基于由粗到精定位的列車駕駛員瞳孔和眼角點檢測
2019-11-08 08:06:04王增才房素素張國新齊亞州
鐵道學報 2019年10期
王增才,趙 磊,房素素,張國新,齊亞州
(1.山東大學 機械工程學院,山東 濟南 250061; 2.高效潔凈機械制造教育部重點實驗室,山東 濟南 250061)
近年來,我國鐵路事業不斷發展,隨著高鐵速度的不斷提升,到達的地域越來越廣,越來越多的人首選鐵路作為出行工具。高速列車與其他交通方式(如輪船、飛機和汽車)相比,安全系數較高,但是一旦出現交通事故,帶來的經濟損失和人員傷亡是十分巨大的,而在所有列車事故發生的原因中,駕駛員疲勞及注意力不集中占比例最高[1],在列車長時間運行時,單一的駕駛環境極易引起駕駛員的疲勞,因此為了保證列車駕駛員和乘客的安全,對列車駕駛人的疲勞狀態進行識別是必要的[1]。而視線方向的變化往往能夠反映列車駕駛員的疲勞和注意力狀態,瞳孔相對于眼角點的位置和運動狀態是視線方向估計的關鍵特征。
本文結合圖像紋理和學習模型,采用粗到精定位的策略來獲取列車駕駛員眼角點和瞳孔位置。首先,利用監督下降法SDM[13]定位模型對列車駕駛人的面部特征點進行定位和跟蹤,獲取眼角點初始位置。然后在區域中通過加權遍歷積分投影算法對瞳孔中心進行粗定位獲得其初始位置。最后,將已定位的瞳孔和眼角點作為初始點,采用基于局部二值特征LBF的級聯回歸方法[14]對眼角和瞳孔點進行進一步精確定位。技術路線見圖1。
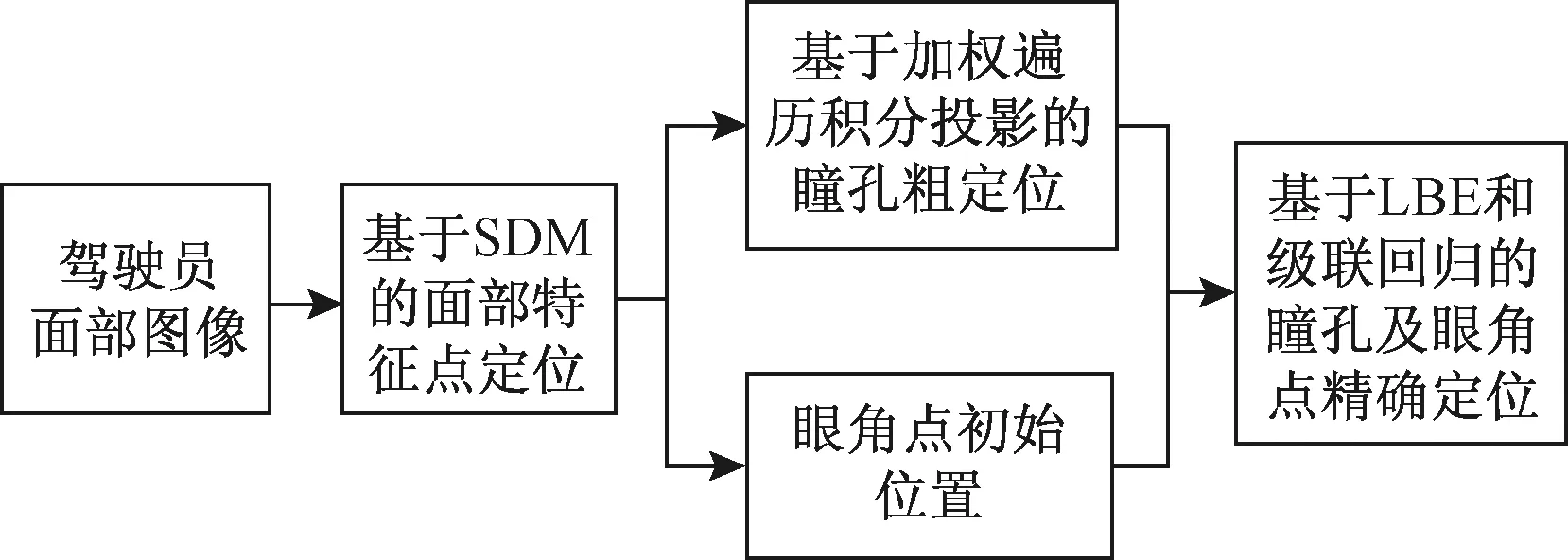
圖1 總體技術路線
1 眼角點粗定位
采用SDM模型對面部特征點進行定位,從而獲取眼睛區域和眼角點初始位置。SDM是牛頓法的改進,主要通過對機器學習模型進行訓練求出梯度的下降方向,解決復雜最小二乘問題。該方法訓練用的目標函數為
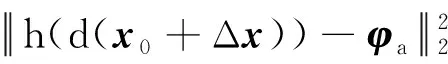
(1)
式中:x0為特征點坐標初始值;h(d(x))為在關鍵點x附近提取的紋理特征(HOG和SHIFT等);φa=h(d(xa))為在標定點附近提取的紋理特征。初始點坐標x0可通過不同的特征點初始化策略得到。該方法通過對式(1)的迭代,使xk+1=xk+Δxk逐漸接近人工標定值xa。首次迭代的式(1)的泰勒展開式為
