基于生成模型的古壁畫非規則破損部分修復方法
2019-11-13 07:13:08溫利龍錢文華
圖學學報 2019年5期
溫利龍,徐 丹,張 熹,錢文華
基于生成模型的古壁畫非規則破損部分修復方法
溫利龍,徐 丹,張 熹,錢文華
(云南大學信息學院,云南 昆明 650500)
為了更好地保存和修復珍貴的古代壁畫藝術,在現有的人工修復技術之上,結合數字虛擬修復方法,使用深度學習中生成網絡的方法自動生成壁畫缺失部分,可以有效地提高修復效率,降低修復成本。用于修復的網絡整體上是一個自編碼器結構,編碼器將待處理壁畫圖像和破損部分對應的掩膜作為輸入,進行特征提取。解碼器將編碼器得到的特征圖通過反卷積的方法恢復到原來尺寸,完成修復,自動將破損區域進行補全。同時,通過對待修復壁畫進行分塊修復再拼接的方法實現了對任意尺寸壁畫的修復。與其他數字壁畫修復方法相比,該方法更加通用,不受壁畫種類和破損情況的限制。在一般破損的壁畫上可以得到超過目前先進水平的修復效果,并且在人眼無法辨識有效信息的大面積破損的壁畫上,仍可以恢復得到有完整語義的圖像。
壁畫修復;卷積神經網絡;生成模型;自編碼器
壁畫作為一種古老的繪畫形式,有著獨特的美學價值和研究價值。但是由于其年代久遠,不可避免地受到不同程度的自然因素和人為因素的破壞,其修復工作一直是古文化研究領域重要的研究課題。傳統人工修復方法依靠科研工作者豐富的經驗和繪畫技術,但耗時較長并且對修復者有極高的要求。隨著計算機技術的發展,數字圖像處理技術為該領域提供了強有力的工具。通過對壁畫的進行數字化采集和數字修復,可以對實體修復提供具有指導意義的修復方案,降低了修復難度,提高了修復效率,減少了對人力的依賴。
數字圖像修復技術利用破損區域以外的圖像已知信息和圖像本身的風格信息,推測出破損區域的圖像內容,再填補回原圖像達到修復的目的。傳統的數字圖像修復技術大多依賴單張圖片中的已知信息,使用擴散或塊匹配的方法進行修復,在實際應用中往往無法完全滿足需求。近年來,深度學習在計算機視覺和圖像處理領域的研究不斷取得進步,使用海量圖片對網絡進行訓練,使得訓練好的模型可以具備大量的先驗知識,為圖像修復提供了另外一種思路。尤其是對抗生成網絡[1]的提出,在圖像修復、補全領域取得了很好的效果。
1 相關工作
傳統的數字圖像修復方法根據待修復區域的大小可以分為2類:①針對較小的破損區域使用信息擴散方法,將已知區域的信息擴散至破損區域達到修復的目的[2-5];②則是針對較大缺損塊的合成匹配方法[6-7]。針對單幅圖像可能不存在可匹配塊的情況,SIMAKOV等[8]將匹配塊的搜索范圍擴大到了單張圖片以外,但是其計算量極大,在實際應用中很難實行。BARNES 等[9]針對此問題提出了一種快速鄰域算法來加速塊搜索的過程,很大程度上解決了計算量過大的問題。
