大學生英語分級閱讀智能文庫構建研究
2019-10-31 04:14:07楊江曹欣雨
科教導刊·電子版 2019年24期
楊江 曹欣雨

摘 要 該文主要從研究背景、設計理念、文本收集、指數(shù)測量等方面介紹了英語分級閱讀智能文庫的構建過程。智能文庫基于中國大學生不同的閱讀動機,涵蓋了以需求為導向的四種英語閱讀材料類型,借助國外的藍思文本分析器,實現(xiàn)了學生的閱讀水平與讀物的閱讀難度之間的匹配,為大學生提供智能測試、智能選書和智能推薦服務,幫助其選擇符合其閱讀水平和閱讀興趣的英文讀物。
關鍵詞 英語分級閱讀 文庫建設 文本難度
中圖分類號:G642文獻標識碼:A
0引言
英文閱讀是學生英語學習的重要環(huán)節(jié),也是學生獲取信息的方式之一。然而,隨著高等教育的普及,中國大學生英語水平也參差不齊,傳統(tǒng)的英語課堂中的教材難以適應每個學生的英語水平,也難度滿足學生個性化的閱讀需求。因此,學生有必要考慮適當?shù)恼n外英文讀物,以適應和滿足其發(fā)展目標。本研究團隊通過調研發(fā)現(xiàn)學生在選擇英文讀物時存在一定困難,即無法選擇難度適宜的閱讀材料。一旦選擇不合適的材料,尤其是難度過大的材料,學生可能會產(chǎn)生不斷查閱生詞、邊讀英文邊讀中文、放棄閱讀等不良閱讀習慣。本研究以這一現(xiàn)實問題為出發(fā)點,試圖建設一個英語閱讀文庫,幫助中國大學生學生找到難度合適的閱讀材料,同時兼顧其個性化的閱讀需求。
分級閱讀(Leveled Reading)是按照讀者的閱讀水平、興趣愛好等要素為不同讀者提供不同讀物的閱讀策略和方法。早在19世紀,美國著名的應用語言學家Stephen D. Krashen在“語言輸入假說”和“情感過濾”理論就體現(xiàn)了分級閱讀理念,他認為人類只有在獲得可理解性的語言輸入時,才能習得語言。“語言輸入假說”中的“i+1”理論認為,“i”表示學習者當前的語言水平,“1”則表示的是略高于學習者當前語言水平的語言知識。輸入的語言材料高于或低于其現(xiàn)有水平,都不利于其語言學習。他還認為要真正產(chǎn)生良好的二語習得效果,輸入的語言材料中的語言成分必須盡可能可被學習者理解。他提出的情感過濾是學習者在二語習得過程存在的影響語言吸收的消極因素,即動機、自信心和焦慮感。學習者只有在學習動機強烈,有自信,無焦慮感的條件下才能有效地進行二語習得。
隨后這一理念在國外、尤其在歐美國家被廣泛接受并不斷發(fā)展。現(xiàn)今歐美地區(qū)普遍使用的分級閱讀標準體系主要有藍思分級閱讀框架、發(fā)展性閱讀評估分級體系、指導性閱讀分級體系、閱讀能力等級體系等。但國外的分級體系并不適合中國學生,尤其是中國大學生這一閱讀需求特殊的群體。他們普遍面對著升學應試、專業(yè)研究、職場工作等現(xiàn)實壓力,且時間和精力十分有限,所以他們需要更有針對性的閱讀材料輔助其英語學習。
在本研究領域或相關課題中,諸多國內學者對我國學生的英語分級閱讀模式已進行了一定教學實踐與探索,這對中國英語閱讀教學范式變革產(chǎn)生了重要影響。但絕大部分學者更關注中小學生的英語分級閱讀,對大學生的英語分級閱讀方面研究甚少,且目前研究也大都存在構建該模式的教學理論上,極少能最大程度地提供一套精準量化的分級閱讀方案并實踐。
因此,在國內大學生英語閱讀水平參差不齊、國外的分級閱讀體系的局限性和專門面向中國大學生閱讀需求的量化分級閱讀方案尚為空白的背景下,我們完成了中國大學生分級閱讀智能文庫的建設,并以網(wǎng)站的形式呈現(xiàn)。其特點如下:
(1)根據(jù)情感過濾理論,閱讀材料的選擇以大學生的特殊閱讀需求為導向,收集的材料致力于涵蓋各專業(yè)領域、場合和用途,并蘊含深厚人文思想。
(2)根據(jù)輸入假說理論,文庫的智能推薦遵循自行建立的 “量化分級體系”,學生的推薦讀物難度控制在一定可理解范圍內,但比當前的閱讀水平高。
(3)智能文庫經(jīng)過多次測試與改進,進一步完善文庫的用戶體驗。
1構建思路
智能文庫的設計思路遵循我們自主構建的“量化分級體系”。“量化分級體系”將Krashen語言輸入假說和“情感過濾”理論作為分級的理論基礎,以中國大學生的英語閱讀實際為現(xiàn)實導向,試圖將讀者的閱讀水平與讀物的難度進行量化,為大學生提供可理解的輸入材料,同時兼顧大學生的閱讀需求,精心選擇符合其現(xiàn)實需求的閱讀材料,激發(fā)學生強烈的閱讀動機。
該體系的量化分級對象由兩部分構成。一是中國大學生的不同的閱讀水平。二是各種英文閱讀材料的難易程度。為了衡量和銜接這兩個量化對象,我們借鑒了美國藍思分級閱讀框架體系,使用了一個統(tǒng)一的度量單位——藍思值(Lexile,簡寫“L”)。藍思值可以用來標記材料的閱讀難度,也可以表示學生的當前閱讀水平。
借助藍思文本分析器(The Lexile Analyzer),可以直接測量并確定英文閱讀材料的難度指數(shù),即藍思值,也可以間接衡量學生的閱讀水平指數(shù)。衡量學生閱讀水平的原則是學生在自身能力范圍內所能勝任的難度最大的閱讀材料。學生所能勝任的閱讀材料難度的最大值,即代表該學生的閱讀水平值。確定學生閱讀水平指數(shù)的實現(xiàn)途徑是搭建一個閱讀測試平臺,制定靈活的測評機制,學生通過進行一系列閱讀理解測試,獲得閱讀水平指數(shù)。
學生閱讀水平測試平臺以“量化分級體系”為參照標準,其所有試題都應保證其來源的權威性和可靠性,試題應標記難度指數(shù),并盡量保證試題的難度范圍足以涵蓋中國大學生的閱讀水平,且各個難度區(qū)間數(shù)量均衡。量化分級體系規(guī)定的難度指數(shù)范圍為500L-1900L,每個難度區(qū)間試題的數(shù)量應不少于100道,便于系統(tǒng)隨機抽題進行測試,保證測試結果的可靠性。其次,測試平臺應遵循我們制定的“預估+調整”的測評機制。小組將測試材料根據(jù)考試類別和難度區(qū)間兩個方面進行了精確劃分,首先,讀者應根據(jù)自己的閱讀動機,選擇進行的英語考試類型,然后系統(tǒng)在此基礎上從該考試類型的題庫中隨機抽取1道閱讀理解,如果學生的答題準確率低于60%,可以選擇換題重測或選擇降低試題難度等級,系統(tǒng)為其隨機抽取難度指數(shù)區(qū)間降低100L的試題;若學生的準確率介于60%-80%,學生的閱讀水平數(shù)值即為該閱讀材料的難度指數(shù);若學生的準確率高于80%,學生可選擇加大測試難度,即為其隨機抽取難度指數(shù)升高100L的試題,該生的閱讀水平指數(shù)等于能夠勝任的閱讀材料的難度指數(shù)最大值。
“量化分級體系”下的智能書庫由三大模塊構成:智能測試、智能選書和智能推薦。這三個模塊是學生體驗系統(tǒng)功能的步驟,也是研究者進行系統(tǒng)研究和開發(fā)的過程。智能測試模塊是一個學生英語閱讀水平測試平臺,制定測評機制,提供一系列閱讀理解試題,通過測試的學生可以準確評估自身閱讀水平,確定閱讀水平指數(shù),為之后的系統(tǒng)推薦提供參考依據(jù)。
