公理化模糊共享近鄰自適應譜聚類算法
2019-11-09 03:41:58儲德潤周治平
智能系統學報 2019年5期
關鍵詞:方法
儲德潤,周治平
(江南大學 物聯網技術應用教育部工程研究中心,江蘇 無錫 214122)
聚類技術作為機器學習領域中的一種無監督技術,在檢測數據的內在結構和潛在知識方面發揮著重要的作用。在過去的幾十年中,許多聚類方法得到了發展,如基于分區的方法(k-means)、基于模型的方法、基于密度的方法、層次聚類方法、模糊聚類方法(fuzzy c-means)和基于圖的方法(spectral clustering)[1]。由于譜聚類在處理非凸形結構的數據集方面的高效性,譜聚類在圖像分割[2-4]、社區檢測[5]、人臉識別[6]等方面得到了廣泛的研究和應用。
然而,傳統的譜聚類算法在使用高斯核函數構造親和矩陣時,需要先驗信息來設置合適的參數以控制鄰域的尺度;并且以距離來度量數據點之間的相似性,沒有考慮到整體數據點的變化情況,對于高維數據來說,較難得到更高的聚類精度。近年來有很多學者對譜聚類算法進行了研究。趙曉曉等[7]結合稀疏表示和約束傳遞,提出一種結合稀疏表示和約束傳遞的半監督譜聚類算法,進一步提高了聚類準確率。林大華等[8]針對現有子空間聚類算法沒有利用樣本自表達和稀疏相似度矩陣,提出了一種新的稀疏樣本自表達子空間聚類方法,所獲得的相似度矩陣具有良好的子空間結構和魯棒性。Chang等[9]提出了一種通過嵌入標簽傳播來改進譜聚類的方法,通過密集的未標記數據區域傳播標簽。以上方法雖然一定程度上提高了譜聚類算法的聚類性能,但是,在大部分譜聚類算法中,高斯核函數中尺度參數的選取往往都是通過人工選取,對聚類結果有一定的影響。NJW算法[10]對預先給定幾個尺度參數進行譜聚類,最后從這幾個聚類結果中選擇具有最佳聚類結果的作為尺度參數,該方法消除了尺度參數選擇的人為因素,但是也增加了計算時間。