基于Hadoop平臺的網站日志分析系統的設計
2019-09-10 07:22:44劉亮
科學導報·學術 2019年43期
劉亮

摘??要:隨著移動互聯網時代的到來,用戶數據呈現出了爆炸式增長,網站產生的訪問日志也越來越大,達到了GB甚至TB級。大規模的日志中,隱藏了企業感興趣的數據,挖掘其中的價值變得非常重要。網站日志分析系統基于Hadoop大數據處理平臺進行設計,由5個部分組成:由Flume組件收集日志編寫MapReduce應用程序對原始數據進行清洗;通過Hive的HQL對數據進行查詢分析;Sqoop組件將Hive中的數據同步到Mysql;使用Echarts對數據進行可視化。經實驗結果表明,數據量大于10G時,集群較于單結點具有更大的優勢;同時,該技術棧使得Hadoop工程師與軟件工程師的工作可以有效分離,充分利用技術人員的技能特點。
關鍵詞:網站日志;集群;Hadoop;
中圖分類號:TP391?????文獻標識碼:A
一、概述
對于GB、TB級別的半結構化數據的處理,傳統的關系型數據庫已經無法在特定的時間內進行查詢分析,隨著互聯網2.0時代的來臨,Web數據已經呈指數級增長,單一結點的平臺已經無法完成海量數據的分析任務。Hadoop是一個適用于大數據處理分析的分布式平臺,其生態系統組件包括:Flume、Hive、Sqoop等,通過Mapreduce對數據進行預處理,導入至Hive進行統計分析,通過Sqoop組件將分析結果同步到關系型數據庫,對于大規模數據處理方面,該技術棧在企業中得到了廣泛應用。
Echarts是一個強大開源的圖表JS類庫,對Hive的分析結果能夠進行圖表化展示,供企業管理層進行決策。
二、相關技術
Hadoop是一個開源的大數據計算框架,具有HDFS、MapReduce、Yarn三大核心組件,開發人員只需要實現map()以及reduce方法就能夠快速編寫MapReduce程序,大大降低了大數據開發的難度。同時,Hadoop具有強大的生態系統,Flume擅長日志的收集、聚合以及傳輸;Hive是一個數據倉庫系統,提供強大的HQL功能;Sqoop是一款HDFS(Hive)與關系型數據庫的傳遞工具。
ECharts屬于Apache的孵化項目,由百度開發,是一個使用JavaScript實現的開源可視化庫,可以流暢的運行在?PC和移動設備上,提供直觀,交互豐富,可高度個性化定制的數據可視化圖表,在數據可視化方面具有廣泛應用。
三、系統設計
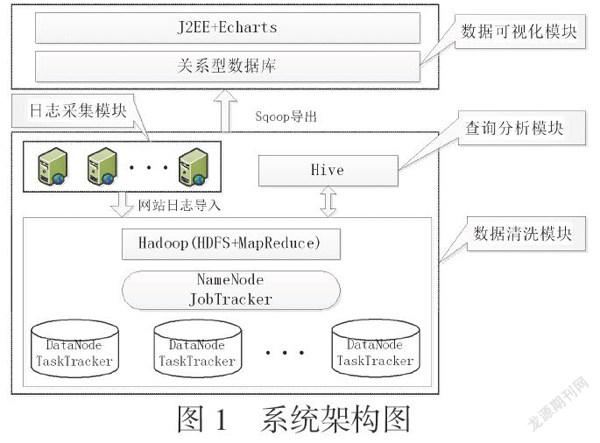
基于MapReduce+Hive+Sqoop+Echarts技術的網站日志分析系統的系統架構如圖1所示:
圖1??系統架構圖
1、日志采集模塊:Flume是一個高可用的日志采集、聚合和傳輸的Hadoop組件,負責將各個前端web服務器中的日志傳送到日志接收節點上。Flume的數據流由事件(Event)貫穿始終。事件是Flume的基本數據單位,它攜帶日志數據(字節數組形式)并且攜帶有頭信息,這些Event由Agent外部的Source生成,當Source捕獲事件后會進行特定的格式化,然后Source會把事件推入(單個或多個)Channel中。你可以把Channel看作是一個緩沖區,它將保存事件直到Sink處理完該事件。Sink負責持久化日志或者把事件推向另一個Source。能保證Flume的可靠性及可恢復性。
