利用MISA多目標(biāo)優(yōu)化的置信規(guī)則庫分類算法
2019-11-09 03:42:30林錦胡家琛劉莞玲吳英杰
智能系統(tǒng)學(xué)報(bào) 2019年5期
林錦,胡家琛,劉莞玲,吳英杰
(福州大學(xué) 數(shù)學(xué)與計(jì)算機(jī)科學(xué)學(xué)院,福建 福州 350116)
數(shù)據(jù)分類研究是數(shù)據(jù)挖掘領(lǐng)域的一個(gè)重要分支,它主要通過已知類別的數(shù)據(jù)集構(gòu)建出各類別的特征空間,再將未知類別的數(shù)據(jù)映射到該特征空間中,從而來確定其所屬類別[1]。目前,數(shù)據(jù)分類主要應(yīng)用于機(jī)器學(xué)習(xí)、模式識(shí)別、遺傳算法、神經(jīng)網(wǎng)絡(luò)、統(tǒng)計(jì)學(xué)、數(shù)據(jù)庫、專家系統(tǒng)等領(lǐng)域。模糊規(guī)則分類系統(tǒng)(fuzzy rule-based classification system, FRBCS)[2-4]廣泛地用于求解分類問題。FRBCS能夠建立清晰的語義模型,具有良好的可解釋性,能夠定性定量地處理專家信息。此后,Yang等[5]提出了基于證據(jù)推理的置信規(guī)則庫推理方法,該方法以IF-THEN規(guī)則庫、模糊理論、DS證據(jù)理論和決策理論等為基礎(chǔ),有效地利用不精確或不完整的信息對復(fù)雜決策問題進(jìn)行建模;Jiao等[6]在置信函數(shù)框架上擴(kuò)展模糊規(guī)則庫分類系統(tǒng)(FRBCS),提出置信規(guī)則庫分類系統(tǒng)(belief rule base classification system, BRBCS)。置信規(guī)則庫分類系統(tǒng)采用數(shù)據(jù)驅(qū)動(dòng)方式由數(shù)據(jù)集自動(dòng)生成置信規(guī)則,建立特征空間與類空間之間的不確定關(guān)系,利用基于置信函數(shù)理論的置信推理方法(belief reasoning method,BRM)對查詢模式進(jìn)行分類推理。但是傳統(tǒng)的置信規(guī)則庫分類系統(tǒng)的推理性能極為依賴于內(nèi)部參數(shù)取值,因此劉莞玲等[7]在BRBCS的基礎(chǔ)上提出基于差分的置信規(guī)則庫分類方法(DEBRM)。該方法能夠有效解決BRBCS中參數(shù)優(yōu)化的問題,使分類系統(tǒng)不需要依賴于增加模糊區(qū)間劃分?jǐn)?shù)量來提高分類準(zhǔn)確度。但該方法隨著前提屬性個(gè)數(shù)的增加,規(guī)則數(shù)量呈指數(shù)式增長,就會(huì)導(dǎo)致置信規(guī)則庫復(fù)雜度增加。因此本文針對Liu等提出的DEBRM分類方法存在無法兼顧準(zhǔn)確率和復(fù)雜度的問題進(jìn)行改進(jìn),提出置信規(guī)則庫分類系統(tǒng)的多目標(biāo)優(yōu)化模型。
多目標(biāo)優(yōu)化問題(multi-criterion optimization problems)涉及多個(gè)目標(biāo)的極大化或極小化,同時(shí)這些目標(biāo)之間往往是互相沖突的[8],一個(gè)目標(biāo)性能的優(yōu)化可能導(dǎo)致另一個(gè)目標(biāo)性能的下降。多目標(biāo)的最優(yōu)解不是一個(gè)特定的解,而是一組Pareto最優(yōu)解,這些解沒有優(yōu)劣之分[9-10]。目前用于解決多目標(biāo)優(yōu)化問題的智能優(yōu)化算法有:傳統(tǒng)遺傳算法、群集智能算法(粒子群、蟻群)、人工免疫算法、神經(jīng)網(wǎng)絡(luò)等[11]。本文擬在DEBRM分類系統(tǒng)中,結(jié)合多目標(biāo)免疫系統(tǒng)算法(MISA),提出利用MISA的置信規(guī)則庫分類方法,通過特征屬性約簡來降低復(fù)雜度并使得準(zhǔn)確率盡可能高;通過對系統(tǒng)的分類準(zhǔn)確率和復(fù)雜度進(jìn)行多目標(biāo)優(yōu)化,從而得到一組均衡解供決策者選擇。在實(shí)驗(yàn)中選用 Iris、Wine、Cancer、Glass這 4 個(gè)經(jīng)典的公共測試數(shù)據(jù)集來驗(yàn)證本文方法的有效性。
1 相關(guān)概念
1.1 基于DE的置信規(guī)則庫分類方法
