面向高維數據環境的個性化推薦質量控制模型研究
2019-10-30 13:04:22宋梅青
現代情報 2019年11期
宋梅青


摘 要:[目的/意義]在高維數據環境下,推薦的精準度和實時性存在相互制約的現象。如何在精準度與實時性之間取得平衡,實現對推薦質量的有效控制是值得研究的問題。[方法/過程]本文首先分析了高維數據環境的成因及其對推薦質量的影響,在此基礎上構建了一種個性化推薦質量控制模型,該模型先評估推薦質量在精準度和實時性兩個方面的損失,再結合應用環境,得到相應的質量控制策略。[結果/結論]實驗分析的結果證明該模型可以在高維數據環境下實現對推薦質量的有效控制,讓推薦系統可以更好地適應不同的應用環境。
關鍵詞:高維數據環境;大數據;個性化推薦;推薦質量;控制;模型;應用環境
DOI:10.3969/j.issn.1008-0821.2019.11.003
〔中圖分類號〕G202 〔文獻標識碼〕A 〔文章編號〕1008-0821(2019)11-0023-07
Abstract:[Purpose/Significance]The accuracy and the real-time performance of recommendation exist mutual restraint under high dimensional data environment.How to achieve the balance between accuracy and real-time performance and to realize effective control of recommendation quality are problems worth studying.[Method/Process]At first,the causes of high dimensional data environment and its affects to recommendation quality were analyzed.On this basis,a quality control model of personalized recommendation was constructed.This model first assessed the loss of recommendation quality from two aspects of accuracy and real-time performance and then combined with the application environments to get the corresponding quality control strategies.[Result/Conclusion]The result of experimental analysis illustrated that the model was able to realize effective control of recommendation quality under high dimensional data environment,so that personalized recommendation system could better adapt to different application environments.
