基于Spark的水泥廠煤耗特性分析與實時診斷
2019-09-03 07:45:10吳敬兵唐漢卿蔡思堯
自動化與儀表 2019年8期
吳敬兵,唐漢卿,蔡思堯
(武漢理工大學 機電學院,武漢 430070)
水泥制造業(yè)是中國建材的重要產(chǎn)業(yè),雖然我國水泥生產(chǎn)消費量居世界首位,但在能耗管控方面與世界先進水平相差甚遠。我國生產(chǎn)每噸水泥的煤耗比世界先進水平要高出20%,電耗高出23%。為響應我國綠色發(fā)展的號召,國內(nèi)水泥行業(yè)需要著重加強能耗管控。當今世界進入了大數(shù)據(jù)時代,大數(shù)據(jù)技術(shù)在互聯(lián)網(wǎng)領(lǐng)域得到了廣泛的應用,各種傳統(tǒng)行業(yè)也都在順應大數(shù)據(jù)的潮流,應采用相關(guān)技術(shù)從海量數(shù)據(jù)中挖掘有價值的信息以改善生產(chǎn)。制造業(yè)的數(shù)據(jù)量雖然不是特別巨大,但數(shù)據(jù)之間的相關(guān)性極為復雜,而且智能制造設備的數(shù)據(jù)需要實時處理[1],任務極為艱巨。
在此背景下開展了水泥廠大數(shù)據(jù)應用的研究,搭建了大數(shù)據(jù)計算平臺,建立了煤耗特性的數(shù)學模型,對實時采集的水泥廠設備運行數(shù)據(jù)進行煤耗預測與診斷,得出具備指導意義的分析結(jié)果。
1 大數(shù)據(jù)平臺架構(gòu)
1.1 大數(shù)據(jù)生態(tài)圈介紹
1)Hadoop Hadoop是分布式系統(tǒng)的基礎(chǔ)架構(gòu),是大數(shù)據(jù)技術(shù)的基礎(chǔ),其核心部分是HDFS和MapReduce。HDFS為分布式文件系統(tǒng),設計用于部署在低廉的硬件上并提供高吞吐量;MapReduce是一款大批量計算的模型,目前已很少使用。Spark,F(xiàn)link等新興的計算引擎速度更快,但它們均基于Hadoop的計算框架。
2)Spark Spark是當前最流行的大數(shù)據(jù)內(nèi)存計算框架,可以基于Hadoop上存儲的數(shù)據(jù)進行計算;提供了大量的庫,包括 SQL,DataFrames,MLlib,GraphX,Spark Streaming。開發(fā)者可以在同一個應用程序中無縫組合使用這些庫,以完成復雜的流處理、機器學習算法、數(shù)據(jù)庫存取等功能[2]。
3)HBase HBase是一個分布式的、面向列的開源數(shù)據(jù)庫。它不同于一般的關(guān)系數(shù)據(jù)庫,是一個適合于非結(jié)構(gòu)化數(shù)據(jù)存儲的NoSQL數(shù)據(jù)庫。其小批量查詢速度快,適合作為查詢功能的媒介。
