基于圖案的多層次跨場景服裝檢索?
2019-11-12 06:38:46周靜紅李華昱
計算機與數字工程 2019年10期
龔 安 周靜紅 李華昱
(中國石油大學(華東)計算機與通信工程學院 青島 266580)
1 引言
隨著網上購物的發展與流行,服裝電子商務快速發展,針對服裝的檢索技術成為了新的研究熱點。現有網絡平臺的服裝檢索方案大多是基于文本的圖像檢索,主要是利用關鍵字針對圖像特征進行描述,然后通過文本匹配檢索的方式實現圖像檢索。文本標簽的定義容易受到標注人主觀認識的影響,檢索結果往往并不理想。基于內容的圖像檢索更加符合人類的感知特點,同時隨著人工神經網絡的發展,這種方法越來越受到相關學者的關注。基于內容的服裝圖像檢索技術依賴于服裝的視覺特征,通過對圖像特征的提取得到特征向量,計算特征向量之間的匹配程度就可以獲得最終的檢索結果。但是目前跨場景服裝圖像檢索技術的發展受到以下兩方面的限制:1)線上線下服裝圖像背景差異大,很大程度上影響了服裝區域檢測的準確性。2)由于服裝款式樣式的多樣性,根據服裝特征進行學習已經不能完全描述出服裝的信息,根據這些信息進行服裝檢索的精確度有待提高。
2 相關工作
基于內容的服裝檢索技術在發展初期大多是通過人臉識別和皮膚檢測等方式大致估計服裝位置,然后通過GIST 特征、SIFT 特征、HOG 特征等描述圖像特征。隨著深度神經網絡在目標檢測和特征表示中的普及,人們對深度模型的相似性學習越來越感興趣,嘗試將深度神經網絡應用到服裝檢索中。基于全局特征描述方法[1~3]多采用顏色直方圖等統計學特征,對服裝的款式、顏色等特征進行描述,但是對于細粒度特征可能容易忽略。基于細粒度的特征描述方法[4~5]則主要提取服裝局部特征,能夠對服裝的花色等細節特征進行較好描述,不過沒有概括服裝外形樣式等整體特征。Yan等[6]則注重于解決人體姿勢對服裝特征的影響,在具有復雜人體姿態的數據集中取得良好的效果。Liu 等[7]提出使用FashionNet 網絡架構預測提取局部關鍵位置的特征并和服裝的全局特征進行融合,對服裝屬性進行更好的學習和檢索。但是局部關鍵位置的特征需要重新學習,過程較為繁瑣,而且根據人體關鍵部位的局部特征和服裝全局特征差異性不大。人們對服裝進行相似性判斷時,不僅關注服裝樣式顏色等全局特征,內部包含的圖案特征(品牌商標等)也是重要依據。因此,本文針對服裝檢索的現有問題和相關研究提出一種綜合考慮服裝全局特征、服裝細粒度特征和服裝內部差異性大的局部圖案特征進行特征提取和檢索的新方法。