置信規(guī)則庫分類系統(tǒng)(BRBCS)由模糊規(guī)則庫分類系統(tǒng)(FRBCS)在置信函數(shù)框架上擴(kuò)展得來,采用數(shù)據(jù)驅(qū)動(dòng)方式構(gòu)建規(guī)則庫,規(guī)則庫的規(guī)則條數(shù)即結(jié)構(gòu)復(fù)雜度取決于前提屬性個(gè)數(shù)和模糊區(qū)間劃分?jǐn)?shù)。BRBCS的置信規(guī)則結(jié)構(gòu):

傳統(tǒng)基于置信規(guī)則庫參數(shù)學(xué)習(xí)的分類系統(tǒng)(BRBCS)準(zhǔn)確率受參數(shù)值約束,因此Liu等[7]提出基于DE的置信規(guī)則庫推理的分類方法(DEBRM),該方法主要包括基于DE的參數(shù)訓(xùn)練和置信推理過程。
1.2 多目標(biāo)優(yōu)化基本原理

2 MISA-BRM分類系統(tǒng)
在分類系統(tǒng)中,增加前提屬性個(gè)數(shù)可以提高系統(tǒng)推理的準(zhǔn)確率,但同時(shí)也增加了分類系統(tǒng)的復(fù)雜度,所以復(fù)雜度和準(zhǔn)確率是一組相互沖突的目標(biāo)。如何從訓(xùn)練數(shù)據(jù)集中找到使準(zhǔn)確率盡可能大、復(fù)雜度盡可能小的折中方案具有重要意義,因此本文提出利用MISA多目標(biāo)優(yōu)化的置信規(guī)則庫分類方法。該方法對數(shù)據(jù)集進(jìn)行特征屬性約減,并采用差分進(jìn)化方法進(jìn)行參數(shù)學(xué)習(xí)來獲取最優(yōu)結(jié)構(gòu)參數(shù),同時(shí)對經(jīng)典的MISA算法進(jìn)行適應(yīng)性改進(jìn),對分類系統(tǒng)的準(zhǔn)確率和復(fù)雜度進(jìn)行多目標(biāo)優(yōu)化,從而保證分類系統(tǒng)的規(guī)則數(shù)盡可能少(即系統(tǒng)結(jié)構(gòu)復(fù)雜度盡可能低)的同時(shí),又能保證系統(tǒng)分類的準(zhǔn)確率盡可能高。
最大化分類準(zhǔn)確率即最小化分類錯(cuò)誤率,所以本文的兩個(gè)目標(biāo)函數(shù)為分類錯(cuò)誤率和置信規(guī)則庫規(guī)則條數(shù),代表置信規(guī)則庫中的參數(shù):前提屬性個(gè)數(shù)、模糊區(qū)間劃分?jǐn)?shù)、前提屬性權(quán)重、規(guī)則權(quán)重、結(jié)果置信度,中參數(shù)涉及以上所列參數(shù),中參數(shù)涉及前提屬性個(gè)數(shù)、模糊區(qū)間劃分?jǐn)?shù)。因此本文的多目標(biāo)優(yōu)化問題描述為

2.1 改進(jìn)型MISA多目標(biāo)優(yōu)化算法
MISA算法是Coello等[12]根據(jù)免疫系統(tǒng)中抗體的克隆選擇原則提出的。
2.1.1 改進(jìn)型MISA算法原理
改進(jìn)型MISA算法將群體中的所有個(gè)體均視作“抗體”。依據(jù)克隆選擇原則,選擇群體中的非支配解進(jìn)行克隆,根據(jù)它們在解空間的擁擠程度來決定克隆的數(shù)目,并對克隆的個(gè)體進(jìn)行高概率變異和交叉操作,生成新的抗體群[12]。本文對Coello等提出的MISA針對基于置信規(guī)則庫分類問題做適應(yīng)性改進(jìn),并在個(gè)體變異中增加接種疫苗的變異操作。改進(jìn)型MISA與原始型MISA的一個(gè)主要區(qū)別在于確定待克隆抗體的復(fù)制個(gè)體數(shù)的方法不同,改進(jìn)型MISA根據(jù)待克隆抗體所處網(wǎng)格密度及支配情況確定最大可復(fù)制數(shù),再根據(jù)抗體群所能容納的最大個(gè)體數(shù)確定最終的復(fù)制數(shù)量,確定待克隆抗體復(fù)制個(gè)體數(shù)的具體方法如下:
1)確定待克隆抗體最大可復(fù)制個(gè)數(shù)
按照個(gè)體在外部種群(外部種群中個(gè)體互為非支配解)中所處網(wǎng)格的密度及支配關(guān)系分配等級(jí),按照等級(jí)確定最大的克隆數(shù)。分4個(gè)等級(jí):所處網(wǎng)格密度小于平均網(wǎng)格密度,等級(jí)為4,最多可復(fù)制4個(gè)個(gè)體;所處網(wǎng)格密度等于平均網(wǎng)格密度,等級(jí)為3,最多可復(fù)制3個(gè)個(gè)體;所處網(wǎng)格密度大于平均網(wǎng)格密度,等級(jí)為2;個(gè)體被支配且被選為待克隆抗體則等級(jí)為1,最多可復(fù)制1個(gè)個(gè)體。
