面向雙注意力網絡的特定方面情感分析模型
2019-11-15 01:50:18孫小婉孫玉東
計算機研究與發展 2019年11期
孫小婉 王 英 王 鑫 孫玉東
1(吉林大學軟件學院 長春 130012) 2(吉林大學計算機科學與技術學院 長春 130012) 3(符號計算與知識工程教育部重點實驗室(吉林大學) 長春 130012) 4(長春工程學院計算機技術與工程學院 長春 130012)
社交網絡的迅猛發展為人們提供了發表和分享個人言論的廣闊平臺,各種網絡數據迅速膨脹,越來越多的人在網絡上發表意見和表達情感.如何利用自然語言處理(natural language processing, NLP)技術分析社交網絡短文本的情感傾向,已經成為研究人員關注的熱點[1].
用戶在針對某實體發表觀點時,除了在評論中給出總體評價外,通常也會針對該實體的多個方面發表觀點評論.特定方面情感分析(aspect-based sentiment analysis, ABSA)作為情感分析的重要子任務之一,可以針對不同的方面挖掘用戶更細膩更具體的情感表述[2].例如句子“The design of space is good but the service is horrible”,對于特定方面“space”是積極情感,而對于特定方面“service”是消極情感.與普通情感分析不同,特定方面情感分析需要判斷句子中不同方面的情感極性,這不僅依賴于文本的上下文信息,同時也要考慮不同方面的情感信息.因此,在同一句子中針對不同特定方面可能會出現完全相反的情感極性,可見特定方面情感極性的分析可以更加有效地幫助人們了解用戶對不同方面的情感表達.
近年來,深度學習已在NLP領域取得了令人矚目的成功.同時,結合注意力機制(attention mech-anism)的神經網絡模型在特定方面情感分析任務中取得了比以往方法更好的效果.梁斌等人[3]提出一種基于多注意力的卷積神經網絡(convolutional neural network, CNN),利用詞向量注意力機制、詞性注意力機制和位置注意力機制與卷積神經網絡結合,使模型在不需要依存句法分析等外部知識的情況下,有效識別特定方面的情感極性.Zhu等人[4]提出使用雙向長短期記憶網絡(long short-term memory, LSTM)構建句子的長期記憶,然后使用CNN從記憶中提取注意力以獲得更具體的句子表示,該方法使用特定方面嵌入表示目標信息,取得較好的分類效果.結合注意力機制的神經網絡可以在訓練過程中高度關注特定方面的特征,并可以有效針對不同特定方面調整神經網絡的參數,進而挖掘更多的隱藏特征.
目前,結合注意力機制的神經網絡主要包括基于注意力機制的卷積神經網絡(CNN)和基于注意力機制的循環神經網絡(recurrent neural network, RNN)[5].CNN在卷積層使用濾波器抽取文本特征,只能獲取濾波器窗口內單詞間的依賴關系,無法獲取句子中所有單詞間的依賴關系,進而無法獲取整體結構信息.在圖像處理領域,相鄰像素點之間往往存在很大的相關程度,但在NLP領域,由于修飾詞、語法規則和表達習慣的影響,使得相鄰單詞的相關程度并不高.RNN及其衍生網絡,例如LSTM,GRU(gated recurrent unit)在NLP領域應用廣泛,RNN的原理是基于“人的認知是基于過往經驗和記憶”這一觀點提出,與CNN不同,RNN不僅考慮前一時刻的輸入,而且賦予網絡對前面內容的記憶功能,但RNN及其衍生網絡這類序列模型,難以實現并行計算,訓練時間過慢,并且句子中單詞間的依賴程度會隨著距離增加而減弱.此外,CNN和RNN這2種結合注意力機制的神經網絡模型,都使用單一注意力模式,即模型只進行單次注意力計算,導致模型無法對句中單詞間的依賴關系實現深層次抽取.
針對上述問題,本文提出面向雙注意力網絡的特定方面情感分析模型(dual-attention networks for aspect-level sentiment analysis, DANSA),主要貢獻有3方面:
1) 提出融合上下文自注意力機制和特定方面注意力機制的多頭雙注意力網絡模型,不僅實現了大規模并行計算,大大降低了模型的訓練時間,而且能夠抽取文本全局結構信息和特定方面與文本的依賴關系.
2) 提出將多頭注意力機制應用在特定方面情感分析任務中,學習文本在不同線性變換下的注意力表示,能夠更全面、更深層次地理解句中單詞之間的依賴關系,更好地解決特定方面情感分析問題.
3) 在SemEva2014數據集和Twitter數據集上進行實驗,相比于傳統神經網絡和基于注意力機制的神經網絡,DANSA取得了更好的情感分類效果,進一步驗證了DANSA的有效性.
1 相關工作
1.1 特定方面情感分析
特定方面情感分析是細粒度的情感分析,對特定方面情感極性的挖掘能夠幫助人們做出更正確的決策[6-7].
在過去的研究中,特定方面情感分析方法主要是基于情感字典和機器學習的傳統方法[8].這些方法需要對輸入文本進行大量的預處理和復雜的特征工程,以及例如依存關系分析等外部知識.模型的優劣,很大程度上取決于人工設計和先驗知識,耗時耗力且模型推廣能力差.
近年來,深度學習技術在NLP各類任務中取得了重大突破,在特定方面情感分析領域也取得了比傳統機器學習方法更好的效果.Xue等人[9]提出基于卷積神經網絡和門控制的模型,利用Gated Tanh-ReLU單元根據給定的特定方面或實體選擇性地輸出情感極性,在訓練速度和分類準確度上都取得了較好的效果.Piao等人[10]提出使用CNN和RNN聯合解決金融領域中的特定方面情感極性預測問題,利用Rigde回歸和特定方面預測投票策略,不依賴任何的手工標注.Ma等人[11]提出在使用Senti-LSTM模型解決特定方面情感分析問題時,聯合情感常識共同對模型進行訓練并得到更好的分類效果.這類基于深度神經網絡的模型與傳統機器學習方法相比,大大降低了預處理和特征工程的工作量,但仍需要結合一些如依存句法分析、依存關系樹等外部知識.
