分布式存儲系統(tǒng)中容錯技術綜述
2019-08-30 03:31:56劉景偉
無線電通信技術 2019年5期
關鍵詞:信息
李 鑫,孫 蓉,2*,劉景偉
(1.西安電子科技大學 綜合業(yè)務網(wǎng)理論及關鍵技術國家重點實驗室,陜西 西安 710071;2.華僑大學 廈門市移動多媒體通信重點實驗室,福建 廈門 361021)
0 引言
在當前云計算時代,全球流量快速增長,互聯(lián)網(wǎng)、物聯(lián)網(wǎng)、移動終端、安全監(jiān)控和金融等領域的數(shù)據(jù)量呈現(xiàn)出“井噴式”增長態(tài)勢。存儲在云服務器中數(shù)據(jù)的增長速率甚至超越了摩爾法則,云存儲系統(tǒng)成為云計算的關鍵組成部分之一。數(shù)據(jù)的飛速增長對存儲系統(tǒng)的性能和擴展性提出了更苛刻的挑戰(zhàn)。傳統(tǒng)的存儲系統(tǒng)采用集中式的方法存儲數(shù)據(jù),使得數(shù)據(jù)的安全性和可靠性均不能保證,不能滿足大數(shù)據(jù)應用的需求。分布式存儲系統(tǒng)以其巨大的存儲潛力、高可靠性和易擴展性等優(yōu)點成為大數(shù)據(jù)存儲的關鍵系統(tǒng)并被推廣應用到降低存儲負荷、疏通網(wǎng)絡擁塞等業(yè)務領域上,且其以高吞吐量和高可用性成為云存儲中的主要系統(tǒng)。目前Hadoop分布式文件系統(tǒng)(Hadoop Distributed File System,HDFS)作為谷歌文件管理系統(tǒng)(GFS)[1]的開源實現(xiàn)已成為最主流的分布式系統(tǒng),它被應用于許多大型企業(yè),如Facebook,Yahoo,eBay,Amazon等。
為了應對海量數(shù)據(jù)的存儲需求,該類存儲系統(tǒng)的規(guī)模往往非常龐大,一般包含幾千到幾萬個存儲節(jié)點不等。早在2014年,中國互聯(lián)網(wǎng)百度公司單個集群的節(jié)點數(shù)量就超過了10 000[2]。近兩年,騰訊云的分布式調度系統(tǒng)VStation管理和調度單集群的節(jié)點數(shù)量可達100 000。然而數(shù)量龐大的節(jié)點集群經(jīng)常會產(chǎn)生如電源損壞、系統(tǒng)維修及網(wǎng)絡中斷等故障致使節(jié)點失效頻發(fā)。據(jù)一些大型分布式存儲系統(tǒng)的統(tǒng)計數(shù)據(jù)表明,平均每天都會有2% 左右的節(jié)點發(fā)生故障[3]。在過去一年中,迅速發(fā)展的云計算市場不斷涌出如谷歌云、亞馬遜AWS、微軟Azure及阿里云等主流云服務器大型宕機事件[4]。
由此可見,全球的云服務器發(fā)生故障導致數(shù)據(jù)丟失的情況時有發(fā)生。顯然,能夠可靠存儲數(shù)據(jù)并有效修復失效數(shù)據(jù)的容錯技術對分布式存儲系統(tǒng)的重要性不言而喻。因此如何及時有效地修復失效節(jié)點,確保數(shù)據(jù)能被正常地讀取和下載就顯得非常重要。據(jù)統(tǒng)計,在一個有3 000個節(jié)點的Facebook集群中,每天通常至少會觸發(fā)20次節(jié)點修復機制。具有節(jié)點修復能力的數(shù)據(jù)容錯技術是通過引入冗余的方式來保證分布式存儲系統(tǒng)的可靠性,存儲系統(tǒng)能夠容忍一定數(shù)量的失效節(jié)點,即提高了系統(tǒng)的數(shù)據(jù)容錯能力。
為了保證用戶訪問數(shù)據(jù)的可靠性、維持分布式存儲系統(tǒng)的容錯性,需要及時修復失效節(jié)點。良好的容錯技術要求存儲系統(tǒng)具有低的冗余開銷、低的節(jié)點修復帶寬、低的編譯碼復雜度等特點。如何降低失效節(jié)點的修復帶寬、降低磁盤I/O、降低存儲系統(tǒng)編譯碼的復雜度、提高系統(tǒng)的存儲效率成為分布式存儲中研究的熱門方向,因此,能夠有效彌補多副本機制和MDS碼不足的分布式存儲編碼應運而生。
1 傳統(tǒng)的存儲容錯
傳統(tǒng)最常見也是最早的存儲容錯是多副本機制和MDS碼。通常,多副本機制引入冗余簡單,但其存儲負載很大,存儲效率非常低,如Google文件系統(tǒng)和Hadoop文件系統(tǒng)等。傳統(tǒng)的最大距離可分(Maximum Distance Separable,MDS)碼結構可以實現(xiàn)分布式存儲編碼,比如里德-所羅門(Reed-Solomon,RS)碼,以及Google Colossus,HDFS Raid,Microsoft Azure,Ocean Store等。其存儲成本更低,但是其擁有更高的修復成本和訪問延遲,而且沒有考慮存儲開銷、磁盤I/O開銷等,因此并不適合用于大規(guī)模分布式存儲系統(tǒng)。
1.1 多副本機制
多副本機制是產(chǎn)生冗余最基本的方式。為了彌補數(shù)據(jù)失效帶來的損失,確保存儲系統(tǒng)中數(shù)據(jù)的完整性,將數(shù)據(jù)的副本存儲在多個磁盤中,只要有一個副本可用,就可以容忍數(shù)據(jù)丟失。如圖1所示。如果數(shù)據(jù)以最常見的3副本方式存儲,那么原始數(shù)據(jù)會被復制到3個磁盤上,因此任何1個磁盤故障都可以通過剩余2個磁盤中任意1個來修復。顯然,該3副本機制有效的存儲空間理論上不超過總存儲空間的1/3,多副本機制顯著降低了存儲效率。
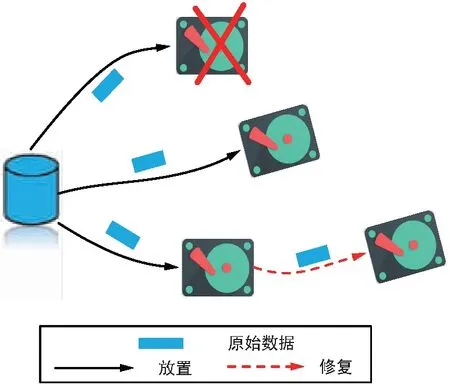
