申威眾核處理器上的三對角并行求解器*
2019-10-24 07:45:12王欣亮
計算機與生活 2019年10期
劉 侃,王欣亮,許 平,薛 巍,2+
1.清華大學 計算機科學與技術系,北京100086
2.國家超級計算無錫中心,江蘇 無錫214100
+通訊作者E-mail:xuewei@mail.tsinghua.edu.cn
1 引言
計算機數值模擬是科學和工程領域廣泛使用的研究方法。通過將真實的問題經過數學建模,可以用數值計算的方式對這些問題進行模擬。在計算機中,連續的真實世界往往用有限、離散的數據來表示。隨著人們對數值模擬精度的需求越來越高,高分辨率的數值模擬成為必需。而高分辨率帶來的大數據量和大計算量,則對數值計算的性能提出了非常高的要求。
偏微分方程是真實問題中常見的一類數學模型。對于含時的偏微分方程,主要的兩種求解方法是顯式方法和隱式方法。其中,隱式方法可以將微分方程的求解轉化為一系列線性方程組的求解。而對于一維空間的問題,隱式方法中最常見的線性方程組便是三對角方程。而在二維和三維空間的問題的求解中,常有需要求解大量一維子問題的場景,如交替方向隱式方法[1-2]、迭代求解器的預調節器[3]等。因此,三對角方程求解器廣泛地被應用于如計算機圖形學[1,4-5]、流體力學[2,4,6]、三次樣條計算[7]等眾多科學和工程領域。為了解決實際應用中在高維空間中求解大量一維子問題的需要,本文所討論的范圍是求解大量的、規模不太大的三對角方程的情況,求解器最重要的性能指標是吞吐率,即大量三對角方程的總未知數數量與總求解時間之比。
目前,對于三對角方程,中央處理器(central processing unit,CPU)、圖形處理器(graphics processing unit,GPU)等主流硬件平臺上都提出了高度優化的并行算法,同時有基礎數學庫支持。但是對于申威26010眾核處理器,還沒有一種算法能有效地利用其硬件特性來達到最大化的性能。針對這一現狀,本文綜合考慮的申威處理器的硬件特性,從計算量、訪存量和并行度等方面分析追趕法(Thomas algorithm)、循環消去(cyclic reduction,CR)算法和并行循環消去(parallel cyclic reduction,PCR)算法在申威處理器上可能達到的性能,設計了一種面向申威處理器的分布式CR 算法swDCR(Sunway-oriented distributive cyclic reduction)。其吞吐率相比主核上的追趕法達到了單精度43.9 倍和雙精度36.7 倍的加速,相比從核上的追趕法達到了單精度和雙精度均2.07倍的加速。
2 背景介紹
2.1 申威處理器架構介紹