Ye等[11]在有向KNN圖中考慮了一種基于共享最近鄰的魯棒相似性度量,大大提高了譜聚類的聚類精度。Jia等[12]提出了一種基于共享近鄰的自校正p譜聚類算法,該算法利用共享最近鄰來度量數據間的相似性,然后應用果蠅優化算法找到p-laplacian矩陣的最優參數p,從而更好地進行數據分類。王雅琳等[13]提出一種基于密度調整的改進自適應譜聚類算法,通過樣本點的近鄰距離自適應得到尺度參數,使算法對尺度參數相對不敏感。
傳統的譜聚類以及上述大部分改進的譜聚類算法都是單一的針對距離度量或者尺度參數進行調整,本文從一個新的角度出發,在公理化模糊集(AFS)理論的基礎上,結合局部密度估計和共享近鄰的定義,提出一種基于AFS理論的共享近鄰自適應譜聚類算法——公理化模糊共享近鄰自適應譜聚類算法。利用AFS理論提出了一種模糊相似性度量方法,并將其作為譜聚類算法輸入的親和矩陣。同時采用共享近鄰的方法發現密集區域樣本點分布的結構和密度信息,并且根據每個點所處領域的稠密程度自適應調節參數,與高斯核距離測度相比,本文的解決方案對參數具有較強的魯棒性,增強了對各種數據集的適應性,減少了噪聲數據帶來的不良影響。
1 相關算法理論
1.1 譜聚類算法
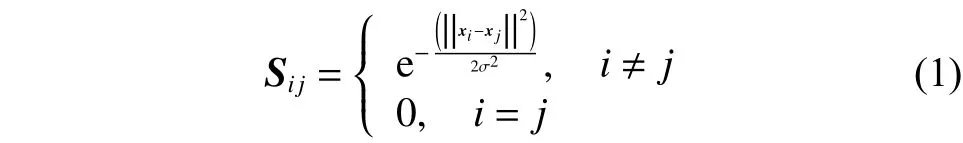
作為一種簡單而有效的聚類準則,歸一化割(Ncut)在文獻[14]中提出,其定義為
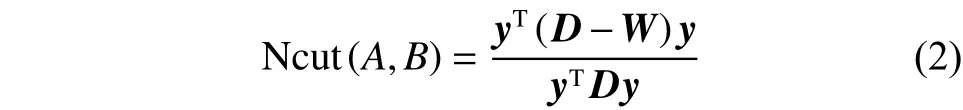

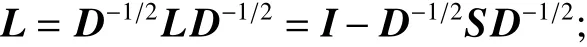
5)利用經典的聚類算法如k-means對特征向量空間中的特征向量進行聚類。
1.2 AFS理論