圖1 3副本機制
1.2 MDS碼
如果系統(tǒng)編碼設計的目標是在不犧牲磁盤故障容忍度的前提下最大化存儲效率,那么存儲系統(tǒng)采用MDS碼來儲存數(shù)據(jù),因為它可以為相同的存儲開銷提供更高的可靠性。也就是說MDS碼是一種能提供最優(yōu)儲存與可靠性權衡的糾刪碼。在一個分布式存儲方案中,原始文件首先被分成k個數(shù)據(jù)塊,接著它們編碼生成n個編碼塊并存儲在n個節(jié)點中。訪問任意l(l≥k)個節(jié)點,通過糾刪碼的譯碼就可恢復出原始文件,如果l=k,該碼就滿足MDS性質,最多能夠容忍(n-k)個節(jié)點的失效。如圖2所示,原始文件被MDS碼編碼生成5個數(shù)據(jù)塊并放置到5個磁盤中。任意某個磁盤損壞,都能通過訪問其他4個幸存磁盤中的3個來修復。
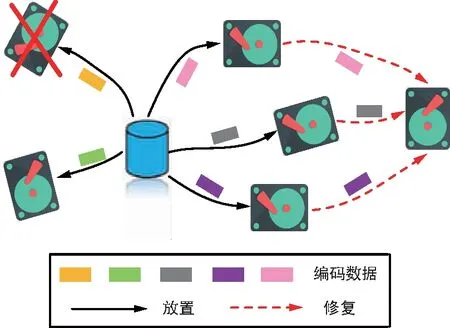
圖2 (5,3)MDS碼修復失效磁盤
MDS碼的3個主要缺點阻礙了它在分布式存儲系統(tǒng)中的推廣。首先,為了讀取或寫入數(shù)據(jù),系統(tǒng)需要對數(shù)據(jù)進行編譯碼,由于CPU限制會導致高延遲和低吞吐量。根據(jù)調研,即使Facebook存儲系統(tǒng)的集群中用MDS碼只編碼一半數(shù)據(jù),修復流量也會使集群中的網(wǎng)絡鏈路接近飽和。其次,MDS碼修復失效節(jié)點時必須訪問多個編碼塊,而訪問的這些編碼塊足以得到所有的原始數(shù)據(jù),這樣的修復代價也太大了。最后,托管在云存儲中的應用程序對磁盤I/O性能很敏感,且由于大多數(shù)數(shù)據(jù)中心引入鏈路超額配置;因此帶寬始終是數(shù)據(jù)中心內的有限資源,使得MDS碼的節(jié)點修復在帶寬開銷和磁盤I/O開銷方面都非常昂貴。
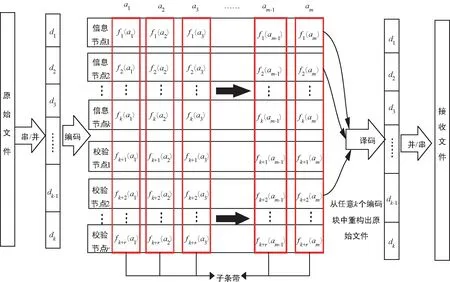
圖3 采用MDS編碼的分布式儲存模型
2 分布式存儲編碼及性能比較
為了降低修復故障節(jié)點的帶寬開銷,有幾種分布式存儲編碼,即再生碼[6](Regenerating Codes,RGC)、局部可修復碼[7](Locally Repairable Codes,LRC)和MDS陣列碼等被提出來,它們都有各自的優(yōu)缺點。如RGC和LRC的修復帶寬較小,但由于它們在修復過程中有大量的矩陣運算,計算復雜度很高,因此構造過程非常復雜;Piggybacking編碼的研究還處在起步階段,有很多理論和實際應用還不太完善;MDS陣列碼如EVENODD,B-code,X-code,RDP,STAR,Zigzag碼等,它們的編譯碼過程基本都是構建在低階域的簡單運算之上,復雜度低。但受限于陣列碼的構造過程,它們所設計的冗余節(jié)點很少,導致其容錯能力有限,修復能力一般都比較弱,修復效率較低。目前,在容錯技術中存儲和修復性能更勝一籌的分布式存儲編碼主要有 3類:① 注重存儲與修復開銷平衡的RGC;② 面向優(yōu)化磁盤I/O開銷的LRC,③ 不改變系統(tǒng)節(jié)點分布結構的Piggybacking編碼。
2.1 RGC
為了降低MDS碼的節(jié)點修復帶寬,Dimakis等人受網(wǎng)絡編碼的啟發(fā)將編碼數(shù)據(jù)的修復建模為信息流圖,從而提出了再生碼,其約束條件是維持容忍磁盤故障的能力[6]。基于此模型來表征存儲與帶寬之間的最優(yōu)權衡,即給定磁盤上存儲的數(shù)據(jù)量大小,可以得到修復過程中需要傳輸數(shù)據(jù)量的最優(yōu)下界。
2.1.1 RGC原理
在信息流圖中,所有的服務器可以分為源節(jié)點、存儲節(jié)點和數(shù)據(jù)收集器,其中源節(jié)點表示數(shù)據(jù)對象產(chǎn)生的服務器。圖4為RGC信息流圖。
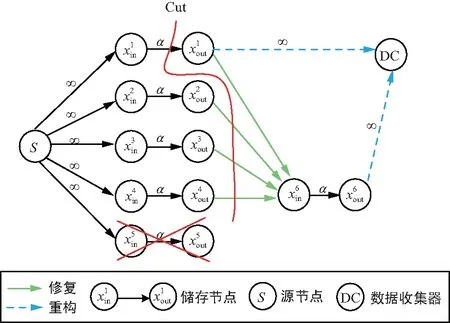
圖4 RGC信息流圖
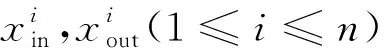
MDS碼節(jié)點的數(shù)據(jù)恢復是要新生節(jié)點接收來自服務器(數(shù)據(jù)提供者)的k個數(shù)據(jù)塊后,在新生節(jié)點上進行編碼產(chǎn)生節(jié)點新數(shù)據(jù)。但再生碼是在數(shù)據(jù)提供者和新節(jié)點上都能進行編碼,即數(shù)據(jù)提供者(存儲節(jié)點)有不止一個編碼段。當需要修復節(jié)點時,提供者先發(fā)送自己編碼段的線性組合,新節(jié)點將接收到的編碼段再次編碼重構新的節(jié)點。如圖5所示,假定任意2個磁盤都足以恢復原始數(shù)據(jù)的MDS碼,即k=2,每個磁盤存儲一個包含2個編碼段的編碼塊。對MDS碼而言,恢復故障磁盤至少需要給新磁盤發(fā)送2個編碼塊(4個編碼段)。但數(shù)據(jù)經(jīng)提供者編碼后再發(fā)送給新磁盤的數(shù)據(jù)量可減少至1.5個編碼塊(3個編碼段),這樣就能減小數(shù)據(jù)的傳輸量,降低25%的帶寬消耗。
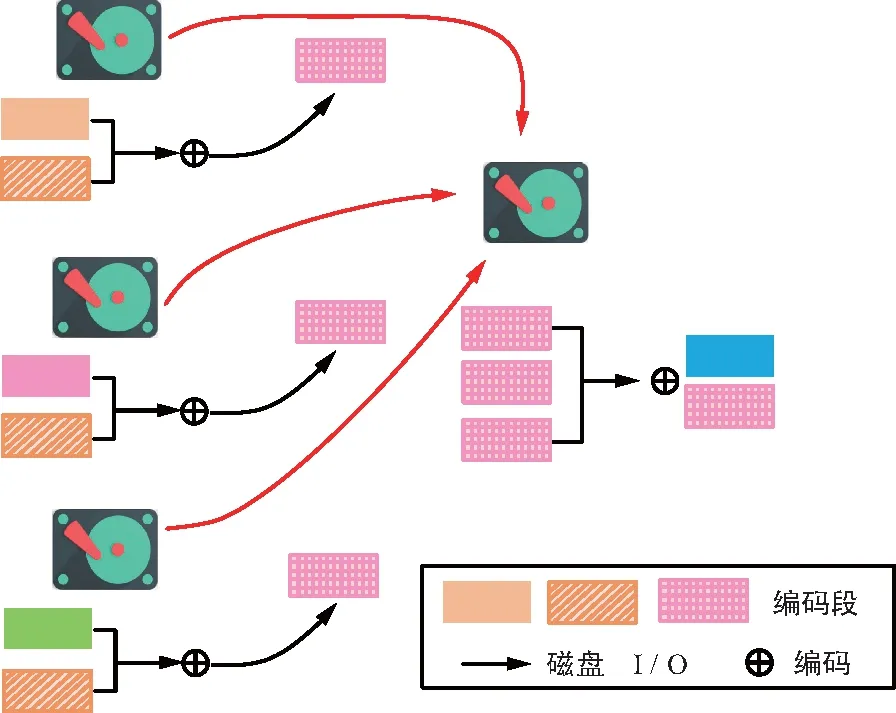
圖5 RGC基本原理圖
Dimakis等人利用信息流圖計算最小割界得到失效節(jié)點修復帶寬的下限曲線,再生碼就是在存儲開銷α和修復帶寬γ的最優(yōu)曲線上。該曲線上存在最小存儲和最小修復帶寬這2個極值點。達到存儲最小的極值點的編碼稱為最小存儲再生碼(Minimum Storage Regenerating Codes,MSR)[7],達到修復帶寬最小極值點的編碼稱為最小帶寬再生碼(Minimum Bandwidth Regenerating Codes,MBR)[8]。