4)Flume Flume是一個高可用、高可靠、分布式的海量日志采集、聚合和傳輸?shù)南到y(tǒng);支持在日志系統(tǒng)中定制各類數(shù)據(jù)發(fā)送方用于收集數(shù)據(jù)。同時,F(xiàn)lume提供對數(shù)據(jù)進行簡單處理,并寫到各種數(shù)據(jù)接受方的功能。
5)Kafka Kafka是一種高吞吐量的分布式發(fā)布訂閱消息系統(tǒng),運行在普通硬件上的Kafka也可以支持每s百萬條消息,具備高吞吐量,支持通過Kafka服務器和消費機集群來分區(qū)消息,支持Hadoop并行數(shù)據(jù)加載。
1.2 平臺架構(gòu)
平臺采用架構(gòu)如圖1所示。數(shù)據(jù)處理流程如下:
步驟1采集水泥廠過往穩(wěn)態(tài)運行數(shù)據(jù)與煤耗數(shù)據(jù)存儲到HBase以及HDFS中。
步驟2使用Spark提取過往數(shù)據(jù),調(diào)用MLlib機器學習算法庫中的算法對數(shù)據(jù)進行處理以及建立煤耗特性模型。
步驟3采用Flume對接Kafka的方式采集實時數(shù)據(jù)到Spark Streaming,輸入到煤耗特性模型以及診斷模型中計算后將結(jié)果寫入HBase和MySQL。
步驟4在Web端讀取HBase中的結(jié)果數(shù)據(jù)并使用Echarts實現(xiàn)數(shù)據(jù)的可視化處理。

圖1 平臺架構(gòu)Fig.1 Platform architecture
2 煤耗特性建模
2.1 數(shù)據(jù)計算流程
步驟1采集、清洗數(shù)據(jù)。采集水泥生產(chǎn)設備的穩(wěn)態(tài)運行數(shù)據(jù)10000條,并進行數(shù)據(jù)清洗,剔除錯誤或異常數(shù)據(jù),以防止其帶來的模型精度誤差[3]。
步驟2特征選擇。由于水泥生產(chǎn)設備的運行數(shù)據(jù)種類繁多,即對于煤耗指標來說特征值過多,嚴重影響計算速度與模型精度[4]。因此,需要先使用降維算法中的特征選擇算法對特征進行篩選,計算出各特征對煤耗變化的權(quán)重并按大小排列,剔除對煤耗影響較小的特征。
步驟3計算各特征的基準值。使用聚類算法將篩選出來的特征計算出基準值,為后續(xù)煤耗診斷提供參考指標。
步驟4建立煤耗特性模型。將清洗、篩選后的數(shù)據(jù)分為訓練數(shù)據(jù)和測試數(shù)據(jù)兩部分,使用訓練數(shù)據(jù)建立煤耗特性的數(shù)學模型,使用測試數(shù)據(jù)評定模型的精度并反復調(diào)優(yōu)。
2.2 特征選擇
2.2.1 特征選擇的意義
水泥生產(chǎn)設備數(shù)量多且體積龐大,運行參數(shù)繁多,設備內(nèi)部還布置有很多的傳感器監(jiān)測點。每一種數(shù)據(jù)都是煤耗的一個特征值,而過多的特征會帶來較大的模型精度誤差,因此要使用特征選擇算法選出對煤耗影響較大的一部分特征。
特征選擇的意義如下:①減少所需的存儲空間;②加快計算速度;③去除冗余特征,即對煤耗完全沒有影響的特征;④提高模型精度,太多的特征或太復雜的模型可能導致過擬合。