Key words:high dimensional data environment;big data;personalized recommendation;recommendation quality;control;model;application environment
個性化推薦技術在電子商務、社交、廣告和新聞領域都取得了商業上的成功,受到眾多學者的關注。精準度和實時性是個性化推薦質量的兩個核心指標,推薦的精準度越高、實時性越強,就表示推薦質量越好。大數據時代的來臨,高維數據環境對推薦系統來說已經成為常態。在高維數據環境下,個性化推薦的精準度和實時性存在相互制約的現象,即:在追求更高精準度的同時,其推薦實時性往往會下降,反之如果想實現更高實時性則精準度也會受到影響。因此,當應用環境變化需要調節推薦的精準度或者實時性時,就必須在它們兩者之間取得一個平衡,不能為了提升一個推薦質量指標,而導致另一個推薦質量指標的大幅下降,這樣系統的推薦質量是無法保證的。由此,本文提出一種面向高維數據環境的個性化推薦質量控制模型,該模型通過對比推薦質量在精準度和實時性兩個方面的損失,來尋找有效的推薦質量控制策略,讓推薦系統可以更好地應對不同的應用環境。本研究不僅豐富了個性化推薦的理論體系,也為實際應用提供借鑒。
1 相關研究
個性化推薦是通過一定的技術手段來挖掘數據中的用戶興趣,再根據用戶興趣挖掘的結果來篩選待推薦的項目,最后生成推薦集合推送給目標用戶。目前有關個性化推薦的研究中,比較有代表性的有:
1)根據內容相似性來實現推薦。安悅等[1]提出一種基于內容的熱門微話題個性化推薦算法,該算法通過對比內容的相似性為用戶尋找感興趣的微話題,實驗結果表明該算法可以在一定程度上解決微博數據過載的問題,實現較好的推薦效果。王嫣然等[2]提出一種基于內容過濾的科技文獻個性化推薦算法,該算法將訪問時間權重和文獻重要度兩種概念與內容過濾相結合,實現了推薦精準度的提升。王潔等[3]先根據歷史瀏覽記錄對有相同興趣的用戶進行聚類,再通過內容相似性挖掘尋找推薦項目,實驗證明該個性化推薦方法可以有效提升推薦的精準度。
2)根據社交網絡中的用戶關系實現推薦。陳婷等[4]提出一種融合社交信息的個性化推薦方法,該方法將用戶評分相似度與社交網絡中的信任關系兩者相結合來尋找最近鄰,結合用戶自身偏好和最近鄰的影響實現評分預測,實驗結果證明該算法可以提升推薦的精準度。李鑫等[5]提出了一種基于興趣圈中社會關系挖掘的個性化推薦算法,該算法將興趣圈中的社會關系與矩陣分解模型相結合,實現矩陣分解的優化,實驗證明該方法在解決推薦冷啟動方面有較好的效果。Ma H等[6]將信任網絡與用戶評分結合,通過概率矩陣分解來優化推薦。景楠等[7]提出了一種基于用戶社會關系的好友個性化推薦算法,該算法將用戶在社會網絡中的影響力和社會關系相結合實現推薦算法的改進。
3)利用標簽信息來改進推薦效果。陳梅梅等[8]提出了基于標簽簇的信任張量模型,再通過計算簇內和簇間的信任強度,實現對傳統相似性計算的補充,從而改進個性化推薦的準確性。孔欣欣等[9]提出一種基于標簽權重評分的個性化推薦模型,并結合該模型對多類傳統推薦算法進行改進,實驗證明了該模型的有效性。李瑞敏等[10]通過分析用戶、標簽和項目之間的關系建立圖模型,在此基礎上將初步推薦列表與間接關聯集合進行綜合,實現對推薦算法的改進。
4)融合情境的個性化推薦。劉海鷗等[11]提出了一種對多種情境進行興趣建模的方法,該方法可以提升推薦的精準度。周明建等[12]用多維度建模法構建了知識情境模型,通過計算知識情境的相似性來尋找關聯知識并實現推薦,實驗表明該方法提升了個性化推薦的精準度。