在壁畫修復領域,PEI等[10]針對中國古壁畫使用馬爾科夫隨機域模型對圖像進行色彩增強和紋理合成的方法進行修復;ZITOVá和FLUSSER[11]則在壁畫修復過程中結合了化學分析的方法;WANG等[12]專門針對古壁畫中人臉破損的情況提出了語義學習框架進行修復。
以上方法在圖像本身有較好的結構信息或者破損面積很小的情況下(如當壁畫的破損區域為劃痕、裂縫),可以取得很好的效果,但是無法處理高層次的語義信息并且當缺失部分過大或者缺失信息存在唯一性時,無法進行很好地修復。與之對應的深度學習方法,則有較好的解決方案。YEH等[13]采用了一種和塊匹配相似的思路,不直接在圖像中尋找相似圖塊,而是將圖像通過編碼器之后尋找最接近的隱空間向量,并解碼恢復為填充圖塊達到修復的目的。ULYANOV等[14]進一步證明了使用單幅圖片結合神經網絡的方法在破損區域較小時可以取得很好的修復效果。
早期的神經網絡修復方法(如直接使用卷積神經網絡的方法[15])對破損進行修補,將待修復的區域視為圖像噪聲,在破損區域較細小(如文字的遮擋等)情況下取得了很好的效果。PATHAK等[16]針對圖像中間區域的缺失使用對抗生成的方法生成具有語義信息的圖塊對破損圖像進行填充。IIZUKA等[17]在此基礎上添加了全局和局部鑒別器,分別對修復得到的整幅圖像和破損對應區域進行損失計算,得到了比之前更好的效果。同樣基于文獻[16]的工作,YANG等[18]將非破損區域的紋理信息進行了提取并應用到修復區域中,使得修復圖像在紋理上有了更好的一致性。而YU等[19]則是使用了一個精煉網絡對PATHAK的結果進行再次處理來得到更為精細的結果,并取代修復完成后的邊緣處理過程。LIU等[20]使用非規則化卷積的操作,實現了使用卷積神經網絡的方法對非規則化破損區域的修復。NAZERI等[21]首先利用生成模型得到缺失部分的邊緣信息,并將得到的邊緣信息和圖像一同送入修復網絡進行重建。LI 等[22]專門針對人臉圖片進行訓練,并結合了分割網絡對重建的人臉進行分割計算損失來確保生成的人臉圖片在語義上正確,證明了專門針對某一種類圖片進行訓練和網絡設計可以讓模型較好地學習到該領域的語義信息,尤其在人臉領域可以取得很好的效果。但是在壁畫修復領域,現存的壁畫在數量上相對較少,并且不同種類的壁畫之間風格和色彩等相差很大,無法專門建立相應數據集進行訓練,本文訓練過程只使用了普通圖片數據集,讓網絡充分學習像素間關系。實驗結果證明在訓練集不使用壁畫數據的情況下,訓練得到的模型依然能在壁畫修復中取得較好的效果。
使用神經網絡進行圖像風格遷移[23-24]的成功對圖像修復帶來了很大的啟發,尤其是風格損失和內容損失相結合的方法,可以使得生成的修復塊與原圖的拼接更加自然。YANG等[25]根據此思路提出了多尺度的網絡合成修復方法,得到的修復區域不僅在紋理結構上與原圖很接近,并且在內容和風格上也有很好的一致性。