2.2.2 Stability selection 穩(wěn)定性選擇算法
將采用Stability selection穩(wěn)定性選擇算法來實現(xiàn)水泥廠高維數(shù)據(jù)的特征選擇。
Stability selection穩(wěn)定性選擇算法是特征選擇類型中較為新穎的算法,將2次抽樣和選擇算法相結(jié)合,具有很高的精度。它的主要思想是在不同的數(shù)據(jù)子集和特征子集上運行特征選擇算法,不斷地重復,最終匯總特征選擇結(jié)果,結(jié)果用得分的形式來表示各特征的影響系數(shù)大小。理想情況下,重要特征的得分會接近1,稍微弱一點的特征得分會是非零數(shù),而最無用的特征得分將會接近于0。
2.2.3 特征選擇結(jié)果
穩(wěn)定性選擇算法執(zhí)行的部分結(jié)果見表1。特征選擇將選取影響得分>0.5的32個特征。
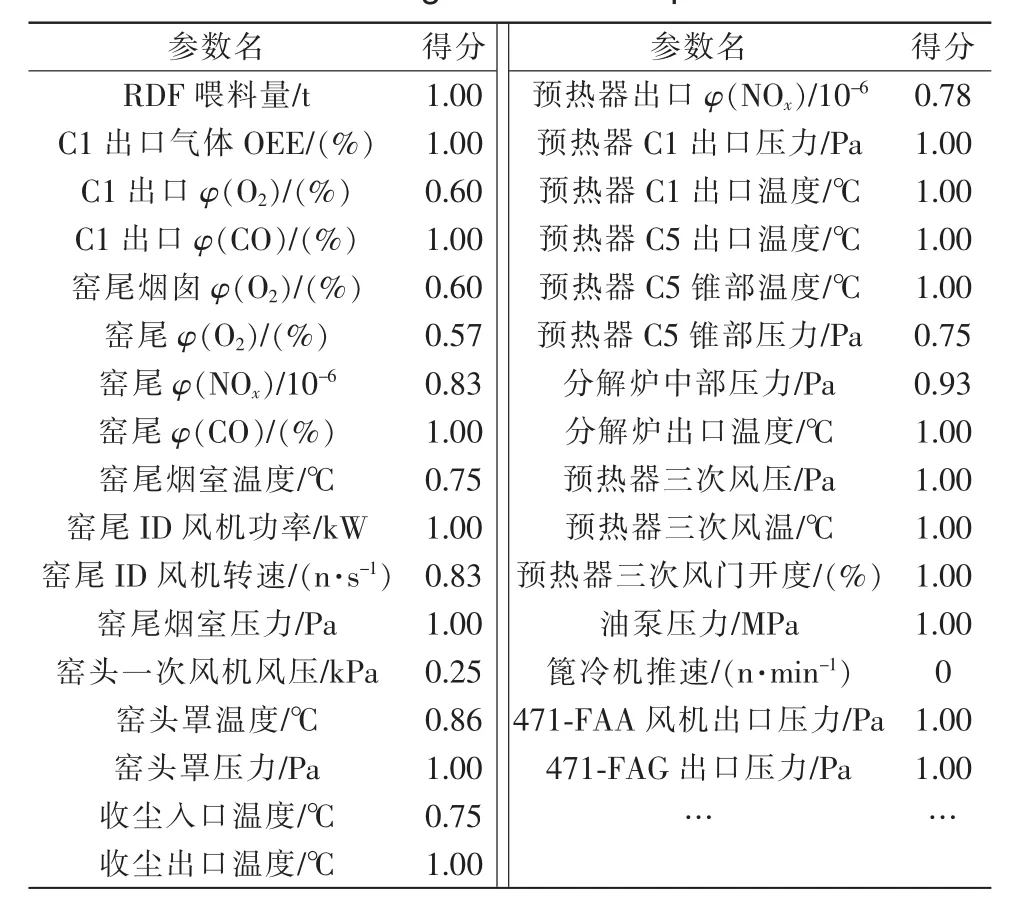
表1 特征對煤耗的影響系數(shù)Tab.1 Coefficient of characteristic influencing coal consumption
2.3 基準值計算
2.3.1 K-means||聚類算法
將采用K-means||聚類算法計算各特征的基準值。
K-means是一種被廣泛使用的聚類算法,原理簡單,計算快并且精度較高,但必須提前確定聚類中心的個數(shù)。而煤耗的特征數(shù)量是已知的,特征數(shù)量即為聚類中心的個數(shù)。K-means||是K-means的一種改良版,在并行計算的同時還改變了每次遍歷時的取樣策略,大大提升了效率。
K-means算法的原理是基于相似度將數(shù)據(jù)樣本劃分到距離最近的類中,每個類由其類中心的位置代表,因此算法的本質(zhì)是將每個數(shù)據(jù)樣本劃分到與其相似度最大的類中心所對應的類中[5]。
計算相似度即為計算距離,使用歐式距離進行判定,即

算法的主要步驟如下:
步驟1初始化k個類中心,k即特征數(shù)量;
步驟2計算數(shù)據(jù)樣本與各類中心的距離,將數(shù)據(jù)樣本劃分到最近的類中;
步驟3更新類中心;
步驟4重復前2個步驟直到滿足收斂條件。
2.3.2 聚類結(jié)果
聚類僅對特征選擇出來的15種特征進行計算,部分結(jié)果見表2。
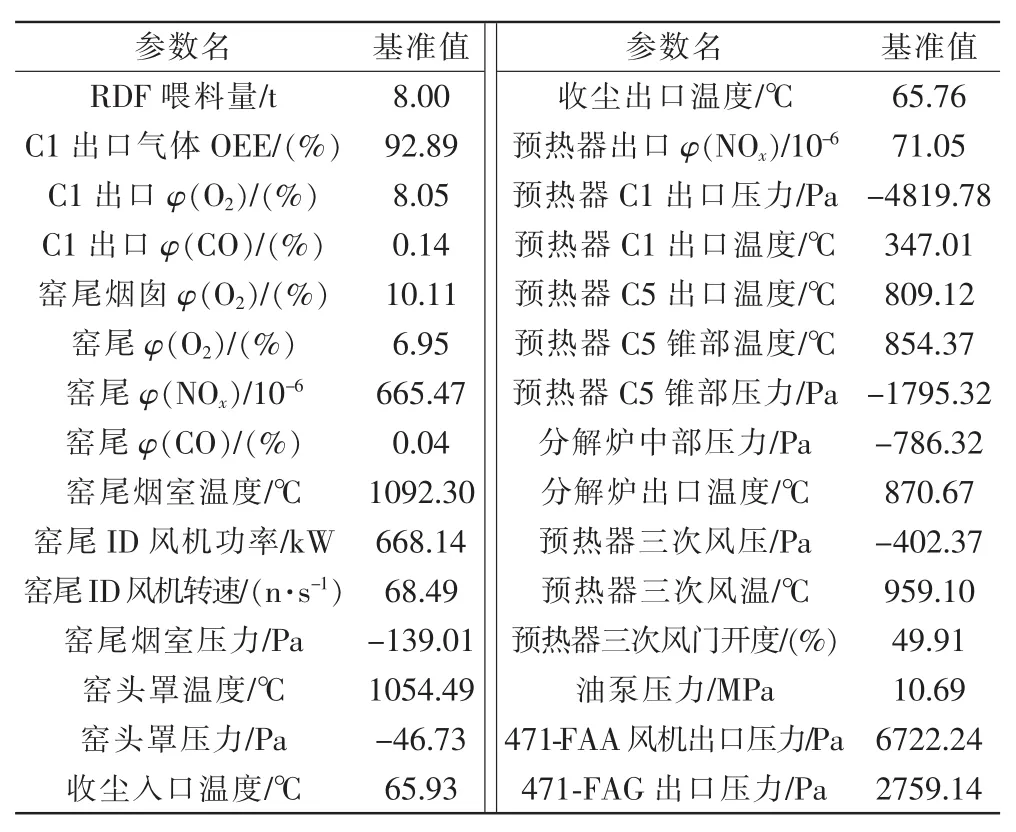
表2 選定特征的基準值Tab.2 Baseline values of selected features
2.4 建立煤耗特性模型
2.4.1 Random Forest隨機森林算法
將采用隨機森林算法的回歸功能建立水泥廠煤耗特性模型。