2)確定待克隆抗體的復(fù)制個(gè)數(shù)
抗體群設(shè)置最多可容納個(gè)體數(shù)。將抗體群可容納個(gè)體數(shù)視為復(fù)制名額個(gè)數(shù),具體過程如下:
①待克隆抗體按照優(yōu)先級(jí):被支配數(shù)少>所處網(wǎng)格密度小>支配其他個(gè)體數(shù)多排成一列縱隊(duì);
②從隊(duì)頭到隊(duì)尾依次查看待克隆抗體的等級(jí),當(dāng)待克隆抗體等級(jí)大于0且抗體群可容納個(gè)體數(shù)大于0時(shí),待克隆抗體獲得1個(gè)復(fù)制名額,每分配出1個(gè)名額,獲得名額的待克隆抗體等級(jí)減1,抗體群可容納數(shù)減1;當(dāng)抗體群可容納個(gè)體數(shù)等于0時(shí)結(jié)束分配;
③走到隊(duì)尾整個(gè)抗體群的抗體等級(jí)累加和大于0,返回執(zhí)行②。
除了待克隆抗體的克隆個(gè)體數(shù)確定方式不同外,改進(jìn)型MISA采用二進(jìn)制染色體編碼,抗體長度等于最大前提屬性個(gè)數(shù),取值為0代表刪除這個(gè)前提屬性,取值為1代表選中這一前提屬性。確定前提屬性后構(gòu)建規(guī)則庫,規(guī)則庫編碼采用實(shí)數(shù)編碼,一個(gè)規(guī)則庫作為一個(gè)個(gè)體;無交叉操作,變異操作包括單點(diǎn)變異和接種疫苗,具體的提取疫苗和接種疫苗方法說明如下。
1)提取疫苗:疫苗群體限制最大個(gè)數(shù),抗體被選為疫苗的條件為被支配數(shù)為0,支配數(shù)大于0。根據(jù)Pareto的定義,能夠支配其他個(gè)體的個(gè)體不是屬性最少也不是屬性最多的個(gè)體,而是屬性個(gè)數(shù)居中的個(gè)體,如選取的特征屬性個(gè)數(shù)為5,受它支配的解是屬性個(gè)數(shù)大于5且分類錯(cuò)誤率大于它的個(gè)體,這一定程度上說明這5個(gè)屬性中可能具有區(qū)分性較高的特征屬性或特征屬性組合。
2)接種疫苗操作:隨機(jī)從免疫群體中隨機(jī)選取一個(gè)個(gè)體,從疫苗染色體中所有值為1的染色體單位中隨機(jī)選取1個(gè)單位,再從所有值為0的染色體單位中隨機(jī)選取1個(gè)單位,將這2個(gè)單位植入個(gè)體中。植入個(gè)體后,有4種可能情況:個(gè)體特征屬性減少或增加一個(gè);個(gè)體特征屬性完全不變;個(gè)體屬性特征個(gè)數(shù)不變但選取的特征屬性改變;有可能使個(gè)體具有高區(qū)分性的特征屬性,或刪除不必要的屬性。
2.1.2 外部種群及自適應(yīng)網(wǎng)格算法
外部種群用于保存Pareto非劣解,外部種群中的個(gè)體兩兩之間不存在支配與被支配關(guān)系。為了使非支配解盡可能均勻地分布于Pareto前沿,外部種群采用Knowles等[13]提出的自適應(yīng)網(wǎng)格法進(jìn)行更新,詳見算法1。
算法1 自適應(yīng)網(wǎng)格算法
輸出 Pareto最優(yōu)前沿。
2)循環(huán)遍歷Q;
5)判斷外部種群個(gè)體數(shù)是否達(dá)到最大值:如果外部種群個(gè)體數(shù)達(dá)到所能容納的最大值,那么執(zhí)行 6),否則將加入 EP;
7)循環(huán)結(jié)束。
2.1.3 改進(jìn)型 MISA 算法流程
改進(jìn)型MISA算法的算法流程的主要部分和原始MISA算法相同:生成抗體群,更新自適應(yīng)網(wǎng)格,選擇待克隆抗體,確定待克隆抗體的復(fù)制數(shù)量。但改進(jìn)型MISA在變異操作中加入了接種疫苗操作,因此增加了疫苗提取的過程,具體流程如算法2~4所示。
算法2 疫苗提取及更新算法
輸入 抗體群;
輸出 更新后的疫苗群體。
1)選取出抗體群中被支配數(shù)為0,支配數(shù)大于0的個(gè)體,將選出的個(gè)體按照支配個(gè)體數(shù)降序排列形成群體P;
2)疫苗提取及更新:如果疫苗群體為空,在符合群體P個(gè)體數(shù)和疫苗群體個(gè)體數(shù)最大值的約束條件下,按隊(duì)列先后順序?qū)⑷后wP中個(gè)體復(fù)制到疫苗群體中;否則,將群體P中個(gè)體和疫苗群體中個(gè)體合并起來,并按照支配個(gè)體數(shù)降序排列形成群體P',在符合群體P'個(gè)體數(shù)和疫苗群體個(gè)體數(shù)最大值的約束條件下,按隊(duì)列先后順序?qū)⑷后wP'中個(gè)體復(fù)制到疫苗群體中。