3 網絡模型設計
3.1 神經網絡算法流程
根據人類對服裝的認知特點,本文提出基于圖案的多層次跨場景服裝檢索方法。神經網絡算法流程圖如圖1 所示,輸入為線下日常服裝圖像,網絡從輸入服裝圖像中檢測提取出目標服裝區域以及服裝上的特殊圖案區域,針對兩個區域分別提取各自的圖像特征,然后將全局服裝特征和局部圖案特征融合作為服裝整體特征描述,根據線上線下服裝圖像特征向量的相似度進行排序,輸出線上數據集圖像。
3.2 網絡模型
本文構建的網絡模型如圖2 所示。網絡由三部分組成:第一部分使用YOLOv2[8]對服裝圖像進行檢測,識別出日常場景和在線商城場景中服裝圖像的上身和下身部分以及圖案區域。第二部分是兩個Resnet[9]網絡,其中一個使用triplet loss[10]函數作為損失函數針對服裝區域進行度量學習,提高網絡對跨場景服裝圖像的識別能力;另一個網絡使用ImageNet[10]進行預訓練,然后通過服裝數據集圖案區域微調之后對圖案區域進行特征提取。第三部分是圖像檢索,融合兩個Resnet網絡輸出作為特征向量保存到數據庫中以便進行服裝圖像檢索。
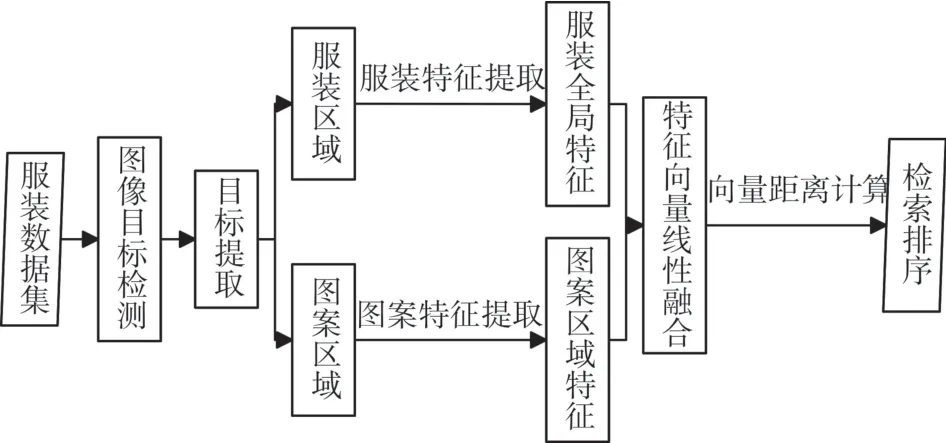
圖1 神經網絡算法流程圖
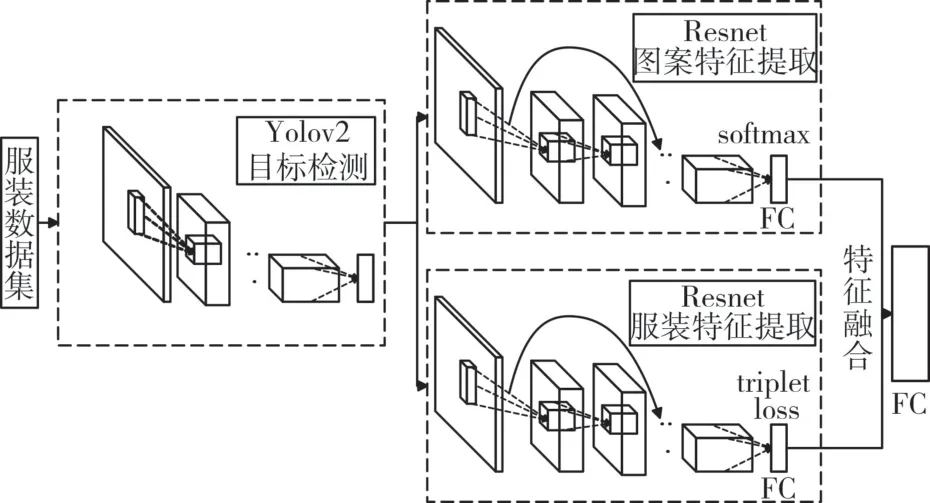
圖2 網絡模型
3.2.1 YOLOv2網絡目標檢測
圖像分割是圖像檢索的重要前提,對于跨場景服裝檢索而言,輸入的日常服裝圖像通常背景復雜,而相關的在線服裝圖像背景單一,所以二者存在較大差異,導致檢索精度較差。因此,利用目標檢測算法定位并分割出服裝圖像的目標區域,有利于消除背景區域對目標區域的特征干擾,提高服裝檢索精度。其中,YOLOv2 是目前目標檢測效果較好的深度學習算法。
利用YOLOv2 提取不同場景服裝圖像目標區域的具體步驟如下:
1)在卷積層提取的特征圖上進行13*13 的網格劃分;
2)采用k-means 聚類算法選擇具有代表性的先驗框(centroid)維度,其中,k-means 算法采用的距離函數(度量標準)為
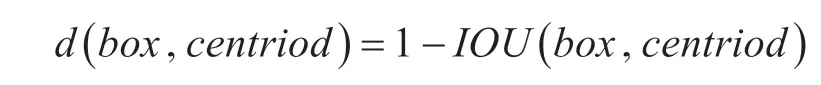
通過對數據集中的ground true box(人工標記的物體)做聚類,找到ground true box 的統計規律。經過聚類分析,選取5個初始候選框。