MSR的節(jié)點存儲大小和節(jié)點修復帶寬可以表示為:
MDS碼的存儲開銷最小,而MSR碼節(jié)點的儲存開銷就等于傳統(tǒng)MDS碼的節(jié)點大小,因此可以被當做MDS碼。當d=n-1時,則上式變?yōu)椋?/p>
當n趨于無窮大時,其修復帶寬等于一個編碼塊大小,但MDS碼的修復帶寬為k倍的編碼塊大小,因此MSR碼節(jié)省很大的修復帶寬。
MBR的節(jié)點存儲大小和節(jié)點修復開銷可以表示為:
當d=n-1時,則上式變?yōu)椋?/p>
從上式可以看出,MBR碼的節(jié)點存儲大小和修復開銷一致,存儲和修復帶寬大小比一個編碼塊稍微大些,因此其修復帶寬非常小。
2.1.2 RGC發(fā)展現(xiàn)狀
分布式存儲網(wǎng)絡中一個重要的性能指標是它的安全性。RGC除了數(shù)據(jù)存儲容錯外,還可以應用在信息安全上。它是一種用于提供數(shù)據(jù)可靠性和可用性的分布式存儲網(wǎng)絡編碼,能實現(xiàn)高效的節(jié)點修復和信息安全[9]。其中竊聽者可能獲得存儲節(jié)點的數(shù)據(jù),也可能訪問在修復某些節(jié)點期間下載的數(shù)據(jù)(如果竊聽者發(fā)現(xiàn)添加到系統(tǒng)中的新節(jié)點替換了失效的節(jié)點,那么它就可以訪問修復期間下載的所有數(shù)據(jù),這嚴重威脅了數(shù)據(jù)的安全和隱私)。在這種不利環(huán)境下,Dimakis提出了RGC的準確構造從而實現(xiàn)了信息保密,即在不向任何竊聽者透露任何信息的情況下,可以安全存儲并向合法用戶提供最大的數(shù)據(jù)量,同時得到了一般分布式存儲系統(tǒng)保密容量的上限,并證明了這個界對于帶寬受限的系統(tǒng)來說是緊密的,這在點對點分布式存儲系統(tǒng)中是有用的[10]。考慮用分散數(shù)據(jù)保護一個分布式存儲系統(tǒng)的問題,研究了節(jié)點間交互在減少總帶寬方面的作用[11]。當節(jié)點相互獨立,交互是沒有用的,并且總是存在一個最優(yōu)的非交互方案。除此之外,RGC在信息安全保密方面也有研究[12]。
RGC按照故障節(jié)點的修復特點可分為功能性修復和準確性修復。功能性修復是指恢復新節(jié)點后使系統(tǒng)仍具有MDS性,以維持對故障節(jié)點的容忍度,一般的再生碼都是功能性修復。準確性修復是指新生節(jié)點中的數(shù)據(jù)與被修復失效節(jié)點中的數(shù)據(jù)相同。因此在前期研究基礎上出現(xiàn)了準確RGC的概念,當節(jié)點失效后能進行準確修復,這意味著系統(tǒng)形式的編碼結構可以結合準確重構節(jié)點來實現(xiàn)與多副本機制一樣低的訪問延遲。常用的方法是干擾對齊技術,把不需要的向量對齊到相同的線性子空間以達到消除的目的[13]。
目前大多數(shù)關于RGC的研究都集中在單一節(jié)點的恢復上,但是在大型分布式存儲系統(tǒng)中同時看到2個或更多的節(jié)點故障是很常見的。為了充分利用好修復多個故障節(jié)點的契機,一種協(xié)同修復機制應運而生,即修復節(jié)點之間可以相互共享數(shù)據(jù)。此類RGC被稱為合作RGC[14],它的出現(xiàn)使得用更低的帶寬來修復多個故障節(jié)點成為可能。
縱然RGC達到了存儲與帶寬開銷之間的最優(yōu)權衡,但因為其需要繁瑣的數(shù)學參數(shù)和復雜的編碼理論基礎,實現(xiàn)過程很難。目前RGC大多在有限域GF(2q)上進行多項式運算。加法在計算機上處理較為簡單,然而乘法和除法卻相對復雜,更有甚者需要用到離散對數(shù)和查表才能處理。這使得RGC的編譯碼復雜度很高,因而很難滿足分布式存儲系統(tǒng)對計算復雜度的要求。RGC作為MDS碼的改進版,擁有良好的理論基礎,但是現(xiàn)有的絕大部分RGC編譯碼復雜度很高且碼率低,所以迫切地提出高碼率且編譯碼復雜度低的RGC,這具有積極的現(xiàn)實意義。若同時結合磁盤I/O、數(shù)據(jù)存儲安全和網(wǎng)絡結構等方面構造,能進一步推廣RGC的應用范圍。
2.2 LRC
與通過犧牲磁盤I/O開銷來節(jié)省帶寬消耗的RGC不同, LRC具有較少的磁盤訪問數(shù)量。它是通過強制一個失效節(jié)點中的數(shù)據(jù)只能通過某些特定的存儲節(jié)點來進行修復,從而減少需要讀取和下載的數(shù)據(jù)量來降低修復帶寬。雖然這種方式犧牲了對節(jié)點故障的容忍度(LRC的理論可譯性:能夠修復信息理論上可譯的故障模式,即LRC不具有MDS性質),以犧牲少量存儲開銷為代價(增加了額外的局部校驗塊),但會顯著降低磁盤I/O開銷。眾所周知,磁盤I/O開銷越大,使用壽命就越短。因此LRC在數(shù)據(jù)容錯技術中的地位不容小覷。
2.2.1 LRC的原理