本文借鑒了風格遷移中損失函數的設計,同時與對抗損失相結合,提出了一個基于自編碼器結構的圖象修復網絡,并且針對壁畫破損部分多為非規則的脫落、裂紋等形狀設計了相應掩膜用于模型訓練。
2 方法介紹
本文網絡模型整體上是一個典型的自編碼器結構,分為編碼和解碼2部分,網絡的數據流如圖1所示。其中編碼部分將待處理圖像和掩膜圖像進行編碼得到一個中間特征,解碼部分對進行解碼執行一個和編碼器相反的操作恢復得到完整的圖像。為了得到更好的訓練效果,本文的編碼解碼部分采用了類似UNet[26]的網絡結構對其中間各層特征進行了拼接融合。主要貢獻有:①模型訓練時充分考慮到壁畫破損多為不規則裂縫與脫落,并按此設計了任意形狀的掩膜;②在損失函數的計算中將所有的損失函數的計算都分為整體損失和局部損失2部分;③采用分塊修復的方法實現了對任意尺寸壁畫的修復。
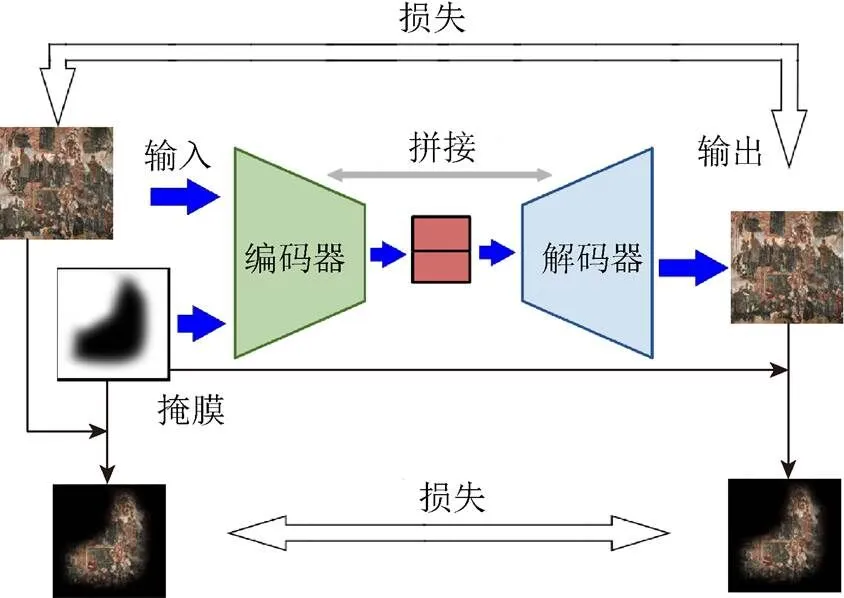
圖1 網絡總體結構圖(E表示Encoder,D表示Decoder)
2.1 編碼器
編碼器部分采用了卷積神經網絡的結構,將掩膜與待處理圖像同時作為網絡的輸入。掩膜用于控制輸入圖像的處理過程,實現對非規則區域的處理。在一個卷積窗口的處理中,卷積結果計算式為
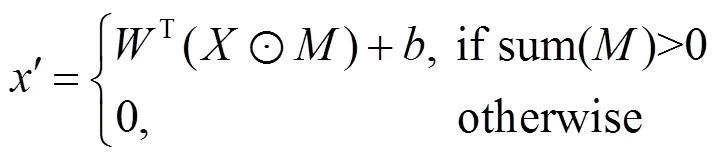
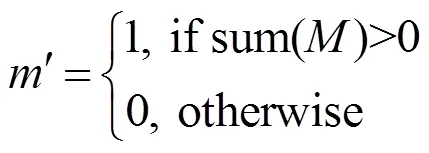
收縮方法同樣通過卷積操作實現,如果在一個卷積窗口中,該窗口掩膜像素值之和大于0,則置該窗口的掩膜為1,否則仍置為0。通過每次在卷積過程中收縮掩膜的方法,在經過幾層卷積操作之后,最終掩膜將會全部置為1,其過程如圖2所示。可以看出,掩膜的大小隨著每層卷積操作不斷縮小,最終編碼器的輸入為2部分,一部分時輸入圖像的特征圖,另一部分則是全為1的掩膜處理圖。
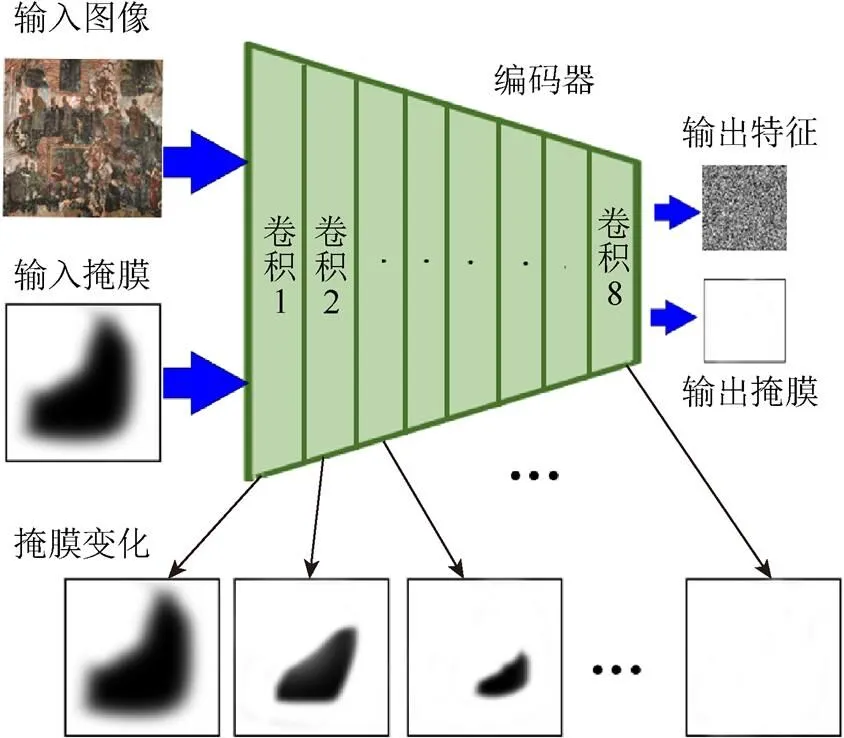
圖2 編碼器對掩膜的處理過程
2.2 解碼器
解碼器采用了與編碼器相反的操作,通過對編碼器處理得到的特征進行反卷積的操作,將特征恢復到與輸入圖像相同大小。處理過程如圖3所示。其中反卷積的操作由上采樣和卷積兩部分操作組成,最后一層不再輸入掩膜圖像,而是將最后一層反卷積得到的圖像進行傳統的卷積操作得到最終圖像。在這一部分的處理中,掩膜雖然一直隨著輸入特征一起處理,但實際上,全1的掩膜并不會對解碼器的輸入有任何影響,之所以同時輸入網絡是為了保持解碼器與編碼器在結構和特征數值上的對應關系,便于其間特征的拼接融合。最后一個卷積層有3個大小為1的卷積核,對圖像尺寸不產生影響,只是將圖像恢復到RGB三通道。

圖3 解碼器結構圖
2.3 損失函數