算法3 加入接種疫苗的多目標(biāo)變異算法
輸入 被選中將要進(jìn)行克隆的個(gè)體;
輸出 經(jīng)過變異/接種疫苗生成新抗體群。
1)將待克隆抗體按照可克隆個(gè)數(shù)進(jìn)行克隆,生成新的初始抗體群V;
3)隨機(jī)選取[0, 1]的一個(gè)值r;
5)否則進(jìn)行疫苗接種:隨機(jī)選取一個(gè)疫苗w;隨機(jī)選取w中染色體單位值為0的片段;隨機(jī)選取w中染色體單位值為1的片段;對的個(gè)體植入、;
6)循環(huán)結(jié)束。
利用MISA多目標(biāo)優(yōu)化的置信規(guī)則庫分類算法有機(jī)融合了算法1、2、3、MISA和DE參數(shù)訓(xùn)練方法。多目標(biāo)免疫系統(tǒng)算法的選擇進(jìn)化機(jī)制是整個(gè)算法的核心,使得差分訓(xùn)練規(guī)則庫參數(shù)和特征屬性選擇組合兩個(gè)優(yōu)化過程相互促進(jìn),最終獲得一組Pareto最優(yōu)解。DE參數(shù)訓(xùn)練方法對根據(jù)抗體構(gòu)建的規(guī)則庫進(jìn)行參數(shù)優(yōu)化,得到不同的特征屬性選擇組合構(gòu)建的置信規(guī)則庫的近似最優(yōu)分類性能,進(jìn)而采用MISA的選擇機(jī)制和自適應(yīng)網(wǎng)格進(jìn)行抗體選擇,將分類性能好的特征屬性組合保留在外部種群中,同時(shí)也將區(qū)分性高的特征屬性保留下來,在抗體進(jìn)化的時(shí)候,采用變異增加抗體群的多樣性,疫苗提取、更新和接種疫苗算法使得區(qū)分性高的特征屬性在抗體群中擴(kuò)散,讓抗體能夠得到更優(yōu)的分類性能,迭代更新外部種群,不斷優(yōu)化外部種群中抗體的特征屬性選擇組合、分類性能。
算法4 利用MISA多目標(biāo)優(yōu)化的置信規(guī)則庫分類算法
輸入 無;
輸出 Pareto最優(yōu)前沿。
1)初始化抗體群,初始化外部種群為空;
2)對由每個(gè)抗體構(gòu)建得來的置信規(guī)則庫采用DE參數(shù)訓(xùn)練方法進(jìn)行參數(shù)訓(xùn)練;
3)計(jì)算每個(gè)抗體的適應(yīng)值,進(jìn)而判斷每個(gè)抗體是否是Pareto解;
4)將得到的非支配個(gè)體復(fù)制到外部種群(調(diào)用算法1);
5)按一定的標(biāo)準(zhǔn)選取待克隆抗體;
6)按一定的標(biāo)準(zhǔn)確定待克隆抗體的復(fù)制數(shù)量;
7)抽取并更新疫苗(調(diào)用算法2);
8)如果達(dá)到MISA算法最大迭代次數(shù)則end,否則進(jìn)行9);
9)克隆抗體,并對個(gè)體進(jìn)行變異或疫苗接種(調(diào)用算法 3);
10)返回到 2)。
2.2 MISA-BRM分類模型
在MISA-BRM分類方法中,將前提屬性的選取編碼作為抗體,根據(jù)抗體構(gòu)建出初始的規(guī)則庫,將置信推理方法BRM作為推理機(jī),結(jié)合差分進(jìn)化算法對待優(yōu)化參數(shù)進(jìn)行學(xué)習(xí)矯正,進(jìn)而計(jì)算抗體在復(fù)雜度、分類錯(cuò)誤率兩個(gè)目標(biāo)函數(shù)上的適應(yīng)值,然后采用MISA的選擇進(jìn)化機(jī)制,在系統(tǒng)的復(fù)雜度、分類錯(cuò)誤率兩個(gè)維度上尋找Pareto解。算法的流程如圖1所示。

圖1 MISA-BRM模型Fig. 1 MISA-BRM model diagram
3 實(shí)驗(yàn)分析
3.1 實(shí)驗(yàn)環(huán)境
實(shí)驗(yàn)環(huán)境的基本信息:Intel(R) Core(TM) i7-6700 CPU @3.40 GHz處理器,8核,16 GB內(nèi)存,Window10 操作系統(tǒng)。
3.2 數(shù)據(jù)集參數(shù)設(shè)置
3.2.1 實(shí)驗(yàn)數(shù)據(jù)集
