網(wǎng)絡(luò)拓?fù)涮卣鞯牟黄胶鈹?shù)據(jù)分類
2019-11-09 03:41:54普事業(yè)劉三陽白藝光
智能系統(tǒng)學(xué)報(bào) 2019年5期
普事業(yè),劉三陽,白藝光
(西安電子科技大學(xué) 數(shù)學(xué)與統(tǒng)計(jì)學(xué)院,陜西 西安 710126)
在數(shù)據(jù)分類的研究中,普遍存在類別分布不平衡[1]的問題,即某一類別的樣本數(shù)量遠(yuǎn)遠(yuǎn)多于另一類(分別稱為多數(shù)類和少數(shù)類),具有這樣特征的數(shù)據(jù)集視為不平衡。傳統(tǒng)的分類算法,如支持向量機(jī)(SVM)在處理不平衡數(shù)據(jù)時(shí),分類超平面往往會(huì)向少數(shù)類偏移,導(dǎo)致對少數(shù)類的識(shí)別率降低,而隨機(jī)森林(random forest,RF[2])分類時(shí)易出現(xiàn)分類不佳、泛化誤差變大等問題。針對支持向量機(jī)在訓(xùn)練樣本點(diǎn)過程中存在的噪聲和野點(diǎn)問題,不少研究學(xué)者提出了相應(yīng)的改進(jìn)算法。如臺(tái)灣學(xué)者Lin等[3]提出模糊支持向量機(jī)(fuzzy sup-port vector machines,F(xiàn)SVM),根據(jù)不同數(shù)據(jù)樣本對分類的貢獻(xiàn)不同,賦予不同的隸屬度,將噪聲和野點(diǎn)與有效樣本區(qū)分開,然而實(shí)際數(shù)據(jù)集中除了存在噪聲和野點(diǎn),不同類別的樣本個(gè)數(shù)差異也會(huì)影響算法的分類精度。目前對不平衡數(shù)據(jù)分類的研究主要集中在算法層面和數(shù)據(jù)層面的改進(jìn),如通過對不平衡數(shù)據(jù)集進(jìn)行欠采樣(under-sampling[4])、過采樣(SMOTE[5])、不同懲罰因子的方法(different error costs,DEC[6])和集成學(xué)習(xí)方法[7]等,這些方法在處理不平衡數(shù)據(jù)時(shí)一定程度上提高了少數(shù)類的分類精度,然而欠采樣在刪除樣本點(diǎn)時(shí)易造成重要信息的丟失,過采樣又會(huì)帶來信息的冗余,并增大算法時(shí)間復(fù)雜度,代價(jià)敏感學(xué)習(xí)算法雖然定義了正負(fù)類不同的懲罰因子,但卻沒有考慮到樣本點(diǎn)的實(shí)際分布情況,這些問題又會(huì)直接影響算法的分類效果。傳統(tǒng)的分類方法在構(gòu)建分類模型時(shí)僅考慮了數(shù)據(jù)樣本點(diǎn)的物理特征(如距離、相似度等),并沒有更深層次地挖掘數(shù)據(jù)點(diǎn)之間的關(guān)聯(lián)特征,但實(shí)際應(yīng)用中的數(shù)據(jù)集樣本之間并不是孤立存在的,它們之間除了位置上的差異,關(guān)聯(lián)信息也是不可忽略的。