損失函數分為生成過程中的對抗損失和整體的生成圖像和輸入圖形間的風格損失、內容損失和總變分損失。所有損失在計算過程中充分考慮生成的整體圖像和掩膜對應的缺失部分圖像。為了使對抗損失更加適應本文的應用場景,本文使用式(3)和式(4)的對抗損失的設計,表示分別對生成的整體圖像和掩膜對應部分計算對抗損失,即
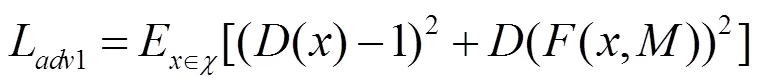
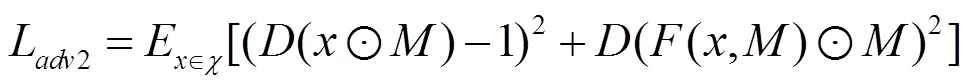
其中,函數為整個編碼解碼網絡;和分別為輸入的圖像和掩膜;為一個簡單的鑒別網絡。
內容重建損失的計算如式(5)和式(6),分為2個部分:一部分是掩膜對應圖像的重建損失,另一部分是掩膜之外圖像的重建損失,即
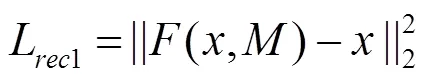
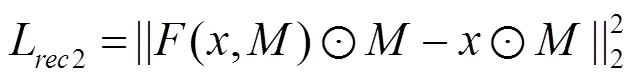
為了使生成的缺失部分和原圖像風格一致,在損失函數中同時加入風格遷移中的風格損失和總變分損失。其中,風格損失的計算依賴于從預訓練好的卷積神經網絡中提取到的特征與葛郎姆矩陣,其定義如式(7),采用VGG16[27]作為特征提取網絡,其中為網絡的第層。
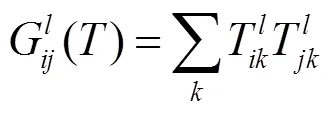
風格損失同樣也分為2個部分:一部分對應生成的完整圖像,另一部分用于計算掩膜對應的缺損位置生成的圖像,其計算公式為

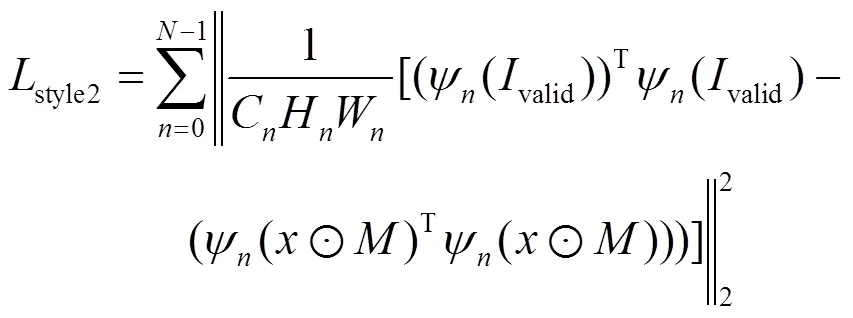
為了達到平滑性的需求,本文同時使用了總變分損失,其計算如公式為
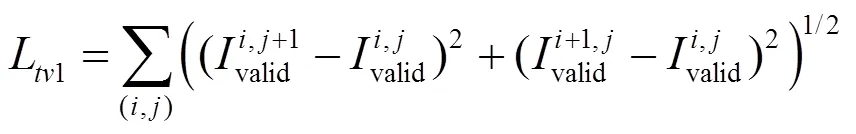
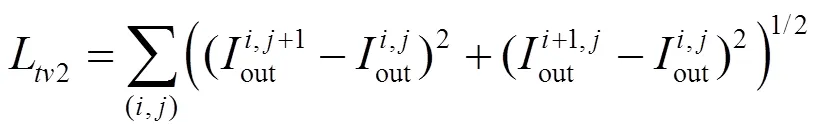
最終網絡的整體損失函數計算公式為
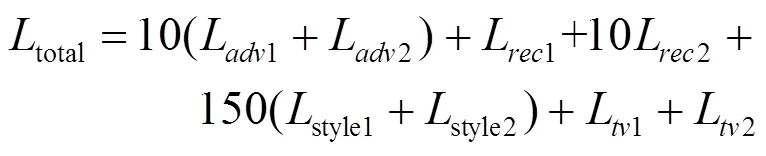
其中,各個損失的權重是在多次實驗測試中得到的效果較好的一組權重值。
2.4 掩膜設計
針對數字壁畫圖像中破損部分形狀的特點,為了達到更好的修復效果,需要對訓練過程中使用的掩膜進行專門的設計。
本文使用的掩膜圖像是通過使用自適應閾值分割的方法對收集到的古壁畫圖像進行粗略的破損區域提取得到,并將提取得到的掩膜圖像進行分割、旋轉、對稱變換,以及膨脹腐蝕等形態學操作進行擴充。但是由于收集到的壁畫圖像有限,盡管經過大量的變換操作,仍無法得到與大規模的訓練數據集的數據規模相匹配的掩膜數量。因此,在訓練過程中,每次加載掩膜圖像時都使用自動化腳本隨機在掩膜圖像上添加圓圈和線條的組合。圖4展示了一些掩膜圖像,圖4(a)~(f)為從壁畫圖像中得到的原始掩膜,圖4(g)~(i)為每次訓練時在原始掩膜上添加隨機繪制形狀后得到的掩膜圖像。

圖4 使用到的掩膜圖像示例((a)~(f)為從壁畫中得到的原始掩膜圖像示例,(g)~(i)為每次訓練時在原始掩膜上隨機繪制后得到的掩膜圖像示例)