AFS理論是劉曉東[15-18]在1998年提出的一種基于AFS代數和AFS結構的模糊理論,AFS理論放棄使用距離度量來計算數據之間的相似性關系,而是將觀測數據轉化為模糊隸屬函數,并實現其邏輯運算。然后,可以從AFS空間而不是原始特征空間中提取信息。在AFS空間中利用模糊關系來構建數據之間的相似性度量。采用模糊隸屬度來表示數據之間的距離關系,增強了在處理現實數據中對各種數據集的適應性,為處理離群點提供了有效方法。
在文獻[15]中,根據EI代數的定義,對于任意概念集合,表示A中模糊概念的集合,為了更好地提取數據結構,清楚地說明可將AFS理論結合以下場景:
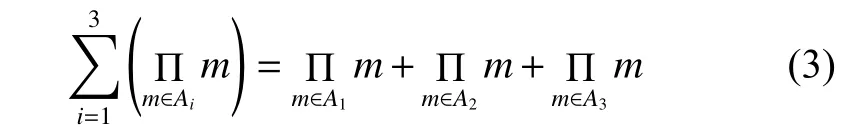
這些基于簡單概念的EI代數運算生成的概念被認為復雜的概念。

其中,每個模糊集可以被唯一地分解:
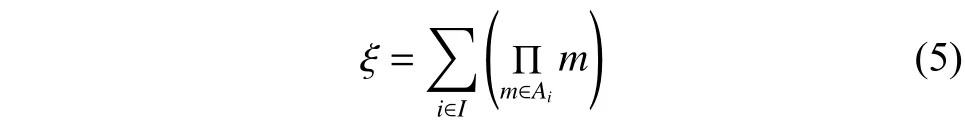
2 所提算法
2.1 在模糊空間建立距離度量
本文提出的親和矩陣構造方法是建立在AFS理論基礎上的,該過程允許我們在發現的判別模糊子空間中表示不同模糊項的樣本。這些子空間由模糊隸屬函數選擇,消除了不明顯或噪聲特征。因此,它們被認為能夠改善內部相似和減少相互相似。此外,利用AFS中定義的模糊隸屬度和邏輯運算,放寬了歐氏假設對數據距離推斷的影響。更具體地說,本文使用一個樣本的隸屬度屬于另一個樣本的描述,用模糊集表示為距離度量。在最初的AFS聚類[19-21]基礎上,在AFS空間上構建相似性度量。
首先建立隸屬度函數,需要定義以下有序關系:設X是一個樣本集合,M是X上的一組模糊集合。對于任意,,可以寫成:
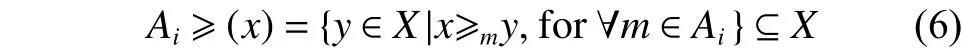
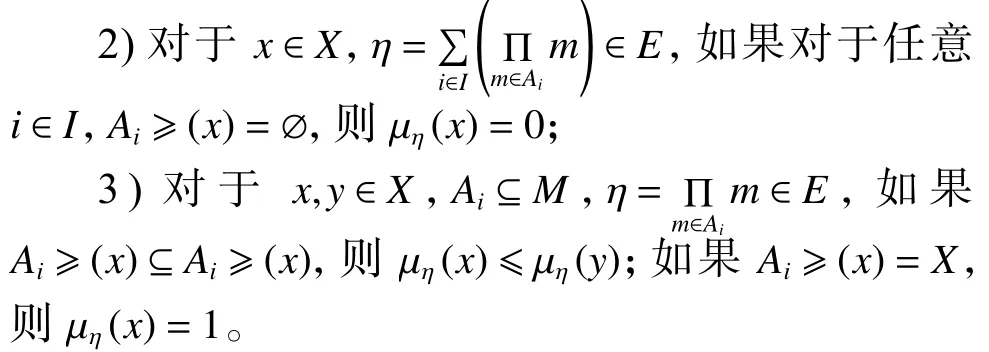
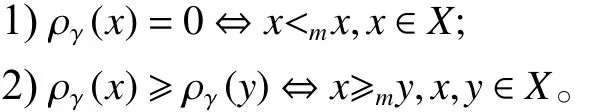
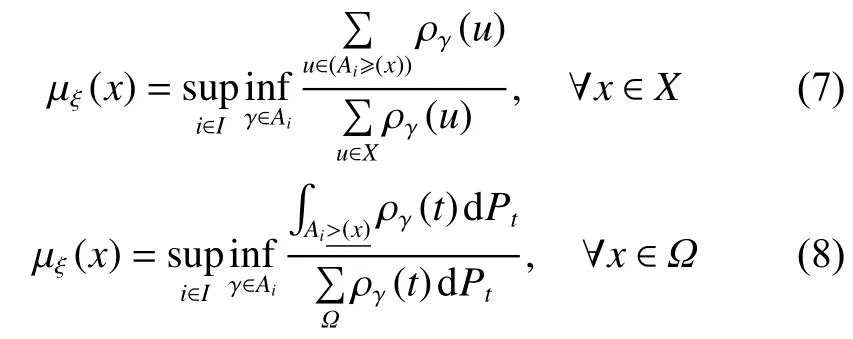
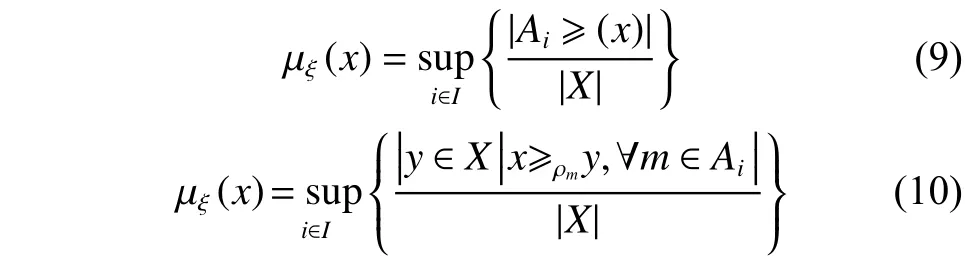