目前,將注意力機制與神經網絡相結合的方法,已經成為特定方面情感分析問題的主流方法.Cai等人[12]提出將注意力機制與LSTM結合進行特定方面情感的層次提取,同時關注情感術語和特定方面的潛在聯系.Gu等人[13]認為現有的工作大多忽略特定情感詞與句子之間的關系,提出基于雙向門控循環單元(gated recurrent unit, GRU)的位置感知雙向注意力網絡,認為當特定方面術語出現在某一句子中時,其鄰近的單詞應該比其他長距離單詞給予更多的關注.He等人[14]提出將語法信息融入到注意力機制中,再與LSTM相結合,可以更好地預測特定方面的情感極性.Yi等人[15]提出conv-attention機制,將CNN的卷積操作與注意力結合,通過卷積運算生成特定方面的注意力,對上下文單詞的時序信息進行建模.這些結合注意力機制的神經網絡在無需額外的語義分析等外部知識的情況下,取得了比僅使用神經網絡模型更好的效果.但此類方法,多數使用單一層面注意力機制,沒有對注意力信息進行更深層次的挖掘,且使用的神經網絡存在訓練速度慢、無法獲得全局結構信息等缺點.
1.2 注意力機制
注意力機制最早在圖像處理領域提出[16],目的是讓網絡模型在訓練過程中高度關注指定的目標.近年來,注意力機制在NLP領域也發揮著越來越重要的作用.Cheng等人[17]將注意力機制應用到機器翻譯任務中,提出全局注意力和局部注意力2種機制,為注意力機制在NLP中的應用奠定了基礎.Yin等人[18]提出將注意力機制與CNN結合解決句子對的建模問題,該方法使用在卷積時進行注意力計算、在池化時進行注意力計算以及在卷積和池化時同時進行注意力計算這3種方式進行建模,提供了在CNN中使用注意力機制的基礎思路.短短幾年內,如何利用注意力機制解決NLP領域問題已經成為研究人員關注的熱點.谷歌翻譯團隊[19]提出僅使用注意力機制的Transformer網絡,該網絡使用大量自注意力機制獲取單詞間的依賴關系,并提出多頭注意力的概念,即不再使用單一注意力信息,而是將輸入經過不同的線性變化獲取更全面的注意力表示.
注意力機制的特性使得其可以很好地解決句子中特定方面情感極性判別問題.Fan等人[20]提出利用細粒度注意力機制和粗粒度注意力機制組成多粒度注意力網絡,并設計特定方面對齊損失來描述具有相同上下文的特定方面之間的方面級別交互.Wang等人[21]提出面向語法導向的混合注意力網絡,使用全局注意力來捕獲特定目標的粗略信息,利用語法指導的局部注意力查看在語法上接近特定方面的單詞,利用信息門來合成全局注意力和局部注意力信息,并自適應生成較少噪聲和更多情緒導向的表示,解決了全局注意力將高注意力得分分配給不相關的情感單詞的困擾.這些方法不僅證明了注意力機制在特定方面情感分析領域的有效性,還為今后的研究提供了新的思路.
2 問題描述與方法概論
2.1 任務定義
給定長度為n的句子,即s={w1,w2,…,a1,a2,…,wn}每個句子由一系列的詞語wi組成,其中a1和a2是句子s中特定方面的目標詞,每個句子有一個或多個目標詞.本文的任務是根據輸入的句子判斷句子中特定方面的情感極性(積極、消極、中立),例如句子“a group of friendly staff,the pizza is not bad,but the beef cubes are not worth the money”,該句中特定方面“staff”,“pizza”,“beef cubes”的情感極性分別為積極、中立和消極.本文將句子以詞為單位形成1個詞序列,然后通過詞嵌入層將每一個詞映射成低維空間中的連續值詞向量,得到上下文詞向量矩陣Ec∈Rk×c′和特定方面詞向量矩陣Ea∈Rk×a′,其中k為詞向量維度,c′為上下文詞向量數量,a′為特定方面詞向量數量.
2.2 方法概述
為了更好地識別同一句子中不同特定方面的情感極性,本文針對不同的特定方面將句子表示為多個分句,分句的個數取決于不同特定方面的數量,例如句子“Good food but dreadful service at that restaurant”表示成表1所示形式.本文采用多頭注意力機制來構建DANSA模型的2種注意力機制:
1) 特定方面注意力機制.將特定方面詞向量矩陣與上下文詞向量矩陣做注意力運算,獲取對特定方面的注意力信息,從而加強模型對特定方面的關注程度.
2) 上下文自注意力機制.對上下文詞向量矩陣中每一個詞向量進行自注意力操作,以獲得每一個單詞與其他單詞的依賴關系,進而獲取輸入句子的全局結構信息.

Table 1 Form of Sentences表1 分句形式
2.3 特定方面注意力機制
注意力機制的目的是在訓練過程中,讓模型了解輸入數據中哪一部分信息是重要的,從而使模型高度關注這些信息.對于特定方面情感分析而言,可以通過分析文本內容得到哪些詞與句子中特定方面目標詞的相關度更高.例如句子“The appetizers are ok,but the service is slow”,詞語“ok”是用來形容目標詞“appetizers”的,而詞語“slow”是用來形容目標詞“service”的,因此在該句中,詞語“ok”相比“slow”與目標詞“appetizers”相關程度更高.同理,詞語“slow”相比“ok”,與目標詞“service”的相關度更高.
特定方面注意力機制如圖1所示,對于句子“The appetizers are ok,but the service is slow”,通過詞嵌入操作可以得到上下文詞向量矩陣Ec=(x1,x2,…,x9)和特定方面詞向量矩陣Ea=(t1,t2),其中t1為特定方面“appetizers”,t2為特定方面“service”.首先,將特定方面詞向量矩陣中的每一個詞與上下文詞向量矩陣進行相似度計算,得到相似度向量e,e中的值表示相應位置詞向量間的相似程度,形式為
eij=f(ti,xj).
(1)
常用相似度計算函數主要有加性相似度函數和點積相似度函數,加性相似度函數使用神經網絡來計算2部分的相似度,形式為
eij=wTσ(ti+xj),
(2)
其中,σ(·)表示激活函數,wT為訓練參數.點積注意力通過點積運算計算2部分的相似度,形式為
eij=ti,xj,
(3)
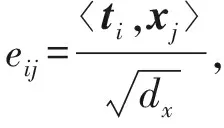
(4)
其中,dx表示詞向量xj的維度.