常規(guī)的RGC修復故障節(jié)點時,都需要請求幸存節(jié)點將其數(shù)據(jù)的線性組合發(fā)送給新節(jié)點,即RGC僅僅針對存儲與修復開銷,而沒能節(jié)省磁盤I/O。在修復故障節(jié)點過程中,RGC最終從幸存節(jié)點讀取的數(shù)據(jù)量將遠遠多于寫入新節(jié)點的數(shù)據(jù)量,過多的磁盤I/O操作會嚴重影響數(shù)據(jù)中心的總體磁盤I/O性能,使得磁盤I/O開銷成為存儲系統(tǒng)中故障節(jié)點恢復的一個主要性能瓶頸[15]。磁盤I/O開銷與修復故障節(jié)點時訪問的幸存節(jié)點數(shù)目(即局部修復度)成正比,因此訪問的幸存節(jié)點數(shù)越少(局部修復度越小),磁盤I/O開銷就越少。需要明確的是,寫操作發(fā)生在新節(jié)點上,且寫操作的數(shù)據(jù)量等于一個存儲節(jié)點的大小。由于寫操作作為重構新節(jié)點的最后一步是不可或缺的,因此在實際修復過程中更關心的是從幸存節(jié)點中讀取的數(shù)據(jù)量。
MDS碼修復一個節(jié)點要求讀取k個編碼塊。從圖5可以看到,RGC中數(shù)據(jù)提供者的編碼操作不能減少讀的數(shù)據(jù)量,只是減少了數(shù)據(jù)的傳輸量,因為發(fā)送編碼后的數(shù)據(jù)是需要讀取節(jié)點內整個編碼塊(所有編碼段)之后再進行編碼才生成的。因此,有2種方法可以降低磁盤I/O開銷。第1種,從幸存節(jié)點中選取特定的編碼段,而位于同一節(jié)點中的其他編碼段因為沒有參與編碼就不用讀取;第2種,選取少量的特定節(jié)點作為數(shù)據(jù)提供者而不是任意k個節(jié)點。特別是,LRC采用的是第2種方法。假定任意3個節(jié)點都足以得到原始數(shù)據(jù)的MDS碼,即k=3。修復一個故障節(jié)點,MDS碼和再生碼需要讀取6個編碼段,而圖6中卻只需要讀取2個特定的編碼段,所以能降低磁盤I/O開銷。
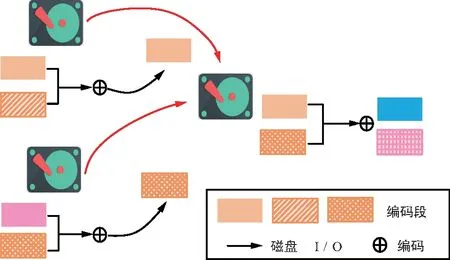
圖6 訪問特定編碼段(或/和特定節(jié)點)來降低磁盤I/O開銷
LRC之所以能通過選定特定節(jié)點來修復失效節(jié)點是因為它以額外的存儲開銷為代價,任意某個節(jié)點都可以通過某些特定的編碼塊進行修復,減少了修復過程中連接的節(jié)點數(shù),也減少了磁盤I/O開銷。雖然LRC具有較好的局部修復特性,但卻無法擁有像MSR碼和MBR碼等那樣較低的存儲與修復開銷。目前采用LRC編碼的大型系統(tǒng)主要有Facebook的分布式文件系統(tǒng)HDFS和微軟的Azure[11]。且Azure已廣泛應用于微軟內部的網(wǎng)絡搜索、視頻服務、音樂游戲及醫(yī)療管理等業(yè)務。LRC的實現(xiàn)方法主要包括分層編碼(Hierarchical Codes,HC)和簡單再生碼(Simple Regenerating Codes,SRC)。HC是將原始文件進行編碼(一般采用RS碼)之后,進行二次編碼得到額外的局部冗余校驗塊。當需要恢復一個失效節(jié)點時,通過訪問該故障節(jié)點所在分組內的幸存節(jié)點和該組內編碼產(chǎn)生的局部校驗塊即可,而并不需要像MDS碼那樣訪問更多的幸存節(jié)點,因此HC可以降低故障節(jié)點的修復帶寬和磁盤I/O操作。Papailiopoulos等人將可糾正多個錯誤的RS碼與簡單的異或運算結合,構造出一類LRC,即SRC[16]。該方案通過訪問少量幸存節(jié)點來修復單節(jié)點故障,利用特定的放置規(guī)則降低了失效節(jié)點的修復帶寬。
2.2.2 LRC 的發(fā)展現(xiàn)狀
LRC除了有數(shù)據(jù)容錯存儲的應用外,國際上已經(jīng)有學者開始嘗試利用LRC解決分布式存儲中的安全問題。2016年,Kumar等人為分布式存儲設計了一種可修復噴泉碼(Repairable Fountain Codes,RFC),在信息安全理論上提出了針對存儲節(jié)點的竊聽模型,應對通過失效節(jié)點的修復來竊取其他幸存節(jié)點數(shù)據(jù)的威脅[17]。Rawat等人通過平衡LRC的安全性和修復度,提出了安全性最佳的局部修復度結構的編碼方案,可有效抵抗監(jiān)聽[18]。在2017年,Kadhe等人又通過內碼和外碼的聯(lián)合設計,構造了一種廣泛的安全存儲碼方案,同時考慮了MSR碼和LRC這2種分布式存儲編碼。
目前,學術上針對單個節(jié)點失效LRC的研究主要集中在以下的構造方法中:
① 基于二元LDPC碼的構造:2016年,Hao等人闡述了一類有著多修復組的LRC與二元LDPC碼的關系,提出了用正則LDPC碼去構造LRC的方法[19]。2017年,Su等人在上述工作基礎上基于循環(huán)置換矩陣和仿射變換矩陣提出了2種二元LRC的構造方法,達到了距離限[20]。
② 基于聯(lián)合信息可用性構造:2017年,Kim等人利用聯(lián)合信息的可用性(任何可譯碼的糾刪符號集可以從任何一組具有小基數(shù)的多個不相交符號集進行修復)提出了LRC的2個Alphabet-Dependent限[21]。
③ 基于圖模型的構造:2017年,Kim等人還利用具有r個頂點和t個邊的超圖構造出了有著(r,t)可用性的二元LRC[22]。此前,他還提出過2個具有聯(lián)合修復度的LRC的獨立上限,并利用簡單圖模型設計出滿足該獨立上限的LRC,利用簡單圖設計出具有最佳碼率和聯(lián)合信息修復度的LRC[23]。
④ 基于平均修復度的構造:LRC的平均修復度,影響著修復帶寬的大小、磁盤I/O的開銷。Shahabinejad等人提出了一個適用于任意LRC的平均修復度的下限,并設計出3種LRC。2017年,他們通過研究信息塊的最佳平均修復度,得到了一個更低的下限[24]。
⑤ 基于Matroid理論的構造:Westerb等人給出了擬陣與LRC之間的聯(lián)系,通過線性的或者一般仿射來使用這些擬陣結構,可以構造新的LRC[25]。Tamo等人也通過擬陣提出了簡單準確的LRC構造[26]。
