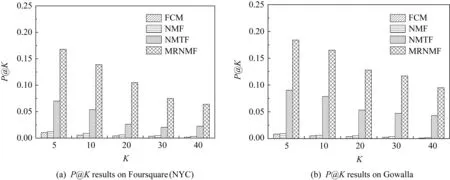
Fig. 2 Precision comparison of POI recommendation圖2 POI推薦的準確率對比
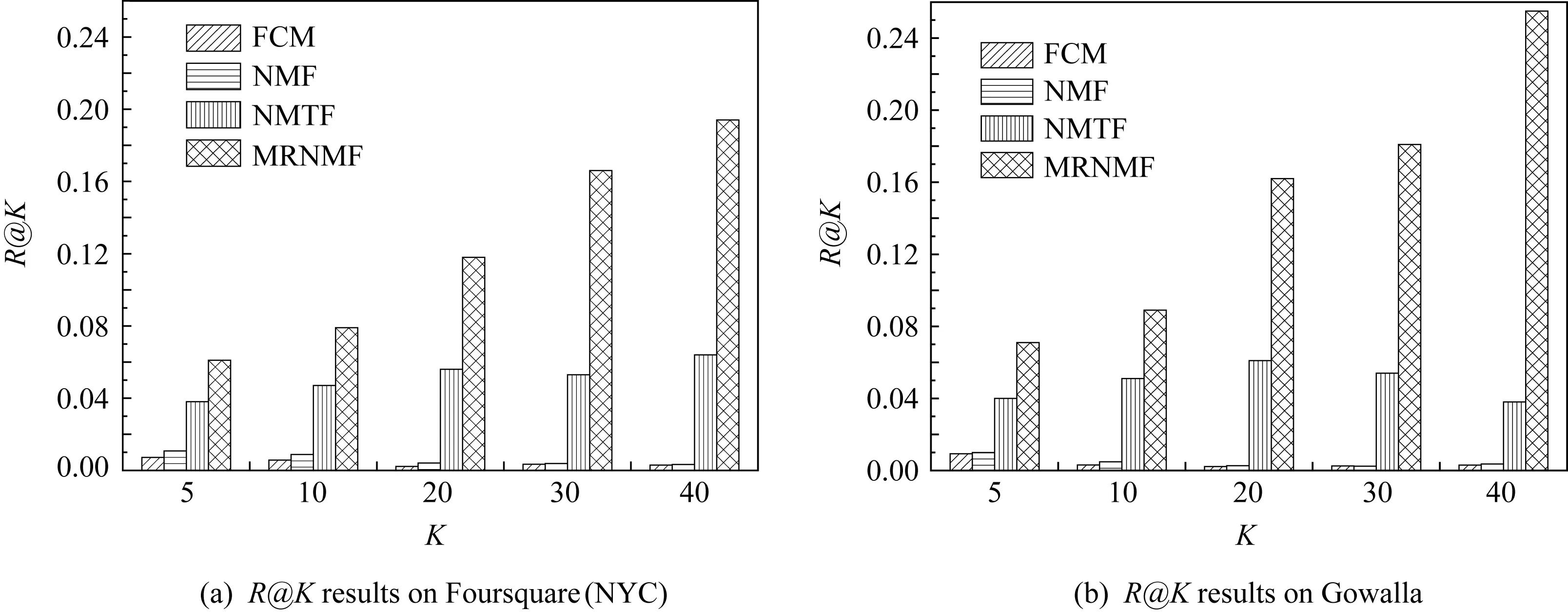
Fig. 3 Recall comparison of POI recommendation圖3 POI推薦的召回率對比
2) 朋友推薦效果對比
在朋友推薦性能上,本文比較了4種方法在用戶層上推薦Top-K個相似用戶或朋友的準確率與召回率,結果如圖4與圖5所示,各方法所設置的用戶社區簇參數在Foursquare(NYC)與Gowalla數據集上分別為18與30.從圖4與圖5可以看出,本文的MRNMF方法在Foursquare(NYC)和Gowalla上對朋友推薦的準確率、召回率指標都普遍優于其他3種方法;FCM與NMF方法有比較相近的朋友推薦性能,原因是這2種方法僅能得到比較簡單的用戶重疊社區而無法顧及多維關系的影響.在結合了多維關系與特征之后,MRNMF方法比NMTF方法的推薦準確率提升至少25%以上,同時在召回率上高出11%~20%.
