一種基于Logicboost的軟件缺陷預測方法
2019-10-08 11:55:52張洋
軟件 2019年8期


摘 ?要: 針對軟件缺陷預測中對不平衡數據分類精度較低的問題,提出了一種新的基于LogitBoost集成分類預測算法,使用SMOTE方法對原始數據集進行平衡處理,然后使用隨機森林算法作為弱分類器算法進行分類預測,最后使用LogitBoost算法以加權方式集成各弱分類器的結果。通過在NASA MDP基礎數據集上驗證得出本文提出的分類預測算法比數據集均衡處理前準確率高出0.1%-11%,同時在均衡處理后比KNN算法平均高出0.9%,比SVM算法平均高出0.4%,比隨機森林算法平均高出0.1%。
關鍵詞: 不平衡數據;LogitBoost集成算法;隨機森林算法;軟件缺陷預測
中圖分類號: TP206+.3 ? ?文獻標識碼: A ? ?DOI:10.3969/j.issn.1003-6970.2019.08.019
本文著錄格式:張洋. 一種基于Logicboost的軟件缺陷預測方法[J]. 軟件,2019,40(8):7983
【Abstract】: Aiming at the problem of low classification accuracy of unbalanced data in software defect prediction, a new integrated classification prediction algorithm based on LogitBoost is proposed. SMOTE method is used to balance the original data set, then random forest algorithm is used as weak classifier algorithm for classification prediction. Finally, the results of weak classifiers are integrated in a weighted way using LogitBoost algorithm. Through the verification on NASA MDP basic data sets, the classification prediction algorithm proposed in this paper is 0.1%-11% higher than that before data balancing, 0.9% higher than that of KNN algorithm, 0.4% higher than that of SVM algorithm and 0.1% higher than that of random forest algorithm.
【Key words】: Unbalanced data; Logitboost integration algorithms; Random forest algorithm; Software defect prediction
0 ?引言
軟件缺陷是指計算機軟件或程序中存在的某種破壞正常運行能力而導致的問題和錯誤或者其他隱藏的功能缺陷。2011年“甬溫線”列車因控制軟件設計缺陷導致列車追尾事故造成了大量人員傷亡、2012年美國騎士資本集團的交易軟件缺陷問題造成股票交易異常損失近4.4億美元、2019年波音737MAX因軟件缺陷導致多起墜機事件,大量的人員傷亡和財產損失無不在警示人們對軟件質量的重視,也進一步促進了對軟件缺陷預測的研究。
因為軟件缺陷客觀存在,而且某些隱藏較深的缺陷不容易發現,而一個軟件缺陷如果在開發早期發現那么解決該問題的成本會比較小,而越往后解決缺陷問題的成本會逐漸增加,而開發完成后才發現的缺陷最嚴重的情況是有可能項目需要重新開發,所以研究軟件缺陷問題的關鍵就是如何最大程度的發現軟件或程序中的隱藏缺陷,而開發一款高質量的算法讓其能判定軟件中的大部分缺陷是解決當前問題的重中之重[1]。
1 ?相關研究