⑥ 基于Rank-Metric碼的構造:Silberstein等人基于最大秩距離(Maximum Rank Distance,MRD)Gabidulin碼提出了LRC的構造方法[27],采用串行級聯(lián)編碼的結構,用MDS碼作為外碼,RGC或LRC作為內碼,實現(xiàn)容錯存儲。
2.3 Piggybacking編碼
相比于RGC和LRC,Piggybacking編碼以其較低的計算復雜度、設計靈活等特點開始在數(shù)據(jù)容錯技術中占有一席之地。編碼設計完成后,它不改變原有系統(tǒng)的節(jié)點分布結構,不產(chǎn)生額外的存儲負載、在修復失效數(shù)據(jù)時將底層碼的譯碼替代為求解與失效數(shù)據(jù)相關的Piggyback方程。這樣不僅顯著降低了修復帶寬,還有效降低了修復復雜度,為海量數(shù)據(jù)可靠、高效的存儲提供了強有力的保障。
2.3.1 Piggybacking編碼的原理
2013年Rashmi等人首次提出了Piggybacking框架的概念,且將該框架下構造的Piggybacking編碼用來應對存儲系統(tǒng)中頻發(fā)的故障節(jié)點[28]。他們解釋Piggybacking的含義是將MDS碼作為基本碼,將擴展后的MDS碼中某些條帶的數(shù)據(jù)符號通過精心設計好的Piggyback函數(shù)嵌入到其他條帶中形成Piggyback塊的一種設計。失效的數(shù)據(jù)符號可以通過求解Piggyback方程來替代傳統(tǒng)的MDS譯碼來恢復,這樣能有效降低修復帶寬。
Piggybacking編碼的框架是在一個任意的、被稱為基本碼的基礎上操作,目前的基本碼都采用MDS碼。Piggybacking編碼保持了基本碼的很多屬性,比如最小距離和操作域。Piggybacking框架有一個顯著的特點就是在不改變原有存儲節(jié)點的分布結構下減少了額外的存儲開銷,即不需要增加除MDS編碼以外的校驗節(jié)點,依舊能保持數(shù)據(jù)重建性。另外,Piggybacking編碼滿足MDS性質可以實現(xiàn)高碼率,擁有少的子條帶數(shù)和修復節(jié)點時更少的平均數(shù)據(jù)讀取量和下載量等特點。另一個特別吸引人的點就是Piggybacking編碼支持任意碼長為n、信息位長度為k的基本碼(碼參數(shù)的選擇取決于基本碼的需要)。然而有的碼如Rotated-RS碼,當校驗節(jié)點數(shù)r∈{2,3}和信息節(jié)點數(shù)k≤36時才存在[29];EVENODD碼和RDP碼也只在r=2時才可以實現(xiàn)。再加上Piggybacking編碼設計靈活、復雜度低和易于系統(tǒng)實現(xiàn)等特點,目前已經(jīng)應用于Facebook Warehouse Cluster,HDFS等系統(tǒng)中[30]。通常Piggybacking編碼采用系統(tǒng)形式,因為系統(tǒng)形式中的信息節(jié)點承載了所有未編碼的原始數(shù)據(jù)。因此用戶通過直接訪問信息節(jié)點就可以得到原始數(shù)據(jù),而不用訪問某些校驗節(jié)點采用MDS譯碼來恢復原始數(shù)據(jù),這樣不僅降低了獲取原始數(shù)據(jù)的復雜度,還降低了獲取數(shù)據(jù)的延遲。
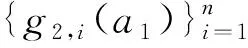

圖7 Piggybacking框架
2.3.2 Piggybacking編碼的發(fā)展現(xiàn)狀
作為Piggybacking編碼的鼻祖,Rashmi等人提出了3種Piggybacking設計[29]。第1種設計是基于較少的子條帶數(shù)量,其中最少的子條帶數(shù)只有2。這類設計修復信息節(jié)點時根據(jù)碼參數(shù)不同可以節(jié)省25%~50%不等的修復帶寬,且該設計也具備修復校驗節(jié)點的能力。經(jīng)計算表明,當整個Piggybacking框架采用的條帶(例)數(shù)m越大時,修復帶寬越低,修復效率越高。第2種設計是由(2r-3)列結構相同的MDS碼組成,并在最后(r-1)列中增加了Piggyback方程。該設計要求校驗節(jié)點數(shù)r≥3,相比第1種設計擁有更高的修復效率,平均能有效減少約50%的修復帶寬。這是以犧牲子條帶數(shù)量為代價:要求最少子條帶數(shù)為(2r-1),且該設計不能有效修復校驗節(jié)點。作者將關注度從修復帶寬轉移到修復度上,設計了第3種Piggybacking編碼,該碼可以有效修復最小修復度可達k+1的MDS碼中的信息節(jié)點。
隨著Piggybacking編碼被提出,研究者們正試圖尋找構造有效的Piggybacking框架來修復失效節(jié)點。Yuan等人提出一種廣義的Piggybacking編碼,并證明了當校驗節(jié)點數(shù)趨于無窮大時,信息節(jié)點的修復帶寬比率趨近于零,而且非常接近分布式存儲編碼修復帶寬的理論極限(cut-set bound[31])。Kumar等人針對信息節(jié)點的修復設計了一種Piggybacking框架,然而該Piggybacking結構并沒有維持MDS性質[32],且當B類校驗節(jié)點數(shù)增加時,信息節(jié)點的修復帶寬會減少,同時也增加了系統(tǒng)的存儲負載。Shangguan等人提出了一種Piggybacking編碼用于修復信息節(jié)點,他們根據(jù)不同Piggyback塊中嵌入的信息符號數(shù)量的不同將信息節(jié)點進行劃分,由此獲得了較低的修復帶寬[33]。Yang等人保證信息節(jié)點可修復的同時,為減少校驗節(jié)點的修復帶寬提出了一種Piggybacking框架[34]。
