基于自監(jiān)督深度學習的人臉表征及三維重建
2019-09-11 02:28:50劉成攀
傳感器與微系統(tǒng) 2019年9期
關(guān)鍵詞:模型
劉成攀, 吳 斌, 楊 壯
(1.西南科技大學 信息工程學院,四川 綿陽 621010; 2.特殊環(huán)境機器人技術(shù)四川省重點實驗室,四川 綿陽 621010)
0 引 言
三維人臉重建能通過稠密人臉對齊獲取三維幾何特征解決二維人臉的大姿態(tài)和遮擋等挑戰(zhàn),是計算機視覺中基礎(chǔ)且備受關(guān)注的任務(wù)。
傳統(tǒng)三維人臉重建主要基于優(yōu)化算法,如迭代最近點[1]獲取3DMM模型系數(shù)進而利用單個臉部圖像渲染相應(yīng)的三維人臉。然而這些方法存在復雜度高、耗費時間長、難以尋找局部最優(yōu)方案以及初始化效果差的問題。隨著卷積神經(jīng)網(wǎng)絡(luò)的發(fā)展,利用神經(jīng)網(wǎng)絡(luò)來學習回歸3DMM系數(shù)顯著改善了三維重建的質(zhì)量和效率。文獻[2]提出的端到端帶有新型損失函數(shù)的卷積神經(jīng)網(wǎng)絡(luò)(3DDFA)改善了大姿態(tài)下面部人臉對齊的性能。文獻[3]提出密集臉對齊(DeFA)并用多個約束和多個數(shù)據(jù)集實現(xiàn)了非常稠密的三維人臉面部對齊結(jié)果。文獻[4]提出基于直接體積回歸的單幅圖像大姿態(tài)三維人臉重建方法(VRN),繞過3DMM的構(gòu)造和匹配,卻需要大量時間來預(yù)測體素信息。文獻[5]提出位置映射回歸網(wǎng)絡(luò)(PRN)的端到端的方法,直接從單個圖像重新獲得完整的三維面部形狀以及語義信息并預(yù)測密集對齊。盡管上述方法高效,但構(gòu)建UV映射的方法卻很復雜。最近,文獻[6]提出的二維輔助自我監(jiān)督學習的算法(2DASL),有效利用二維人臉中的嘈雜地標信息顯著改善三維人臉面部模型學習,在三維面部重建和密集面部對齊方面取得了很高的性能。
除了VRN和PRN,大部分方法都是利用卷積神經(jīng)網(wǎng)絡(luò)回歸估計3DDM參數(shù)。但它們都面臨同重建的三維模型由于人臉姿態(tài)變化不能很好表征區(qū)分個體。目前流行的基于3DMM的方法只考慮一對一重建過程,而不考慮輸入圖像的相關(guān)性或差異,這使獲得的結(jié)果對于人臉表征不可信。
為解決這一問題,本文提出一種新的基于自監(jiān)督深度學習的人臉表征及三維重建算法,基于EfficientNet—B4設(shè)計孿生(Siamese)神經(jīng)網(wǎng)絡(luò)并引入多個損失函數(shù)進行多對一訓練,使不同姿態(tài)下同一個體的不同幾何形狀被約束為相同身份并保留,對3DMM參數(shù)學習的過程更有魯棒性。
1 算法原理
1.1 三維形變模型
三維形變模型3DDM提供了三維人臉形狀參數(shù)S∈R3N,S儲存線性組合關(guān)系的N個網(wǎng)絡(luò)格點的三維坐標[8]。人臉形狀滿足如下函數(shù)關(guān)系
(1)
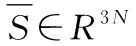