申威26010 眾核處理器是中國第一款自主研發的眾核處理器。基于申威26010 處理器的神威太湖之光超級計算機,在2016 年到2017 年間曾是世界上計算能力最高的超級計算機,至2018 年11 月世界排名仍居第三。其理論計算能力達125 PFlops,Linpack[8]實測計算能力達到93 PFlops。
申威26010 眾核處理器架構如圖1 所示。一個處理器包含4個核組,每個核組具有765 GFlops的峰值計算能力和34.1 GB/s的理論訪存帶寬。每個核組包含一個主核(management processing element,MPE)和64 個從核(computation processing element,CPE),從核通過8×8網格的形式組織成從核陣列。
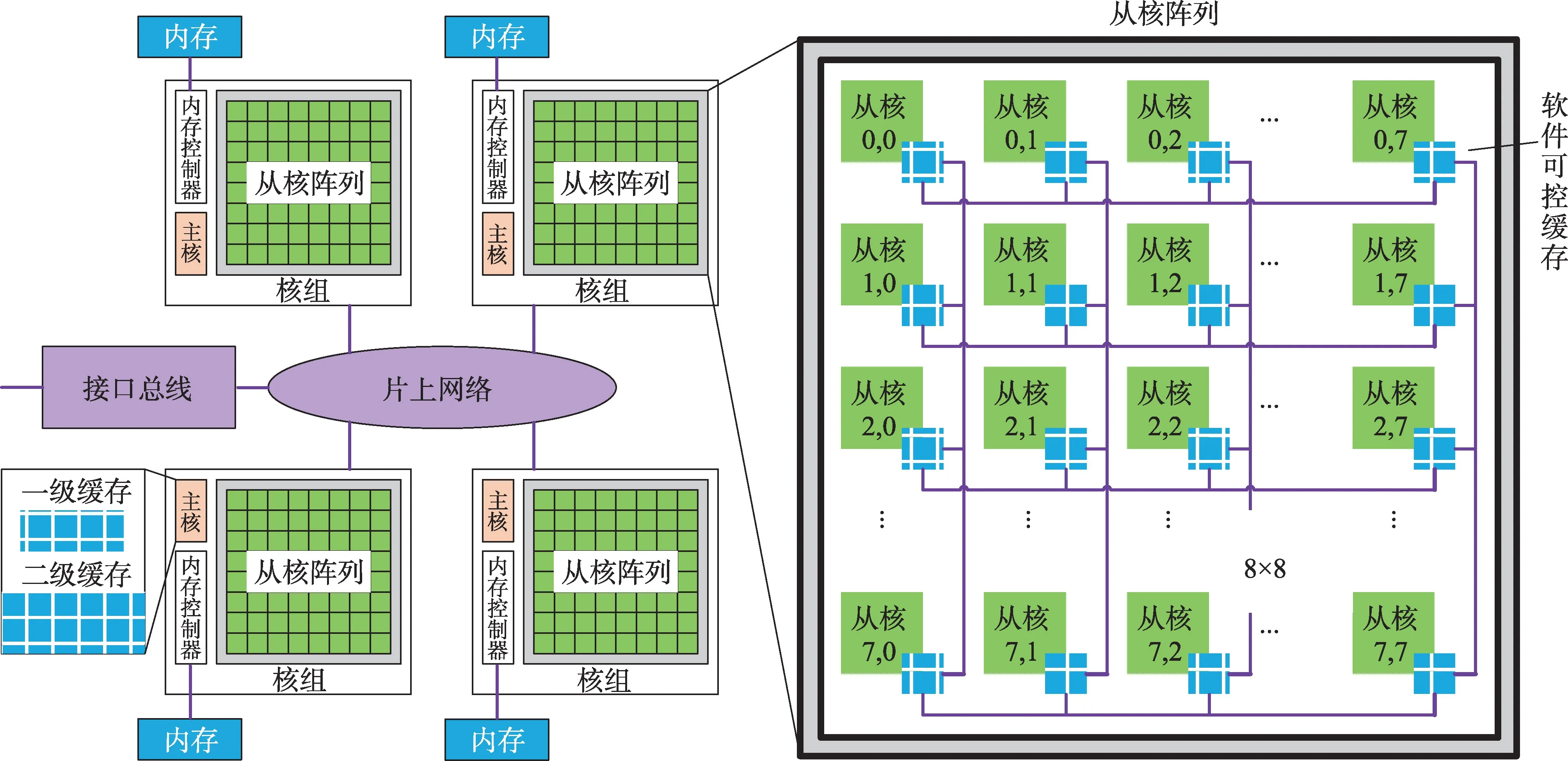
Fig.1 Architecture of Sunway 26010 many-core processor圖1 申威26010 眾核處理器架構
每個主核具有一個32 KB 一級指令緩存、一個32 KB 一級數據緩存和一個256 KB 二級緩存,每個從核具有一個16 KB 指令緩存和64 KB 便箋式存儲器(scratch pad memory,SPM)。除了SPM 以外的緩存都是由硬件控制,并對軟件透明的。SPM 的訪問延遲和帶寬與主核的一級緩存相當,但區別在于軟件可控。
從核對主存的訪問有兩種模式:全局讀入/寫出(global load/store,gload/gstore)和直接內存訪問(direct memory access,DMA)。gload/gstore完成主存和寄存器之間的數據傳輸,帶寬較低,適合細粒度的數據訪問;DMA 完成主存和SPM 緩存之間的數據傳輸,在訪問大段連續數據時帶寬較高,適合粗粒度的數據訪問。根據Xu等的測試[9],用一個核組64個從核運行Stream Triad測試程序,測得DMA的帶寬為22.6 GB/s,而gload/gstore的帶寬只有不到1.5 GB/s。
在從核組成的8×8陣列上,同行或同列的兩個從核之間可以通過寄存器通信高速互傳數據。每個從核具有一個寄存器發送緩沖區、一個寄存器行接收緩沖區和一個寄存器列接收緩沖區。在進行寄存器通信時,發送方從核會將數據放入發送緩沖區,并由核間互連將數據傳輸到接收方從核的行/列接收緩沖區中。在接收數據時,接收方從核會從行/列接收緩沖區取出數據。利用寄存器通信可以實現核間數據的高帶寬低延遲傳輸,根據Xu等的測試[9],兩個從核之間的點到點通信延遲不超過11 個指令周期,單個核組的從核陣列上的寄存器通信集合帶寬可以高達637 GB/s。寄存器通信沒有低層緩存的訪問開銷,無論是延遲還是帶寬,都遠遠優于目前主流硬件平臺上通過共享緩存實現的核間通信。