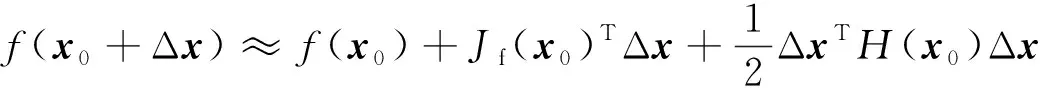
(2)
式中:Jf(x0)為矩陣的一階導數;H(x0)為矩陣的二階導數。將式(2)對Δx求導并設置為0,得到
Δx1=-H-1(x0)Jf(x0)=-2H-1(x0)Jf(x0)(φ0-φa)
(3)
其中,φ0=h(d(x0)),首次迭代可以看作特征差Δφ0=φ0-φa在R0=-2H-1(x0)Jf(x0)方向上的投影,其投影結果用Δx1表示。因此,可以用式(4)來表示首次迭代。
Δx1=R0φ0+b0
(4)
根據SDM算法,第k步迭代后式(4)改寫為
xk=xk-1+Rk-1φk-1+bk-1
(5)
式中:xk為第k次迭代后面部關鍵點的位置:φk-1為第k-1次迭代后關鍵點附近的特征;Rk-1為下降方向;bk-1為偏差項,Rk-1和bk-1通過訓練得到。在訓練過程中,該模型主要更新形狀差值Δxk=xa-xk-1和特征向量φk兩個參數,來生成新的訓練樣本,訓練的過程為
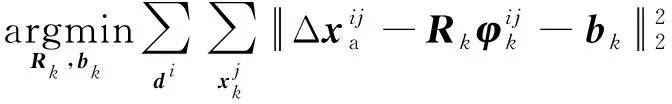
(6)
式中:di為第i張圖像;j為特征點的編號。式(6)是最小二乘問題,可求解析解。定義F=[φ1],A=[Rb]。則
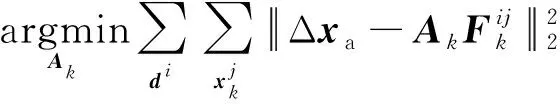
(7)
根據式(7),可求Ak的解析解為
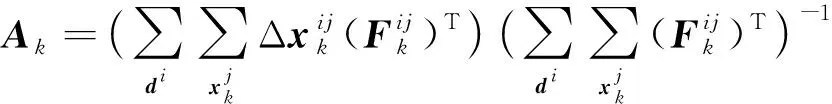
(8)
得到Ak后,根據迭代公式和每張人臉圖片上的面部特征,可以得到
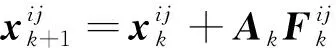
(9)
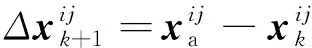
(10)
在訓練過程中,只需要在每次迭代后的新坐標附近計算紋理特征,然后通過式(9)和式(10)進行多次迭代可以得到最終位置。將每次迭代得到的A保存,用于定位新的樣本圖像。
訓練好模型后,其測試過程如下:(1)采用Adaboost人臉定位算法定位人臉區域;(2)根據人臉區域初始化人臉形狀,得到x0;(3)采用SDM學習到的參數下降方向Rk和bk不斷更新人臉形狀xk,回歸出最終的人臉形狀。本文采用3名駕駛員的視頻圖像來對模型進行測試,部分定位結果見圖2。可以看出該方法能夠實現駕駛員眼睛特征點的有效檢測。