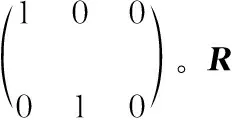
V(g)=f×Pr×R×S+t2d
(2)
1.2 EfficientNet-B4
Google在2019年ICML會上提出一種新的簡單高效模型尺度縮放方法,使用固定的縮放系數(shù)集合,均勻地縮放每個維度[10]。模型的三個互連超參數(shù)的加權(quán)比例為—輸入的分辨率r、網(wǎng)絡(luò)的深度d和網(wǎng)絡(luò)的寬度w。借助這種新的縮放方法,選取殘差神經(jīng)網(wǎng)絡(luò)Resnet—50為基線網(wǎng)絡(luò)進行復合縮放,d,w,r分別設(shè)置為4,2,2。
1.3 孿生神經(jīng)網(wǎng)絡(luò)
整體框架如圖1,將EfficientNet—B4作為孿生神經(jīng)網(wǎng)絡(luò)的骨干,最后兩層被替換為并行全連接層,一層輸出為62維的3DMM參數(shù),另一層是用于面部識別的512維人臉特征向量。
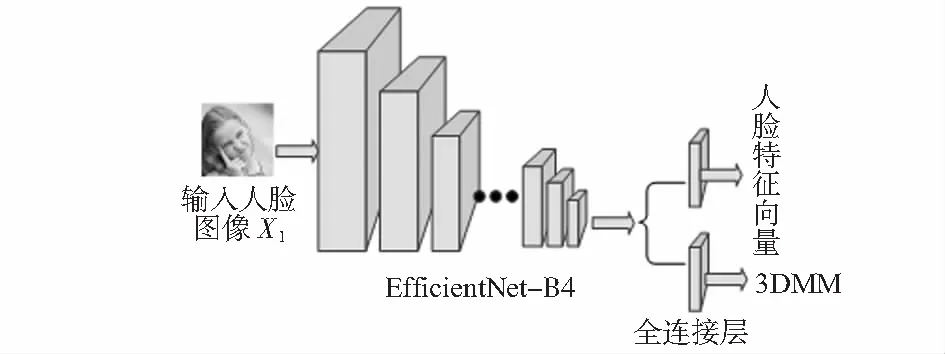
圖1 整體框架
孿生神經(jīng)網(wǎng)絡(luò)如圖2,最左邊為輸入X1和X2,W為學習得到的共享參數(shù)向量,GW(X1)3d和GW(X2)3d為回歸的3DMM參數(shù)。特征空間中,GW(X1)id和GW(X2)id為輸入面部圖像的兩種表示。從GW(X1)3d和GW(X2)3d中各選50個元素作為形狀參數(shù)GW(X1)shp和GW(X2)shp。通過以下3個損失函數(shù)訓練整個模型。
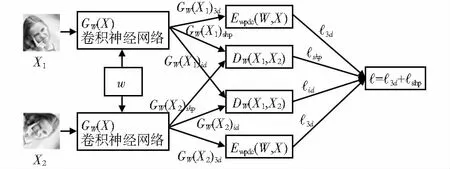
圖2 孿生神經(jīng)網(wǎng)絡(luò)
第一個是三維標注圖像的加權(quán)系數(shù)預(yù)測損失函數(shù),用于衡量模型預(yù)測3DDM系數(shù)時的準確性,第二個是約束損失函數(shù),用于減小臉部受姿態(tài)形變的影響,第三個是身份損失函數(shù),用于確保同身份的人臉在特征空間中具有相似分布。因此,整體的訓練損失函數(shù)為
(3)
1.4 損失函數(shù)
1.4.1 加權(quán)參數(shù)距離損失函數(shù)
根據(jù)3DMM參數(shù)中不同參數(shù)的重要程度引出公式
(4)
(5)
Q=diag(q1,q2,…,q62)
(6)
(7)
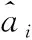
1.4.2 對比損失函數(shù)
參數(shù)化距離損失函數(shù)DW為GW(X1)shp和GW(X2)shp歐氏距離
DW(X1,X2)=‖GW(X1)shp-GW(X2)shp‖2
(8)
將DW(X1,X2)簡寫為DW,損失函數(shù)描述如下
(9)
(1/Y){max(0,m-DW)}2
(10)
式中 (Y,(X1,X2)j)為第j個標記的樣本對,X1和X2為輸入圖像對,若X1和X2都屬于同一人則Y的值為1,否則Y的值為0,P為訓練對的數(shù)量,m為邊距。
對輸出GW(X1)id和GW(X2)id采用相同損失函數(shù),唯一區(qū)別在于DW(X1,X2),其被如下定義