2.5 分塊修復
現實中,待修復的數字壁畫尺寸是任意的,但是神經網絡有著固定的輸入大小。為為,本文采用了對輸入圖像分塊處理再拼接的方法,其處理如圖5所示。將大于512×512的圖片進行分割,長、寬不足512的部分進行空白填充。然后將各個圖塊分別輸入網絡中進行修復,最后再將修復好的圖塊拼接在一起得到最終完整的修復圖,在此過程中,掩膜也隨之一起進行分割。
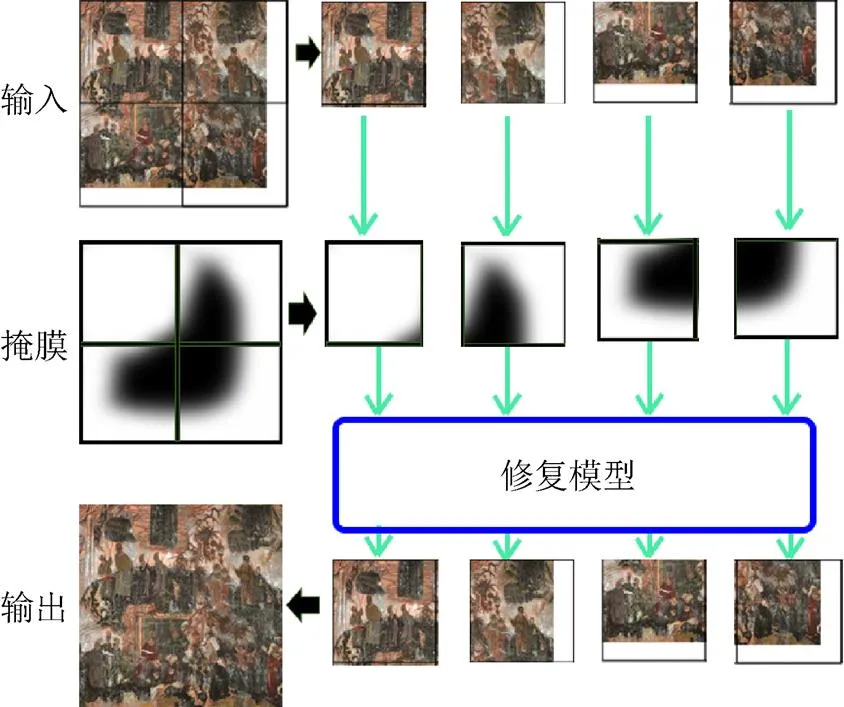
圖5 分塊修復拼接示意圖
3 修復結果分析
使用本文提出的模型對一些現存的數字壁畫進行修復,取得了較好的效果。圖6顯示了在裁剪的敦煌壁畫上進行測試的結果。可以看出,在壁畫存在輕微破損和一般破損時,很容易修復得到完整的結果圖,甚至在嚴重破損的情況下,該模型也可以得到一個在風格和語義上與原圖接近的結果。

圖6 在敦煌壁畫上的測試結果
針對一些大面積塊的破損,本文方法也得到了較好的修復效果,如圖7所示。

圖7 在較大面積破損情況下修復結果
本文針對不同類型、不同破損情況的真實壁畫圖像進行修復,得到的結果如圖8所示。
從修復結果中可以看出,使用本文提出的模型在各種古壁畫破損情況下均可以取得很好的效果,掩膜所覆蓋的非規則破損區域均可以通過該生成模型得到在紋理結構和語義上都與原圖相符的修復結果,證明了本文方法的有效性。

圖8 針對不同風格、不同破損類型的古壁畫的修復結果
為了進一步證明本文方法在古壁畫修復上的優越性,本文與目前在非規則破損區域修復上效果最好的模型[20]進行了比較,比較結果如圖9所示。其中,掩膜2是掩膜1經過膨脹操作擴大以后得到的掩膜。

圖9 與其他方法進行對比
可以看出,在使用相同大小的掩膜1的情況下,本文方法可以得到一個較好的修復結果。而對比方法中則會因為掩膜較小而出現修復得到的區域色彩明顯淺于周圍區域的問題,在適度擴大掩膜區域之后該問題才會得到解決。最終得到的結果與本文方法相比在細節上也較為模糊。本文方法在利用相同的周圍信息的情況下可以得到更好的修復結果,并且修復結果更為清晰。
4 結 論
本文使用深度學習的方法對壁畫進行虛擬修復。通過使用生成模型的方法對壁畫缺損部分進行生成,填充到破損區域達到修復的目的,取得了較好的修復效果,并且與之前的方法相比更為通用,不受破損情況的限制,在損失信息極大的情況下仍可以恢復出一個語義上完整的結果圖,并且可以利用較少的周圍信息就可以得到較好的結果。同時該修復結果說明了在修復任務中不需要特定領域的圖像參與訓練來提高這一領域相關圖片的修復效果。
[1] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]//Proceedings of the 26th International Conference on Neural Information Processing Systems. Goslar: Eurographics Association Press, 2014: 2672-2680.