2.3.3 Piggybacking編碼的理論研究、構造與應用
Piggybacking編碼的研究主要處在理論和構造階段,因此從Piggybacking碼的理論研究、構造和可能應用的這3個方向對其研究內容進行闡述,其結構如圖8所示。
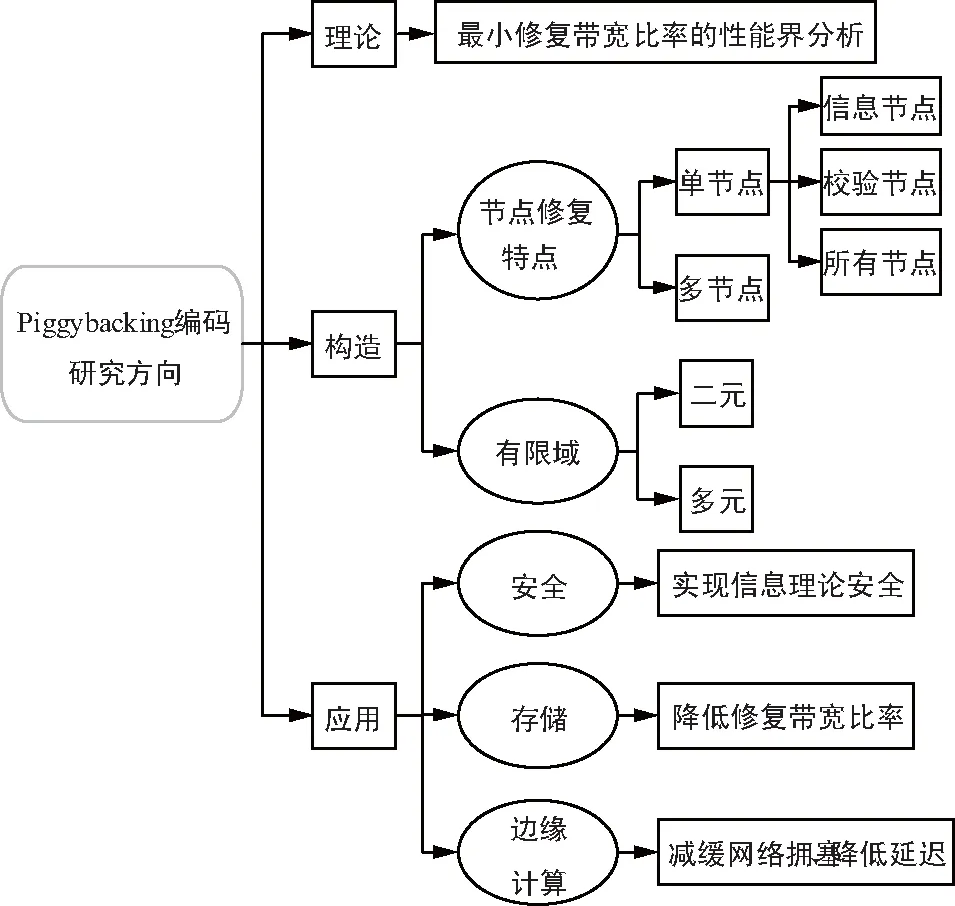
圖8 Piggybacking編碼的研究方向
2.3.3.1 理論研究
Piggybacking編碼通常是以MDS碼作為基本碼,然而MDS碼的弊端很多,比如:系統(tǒng)中MDS碼的編譯碼操作經(jīng)常會導致高延遲和低吞吐量的情況,MDS碼的修復代價太高,MDS碼修復度較大,對磁盤I/O性能不友好。更加遺憾的是,由于MDS碼的編譯碼復雜度很高,會導致Piggybacking編碼的編譯碼復雜度也不低。因此對于Piggybacking編碼來說,選擇復雜度低的基本碼是降低自身復雜度最快、也是最有效的方法。比如可以考慮將復雜度較低的類LDPC碼來作為基本碼。
一種Piggybacking編碼性能的好壞,不僅在于其具有較低的修復帶寬比率,更希望它能有更快的收斂速度,有最小的修復帶寬比率下界。因此,需要對該碼的最小修復帶寬比率的性能界進行分析。收斂速度越快,說明該碼的最小修復帶寬比率下降速度越快;最小修復帶寬比率能達到的下界越低,說明該碼的修復性能越好。
2.3.3.2 構造
理論上基于有限域構造,通過Piggyback塊構造后產(chǎn)生的Piggybacking編碼不改變基本碼的有限域,也就是說Piggyback函數(shù)設計得到的Piggybacking編碼不僅適用于二元域,也同樣適用于多元域Fq(q為素數(shù)冪)。根據(jù)面向修復節(jié)點特點主要分為單節(jié)點修復和多節(jié)點修復,具體如下。
(1)單節(jié)點修復
在Piggybacking編碼的構造階段,也就是設計Piggybacking的框架,目前所有研究只是停留在單節(jié)點的修復設計上,而且大部分都是針對信息節(jié)點的修復,檢驗節(jié)點的非常少,而同時有效修復所有節(jié)點的Piggybacking碼就更少。本小節(jié)針對這3種編碼設計,分析構造它們所采取的構造思路如下:
a.信息節(jié)點的修復
一種Piggybacking編碼能夠修復信息節(jié)點,是因為Piggyback函數(shù)中嵌入了信息節(jié)點中的原始信息數(shù)據(jù),然后將這些Piggyback函數(shù)嵌入到不同校驗節(jié)點中的不同子條帶(或條帶)中。顯然,當信息節(jié)點失效時,帶有信息節(jié)點中失效信息數(shù)據(jù)符號的Piggyback函數(shù)存在于沒有損壞的校驗節(jié)點中,通過這些函數(shù)構造的逆過程即求解Piggyback方程,可得到失效數(shù)據(jù)。但當校驗節(jié)點失效時,失效的校驗符號沒有留下任何與之相關的Piggyback函數(shù)(塊),因此該Piggybacking編碼就無法通過求解Piggyback方程來恢復,只能通過該Piggybacking編碼基本碼的MDS性質譯出。但這樣的修復帶寬是大于通過求解Piggyback方程來恢復失效數(shù)據(jù)的修復帶寬,且當基本碼的編碼參數(shù)增大(分布式存儲系統(tǒng)規(guī)模的增大),通過MDS性質譯出的修復帶寬是遠遠大于通過求解Piggyback方程的。
對于不同的Piggybacking編碼而言,其最小修復帶寬比率(或修復效率)與修復帶寬比率的收斂速度均不相同。這與該Piggybacking編碼的Piggyback函數(shù)和該Piggyback塊放置的位置息息相關。一般情況Piggybacking編碼的修復帶寬比率越低,修復效率越高,其Piggyback函數(shù)構造的復雜度就越高,方法就越巧妙。
通常可以采用整體法和分集法。整體法是將所有信息節(jié)點中的信息數(shù)據(jù)看成一個大的集合,需要構造出一種Piggyback函數(shù),將這些數(shù)據(jù)按照此編碼規(guī)則統(tǒng)一進行嵌入;分集法是將信息節(jié)點進行分組(理論分析,一般均分后的性能是最優(yōu)的),針對每個集合需要對應構造出一種Piggyback函數(shù),不合集合之間的函數(shù)不同,將各自集合中的信息數(shù)據(jù)采用與之對應的Piggyback函數(shù)進行嵌入。經(jīng)分析,分集法的修復帶寬比率的收斂速度大于整體法,因此它的修復效率更高,復雜度也較高。
b.校驗節(jié)點的修復
同理,一種Piggybacking編碼能夠修復校驗節(jié)點,是因為Piggyback函數(shù)中嵌入了校驗節(jié)點中的校驗符號數(shù)據(jù),將這些Piggyback函數(shù)嵌入到不同校驗節(jié)點中的不同條帶(或子條帶)中。與修復信息節(jié)點的Piggybacking編碼相比不同的是:該Piggyback塊也需加到校驗節(jié)點上,而不是信息節(jié)點上。通常為了用戶方便有效讀取和下載數(shù)據(jù),分布式存儲系統(tǒng)一般是系統(tǒng)節(jié)點,也就是當系統(tǒng)中信息節(jié)點沒有損壞時用戶只需讀取下載信息節(jié)點中自己需要的數(shù)據(jù)即可,無需進行MDS譯碼操作,這樣可以大大降低復雜度和讀取延遲。只有當信息節(jié)點或校驗節(jié)點失效時,才會動用嵌在校驗節(jié)點中的Piggyback塊進行失效節(jié)點的修復。