3)對特征圖上的每個網格預測5 個bounding box(邊界框),每一個bounding box 預測5 個坐標值:tx,ty,tw,th,to。如果這個網格距離圖像左上角的邊距為(cx,cy)以及該網格對應的bounding box prior(先驗框)維度的長和寬分別為(pw,ph),那么對應的預測框為
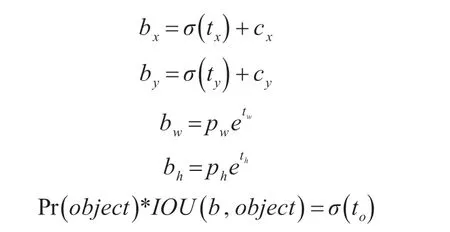
其中,σ 定義為sigmoid 激活函數,將函數值約束到[0,1],用來預測相對于該網格中心的偏移(不會偏離網格);預測框的位置是相對于bounding box prior的寬高乘以系數得到。
4)提取IOU 值大于等于0.7 的bounding box 為服裝區域和圖案區域。
3.2.2 Resnet網絡特征提取
只有對目標區域特征進行準確、完整的特征提取才能完成更好的特征匹配與圖像檢索。近年來卷積神經網絡(Convolutional Neural Networks,CNN)[11]在特征提取方面的應用越來越廣泛,同時含更多隱含層的深度卷積網絡相較于淺層神經網絡具有更強大的特征學習和特征表達能力。但是CNN 隨著網絡層數的增加,訓練難度不斷加大,很難保證模型能訓練到一個理想的結果。微軟亞洲研究院He 等[12]2015 年(正式發表于CVPR2016)提出了殘差學習的思想,很好地解決了深度網絡訓練難的問題,使得網絡層數達到了一個新的高度。為提取服裝和圖案圖像的多層次特征,更好地表達圖像的語義信息,本文在深度卷積網絡的基礎上,引入殘差學習的思想,使用深度殘差網絡進行特征識別。
圖3 是殘差學習模塊的示意圖,殘差學習模塊可以作為神經網絡的一部分或多個部分。假設該部分神經網絡的輸入為x,要擬合的函數映射(即輸出)為H(x),可以定義另外一個殘差映射F(x)=H(x)-x,則原始的函數映射H(x)可以表示為F(x)+x。He通過實驗說明:優化殘差映射F(x)比優化原始映射H(x)要容易的多。F(x)+x在前饋神經網絡中可以理解為捷徑(shortcut)x 與主徑F(x)的加和。捷徑并沒有引入額外的參數,不影響原始網絡的復雜度,整體網絡依然可使用現有的深度學習反饋訓練求解。
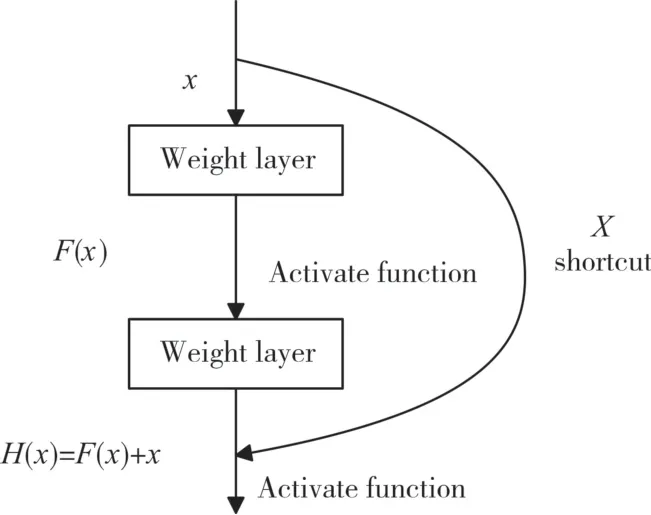
圖3 殘差學習示意圖
3.2.3 基于triplet loss的度量學習