申威處理器的寄存器通信機制存在來源混淆問題。當一個從核1可能要從同列的從核0和從核2接收數據時,來自從核0和從核2的數據都會被放入從核1的寄存器列接收緩沖區中,當從核1從寄存器列接收緩沖區中取數據時便不能區分其來源。在必要時,需要加同步使得兩次寄存器通信先后進行,或將發送源的編號作為數據的一部分進行通信。
綜上所述,在設計申威處理器上的算法時需要考慮三個硬件特性:
SPM 緩存:軟件可控的特性使得它比硬件控制的緩存更靈活,但是需要考慮將哪些數據放入緩存中。
DMA:帶寬遠高于gload/gstore,但只適用于粗粒度的內存訪問。應盡可能避免零散的數據訪問。
寄存器通信:可以實現核間高速的數據傳遞,但只能在同行或同列間傳輸,而且應該避免來源混淆問題。
2.2 三對角方程求解算法的相關工作
三對角方程是一類形如Ax=d的方程組,其中A是三對角矩陣,d是已知向量,需要求解未知向量x,如圖2(a)所示。在內存中,矩陣A的三條對角線和右端向量d通常是連續存儲的,并且可以認為存在a0=cn-1=0,以保證數據對齊,如圖2(b)所示。
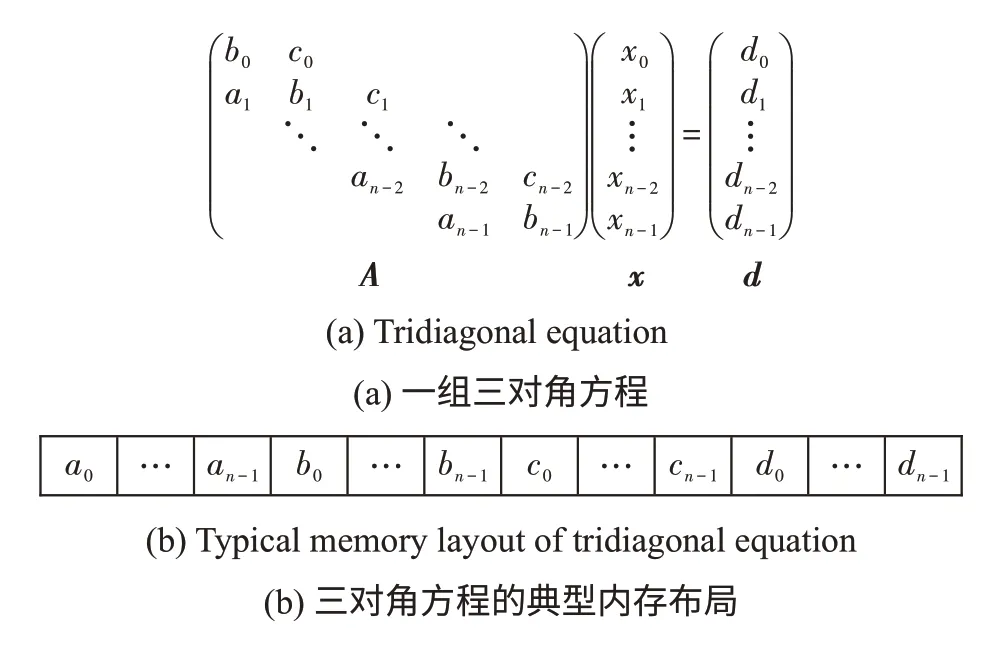
Fig.2 Definition of tridiagonal equations圖2 三對角方程的定義
三對角方程的經典解法是基于高斯消去法的追趕法[10]。追趕法分為前向分解和后向回代兩個階段,在前向分解中,通過式(1),從第一行到最后一行,將方程變為上三角形式。
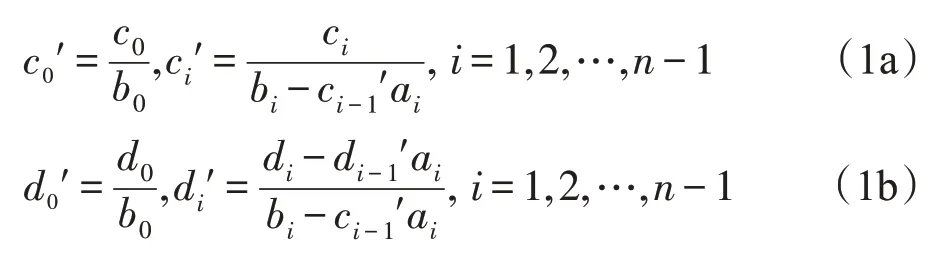
在后向回代過程中,通過式(2),從最后一行到第一行,求出解。
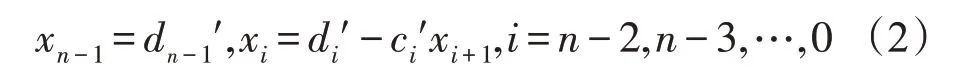
如果不考慮向量化和緩存,那么追趕法的計算量和訪存量都是最小的,因此是最快的串行算法。追趕法在求解單個三對角方程時是完全串行的,雖然在線程級粗粒度并行上,多個方程可以并行地求解,但是難以有效地利用向量化等細粒度并行機制。
CR算法由Hockney在1965年提出[11]。該算法包含兩個階段:前向消去階段和后向回代階段。在前向消去階段,將方程的偶數行提取出,按照式(3)得到一個規模折半的方程。
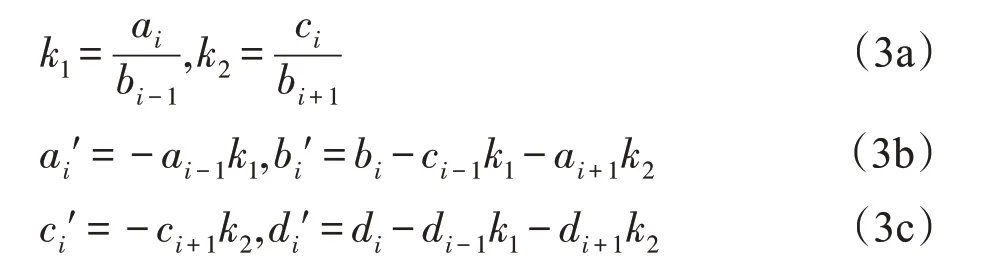
對新的方程可遞歸地進行消去,直到得到一個兩個未知數的方程時,可直接求解。
在后向回代階段,當偶數行的解已被求出時,按照式(4)可求得奇數行的解。

CR 算法可就地進行,即用新的a、b、c和d覆蓋內存中偶數行的a、b、c和d的位置。但這會使新的方程在內存中不連續,影響后續訪問的效率。針對這個問題,G?ddeke 和Strzodka 討論了數據布局的優化和利用GPU 共享內存的優化[12];Davidson 和Owens討論了GPU上的寄存器打包的優化[13]。