圖2 面部特征定位檢測結果
2 瞳孔粗定位
在面部特征點定位后,確定眼角點的初始位置,但是該模型無法確定瞳孔的初始位置。因此,本文通過模板遍歷法[5]提取眼睛圖像的灰度比率,然后將其作為權值構建積分投影曲線,用來粗定位駕駛員瞳孔位置。
利用滑動模板對眼睛區域進行灰度分析:首先將在獲取眼睛區域圖像,然后用圖3所示的模板W從圖像左上角對其進行遍歷。在每個位置上計算模板所覆蓋區域的灰度比率值。模板W區域內灰度比率的計算公式為
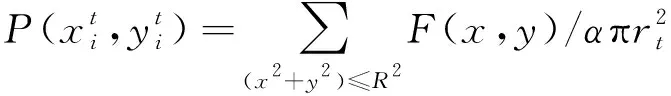
(11)
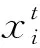
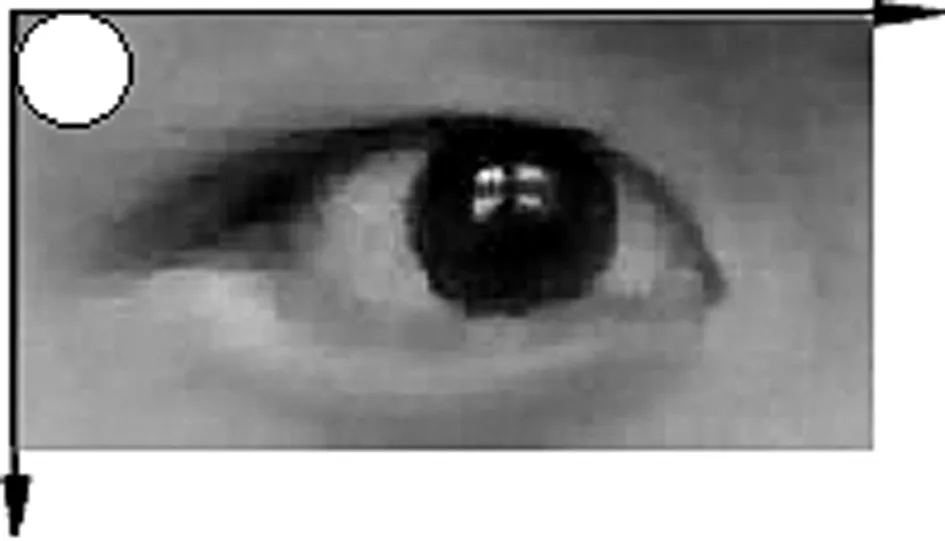
圖3 圓形滑動模板的遍歷方法
將灰度比率作為權值,通過式(12)和式(13)來計算圖像的加權積分投影曲線。在瞳孔區域的位置,投影曲線在x軸和y軸兩個方向均有極小值,將兩個方向曲線的極小值作為粗定位的坐標值,實現瞳孔位置的初始定位。

(12)
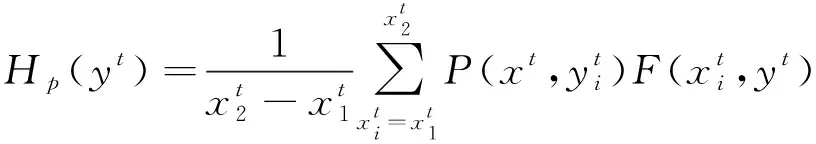
(13)
3 瞳孔和眼角點精確定位
本文利用LBF特征和回歸模型同時定位瞳孔點和眼角點,該方法不僅能夠對駕駛員的眼角點和瞳孔點進一步精確定位,而且還能將眼角點作為約束,避免干擾對瞳孔點定位精度的影響。
3.1 形狀回歸算法
本文采用的回歸方法通過級聯形式來擬合得到總體形狀S。以S0作為初始形狀,利用每次迭代獲取的形狀增量ΔS對總體形狀S擬合。第t次迭代求得的ΔSt為
ΔSt=WtΦt(I,St-1)
(14)
式中:St-1為上一次迭代獲取的形狀;I表示輸入圖像;Фt為關鍵點的征映射函數向量,依賴I和St-1;Wt為回歸矩陣。利用這種方式學習的特征作為關鍵點的編碼特征。將ΔSt加入到St-1,進行下一步計算。
映射函數向量Фt主要通過學習和手動設計得到。但是,若將所有樣本中關鍵點均在手動設計的映射函數中選擇,那么在較大空間中學習到較為理想的特征組合是很難的。因此,該模型通過基于局部學習的策略來獲取映射函數。
特征映射函數由多個局部特征映射函數構成,本文Φt主要由3個關鍵點組成:左右兩側的眼角點和一個瞳孔點。因此映射函數向量為