網絡使用三張圖像組成三元組作為樣本,記為(xia,xip,xin),其中xin是線下服裝圖像,xip作為與xni相同類別的線上正樣本圖像,xai是隨機選取的線上服裝,與線下服裝不同類別,稱作負樣本。損失函數可表達為
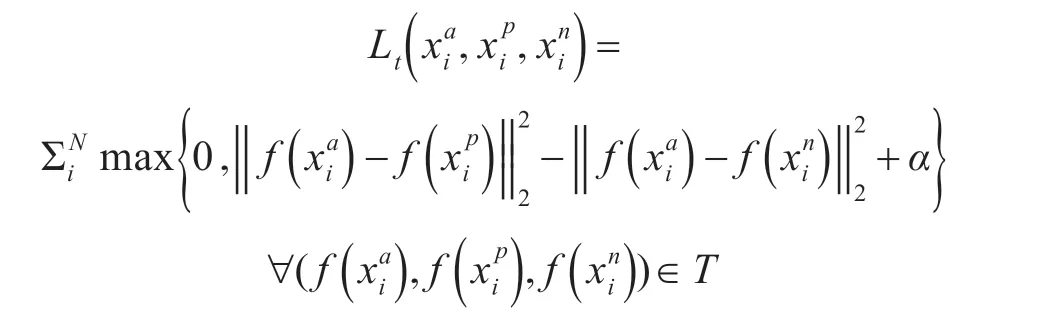
其中T 是所有三元組集合,α為閾值參數。該損失函數主要為了增大不同類別間的距離,同時減小同類間的距離,可以通過學習將服裝背景的影響減小,從而提高跨場景檢索準確率。
3.2.4 特征融合檢索
從前一部分的兩個Resnet 網絡中學習得到兩種特征向量,融合服裝區域全局特征和圖案的局部特征,就構成了服裝的多層次特征描述。最終得到服裝圖像的768 維服裝特征向量,其中512 維來自服裝全局特征,256 維來自圖案特征。特征融合采用線性融合即可。由于一些服裝可能識別不出明顯的圖案區域,對服裝的多層次特征描述影響較小,但是網絡可以提高帶有圖案服裝的檢索準確度,有助于提升數據集整體檢索準確度。
4 實驗和分析
4.1 數據集
為了驗證加入圖案區域特征后跨場景檢索的效果,本文建立一個服裝圖片數據集,數據集中共有17320 張不同款式顏色的服裝圖像,服裝數據庫大多來自其他數據集(DeepFashion、DARN[12]),也有部分采集自淘寶、京東等購物網站的服裝和人們在不同環境下的日常服裝。線上服裝占80%左右,剩下的線下服裝每個都有與之相對應的商品圖像構成服裝對,以便進行度量學習。同時服裝中包含明顯圖案區域的占大概50%左右。所有服裝都按照款式(T 恤、外套、短裙等)、樣式(純色、條紋、豹紋等)、材質(羊毛、皮革、棉麻等)等屬性做了詳細的標注,以便于訓練和評價檢索精度。屬性類別和示例如表1所示。
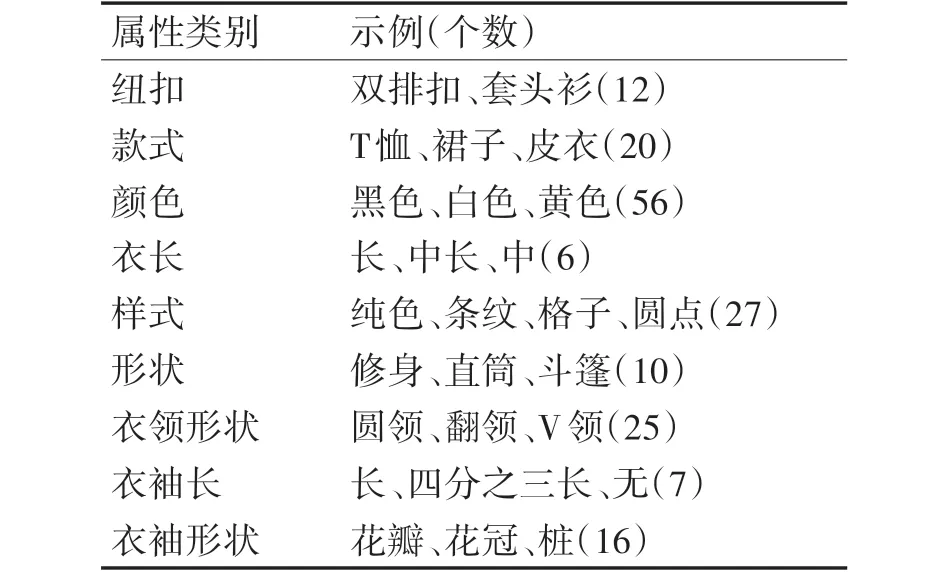
表1 服裝屬性類別和示例(括號中數字是該類別總個數)
使用ImageNet數據集對服裝圖案進行預訓練,同時使用本文新建數據集中的圖案區域進行訓練微調。
4.2 實驗結果和分析
本文使用的網絡記為Pattern-Net,分別對文中使用的部分網絡結構進行替換,在本文構建的服裝數據集上進行圖像檢索,對比實驗結果。
1)用FastRCNN 網絡[13]替換進行目標檢測部分的YOLOv2網絡,記為FastRCNN-Net;
2)將網絡特征提取部分的Resnet 網絡用CNN網絡替換,記為CNN-Net;