由于修復校驗節(jié)點的校驗塊就放在校驗節(jié)點上,因此該種Piggybacking編碼就有了一個與修復信息節(jié)點Piggybacking編碼不同的設計關鍵:校驗節(jié)點的修復依賴與它相關的校驗節(jié)點,因此必須保證每個校驗節(jié)點的Piggyback塊(用于修復校驗節(jié)點)不能嵌入本校驗節(jié)點的校驗符號,假如該校驗節(jié)點失效后,該節(jié)點中的校驗符號連同與其唯一相關的Piggyback塊一起丟失,該符號就無法通過Piggyback方程譯出。為了提高Piggyback方程的可解性,即保證每個數(shù)據(jù)符號都能被正確恢復出,要求每個失效信息節(jié)點里的待嵌入數(shù)據(jù)符號不能嵌入同一個Piggyback塊里(避免出現(xiàn)方程式的個數(shù)少于未知數(shù)個數(shù)的情況),因此這些數(shù)據(jù)符號需要盡可能地散列,當然這個條件對修復信息節(jié)點的設計也需要滿足。為了設計修復帶寬比率低的用于修復校驗節(jié)點的Piggybacking編碼,除了滿足上面的設計要求,還在于Piggyback函數(shù)的巧妙設計。也可采用整體法和分集法,分析比較它們之間的修復效率。
c.所有節(jié)點的修復
經(jīng)過對以上2種節(jié)點修復方法的簡單描述,本節(jié)是對所有節(jié)點的修復分析方法進行闡述。該種Piggybacking編碼的構造要求是需要同時滿足對信息節(jié)點和校驗的有效修復。用于修復信息節(jié)點和校驗節(jié)點的Piggyback塊都要嵌入校驗節(jié)點中。因此, Piggybacking編碼可分為兩大類:一類是將修復信息節(jié)點的Piggyback塊和修復校驗節(jié)點的Piggyback塊混合嵌入到校驗節(jié)點中;另一類是,將這2種Piggyback塊分開嵌入校驗節(jié)點中。當這2種校驗塊出現(xiàn)混合嵌入同一個校驗節(jié)點的同一列時,必須清楚當修復信息節(jié)點或校驗節(jié)點時,用于修復另一種節(jié)點的Piggyback塊是否會對正在修復節(jié)點的修復帶寬產(chǎn)生影響,這樣是否會引入額外的修復帶寬(相比于單一節(jié)點修復的Piggybacking編碼),以及Piggyback函數(shù)的設計復雜度增加的程度。當這2種校驗塊放置的子條帶沒有混合時,無形中又增加了Piggybacking編碼框架中的校驗塊的嵌入子條帶數(shù),這樣是否會影響該Piggybacking編碼設計的參數(shù)(子條帶數(shù))要求。把握好上述2種情況,才能設計出復雜度低、同時有效修復2種節(jié)點的Piggybacking編碼。
(2)多節(jié)點修復
目前所有關于Piggybacking編碼的研究,針對失效節(jié)點的修復都是單節(jié)點修復。但Piggybacking編碼的多節(jié)點修復可以類似RGC和LRC,且在實際的分布式存儲系統(tǒng)中有著重要的現(xiàn)實意義,這對深入研究Piggybacking編碼有一定的參考價值。
不同Piggybacking編碼的設計框架不同,即針對其修復節(jié)點的方法不盡相同。因此,不同Piggybacking編碼的多節(jié)點修復方法也不同。最重要的是,多節(jié)點的修復情況相比單節(jié)點更加復雜,包括3種情況:① 失效的全部都是信息節(jié)點;② 失效的全部都是校驗節(jié)點;③ 失效的一部分是信息節(jié)點,一部分是校驗節(jié)點。對于同一種Piggybacking編碼,其信息節(jié)點和校驗節(jié)點的修復帶寬不同,因此以上3種情況的修復帶寬都不相同,必須分情況討論。最終通過概率論與數(shù)理統(tǒng)計的方法求得平均多節(jié)點修復帶寬比率。另外,需注意的是,多節(jié)點修復的失效節(jié)點數(shù)以2起步,小于等于校驗節(jié)點數(shù)r(其基本碼MDS碼能容忍的最大失效節(jié)點數(shù)為n-k=r)。
多節(jié)點的修復過程中會出現(xiàn)一種權衡,失效節(jié)點中的失效符號(需要求解未知數(shù)的個數(shù))與Piggyback方程個數(shù)的關系。顯然,Piggyback方程越多,利用線性方程能求解的未知數(shù)(失效節(jié)點中的符號數(shù))就越多,則通過MDS譯碼求解剩余未知數(shù)減少,總的消耗帶寬就小(最差的情況就是所有失效節(jié)點全部用MDS譯碼,即大小等于原始數(shù)據(jù)大小)。所以希望通過MDS譯碼求解的符號數(shù)應盡量少。但又不能太少,否則Piggyback方程的個數(shù)少于剩余需要求解符號數(shù)的個數(shù)時,又無法求解。因此,必須針對不同的Piggybacking編碼,找到它的修復帶寬的權衡,才能求得其最小的多節(jié)點修復帶寬比率。
可以先對該Piggybacking編碼的2個失效節(jié)點進行分析總結,找出它的權衡,再將這種方法推廣到多個修復節(jié)點的推算中,難易程度循序漸進,且準確率更高。
2.3.3.3 應用
(1)存儲
Piggybacking編碼作為分布式存儲編碼中的新生力量,誕生于大數(shù)據(jù)、云計算時代。目前它的主要應用是存儲業(yè)務,并已經(jīng)應用到了Facebook Warehouse Cluster,HDFS等系統(tǒng)中。