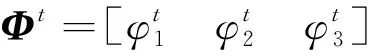
(15)
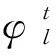
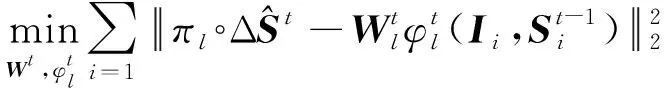
(16)
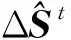
本文用訓練隨機森林RF(Random Forest)回歸模型作為每個關鍵點的映射函數,提取每一個點的LBF特征,通過全局級聯回歸精確定位左右兩側的眼角點和瞳孔點。
3.2 RF模型
RF是一種基于多個決策樹的組合算法,主要是以分類回歸樹為基礎的分類回歸模型。RF由多個決策樹構成,模型通過Bootstrap算法隨機地在數據中有放回地抽取樣本來訓練每一顆樹,每一次訓練的決策樹都因為訓練樣本不同而其參數也不一樣。因此,RF能夠隨機生成多個決策樹,最后選擇重復程度最高的決策樹作為結果。由回歸樹構成的組合模型通過求每顆回歸樹的平均值形成RF模型的預測值。RF回歸算法的流程見圖4。
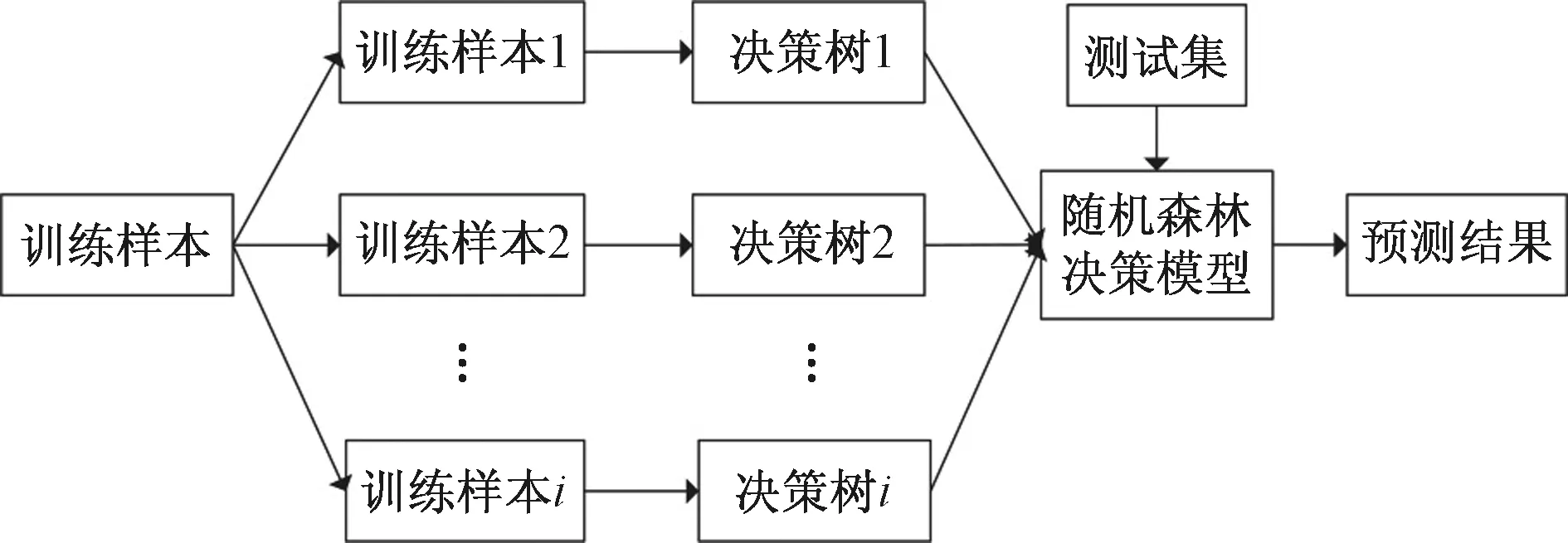
圖4 RF模型
3.3 LBF特征
與RF模型不同,本文利用基于RF結構的模型來提取特征點局部特征。在特征提取的過程中,每一個特征點都對應一個RF模型,而每個RF是由相互獨立的多個決策樹構成。本文通過求圖像中兩個不同坐標點像素的差值獲取形狀索引特征,并將其作為輸入。本文RF模型是針對單個特征點,每個RF回歸模型所對應的點不會關聯到其他RF對應的特征點。圖5中,隨著迭代次數的增加,隨機點生成的圓形區域半徑逐漸減少。

圖5 最優局部區域選取
利用以上形狀索引特征的獲取方法,訓練RF模型。在訓練過程中,令輸入為X={I,S},預測目標由Y=ΔS表示。在訓練的過程中,每棵樹中的每個節點的訓練過程都相同,從隨機生成的形狀索引特征集合中選取一個特征的集合,然后將獲取的樣本分配到每個決策樹的左右子樹中。對決策樹的每個節點,我們期望左右子樹的樣本數據方差減少最大。每一個決策樹的節點都利用這種方法進行訓練,而且每顆樹均相互獨立訓練,且方法相同。訓練完后,決策樹的所有葉節點都保存一個特征點的二維偏移量。利用RF輸出由0和1組成的二值特征。將所有樣本點的特征串聯起來,建立整個特征點形狀的LBF特征。該方法技術路線見圖6。