智能選書模塊中,基于對學生的多元閱讀需求的深度挖掘,我們?yōu)閷W生提供種類齊全、主題豐富的英文材料,學生可以給自己的需求訂閱不同種類的閱讀材料,或選擇自己感興趣的文章、書籍類型或主題。智能推薦模塊中,系統(tǒng)會根據(jù)參照平臺提供的學生閱讀水平數(shù)值,結合學生已選擇的閱讀材料類型或主題,自動從書庫中推薦符合其水平、滿足其需求的閱讀材料,幫助大學生選擇合適的英文閱讀材料。
系統(tǒng)的建設的出發(fā)點是竭力實現(xiàn)面向中國大學生的英語閱讀智能推薦。各個模塊的建設都是為了這一總目標服務。其中測試平臺模塊將幫助學生對自己的閱讀水平認知更加清晰明確,避免盲目選擇閱讀材料難度過大或過小;幫助學生通過具體的閱讀水平指數(shù)的變化找到進步空間、樹立閱讀目標、制定閱讀計劃等;激發(fā)閱讀學生的閱讀主觀能動性,促進閱讀習慣養(yǎng)成。
2構建過程
大學生英語分級閱讀智能書庫是一個由5萬多篇英語文章、2萬多本英文原著和1000套測試題組成的龐大的數(shù)據(jù)庫。主要的建設過程包括文本收集、文本預處理、文本標注、指數(shù)測量和系統(tǒng)開發(fā)。
2.1文本收集
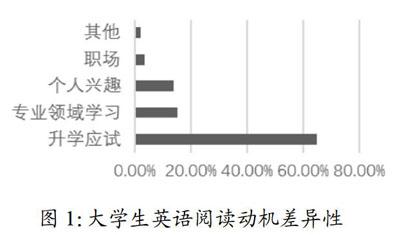
文本收集的依據(jù)是選擇與中國大學生閱讀動機緊密相關的英文材料,有針對性地滿足大學生的閱讀實際需求。基于這一思路,我們首先對全國大學生的英語閱讀動機進行了抽樣調查,研究了大學生閱讀動機的差異性(見圖1)。其次,根據(jù)大學生的實際閱讀需要,我們確定了文本選擇的四種類型,包括升學應試類、專業(yè)學習類、職場工作類和文學素養(yǎng)類。擬定文本類型后,使用網(wǎng)絡爬蟲技術大批量獲取文本。
2.1.1動機研究
研究小組通過問卷調查的方式調查了來自全國各地的高校大學生3000名的英語閱讀動機。其中接近65%的大學生的英語閱讀動機是順利通過英語考試,如大學英語四六級、考研、出國留學考試等。一部分學生是為了更好地進行專業(yè)領域學習,如閱讀國際教材、了解國際新聞等。一接近15%的學生的閱讀動機是提升文學素養(yǎng),他們以個人興趣為出發(fā)點爾,喜歡閱讀英文小說,認為閱讀小說是一種思想交流、情感共鳴。研究表明,學生長期堅持閱讀英語原版小說,活的文化語境更有利于閱讀習慣的養(yǎng)成,有利于學生在語言表達時更加地道。極少數(shù)學生閱讀英文材料是為了更好的適應將來的工作環(huán)境,主要體現(xiàn)在面試求職、國外出差時的正常交際、特定場合下的談判溝通等。
2.1.2文本收集類型
根據(jù)調查結果,我們面向大學生的英語顯示閱讀需求,以實際需求為導向,確定了智能書庫需要收集的四種文本材料類型:英語考試類、英語學習類、職場英語類和原版小說類。其中英語考試類材料以閱讀理解的形式納入測試題庫中,作為測試學生英語水平的材料來源。
英語考試類文章的具體類別為大學英語、英語專業(yè)、考研英語、出國留學等,文章來源是各種考試閱讀真題。英語學習累文章的具體類別是英文刊物、新聞時訊、學科基礎和專業(yè)教材等,文章來源是China Daily及各種外刊、VOA等新聞廣播、各學科的英文原版教材等。英語職場類文章包括精英演講、面試英語、外貿(mào)英語、商務會話等,文章來源是各專業(yè)領域的名人演講稿、面試和外貿(mào)相關的教材等。英語原版小說的主題有金錢、權利、愛情、犯罪、驚悚、懸疑、成長、友誼、人生、宗教、動物、諷刺等40余種。英語原版小說將近1萬本,一本小說同時標注有2-4個主題,為學生創(chuàng)造了更大的選擇空間。收集過程盡量保持各個分類中材料類型和數(shù)量上的平衡。