Random Forest隨機森林算法是一種集成算法(Ensemble Learning),具有速度快,模型精確度極高,功能多樣等諸多優(yōu)點。隨機森林算法主要用于分類與回歸問題,屬于Bagging類型,通過組合多個弱分類器,通過投票進行分類,通過取均值進行回歸[6],使整體模型的結(jié)果具有較高的精確度和泛化性能。隨機森林算法原理如圖2所示,執(zhí)行原理及步驟如下:
1)從訓練數(shù)據(jù)中隨機抽取部分樣本,作為每棵樹的根節(jié)點樣本。
2)在建立決策樹時,隨機抽取部分候選屬性,從中選擇最合適的屬性作為分裂節(jié)點。
3)建立好隨機森林后,對于測試樣本,進入每一棵決策樹進行類型輸出或回歸輸出。若為分類問題,以投票的方式輸出最終類別;若為回歸問題,每一棵決策樹輸出的均值作為最終結(jié)果。
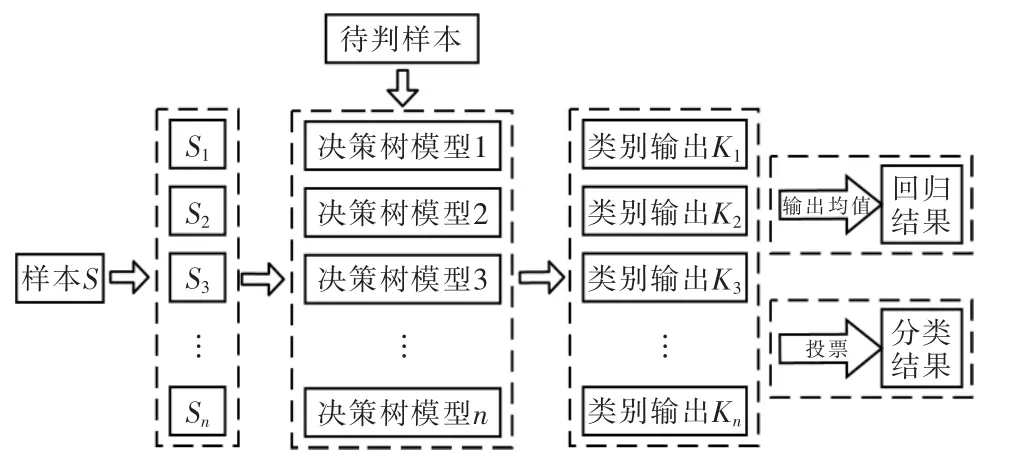
圖2 隨機森林原理Fig.2 Principle of random forest
2.4.2 數(shù)據(jù)預處理
在Spark中,隨機森林回歸所采用的數(shù)據(jù)格式為LIBSVM格式,因此在訓練模型之前需要先將采集到的數(shù)據(jù)轉(zhuǎn)換為此格式。LIBSVM的每一條數(shù)據(jù)類型為LabeledPoint,其格式為
label index1:value1 index2:value2 index3:value3…
其中:label為目標值即煤耗;index為特征索引;value為特征值。
2.4.3 煤耗特性模型
建立回歸模型首先將數(shù)據(jù)分為2份,70%作為訓練數(shù)據(jù),30%作為測試數(shù)據(jù)。訓練完成后,代入測試數(shù)據(jù)計算均方誤差以評估模型準確度,通過改變參數(shù)、對比誤差對模型進行調(diào)優(yōu)。隨機森林回歸算法的部分Scala代碼如下:


3 煤耗的實時預測與診斷
3.1 計算規(guī)劃
煤耗特性建模各步驟均為離線計算,無需部署在服務器端,直接編寫代碼調(diào)用Spark API運行在IDE上即可,只需在計算完成后將基準值存為一個Array[Double]類型的變量,將模型保存在項目resource目錄下以便煤耗預測與診斷時進行快速調(diào)用。
煤耗預測與診斷需要實時計算,將使用Spark Streaming進行流處理,并且需要將項目打包提交到服務器端運行,以實時的接收數(shù)據(jù)。
3.2 實時數(shù)據(jù)的采集
在大數(shù)據(jù)技術(shù)中,采集實時數(shù)據(jù)常用Fume-Kafka-Spark Streaming的方式,相較于Flume直接對接Spark Streaming的方式,具有數(shù)據(jù)推送穩(wěn)定,數(shù)據(jù)丟失率低的優(yōu)點[7]。
1)配置 Flume的 conf文件,主要參數(shù)設置:sources.command=tail-F 加水泥廠日志文件名稱,追蹤文件,將新增數(shù)據(jù)發(fā)送給 Kafka,將 sinks.type設置為 org.apache.flume.sink.kafka.KafkaSink,將 sinks.kafka.topic設置為項目名,提交任務后flume就會將數(shù)據(jù)傳輸給Kafka。