在CR算法的基礎上,Hockney 和Jesshope 于1981 年提出了PCR 算法[14]。與CR 算法不同之處在于,PCR算法不僅提取出原方程的偶數行做消去,也提取出原方程的奇數行做消去,從而將原方程轉化為兩個規模折半的方程。將兩個新方程分別遞歸求解后便可得到全部解,不再需要后向回代。
但是這個版本的PCR 算法是不實用的,因為它的計算復雜度相比追趕法和CR 算法的O(n)提高到了O(nlgn)。為了解決這一問題,Sakharnykh 將它與追趕法結合提出PCR-并行追趕法(PCR-pThomas algorithm)[2,6],將原來的lgn層遞歸分解改為常數層分解,之后并行地用追趕法求解所得到的常數個小規模的方程。這樣使得訪存和計算次數大幅減少,而且處理器的向量化運算仍然可以得到充分利用,但是多線程并行較困難。Kim等通過利用GPU上的共享內存進一步優化了內存訪問,提出了tiled-PCRpThomas 算法,其訪存量與經典的追趕法一致[15]。Wang 等通過將這一算法推廣到英特爾至強融合架構,利用寄存器優化內存訪問,并分析了PCR層數的最佳選擇,提出了register-PCR-(half)-pThomas算法[16]。
另外,Bondeli[17]、Polizzi等[18]和Chang等[19]也分別從不同的角度討論了大規模三對角方程的求解,但都是采用分治策略,將它的求解轉化成很多小規模方程的求解。本文所討論的范圍是求解大量的、規模不太大的三對角方程的情況。
表1 總結了追趕法、CR 算法和PCR-pThomas 算法的優缺點。
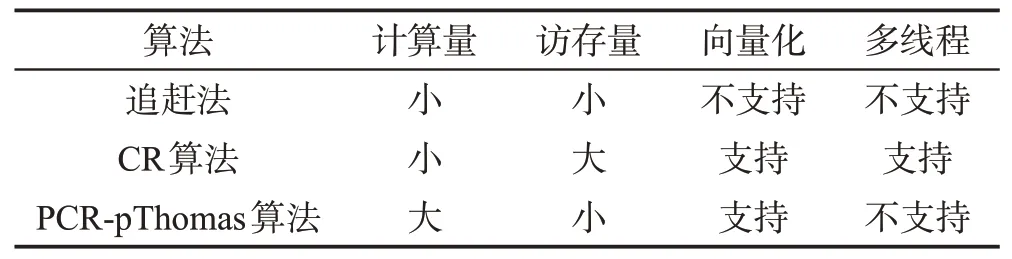
Table 1 Comparison of Thomas,CR algorithm and PCR-pThomas algorithm表1 追趕法、CR算法和PCR-pThomas算法的比較
3 申威眾核架構的三對角方程并行求解算法分析
首先考慮追趕法。在申威處理器的從核上,單精度除法的平均每條指令周期數(cycles per instruction,CPI)約為加乘的15倍;若將一次除法折合成15個加乘,則單精度下標量計算訪存比為0.917。同理,雙精度下將除法折合成30 次加乘,計算訪存比則為0.875。因此在申威處理器的從核上,追趕法是訪存受限的。
然后考慮PCR-pThomas 算法。一方面,申威處理器對單精度和雙精度浮點運算的向量化寬度都只有4 個浮點數。如表2 所示,PCR-pThomas 算法中,最多只能相比追趕法減少0.5n次向量除法,同時還要引入額外的向量混洗(shuffle)操作,向量化給PCR-pThomas 算法帶來的提升空間小。另一方面,PCR-pThomas 算法和追趕法的訪存量相同,受到同樣的訪存帶寬限制。綜合以上兩點,可以發現,PCRpThomas算法很難達到比追趕法更高的性能,因此在這兩者之中選擇更簡單的追趕法即可。