[2] SHEN J H, CHAN T F. Mathematical models for local non-texture inpainting [J]. SIAM Journal on Applied Mathematics, 2002, 62(3):1019-1043.
[3] CHAN T F, SHEN J H. Nontexture inpainting by curvature-driven diffusions [J]. Journal of Visual Communication and Image Representation, 2001, 12(4): 436-449.
[4] BALLESTER C, BERTALMIO M, CASELLES V, et al. Filling-in by joint interpolation of vector fields and gray levels [J]. IEEE Transactions on Image Processing, 2001, 10(8):1200-1211.
[5] BERTALMIO M, SAPIRO G, CASELLES V, et al. Image inpainting [J]. Siggraph, 2005, 4(9): 417-424.
[6] EFROS A A, FREEMAN W T. Image quilting for texture synthesis and transfer [C]//Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques-SIGGRAPH’01, Not Known. New York: CAM Press, 2001: 341-346.
[7] EFROS A A, LEUNG T K. Texture synthesis by non-parametric sampling [C]//Proceedings of the 7th IEEE International Conference on Computer Vision, New York: IEEE Press,1999: 1033-1038.
[8] SIMAKOV D, CASPI Y, SHECHTMAN E, et al. Summarizing visual data using bidirectional similarity [C]// 2008 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2008: 1-8.