5)基于協同過濾的個性化推薦。杜永萍等[13]將用戶間的信任關系與評分相似性相結合來尋找最近鄰,實現對傳統協同過濾推薦算法的改進。董立巖等[14]提出一種基于時間衰減的協同過濾個性化推薦算法,該算法將遺忘曲線和記憶周期融入協同過濾推薦中,以興趣衰減函數來優化評分相似性的判斷,實驗證明該算法可提高推薦的精準度。郭蘭杰等[15]提出一種融合社交網絡的協同過濾個性化推薦算法,該算法利用社交網絡中的朋友關系來進行評分矩陣的填充,可有效緩解數據稀疏性問題,實現算法的改進。郭弘毅等[16]提出一種融合社區結構和興趣聚類的協同過濾改進算法,該算法先識別社交網絡中的社區結構,再與用戶興趣聚類信息進行融合來共同優化矩陣分解模型,實驗證明該算法提升了推薦的精準度。
總體來看,目前針對個性化推薦的研究中,無論是優化相似性的度量方法,還是改進最近鄰的查找流程,或是優化矩陣降維的方法等等,其改進的思路都是通過對推薦算法的不同環節進行優化改進來提升推薦質量。大數據時代,推薦系統經常面對高維的數據環境,高維數據環境下推薦精準度和推薦實時性相互制約的現象,會嚴重影響推薦質量的穩定,讓推薦系統無法適應應用環境的變化,而目前恰恰缺少對該問題解決方法的研究。由此,本文提出一種面向高維數據環境的個性化推薦質量控制模型,為解決該問題提供參考。
2 推薦系統高維數據環境的形成原因
大數據時代用戶數據極大豐富,個性化推薦系統為了更好地感知用戶的興趣偏好,會通過不同渠道收集用戶的各類數據,并將它們集中存儲起來作為推薦算法的數據源。如果這些數據源中的數據具有很高的維度,那么推薦系統就處在高維數據環境當中。推薦系統高維數據環境的形成原因主要有以下兩點:
第一,用戶數和項目數的快速增長,導致推薦系統主數據源的維度大幅增加。個性化推薦系統是通過分析用戶已有消費或評分記錄,來判斷用戶的興趣,再在用戶未消費過的項目中匹配合適的推薦項目。因此,用戶消費或者評分的歷史記錄就是推薦系統的主數據源。隨著用戶數和項目數的快速增長,用戶歷史消費記錄矩陣或用戶對項目的評分矩陣都會大幅擴容,形成高維數據環境。
第二,由于數據之間存在關聯關系,附屬數據源的維度也會快速增長。上文提到推薦系統會收集各類用戶數據作為興趣感知源。本文將歷史消費信息與評分信息以外的數據統稱為附屬數據源。這些附屬數據雖然來源很多,數據類型和數據格式也很復雜,但它們都有一個共同特點,就是可以根據用戶的行為軌跡進行關聯。這樣一來不同類型的用戶數據不再是相互孤立的,而是通過這種關聯關系緊密地聯系起來。因此,當主數據源的維度增加時,附屬數據也必須進行相應擴容。比如將用戶背景信息、社交網絡、標簽等與歷史購買記錄或用戶評分進行融合來實現推薦時,當購買記錄矩陣或評分矩陣的維度增加時,與之對應的用戶背景信息、社交網絡信息或者標簽信息的數據維度也在增長,這些附屬數據維度的增長速度甚至快于主數據源本身,由此進一步促使了推薦系統高維數據環境的形成。
3 高維數據環境對個性化推薦質量的影響
精準度與實時性是個性化推薦質量的兩個核心指標,以下將分別介紹高維數據環境對推薦精準度和推薦實時性的影響,最后分析了精準度與實時性在高維數據環境下相互制約的原因。
3.1 高維數據環境對推薦精準度的影響
個性化推薦是通過分析用戶行為數據或用戶背景數據等信息來判斷用戶的興趣偏好。用戶的興趣是多方面,每個方向上都可能有潛在的興趣點,要想感知這些興趣,就需要有相應的用戶數據。總的來說,用戶興趣感知源越多,就越能從多個側面來推斷用戶的偏好。當推薦系統處于高維數據環境時,主數據源和附屬數據源都涵蓋了大量的有用信息,推薦系統可以利用不同的算法模型來挖掘用戶的興趣。從這個角度來說,高維數據環境對提升推薦精準度有正面的作用。比如推薦系統可以利用用戶背景數據與消費評價數據進行融合,在多個用戶背景維度上對其興趣進行細分,這樣預測出的用戶興趣的精準度會大大提高,同樣的結合項目本身的屬性或者社交網絡、信任關系等也可以提升推薦的精準度。總的來說,高維數據環境為推薦系統提供了豐富的興趣感知源,為推薦精準度的提升奠定了數據基礎。