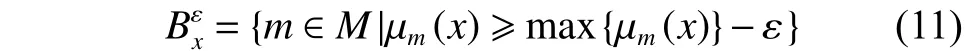
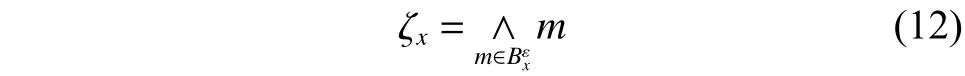
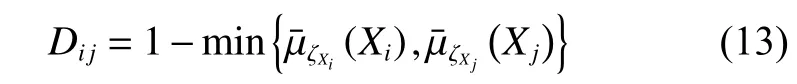
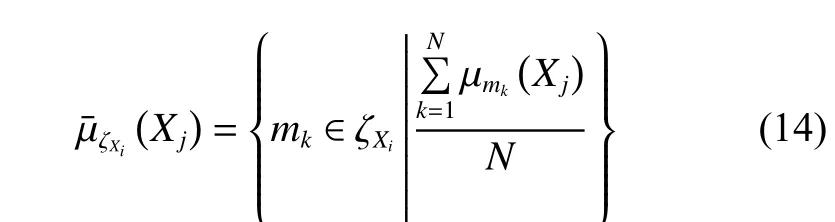
在AFS理論的基礎上,為了更好地提取數據結構,在AFS空間中建立了距離測量,公式為
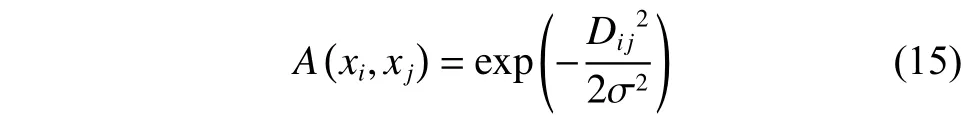
2.2 所提算法
在2.1小節中雖然利用AFS理論在譜聚類算法中構建了新的距離度量,即,但是高斯核函數中是一個人工指定的參數,為每個數據集指定一個合適的參數是一件很復雜的事,需要花費大量的時間和精力。本文將數據點的領域信息加入相似度的計算中,并結合共享近鄰的思想,在AFS理論距離測量的基礎上定義了一個能夠自適應得到尺度參數的高斯核函數——基于AFS理論的共享近鄰自適應高斯核函數,其定義為

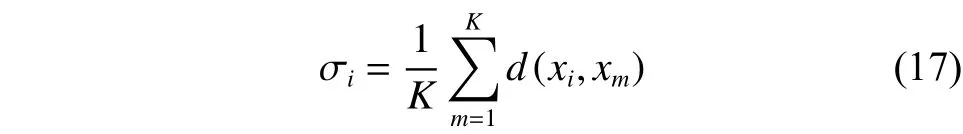
2.3 所提算法流程
算法 公理化模糊共享近鄰自適應譜聚類算法(AFSSNNSC)
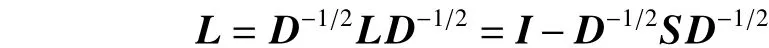
11)利用經典的聚類算法如k-means對特征向量空間中的特征向量進行聚類。
3 實驗與結果分析
3.1 實驗環境及性能指標
在UCI、USPS手寫數字的相同數據集上,采用本文提出的方法和文獻[10]的NJW譜聚類(SC)、文獻[21]的AFS聚類算法(AFS)、文獻[22]的self-tuning spectral clustering(STSC)算法、基于K均值的近似譜聚類(KASP)[23]、基于Nystrom近似譜聚類(Nystrom)[24]和基于地標點譜聚類算法(LSC-R,LSC-K)[25]進行對比實驗。