在實(shí)驗(yàn)部分本文選用University of Galifornia at Irvine分校網(wǎng)頁中獲取的公共測試集來驗(yàn)證算法有效性。數(shù)據(jù)集主要包括鳶尾花特征數(shù)據(jù)Iris、紅酒化學(xué)成分特征數(shù)據(jù)Wine、乳腺癌數(shù)據(jù)Cancer和玻璃類型數(shù)據(jù)Glass。表1列舉了這4個(gè)測試數(shù)據(jù)集中前提屬性數(shù)量、類別數(shù)量和數(shù)據(jù)集大小的信息。
其中Cancer原數(shù)據(jù)集中存在缺失數(shù)據(jù),實(shí)驗(yàn)中將缺失的16條數(shù)據(jù)刪除,保留683條數(shù)據(jù)。

表1 測試數(shù)據(jù)的基本信息Table 1 Basic information regarding the test data
3.2.2 參數(shù)設(shè)置
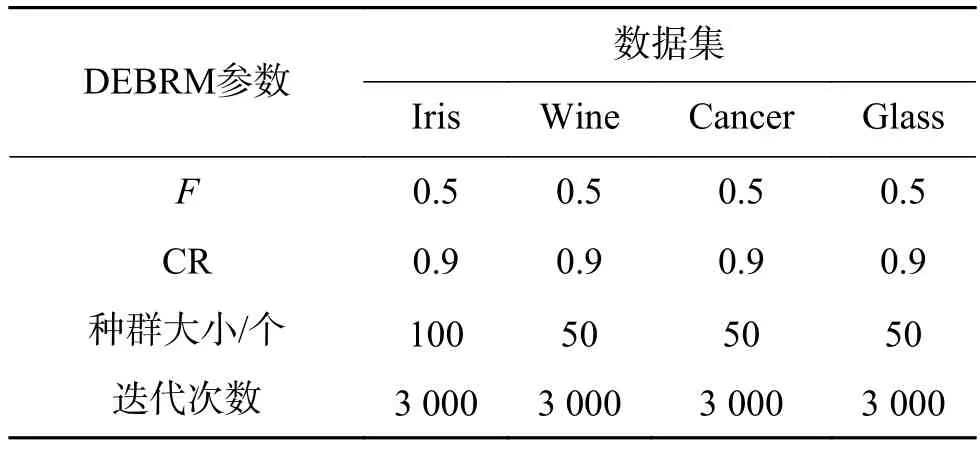
表2 DEBRM參數(shù)設(shè)置信息Table 2 The parameter setting information for DEBRM
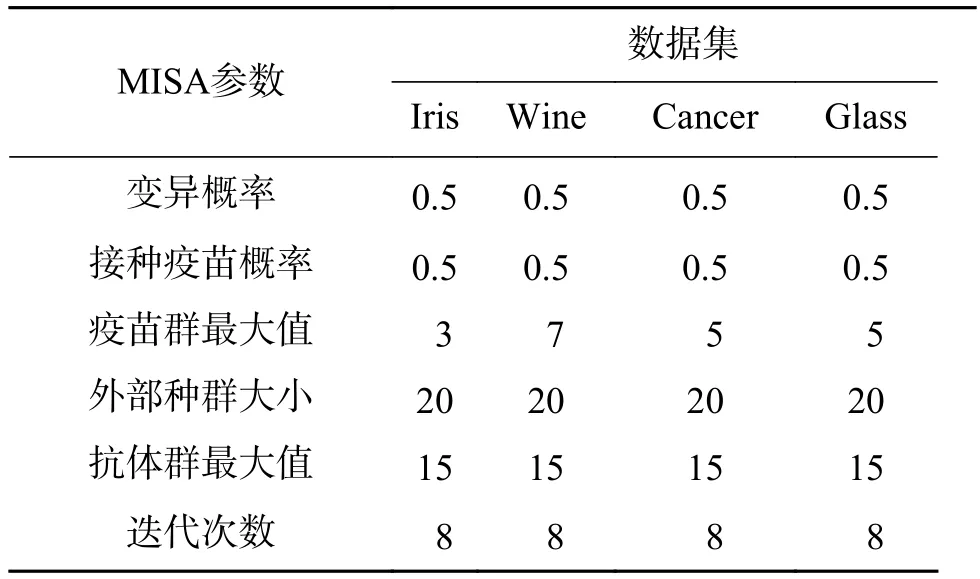
表3 MISA參數(shù)設(shè)置信息Table 3 The parameter setting information for MISA
3.3 數(shù)據(jù)集實(shí)驗(yàn)分析
實(shí)驗(yàn)中針對每組數(shù)據(jù)集,采用十折交叉驗(yàn)證方法對提出的算法進(jìn)行測試,數(shù)據(jù)集劃分方法采用分層抽樣方法。實(shí)驗(yàn)中用總的數(shù)據(jù)集(訓(xùn)練集+測試集)的錯(cuò)誤率進(jìn)行Pareto適應(yīng)值計(jì)算。針對每一數(shù)據(jù)集,取10組實(shí)驗(yàn)中在整個(gè)數(shù)據(jù)集上獲得的最高準(zhǔn)確率值最大的一組的實(shí)驗(yàn)結(jié)果來展示,采用圖表方式展示實(shí)驗(yàn)結(jié)果。用圖2~5分析整個(gè)數(shù)據(jù)集的Pareto最優(yōu)解集分布情況,圖中的點(diǎn)是外部種群中保存的Pareto非劣解,圖中的曲線是外部種群中所有Pareto最優(yōu)解對應(yīng)的目標(biāo)向量組成的Pareto最優(yōu)曲線;用表格數(shù)據(jù)分析數(shù)據(jù)集的Pareto最優(yōu)解集及其對應(yīng)的訓(xùn)練集和測試集的實(shí)驗(yàn)結(jié)果。
3.3.1 Iris 數(shù)據(jù)集實(shí)驗(yàn)分析
在Iris數(shù)據(jù)集中,每個(gè)類別的數(shù)據(jù)分布均勻。本文方法解決Iris數(shù)據(jù)集分類問題的Pareto最優(yōu)曲線如圖2所示。對Iris的訓(xùn)練數(shù)據(jù)集、測試數(shù)據(jù)集及整個(gè)數(shù)據(jù)集上的分類準(zhǔn)確率如表4所示。

圖2 Iris數(shù)據(jù)集的Pareto最優(yōu)曲線Fig. 2 The Pareto optimal curve for the Iris dataset
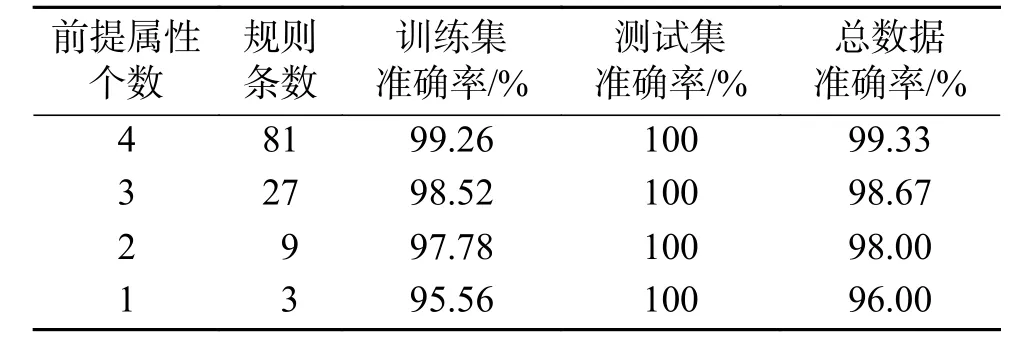
表4 Iris數(shù)據(jù)集上MISA-BRM的Pareto最優(yōu)解集Table 4 The Pareto optimal solution set of MISA-BRM for the Iris dataset
通過以上實(shí)驗(yàn)結(jié)果分析可知,在Iris總數(shù)據(jù)集上,Pareto最優(yōu)解集中4種不同的前提屬性個(gè)數(shù)的分類準(zhǔn)確率差距較小,其中4個(gè)前提屬性的分類結(jié)果與3個(gè)前提屬性分類的準(zhǔn)確率僅相差0.66%。相同的前提屬性個(gè)數(shù),選取不同的前提屬性構(gòu)建規(guī)則庫分類系統(tǒng)得到的分類準(zhǔn)確率不同。通過實(shí)驗(yàn)可知,針對Iris,本文方法通過對分類系統(tǒng)進(jìn)行多目標(biāo)優(yōu)化可以在滿足較高準(zhǔn)確率情況下構(gòu)建出復(fù)雜性更低的分類模型。
