結合反殘差塊和YOLOv3的目標檢測法*
2019-09-11 02:28:58焦天馳林茂松賀賢珍
傳感器與微系統 2019年9期
焦天馳, 李 強, 林茂松, 賀賢珍
(西南科技大學 信息工程學院,四川 綿陽 621010)
0 引 言
近幾年,目標檢測[1]在汽車的輔助駕駛系統、機器人技術、工業物聯網智能監控等領域有著廣泛的應用[2]。隨著卷積神經網絡在圖像分類挑戰中取得成功后,大量基于深度卷積神經網絡的方法被用于目標檢測,這些方法大致可分為基于候選框的方法和基于回歸的方法。前者主要有R-CNN、SPP-net[3]、R-FCN、Faster R-CNN[5]等方法,在檢測精確度上有著優異的表現;后者主要有SSD和YOLO[7]等,方法在實時性上有著明顯的優勢。
文獻[9]通過聚類和RPN網絡提取可能含有行人的區域,再對目標區域進行判別和分類,相比DPM的方法得到更好的檢測效果。文獻[10]提出了一種數據增強方法,有效的提高了遮擋條件下的人臉召回率。文獻[11]通過融合PN網絡、FTN網絡以及不同卷積層的特征,使得對目標的識別和定位得到了顯著優化。對于目標檢測模型而言,在保持精度的同時,減少計算次數和內存占用成了亟需解決的問題。
本文基于回歸的目標檢測方法,以YOLOv3模型為主體,提出一種基于深度可分離卷積網絡的M-YOLOv3目標檢測方法,將以反殘差塊為基礎的輕量級網絡[13]作為特征提取網絡,通過多尺度預測和特征融合提高模型性能;使用靜態行人數據集INRIA對算法進行驗證分析,針對本文采用的網絡結構和數據集通過聚類分析的方法生成先驗框,加快收斂速度。與YOLOv3的對比試驗表明:改進后的方法在INRIA數據集上準確率、召回率和實時性上都有著較好的提升。
1 基本原理
1.1 特征提取網絡
目標檢測算法性能的好壞與基礎特征提取網絡有很大關系,YOLOv3中采用類Resnet[14]的Darknet53作為特征提取網絡,該網絡包含53個卷積層。YOLOv2對于前向過程中張量尺寸的變化通過5次最大池化進行,而在YOLOv3的基礎網絡Darknet53里則是通過5次增大卷積核的步長來進行。一方面YOLOv3采取這樣的全卷積結構,另一方面其引入殘差結構,使得訓練網絡的難度大大減小,從而提高網絡分類的準確率。
1.2 檢測流程