向量e通過歸一化操作得到注意力權重向量ea,ea中的元素代表相應位置上特定方面單詞與上下文中單詞的相關程度:
(5)
最后,特定方面詞向量可以用權重矩陣中對應的權重與原來的詞向量加權求和表示:
(6)

Fig. 1 The aspect attention mechanism圖1 特定方面注意力機制
2.4 上下文自注意力機制
自注意力機制是注意力機制的一種特殊形式,通過計算句子中每一個單詞與其他所有單詞的注意力得分,獲取每一對單詞間的依賴關系,對于遠程和局部依賴都具有良好的靈活性.本文采用自注意力機制獲取輸入文本上下文中單詞的依賴關系,以獲取全局結構信息.例如句子“Great food but the service was dreadful”,上下文自注意力機制的任務是要分別計算句子中7個單詞與其他單詞的注意力得分.
對于經過詞嵌入的上下文詞向量矩Ec經過上下文自注意力機制操作后得到相同維度的自注意力矩陣Bc,如圖2所示:
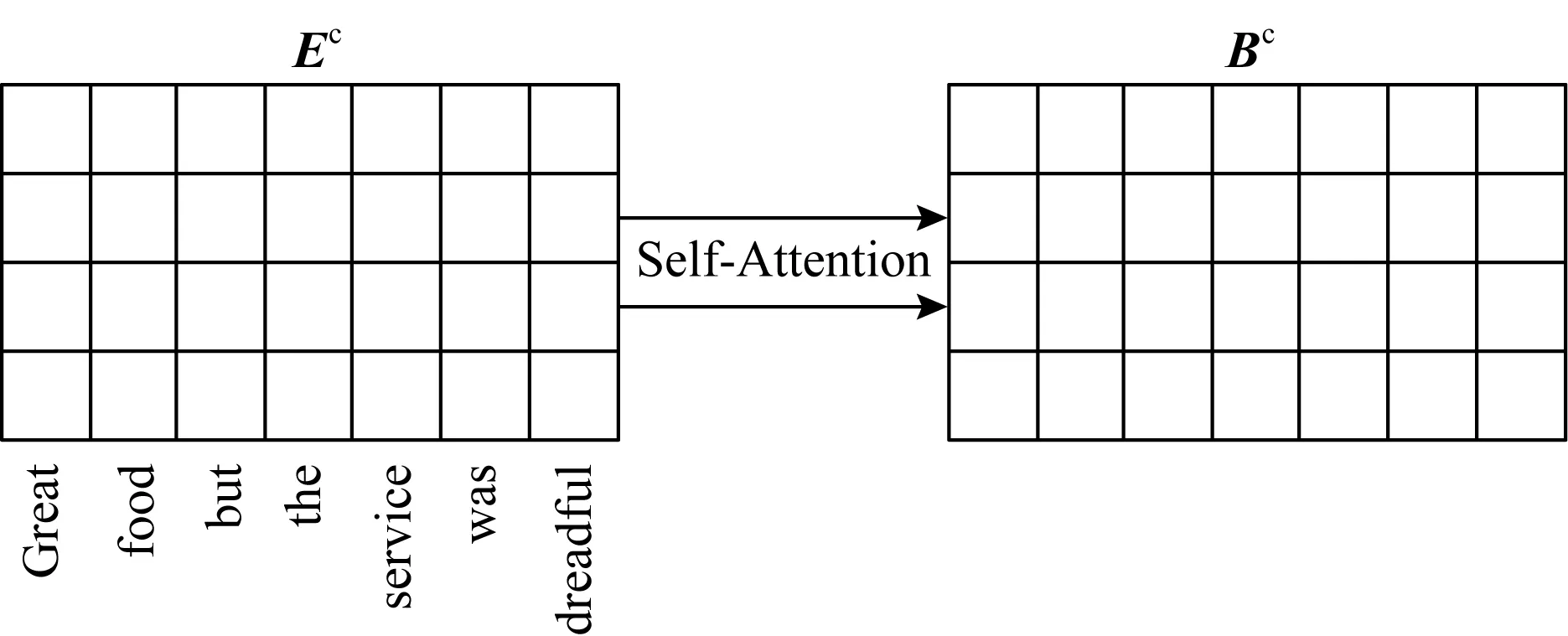
Fig. 2 The context self-attention mechanism圖2 上下文自注意力機制
2.5 多頭注意力機制下的雙注意力
傳統的注意力機制只考慮單詞之間單一層面的注意力信息,多頭注意力通過計算句子在不同線性變換下的表示來獲取更全面的注意力信息.
如圖3所示,以句子“The food is great”為例,句中單詞經過詞嵌入后得到相應的詞向量x1,x2,x3,x4,分別與線性變換矩陣W(1),W(2),W(3)進行點乘得到相對應的線性變換后的向量.特定方面“food”經過詞嵌入后得到相應的詞向量,與線性變換矩陣Wp點乘后得到對應的向量p1.

Fig. 3 The examples of linear transformations圖3 線性變換例子
特定方面“food”注意力計算過程有3個:1)計算p1與k1,k2,k3,k4的相似度得分;2)對相似度得分進行歸一化操作;3)用歸一化后得到的權重分別與對應位置的v1,v2,v3,v4相乘求和,進而得到最終的注意力向量.
同理,上下文“The food is great”自注意力計算過程就是將p1替換成上下文詞向量線性變換后的表示q1,q2,q3,q4.多頭注意力機制就是在多次不同組線性變換下,重復上述操作.
3 面向雙注意力網絡的特定方面情感分析模型(DANSA)
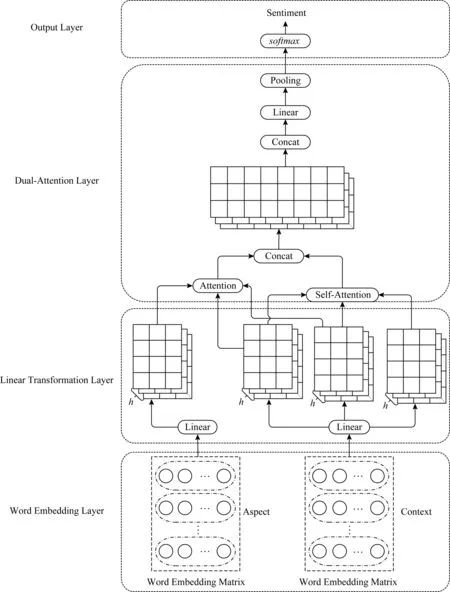
Fig. 4 Framework of DANSA圖4 DANSA模型框架
面向特定方面細粒度情感分析的雙注意力網絡(DANSA)如圖4所示,文本上下文與特定方面目標詞首先通過嵌入層將每個單詞映射成1個多維連續值詞向量進而得到上下文詞向量矩陣與特定方面詞向量矩陣,然后通過線性變換層得到2個矩陣在多次不同線性變換下的映射矩陣,再通過雙注意力層對不同映射矩陣進行特定方面和文本上下文雙注意力操作得到注意力表示矩陣,最后經過輸出層得到最終的情感分類結果,DANSA由4部分組成:
1) 詞嵌入層.將輸入看作以詞為單位的詞序列,通過本層將輸入文本上下文序列和特定方面序列中的每一個詞映射為1個多維的連續值詞向量,從而得到2部分的詞向量矩陣.