為了進(jìn)一步說明本文方法的有效性,將本文方法與BRBCS、DEBRM分類方法解決Iris 數(shù)據(jù)集分類問題時(shí)構(gòu)建的分類系統(tǒng)的復(fù)雜度和準(zhǔn)確率進(jìn)行對比,如表5所示。通過表5分析可知,傳統(tǒng)的BRBCS規(guī)則條數(shù)有兩千多條,而本文方法將規(guī)則條數(shù)約簡到二十多條,且本文方法在整個(gè)數(shù)據(jù)集的分類準(zhǔn)確率比傳統(tǒng)的BRBCS高。相比于DEBRM,規(guī)則約簡了54條,測試數(shù)據(jù)集的分類準(zhǔn)確率與DEBRM持平,訓(xùn)練數(shù)據(jù)集的分類準(zhǔn)確率低了1.48%,總的數(shù)據(jù)集分類準(zhǔn)確率低了1.33%,盡管該方法犧牲了一定的準(zhǔn)確率,但其降低了系統(tǒng)復(fù)雜度,可以為決策者根據(jù)實(shí)際需要提供更多的選擇。
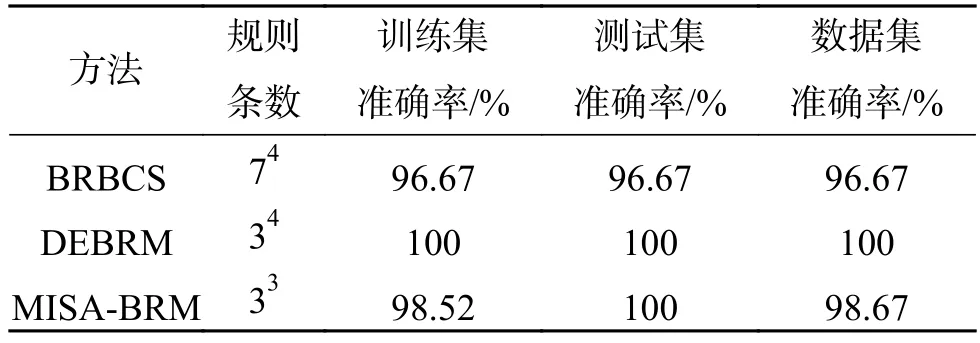
表5 Iris數(shù)據(jù)集結(jié)構(gòu)復(fù)雜度和分類準(zhǔn)確率對比Table 5 Comparison of the structural complexity and classification accuracy with respect to the Iris dataset
3.3.2 Wine 數(shù)據(jù)集實(shí)驗(yàn)分析
在Wine數(shù)據(jù)集中,各類別的數(shù)據(jù)量分布較不均勻。本文方法用于解決Wine數(shù)據(jù)集的Pareto最優(yōu),曲線如圖3所示。
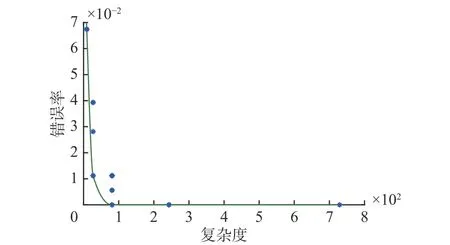
圖3 Wine數(shù)據(jù)集的Pareto最優(yōu)曲線Fig. 3 The Pareto optimal curve of the entire Wine dataset
對Wine的訓(xùn)練數(shù)據(jù)集、測試數(shù)據(jù)集及整個(gè)數(shù)據(jù)集上的分類準(zhǔn)確率如表6所示。
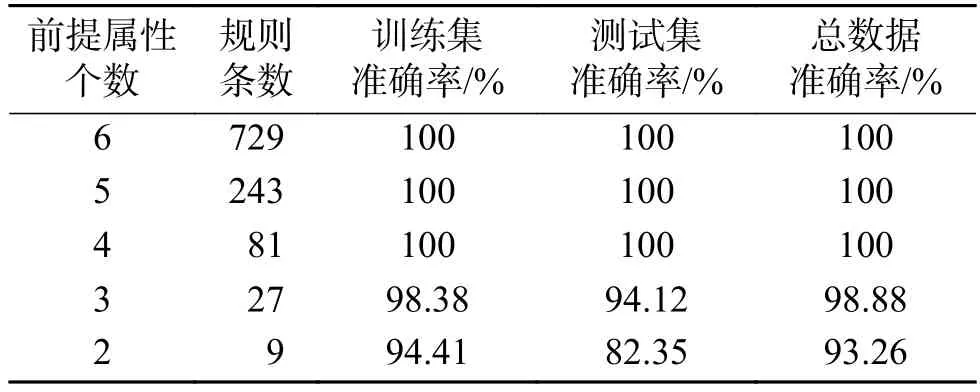
表6 Wine數(shù)據(jù)集上MISA-BRM的Pareto最優(yōu)解集Table 6 The Pareto optimal solution set of MISA-BRM with respect to the Wine dataset
通過圖3及表6分析可知,在Wine數(shù)據(jù)集上,取其中4個(gè)前提屬性能獲得100%的分類準(zhǔn)確率,相比于取13個(gè)前提屬性規(guī)則條數(shù)由上萬條減少為幾十條,且分類準(zhǔn)確率得到提高;通過實(shí)驗(yàn)可知,針對Wine數(shù)據(jù)集前提屬性個(gè)數(shù)在4~6,系統(tǒng)能夠獲得較好的分類效果。
為了進(jìn)一步說明本文方法的有效性,將本文方法與DEBRM分類方法解決Wine數(shù)據(jù)集分類問題時(shí)構(gòu)建的分類系統(tǒng)的復(fù)雜度和準(zhǔn)確率進(jìn)行對比,如表7所示。
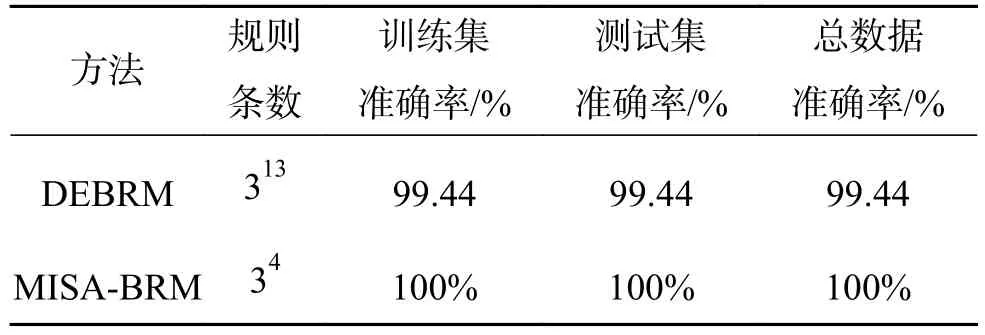
表7 Wine數(shù)據(jù)集結(jié)構(gòu)復(fù)雜度和分類準(zhǔn)確率對比Table 7 Comparison of the structural complexity and classification accuracy with respect to the Wine dataset
通過表7分析可知,相比于Liu等提出的DEBRM分類系統(tǒng),基于MISA多目標(biāo)優(yōu)化的置信規(guī)則庫分類系統(tǒng)的規(guī)則數(shù)量由約簡到,約簡了1 594 242條,不僅極大降低了系統(tǒng)復(fù)雜度,且系統(tǒng)分類準(zhǔn)確率達(dá)到了100%。可見,系統(tǒng)分類準(zhǔn)確率與系統(tǒng)復(fù)雜性并不呈正比關(guān)系,有時(shí)規(guī)則越多,推理準(zhǔn)確率反而越低。
3.3.3 Cancer數(shù)據(jù)集實(shí)驗(yàn)分析
Cancer數(shù)據(jù)集總的數(shù)據(jù)量較大,同樣各類別數(shù)據(jù)分布較不均勻。本文方法用于解決Cancer數(shù)據(jù)集的Pareto最優(yōu)曲線,如圖4所示。對Cancer訓(xùn)練數(shù)據(jù)集、測試數(shù)據(jù)集及整個(gè)數(shù)據(jù)集上的分類準(zhǔn)確率如表8所示。