本文算法實驗是在MATLAB 2014b,計算機的硬件配置為Intel i7-4770 CPU 3.40 GHz、16 GB RAM的平臺下進行。為了評估所提算法的聚類性能,本文使用聚類誤差(CE)[26]和歸一化互信息(NMI)[27]2種性能指標對本文算法與其他聚類方法的聚類結果進行了比較。其中CE被廣泛用于評價聚類性能,CE越低聚類性能越好。NMI也是一種廣泛使用的評估算法聚類性能的測量標準,NMI越大性能越好。
3.2 UCI數據集實驗結果與分析
為了驗證所提出算法的有效性,本文將所提的算法和其他方法應用于UCI數據庫中的11個基準數據集作為測試樣本,表1為這11類數據集的特征,分別是數據總量、維數以及類的個數。
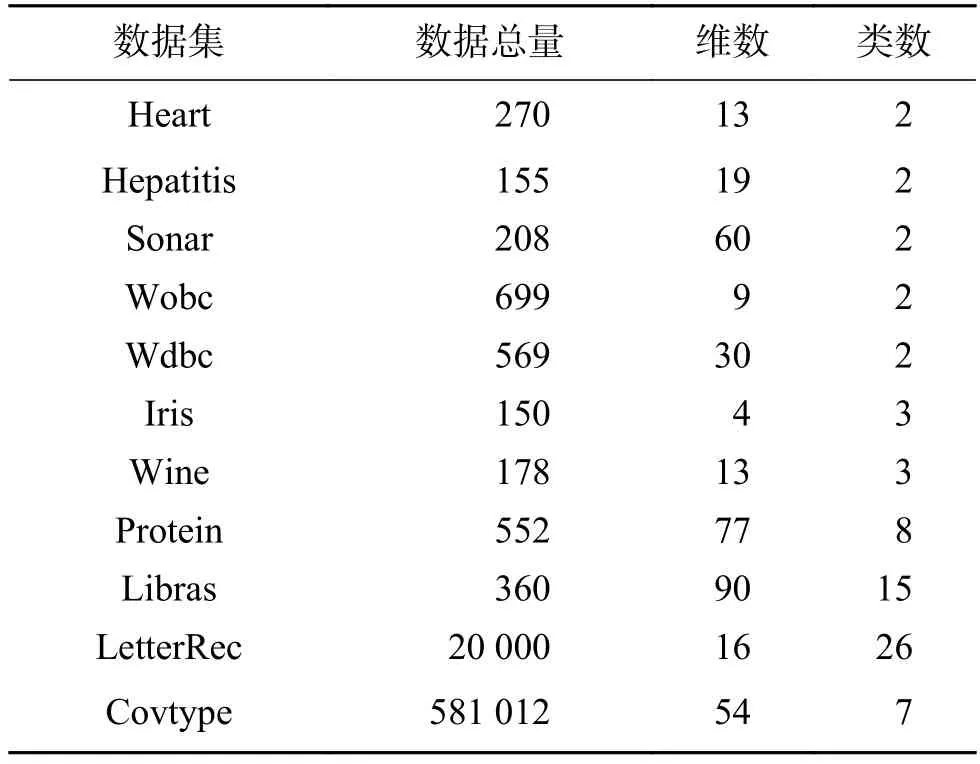
表1 UCI實驗數據集的特性Table 1 Characteristics of the UCI experimental datasets
基于聚類誤差(CE)的實驗結果如表2所示,由表2可知所提的方法在大部分實驗數據集上均獲得了優于對比算法的CE值;所提出的方法在Heart、Hepatitis、Wdbc、Protein 和 Libras數據集上的CE分別為15.27%、27.14%、6.03%、51.12%、52.31%,相比較AFS算法而言均改進了10%以上,在其他5個數據集上的CE相比較AFS也均有所提高。證明了利用譜理論對相似矩陣進行劃分比之前提出的傳遞閉包理論好得多,考慮到傳遞閉包方法的驗證循環,所提出的方法也相對更快、更容易實現。在Iris、Wine數據集中,所提算法的CE分別為7.42%和2.89%,相對聚類錯誤率略高于STSC算法。