軟件缺陷預測方法分為靜態軟件缺陷預測方法和動態軟件缺陷預測方法[2],本文研究內容屬于靜態軟件預測方法。目前針對靜態軟件預測采用的方法有神經網絡[3]、支持向量機(SVM)[4]、決策樹方法[5]、貝葉斯網絡方法[6]、隨機森林算法[7]、關聯規則挖掘方法[8]、集成學習方法[9]等方法,其中神經網絡方法是一種非監督分類方法依賴傳統方法尋找神經網絡權值,所以比較難找到全局最優解;SVM方法能較好的應對不平衡數據和數據多維的情況,但容易受到噪聲樣本數據的影響;其他分類算法因為數據不平衡的問題導致預測精度比較低;集成學習方法集成了多個弱分類器的方法以構成強分類器,所以較單個弱分類器分類預測性能較高,是目前比較好的一種缺陷預測方法。因為以上很多分類預測算法都受到數據集不平衡的影響,所以針對這個問題有非常多的學者進行了研究,而且在軟件缺陷預測研究領域中不平衡數據集對軟件缺陷預測方法的效果影響很大[10],目前針對數據集不平衡的研究有多種方法,有向上過采樣補充少數樣本方法[11],有向下欠采樣減少多數樣本方法[12],還有同時使用過采樣和欠采樣相結合減少多數類樣本增加少數類樣本的方法[13]等。本文在研究了以上多種方法后發現采用向上過采樣的方法較其他兩種方法能保留更多原始樣本數據信息并且在軟件缺陷預測方法中分類預測效果也比較好,所以本文的實驗過程都是在使用SMOTE方法[11](Synthetic Minority Oversampling Technique)對數據集進行預處理的基礎上進行實驗,然后在此基礎上使用新提出以隨機森林分類算法作為基分類算法并結合LogicBoost[14]邏輯集成算法集成多個基分類算法進行分類預測的方法進行驗證并與其他幾類常見的分類預測算法進行了比較,同時為驗證對數據集使用過采樣平衡處理后算法的性能是否提高本文還對各種方法在原始不平衡數據集和平衡后數據集的分類預測結果進行比較。為更有效的評價分類結果,本文選擇了準確率、AUC值、G-mean值三個業界認可的有效性能評價指標對結果進行評價,并使用NASA MDP數據集[15]完成整個實驗。
2 ?基于LogicBoost的軟件預測方法
2.1 ?SMOTE采樣
數據集不平衡的問題一直是分類問題最大的困擾,而對于需要預測的有缺陷的數據集總是少數,而且在某些數據集中占比非常低,為解決樣本少,特征缺失的問題,Chawla等人提出了SMOTE方法,該方法通過計算少數樣本k個相鄰樣本間的歐式距離得到最近鄰的k個樣本,然后生成0到1之間的隨機數與隨機抽取的近鄰樣本合并生成新樣本,重復這個過程直到樣本間達到平衡。其具體生成生新樣本的方法如式1所示,其中Pj表示新樣本,N表示生成樣本數量。
2.2 ?LogicBoost算法
Logitboost算法是由Friedman等人提出的一種改進型Boosting算法[16],是一種集成各弱分類器結果變成強分類器的集成分類算法。LogitBoost使用加權最小二乘法估計分類函數并以加權的方式對基礎分類器的結果進行評價,如果分類結果出現錯誤則會加大其權重,相反權重減小,通過迭代多次每次給不同的基礎分類器重新計算權重,最后采用加權的方式合成各基礎分類器的分類結果作為最終分類結果,具體現過程如下:
(1)給定一個測試集(xi1, xi2…xin, yi),yi={Y, N}表示有缺陷和無缺陷兩類。
(2)給樣本賦予權重wi=1/N, i=1…N,使得每個樣本被抽到的概率一致,然后使用基礎分類器,根據權重以迭代的方式建立預測模型,每一輪提升都會給錯誤分類的樣本增加權重,正確的減小權重,其中F(x)=0, Pi=1/2。
(3)假定算法迭代M次,m=1,2,…,M
2.3 ?隨機森林算法
隨機森林是由Breiman提出的一種基于Bagging[17]算法與隨機子空間算法[18]的集成算法,其基本思想是多個決策樹對同一個測試數據集進行分類建立隨機森林決策樹,然后在分類預測過程中通過多個決策樹投票的方式統計所有決策樹的結果來最終判定樣本的分類結果。隨機森林的算法主要優點是算法的準確性比單個決策樹都高,而且每棵決策樹選擇分類屬性可以隨機,同時每棵決策樹選擇測試數據集也可以隨機,這兩個隨機讓算法減少了算法產生過擬合的結果同時也降低了噪聲樣本數據的影響。算法的實現過程如下:
輸入:訓練樣本數據集,特征集合
輸出:隨機森林決策樹
(1)隨機選擇訓練樣本數據集。對于每棵樹而言,隨機且有放回地從訓練集中的抽取N個訓練樣本作為該樹的訓練集。
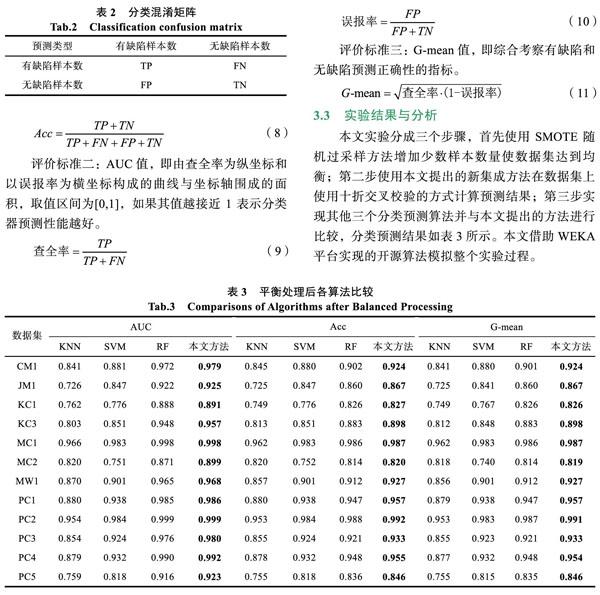