2.2文本預處理
文本預處理包括對收集到的4萬多篇文章、近1萬本小說進行文本核對、格式檢查和信息標注。信息標注在Microsoft Office Excel電子表格軟件中進行,標注完成后利用程序將SVC格式文件轉換成SQL語句文件,將其導入數(shù)據(jù)庫中。
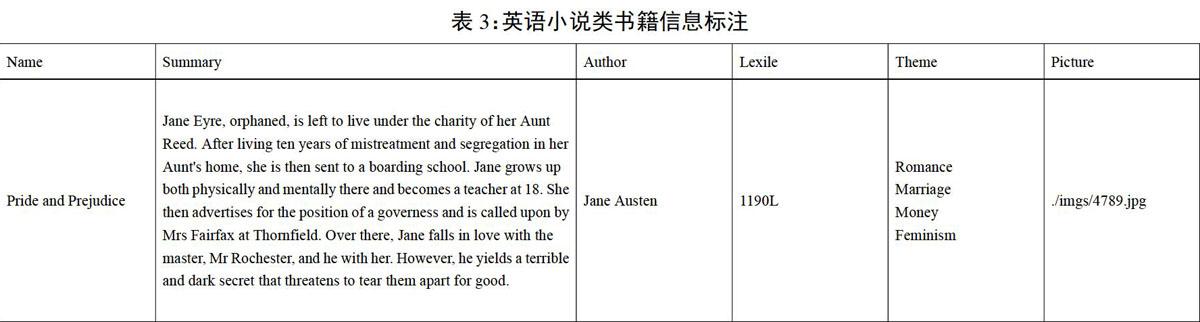
標注內容由材料類型決定。文章類標注內容包括:文章標題、適用類型、字數(shù)和難度指數(shù)。書籍標注內容包括:書名、封面圖片、作者、主題、摘要、目錄和難度指數(shù)。其中文章類中的適用類型,和書籍類中的主題、摘要部分由小組查閱資料、反復討論確定。表1和表2列舉了部分英語文章和小說的詳細標注信息。
2.3指數(shù)測量
指數(shù)測量是英語智能文庫構建過程中的重要環(huán)節(jié),直接關系到讀物難度與讀者閱讀水平的匹配。根據(jù)測量的對象,指數(shù)測量劃分為兩個部分:讀物難度測量和學生閱讀水平測量。針對讀物難度的測量,我們使用的工具是由國外MetaMetrics研發(fā)的藍思分級閱讀框架下的藍思文本分析器(Lexile Analyzer)來獲得讀物難書指數(shù);針對學生閱讀水平的測量,我們遵循了“分級量化體系”的原則之一:即學生的閱讀水平指數(shù)直接等于其能勝任的最大難度的測試文章的難度指數(shù)。
2.3.1測量工具
該分析工具主要從兩個維度來衡量讀物難度,即語義難度(Sematic Difficulty)和句法難度(Syntactic Complexity)(Lennon&Burdick,2004)。文本復雜度的測量單位是Lexile值(Lexile mesurement,L)。
藍思文本分析器衡量語義難度的基本理念是詞匯頻率。一個詞匯在閱讀中出現(xiàn)的頻率越高,即越常出現(xiàn),讀者就會越熟悉,相應閱讀起來的難度就會越低,反之亦然。詞匯頻率是通過大型語料庫計算得出的頻率。具體計算方式為:在6億詞匯量的語料庫中,計算出某一詞匯在每五百萬詞中出現(xiàn)次數(shù)的對數(shù)(Log),并以此對數(shù)作為詞匯頻率。
分析器測量文本的句法難度是通過易讀性公式進行計算的。計算一篇文章的難度時會先將文章分成125到140個不等的單詞分段,通過一個代數(shù)公式(Lexile equation),把該片段的詞匯頻率和句子長度綜合運算,得出每一片段的藍思值,最后再根據(jù)對所有片段的藍思值進行平均,從而計算出這篇文章的藍思值。
2.3.2文本難度指數(shù)
經(jīng)過文本收集和預處理,小組人工將4萬多篇英語文章和近1萬本英語小說一本本導入藍思文本分析器,測量每一本的藍思值,并將該指數(shù)標注在預處理表格中的文本難度的空白部分。由于篇幅有限,該論文僅列舉部分英文文章和小說的信息標注結果,英語文章以CET4閱讀和China Daily為例,英語小說以簡·奧斯汀的代表作《傲慢與偏見》(Pride and Prejudice)為例。在測量所有讀物的藍思值后,我們統(tǒng)計了這些讀物所在的藍思值區(qū)間,為了符合預計要求的文本讀物難度,即文庫中的讀物難度指數(shù)均控制在500L-1900L之間,該指數(shù)區(qū)間外的文本將被剔除。