因為這兩個數據集中只有150個樣本和178個樣本,但是差異實際上只有一兩個樣本,但相對于總體而言,所提算法CE普遍低于其他算法在各數據集上的結果,仍具有較好的優越性;與基于距離度量的方法相比所提算法在給出的所有數據集中都顯示出了優越性,在Sonar數據集上更加改進5%以上,本文算法與基于Nystrom近似譜聚類方法相比在所有數據集上均有1%以上的優勢。本文算法與基于地標點的譜聚類方法LSC-R和LSC-K相比也展現出較好的聚類性能。這是因為通過模糊隸屬函數代替距離度量數據之間的相似性,利用模糊語義結構解釋數據之間的復雜的相互關系,增強了算法的魯棒性。對于Protein、Libras等多聚類數據集,AFS的聚類錯誤率偏高,因為AFS聚類需要根據每個集群的邊界選擇最好的數據聚類分區。隨著集群規模數量的不斷增加,將很難去清晰地找到邊界,這樣聚類誤差也會隨之增高。總體而言,與對比文獻方法相比,所提算法的CE值在所有實驗數據集上均得到了改善,降低了算法的聚類錯誤率。
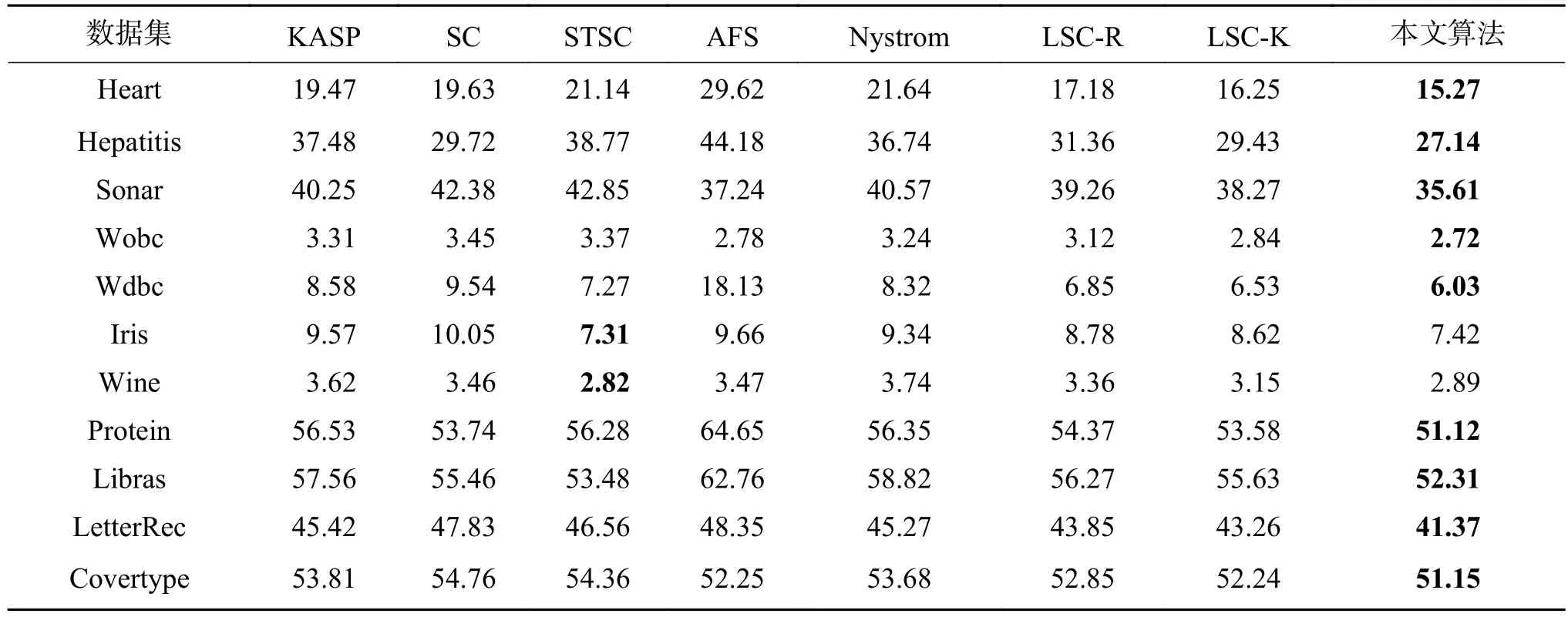
表2 UCI數據集上的CE比較Table 2 Comparison of CE on the UCI datasets %
在歸一化互信息(NMI)中測量的聚類性能如表3所示。所提出的算法的聚類結果NMI與其他方法的NMI相比都得到了改善,尤其在Heart和Protein數據集上,所提算法相對于KASP、SC、STSC、AFS和Nystrom對比算法而言NMI均提高了5%以上。只是在Wine數據集上,所提算法的NMI為87.86%,與其他算法相當,但在整個對比表格中為最好的聚類性能。由于所選Covertype數據集是一個從地圖變量預測森林覆蓋類型的數據集,它們都主要是在荒野地區發現的,所以覆蓋類型在實際地理上是非常接近的,相對于其他數據集而言,這個數據集數據特性更加復雜。所以在Covertype數據集下所有算法的NMI都普遍較低,但是所提算法獲得了比其他算法更好的聚類效果。