[9] BARNES C, GOLDMAN D B, SHECHTMAN E, et al. PatchMatch: A randomized correspondence algorithm for structural image editing [J]. ACM Transactions on Graphics, 2009, 28(3): 1-11.
[10] PEI S C, ZENG Y C, CHANG C H. Virtual restoration of ancient Chinese paintings using color contrast enhancement and lacuna texture synthesis [J] IEEE Transactions on Image Processing, 2004, 13(3): 416-429.
[11] ZITOVá B, FLUSSER J. Image registration methods: A survey [J]. Image and Vision Computing, 2003, 21(11): 977-1000.
[12] WANG Q, LU D M, ZHANG H X. Virtual completion of facial image in ancient murals [C]//2011 Workshop on Digital Media and Digital Content Management. New York: IEEE Press, 2011: 203-209.
[13] YEH R, CHEN C, LIM T Y, et al. Semantic image inpainting with perceptual and contextual losses [CP/OL]. (2016-02-26). [2019-05-02]. https://arxiv.org/abs/ 1607.07539.
[14] ULYANOV D, VEDALDI A, LEMPITSKY V. Deep image prior [C]//2018 Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 9446-9454.
[15] K?HLER R, SCHULER C, SCH?LKOPF B, et al. Mask-specific inpainting with deep neural networks [M]// Lecture Notes in Computer Science. Heidelberg: Springer, 2014: 523-534.