Silva等[8-9]將僅考慮樣本點(diǎn)物理特征的傳統(tǒng)分類方法視為低層次分類,把數(shù)據(jù)樣本點(diǎn)看作網(wǎng)絡(luò)節(jié)點(diǎn),提出了基于網(wǎng)絡(luò)信息特征的高層次數(shù)據(jù)分類方法,在訓(xùn)練樣本點(diǎn)分類模型時(shí)既考慮了樣本點(diǎn)的位置關(guān)系,又考慮到了數(shù)據(jù)點(diǎn)之間的拓?fù)涮卣鳎瑢蓚€(gè)層次的分類器有效地結(jié)合,并在數(shù)字圖像識(shí)別中取得較高的準(zhǔn)確度。Carnerio等[10]提出了基于復(fù)雜網(wǎng)絡(luò)的新型分類器,通過KNN法或KAOG[11]法建立子網(wǎng)絡(luò)模型,利用谷歌PageRank度量方法賦予網(wǎng)絡(luò)節(jié)點(diǎn)不同影響力概念,依據(jù)Spatio structural effi-ciency和節(jié)點(diǎn)間的距離特征實(shí)現(xiàn)分類。文獻(xiàn)[12]針對復(fù)雜網(wǎng)絡(luò)中的鏈路預(yù)測問題介紹了多種基于局部和全局結(jié)構(gòu)的節(jié)點(diǎn)相似度模型,分析出實(shí)際復(fù)雜系統(tǒng)中網(wǎng)絡(luò)節(jié)點(diǎn)的相互影響關(guān)系,兩個(gè)節(jié)點(diǎn)之間產(chǎn)生連邊的概率大小是由網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)和幾何結(jié)構(gòu)共同決定的。文獻(xiàn)[13]中把鏈路預(yù)測問題視為一個(gè)二分類問題,提出了一個(gè)數(shù)據(jù)分類問題的概率模型,將待測樣本點(diǎn)的類別歸屬于相似度分?jǐn)?shù)高的類。
鑒于高層次數(shù)據(jù)分類方法在無偏數(shù)據(jù)集上的優(yōu)越性,本文從數(shù)據(jù)樣本點(diǎn)的物理特征和拓?fù)涮卣鞣较虺霭l(fā),綜合考慮數(shù)據(jù)點(diǎn)之間的位置關(guān)系和關(guān)聯(lián)信息,提出基于網(wǎng)絡(luò)拓?fù)涮卣鞯牟黄胶鈹?shù)據(jù)分類方法(imbalanced data classification of network tolopogy characteristics,NT-IDC)。首先利用KNN法建立與每類數(shù)據(jù)點(diǎn)對應(yīng)的網(wǎng)絡(luò)結(jié)構(gòu),將數(shù)據(jù)樣本實(shí)例對應(yīng)網(wǎng)絡(luò)中的節(jié)點(diǎn),使具有相同類別的網(wǎng)絡(luò)節(jié)點(diǎn)之間產(chǎn)生連邊,并依據(jù)其連接特性計(jì)算出每個(gè)節(jié)點(diǎn)的局部效率作為拓?fù)湫畔ⅲ瑧?yīng)用基于距離倒數(shù)的相似度作為兩個(gè)節(jié)點(diǎn)產(chǎn)生連邊概率的物理特征,將拓?fù)涮卣髋c樣本點(diǎn)的物理特征一起作為判別測試點(diǎn)類別歸屬的依據(jù),為了克服由不同類別的數(shù)據(jù)樣本點(diǎn)個(gè)數(shù)差異帶來的影響,構(gòu)建了一種引入不平衡因子的新型概率模型。本文所建立的基于數(shù)據(jù)點(diǎn)物理特征和拓?fù)涮卣鞯姆诸惸P透臃蠈?shí)際數(shù)據(jù)集樣本點(diǎn)的分布情況,實(shí)驗(yàn)驗(yàn)證了本文所提方法具有可行性和有效性,與傳統(tǒng)的分類器模型有著一定的區(qū)別。