(2)隨機選擇訓練樣本的特征數。假定樣本的特征維度為M,指定一個常數m< (3)每棵樹都盡最大程度的生長,并且沒有剪枝過程。 (4)所有生成樹都停止生長后,隨機森林決策樹構建完成。 2.4 ?基于LogicBoost的軟件預測算法 輸入:測試數據屬性集{A1,A2…An}以及樣本實例數據 輸出:輸出分類預測結果和成功率 (1)對原數據集進行清理,清楚重復項,以消除重復項對測試結果過擬合的影響。 (2)根據SMOTE規則對數據集進行數據樣本隨機過采樣增加少數類樣本,采樣比例=(無缺陷實例數/有缺陷實例數)-1,設置k=5,即通過計算樣本間的歐式距離找到最鄰近的5個樣本,然后使用隨機的方式循環地選擇近鄰樣本乘以隨機數增加少數樣本使數據集均衡。 (3)構建隨機森林算法的決策樹模型,隨機森林算法默認的基分類算法為分類回歸樹,設置特征選擇數量隨機生成,通過多次實驗得到選擇訓練樣本數量在70%的時候效果最好,同時設置生成樹無限生長直到葉子只包含一個類別的樣本后停止生長。 (4)建立LogitBoost計算模型,生成樣本權重矩陣,并生成工作變量,建立基于最小二乘法的擬合函數估計分類函數,并在每次迭代重新計算權重和樣本概率。 (5)使用隨機森林算法作為LogitBoost的基礎分類器,設置迭代次數為100,并使用十折交叉校驗的方式把樣本分成十分,每次使用其中九份作為訓練數據集一份作為測試集,總共迭代十次最后經過加權統計的方式得到所有樣本的分類預測結果。 (6)輸出分類預測結果和成功率。 3 ?實驗結果與分析 3.1 ?數據集 本文采用NASA公布的MDP軟件缺陷數據集作為實驗數據集,并且對原數據集進行了清理刪除了原始數據集中出現的重復樣本,具體如表1所示列出了樣本集名稱、樣本總數、有缺陷樣本數、無缺陷樣本數以及不平衡度,其中不平衡度等于無缺陷樣本和有缺陷樣本的除數,可以發現數據集非常不平衡,從1.84到45.56不等。 3.2 ?評價標準 為有效評價各算法性能,使用分類混淆矩陣如表2表示預測完成后各項結果數據,其中TP表 ? 示有缺陷樣本被正確預測的數量,FN表示無缺陷樣本預測成有缺陷樣本數量,FP表示有缺陷樣本預測為無缺陷樣本數量,TN表示無缺陷樣本正確預測 ?數量。 評價標準一:準確率(Acc),即有缺陷樣本和無缺陷樣本都預測正確在整個樣本中的比例。 3.3 ?實驗結果與分析 本文實驗分成三個步驟,首先使用SMOTE隨機過采樣方法增加少數樣本數量使數據集達到均衡;第二步使用本文提出的新集成方法在數據集上使用十折交叉校驗的方式計算預測結果;第三步實現其他三個分類預測算法并與本文提出的方法進行比較,分類預測結果如表3所示。本文借助WEKA平臺實現的開源算法模擬整個實驗過程。 通過以上實驗可以得到本文方法在三個評價標準上較其他三個分類預測方法都表現比較好,圖1和圖2列出了各方法在數據集未做平衡處理與平衡處理后在數據集上的準確率柱形圖,可以看到各算法在數據集平衡處理前后算法性能有不同程度的提升,而本文提出的方法樣本數據平衡的情況下預測性能比其他方法的準確率都高。 4 ?結論 本文基于LogicBoost算法和隨機森林算法提出一種新的集成分類預測算法,該算法使用隨機森林分類算法作為基分類算法,有效發揮了隨機森林算法的高分類精度優勢,同時結合LogicBoost集成算法進一步提高預測精度。選擇的NASA MDP數據集是美國宇航局公布的軟件缺陷數據集,該數據集收集了多個軟件的度量屬性和樣本數據,是軟件缺陷研究領域可直接進行分類預測的數據集。本文選擇了其中 12個基礎數據集驗證提出方法的預測效果,同時采用原始數據集和使用SMOTE方法隨機過采樣均衡的數據集兩個差異性的數據集進行對比實驗,實驗結果表明本文提出的方法在均衡數據集上效果比其他預測算法有較高的性能。雖然本文預測結果對比其他幾類分類算法較好,但本文未考慮多特征屬性對算法結果的影響,下一步將著重研究多特征屬性提取后驗證本文方法是否有更高的預測精度。 參考文獻 [1] 孔軍, 吳偉明, 谷勇浩. 基于缺陷模式匹配的靜態源碼分析技術研究[J]. 軟件, 2016, 37(11): 146-149. [2] 郝世錦, 崔冬華. 基于缺陷分層與PSO算法的軟件缺陷預測模型[J]. 軟件, 2012, 33(2): 51-52. [3] JIN C, JIN S W, YE J. Artificial neural network-based metric selection for software fault-prone prediction model[J]. IET Software, 2012, 6(6): 479-487. [4] LARADJI I H, ALSHAYEB M, GHOUTI L. Software defect prediction using ensemble learning on selected features[J]. Information & Software Technology, 2015, 58: 388-402. [5] WANG J, SHEN B, CHEN Y. Compressed C4. 