從實驗結果可以看出,STSC不是很穩定,它在Hepatitis和Sonar數據集上的NMI情況都非常差,由于在STSC和本文算法中都考慮到了數據之間的相互關系,利用到了數據鄰居的近鄰作用,所以可以從中得出結論,與考慮到數據樣本關系之間的傳統距離度量作為相似性度量相比,采用具有數據樣本模糊關系的模糊隸屬度作為距離度量,在相似性度量上更具有魯棒性。總體而言,所提算法相較于對比算法都具有明顯的改善。
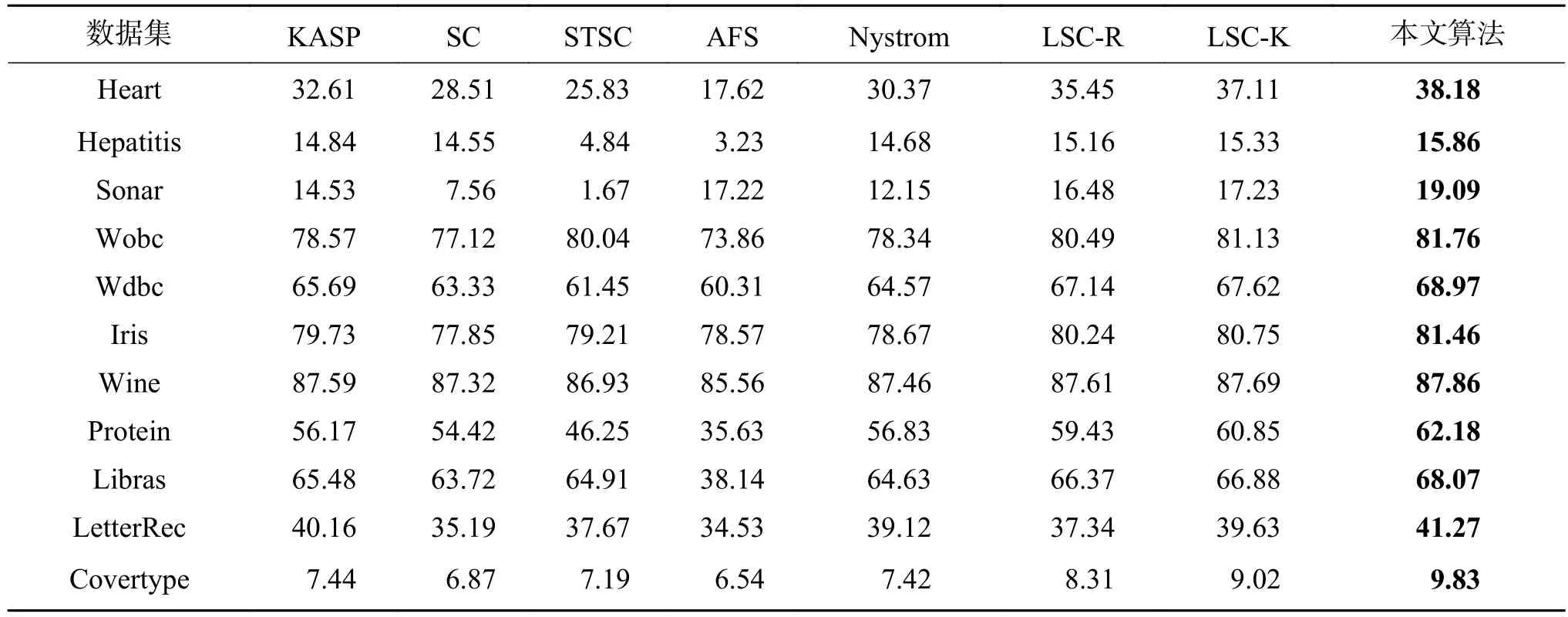
表3 UCI數據集上的NMI比較Table 3 Comparison of NMI on the UCI datasets %
3.3 USPS數據集實驗結果與分析
選擇兩個典型譜聚類算法SC和STSC與所提方法在廣泛使用的USPS數據庫中的手寫數字數據集進行對比實驗。該數據集包含美國郵政總局通過掃描信封中的手寫數字獲得的數字數據。原始掃描的數字是二進制的,大小和方向不同。本文使用的圖像經過了大小歸一化,得到了1 616張256維的灰度圖像。它包含7 291個訓練實例和2 007個測試實例(總共9 298個)。為了展示該方法的可伸縮性,考慮了不同數量的集群。具體來說,數字子集{0,8}、{4,9}、{0,5,8}、{3,5,8}、{1,2,3,4}、{0,2,4,6,7}和整個集合{0,1,···,9}用于測試本文提出的算法。這些子集的詳細信息如表4所示。分別在每個子集上進行實驗,并使用CE和NMI來測量性能。

表4 USPS實驗數據集的特性Table 4 Characteristics of the USPS experimental datasets
從圖1可以看出,在CE方面,所提算法在所有的情況下都優于STSC和SC,尤其在{0,8}、{0,5,8}、{3,5,8}、{0,2,4,6,7}、{0,1,···,9}數據集上CE均改善了5%以上,甚至在{3,5,8}上CE相較于其他對比算法,所提算法改進了10%以上。總體而言與SC和STSC相比,可以從圖1中看出所提出的方法均得到明顯的改善。