3.2 高維數據環境對推薦實時性的影響
推薦實時性也是推薦質量的重要指標,當用戶訪問網站時,推薦系統必須快速地識別用戶的潛在意圖,并及時給予推薦,這樣用戶根據系統推薦進行進一步的選擇。如果推薦集合的計算時間太長,無法保證推薦的實時性,用戶可能跳轉到另外一個頁面,其興趣可能已經發生轉化,或者在新的頁面下已經沒有了推薦欄的設置,無法實現推薦。這樣系統的推薦質量會大大下降,用戶體驗也會降低。因此,保證推薦實時性對推薦系統來說非常重要。在高維數據環境下,用戶興趣感知源的增加,對推薦精準度來說是利好,但是對于推薦實時性來說,會使得興趣挖掘的計算復雜度大幅提升,從而導致系統開銷過大,直接影響推薦系統的響應。特別是將附屬數據源與主數據源進行融合挖掘時,計算復雜度的數量級會大大增加。此外,當大量用戶同時訪問時,系統的負擔會進一步加重,系統響應時間也會延長。總的來說,高維數據環境會降低推薦的實時性。
3.3 高維數據環境下精準度和實時性相互制約的原因 ?在高維數據環境下,系統要想改善推薦的精準度,就希望從不同角度來深入挖掘用戶的興趣偏好,這時需要調用的用戶數據會大幅增加。而調用數據的增加會使得興趣挖掘的計算量大幅提升,推薦實時性就無法保證。如果只調用很少的數據來挖掘用戶的興趣,雖然減少了計算量但無法深入感知用戶的興趣偏好,推薦精準度就很難保證,這就是造成推薦精準度和推薦實時性相互制約的原因。
推薦系統可以使用不同的算法來實現推薦,也可以通過多類型算法相互補充實現更高的精準度。因此,需要重點說明的是精準度與實時性的相互制約是針對整個推薦系統來說的。部分推薦算法通過模型的改進,可以在提高精準度的同時也提升實時性,但這只是局限在算法的層面,改進算法相對于原來的算法,在調用數據不變的情況下可以實現精準度與實時性的同時改進。但是,當推薦系統使用這種改進算法進行實際推薦時,其調用數據的越來越多,推薦實時性必然會下降。此外,還需要強調的是推薦精準度的提升不是無限的,達到局部的峰值以后會下降。
綜上,為實現高維數據環境下對推薦質量的有效控制,本文提出一種個性化推薦質量控制模型,下文將詳細介紹該模型的設計,并通過實驗分析驗證模型的有效性。
4 面向高維數據環境的個性化推薦質量控制模型4.1 模型的詳細設計
本文提出的面向高維數據環境的個性化推薦質量控制模型,包含6個主要步驟,具體如下:
4.1.1 對推薦系統的狀態進行標記
在高維數據環境下,推薦系統通過挖掘歷史數據中的用戶興趣來產生推薦,挖掘越深越耗時,但精準度會提升。放棄精準度的提升,降低挖掘深度就會節省時間,提升推薦的實時性。推薦系統通過調整挖掘深度來控制精準度與實時性的高低。設F={ft,0,1,2,3,…,k}為推薦系統處于不同挖掘深度時的狀態集合(非空集合),ft為F中的任意一個系統狀態,ft記錄了系統調用的推薦算法的相關信息以及調用數據的范圍。設wft表示推薦系統處于狀態ft時的推薦精準度,設dft表示推薦系統處于狀態ft時的推薦實時性。F中的每一個的系統狀態分別對應一組精準度與實時性的值。
4.1.2 計算推薦實時性