2) 線性變換層.通過對上下文和特定方面2部分詞向量矩陣進行多次不同線性變換,得到2部分詞向量矩陣在不同線性變換條件下的表示,從而使模型能夠從多方面捕獲上下文和特定方面的特征信息.
3) 雙注意力層.通過計算上下文部分的多頭自注意力,捕獲詞與詞間的依賴關系,獲取文本的整體結構信息.然后,計算特定方面對于文本的注意力得分,以獲取文本與特定方面間的依賴關系.將2部分注意力進行拼接并再次進行線性映射操作,利用池化操作獲得不同線性變換條件下最重要的情感特征.
4) 輸出層.使用softmax函數得到輸出結果,最終獲取特定方面的情感極性.
3.1 模型構建
給定句子在經過詞嵌入層后得到上下文詞向量矩陣Ec=(x1,x2,…,xn)和特定方面詞向量矩陣Ea=(t1,t2,…,tm),在線性變換層,通過對2個矩陣進行不同的線性變換,得到2個矩陣在不同線性變換下的表示,圖5描述了1次線性變換的過程,線性變換層的工作就是重復此過程n次.
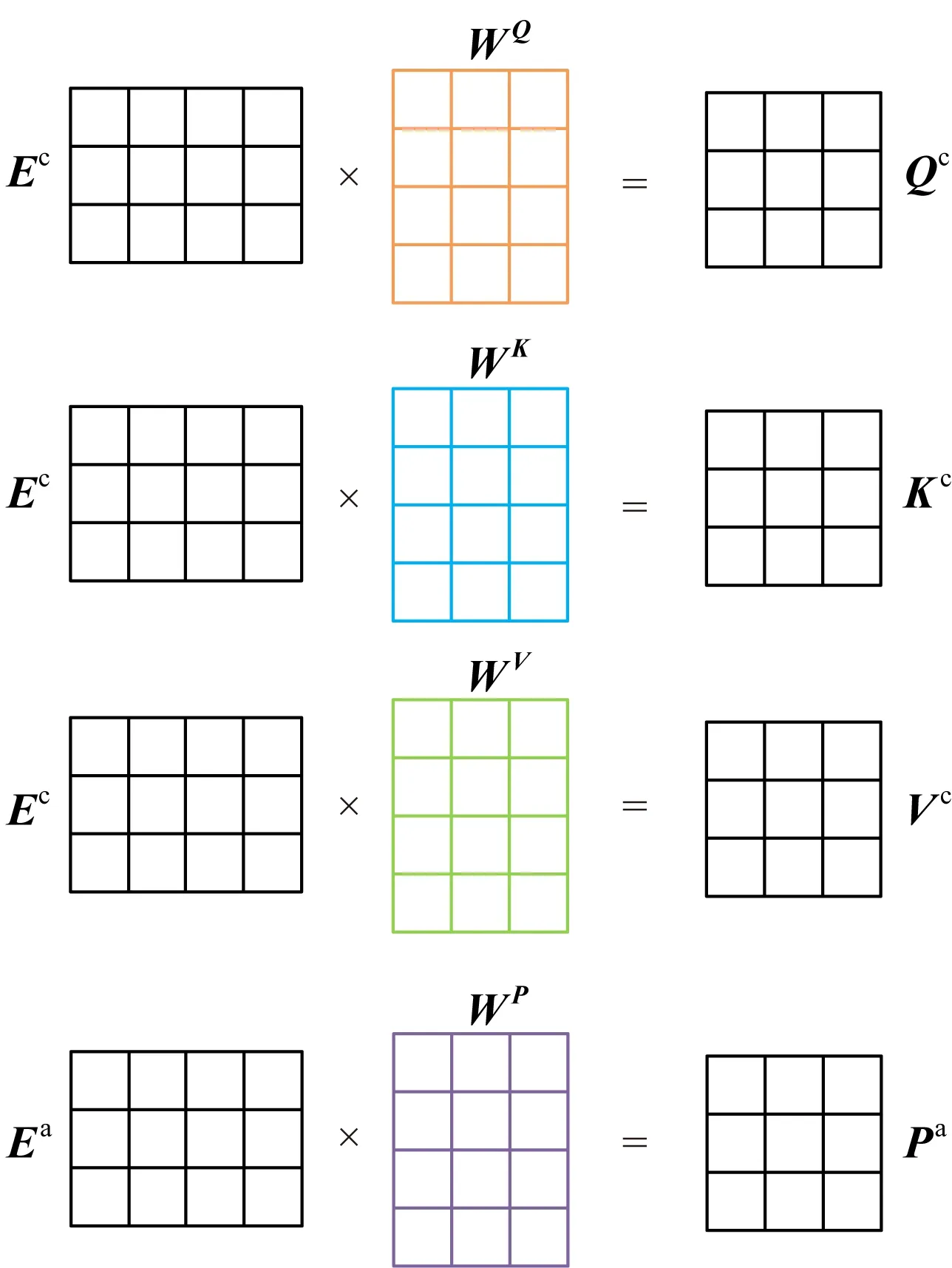
Fig. 5 Process of linear transformation圖5 線性變換過程
上下文詞向量矩陣Ec經過不同的3組線性變換得到矩陣Qc,Kc,Vc,特定方面詞向量矩陣Ea經過線性變換得到矩陣Pa.其中WQ,WK,WV,WP為線性變換參數矩陣.
在雙注意力層,上下文自注意力矩陣Sc的計算方式為
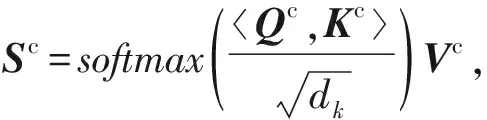
(7)
其中,dk為矩陣Kc列向量的維度.使用線性變換后的矩陣Qc,Kc,Vc通過縮放點積注意力函數得出.