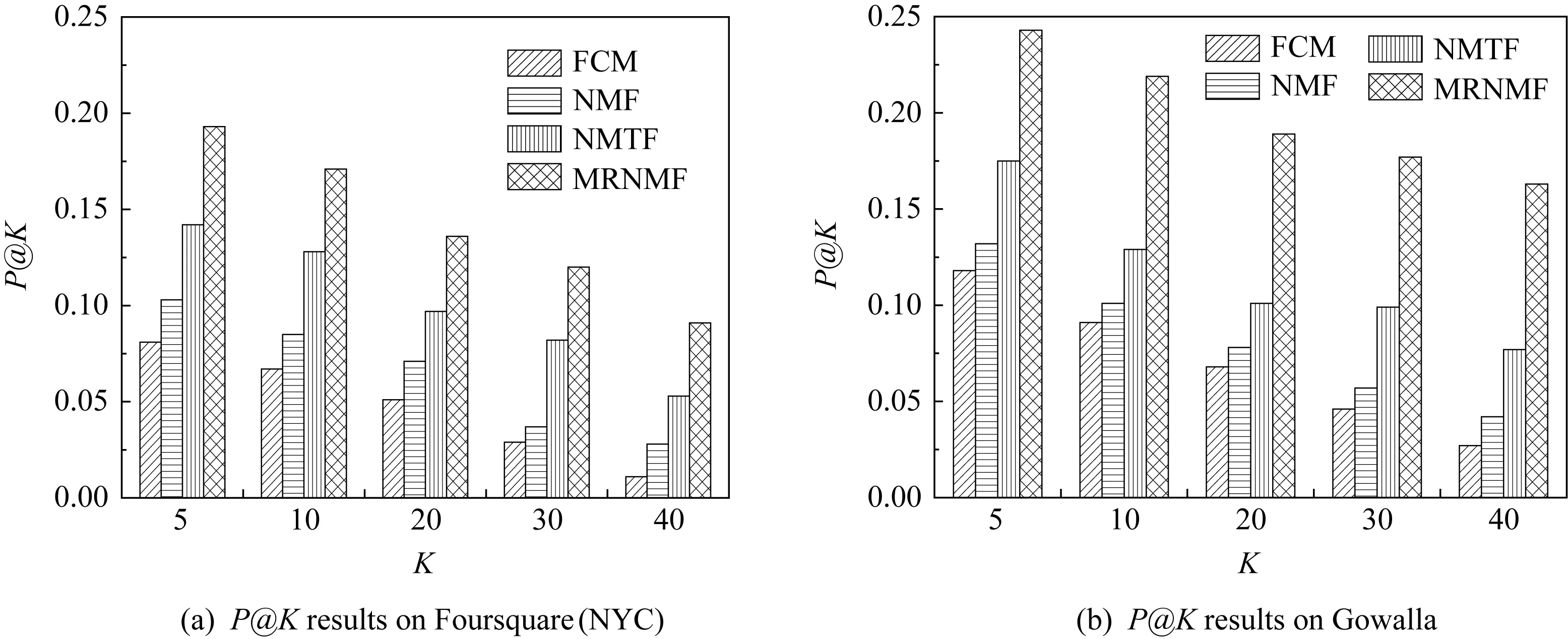
Fig. 4 Precision comparison of friend recommendation圖4 朋友推薦的準確率對比
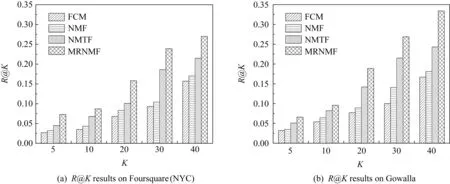
Fig. 5 Recall comparison of friend recommendation圖5 朋友推薦的召回率對比
綜合圖2~5可得出,考慮到地理位置簽到密度比用戶社交關系存在更大的數據稀疏性,上述 4種方法都在朋友推薦性能上表現出比POI推薦更好的質量;從數據集角度看,4種方法在Gowalla上的朋友推薦性能普遍都比Foursquare(NYC)上的效果更好,這與Gowalla數據集上的用戶社交關系較密集有關,用戶社區結構特征也更明顯.總的來看,本文提出的MRNMF方法既能發現用戶重疊社區,又能獲得興趣點聚簇,這兩者同時還具有一定的關聯性,從而使得該方法在朋友推薦與POI推薦的性能上都整體上優于其他方法.