推薦實時性可以用推薦時間來反映,推薦時間越短實時性越好。然而使用推薦時間來直接表示推薦實時性不能反映算法挖掘的細節。由此,本文在衡量推薦實時性時采用算法計算量來替代推薦時間。所謂算法計算量,為推薦算法在所調用的數據中需要比對的用戶數或者項目數。在個性化推薦中,推薦時間與算法計算量成正比,即:算法計算量越大,推薦時間越長,其對應的推薦實時性越低。反之,算法計算量越小,其推薦時間越短,相應的推薦實時性越高。計算F中每個系統狀態下的推薦實時性,再將F中的系統狀態按照其對應的推薦實時性從高到低順序排列,形成一個系統狀態列表L。設系統狀態為ft時的算法計算量為Qft,即推薦實時性dft就等于Qft的值。
4.1.3 確定推薦實時性的臨界值
在個性化推薦中,系統會根據應用環境和用戶反饋,設置推薦實時性的臨界值。該臨界值就是推薦系統能夠接受的最長推薦時間,超過這個臨界值,則被認定無法實現即時的推薦,精準度的高低就失去了意義。由于本文采用算法計算量替代推薦時間來評價推薦實時性,所以推薦實時性的臨界值,就是算法計算量的上限值,設該上限值為B。將系統狀態列表L中推薦實時性超過臨界值B的系統狀態刪除,形成新的列表L1。
4.1.4 計算推薦精準度
計算h′ ft是為了測量其它系統狀態相對于基準狀態的實時性損失程度。因此,必須以Qf0為基準減去Qft,這種順序安排對應了質量損失的意義。先計算不同系統狀態下算法計算量的差值的絕對值,再判斷推薦實時性的方向系數,是為了分別展示推薦實時性的變化幅度和變化方向。
當推薦實時性損失h′ ft為正數時,表示與基準狀態相比推薦實時性下降了。當h′ ft為負數時,表示與基準狀態相比推薦實時性提高了。
根據上述公式,計算列表L2中除基準狀態f0以外的其它系統狀態的推薦精準度損失和推薦實時性損失。
4.1.6 建立推薦質量控制節點
將推薦精準度損失與推薦實時性損失的結果,按照列表L2中系統狀態的順序依次排列,可以對比不同系統狀態下精準度與實時性的損失程度,由此可建立推薦質量控制節點,推薦質量控制節點的格式如表1所示:
在個性化推薦中,系統都會盡量提升推薦的精準度,由于基準狀態的精準度最高,所以可以讓系統先以基準狀態進行推薦。當系統的應用環境發生變化,需要改變推薦精準度或推薦實時性時,為保證推薦質量的穩定,避免單一推薦質量指標的大幅下降,可以先設置質量控制的目標。根據質量控制目標的要求,找到相應的推薦質量控制節點。再通過推薦質量控制節點中系統狀態的信息,設置算法的挖掘深度和數據調用的范圍,由此可以實現有效的推薦質量控制。
4.2 仿真實驗
4.2.1 實驗說明
本次實驗以協同過濾推薦系統為例,對提出的個性化推薦質量控制模型進行驗證,并完整的展示該控制模型的全過程,為其他學者使用模型提供參照。實驗中的協同過濾推薦系統以用戶—項目評分矩陣為主數據源,以用戶背景中的年齡數據為附屬數據源,通過將用戶年齡數據與評分數據進行融合來實施興趣挖掘。具體算法過程如下:設與目標用戶年齡差值的絕對值小于等于K的用戶,為目標用戶的同年齡段用戶。算法先將與目標用戶處于同一年齡段的用戶查找出來,作為最近鄰的備選,再在同年齡段用戶群中利用評分相似性篩選出最近鄰用戶集合,最后計算項目的推薦分數,生成最終的推薦列表。實驗中K的取值不同,意味著算法挖掘深度和調用數據的不同,不同的K值對應著個性化推薦質量控制模型中的不同系統狀態。
4.2.2 數據來源
本實驗的數據來自美國明尼蘇達大學的Grouplens研究項目組提供的ml-100k數據集,該數據集中的文件u.data包含了943位用戶對1 682部電影的10萬條評分記錄,評分標準采用五分制,用戶打分越高表示用戶對該電影的滿意度越高。由u.data生成了5組訓練集和測試集。文件u.user記錄了用戶的背景信息。
