一種基于隨機游走的歌曲推薦算法
2019-10-18 09:18:44吳雪君米紅娟
網絡安全與數據管理 2019年10期
吳雪君,米紅娟,李 欣
(蘭州財經大學 信息工程學院,甘肅 蘭州 730020)
0 引言
互聯網的快速發展使得用戶在面對呈指數級增長的信息量時很難挖掘出有用的資源。推薦算法的出現在一定程度上為用戶緩解了這個難題。推薦算法主要通過歷史數據中用戶對項目的行為操作,利用相應算法計算相似度,為用戶推薦他可能感興趣的項目。現在已經有許多實際的應用,如Netflix的電影推薦,亞馬遜網站的圖書、CD推薦等。
常見的主流音樂推薦算法可以分為三種:基于內容的推薦算法、協同過濾推薦算法、混合推薦算法。基于內容的推薦算法[1]易于實現,它只需要用戶個人的歷史數據,分析用戶曾經喜歡過的歌曲的屬性信息,計算所用歌曲間的相似度,為用戶推薦相似的未收聽過的歌曲。但是推薦結果缺乏多樣性,且特征提取的方法受到技術的限制。協同過濾推薦算法[2-3]是根據歷史數據中用戶對歌曲的評分(評分數據可以是用戶對項目的各種操作),計算相似度,發現偏好相同的用戶,根據相似用戶的偏好預測目標用戶對其他歌曲的喜好程度,不足之處是存在冷啟動問題和數據稀疏性問題。混合推薦算法將上述兩種算法互補組合進行推薦,比如Stanford大學推出的Fab系統,將兩種算法結合為用戶提供個性化推薦[4]。
有學者也提出了新的推薦算法,例如基于圖結構進行推薦。傳統的隨機游走(Random Walk,RW)[5]是一種理想的數學模型,它從所處的節點出發,以相同的幾率游走到其某一個鄰居節點,可以將它假設成馬爾科夫鏈。隨著研究的發展,隨機游走模型也被應用在推薦系統中,實現對用戶的個性化推薦。YILDIRIM H等人[6]提出了一種基于隨機游走模型的面向項目的協同過濾推薦算法,使用項目間的余弦相似度和修正的余弦相似度來初始化狀態轉移概率,該模型能在稀疏數據下增強相似性矩陣。ZHANG L等人[7]提出了一種基于分類隨機游走的推薦算法,引入了分類等級分數,針對用戶對不同類別的偏好進行推薦。對于冷啟動問題,SHANG S等人[8]利用社交信息來解決缺少用戶評分信息時的冷啟動問題,通過構建用戶-項目有向圖,結合項目內容和社交信息為用戶進行推薦。
近年來,場論在其他學科中的應用越來越廣泛,已有學者提出經濟場、物流場等概念與理論。費孝通[9]提出“場”是一個研究多學科的綜合平臺,可以給其他學科的研究提供新的理論依據與研究視角。湯銀英[10]在物流場的基礎上,建立了物流場理論體系,研究了物流場的各種特性,構造了發展動力場模型,為物流企業的發展提供策略。
本文提出一種基于隨機游走的音樂推薦算法,首先根據歌曲的基本信息和用戶的收聽數據,計算歌曲間的綜合相似度,降低評分矩陣的稀疏性,構建歌曲相關圖,再結合物理場論中的場力公式,將歌曲看作相互作用的節點,結合音樂的重要度,確定隨機游走模型中的轉移概率矩陣,降低隨機游走的時間復雜度,提高歌曲推薦的準確性。
1 推薦算法相關理論
1.1 隨機游走模型
隨機游走由一系列隨機的軌跡組成,在推薦系統中,對于m個用戶和n個項目,模型中用戶游走到當前節點的概率由前一步P(Xu,d+1=j|Xu,d=i)決定,Xu,d=i表示用戶u隨機游走d步后在項目i處的隨機變量[6]。