3) 用戶重疊社區的模塊度比較
為了評價用戶重疊社區結構,本文比較了4種方法分別在Foursquare(NYC)與Gowalla數據集上的重疊社區模塊度Q值,設定劃分的用戶社區簇參數c分別為12,18,24,30,實驗結果如表2所示:
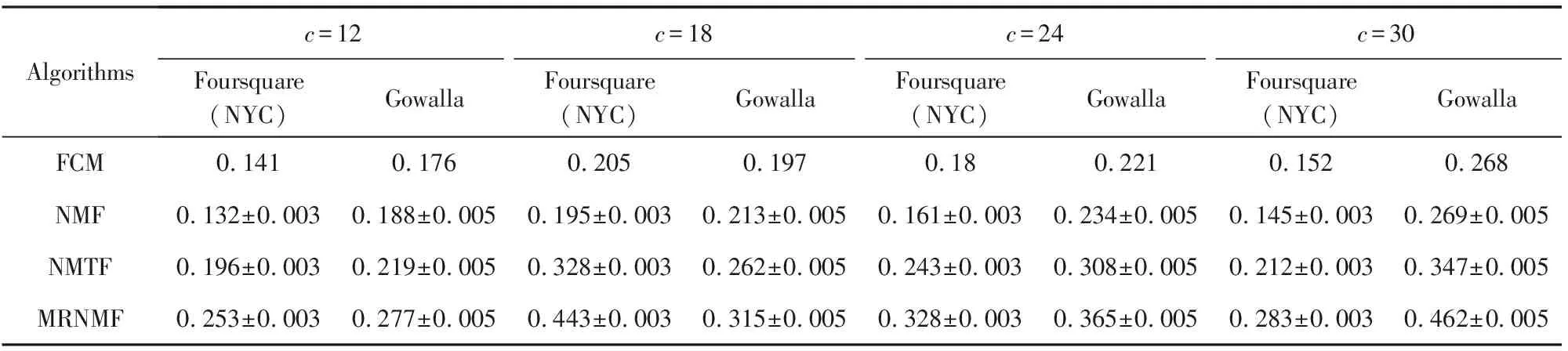
Table 2 Comparisons of Modularity Q Values of Four Methods Under Different Clusters表2 4種方法在不同社區簇c下的模塊度Q值對比
從表2中可以看到,FCM與NMF方法在2種數據集上的社區模塊度值基本相近,表明這2種方法獲得了幾乎相同的社區特性,由于兩者都僅考慮了單一維度的社交關系,與NMTF與MRNMF方法相比,重疊社區結構仍不夠明顯.總體而言,本文的MRNMF方法在不同社區簇參數c下都表現出最好的模塊度性能,當社區簇大小分別在Foursquare(NYC)與Gowalla上取18與30時有最大的模塊度值,其原因是MRNMF方法在矩陣三因子分解中不僅結合了用戶社交關系與簽到關系信息,還加入了興趣點特征,因而能夠獲得最優的用戶重疊社區效果,由此表現出最佳的朋友推薦能力.
4) 社區簇c與位置簇g參數的影響分析
下面將考察MRNMF模型中的社區簇與位置簇大小分別對朋友推薦與POI推薦的性能影響.對式(6)進行非負矩陣三因子分解時涉及到2個重要參數是社區簇c與位置簇g,圖6顯示了社區簇參數分別在Foursquare(NYC)和Gowalla數據集上對朋友推薦的準確率變化情況,而圖7則給出了不同位置簇參數在這2種數據集上對POI推薦的準確率結果.