1 相關(guān)概念
基于網(wǎng)絡(luò)拓?fù)涮卣鞯牟黄胶鈹?shù)據(jù)分類算法包括兩個(gè)階段:網(wǎng)絡(luò)的構(gòu)建和測試點(diǎn)的類別預(yù)測。利用較為常見的KNN法對訓(xùn)練數(shù)據(jù)集中的每一個(gè)樣本點(diǎn),從其前個(gè)最近的鄰居節(jié)點(diǎn)中找到標(biāo)簽信息相同的節(jié)點(diǎn)并在兩點(diǎn)之間建立一條有向邊,每個(gè)數(shù)據(jù)樣本點(diǎn)與網(wǎng)絡(luò)中的節(jié)點(diǎn)對應(yīng),且節(jié)點(diǎn)與樣本點(diǎn)具有相同的標(biāo)簽類型,建立網(wǎng)絡(luò)鄰接矩陣A,這樣就將整個(gè)數(shù)據(jù)集映射成帶有節(jié)點(diǎn)標(biāo)簽信息的網(wǎng)絡(luò),是節(jié)點(diǎn)集合,E是邊的集合,L =是標(biāo)簽集合。在預(yù)測階段,利用文中構(gòu)建的分類模型去判斷測試數(shù)據(jù)樣本點(diǎn)Y =的標(biāo)簽類型,對于已經(jīng)判斷過標(biāo)簽類型的測試節(jié)點(diǎn),選擇直接丟棄的策略,不再歸合到由訓(xùn)練點(diǎn)所建立的子網(wǎng)絡(luò)結(jié)構(gòu)中,圖1為本文實(shí)現(xiàn)數(shù)據(jù)分類的幾個(gè)步驟的圖解,假設(shè)建立網(wǎng)絡(luò)中,最終將測試點(diǎn)歸為整體性測度大的類別。
1.1 節(jié)點(diǎn)局部效率
復(fù)雜網(wǎng)絡(luò)由圖論逐漸發(fā)展而來,基于圖論的網(wǎng)絡(luò)結(jié)構(gòu)模型在表達(dá)數(shù)據(jù)之間的關(guān)系時(shí)具有明顯的優(yōu)勢[14-16],本文所提出的方法在計(jì)算網(wǎng)絡(luò)節(jié)點(diǎn)局部效率時(shí)正是建立在圖論的基礎(chǔ)上。網(wǎng)絡(luò)中的節(jié)點(diǎn)可以既是起點(diǎn)又是尾點(diǎn),因此由數(shù)據(jù)樣本點(diǎn)的連接關(guān)系所建立的圖是有向的,為了更多地挖掘網(wǎng)絡(luò)中的數(shù)據(jù)點(diǎn)之間的拓?fù)潢P(guān)系,在數(shù)據(jù)樣本點(diǎn)訓(xùn)練階段,充分考慮每個(gè)節(jié)點(diǎn)的連接特性,賦予節(jié)點(diǎn)不同的效率,使節(jié)點(diǎn)之間具有差異性,本文計(jì)算網(wǎng)絡(luò)節(jié)點(diǎn)的局部效率公式[17]為
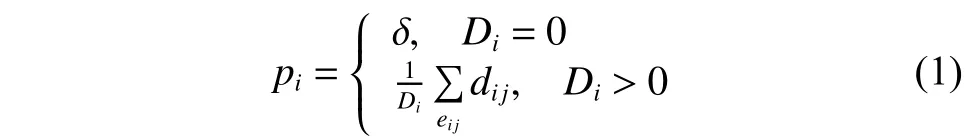
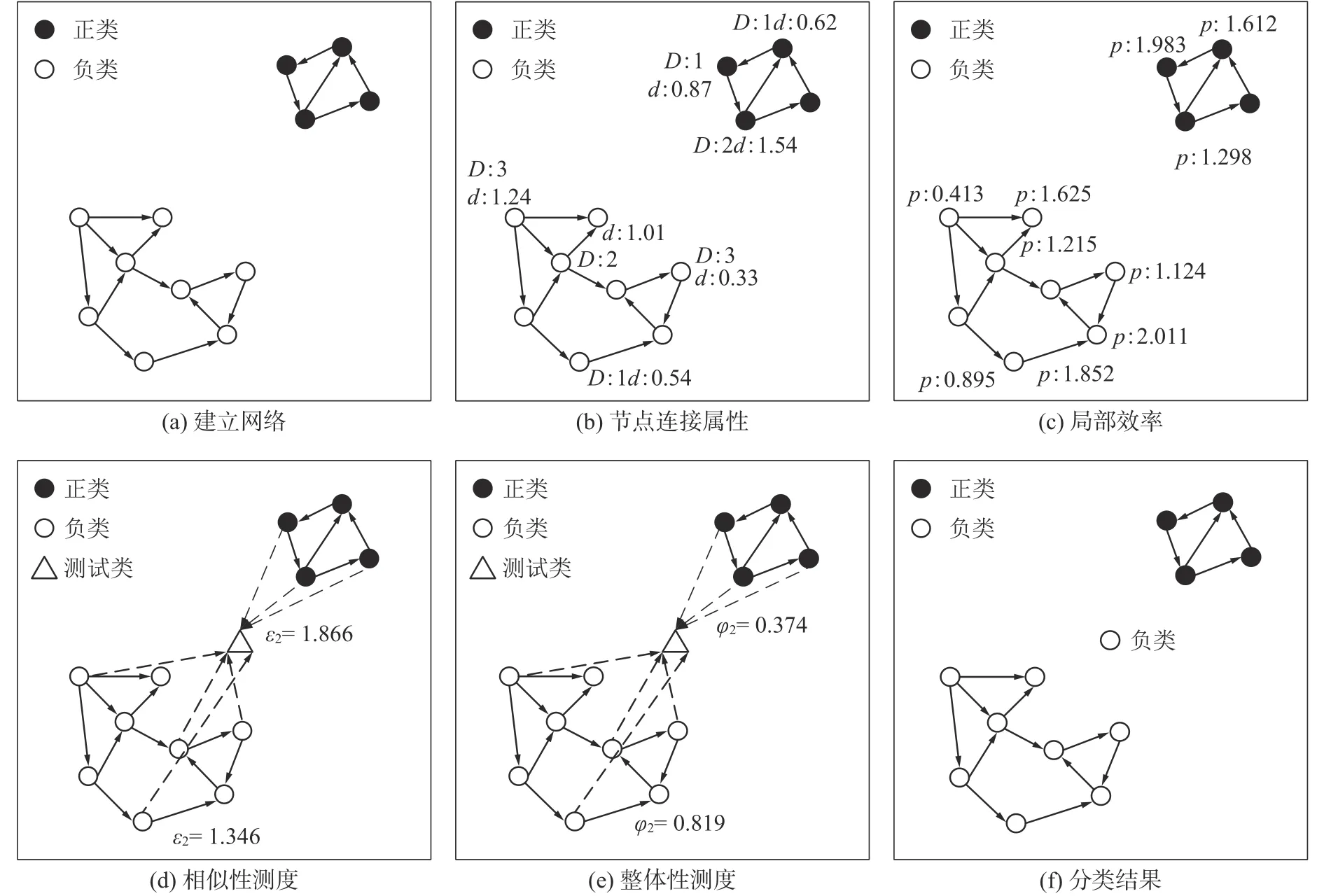
圖1 NT-IDC的圖解Fig. 1 The diagram of NT-IDC
1.2 基于相似度的類別歸屬