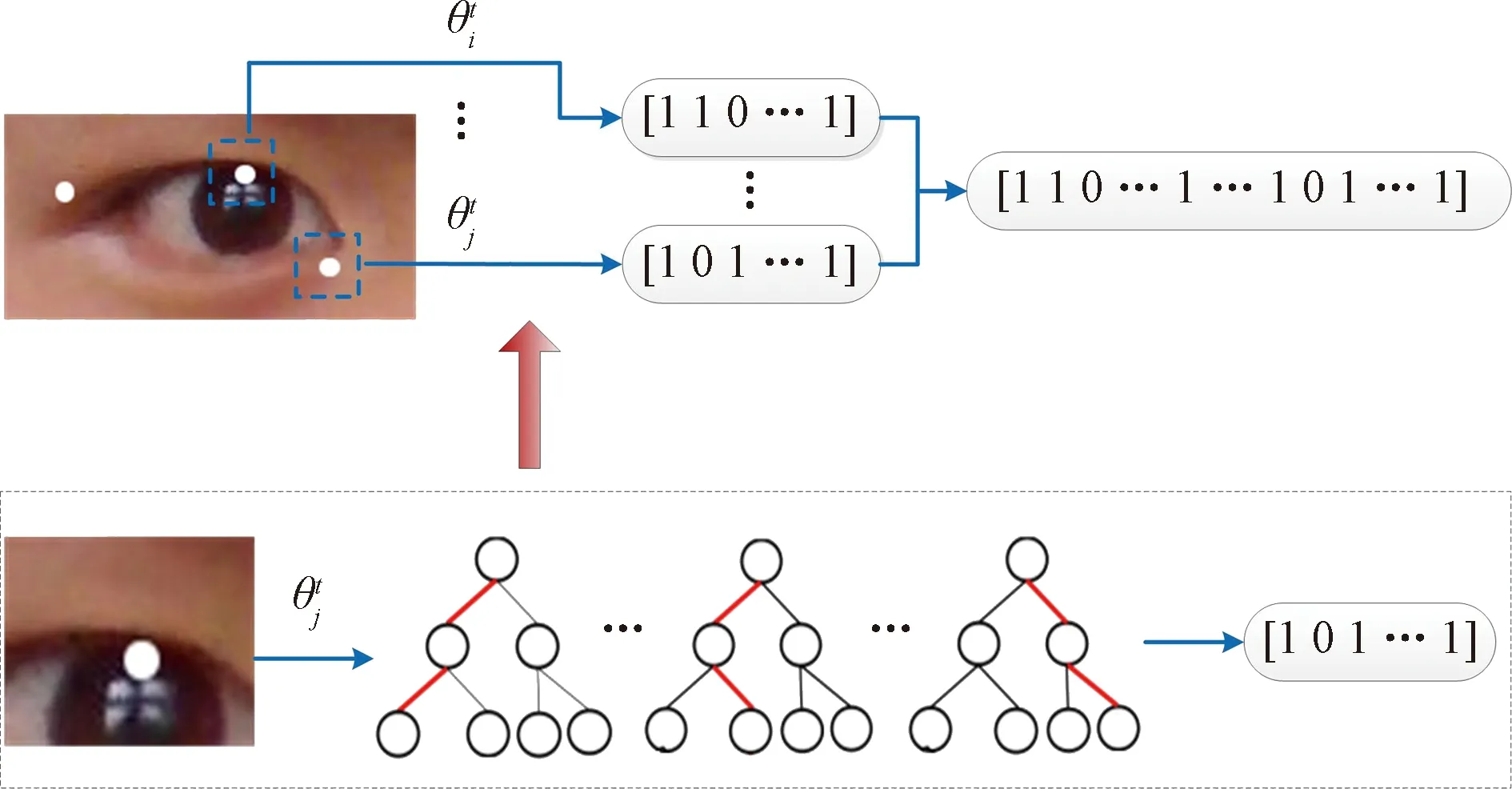
圖6 LBF特征提取
3.4 整體線性回歸方法
在得到LBF特征后,求出關鍵點的全局特征映射函數Wt,即
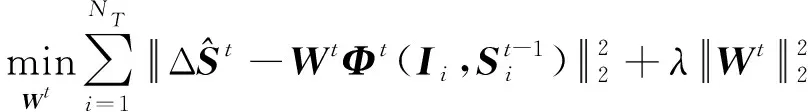
(17)
式中:λ為正則項系數,防止模型出現過擬合;NT為樣本的個數。
該模型的優化和檢測步驟過程為:(1)利用SDM模型和加權遍歷積分投影方法獲取基于NT個關鍵點的初始形狀S0;(2)根據真實特征點形狀S和圖像I學習每個點的RF模型并求LBF特征;(3)利用式(17)計算全局線性投影Wt;(4)重復步驟(2)和(3),一直到模型收斂,得到Фt和Wt;(5)在檢測過程中,將眼睛圖片和初始坐標作為輸入,求出對應的LBF特征,然后利用Wt和Фt得到關鍵點的形狀差值,并根據下式對形狀進行更新
St=St-1+WtΦt
(18)
多次迭代后,獲得眼角點和瞳孔點的位置。
4 實驗與討論
為了驗證本文方法的有效性,采用基于靜態圖像和視頻圖像的數據集進行實驗。首先,利用公共圖像數據集進行實驗并與之前提出的方法比較;然后,利用公共視頻和自建視頻數據集模型進行實驗分析,并研究該算法的檢測精度和效率。
本文采用目前通用的定位精度判定準則[7-12]來驗證提出方法的有效性,其計算方法為
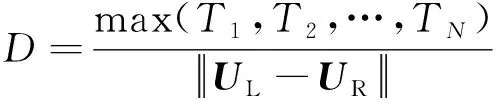
(19)
式中:Ti(i=1, 2, …,N)為第i個需要定位的點與其標定點之間的距離;UL和UR為左右眼睛中心的位置,可以通過標對眼睛標定點平均得到;D為每個需要定位的點的誤差值。錯誤特征曲線[7-12]是通用的特征點定位模型評價工具,因此本文用該曲線進行模型精度比較,誤差曲線的x軸坐標為D,y軸坐標的值為正確率,即橫坐標中點d對應的縱坐標的正確率為定位誤差率D≤d的樣本數量占測試樣本總數的比率,其公式為
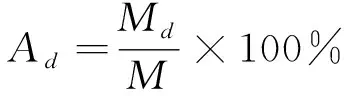
(20)
式中:Ad為當誤差值為d時的正確率;Md為定位誤差值在D≤d的情況下樣本的數量;M表示樣本總數量。
4.1 靜態圖像模型性能試驗