由圖6可知,朋友推薦準確率在2種數據集上的變化趨勢基本相同,在不同Top-K值下的朋友推薦準確率都隨著社區簇的增大而逐漸升高,當用戶社區簇c在Foursquare(NYC)與Gowalla上分別為18和30時,推薦準確率達到最大值,這說明劃分合適的社區簇有助于發現真實的用戶群體.由于數據集Foursquare(NYC)上的用戶數量少于Gowalla,且社交用戶關系度要比Gowalla的更稀疏,因此在Foursquare(NYC)數據集上的朋友推薦準確率略低于Gowalla.
從圖7可以看出,POI推薦在不同Top-K值下的準確率都隨著位置簇參數g的增大而平緩升高,當位置簇數在Foursquare(NYC)與Gowalla數據集上分別取35與30時有最好的推薦性能,考慮到地理位置具有較大的稀疏性,并且位置相似性度量受到距離與標簽屬性因素不平衡的影響,地理位置聚簇的結構特征雖不如用戶社區簇那樣明顯,但比傳統POI推薦方法的準確性還是有較大的提高.綜上,MRNMF方法能同時獲得關聯的用戶重疊社區與位置簇,有助于提高朋友推薦與POI推薦的精度.
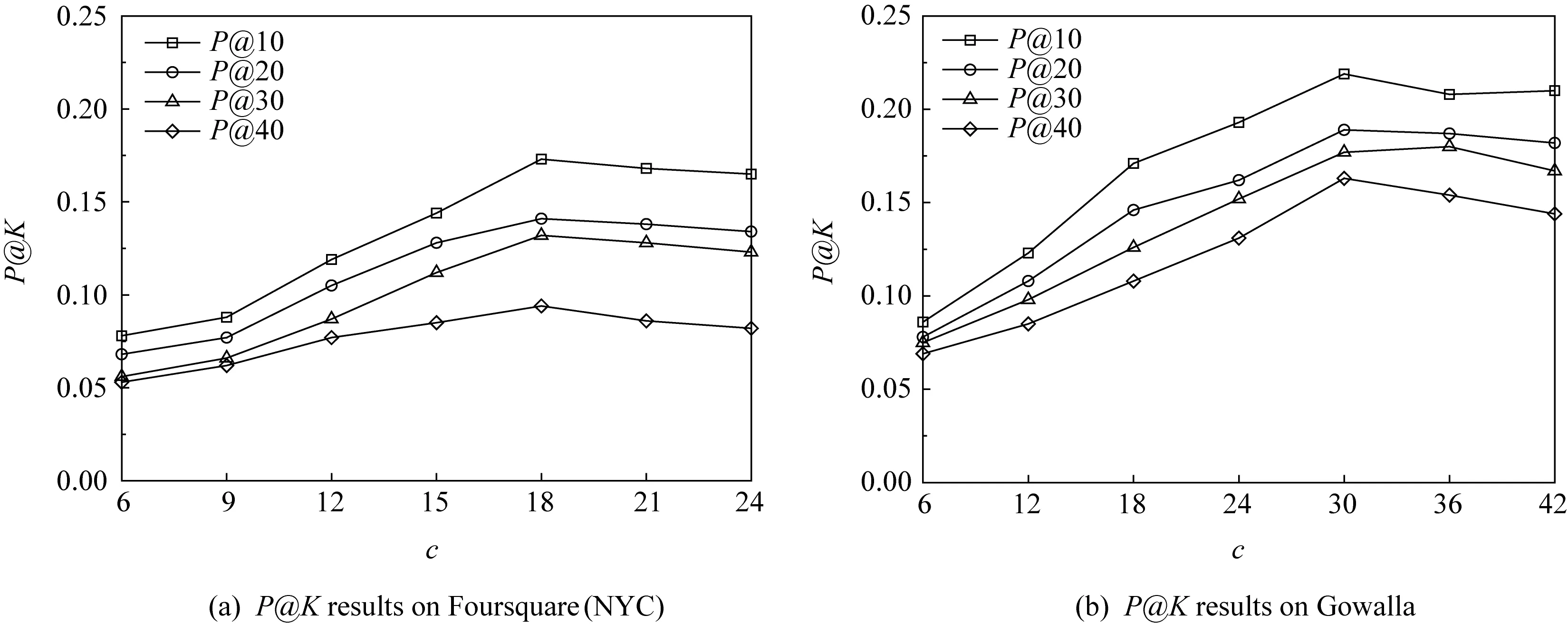
Fig. 6 Effect of community cluster parameter c on friend recommendation圖6 社區簇參數c對朋友推薦的影響
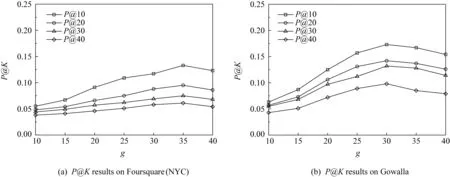
Fig. 7 Effect of location cluster parameter g on POI recommendation圖7 位置簇參數g對POI推薦的影響
5) 權重因子α與β的影響分析
在如式(6)的MRNMF方法中,α與β分別代表了考慮用戶社交關系與興趣點特征的權重因子,它們在一定程度上調節著用戶社區與位置簇的聚類結果.圖8與圖9分別檢驗了不同的α與β對Top-K值取10時朋友推薦與POI推薦的準確率變化情況.在2種數據集上的實驗結果顯示,參數α與β分別對朋友推薦與POI推薦的準確率表現出基本相同的變化趨勢,即都是先升后降的過程,并各自在0.5與0.1時取得最大值.實驗驗證了α與β所控制的社交關系與興趣點特征比重能夠直接影響到朋友推薦與POI推薦的效果.