將數(shù)據(jù)樣本點(diǎn)映射成網(wǎng)絡(luò)節(jié)點(diǎn),則待測樣本點(diǎn)的類別歸屬與網(wǎng)絡(luò)中的每個(gè)節(jié)點(diǎn)都有關(guān)系,一般來說,距離越近的兩個(gè)節(jié)點(diǎn)屬于同類的可能性就越大。
基于這種思想,本文用距離倒數(shù)表示網(wǎng)絡(luò)節(jié)點(diǎn)之間的物理特征,則節(jié)點(diǎn)和之間的相似度可表示為
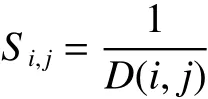
任給一個(gè)網(wǎng)絡(luò),未知標(biāo)簽信息的節(jié)點(diǎn)類別用0表示,對網(wǎng)絡(luò)中任意一對節(jié)點(diǎn)和,存在相應(yīng)的距離相似度,則無標(biāo)簽節(jié)點(diǎn)屬于的概率為
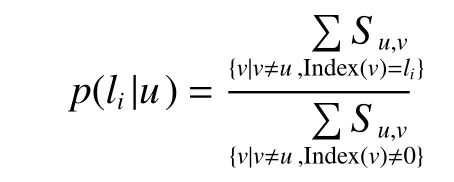
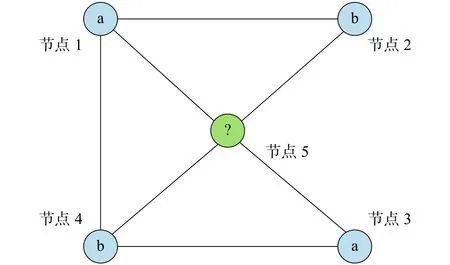
圖2 預(yù)測節(jié)點(diǎn)的標(biāo)簽說明Fig. 2 Description of the node label prediction
2 不平衡數(shù)據(jù)分類
本文算法是從網(wǎng)絡(luò)節(jié)點(diǎn)的連接特性中提取出拓?fù)涮卣髋c數(shù)據(jù)樣本點(diǎn)的距離相似度,并一起用于實(shí)現(xiàn)數(shù)據(jù)分類。具體地,在引入不平衡因子的條件下,將子網(wǎng)絡(luò)中每個(gè)節(jié)點(diǎn)的局部效率與節(jié)點(diǎn)間的歐式距離結(jié)合起來,根據(jù)測試樣本點(diǎn)與每個(gè)子網(wǎng)絡(luò)的整體性測度來確定類別歸屬。
2.1 相似性測度
文獻(xiàn)[10]中是將子網(wǎng)絡(luò)效率與待測節(jié)點(diǎn)之間的物理特征結(jié)合在一起,考慮到網(wǎng)絡(luò)中搖擺節(jié)點(diǎn)的存在,僅僅利用平均功率無法有效地分辨出對分類結(jié)果影響較小的節(jié)點(diǎn),為了更好地區(qū)別單個(gè)節(jié)點(diǎn)對測試點(diǎn)分類結(jié)果的影響,本文將每個(gè)節(jié)點(diǎn)的局部效率分別與物理特征結(jié)合到一起,可以對影響較小的樣本點(diǎn)有較好的識(shí)別,其表達(dá)式為

2.2 整體性測度
傳統(tǒng)的有監(jiān)督和無監(jiān)督的分類器構(gòu)建多是以數(shù)據(jù)樣本點(diǎn)的物理特征作為判別依據(jù),但實(shí)際數(shù)據(jù)集中的數(shù)據(jù)點(diǎn)并不是孤立存在的,正如鏈路預(yù)測問題中一個(gè)節(jié)點(diǎn)的兩個(gè)鄰居節(jié)點(diǎn)之間是否建立連邊除了受共同鄰居個(gè)數(shù)的影響外,還與共同鄰居的性質(zhì),如度、聚類系數(shù)和介數(shù)中心性等有關(guān)。把每個(gè)節(jié)點(diǎn)看成獨(dú)立或同等分布是有缺陷的,不符合實(shí)際數(shù)據(jù)集的樣本點(diǎn)之間的關(guān)系,利用整體性測度大小去判斷待測樣本點(diǎn)的類別歸屬,正是將數(shù)據(jù)點(diǎn)的物理特征和關(guān)聯(lián)特征結(jié)合在一起的體現(xiàn),對于測試樣本點(diǎn) t,整體性測度定義為