同理,特定方面注意力矩陣Da為
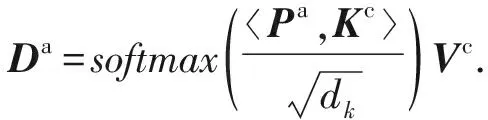
(8)
將每次線性變換下得到的上下文自注意力矩陣與特定方面注意力矩陣進行拼接,得到雙注意力矩陣Ui,然后將每次線性變換后的雙注意力矩陣U1,U2,…,Un進行拼接,再次進行線性變換得到最終的注意力表達矩陣Z:
Z=concat(U1,U2,…,Un).
(9)
在模型的最后一層,將上層輸出矩陣進行平均池化操作得到特征向量zavg,然后像傳統的神經網絡一樣,將池化后的結果經過全連接層后輸入到最終的softmax分類器中,從而得到最終的情感極性.
3.2 模型訓練
本文使用雙注意力層輸出作為全連接層輸入,通過一個softmax函數輸出最終情感極性,即:
y=softmax(Wzavg+B),
(10)
其中,zavg為雙注意力層輸出,W為全連接層權重矩陣,B為全連接層偏置項矩陣.本文使用反向傳播法來優化模型,交叉熵為
(11)
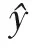
4 實 驗
4.1 實驗數據
本文采用SemEval2014數據集(1)http:alt.qcri.orgsemeval2014和Twitter數據集進行對比實驗,數據樣本的情感極性分為積極、消極和中性.其中,SemEval2014數據集是語義測評比賽任務的數據集,包括laptop和restaurant 2個領域的用戶評論.通過對比實驗,驗證了本文提出的DANSA在不同領域數據集上都取得了較好的情感分類性能,表2給出本文實驗使用數據統計:
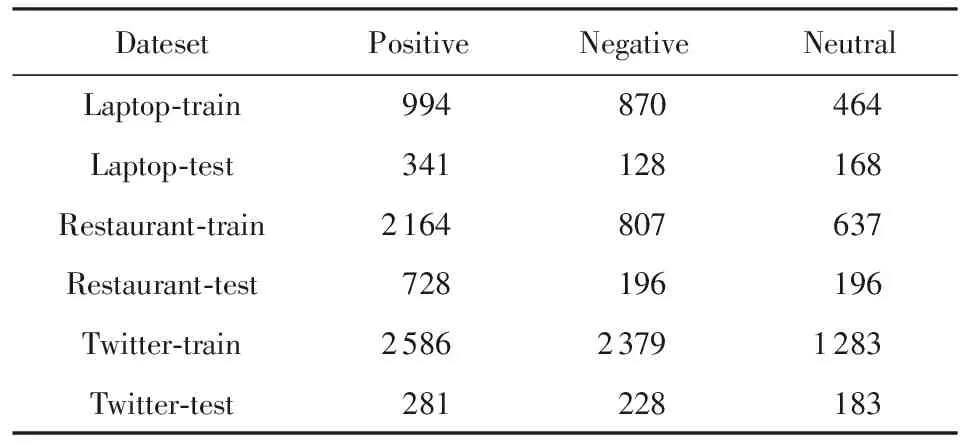
Table 2 Statistic of the Datasets表2 實驗使用數據統計
4.2 超參數
在本文的實驗中,詞向量采用Pennington等人[22]提出的Glove詞向量(2)http:nlp.stanford.eduprojectsglove,其中每個詞向量維度為300維,詞典大小為1.9 MB.對于未登錄詞,采用均勻分布U(-0.01,0.01)隨機初始化詞向量.L2正則項系數設置為10-4,隨機失活率(dropout rate)設置為0.5,Adam優化器初始學習率為0.01,模型迭代次數(epoch)為10.在線性變換層,線性變換次數設置為8,注意力函數采用縮放點積注意力.
4.3 對比實驗
將本文提出的DANSA同8種方法在2個不同數據集上進行實驗:
1) SVM.基于特征的SVM分類方法,是傳統機器學習的常用方法.
2) CNN.基于Kim[23]提出的卷積神經網絡模型,是最基礎的卷積神經網絡.
3) ATT-CNN.基于Wang等人[24]提出的基于注意力機制的卷積神經網絡.
4) LSTM.基礎LSTM網絡,使用最后隱藏狀態作為句子表示,輸入到最終分類器中.
5) TD-LSTM.基于Tang等人[25]提出的使用2個LSTM網絡,分別作用于特定方面之前的文本和之后的文本,然后使用2個LSTM網絡的最后隱藏狀態的拼接預測情感極性.
6) AT-LSTM.基于Wang等人[26]提出的通過LSTM網絡對文本上下文建模,然后將隱狀態與特定方面聯合嵌入監督注意力向量的生成,再由生成的注意力向量產生最后的特定方面情感極性.
7) ATAE-LSTM.是在AT-LSTM基礎上的拓展,它將特定方面嵌入向量與每個單詞嵌入向量相加表示上下文.
8) IAN.基于Ma等人[27]提出的使用2個LSTM網絡分別對句子和特定方面進行建模,交互生成2部分的注意力向量用于情感分類.
不同模型在SemEval2014和Twitter數據集上經過10次迭代后的準確率如表3所示,對于實驗結果的分析為:
1) 在前4種沒有使用注意力機制的模型中,普通CNN網絡的情感分析模型準確率偏低.CNN在圖像處理領域的有效性是有目共睹的,這是因為在圖像上相鄰像素點通常是相關的,而在自然語言處理中,句子中相鄰的詞語未必相關,相關詞語之間可能存在若干的修飾詞語,這導致CNN卷積操作所獲取的信息不完整,不能有效地利用數據信息.傳統SVM分類器準確率雖然略高于普通CNN,但分類效果仍不理想,這是因為本文在實驗過程中沒有做過多特征工程的工作,而傳統機器學習方法的優劣很大程度上取決于特征工程的質量.基礎LSTM模型的結果優于前2種模型,這是因為LSTM善于處理序列問題并通過門機制來實現長時依賴,但基礎LSTM并沒有特別關注句子中的特定方面目標詞.TD-LSTM相比普通LSTM在3個數據集上的準確率分別提升了2.8%,1.29%,1.56%,原因是TD-LSTM開始對特定方面進行關注,它通過在文本中特定方面的左右分別建模,利用2個LSTM網絡來學習特定方面的表示,這種方法雖然取得了一定的效果,但對于模型來說,文本中每個詞對特定方面的影響都是相同的,沒有對更重要的部分重點學習.