Pij=P(Xu,d+1=j|Xu,d=i)
(1)
其中,Pij∈P,P為m×n的轉移概率矩陣。
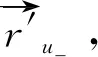
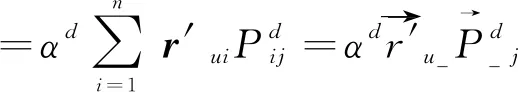
(2)
定義用戶u在節點j的總概率如式(3)所示。
(3)
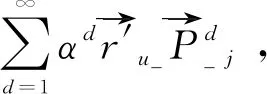
1.2 場論模型
場是物質存在的基本形式,相互作用存在于場之間,如溫度場、電場、磁場等。在場中,某物質對其他物質產生的影響可以用作用力表示。在萬有引力場中,任意兩質點間的引力由式(4)計算。
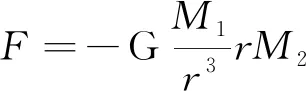
(4)
場力的統一公式如式(5)所示。
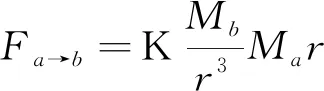
(5)
其中,K是常數,M表示物質的特性(包括式(4)中的M1與M2,式(5)中的Ma與Mb),比如質量、重要性等,r是兩種物質之間的“距離”。
2 基于隨機游走的歌曲推薦算法
2.1 構造歌曲相關圖
2.1.1 歌曲評分相似度
設用戶集U={u1,u2,...,ua,...,um},歌曲集I={i1,i2,...,ij,...,in},根據數據集中用戶的行為操作,構造二部圖G=
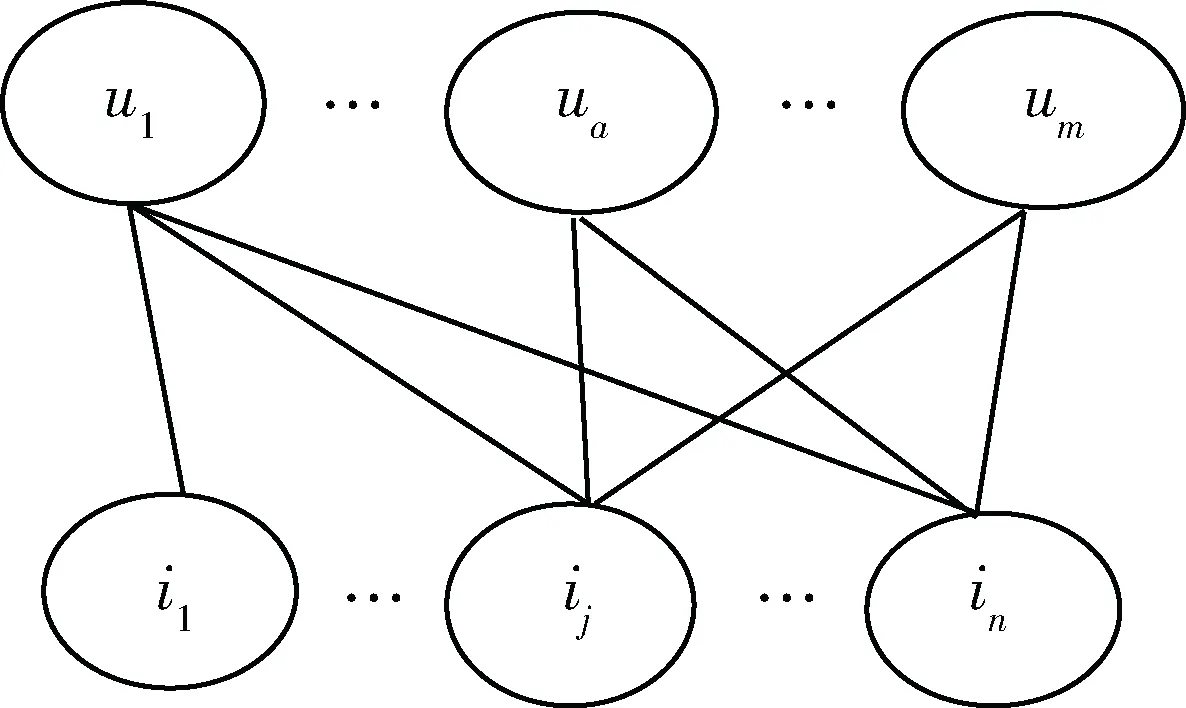
圖1 二部圖示例
基于協同過濾的歌曲推薦算法通過分析歷史數據集中用戶對歌曲的評分來獲得項目或用戶間的關系。對于m個用戶和n個項目,用戶對項目進行自己的操作,比如購買、分享、刪除等,這些行為操作表示了用戶對項目一定的喜惡程度,是一種隱式評分。在如式(6)所示的用戶-項目評分矩陣R中,raj表示第a個用戶對第j個項目的評分值。傳統的協同過濾推薦算法通過評分矩陣計算相似度,得到具有相似偏好的用戶或項目進行推薦。本文使用的數據集中用戶的歷史操作是以收聽歌曲的次數計數,所以以用戶收聽某首歌曲的次數來作為用戶對項目的評分。

(6)
歌曲ix和歌曲iy的評分相似度計算的基本思想是,找出既收聽過歌曲ix,也收聽過歌曲iy的所有用戶Uix,iy,然后計算相似度Simix,iy。計算歌曲相似度的方法有很多,如皮爾遜相關系數、余弦相似度、修正的余弦相似度[11]等。
經過對現有語料的分析,用戶收聽某首歌曲的次數變化范圍在1~7 939之間,用戶一般不會再次收聽不喜歡的歌曲,但是會不斷循環收聽喜歡的歌曲。根據數據集中用戶收聽歌曲的歷史行為,生成User-Item矩陣。為消除用戶收聽歌曲存在的次數差異,通過式(7)對數據做最大值最小值歸一化。
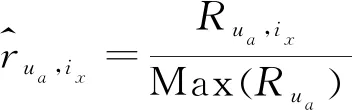
(7)
其中,Max(Rua)表示第a行元素中的最大值,即用戶ua收聽單首歌曲的最大次數,Rua,ix表示用戶Ua收聽歌曲ix的次數。
本文選取改進的余弦相似度方法計算歌曲評分相似度,如式(8)所示。
Sim1(ix,iy)=
(8)
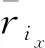