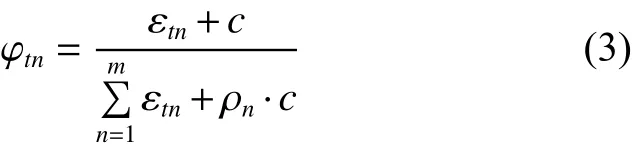
2.3 算法步驟和時(shí)間復(fù)雜度
算法 網(wǎng)絡(luò)拓?fù)涮卣鞯牟黄胶鈹?shù)據(jù)分類
1) 構(gòu)建網(wǎng)絡(luò);
2) 根據(jù)式(1)計(jì)算網(wǎng)絡(luò)節(jié)點(diǎn)局部效率;
3) 根據(jù)式(2)計(jì)算待測節(jié)點(diǎn)與每個(gè)子網(wǎng)絡(luò)的相似性測度;
4) 根據(jù)式(3)計(jì)算待測節(jié)點(diǎn)與每個(gè)子網(wǎng)絡(luò)的整體性測度;
5) 依據(jù)整體性測度的大小預(yù)測待測樣本點(diǎn)的標(biāo)簽。
對于本文所提算法的時(shí)間復(fù)雜度分析:假設(shè)用于建立網(wǎng)絡(luò)的樣本點(diǎn)個(gè)數(shù)為,鄰居節(jié)點(diǎn)數(shù)為,且滿足,以每個(gè)節(jié)點(diǎn)為起點(diǎn)的最大有向邊數(shù)為,故整個(gè)網(wǎng)絡(luò)中的有向邊最多為條;1)構(gòu)建網(wǎng)絡(luò)時(shí)需要計(jì)算任意一對節(jié)點(diǎn)之間的距離,耗時(shí)較長,計(jì)算量為;2)在計(jì)算節(jié)點(diǎn)局部效率時(shí)需要計(jì)算節(jié)點(diǎn)的度,其時(shí)間復(fù)雜度為;3)中計(jì)算待測點(diǎn)與每個(gè)子網(wǎng)絡(luò)的相似性測度,已知網(wǎng)絡(luò)節(jié)點(diǎn)個(gè)數(shù)為,故這一階段時(shí)間復(fù)雜度為;4)中最壞的情況是整個(gè)網(wǎng)絡(luò)節(jié)點(diǎn)的類別數(shù)較多,其計(jì)算量不大于;5)中依據(jù)測試樣本點(diǎn)與哪類子網(wǎng)絡(luò)的整體性測度大,就確定該節(jié)點(diǎn)的類別,這步完成需要時(shí)間量為。通過上面的分析,把算法步驟各個(gè)階段的時(shí)間復(fù)雜度整合到一起,得出本文方法時(shí)間復(fù)雜度為,取最高階,時(shí)間復(fù)雜度為,這與SVM的時(shí)間復(fù)雜度[18]仍具有可比性。
3 實(shí)驗(yàn)結(jié)果及分析
3.1 評(píng)價(jià)指標(biāo)
傳統(tǒng)的分類方法多采用正確率(測試樣本點(diǎn)中正確分類的個(gè)數(shù)占總的個(gè)數(shù)的比例)作為評(píng)價(jià)指標(biāo),其對應(yīng)的混淆矩陣可用來表示實(shí)際分類情況,見表 1 所示。表 1 中,TP+FN=N+,F(xiàn)P+TN=N-,N+為測試樣本正類數(shù),N-為測試樣本負(fù)類數(shù)。
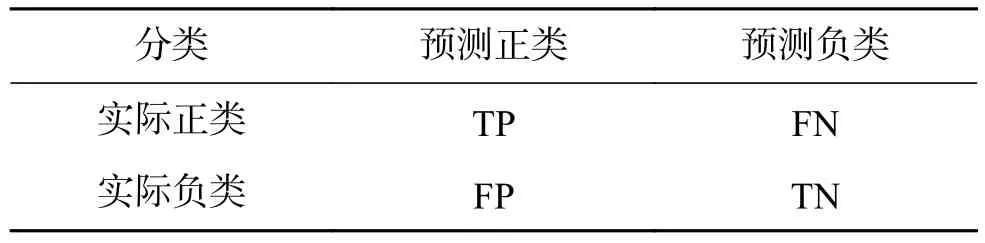