2) 在另外4種將注意力機制與神經網絡相結合的模型中,其準確率相比沒有使用注意力的模型,都有明顯提升,證明了注意力機制在特定方面情感分析任務中的有效性.由于CNN在NLP中的局限性,ATT-CNN的結果相比于將注意力與LSTM相結合的模型,結果并不理想.AT-LSTM,ATAE-LSTM,IAN都是將注意力機制與LSTM相結合的方法,在準確率上相比4種方法都有所提升.AT-LSTM和ATAE-LSTM通過注意力機制來監督特定方面上下文中的重要信息,并且將特定方面與文本進行聯合嵌入,這為特定方面情感分類生成更合理的表示.IAN對文本和特定方面進行單獨建模,交互的生成注意力,不僅學習文本中對特定方面相對重要的信息,也學習了特定方面中對文本更重要的信息,再次證明了注意力機制的有效性.
3) 本文提出的DANSA在對比實驗中取得了最好的效果,證明了模型的有效性.在將注意力與神經網絡相結合的模型中,都使用了單一的注意力機制,都是從單一層面獲取注意力信息,而DANSA使用多頭注意力機制來搭建注意力網絡,它將文本和特定方面進行多次不同的線性變換,學習兩者在不同線性變換下的注意力表示,能夠更深層次地學習和表示文本.不同于基于CNN的模型,DANSA通過自注意力計算,獲取了文本全局的依賴信息;與基于LSTM網絡的模型相比,模型首先通過自注意力來獲取文本中每一個詞向量與其他詞向量的相關度,實現了詞向量之間的長距離依賴,再通過特定方面注意力的計算,獲取了文本中對特定方面的重要信息,從而得到更好的分類效果,同時DANSA能夠實現大規模并行化計算,大大提升了模型訓練速度.
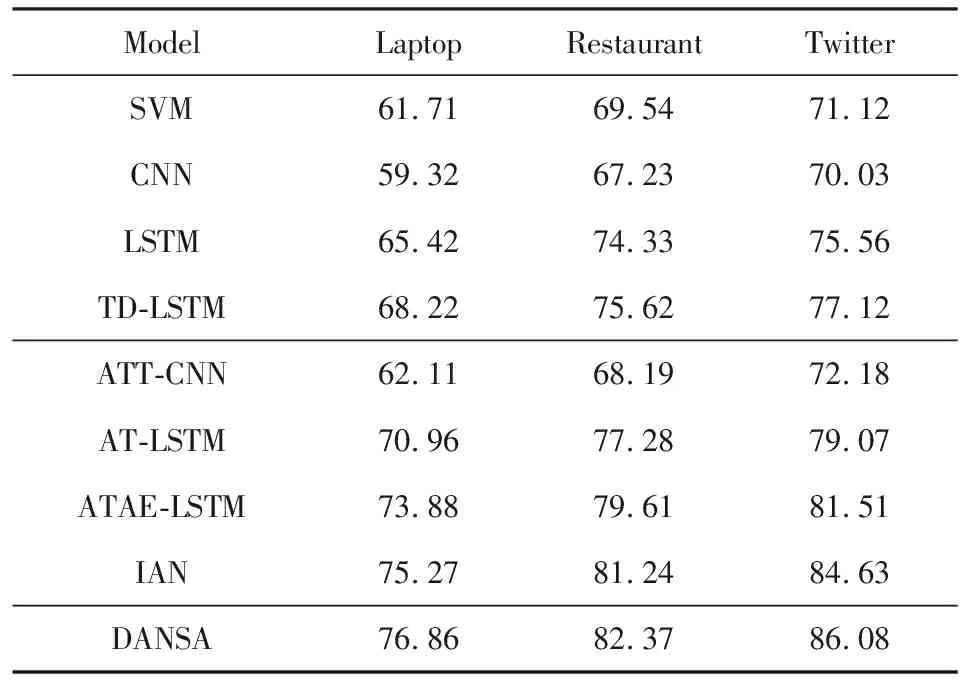
Table 3 Accuracy of Different Models表3 不同模型的準確率 %
4.4 DANSA模型分析
4.4.1 運行時間分析
本文使用相同的詞向量矩陣和相同的數據集,在相同的CPU,GPU和網絡框架下完成訓練時間對比實驗,表4給出了不同模型在Restaurant領域數據集上完成1次迭代的訓練時間對比結果.
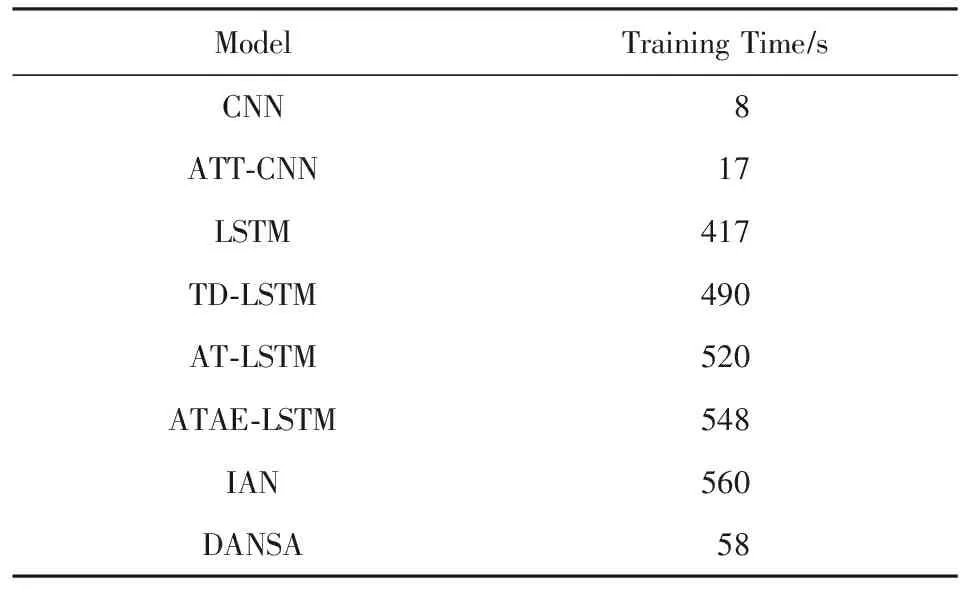
Table 4 Runtime of Each Training Epoch表4 不同模型完成1次迭代的訓練時間
從表4可以看出, 在基于LSTM的模型中,普通的LSTM模型訓練時間需要417 s,加入注意力機制的AT-LSTM和ATAE-LSTM的訓練時間都超過了500 s.訓練時間過長是LSTM網絡最大的弱點,由于網絡接收序列形數據,導致無法實現并行計算,并且LSTM的每一個單元都需要相當復雜的運算操作,這些原因都大大增加了LSTM的訓練時間.