YOLOv3以回歸的方式訓練網絡,首先通過K-means算法對數據集樣本進行聚類分析,在3個不同尺度上生成3組先驗框,后續邊界框的大小將基于9個先驗框進行微調。輸入416×416的圖像,經過基礎網絡進行特征提取,輸入FPN結構。最終生成3個尺度的特征圖作為預測,分別為13×13,26×26和52×52。將這些特征圖劃為網格區域,在每一個網格上預測3個邊界框,一共產生(13×13+26×26+52×52)×3=10 647個邊界框。每個邊界框預測4個坐標:tx,ty,tw,th。目標網格到圖像左上角的距離為(cx,xy)并且它對應的邊界框寬和高為pw,ph。對應的預測關系如下
bx=σ(tx)+cx,by=σ(ty)+cy,bw=pwetw,bh=pheth
(1)
每個網格還預測物體在預測框中的概率Pr(Object),并通過公式對預測框進行打分
(2)
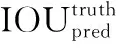
2 改進的YOLOv3
2.1 M-YOLOv3網絡設計
本文在YOLOv3目標檢測算法模型的基礎上,將輕量化網絡Mobilenetv2與YOLOv3算法相結合。Mobilenetv2中主要通過使用深度可分離卷積[15,16](depth-wise separable convolution)的操作減少卷積過程中的計算量,從而降低模型整體的復雜度。深度可分離卷積對于許多高效的神經網絡來說是非常關鍵的部分,其將一個標準的卷積操作分解為兩步完成。第一步,深度卷積(depthwise convolution):對每個輸入通道利用單個卷積核進行卷積;第二步,逐點卷積(pointwise convolution):利用1×1卷積將上一步的特征圖在深度方向進行加權組合,獲得更多的特征。再引入了Resnet中殘差塊的思想,結合深度可分離卷積的特點生成反殘差塊(inverted residual block)如,從而加強網絡的特征學習。通過反殘差塊的堆疊形成Mobilenetv2網絡,結構如表1。
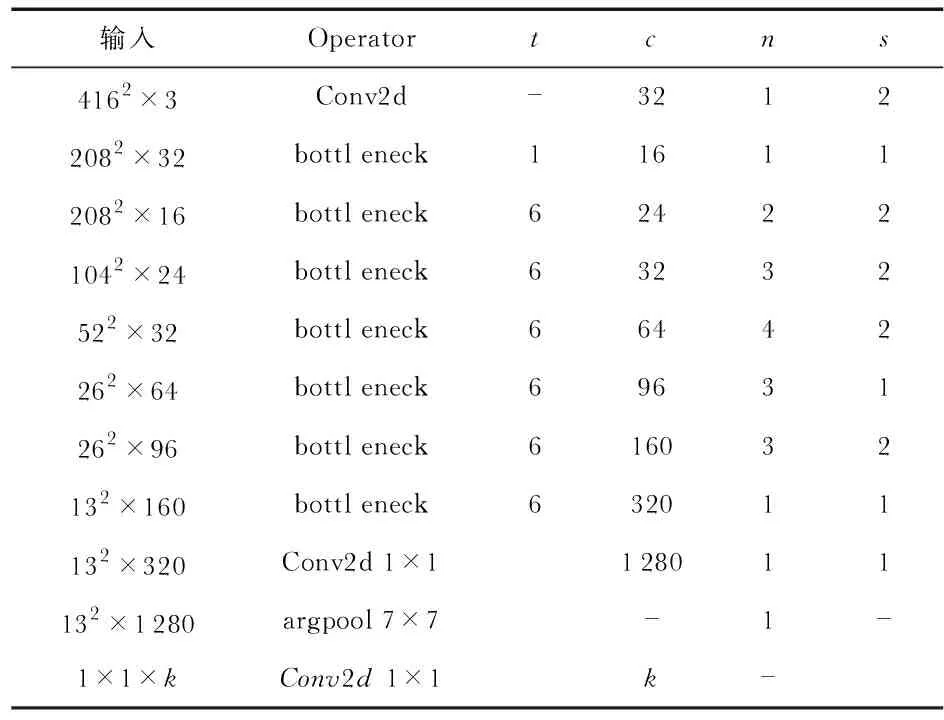
表1 Mobilenetv2網絡結構
其中,t為“擴展”倍數,c為輸出通道數,n為重復次數,s為步長。首先,去掉mobilenetv2網絡的最后的一個平均池化層和一個卷積層,得到維度為320的輸出結果,在其后增添一個1×1×1 280的卷積層。輸入圖像的尺度為416×416,32倍降采樣得到尺度13×13的特征圖;對13×13的特征圖進行2倍的上采樣與第12層的輸出進行拼接得到26×26的特征圖;將26×26的特征圖進行2倍的上采樣與第5層的輸出結果進行拼接得出52×52的特征圖;利用這3種不同尺度的特征圖分別建立特征融合目標檢測層,從而實現大、中、小尺度的預測。改進后的M-YOLOv3結構如圖1。
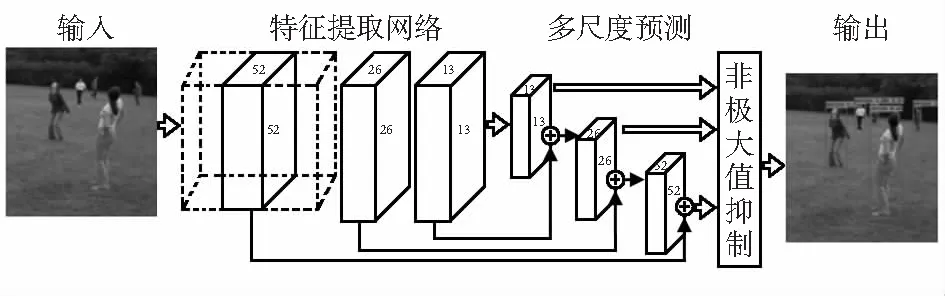