4.2.3 結果分析
在實際應用中,設定同年齡段用戶的年齡差距不宜過大,本試驗依次測試k從0~6的試驗結果。根據本文提出的個性化推薦質量控制模型,依次計算k的取值從0~6的7個系統狀態下的推薦精準度與推薦實時性。
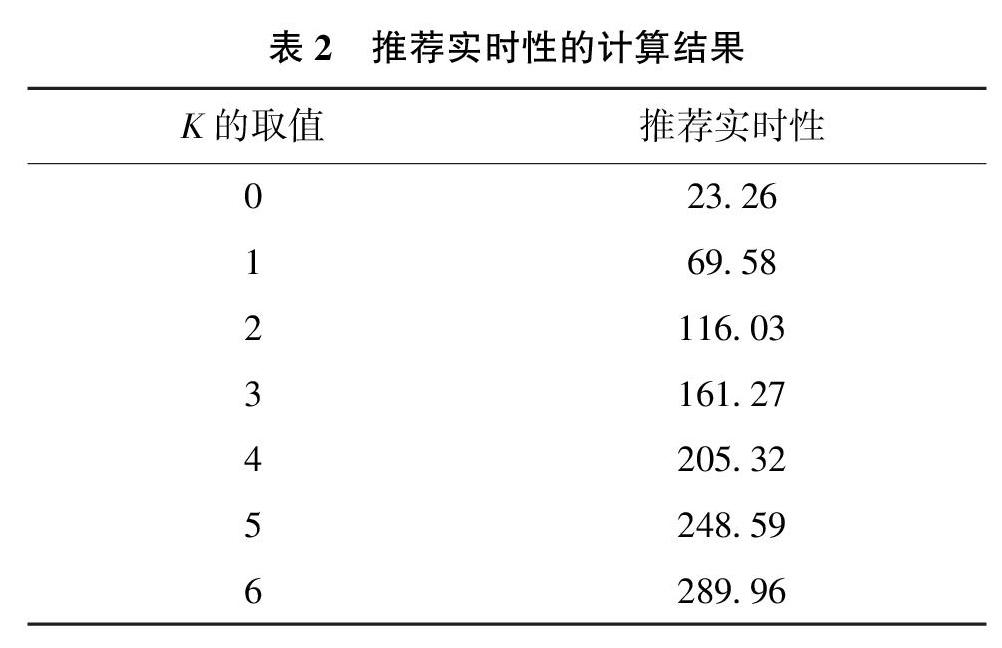
首先計算推薦實時性,本文用算法計算量替代推薦時間來評價推薦實時性。分析本實驗中的推薦算法可以發現,在算法的相似性計算環節,通過對比目標用戶與每一個潛在相似用戶之間的評分相似性程度來尋找最近鄰。因此目標用戶需要對比的潛在相似用戶數的變化直接反映了算法計算量的變化。先計算全部用戶在K取不同取值時的潛在相似用戶數,再取平均值可以作為推薦實時性的值,最終的計算結果如表2所示:
根據表2中推薦實時性的計算結果可以發現,隨著K值的增加,推薦系統查找潛在用戶的范圍逐漸擴大,推薦實時性逐漸下降。k=0時,推薦系統需要對比23.26個潛在相似用戶來實現推薦。k=6時,推薦需要對比的潛在用戶數增長為289.96個。本試驗設定推薦實時性的臨界值為總用戶數的30%,則臨界值為282.9。根據個性化推薦質量控制模型,刪除k=6的狀態,保留k等于0~5的6個系統狀態。計算這6個系統狀態下對應的推薦精準度,計算結果如表3所示。
根據表3中推薦精準度的計算結果可以發現,從當K從0增長到5的過程中,其推薦精準度剛好也是逐漸上升。根據個性化推薦質量控制模型,以K=5的系統狀態為基準狀態,計算其它系統狀態的推薦質量在精準度和實時性兩個方面的損失,將計算結果按照推薦質量控制節點的格式排列,結果如表4所示:
表4中,由于k=5為基準狀態,所以其推薦精準度和推薦實時性的損失都為0。通過表4可以發現,跟基準狀態相比,其它系統狀態的推薦實時性損失都為負值,這表示推薦實時性都提高了,與此同時推薦精準度損失都為正值,意味著推薦精準度都下降了。
按照K值從4到0的順序,將表4中推薦實時性損失的絕對值與其相應的推薦精準度損失,繪制成圖1。
通過圖1可以發現,k的值從4到0的變化過程中,推薦實時性提升的程度要大大高于精準度下降的程度。本實驗模擬一個應用環境來演示如何應用推薦質量控制節點來尋找合適的質量控制策略。系統剛開始以基準狀態進行個性化推薦。假設短時間內訪問用戶數大幅增長,系統需要提升推薦實時性,但是希望推薦精準度保持在基準狀態的90%以上的水平。參照表4中的推薦質量控制節點,從
圖1 精準度與實時性的損失對比圖
k=5時的系統狀態到k=2時的系統狀態,算法的計算量減少53%,推薦實時性大幅提升,而此時推薦精準度只下降了9%,符合質量控制目標的要求。由此可以根據k=2時的系統狀態實施推薦。如果應用環境進一步改變,系統可設定新的質量控制目標,再和上述過程一樣找到合適的推薦質量控制節點實施推薦,由此實現了對個性化推薦質量的有效控制。
5 結 語
本文以大數據時代為背景闡述了推薦系統高維數據環境的形成原因,并且詳細分析了高維數據環境對個性化推薦質量的影響。然后針對性地提出了一種個性化推薦質量控制模型,該模型可以在高維數據環境下通過對比推薦精準度與推薦實時性的損失,形成一系列推薦質量控制節點。再根據應用環境的差異,選擇合適的推薦質量控制節點。最后根據該控制節點的系統狀態信息,實現推薦系統的狀態切換,從而達到對推薦質量進行有效控制的目的。未來筆者將進一步對該領域進行深入研究。
參考文獻
[1]安悅,李兵,楊瑞泰,等.基于內容的熱門微話題個性化推薦研究[J].情報雜志,2014,33(2):155-160.