(2)安全
Piggybacking編碼與同屬于分布式存儲編碼的RGC和LRC一樣,都具有維護信息理論安全的潛力。因此,可以使Piggybacking編碼既能成為一種執(zhí)行高效、復雜度低的節(jié)點修復,同時還能實現(xiàn)信息數(shù)據(jù)的安全性。
考慮一個理論上能應對在存儲節(jié)點的竊聽模型,并通過損壞節(jié)點的修復得到其他節(jié)點的數(shù)據(jù)。其中的竊聽者可能獲得存儲節(jié)點的數(shù)據(jù),也可能訪問在修復某些節(jié)點期間下載的數(shù)據(jù),通過設計安全可靠的Piggyback函數(shù),既能對失效節(jié)點進行有效修復,還能使竊聽者獲得的數(shù)據(jù)無法解密譯出,從而確保信息的保密能力。在不向任何竊聽者透露任何信息的情況下,可以安全存儲并向合法用戶提供最大的數(shù)據(jù)量。最后通過證明竊聽者和原始數(shù)據(jù)之間的互信息為0,即竊聽失敗,證明Piggybacking編碼的安全模型可行。可以對信息理論安全和Piggyback函數(shù)設計的復雜度進行權衡分析,提出理論安全和具有最低Piggyback函數(shù)設計的復雜度二者結合的Piggybacking編碼方案可抵抗竊聽。另外,除了在Piggyback函數(shù)的設計(編碼)上考慮,還可以結合信息安全方面的知識建立安全模型。
(3)邊緣計算
如果在分布式存儲系統(tǒng)中完全依賴云中心去修復失效節(jié)點,不僅會占用大量的網(wǎng)絡帶寬,還會導致整個系統(tǒng)的性能瓶頸變?yōu)榫W(wǎng)絡帶寬的瓶頸,因為云中心的處理速度要遠超網(wǎng)絡中數(shù)據(jù)的傳輸速度。若節(jié)點的修復計算能搬移到邊緣節(jié)點,且只向云中心提交處理后的結果,不僅能降低不必要的帶寬消耗,還能減少修復延遲,從而進一步提高系統(tǒng)性能。另外,就地處理數(shù)據(jù),可以大大降低數(shù)據(jù)在網(wǎng)絡傳輸中被竊取的風險,有效進行隱私保護,保障數(shù)據(jù)安全。
協(xié)同邊緣如圖9所示,它連接了多個在物理位置或網(wǎng)絡結構中分散的邊緣節(jié)點。邊緣節(jié)點作為一個將終端用戶和云中心連接具有數(shù)據(jù)處理能力的小型數(shù)據(jù)中心,也是邏輯概念的一部分[35]。實線箭頭代表云服務器中心給邊緣節(jié)點下發(fā)任務,虛線箭頭表示多個終端用戶將自己產(chǎn)生的數(shù)據(jù)交給具有計算能力的邊緣節(jié)點進行處理。在網(wǎng)絡邊緣處,節(jié)點不僅可以從云中心請求服務和內容,還可以在本地執(zhí)行計算卸載、數(shù)據(jù)存儲、緩存和處理以及物聯(lián)網(wǎng)管理等任務。基于這些能力,需要對邊緣節(jié)點進行良好設計,保證存儲系統(tǒng)中數(shù)據(jù)的可靠、安全和隱私[36]。綜上所述,這些分布式邊緣節(jié)點為終端用戶提供了合作和共享數(shù)據(jù)的機會。因此,邊緣計算具有極大潛力,可以通過與Piggybacking編碼結合來安全高效地解決分布式存儲系統(tǒng)中失效節(jié)點的修復難題。
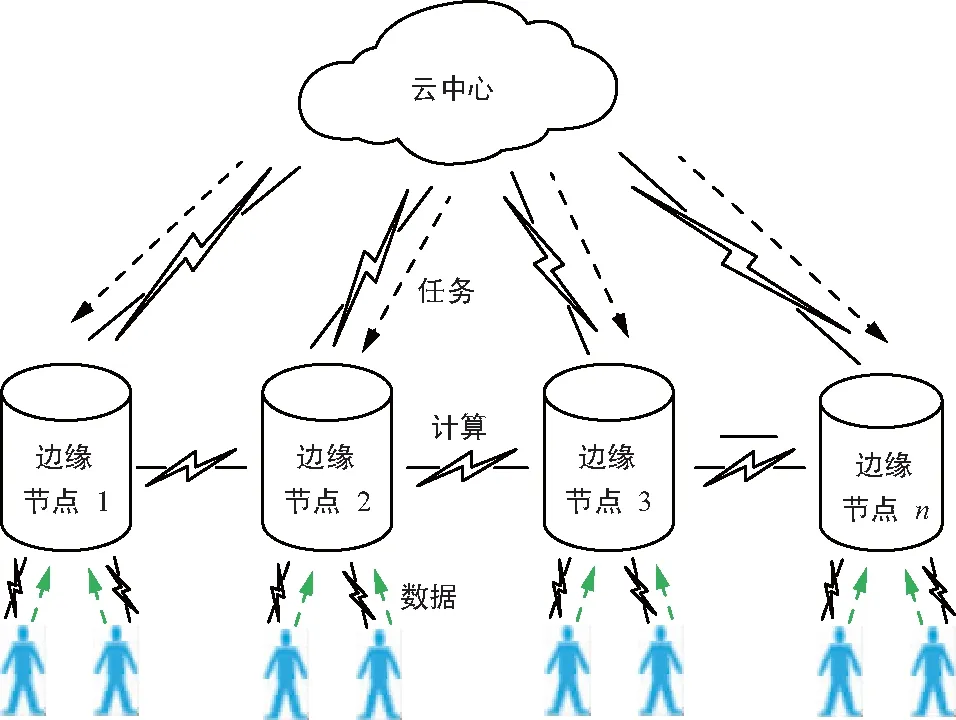
圖9 分布式存儲中協(xié)同邊緣計算范式的結構
2.4 性能比較
表1針對文中5種存儲容錯方式的性能進行了簡單粗略比較(注:從這幾種容錯存儲的基本原理來考慮,并沒有針對具體的容錯參數(shù)或碼參數(shù))。其中“★”的數(shù)量表示性能的相對大小程度,即4顆星表示最高,3顆星表示較高,2顆星表示較低,1顆星表示最低。例如多副本機制的修復帶寬開銷最低,用1顆星表示;其存儲開銷最大,用4顆星表示。
表1 幾種存儲容錯方式的性能比較

存儲容錯修復帶寬銷存儲開銷修復度計算復雜度容錯能力多副本機制★★★★★★★★★★★MDS碼★★★★★★★★★★★★★★RGC★★★★★★★★★★★★★★LRC★★★★★★★★★★★★★Piggybacking編碼★★★★★★★★★★★
3 結束語
本文簡單介紹了目前分布式存儲系統(tǒng)中常見的容錯技術,主要分為4部分:① 傳統(tǒng)的容錯技術即最早的多副本機制和MDS碼;② 基于網(wǎng)絡編碼的再生碼;③ 著眼于降低磁盤I/O的局部可修復碼;④ 不改變存儲結構的Piggybacking編碼。傳統(tǒng)的容錯技術與分布式存儲編碼的容錯相比,其基本性能劣勢比較明顯,慢慢會被取代。不同的分布式存儲編碼都有自己優(yōu)缺點,具體選擇哪種容錯方式要根據(jù)分布式存儲系統(tǒng)的需求來決定。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創(chuàng)業(yè)(2009年10期)2009-10-08 04:52:00
數(shù)字社區(qū)&智能家居(2009年7期)2009-09-29 08:16:48
數(shù)字社區(qū)&智能家居(2009年11期)2009-06-25 04:30:34
數(shù)字社區(qū)&智能家居(2009年3期)2009-04-21 03:09:04
數(shù)字社區(qū)&智能家居(2009年2期)2009-03-27 04:33:44
數(shù)字社區(qū)&智能家居(2009年12期)2009-02-03 07:50:48
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