為了保證本文提出模型的有效性和魯棒性,采用MUCT[15],UULM[16]和Gi4E[17]數據集作為訓練集,采用BioID[18]數據集作為測試集。訓練用的3個數據集是由不同的研究機構建立的,其圖像大小和分辨率互不相同。但是,與面部特征點定位模型的訓練方法相似,本文模型在訓練中僅需提取面部特征點位置附近區域的紋理特征,圖像的大小和分辨率并不影響模型的訓練過程。因此,本文將這3個數據集合并訓練模型。
BioID數據集包含了23個人的總共1 521張圖片。該數據集包含了不同的環境、被檢測人的頭部姿態和眼鏡狀態,部分被檢測人有佩戴眼鏡。因此,能夠驗證檢測模型的有效性[7-12]。
BioID數據集是由靜態圖像構成的,在實驗過程中采用以下定位步驟:(1)利用AdaBoost方法對圖像中的人臉進行定位;(2)采用SDM方法得粗定位眼角點;(3)采用積分投影曲線粗定位瞳孔位置;(4)采用LBF判別形狀回歸模型精確定位眼睛特征點。在實驗過程中,需要去除BioID數據庫中無法定位人臉特征的圖片,但是并不影響最終的結果[7, 11],因為去除的圖片僅為5張圖片,不超過整個數據集的0.5%。
提取部分結果圖像并分析其有效性,見圖6。圖6(a)、圖6(c)和圖6(d)所示在駕駛人佩戴眼鏡時,本文方法能夠有效定位。圖6(b)當駕駛人眼睛狀態改變時,本文方法能夠有效定位眼角點和瞳孔位置。圖6(c)所示光照改變時,本文方法的定位效果也沒發生較大改變。圖6(d)~圖6(f)所示,在被測試者的瞳孔位置發生大范圍改變時,該模型也能正確定位。

圖6 在BioID數據集中瞳孔和眼角點的定位結果
我們對瞳孔眼角點定位精度曲線進行分析,實驗結果見圖7,其中GP為基于本文采用的瞳孔粗定位方法,即通過加權的灰度積分投影曲線定位瞳孔位置。結果顯示,與基于GP的瞳孔檢測方法比較,基于SDM的眼角粗定位精度較高。可以看出,本文采用的瞳孔和眼角點定位方法的定位精度均高于粗定位方法。另外,眼角點的定位精度比瞳孔點的定位精度差,這主要是由于不同數據集對眼角點的標定位置略有不同。
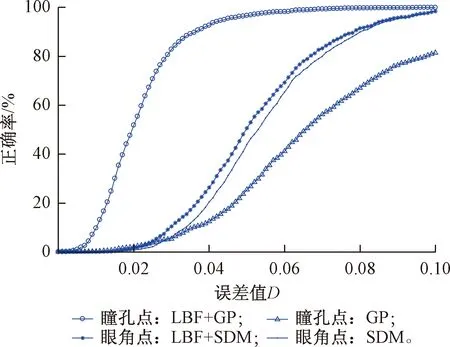
圖7 在BioID數據集中瞳孔和眼角點的錯誤特征曲線