表1 混淆矩陣Table 1 Confusion matrix
然而,對于非平衡數(shù)據(jù)集則采用不平衡分類中的敏感性Se和特異性Sp作為性能評(píng)價(jià)的兩個(gè)輔助指標(biāo),幾何平均值Gm和F-value作為綜合性指標(biāo),它們在一定程度上可用來衡量算法的優(yōu)劣,其定義為
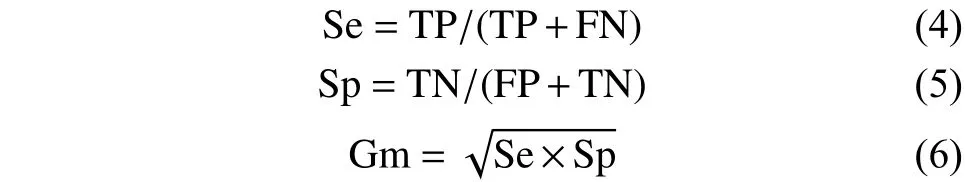
式中:Se代表分類器在少數(shù)類樣本上的預(yù)測能力;Sp代表分類器在多數(shù)類樣本上的預(yù)測能力。Se和Sp的值越大表示分類效果越好,但現(xiàn)實(shí)不平衡數(shù)據(jù)中往往少數(shù)類樣本攜帶更有價(jià)值的信息,所以在實(shí)際應(yīng)用中更應(yīng)該想著如何提高Se值。
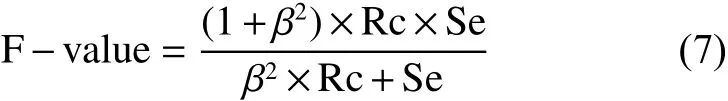
3.2 實(shí)驗(yàn)結(jié)果及分析
為了驗(yàn)證本文所提分類方法的有效性,首先用一個(gè)人造數(shù)據(jù)集給出證明,實(shí)驗(yàn)中得出的結(jié)果均是在MATLAB 2012a軟件上運(yùn)行得出的,臺(tái)式計(jì)算機(jī)具體配置為:系統(tǒng)為64位的Windows10企業(yè)版,處理器為Intel(R) Core(TM) i7-6700CPU,內(nèi)存大小8 GB。本文實(shí)驗(yàn)中非線性的核函數(shù)使用較為廣泛的Gauss徑向基(RBF)核函數(shù)。考慮到SVM在數(shù)據(jù)分類上是具有代表性的算法,本文用來對比的算法均使用SVM作為基分類器,Undersampling中使用基于歐氏距離的欠采樣方法[19],DEC中正負(fù)類樣本的懲罰因子設(shè)置為樣本個(gè)數(shù)不平衡比,SMOTE中最近鄰個(gè)數(shù)設(shè)置,通過網(wǎng)格搜索算法得到和懲罰參數(shù),所有對比算法中懲罰參數(shù)的候選集設(shè)定為,的候選集設(shè)定為,均取最優(yōu)時(shí)的數(shù)值參加計(jì)算。本文使用五折交叉驗(yàn)證的方法對數(shù)據(jù)集進(jìn)行驗(yàn)證,每次迭代選擇其中4組作為訓(xùn)練集,1組作為測試集,每組訓(xùn)練集和測試集中的正負(fù)類樣本點(diǎn)數(shù)量差異均定義為不平衡比,把本文算法分類結(jié)果與SVM、FSVM、DEC、SMOTE和Under-sampling算法結(jié)果進(jìn)行比較,每種算法在數(shù)據(jù)集上運(yùn)行20次五折交叉驗(yàn)證取平均值,并將最大的Gm值和F-value值用黑體標(biāo)出。
3.2.1 人造數(shù)據(jù)集
在二維空間中隨機(jī)生成樣本點(diǎn)不平衡比為1000:50的線性不可分?jǐn)?shù)據(jù)集(見圖3),其樣本點(diǎn)符合正態(tài)分布,多數(shù)類含有1 000個(gè)樣本點(diǎn),少數(shù)類含有50個(gè)樣本點(diǎn),采用基于網(wǎng)絡(luò)拓?fù)涮卣鞯牟黄胶鈹?shù)據(jù)分類方法與其他經(jīng)典算法相比較,表2給出了各算法在該數(shù)據(jù)集上的分類結(jié)果,從表中可以看出,本文所提方法對不平衡數(shù)據(jù)集具有良好的分類性能。