3)不使用triplet loss 函數作為損失函數進行度量學習,記為TL-Net;
4)僅使用全局服裝特征對服裝圖像進行檢索,記為Part-Net。
其中針對使用了triplet loss 函數的網絡在每迭代5000 次之后重新生成新的三元組,這樣可以讓網絡充分學習來自不同環境場景的圖像。同時在進行圖像檢索時,首先檢索具有相同語義屬性的服裝,然后比較輸入圖像與數據庫圖像特征向量的距離,認為特征距離較短的圖像更相似。表2 展示不同網絡的服裝檢索結果。
表中Top-k(分別取5和10)準確率表示網絡檢索出的前k 個結果中是否包含帶檢索圖像的準確率,其中Part-Net 網絡和Pattern-Net 網絡針對不同數據集的對比如表3所示。
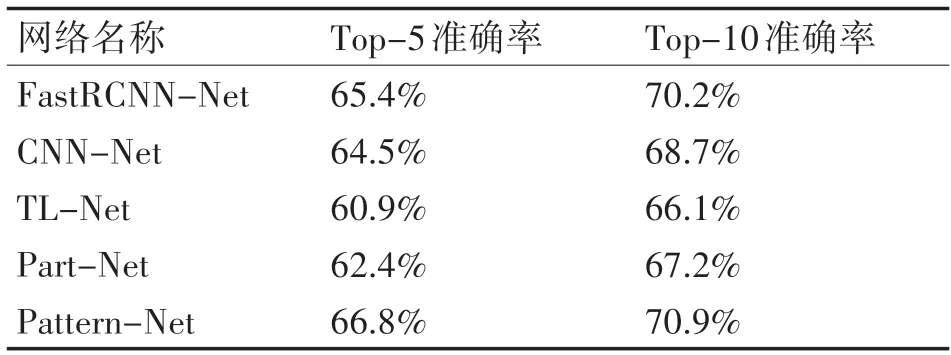
表2 不同網絡的服裝檢索結果
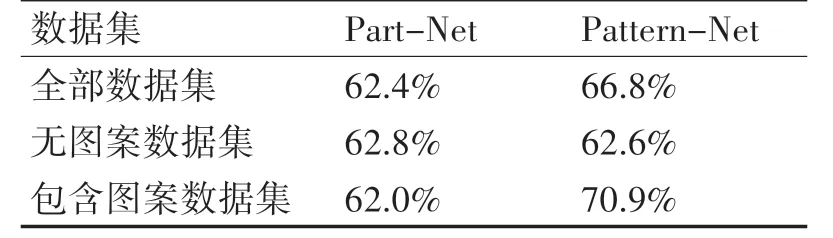
表3 Part-Net網絡和Pattern-Net網絡在不同數據集上的準確率
從表2 可以看出,無論是進行目標檢測的YOLOv2 網絡還是用來特征提取的Resnet 網絡,比其他主流網絡能夠提供更好的性能,同時在網絡學習時使用triplet loss函數有助于跨場景服裝檢索。
表3 說明基于圖案的服裝檢索方法雖然對無圖案數據集的檢索沒有太大影響,但能夠有效提高包含圖案服裝數據集的檢索準確率,從而提高整體數據集準確率4%左右。
網絡檢索結果示例如圖4 所示,從圖中可以看出檢索結果基本能夠將所有的屬性類別考慮全面,同時體現出圖案的屬性特征。

圖4 服裝圖像檢索示例(每行第一張圖片為輸入,后五張為檢索結果)
5 結語
針對現有服裝檢索注重全局特征、對服裝局部特征描述較少的情況,提出一種基于圖案多層次跨場景服裝檢索方法,融合了服裝區域全局特征以及服裝圖案區域局部特征,將服裝圖像特征描述進一步豐富,能夠實現更好的匹配檢索。本文還借鑒使用了基于triplet loss的度量學習進行跨場景服裝圖像的學習,提高了網絡跨場景檢索的能力。實驗結果表明,本文方法能夠有效提高帶有標志性圖案的服裝圖像檢索的準確度,從而提高整體服裝檢索精度。但是對于存在人體遮擋和側身等情況的服裝檢索精確度有待提高,論文的后續工作將著重圍繞這些問題進行展開,以便進一步提高檢索準確率。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