該部分將本文方法與之前提出的瞳孔定位方法進行比較,來進一步驗證本文算法有效性。本文將文獻[7-12]提出的方法與本文提出的算法進行比較,這些算法的實驗數據均采用BioID[7-12]數據集。提取當D≤0.05、D≤0.1和D≤0.25時的樣本占有率作為比較結果,其實驗結果如表1所示。根據實驗結果可以看出,本文模型在取D≤0.05時樣本占比為96.4%,而當D≤0.1時,樣本占比達到100%,在其他方法中,除了文獻[12]的方法外,D≤0.05的樣本占比均未超過90%。其中,取D≤0.1時樣本占比最高為99.4%,D≤0.25時樣本占比均未達到100%。可以看出,與之前提出的方法相比,本文提出方法的定位精度最高且誤差始終保持D≤0.1以內。
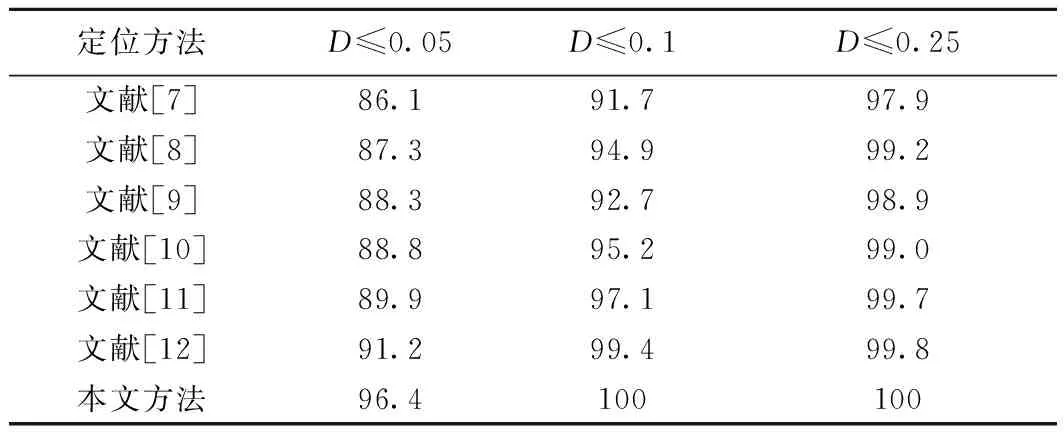
表1 BioID數據集的瞳孔定位檢測結果 %
4.2 基于視頻圖像的模型性能試驗
為了保證定位模型的有效性和魯棒性,本文將Gi4E、MUCT、BioID和UULM數據集作為訓練集,采用FRANK視頻數據集[11,19]和自建的眼睛特征點定位HELD視頻數據集來對模型進行測試。
FRANK數據集是說話的面部視頻數據集,該數據集包含了5 000幀圖像,共一位測試者。
HELD數據集為自建數據庫,共采集了6名測試者在不同頭部姿態和視線方向的面部視頻,并通過手動標定的方法確定瞳孔和眼角點的正確位置,共包含2 103幀圖像。
由于視頻的圖像是連續的,因此實驗過程為:(1)如果是初始幀的圖像則根據4.1節的步驟對眼角點和瞳孔點進行定位,并獲取定位結果;(2)根據前一幀的定位結果,建立眼睛特征點初始模型;(3)采用本文提出的模型精確定位眼睛特征點。
對瞳孔和眼角點定位精度進行分析,實驗結果見圖8、圖9。通過實驗結果看出,基于由粗到精方法的眼角點和瞳孔點的檢測精度均高于粗定位方法,且基于GP的瞳孔位置檢測方法定位精度最低。與4.1節中的實驗結果相似,模型對于眼角點的定位精度仍然低于瞳孔點。由于HELD數據集中的被測試者多于FRANK數據集,模型在HELD數據集中的眼角點定位精度要略低于在FRANK數據集中的精度;但在兩個數據集中,瞳孔定位精度近似,并且眼角點和瞳孔點的定位精度幾乎均在D<0.1范圍達到100%(FRANK:99.9%,HELD:98.6%)。
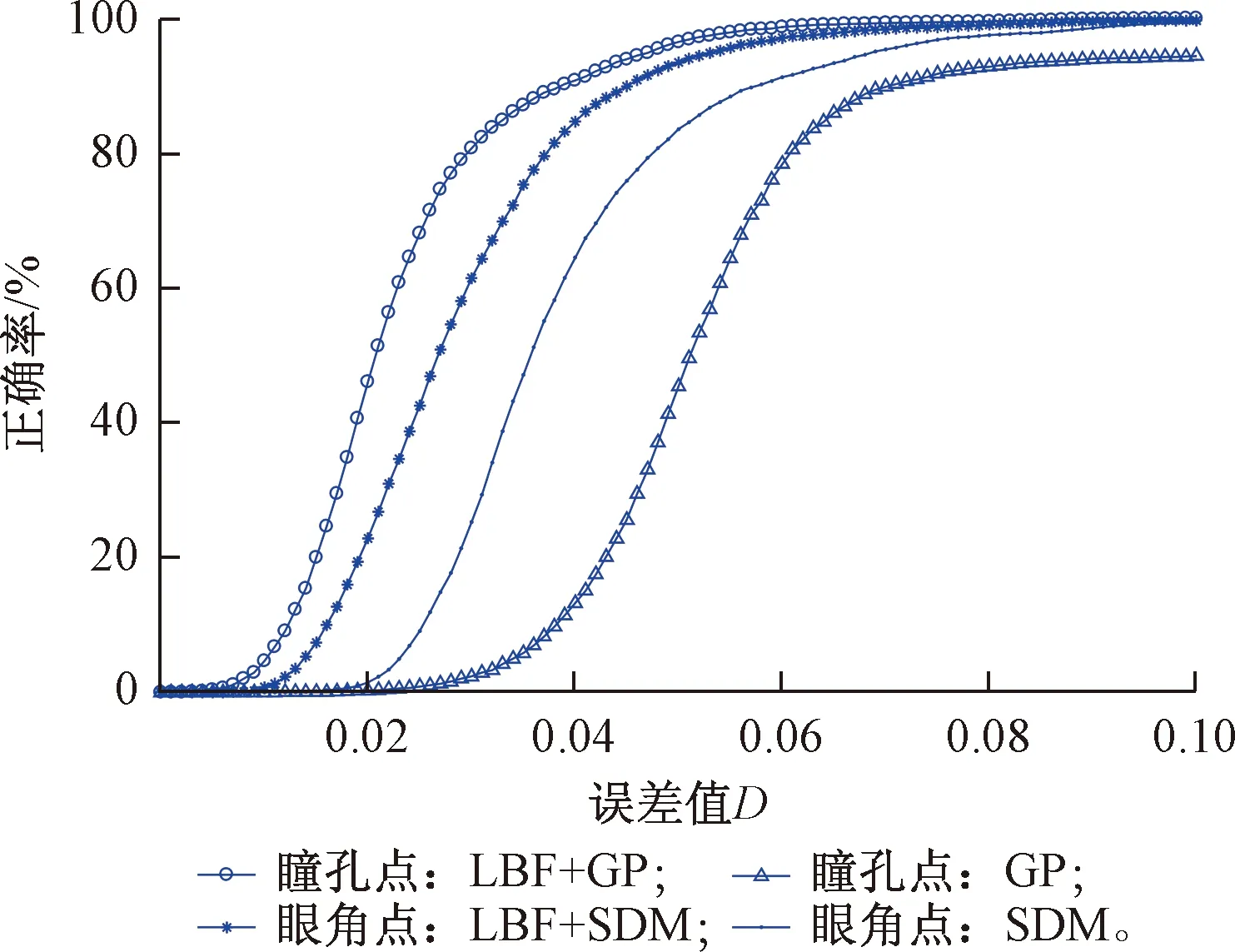
圖8 在FRANK數據集中瞳孔和眼角點的定位結果
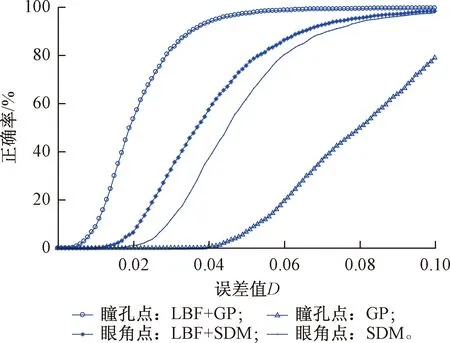