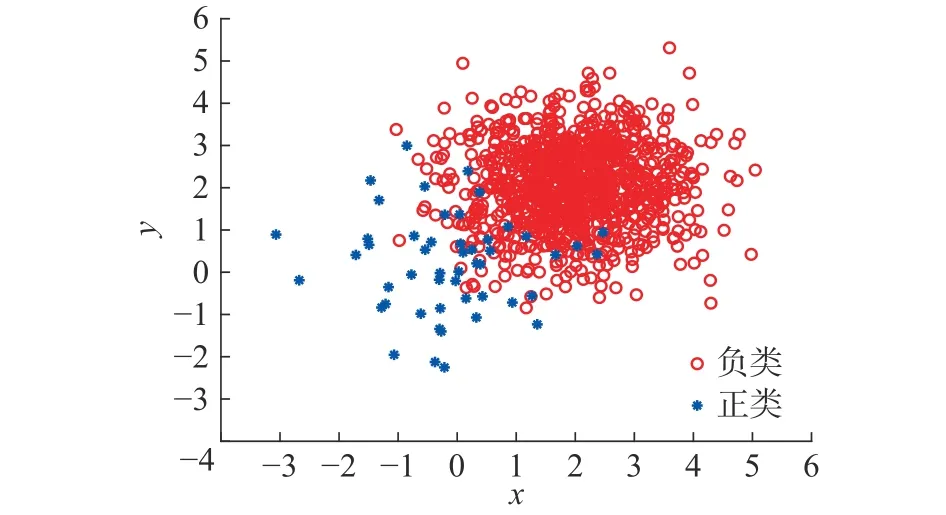
圖3 人工數(shù)據(jù)集Fig. 3 Artificial data set
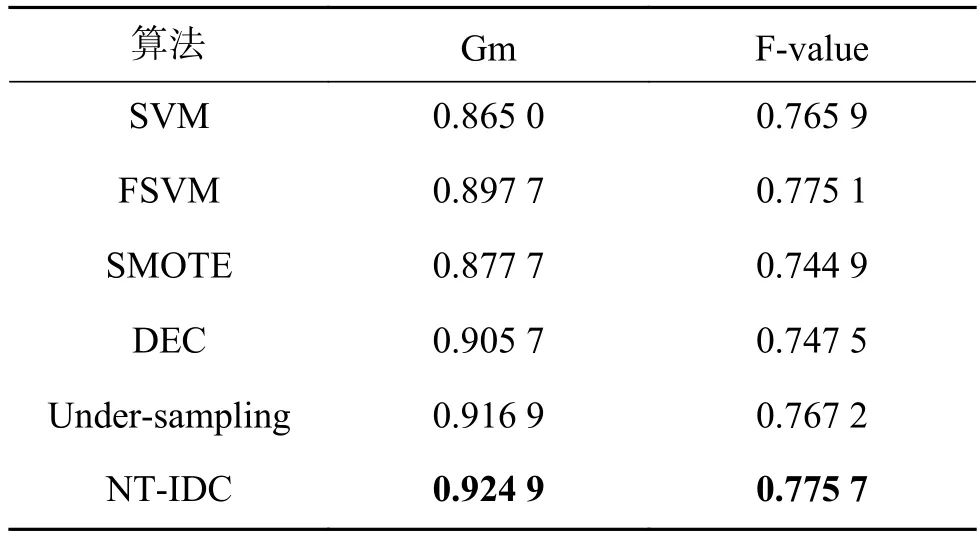
表2 人工數(shù)據(jù)集的分類結(jié)果Table 2 The result of the artificial dataset
3.2.2 真實(shí)數(shù)據(jù)集
從UCI機(jī)器學(xué)習(xí)數(shù)據(jù)庫選擇了10組不平衡的數(shù)據(jù)集來進(jìn)行實(shí)驗(yàn)。所用數(shù)據(jù)集樣本點(diǎn)個(gè)數(shù)范圍為214~5 000,樣本點(diǎn)的屬性維數(shù)范圍為3~34,有的數(shù)據(jù)集可能有多種類別,本文僅考慮二分類問題,對于類別不是兩類的就先把數(shù)據(jù)集都變?yōu)閮深悾哑渲心愁惢蚰硯最惪醋髡悾O碌乃蓄惡喜樨?fù)類,10個(gè)數(shù)據(jù)集的詳細(xì)信息如表3所示。
為了驗(yàn)證算法在真實(shí)數(shù)據(jù)集上的有效性,表4和表5分別給出了不同算法在少數(shù)類和綜合指標(biāo)性能上的對比結(jié)果。在表4中,本文算法在少數(shù)類預(yù)測能力上效果較好,除Yeast和Ecoli外,其余數(shù)據(jù)集都優(yōu)于對比算法。表5中,相比較SVM,其他算法在不平衡數(shù)據(jù)分類中的精度都有了一定的提高,當(dāng)不平衡比率較大時(shí),SVM的分類效果會(huì)變得較差,DEC算法雖然考慮了數(shù)據(jù)的不平衡性,但沒能很好地考慮到樣本點(diǎn)的分布情況,本文算法則較好地處理了這一問題,對樣本點(diǎn)間有關(guān)聯(lián)特征的數(shù)據(jù)集如Haberman、Ecoli、Glass、Imagesegment、wireless和 contraceptive本文算法均取得了最優(yōu)的分類結(jié)果。
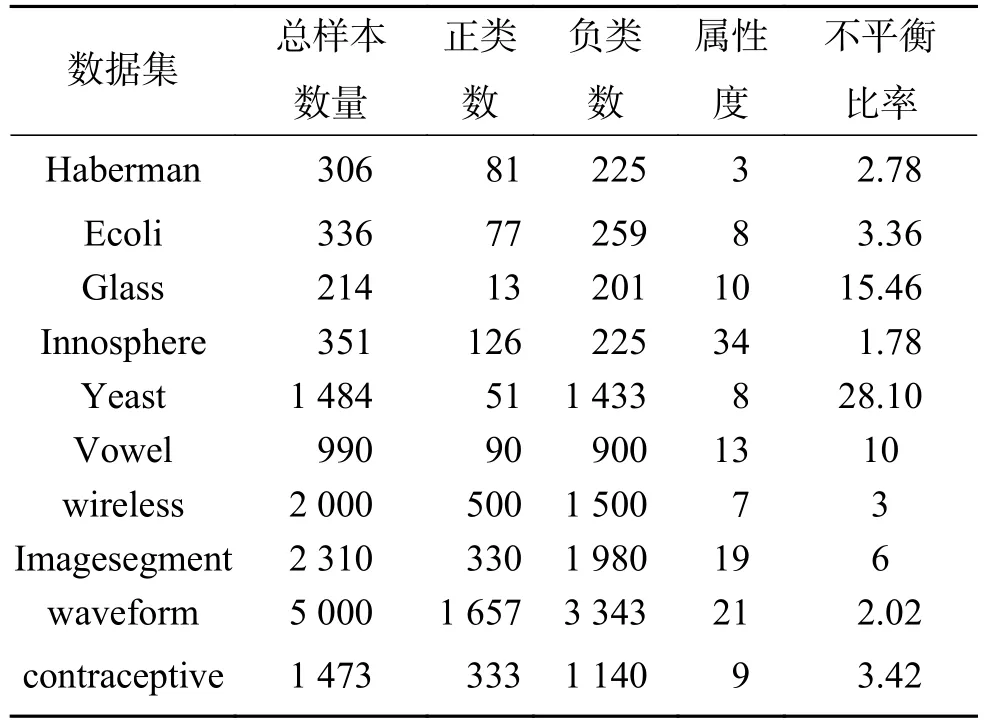
表3 數(shù)據(jù)集信息Table 3 Dataset information
對于數(shù)據(jù)集Haberman、Ecoli和waveform,本文算法的Gm值平均提高了2%左右,但是在數(shù)據(jù)集Yeast和Vowel上,由于節(jié)點(diǎn)之間的關(guān)聯(lián)信息不明顯,算法所能挖掘的網(wǎng)絡(luò)信息受限,對部分測試點(diǎn)無法做出正確地判斷,沒有取得最好的效果,但與SVM、FSVM、DEC、SMOTE和Under-sampling分類方法所取得分類結(jié)果相差不大,表明NT-IDC算法仍有待改進(jìn)。對于正負(fù)類樣本不平衡比率大的數(shù)據(jù)集,因?yàn)楸疚乃惴ㄌ岣吡松贁?shù)類分類性能,在Gm值一定的前提下,當(dāng)FP值變大時(shí),Rc值變小,使得Glass、Vowel和Yeast數(shù)據(jù)集上的F-value值有所波動(dòng),在處理樣本點(diǎn)個(gè)數(shù)較多的數(shù)據(jù)集如waveform上正是因?yàn)榭紤]了數(shù)據(jù)點(diǎn)間的關(guān)聯(lián)信息,所以才表現(xiàn)出一定的優(yōu)越性。