2)在啟動Kafka的consumer時傳入 topic名,這樣Kafka就會接收到Flume的數(shù)據(jù)。
3)在Spark提交的項目程序包中使用KafkaUtils.createStream()方法并傳入topic名,就可以獲取由Kafka推送來的數(shù)據(jù)。
Flume配置文件部分內(nèi)容如下:


3.3 煤耗預測
在項目程序中,使用 RandomForestModel.load()方法讀取煤耗特性模型,并傳入從Kafka接收到的數(shù)據(jù),即可實時預測在當前工況下將會產(chǎn)生的煤耗。由于僅得到預測的煤耗值對于水泥廠調(diào)整煤耗沒有太大的實際意義,因此需要建立診斷模型以計算出具有價值的結(jié)果。
3.4 煤耗診斷
采用控制變量法計算每一特征造成的煤耗偏差,以該值與其所占總煤耗偏差的比重來表示該特征實時值的優(yōu)劣,據(jù)此判斷該特征對應的運行參數(shù)是否需要調(diào)整。煤耗診斷結(jié)果存儲到HBase和MySQL中。煤耗診斷模型為

式中:Pi為第i個特征造成的煤耗偏差占總煤耗偏差的比重;f(x)為煤耗特性模型,計算結(jié)果為預測煤耗;xc為特征的實時值;xb為特征的基準值。
4 數(shù)據(jù)可視化
數(shù)據(jù)可視化能夠使復雜的計算結(jié)果變得一目了然,大大提升觀感和信息理解速度。
使用Echarts提取HBase中的診斷結(jié)果來生成圖表的方式實現(xiàn)數(shù)據(jù)可視化,使用ajax實現(xiàn)圖表的實時更新,可視化效果如圖3所示。
由圖可見,分解爐出口溫度這一參數(shù)的當前數(shù)值處于較差的狀態(tài),會導致噸熟料煤耗增加3.57 kg,占此時總煤耗增值的23.11%。
5 結(jié)語
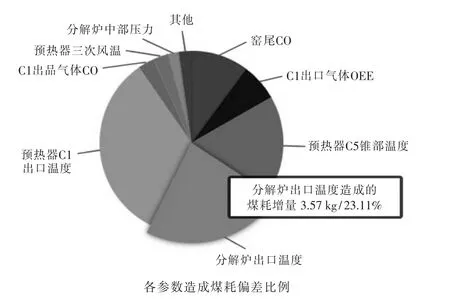
圖3 煤耗實時診斷結(jié)果可視化Fig.3 Visualization of real-time diagnosis results of coal consumption
將大數(shù)據(jù)、數(shù)據(jù)挖掘技術(shù)引入水泥廠的煤耗管控中,為水泥廠搭建大數(shù)據(jù)計算平臺,建立煤耗特性模型,實時采集設備運行參數(shù)進行煤耗診斷,判斷可能引起較大煤耗偏差的參數(shù),從而為水泥廠調(diào)整煤耗提供參考。還研究了煤耗特性模型的建模方法、實時采集數(shù)據(jù)和實時診斷的方法,為將要應用大數(shù)據(jù)技術(shù)的水泥廠提供一些技術(shù)思路和參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