圖1 USPS數據集上CE的性能比較Fig. 1 Performance comparison of CE on the USPS datasets
圖2 顯示了基于NMI的USPS數據集的結果。從圖2中可以看出,所提出的方法在所有情況下都比SC和STSC有優勢。在{0,8}、{1,2,3,4}、{0,1,···,9}上相較于其他對比算法,所提算法的NMI都提高了10%以上,特別是對于具有挑戰性的情況{3,5,8}和多類情況{1,2,3,4}、{0,2,4,6,7}、{0,1,···,9},所提出的算法都具有一定的優越性。
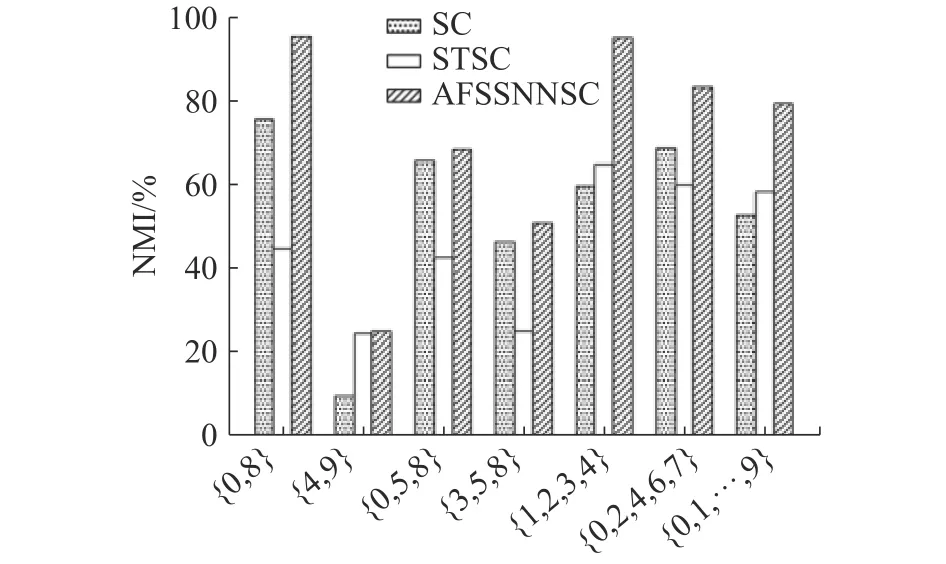
圖2 USPS數據集上NMI的性能比較Fig. 2 Performance comparison of NMI on the USPS datasets
4 結束語
本文提出了一種新的無監督廣義數據親和圖的構造方法,該方法具有更強的魯棒性和更有意義的數據親和圖,以提高譜聚類精度。采用模糊理論定義數據相似度,利用模糊隸屬度函數導出親和圖。此外,親和圖不是盲目地相信所有可用變量,而是通過捕捉和通過對每個樣本的模糊描述,確定了特征子空間中組合分布的微妙兩兩相似關系。同時采用共享近鄰的方法發現密集區域樣本點分布的結構和密度信息,并且根據每個點所處領域的稠密程度自動調節參數,從而生成更強大的親和矩陣,進一步提高聚類準確率,證明了該方法對不同類型數據集的有效性。實驗結果表明,該方法與其他先進的方法相比具有一定的優越性。數據大小的多樣性在一定程度上體現了該方法對于大數據集的可擴展性。在未來將通過系統地將所提出的算法與一些采樣或量化策略相結合來處理一般的可伸縮性問題。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