圖1 M-YOLO結構
2.2 行人先驗框的聚類分析
網絡模型雖然自身可以不斷學習并調整邊界框的大小,但提前預備一組合適尺寸的邊界框可以提高模型的性能。YOLOv3算法中引入了Faster R-CNN里anchor(先驗框)的思想,利用K-means算法維度聚類產生固定寬高比的先驗框,初始的先驗框會影響網絡模型對目標檢測的速度和精度。YOLOv3中通過對COCO數據集的維度聚類產生合適寬高比的先驗框。這里K-means里的距離度量并沒有使用標準的歐氏距離,而采用平均交互比(Avg IOU)作為度量
d(box,centroid)=1-IOU(box,centroid)
(3)
式中box為樣本,centroid為簇中心,IOU(box,centroid)表示樣本框與簇中心框的交并比。選取合適的IOU值,可以在網絡模型的速度和精度之間取得較好的平衡。本文采用INRIA數據集,而YOLOv3中先驗框的選擇是針對COCO數據集取得,其寬高比不能較好地表達行人的特征,由此需要對INRIA數據集進行維度聚類設計先驗框,并依據所需模型的性能選取一組合適的先驗框。本文選取先驗框數量1~9,分別對數據集進行維度聚類,得出平均交并比與先驗框數量的關系如圖2。考慮本文所選用的數據集,尺度變化較大,本文選取先驗框的數量為9。
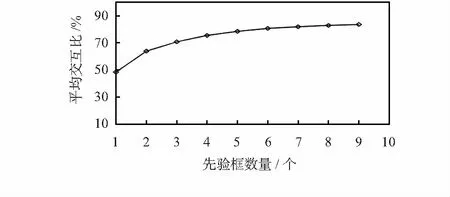
圖2 K-means 維度聚類結果
3 實驗結果分析
INRIA數據集中訓練集和測試集共有正樣本902張,其中包含3 542個行人,圖片中人體大部分為站立姿態且高度大于100像素。行人的尺度變化明顯,背景光線明亮且背景豐富,但其中存在部分標注錯誤的圖片。本文在INRIA數據集的基礎上去除標注信息有誤的圖片得出886張圖片作為實驗數據,隨機劃分為650張訓練集、72張訓練驗證集以及164張測試集。
本文的實驗環境為操作系統:ubantu17.10;深度學習框架:Keras;CPU:英特爾ES-2620 v3;內存:32G;GPU:NVIDA GeForce GTX 1060;
3.1 網絡訓練
本文改進算法M-YOLOv3的訓練和測試輸入尺度均采用416×416,通過多個反殘差塊堆疊形成特征提取網絡提取行人特征,再通過3個不同尺度的特征圖預測行人的位置和坐標信息。針對INRIA數據集,運用K-means維度聚類生成3個尺度的9個先驗框:(31×86),(40×113),(52×146),(60×187),(74×227),(92×291),(120×357),(159×455),(212×602)。分別對YOLOv3和M-YOLOv3進行訓練,初始的學習率為0.001,在迭代次數為 2 000時學習率下降為0.000 1以及在迭代次數為3 000時學習率下降為0.000 01。M-YOLOv3訓練過程中的損失收斂曲線如圖3。