2.4系統(tǒng)開發(fā)
2.4.1網(wǎng)站技術分析
本項目建設的大學生英語分級閱讀智能文庫以網(wǎng)站形式呈現(xiàn),網(wǎng)站在Ubuntu操作系統(tǒng)環(huán)境下運行,利用Mysql數(shù)據(jù)庫軟件創(chuàng)建數(shù)據(jù)庫,主要開發(fā)語言是PHP,圖片的處理工作使用了Adobe Photoshop CC 2019,并對網(wǎng)頁進行不斷優(yōu)化,提升用戶體驗。由于PHP的執(zhí)行網(wǎng)頁速度較快,開發(fā)性和延展性良好,所以我們選擇了的網(wǎng)站后臺開發(fā)語言是PHP。數(shù)據(jù)庫管理系統(tǒng)我們使用了MySQL,可視化操作界面是PhpMyAdmin,直接通過網(wǎng)頁遠程操作位于云服務器上的數(shù)據(jù)庫。網(wǎng)站框架使用了CSS、HTML5和JS。CSS框架簡化了web前端開發(fā)的工作,提高了工作效率。HTML5框架可以讓用戶拜托對平臺的依賴,用戶打開瀏覽器,直接就可以訪問到所需的信息;用戶可以離線使用,也能對頁面文檔進行緩存,下次訪問時更加快捷;并且HTML5具有跨平臺的特性;JS框架安全性高,不被允許訪問本地的硬盤,且不能將數(shù)據(jù)存入服務器,不允許對網(wǎng)絡文檔進行刪除和修改,從而有效地防止數(shù)據(jù)的丟失或對系統(tǒng)的非法訪問。
2.4.2建設策略
網(wǎng)頁的設計和網(wǎng)頁的制作涉及多方面的專業(yè)知識,因此在開發(fā)時我們先進行了全面規(guī)劃,根據(jù)網(wǎng)站的內容與功能寫好了需求計劃書、確定了網(wǎng)站的主題,對網(wǎng)站進行整體的規(guī)劃。另外對于網(wǎng)站相關素材的收集、開發(fā)和測試網(wǎng)站、網(wǎng)站域名空間的申請與備案提前寫好了網(wǎng)站策劃書。
網(wǎng)站以橘色和桃紅色、白色為主色調,頁面布局以簡潔明了為主,在網(wǎng)站上方設置導航欄方便學生頁面跳轉。網(wǎng)站主要針對在校大學生閱讀需求展開設計,保證網(wǎng)頁的主題簡潔和使用方便時網(wǎng)站建設的主要切入點,進行網(wǎng)站整體系統(tǒng)架構的規(guī)劃。本網(wǎng)站主頁面框架圖如圖2所示。
后臺建設:
(1)閱讀測試題庫后臺。閱讀測試題庫包含三個數(shù)據(jù)表:閱讀題表、選項表和答案表,它們之間通過唯一的ID相聯(lián)系,并且閱讀題表含有不同的等級分類。通過MySQL的圖形化界面PhpMyAdmin將經(jīng)過處理的題庫數(shù)據(jù)導入到數(shù)據(jù)表中,為題庫后臺提供數(shù)據(jù)支持。閱讀測試題庫后臺處理流程主要有五個步驟::第一,接受瀏覽器返回的用戶預估閱讀水平情況信息;第二,題庫中隨機抽取相應試題;第三,將抽取到的土木轉換為HTML文件;第四,將HTML頁面文件發(fā)送到用戶瀏覽器病顯示給用戶;第五,用戶開始答題。