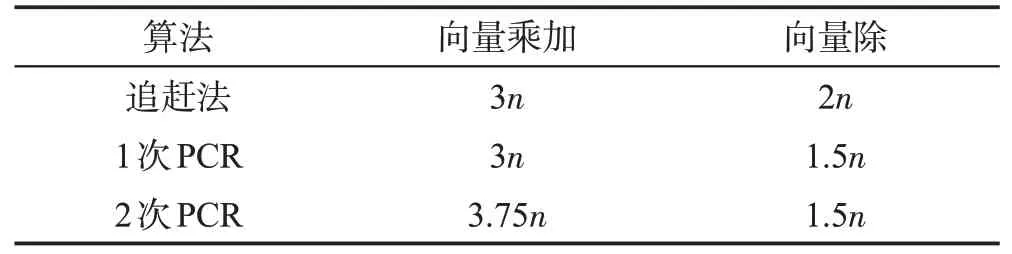
Table 2 Number of floating point operations in Thomas and PCR-pThomas algorithm表2 追趕法與PCR-pThomas算法的浮點運算次數
追趕法在申威處理器上是訪存受限的,要想達到比追趕法更高的性能,必須減少訪存量。在追趕法中,4/9的訪存是讀寫中間變量,即前向消去之后的超對角線和右端向量。注意到申威處理器從核陣列上的緩存是軟件可控的,如果能將這些中間變量放在高速緩存中,那么三對角方程求解器的性能相比追趕法仍有80%的提升空間。
然而每個從核上的緩存大小是有限的,要將所有中間變量都保存在緩存中,單個從核所能求解的方程規模是有上限的。單個從核的緩存是64 KB,考慮到其他棧變量需要占用一定的空間,可求解的方程規模上限在單精度為2 048維,在雙精度下為1 024維;這樣的規模上限對于實際問題來說限制太大。對于更大的規模就需要更大的緩存,為此可以將多個從核的緩存聯合起來,也就是使用多個從核來求解一個方程。
由于涉及到多核,求解算法必須支持線程級并行,否則不同核之間只能串行執行,每個核都會把很多時間浪費在等待其他核上,使得效率較低。追趕法本身不能并行,而PCR-pThomas 算法為了減少計算量和訪存量,舍棄了線程級并行的機會。因此,應該選擇支持線程級并行的CR算法。
本文以CR算法為原型,設計了適合申威處理器的swDCR算法。通過聯合最多64個從核,使得可求解的方程的規模上限提高到了單精度下131 072 維和雙精度下65 536 維。同時,利用申威處理器的寄存器通信機制,使得CR算法的前后依賴數據能在不同從核間有效地傳輸。
4 swDCR的實現與優化
4.1 基礎實現
使用從核緩存中的48 KB來存儲中間數據,其中最初讀入的原始方程占32 KB。在CR算法的每次前向消去時,將得到的新方程寫到當前空閑的空間,同時將原方程的奇數行打包到原方程所占用空間的前半部分。在消去完成后,原方程所占空間的后半部分就被騰出用于下一層消去,整個過程的中間變量便可以存放在這48 KB中;同時打包也可使回代過程的數據訪問變得連續,便于利用向量化運算。
經過一定次數的消去后,每個線程所處理的方程規模都不超過4,此時使用追趕法求解。由于此時數據仍然分布在各個從核的緩存中,稱這一過程的算法為分布式追趕法。雖然它用到了多核,但是實際的執行仍然是串行的,不過由于方程規模足夠小,這部分消耗的時間對整體性能影響很小。在追趕法的前向分解過程中,每個線程會等待前面的線程完成前向分解,并通過寄存器通信將前向消去之后的超對角線和右端向量的最后一個元素傳過來。每個線程完成前向分解后會將該線程處理部分的超對角線和右端向量的最后一個元素傳輸給后方線程。而后向回代過程也是同樣,先等待后方線程,再求解,然后將解的第一個元素傳輸給前方線程。