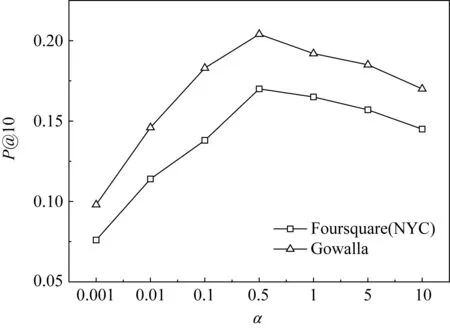
Fig. 8 Precision results of friend recommendation influenced by parameter α圖8 參數α對朋友推薦的準確率影響
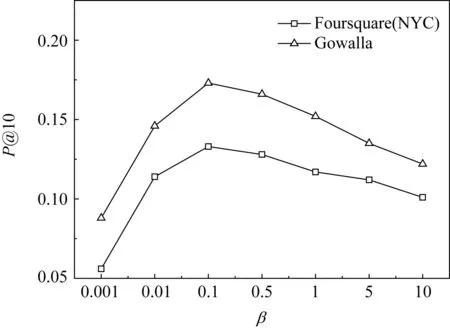
Fig. 9 Precision results of POI recommendation influenced by parameter β圖9 參數β對POI推薦的準確率影響
5 總 結
異質網絡中的社區結構是當前非常值得關注的研究方向,現有研究一直都面臨著如何融合多模實體及其多維關系的挑戰性難題.本文針對LBSN這種新型異質網絡中的社區發現問題,提出了一種融合用戶與位置實體及其多維關系的社區發現方法MRNMF.該方法采用基于非負矩陣分解的聯合聚類模型,通過構建基于距離度量的損失函數來評估矩陣近似分解誤差,并在此基礎上考慮結合用戶社交關系、用戶-位置簽到關系以及興趣點特征等多維度的影響因素,使之融合到統一的表示模型中,然后運用隨機梯度下降法來求解目標函數的局部最優值.其最大的優勢和創新點是通過基于NMF的聯合聚類方法能同時獲得LBSN中緊密關聯的用戶模糊社區與興趣點聚簇,以有效緩解推薦中的數據稀疏問題.最后,在Foursquare(NYC)和Gowalla數據集上的實驗結果表明,本文所提的MRNMF方法在準確率和召回率2個評價指標都優于其他傳統的社區發現方法,在朋友與興趣點這雙重推薦上都具有最優的推薦性能.在未來工作中,我們將進一步考慮時間因素挖掘出反映用戶及興趣點遷移的社區演化結構.
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