(2)讀物后臺。閱讀文庫為用戶提供電子書的閱讀和下載,它的實現(xiàn)過程不同于題庫。電子書是以PDF和TXT文本方式保存在云服務器端的,我們用了一個瀏覽器顯示PDF文件的腳本文件PDF.js,利用該腳本文件將位于云服務器上的PDF文件顯示給用戶。分級文庫包含了一個閱讀材料信息表,保存了所有文章和書籍的標注信息。智能文庫的后臺處理主要有五個步驟:第一,接收到通過用戶測試得到的藍思值區(qū)間和選擇的某一讀物類型;第二,通過算法將符合條件的書籍信息從書籍信息表中提取出來;第三,將提取出來的信息進行處理添加到HTML頁面,并返回給用戶;第四,如果用戶選擇閱讀或下載該書籍,則通過書籍名計算出書籍文件的路徑,然后根據(jù)書籍文件路徑將書籍內容利用PDF.js顯示給用戶。
3測試效果與改進
為了發(fā)現(xiàn)網(wǎng)站存在的不足,研究小組在本校招募了由不同年級、不同學院的25名被試。經(jīng)測試與分析,我們發(fā)現(xiàn)網(wǎng)站中存在的一些問題,并且在問題發(fā)生處增加質量控制措施。測試內容包含兩個部分,即用戶體驗測試和網(wǎng)站測試。
用戶體驗測試中,我們獲得了寶貴的用戶反饋,如網(wǎng)站頁面美觀整潔,功能齊全;讀物種類齊全,且自行下載,離線閱讀;英語水平測試比較靈活,測試結果較為精準。值得改進的地方是文庫下載的閱讀材料中,遇到生詞時不支持點擊查詞功能,我們的改進方法是試圖開發(fā)英文字典詞庫鏈接技術,比如歐陸詞典、朗文詞典等,讀者遇到生詞可以點擊查詢。
網(wǎng)站測試中,我們主要進行了功能測試,弱網(wǎng)測試和性能測試等。負載測試,測試對象分別在一天中四個不同時間段登錄網(wǎng)站,測試網(wǎng)站速度,同時通過相應的軟來測試負載,能允許多少個用戶同時在線。兼容性測試,測試對象在不同的瀏覽器下登錄網(wǎng)站,觀察網(wǎng)站頁面外觀是否一致,檢測網(wǎng)站兼容性。測試結果是測試結果:網(wǎng)頁能在多個瀏覽器中使用,頁面布局整齊協(xié)調,界面分辨率合格,能夠顯示全部功能,能在不同瀏覽器中使用,但低版本瀏覽器比高瀏覽器中的性能要差一些,需要使用滾動條才能顯示所有界面。其他功能正常。我們提出了改進方案,即優(yōu)化網(wǎng)站內部頁面布局,精簡頁面,以方便用戶能夠快速的找到所需要的頁面。
4結論
中國大學生分級閱讀智能文庫的建設遵循了我們自行構建的“分級量化體系”,是專門面向中國大學生的現(xiàn)實閱讀需求的量化分級閱讀方案。在國內這一研究尚為空白的背景下,大學生英語分級閱讀智能書庫構建要解決的難題很多,包括對如何將讀物的閱讀難度進行量化,學生的閱讀水平如何測試,選擇何種閱讀材料以滿足大學生的現(xiàn)實閱讀需求,收集到的文本處理,以及后期的系統(tǒng)開發(fā)等。這一智能書庫結合了中國讀者的實際閱讀需求,幫助讀者測量自己的閱讀水平,找到適合自己水平和興趣的讀物,促進了大學生養(yǎng)成持續(xù)良好的英語閱讀習慣,提高英語閱讀能力。
參考文獻
[1] Krashen,S.D.Principles and Practice in SLA[M].Oxford:Pergamon Press,1982.
[2] 王連雙.大學英語閱讀教學中的分級閱讀模式研究[J].吉林廣播電視大學學報,2016.
[3] 胡鳳娟,程寧寧,王宏宇.從“雙面假設”理論談英語閱讀分級教學[J].教學與管理,2010.
[4] 章辭.英語易讀性研究:回顧與反思[J].湖南工程學院學報,2010.
[5] The Lexile Framework for Reading[J].Popular Measurement,1998.
[6] 羅德紅,余婧.美國藍思分級閱讀框架:差異化閱讀教學和測評工具[J].現(xiàn)代中小學教育,2013.