為了更高的吞吐率,解單個方程時所用到的從核數應該盡可能得少,同時每個從核所處理的問題規模不能超過其上限nmax。可以根據輸入規模來選擇單個方程所用的從核數,如式(5)所示。

若所得到的p大于64,即不可能把CR算法所有中間變量放入緩存中,而必須寫入主存。當涉及到主存訪問時,CR 算法訪存量大的問題將極大地降低算法的效率。另外,大規模的三對角方程也不在本文討論范圍內。在這種情況下,由于追趕法的訪存量更小,選擇回退到追趕法。
4.2 向量化
申威架構下單精度和雙精度浮點運算的向量化寬度都是4 個浮點數。為了有效地利用向量化來加速CR算法的消去與回代過程,應該使得每個線程處理的原方程行數是8的倍數,經消去后得到的新方程的行數是4 的倍數,以保證所有數據的對齊訪問,并避免出現不能向量化的余數部分。雖然可以通過在方程前后補上單位矩陣來使得原始方程規模是8 的倍數,但是經過一次消去后得到的新方程的規模只有原始方程的一半,不一定仍是8的倍數。
針對這一問題,在swDCR算法每次消去之前,引入“借”的機制。在每次消去前,假設線程所處理的原方程的行數已經是8的倍數,那么在需要時該線程會從后方線程“借”方程的4行來自己處理,從而保證在每次消去時處理的方程行數都是8 的倍數。如果這個“借”的過程發生了,那么在回代之后,也需要將所得到的解“還”給后方線程。
在每一層消去時,每個線程將計算自己所處理的方程行數和起始行號。若起始行號不是8的倍數,則當前線程的前4 行歸前方線程處理;若終止行號不是8 的倍數,則后方線程的前4 行歸當前線程處理。另外,若從后方線程“借”了4 行,這4 行也會被打包到原方程所占空間的前半部分,在回代時還會訪問到。
4.3 線程布局
無論是swDCR 算法的消去和回代過程,還是分布式追趕法的求解,都需要每個線程與其前后的線程進行通信。考慮到從核間寄存器通信只能同行或同列傳輸,線程在從核上的布局需要滿足要求:每個線程的前一個線程和后一個線程都在其同行或同列的從核上。一種簡單的線程布局如圖3(a)所示,其中紫色的線連接需要相互通信的兩個從核。
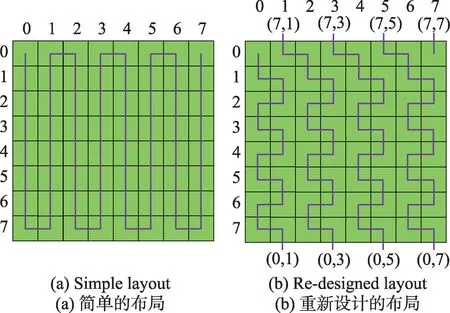
Fig.3 Thread layout on CPEs圖3 從核上的線程布局