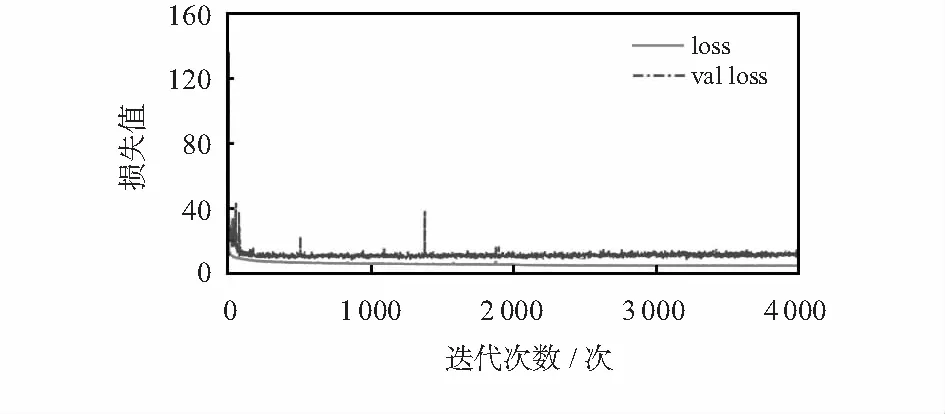
圖3 損失收斂曲線
經過4 000次迭代后,loss和val_loss逐步趨于穩定。最終loss下降到4.6左右,val_loss下降到10左右,表明訓練得到的模型較為理想。圖4為M-YOLOv3在INRIA數據集的檢測效果,其中,對于背景復雜、圖像模糊、行人尺度變化較大且存在遮擋的圖像也有較好的檢測效果。

圖4 M-YOLOv3檢測效果
3.2 性能評價指標
采用來源于信息檢索中對相關性的評價Precision-Recall曲線反映模型對正確檢測出的目標的識別準確程度和覆蓋能力,即召回率(recall)、精度(precision)和AP
(4)
式中TP為正確檢測出目標,FN為沒有被檢測出目標,FP為錯誤檢測目標,AP即PR曲線與x軸圍成的面積。
在測試集上分別對YOLOv3和M-YOLOv3模型進行驗證,得出如圖5所示Precision-Recall曲線對比。
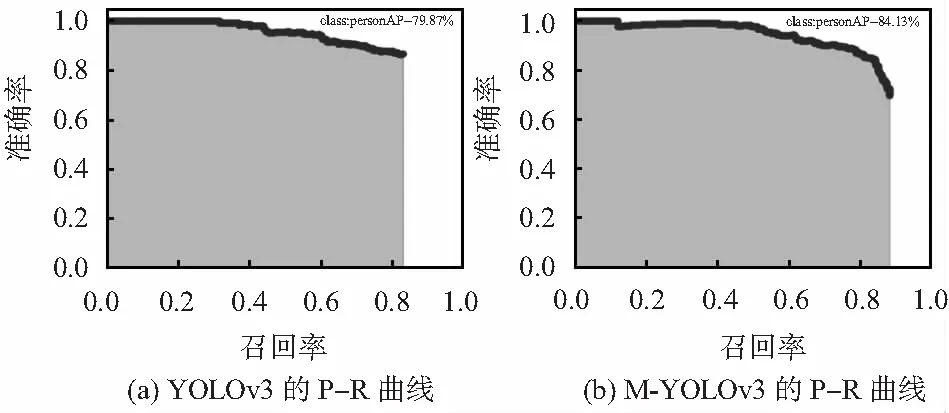
圖5 各網絡P-R曲線
與YOLOv3相比,M-YOLOv3在Precision-Recall曲線上表現的更好。且改進后的M-YOLOv3對行人目標的檢測準確率由79.87 %提升到84.13 %,召回率由83 %提升到88 %。由于模型復雜度的降低,M-YOLOv3較YOLOv3在檢測速度(平均檢測每張圖片所需的時間由0.201 2 s到0.133 5 s)上有著更好的表現。
4 結束語
運用K-means聚類方法對數據集樣本進行聚類分析,提高定位精度,加快收斂。將mobilenetv2作為YOLOv3的基礎網絡,將YOLOv3輸出的32倍下采樣特征圖進行2倍上采樣并與16倍下采樣特征圖拼接,建立輸出為16倍下采樣的特征融合目標檢測層;同樣將16倍下采樣特征圖進行2倍上采樣與8倍下采樣特征圖拼接,建立輸出為8倍下采樣的特征融合目標檢測層。實驗表明,改進后的方法M-YOLOv3在INRIA數據集上準確率、召回率和檢測速度有著不錯的提升。但是改進后的YOLOv3算法在實時性上距離工程應用還有一定差距。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