圖4 Cancer數(shù)據(jù)集的Pareto最優(yōu)曲線Fig. 4 The Pareto optimal curve of the entire Cancer dataset

表8 Cancer數(shù)據(jù)集上MISA-BRM Pareto 最優(yōu)解集Table 8 The Pareto optimal solution set of MISA-BRM using the Cancer dataset
通過圖4和表8分析可知,Cancer數(shù)據(jù)集上取4~5個(gè)前提屬性時(shí)在訓(xùn)練數(shù)據(jù)集上的分類準(zhǔn)確率相差0.81%,測試數(shù)據(jù)集的分類效果相同。可知,針對Cancer 數(shù)據(jù)集,該模型在保證系統(tǒng)復(fù)雜度盡可能低的情況下,還能有效保證系統(tǒng)的分類準(zhǔn)確。
為了進(jìn)一步說明本方法的有效性,將本文方法與BRBCS、DEBRM分類方法解決Cancer 數(shù)據(jù)集分類問題時(shí)構(gòu)建的分類系統(tǒng)的復(fù)雜度和準(zhǔn)確率進(jìn)行對比,如表9所示。
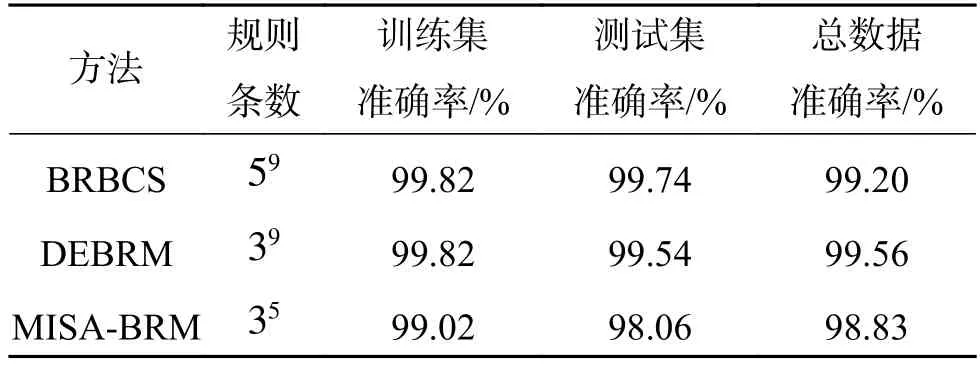
表9 Cancer數(shù)據(jù)集結(jié)構(gòu)復(fù)雜度和分類準(zhǔn)確率對比Table 9 Comparison of the structural complexity and classification accuracy with respect to the Cancer dataset
通過表9分析可知,相比于BRBCS、DEBRM,在Cancer總數(shù)據(jù)集上,MISA-BRM分類方法的準(zhǔn)確率分別降低0.37%、0.73%。但系統(tǒng)的規(guī)則條數(shù)則約簡了上萬條。因此,當(dāng)對系統(tǒng)復(fù)雜度要求較高時(shí),MISA-BRM在準(zhǔn)確率和復(fù)雜度兩個(gè)標(biāo)準(zhǔn)的均衡下有較好的效果。
3.3.4 Glass數(shù)據(jù)集實(shí)驗(yàn)分析
Glass數(shù)據(jù)集有6個(gè)類別,各類別數(shù)據(jù)分布不均勻,且有的類別的數(shù)據(jù)量占總的數(shù)據(jù)量的比率小。本文方法用于解決Glass數(shù)據(jù)集的Pareto最優(yōu)曲線,如圖5所示。
對Glass的訓(xùn)練數(shù)據(jù)集、測試數(shù)據(jù)集及整個(gè)數(shù)據(jù)集上的分類準(zhǔn)確率如表10所示。

圖5 Glass數(shù)據(jù)集的Pareto最優(yōu)曲線Fig. 5 The Pareto optimal curve of the entire Glass dataset
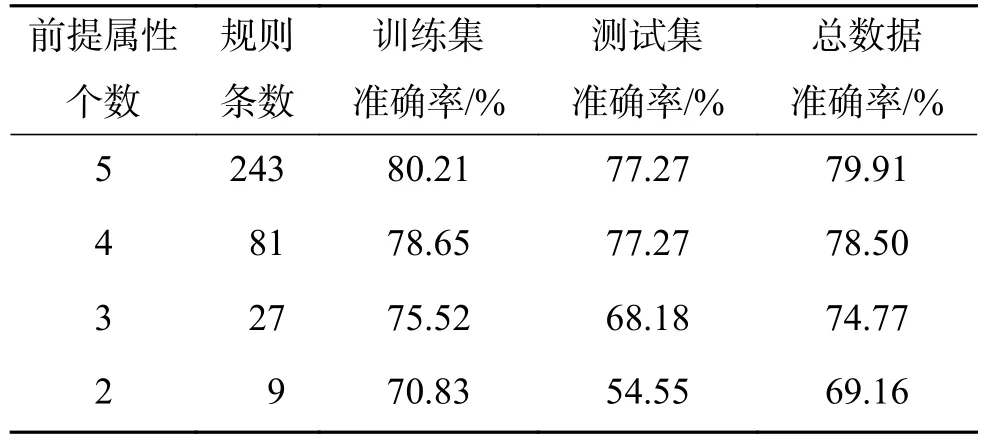
表10 Glass數(shù)據(jù)集MISA-BRM的Pareto最優(yōu)解集Table 10 The Pareto optimal solution set of MISA-BRMwith respect to the Glass dataset
將本文方法與BRBCS、DEBRM分類方法解決Glass 數(shù)據(jù)集分類問題時(shí)構(gòu)建的分類系統(tǒng)的復(fù)雜度和準(zhǔn)確率進(jìn)行對比,如表11所示。
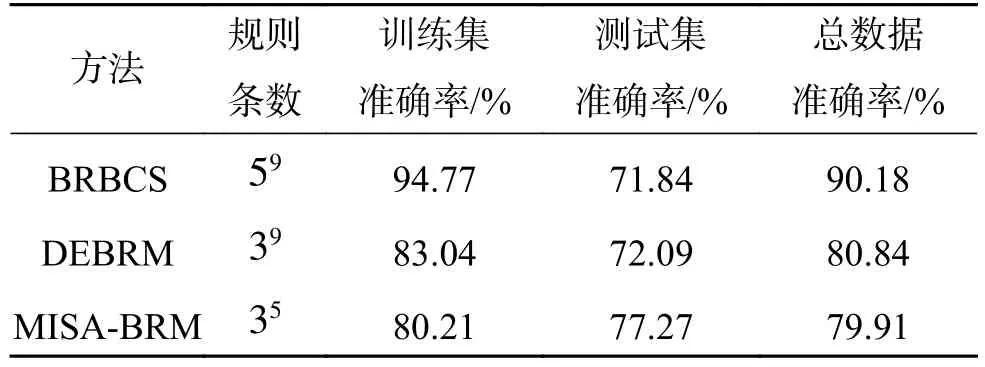
表11 Glass數(shù)據(jù)集結(jié)構(gòu)復(fù)雜度和分類準(zhǔn)確率對比Table 11 Comparison of the structural complexity and classification accuracy with respect to the Glass dataset
分析表10和表11可知:本文方法在前提屬性個(gè)數(shù)為4個(gè)或5個(gè)時(shí)系統(tǒng)能夠獲得較好的分類效果;本文方法在Glass數(shù)據(jù)集上的分類準(zhǔn)確率比BRBCS和DEBRM分別降低了14.56%、2.83%,但規(guī)則條數(shù)分別減少了1 952 882條、19 440條,雖然犧牲了一定的分類準(zhǔn)確率,但規(guī)則數(shù)極大降低。對于Glass測試數(shù)據(jù)集不僅極大約簡了規(guī)則條數(shù)且分類準(zhǔn)確率得到提高。