5 models for software defect prediction[C]//Proc of 2012 12th international conference on quality software.Washington DC: IEEE, 2012: 13-16. [6] 段明璐. 軟件故障樹算法建模的研究[J]. 軟件, 2018, 39(2): 66-74. [7] PUSHPHAVATHI T P, Suma V, RAMASWAMY V. A novel method for software defect prediction: hybrid of FCM and random forest[C]//2014 International Conference on Electronics and Communication Systems (ICECS). Piscataway: IEEE Press, 2014: 1-5. [8] 顏樂鳴. 基于關聯規則挖掘的軟件缺陷分析研究[J]. 軟件, 2017, 38(1): 70-76. [9] WANG T, ZHANG Z, JING X, et al.Multiple kernel ensem-ble learning for software defect prediction[J]. Automated Software Engineering, 2016, 23(4): 569-59. [10] 劉學, 張素偉. 基于二次隨機森林的不平衡數據分類算法[J]. 軟件, 2016, 37(7): 75-79. [11] CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2011, 16(1): 321-357. [12] SUN Z, SONG Q, ZHU X, et al. A novel ensemble method for classifying imbalanced data[J]. Pattern Recognition, 2015, 48(5): 1623-1637. [13] 戴翔, 毛宇光. 基于集成混合采樣的軟件缺陷預測研究[J]. 計算機工程與科學, 2015, 37(5): 930-936. [14] FRIEDMAN J H, TREVOR H,ROBERT T. Additive logistic regression: A statistical view of boosting[J]. The Annals of Statistics, 2000, 38(2): 337-374. [15] SHIRABAD J S, MENZIES T J. The PROMISE repository of software engineering databases[OL]. (2005-03-15)[2019-04- 23]. http://promise.site.uottawa.ca/SERepository. [16] YOAV F. Boosting a weak learning algorithm by majority[J]. Information and Computation, 1995, 121(2), 256-285. [17] BREIMAN L. Bagging predictors[J]. Machine learning, 1996, 24(2): 123-4. [18] HO T K. Random subspace method for constructing decision trees[J]. IEEE Transactions onPattern Analysis & Machine Intelligence, 1998, 20(8): 832-844.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