這樣的線程布局會引起寄存器通信時的來源混淆問題。針對這個問題,在兩次寄存器通信之間加同步當然也是一種解決方法,但是這樣的同步開銷其實是可以避免的。考慮到從同行接收和從同列接收分別經由的是行接收緩沖區和列接收緩沖區兩個不同的緩沖區,可以設計一種線程布局,使得對于每一個線程,其前一個線程和后一個線程的其中一個在同行的從核上,另一個在同列的從核上。新的線程布局如圖3(b)所示。
5 實驗
5.1 性能測試
使用申威處理器的一個核組進行實驗。一個核組具有765 GFlop/s 的峰值計算能力和34.1 GB/s 的理論訪存帶寬。實驗會測試主核上的追趕法、從核上的追趕法以及不同優化前后的swDCR算法。每個算法會測試規模從128 維到32 768 維的足夠量的三對角方程,且分別測試單精度和雙精度的問題。每個數據都是在重復運行200 次后取運行時間的平均值,并以總未知數數量除以總時間計算吞吐率,以總訪存量除以總時間計算訪存帶寬。
圖4 展示了不同算法在申威26010 處理器單個核組上求解單精度和雙精度三對角方程的吞吐率和帶寬。根據實驗結果,主核上的追趕法在單精度和雙精度下都只能獲得1 GB/s 的帶寬,從而吞吐率較低。而從核上的追趕法基本可以獲得21 GB/s 以上的帶寬,但是和本文所提出的swDCR算法相比,由于訪存量較多,吞吐率并不高,約為單精度下6.0×108未知數/s,雙精度下3.0×108未知數/s。
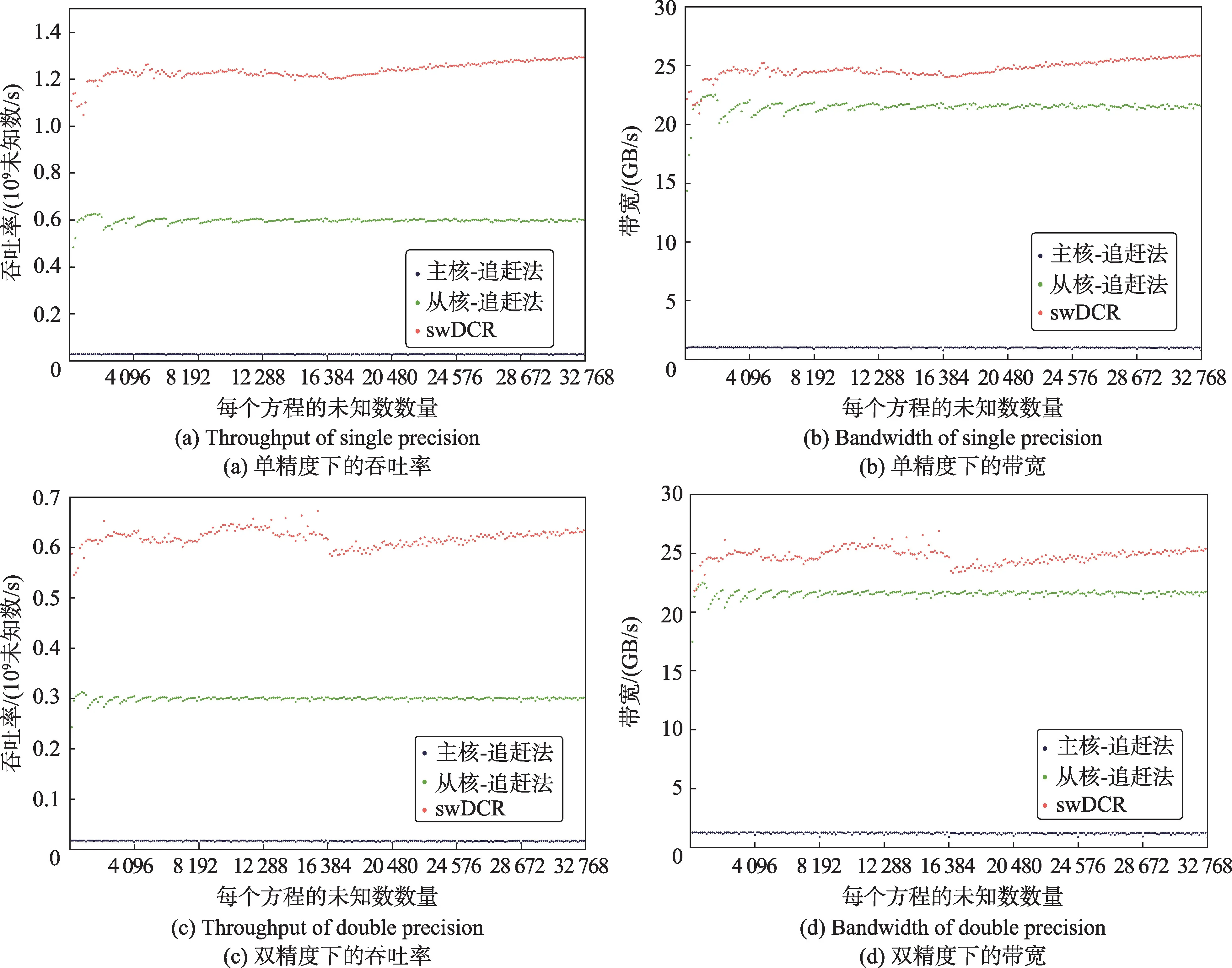
Fig.4 Throughput and bandwidth of different tridiagonal solvers圖4 不同的三對角求解算法吞吐率和帶寬
而本文所提出的swDCR 算法,可以獲得比追趕法更高的24 GB/s 帶寬,是理論帶寬的70%。同時更少訪存量使得吞吐率進一步提高,在不同規模下平均達到單精度下1.23×109未知數/s,雙精度下6.2×108未知數/s。
圖5展示了不同的優化對swDCR算法產生的性能提升。可以發現,向量化對于swDCR 的性能非常關鍵。在沒有向量化的版本中,和追趕法相比并無太大的吞吐率優勢;而在加入向量化優化后,性能得到了顯著的提升。在方程規模較小時,同步的影響較小;而在方程規模較大,也就是所用的從核數較多時,同步對性能的影響逐漸顯現出來。
同時可以發現,性能曲線隨著方程規模的上升,性能會有階躍式的下降,斷點在4 096、8 192、16 384等位置。這主要是因為,在選擇單個方程所用從核數時,在這些位置從核數翻倍,每個從核所處理的問題規模有階躍式的減小,從而導致性能階躍式地降低。這一現象在未經各項優化的版本上最為明顯,而經過各項優化后,算法變得越來越受訪存帶寬限制,這樣的階躍式下降也變得越來越不明顯。同時也可以發現,當每個從核所處理的問題規模逐漸增大時,性能也逐漸提升。