綜上,通過Iris數(shù)據(jù)集、Wine數(shù)據(jù)集、Cancer數(shù)據(jù)集、Glass數(shù)據(jù)集的實(shí)驗(yàn)結(jié)果分析可知:本文采用屬性約簡思想、差分參數(shù)訓(xùn)練方法,并結(jié)合改進(jìn)型MISA算法對置信規(guī)則庫分類系統(tǒng)的復(fù)雜度和準(zhǔn)確度進(jìn)行多目標(biāo)優(yōu)化是有效可行的。
3.4 與其他分類方法的準(zhǔn)確率比較
為了進(jìn)一步說明本文方法的有效性,本節(jié)對比了MISA-BRM與現(xiàn)有其他分類方法[14]用于解決Iris數(shù)據(jù)集、Cancer數(shù)據(jù)集、Wine數(shù)據(jù)集、Glass數(shù)據(jù)集分類問題時(shí)的準(zhǔn)確率,詳見表12和表13。
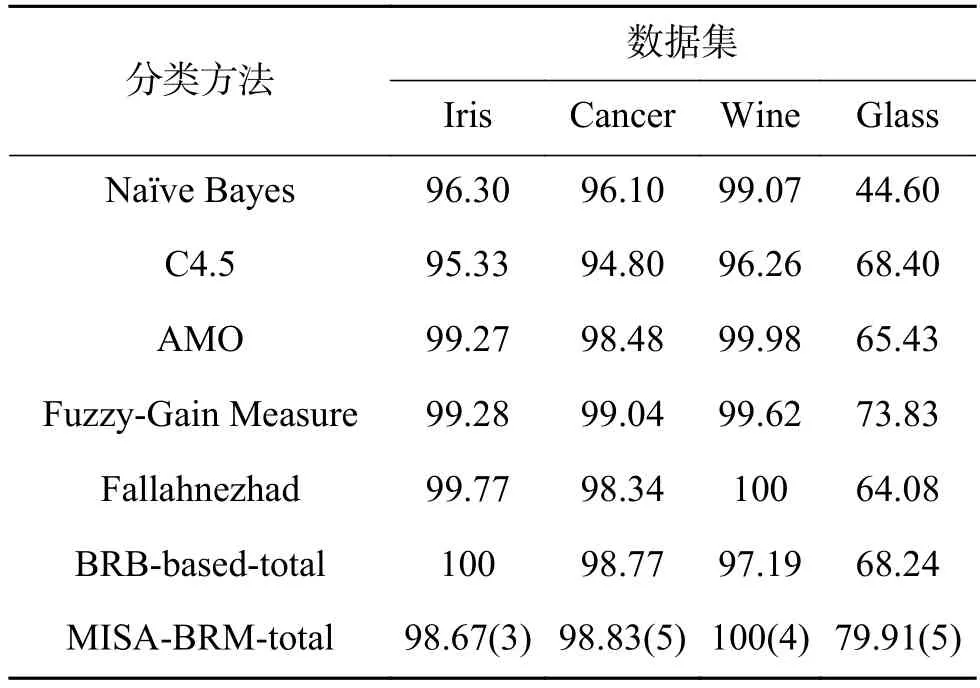
表12 MISA-BRB和其他分類方法的比較Table 12 Comparison with other classification methods%
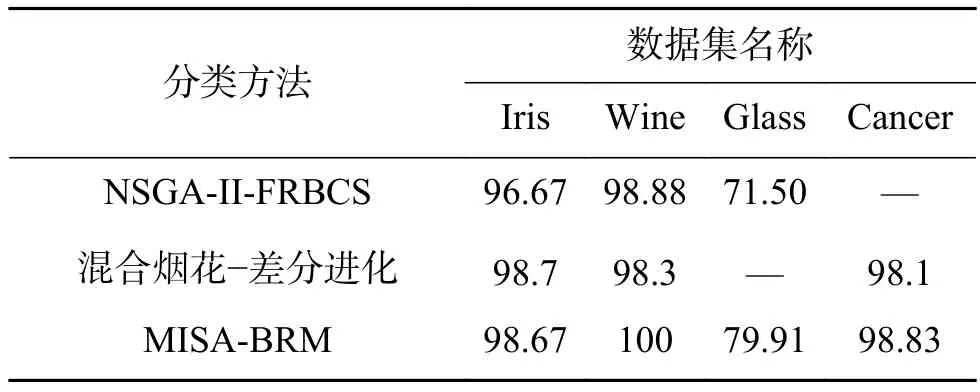
表13 MISA-BRB和其他建模方法的比較Table 13 Comparison with other modeling methods %
對比表12中數(shù)據(jù),MISA-BRB分類方法在Iris數(shù)據(jù)集上準(zhǔn)確率比Na?ve Beyes、C4.5方法高,在Cancer數(shù)據(jù)集上準(zhǔn)確率僅比Fuzzy-Gain Measure方法低;在Wine數(shù)據(jù)集上,得到100%的最好結(jié)果;在Glass數(shù)據(jù)集上,相比于其他6中分類方法,MISA-BRB的準(zhǔn)確率最高。
在表13中,NSGA-II-FRBCS[15]分類方法、基于Pareto混合煙花-差分進(jìn)化算法[16](表中稱混合煙花-差分進(jìn)化)都是以準(zhǔn)確率、解釋性為目標(biāo),進(jìn)行多目標(biāo)優(yōu)化的模糊規(guī)則庫分類方法。從表13可得,針對Iris數(shù)據(jù)集、Wine數(shù)據(jù)集和Glass數(shù)據(jù)集,利用MISA多目標(biāo)優(yōu)化的置信規(guī)則庫分類方法比NSGA-II-FRBCS準(zhǔn)確率更高;利用MISA多目標(biāo)優(yōu)化的置信規(guī)則庫分類方法和基于Pareto混合煙花-差分進(jìn)化算法相比,在Cancer數(shù)據(jù)集上準(zhǔn)確率略高,在Wine數(shù)據(jù)集上準(zhǔn)確率較高。
4 結(jié)束語
本文首次針對提高置信規(guī)則庫分類系統(tǒng)準(zhǔn)確率和降低系統(tǒng)復(fù)雜度的多目標(biāo)優(yōu)化問題進(jìn)行建模。算法采用基于特征屬性序列編碼的方法進(jìn)行特征搜索,使得在規(guī)則數(shù)量減少的情況下盡可能提高分類準(zhǔn)確率。此外,對經(jīng)典的MISA算法進(jìn)行改進(jìn),加入基于Pareto支配關(guān)系的個(gè)體疫苗提取和接種疫苗操作,提出MISA-BRM模型。實(shí)驗(yàn)結(jié)果表明,該算法能尋找到一組具有不同準(zhǔn)確率和復(fù)雜度的Pareto最優(yōu)解集,方便決策者根據(jù)實(shí)際需要進(jìn)行選擇。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:26:14
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
幸福(2018年33期)2018-12-05 05:22:42
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
Coco薇(2017年11期)2018-01-03 20:59:57
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
暨南學(xué)報(bào)(哲學(xué)社會(huì)科學(xué)版)(2016年9期)2017-01-15 13:52:02