2.1.2 歌曲基本信息相似度
根據數據集中音樂的固有信息,例如曲風、演唱者、發行年份等,計算歌曲基本信息相似度。
①曲風屬性可以作為標簽屬性,其取值為搖滾、金屬、說唱等,屬性間的相似度用式(9)計算。
(9)
其中,S1(ix,iy)表示歌曲ix與iy之間的曲風相似度,K表示兩首歌曲共有的標簽數,N表示該屬性所有的標簽數。
②發行年份屬性,對年份進行分段處理,比如10年作一次劃分,年份從1922年~2011年,則1922年記為1,1931年記為2,2011年記為10,劃分后用式(10)計算兩首歌曲之間的發行年份相似度。
S2(ix,iy)=e-|Tix-Tiy|
(10)
其中,S2(ix,iy)表示歌曲ix與iy的發行年份相似度,Tix、Tiy分別表示歌曲ix和iy的發行年份所處的分段值。
③演唱者屬性,將演唱者屬性看作二元屬性,即兩首歌曲的演唱者相同記為1,不同記為0,用Sim3(ix,iy)表示歌曲ix和iy的演唱者相似度。
歌曲ix和iy的基本信息相似度通過Sg(ix,iy)(g=1,2,3)的加權求和得到,如式(11)所示。
(11)
其中,w1表示曲風屬性占的權重,w2表示發行年份屬性占的權重,w3表示演唱者屬性占的權重。
2.1.3 歌曲相關圖
由歌曲評分相似度Sim1(ix,iy)和歌曲基本信息相似度Sim2(ix,iy)加權求和計算歌曲綜合相似度Sim(ix,iy),如式(12)所示。
Sim(ix,iy)=αSim1(ix,iy)+βSim2(ix,iy)
(12)
其中,參數α、β分別表示歌曲評分相似度和歌曲基本信息相似度所占的權重。
2.2 改進的隨機游走推薦模型
傳統的隨機游走算法在時間復雜度上有明顯的缺點,因為在為每個用戶進行推薦時,都需要在整個用戶-項目二部圖上進行迭代,直到每個項目被選擇的概率值收斂,這一過程的時間復雜度非常高。改進后的隨機游走算法通過構建轉移概率矩陣,大大降低了算法的時間復雜度。
由歌曲綜合相似度,得出對應的相似度矩陣M1。運用式(5),計算作用力矩陣Mforce。其中距離r用歌曲節點間的綜合相似度Sim(ix,iy)來計算,如式(13)所示。兩首歌曲越相似,Sim(ix,iy)越大,r就越小,表示歌曲間的“距離”越近。
(13)
式(5)中的物質特性M采用歌曲的重要性,即歌曲的度來衡量,歌曲的度為用戶-歌曲二部圖中歌曲頂點連接的路徑數,也就是收聽過這首歌曲的用戶數,根據用戶-歌曲二部圖得到每首歌曲的度outix。由于每一項都有常系數K,通常K取1,得到歌曲間的場力如式(14)所示。
(14)
綜上,得到作用力矩陣Mforce,其中Mforce(ix,iy)=Fix→iy,Mforce(ix,ix)=0。
對Mforce進行歸一化計算,得到轉移概率矩陣Mtran,其中Mtran(ix,iy)如式(15)所示。
(15)
通過Mtran計算出各節點對應歌曲的最終推薦值N,如式(16)所示,將推薦值N按從小到大排序,得到推薦結果。
由N=(1-λ)N0+λNMtran得[12]:
N=(1-λ)(1-λMtran)-1N0
(16)
其中,N是所有節點的推薦值向量;N0是一個n×1的列向量,表示目標用戶的收聽記錄,N0(ix)=1,表示該歌曲被目標用戶收聽過;N0(ix)=0,表示該歌曲未被目標用戶收聽過,參數λ表示權重。