[2]王嫣然,陳梅,王翰虎,等.一種基于內容過濾的科技文獻推薦算法[J].計算機技術與發展,2011,21(2):66-69.
[3]王潔,湯小春.基于社區網絡內容的個性化推薦算法研究[J].計算機應用研究,2011,28(4):1248-1250.
[4]陳婷,朱青,周夢溪,等.社交網絡環境下基于信任的推薦算法[J].軟件學報,2017,28(3):721-731.
[5]李鑫,劉貴全,李琳,等.LBSN上基于興趣圈中社會關系挖掘的推薦算法[J].計算機研究與發展,2017,54(2):394-404.
[6]Ma H,Yang H,Lyu M R,et al.SoRec:Social Recommendation Using Probabilistic Matrix Factorization.In:Proc.of the Intl Conf.on Information and Knowledge Management.ACM Press,2008:931-940.
[7]景楠,王建霞,許皓,等.基于用戶社會關系的社交網絡好友推薦算法研究[J].中國管理科學,2017,25(3):164-171.
[8]陳梅梅,薛康杰.基于標簽簇多構面信任關系的個性化推薦算法研究[J].數據分析與知識發現,2017,(5):94-101.
[9]孔欣欣,蘇本昌,王宏志,等.基于標簽權重評分的推薦模型及算法研究[J].計算機學報,2017,40(6):1440-1552.
[10]李瑞敏,林鴻飛,閆俊.基于用戶-標簽-項目語義挖掘的個性化音樂推薦[J].計算機研究與發展,2014,51(10):2270-2276.
[11]劉海鷗,孫晶晶,蘇妍嫄,等.面向圖書館大數據知識服務的多情境興趣推薦方法[J].現代情報,2018,38(6):62-67,156.
[12]周明建,趙建波,李騰.基于情境相似的知識個性化推薦系統研究[J].計算機工程與科學,2016,38(3):569-576.
[13]杜永萍,黃亮,何明.融合信任計算的協同過濾推薦方法[J].模式識別與人工智能,2014,27(5):417-425.
[14]董立巖,王越群,賀嘉楠,等.基于時間衰減的協同過濾推薦算法[J].吉林大學學報:工學版,2017,47(4):1268-1272.
[15]郭蘭杰,梁吉業,趙興旺.融合社交網絡信息的協同過濾推薦算法[J].模式識別與人工智能,2016,29(3):281-288.
[16]郭弘毅,劉功申,蘇波,等.融合社區結構和興趣聚類的協同過濾推薦算法[J].計算機研究與發展,2016,53(8):1664-1672.
[17]項亮.推薦系統實現[M].北京:人民郵電出版社,2012:2-63.
[18]Pazzani M,Billsus D.Learning and Revising User Profiles:The Identification of Interesting Web Sites[J].Machine Learning,1997,(27):313-331.
(責任編輯:郭沫含)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
科技視界(2016年21期)2016-10-17 17:06:18
大眾理財顧問(2016年9期)2016-10-11 17:10:17
科技視界(2016年20期)2016-09-29 13:07:14
科技視界(2016年20期)2016-09-29 10:53:22
大眾理財顧問(2016年8期)2016-09-28 14:00:43