DW(X1,X2)=‖GW(X1)id-GW(X2)id‖2
(11)
2 實驗與結(jié)果分析
2.1 訓練和數(shù)據(jù)集
深度學習框架選擇Tensorflow,選用隨機梯度下降SGD作為優(yōu)化器,神經(jīng)網(wǎng)絡(luò)回歸的學習率呈指數(shù)衰減。初始化訓練損失函數(shù)的學習率3d,shp,exp分別為1×10-2,1×10-3,1×10-4,批量大小設(shè)置為32。采用兩階段策略訓練模,在第一階段采用3d損失函數(shù)訓練,第二階段采用總損失函數(shù)訓練。
300W—LP數(shù)據(jù)集包含超過60 000張帶3DMM系數(shù)注釋的人臉圖片,共7 674個人,每個人有90張不同姿態(tài)的照片[11]。將數(shù)據(jù)集分為兩部分,選取7 036人共計630 694張圖片作為訓練集,638人共57 160張圖片作為驗證集。輸入圖像尺寸為112像素×112像素。在訓練期間,以相同概率生成成對真實和假冒人臉圖片。
測試數(shù)據(jù)集包括兩部分,一部分來自驗證集(TEST1),用于評估三維重建和識別的魯棒性,另一部分為AFLW2000—3D(TEST2),用于評估三維重建的準確性。
2.2 三維人臉重建效果分析
首先用標準嚴格迭代最近點(ICP)的算法[12]重建三維人臉并全局對準真實值。接著計算歸一化的參考長度的坐標偏差衡量指標NME。最后,分析在不同姿態(tài)下NME分配情況并畫出箱線圖見圖3(a)(深色表示文中的方法,淺色表示3DDFA算法)。該方法箱形圖寬度比3DDFA窄,表示在姿態(tài)變化下重建模型受形變影響小。圖3(b)顯示在TEST2上兩種算法的比較結(jié)果,本文算法實現(xiàn)了36.13 %的NME,略低于3DDFA的NME(36.16 %),表明在人臉重建上比3DDFA略好一些。
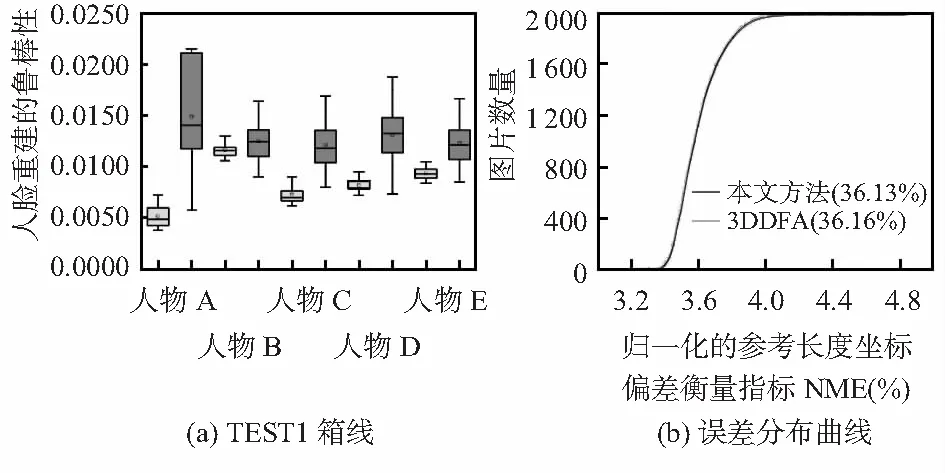
圖3 TEST1箱線與TEST2誤差分布曲線
2.3 在有限條件下的人臉重建效果分析
選取有表情干擾圖片進行實驗,效果如圖4(從左至右依次為原圖、3DDFA效果圖、本文算法效果圖),相比3DDFA算法,本文算法構(gòu)建的三維模型受到表情干擾更少。

圖4 實驗效果圖對比
從TEST1中隨機取6 000對圖像,其中,包含3 000真實對和3 000假冒對,隨機拆分數(shù)據(jù)集進行10次交叉驗證。如圖5所示,該算法達到了97.92 %的識別率。
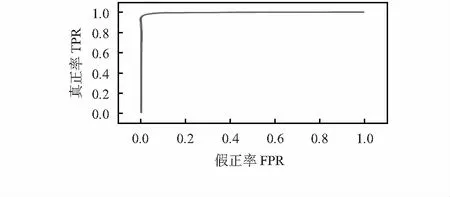
圖5 TEST1上的ROC曲線
3 結(jié) 論
本文采用一種新穎的算法用于增強三維人臉重構(gòu)精確性。將EfficientNet—B4作為主體框架提取3DDM參數(shù)和人臉特征向量。除此之外,引入3個損失函數(shù)增強面部重建的魯棒性,保留面部重建輸入圖像的身份信息。實驗表明:該算法在三維人臉重建和二維人臉識別上比3DDFA表現(xiàn)更為出色。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