3 推薦算法實驗及結果分析
3.1 數據集
公開數據集Million Song Dataset(MSD)包含了一百萬首歌曲的特征分析和元數據。其他幾個互聯網音樂社區貢獻了相關互補數據集,例如The musiXmatch Dataset提供了歌曲的歌詞數據。The Last.fm Dataset提供了歌曲信息、藝術家信息等。Kaggle曾經舉辦過The Million Song Dataset Challenge,利用了一百萬用戶的播放記錄數據。
本文使用到的數據是MSD的子集The Echo Nest提供的可以與MSD關聯的user-song-play count數據集。數據集有元數據和評分數據,其中元數據包括歌曲的曲風、演唱者、發行年份,評分數據是用戶收聽歌曲的次數。
3.2 實驗與結果分析
實驗中訓練集為100萬用戶的收聽歌曲的記錄,Kaggle比賽提供了額外的11萬用戶對38萬多首歌曲的收聽記錄,驗證集為其中1萬用戶的收聽記錄,測試集為剩余10萬用戶的收聽記錄,測試集中一半的收聽數據可見。
根據歌曲元數據計算歌曲基本信息相似度時,對于歌曲的基本信息,曲風、年代、演唱者三者之間存在一定的聯系,例如某一演唱者屬于某一年代,他的歌曲一般在這一年代較流行,也具有該年代的主流曲風。本文實驗中曲風、年代、演唱者所占自的權重均為1/3。
經過實驗證明,計算歌曲綜合相似度時,歌曲評分相似度Sim1(ix,iy)和歌曲基本信息相似度Sim2(ix,iy)的權重為α=0.4,β=0.6時實驗效果最佳。計算歌曲最終的推薦值N時,參數λ取經驗值0.85。
本文采用Kaggle比賽中使用的平均精度均值(Mean Average Precision,MAP)作為評價指標,評價歌曲推薦方法的準確性,其公式如下:
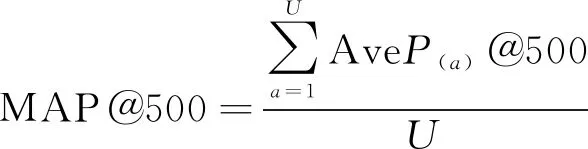
(17)
其中:MAP@500表示給第a個用戶推薦Top500的音樂的平均準確率,U表示所有的用戶數量。
Kaggle比賽第一名Aiolli使用基于內存的協同過濾進行推薦,以該實驗的結果作為參照進行對比,結果如表1所示。

表1 算法運行時間比較
從表1可見,改進的隨機游走歌曲推薦算法提高了推薦的準確性,利用歌曲綜合相似度建立歌曲相似度矩陣,降低了相似度矩陣的稀疏度,再由歌曲的重要性結合場力公式,構造轉移概率矩陣,基于隨機游走進行推薦,相比于協同過濾算法,該算法具有更好的推薦準確性。
4 結論
本文提出了一種基于隨機游走的歌曲推薦算法,引入物理學中的場論理論,解決了隨機游走算法同等對待節點的不足,通過計算歌曲綜合相似度,降低了相似度矩陣的稀疏度,將歌曲的重要性和場力公式結合,構造轉移概率矩陣,進行基于隨機游走的推薦。實驗證明,該方法比一些傳統的協同過濾方法具有更好的推薦準確性。但本文僅利用了歌曲的基本信息和評分數據,沒有充分利用歌曲的其他重要特征,后期將繼續研究如何融合歌曲的更多特征,比如音頻特征、歌詞特征等,以提高算法的推薦準確性。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