與主核上的追趕法相比,swDCR 算法在單精度和雙精度下分別可以獲得43.9 倍和36.7 倍的加速。與從核上的追趕法相比,swDCR 算法在單精度和雙精度下均可獲得2.07倍的加速。這樣的加速效果超出了單從訪存角度考慮得到的1.8倍理論值,相比追趕法,CR 算法適合向量化這一優勢能帶來額外的加速效果。
5.2 精度測試
swDCR在實現中是完全保精度的。為了驗證其求解精度,選取5 個16 384 維的三對角矩陣A,令精確解x的所有元素全為1,計算右端向量d=Ax,以此作為測試算例。用不同算法求解得到x′后,計算前向方均根誤差(root mean square error,RMSE),如式(6)所示。

在申威處理器上測試了swDCR算法和從核上的追趕法,作為參考,在英特爾處理器Core i7上也測試了Math Kernel Library 中帶主元選取的LU 分解法(lower-upper triangular decomposition)。
表3展示了不同算法的求解誤差。可以發現,不同算法的誤差受對角占優性、正定性和條件數的影響基本一致。而swDCR 在對角占優的情況下,誤差和帶主元選取的LU 分解法在同一個數量級。但在非對角占優的情況下有大于10 倍的誤差,這主要是因為在CR算法中,對角線元素作為除數出現在前向消去和后向回代的公式中,如果其絕對值較小則會產生較大誤差。
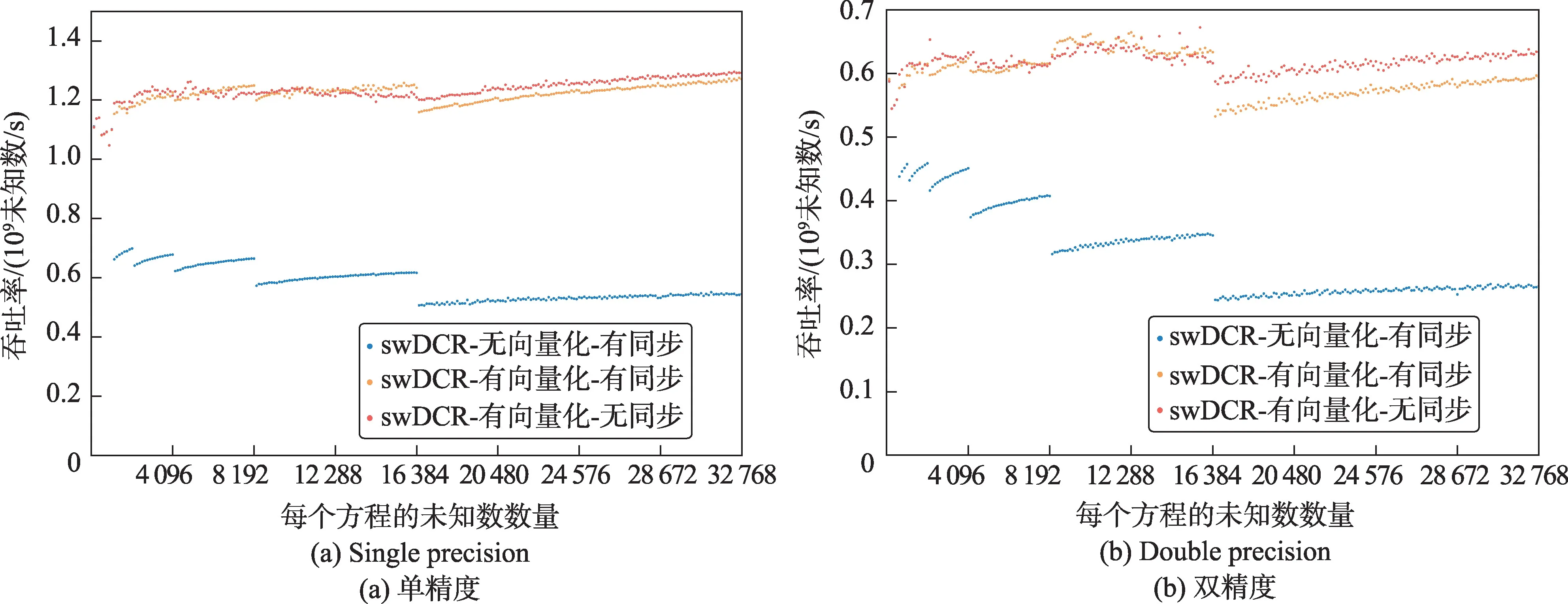
Fig.5 Performance improvement of different optimizations of swDCR圖5 swDCR的不同優化所產生的性能提升
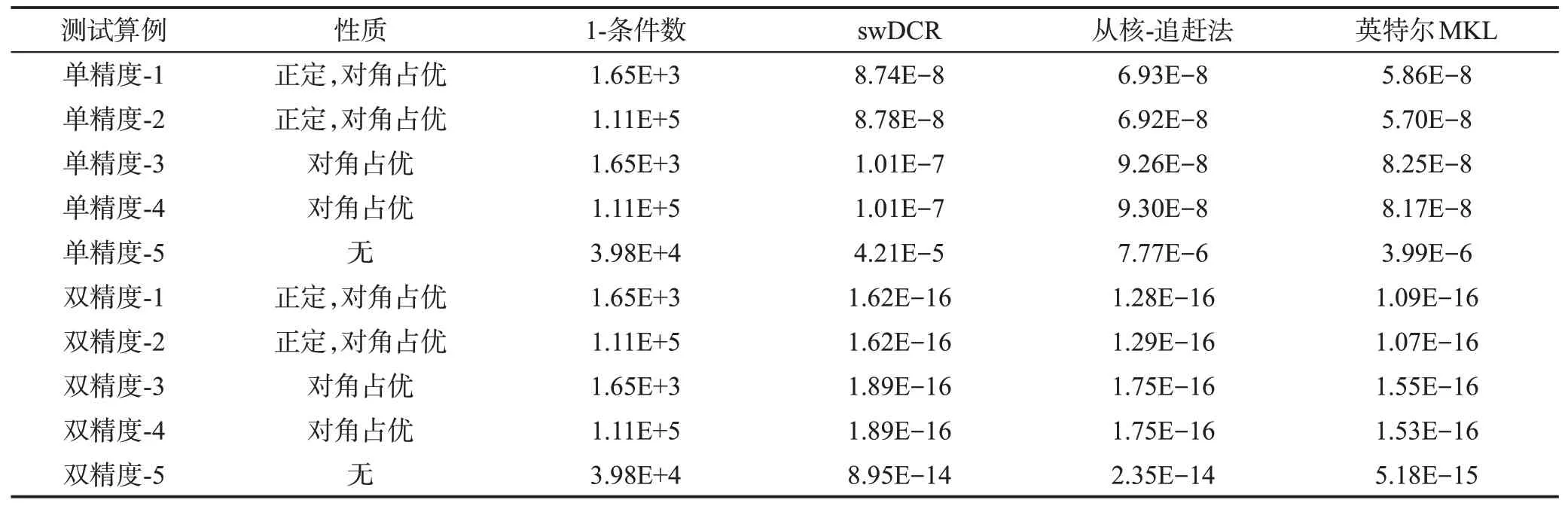
Table 3 RMSE of different algorithms表3 不同算法的方均根誤差
6 結束語
本文通過分析追趕法、CR算法和PCR算法在申威26010處理器上的性能,設計了基于申威處理器的swDCR 算法。通過聯合多個從核上的軟件可控緩存,將過程中的所有中間變量保存在緩存中,從而減少了主存的訪問,提高了算法的效率。通過利用向量化運算等方式,進一步優化算法的性能,使得該算法在訪存量已經達到理論上最少的前提下能利用硬件理論帶寬的70%。其吞吐率相比主核上的追趕法達到了單精度43.9 倍和雙精度36.7 倍的加速,相比從核上的追趕法達到了單精度和雙精度均2.07倍的加速。
swDCR算法可聯合最多64個從核使得可求解的問題規模達到單精度下131 072維和雙精度下65 536維。雖然所能處理的規模已經能滿足絕大多數現有的實際應用的需求,但是仍然是有限的。在進一步工作中,算法的可擴展性將要被著重考慮。一方面,對于未來可能出現的更大規模應用,還需要對算法進行更多改進;另一方面,該算法能否在未來可能出現的架構相似的處理器上獲得足夠的性能,還有待研究。