普通的CNN模型訓練時間是最短的,完成1次迭代的訓練時間只需要8 s,加入注意力機制的ATT-CNN模型的訓練時間也只需17 s,訓練時間遠遠優于LSTM網絡.DANSA模型完成1次迭代時間為58 s,雖然高于基于CNN的模型,但是卻遠遠優于基于LSTM網絡的模型.模型中文本自注意力和特定方面注意力的計算必然會消耗一定時間,但不同線性變換下的注意力是可以并行計算的,這與普通注意力在時間復雜度上是相同的.在保證了準確率的基礎上,DANSA模型的訓練時間相比基于LSTM的模型平均減少了449 s.
4.4.2 線性變換次數分析
對DANSA采用的多頭注意力機制在不同線性變換次數下的準確率進行對比分析,實驗對比結果如圖6所示:

Fig. 6 Accuracy of different transformation times圖6 不同線性映射次數的準確率
實驗對比了線性變換次數為2,4,6,8,10時在數據集Restaurant上經過10次迭代的準確率情況.從圖6可以看出,模型的準確率大體隨著線性變換次數(k)的增加而增加,但當k=10時的準確率相比k=8時有所下降,這說明在此數據集上,當k=10時,可能存在模型的過擬合現象,所以本文在對比實驗中將線性變換次數設置為8.
4.4.3 注意力類型分析
將采用縮放點積注意力的DANSA和采用加性注意力的DANSA在Restaurant數據集上進行準確率對比實驗,在Laptop,Restaurant,Twitter數據集上進行訓練時間對比實驗,實驗結果如圖7與圖8所示.
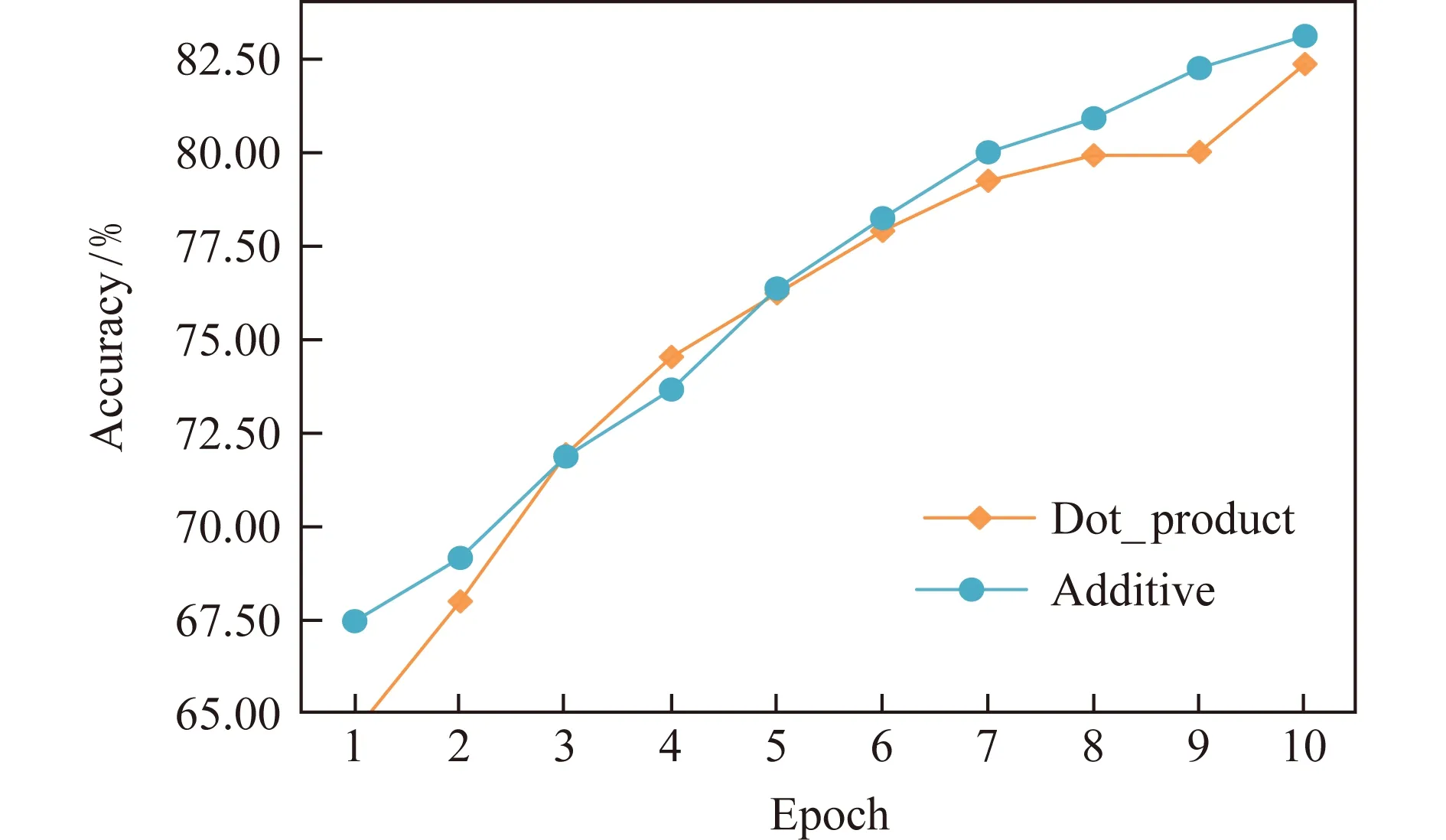
Fig. 7 Accuracy of different attention types圖7 不同注意力類型的準確率

Fig. 8 The runtime of different attention types圖8 不同注意力類型的訓練時間
從圖7可以看到,經過10次迭代之后,使用加性注意力的DANSA模型準確率略高于使用縮放點積注意力的模型.加性注意力使用神經網絡來計算2個元素的相似度或相關度,可以更深層次地學習元素之間的依賴關系,實驗證明在準確率上使用加性注意力的DANSA確實可以取得更好的效果.但從圖8可以明顯地看出,在3個數據集上,使用加性注意力的模型在訓練時間上是使用點積注意力模型的3倍,加性注意力使用神經網絡作為相似度函數,需要訓練更多的參數,需要付出更高的時間成本.考慮到模型的綜合性能,在對比實驗中,本文采用縮放點積注意力來構造DANSA模型.