[16] PATHAK D, KRAHENBUHL P, DONAHUE J, et al. Context encoders: Feature learning by inpainting [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 2536-2544.
[17] IIZUKA S, SIMO-SERRA E, ISHIKAWA H. Globally and locally consistent image completion [J]. ACM Transactions on Graphics, 2017, 36(4): 1-14.
[18] YANG C, LU X, LIN Z, et al. High-resolution image inpainting using multi-scale neural patch synthesis [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 6721-6729.
[19] YU J H, LIN Z, YANG J M, et al. Generative image inpainting with contextual attention [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 5505-5514.
[20] LIU G, REDA F A, SHIH K J, et al. Image inpainting for irregular holes using partial convolutions [M]// Computer Vision- ECCV 2018. Heidelberg: Springer, 2018: 85-100.
[21] NAZERI K, NG E, JOSEPH T, et al. EdgeConnect: Generative image inpainting with adversarial edge learning [CP/OL]. (2019-01-11). [2019-05-02]. https:// arxiv.org/abs/1901.00212.
[22] LI Y J, LIU S F, YANG J M, et al. Generative face completion [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 3911-3919.
[23] CHEN T Q, SCHMIDT M. Fast patch-based style transfer of arbitrary style [CP/OL]. (2016-12-13). [2019-05-02]. https://arxiv.org/abs/1612.04337.
[24] LI C, WAND M. Combining Markov random fields and convolutional neural networks for image synthesis [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 2479-2486.
[25] YANG C, LU X, LIN Z, et al. High-resolution image inpainting using multi-scale neural patch synthesis [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 6721-6729.
[26] RONNEBERGER O, FISCHER P, BROX T. U-Net: Convolutional networks for biomedical image segmentation [M]//Lecture Notes in Computer Science. Heidelberg: Springer, 2015: 234-241.
[27] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [CP/OL]. (2014-09-04). [2019-05-02]. https:// arxiv.org/abs/1409.1556.
The Inpainting of Irregular Damaged Areas in Ancient Murals Using Generative Model
WEN Li-long, XU Dan, ZHANG Xi, QIAN Wen-hua
(School of information Science and Engineering, Yunnan University, Kunming Yunnan 650500, China)
In order to preserve and restore the precious ancient mural art in a better way, based on the existing manual restoration technology, the digital virtual restoration method can effectively improve the efficiency of restoration and reduce the costs of restoration. In this aspect, using the generative network method in deep learning to automatically generate the missing part of the murals for completion and restoration can achieve good results. The network used for restoration is basically an autoencoder. The encoder takes the murals images to be processed and the mask corresponding to the damaged part as the input for feature extraction. The decoder will restore the feature chart obtained from the encoder to its original size by deconvolution, which completes the restoration. In this process, the damaged area will be completed automatically. At the same time, separating the murals into different pieces, restoring and reassembling them later makes it achievable to restore murals of any size. Compared with other digital mural restoration methods, the one proposed in the present study is applicable to more general purposes and not limited by the type of murals and their damage. In the generally damaged murals, this method can achieve a better restoration effect compared with the existing level. Moreover, even for a large-area damaged mural where the naked eyes cannot identify effective information, this method can nevertheless restore it to one containing images of full meaning.
murals repainting; convolutional neural network; generating model; autoencoder
TP 391
10.11996/JG.j.2095-302X.2019050925
A
2095-302X(2019)05-0925-07
2019-01-06;
2019-04-19
溫利龍(1993-),男,山西呂梁人,碩士研究生。主要研究方向為圖像處理、計算機視覺等。E-mail:wenlilong@mail.ynu.edu.cn
徐 丹(1968-),女,江蘇無錫人,教授,博士,博士生導師。主要研究方向為多媒體信息處理、計算機視覺、模式識別等。 E-mail:danxu@ynu.edu.cn
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