綜上分析,本文所提算法在考慮到影響不平衡數(shù)據(jù)分類因素的條件下,表現(xiàn)出良好的分類性能,充分說明了將數(shù)據(jù)點(diǎn)之間關(guān)聯(lián)特征作為數(shù)據(jù)分類性能影響因素的合理性。
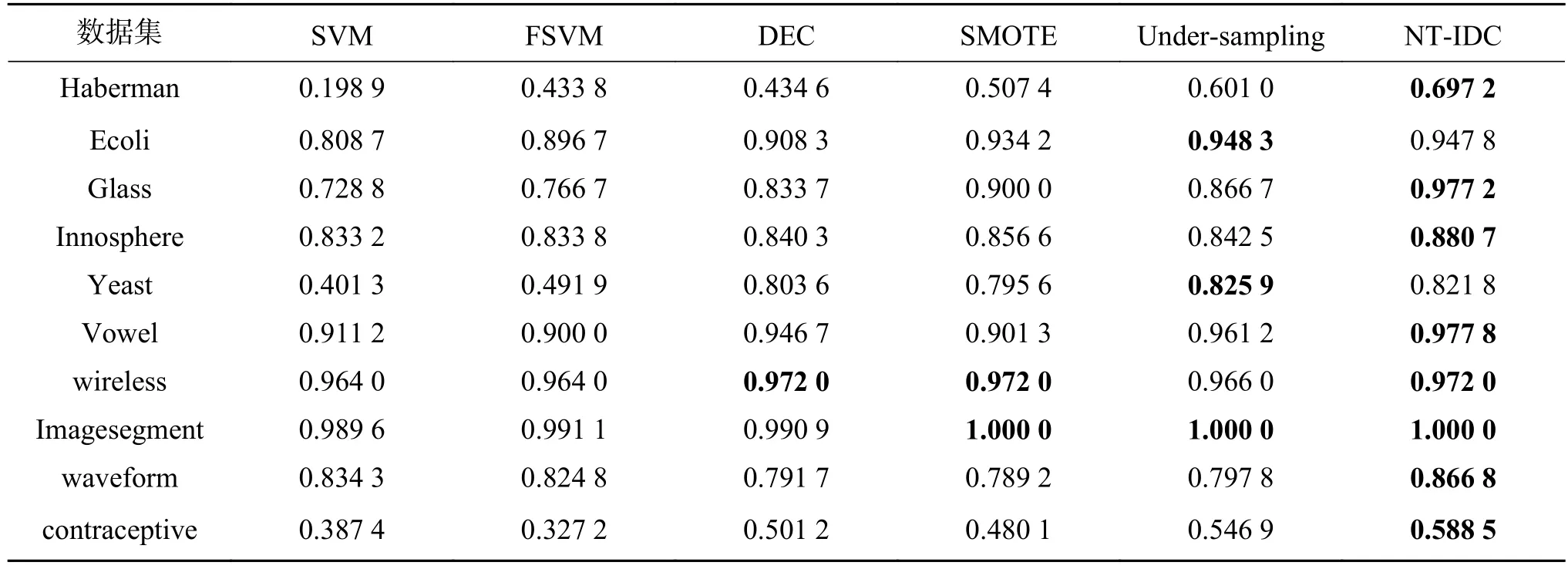
表4 少數(shù)類分類結(jié)果Table 4 The classification result of minority class
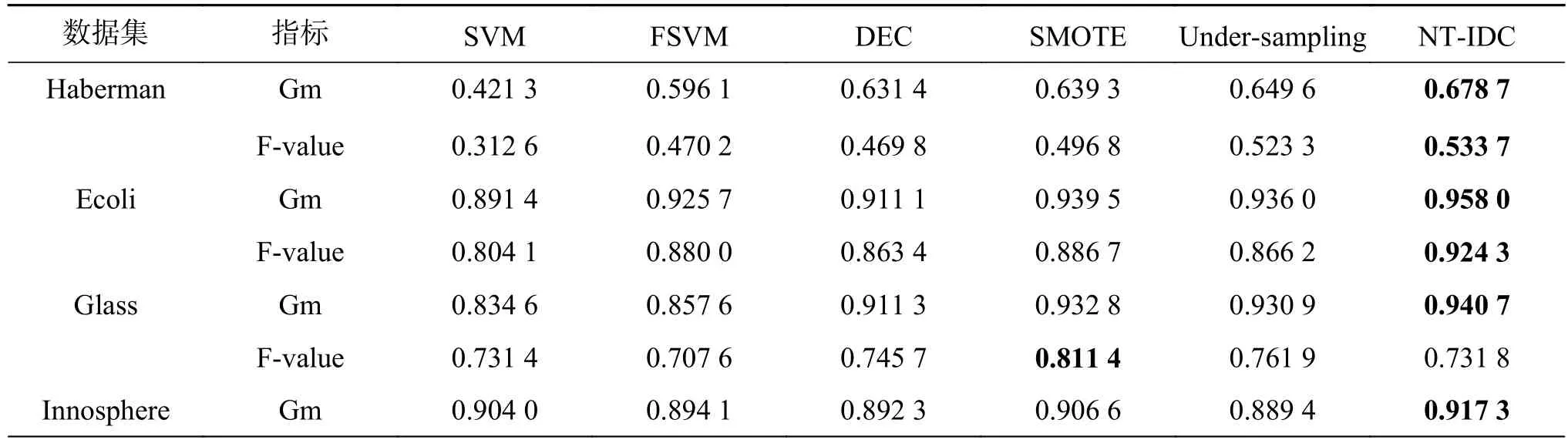
表5 數(shù)據(jù)集在不同算法下的分類結(jié)果Table 5 The classification results of datasets under different algorithms

續(xù)表5
3.3 參數(shù)敏感性分析
為了更好地了解本文算法中參數(shù)對數(shù)據(jù)分類效果的影響,在實(shí)際數(shù)據(jù)集Haberman、Glass、Inno-sphere、Ecoli、和 Imagesegment上分析不平衡因子(見圖4)和KNN中的參數(shù)(見圖5)對分類性能的影響。
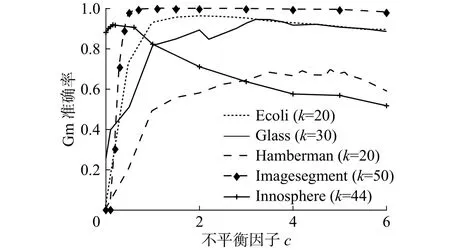
圖4 參數(shù) 對準(zhǔn)確率Gm的影響Fig. 4 The influence of parameter c on accuracy Gm
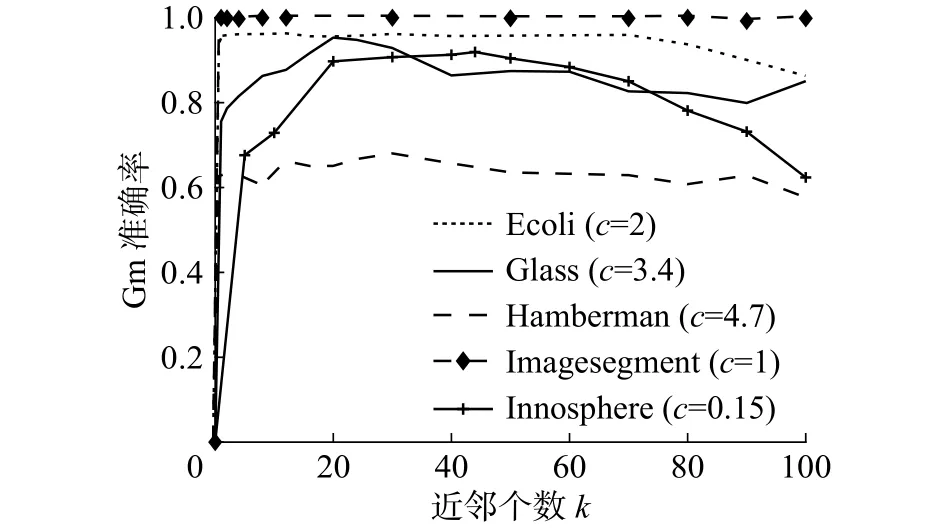
圖5 參數(shù) 對準(zhǔn)確率Gm的影響Fig. 5 The influence of parameter k on accuracy Gm
4 結(jié)束語
本文針對不平衡數(shù)據(jù)分類問題,考慮到傳統(tǒng)分類方法在實(shí)際數(shù)據(jù)集中存在的缺陷,提出一種更符合數(shù)據(jù)集樣本點(diǎn)真實(shí)關(guān)系的數(shù)據(jù)分類方法,算法中除利用數(shù)據(jù)點(diǎn)的物理特征外,還充分挖掘了由這些數(shù)據(jù)點(diǎn)所建立的網(wǎng)絡(luò)拓?fù)涮卣鳎瑢?shí)驗(yàn)結(jié)果表明基于網(wǎng)絡(luò)結(jié)構(gòu)去解決不平衡數(shù)據(jù)分類問題是一個(gè)可行的途徑,除此之外,本文提出的算法仍能夠應(yīng)用于多分類問題。在未來的研究中,將探索如何更有效地挖掘隱藏在網(wǎng)絡(luò)中的節(jié)點(diǎn)行為,找到更加符合數(shù)據(jù)樣本點(diǎn)之間的拓?fù)涮卣鳎缈紤]除節(jié)點(diǎn)局部效率外的其他性質(zhì),不同的數(shù)據(jù)集值選取一般不固定,后續(xù)可以在參數(shù)的優(yōu)化上做進(jìn)一步的研究。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