4.5 注意力可視化
從Restaurant-test數據集中選取句子“Great food but the service was dreadful!”用作自注意力可視化說明,如圖9所示,區域顏色越深,代表注意力權重越大.
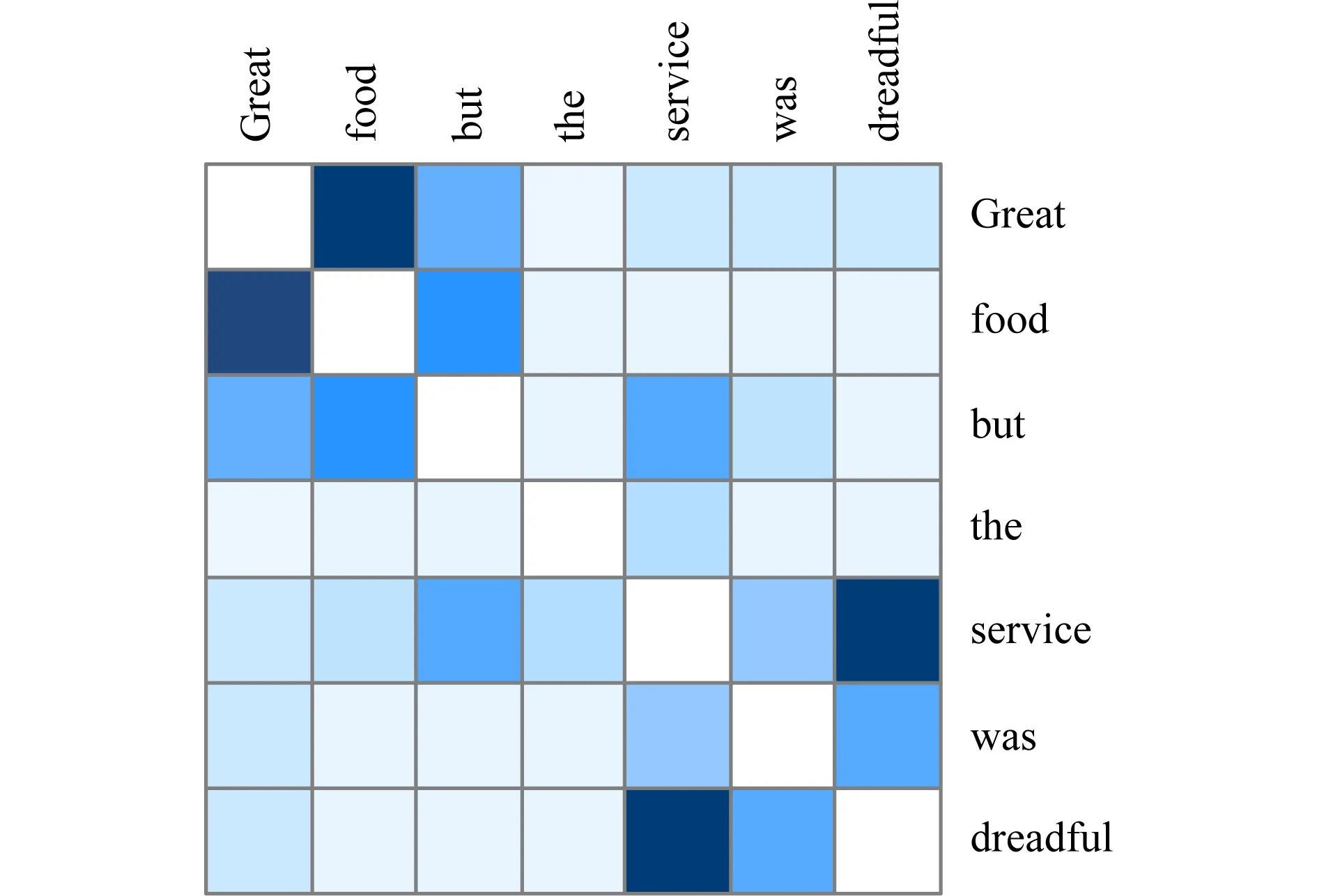
Fig. 9 The context self-attention weights圖9 上下文自注意力權重
從圖9可以看出,名詞、動詞和形容詞等在語義上重要的詞,通常會受到很大的關注,比如句子中的“great”,“food”,“service”,“dreadful”都受到更高的關注,但是一些停用詞則不會受到過高的關注.全局中重要的詞,比如“food”和“service”,由于句子主要是針對這2個詞進行描述,所以它們獲得其他單詞更多的關注.如果一個單詞僅與某些詞有關,那么它會獲得相關詞的更高的關注,例如“food”與“great”相關度極高,“service”只與“dreadful”相關度極高.
選取句子“The appetizers are ok,but the service is slow”用作特定方面注意力可視化說明,如表5所示,表5中句子區域顏色越深,代表該詞注意力權重越大.

Table 5 The Weight of Aspect Attention表5 特定方面注意力權重
從表5可以清楚地看到,對于特定方面“appetizers”,代表“ok”的區域顏色極深,說明詞“ok”與“appetizers”這個特定方面相關度極大,而其他區域都為較淺的顏色.在特定方面為“service”也有同樣的情況,代表“slow”的區域為深紅色,說明“service”與“slow”極為相關.這說明注意力機制可以有效地捕捉與特定方面相關的信息,可以使模型更充分地獲取有效信息.
5 總 結
在以往的工作中,大部分針對特定方面情感分析的研究都是將注意力機制與CNN或LSTM網絡相結合.然而基于CNN的模型無法獲取全局信息,而基于LSTM網絡的模型則需要很高的時間代價且元素間的依賴關系會受到距離的影響,因此本文提出一種面向雙注意力網絡的特定方面情感分析模型(DANSA),將多頭注意力機制應用到細粒度情感分析問題中,主要思想是通過雙注意力網絡學習文本向量之間在不同線性映射下的依賴關系和特定方面與文本之間的依賴關系,并且所獲取的依賴關系不會因為距離而減弱,同時,模型可以實現大規模并行化計算,極大地降低了訓練時間.實驗結果表明,DANSA可以合理有效地解決特定方面情感分析問題.
DANSA目前沒有考慮文本的時序性問題,在未來的研究中,我們將就文本的時序問題和位置關系進行研究,以提升模型的性能.
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
文苑(2018年21期)2018-11-09 01:23:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
小學教學參考(2015年20期)2016-01-15 08:44:38
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