2、數據清洗模塊:通過Flume采集過來的日志,通常需要經過特定的處理,此時需要自定義一個MapReduce程序完成特定的任務,將清洗過后的數據,作為Hive的數據源。MapReduce首先對輸入文件分片,Map輸出的中間結果會先放在內存緩沖區中,從緩沖區寫到磁盤的時候,會進行分區并排序,接下來進入reduce階段,每個reducer對應一個ReduceTask,在真正開始reduce之前,先要從分區中抓取數據,相同的分區的數據會進入同一個reduce。這一步中會從所有map輸出中抓取某一分區的數據,在抓取的過程中伴隨著排序、合并,最后得到完整的reduce輸出。
3、查詢分析模塊:Hive部署在Hadoop集群中的NameNode,也即master節點上,具體的查詢分析由HQL來完成。Hive執行具體的?HQL語句的步驟如下:一、用戶通過客戶端組件(cli,webUI等)提交HQL語句。二、驅動器將接收到的?HQL語句發送到編譯器,編譯器將?HQL語句進行解析、優化。最終的優化策略是一個由MapReduce任務和HDFS任務組成的有向無環圖。最后執行引擎利用?Hadoop來執行這些任務。
4、數據可視化模塊:通過Sqoop將Hive查詢結果同步到關系型數據庫,使用J2EE+Echarts技術對結果以圖表形式進行展示。用戶在向其提供的瀏覽器客戶端上輸入或選擇需要查詢的內容,后臺利用J2EE技術連接關系型數據庫,將查詢結果以JSON格式作為Echarts的數據源,進行以圖表、表格等多種形式進行展示。
四、實驗結果分析
為了測試系統,我們在特定的平臺上做了實驗,分別利用幾組規模不同的數據分別在單機情況下和集群情況下進行時間測試。
實驗環境。實驗環境為單機配置為:處理器類型:Intel(R)Core(TM)i5-8250U;內存容量:8GB。Hadoop集群是由5臺與單機配置相同的服務器組成。在集群中的所有服務器上都運行Centos7.4操作系統,并安裝配置?Hadoop?2.8。在這?5臺服務器中,其中的一臺用來作為Master,并安裝配置Hive?2.3.6,其余4臺作為數據節點。
實驗數據及內容。在實驗中,我們采用實際網站中的日志作為輸入。實驗的內容是統計某一給定的時間片內,用戶訪問網站使用的代理工具前五排名。
③?實驗結果分析。通過分析實驗結果,我們發現,如果數據量小于5G,那么?Hadoop集群并不能發揮其海量處理的優勢,甚至時間消耗大于單機處理。但是,當要處理的網站日志達到10G的時候,Hadoop集群的優勢就會隨著數據量的逐漸增大而顯現出來。如圖?2所示。
圖2??單擊與集群模式耗時比對圖
五、結論
本文使用了Flume、MapReduce、Hive、Sqoop、Echarts等技術設計了一種基于Hadoop集群的網站日志分析平臺,相比于單機模式具有較大的優勢,數據量越大越能體現出集群的優勢;同時,該平臺使得Hadoop工程師可以專注于數據的收集、清洗及分析,傳統軟件工程師可以專注于數據可視化,將兩者的工作有效分離出來,克服了開發人員的技能短板問題,能夠面向企業商業應用,具有積極的推廣意義。
參考文獻
[1]??云計算中Hadoop技術研究與應用綜述[J].夏靖波,韋澤鯤,付凱,陳珍.計算機科學.2016(11).
[2]??周勇,劉鋒.基于Hadoop的Web日志分析系統的設計[J]?軟件工程,2019,2(3):11—12.
[3]??基于Hadoop平臺的日志分析模型[J].于兆良,張文濤,葛慧,艾偉,孫運乾.計算機工程與設計.2016(02)
[4]??陳苗,陳華平.基于Hadoop的Web日志挖掘[J].計算機工程,2011,37(11):37-39.
[5]??TomWhite.Hadoop權威指南[M].曾大聃,周傲英,譯.北京:清華大學出版社,2010.