圖9 在HELD數據集中瞳孔和眼角點的定位結果
分別計算本文提出的模型在這兩個視頻數據集中每幀瞳孔和眼角點的定位誤差值D,其錯誤率結果如表2所示。FRANK數據集中,瞳孔點的誤差值D≥0.15的幀數有2幀(0.04%);D≥0.1的幀數的有5幀(0.10%)。眼角點誤差值D≥0.15的幀數有6幀(0.12%);D≥0.1的幀數的有20幀(0.40%)。HELD數據集中,瞳孔點的誤差值D≥0.15的幀數有0幀(0.00%),D≥0.1的幀數的有3幀(0.14%);眼角點誤差值D≥0.15的幀數有0幀(0.00%);D≥0.1的幀數的有29幀(1.40%)。可以看出,在這兩個數據集中,所有特征點誤差值D≥0.1的幀數均不超過30幀。因此,該方法能夠在不同的面部視頻中魯棒地定位瞳孔和眼角位置。
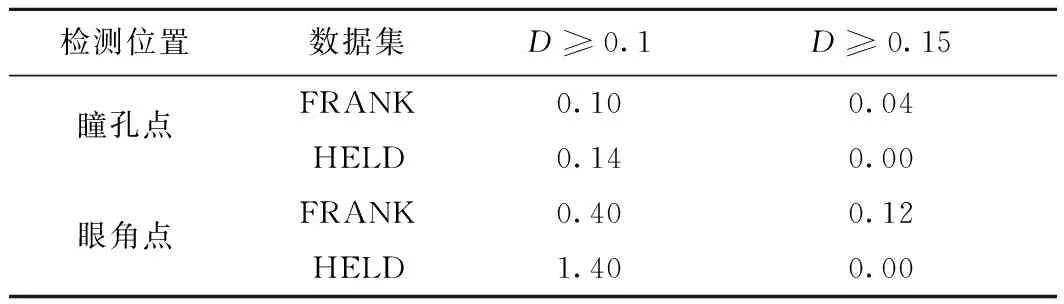
表2 視頻數據集中瞳孔與眼角點定位錯誤率 %
分析該模型在FRANK和HELD視頻數據集中的檢測效率。模型采用MATLABC++混合編程,其硬件運行環境為:Intel(R) Core (TM) i7-6700 CPU @ 3.40 GHz,軟件環境為Windows 10,MATLAB 2017a和VS 2015,其平均運行時間的計算結果如表3所示。從結果可以看出,在這兩個數據集中,模型的平均運行時間差距不大,分別為21 ms和23 ms;經過換算可得出,模型的運行速度均超過43幀/s。因此,本文提出的模型在該軟、硬件環境中能夠滿足對瞳孔和眼角點的實時檢測。

表3 模型運行時間結果
5 結束語
本文提出一種由粗到精定位的列車駕駛員眼角點和瞳孔點定位方法。該方法采用SDM模型對進行粗定位并提取眼睛區域,采用圓形滑動模板遍歷眼睛圖像,根據眼睛瞳孔區域灰度值的特點用加權遍歷積分投影算法對瞳孔進行粗定位。將瞳孔中心點和眼角點作為初始點,采用基于LBF的定位技術對眼角點和瞳孔位置進行精確定位。實驗結果表明:本文提出的方法能夠魯棒地定位瞳孔和眼角點位置,其瞳孔定位精度明顯優于其他方法。因此,利用該方法能夠獲取更加精確的瞳孔相對于眼角點的運動信息,為研究列車駕駛人的視線方向、注意力分散和疲勞駕駛識別方法打下了基礎。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
