云存儲環境下的安全密文模糊檢索方案*
2019-08-27 03:45:50張昌宏
火力與指揮控制 2019年7期
關鍵詞:用戶
張昌宏,陳 元,付 偉
(海軍工程大學信息安全系,武漢430033)
0 引言
隨著用戶數據的日益增長,云存儲服務[1-2]得以發展并逐漸成為一項熱門的數據存儲技術。服務商通過整合網絡中的存儲資源,向用戶提供專門的數據存儲及訪問服務。然而在云存儲服務提供商(CSP,cloud storage provider)[3]信任受限的條件下,用戶隱私敏感數據的安全性保護成為目前的研究熱點之一。
密文檢索技術[4-13]可將用戶的隱私敏感數據加密后再上傳至CSP,并支持授權用戶的檢索請求,在保證數據機密性的前提下,保持了可檢索性。同時,由于檢索操作可以直接在密文上進行,而不用將CSP中所有的密文數據下載、解密之后再檢索,因此,可以極大地提高用戶和服務器的工作效率,并有效降低網絡消耗帶寬。
在傳統的明文檢索技術中,由于檢索用戶掌握的數據與真實數據之間存在著誤差,僅僅依靠精確匹配無法完成相應的檢索功能,因此,支持模糊匹配是十分必要的。然而,在密文檢索中,即使明文數據之間存在較小的誤差,加密后密文之間的誤差會變得很大,因此,密文模糊檢索功能具有很大的挑戰性[13]。
本文通過分析傳統的明文模糊檢索技術,結合密文檢索的特點及要求,提出了一種安全且高效的密文模糊檢索方案。方案以關鍵詞的頻率為權值并引入Huffman樹形結構及其編碼的思想構建密文關鍵詞索引結構,采用Bloom-Filter存儲關鍵詞的模糊集合,最后通過改進的TF-IDF規則對檢索出的密文文檔進行評分排序,以返回最符合用戶需求的Top-k結果。
1 相關研究
根據檢索匹配精度的不同,可以將密文檢索技術分為精確密文檢索[4-8]和模糊密文檢索[9-13]:
1)精確密文檢索技術。Song等人[4]最早提出基于對稱加密體制和偽隨機函數的可搜索加密方案,雖然證明了方案的安全性,但是由于性能與密文的長度成正比,效率較低;Boneh等人[5]提出基于雙線性對和Hash函數的非對稱加密檢索方案,實現了明文的機密性和密文的可檢索性;Hwang等人[6]提出基于連接關鍵詞的多用戶非對稱密文檢索方案,方案所需的存儲空間較大;Wang等人[7]提出連接關鍵詞字域可變的密文檢索方案;Cao等人[8]提出支持多關鍵詞排序的隱私保護檢索方案,但在排序算法中并未考慮到關鍵詞頻率。以上方案均只適用于關鍵詞的精確匹配,不適用于模糊檢索。
2)模糊密文檢索技術。相比于精確密文檢索,模糊密文檢索的難度要更高。Park等人[9]提出基于橢圓曲線和Hamming距離的密文模糊檢索方案,安全性較高,但是效率較低;Li等人[10]提出基于通配符和編輯距離的模糊匹配模式,效率較低;Liu等人[11]提出基于字典的模糊集構造檢索方案,將索引長度降到最低,且效率較高;Wang等人[12]在文獻[10]的基礎上構建了語義樹索引,提高了效率,但抵御統計分析攻擊能力不足。
Li等人[13]通過TF-IDF規則對關鍵詞進行評分,并以此為權值構建Huffman索引樹,基于通配符和編輯距離建立關鍵詞模糊集,在保證安全性的前提下,提高了密文模糊檢索的效率,但是方案不支持結果集的排序。
2 模型描述及設計目標
本節主要對系統模型、敵手模型進行描述,并對其提出相應的設計目標。
2.1 系統模型

圖1 密文模糊檢索模型
如圖1所示,密文模糊檢索模型主要由4個角色組成:數據擁有者(DO,Data Owner)、可信第三方(TTP,Trusted Third Party)、云存儲服務提供商(CSP,Cloud Storage Provider)和數據檢索者(DS,Data Searcher)。
1)DO:數據擁有者將隱私敏感數據及其關鍵詞發送給可信第三方,同時可以提出密文檢索請求;
2)TTP:可信第三方加密明文數據并根據DO提供的關鍵詞建立模糊檢索集及其索引,將加密后的索引及密文上傳至CSP;當DO和DS提供檢索請求時,TTP會根據用戶提供的關鍵詞生成檢索陷門并發送給CSP;
3)CSP:向用戶提供數據存儲、下載及檢索服務;
4)DS:數據檢索者經DO授權后可以提出密文檢索請求并獲取相應的數據信息。
2.2 敵手模型描述
本文將CSP視為“忠實但好奇”的半可信敵手模型。一方面,CSP能夠忠實履行與用戶之間的服務等級協定(SLA,Service Level Agreement)[14],向其提供穩定的數據上傳、下載及檢索等服務;另一方面,CSP出于好奇會對用戶的訪問行為和記錄進行分析,因此,用戶隱私敏感信息存在著一定的安全性威脅。
2.3 設計目標
模型的設計目標主要有以下3個方面:
1)安全。保證用戶隱私敏感數據的安全性,包括明文、關鍵詞索引及陷門和檢索過程的安全性;
2)高效。符合綠色計算的要求,既要減小存儲空間,又要保證密文檢索的效率;這里所說的存儲空間主要是指關鍵詞索引所占的存儲空間;
3)可靠。系統能夠給用戶提供可靠的數據存儲和密文檢索服務。
3 安全密文模糊檢索方案
通過分析傳統的明文模糊檢索技術,并結合密文檢索的特點及要求,本節提出了一種安全且高效的密文模糊檢索方案。為提高檢索效率,方案以關鍵詞的頻率為權值構建Huffman樹并將其作為密文關鍵詞索引;通過Bloom-Filter存儲關鍵詞的模糊集合,既能夠減少存儲空間又可以實現快速匹配;最后通過改進的TF-IDF規則對檢索出的密文文檔進行評分排序以返回最符合用戶需求的Top-K結果。
3.1 預備知識
3.1.1 Huffman樹及其編碼
Huffman樹又被稱為最優二叉樹,是一種帶權路徑長度最小的樹形結構。由于權值越大的節點深度越小,訪問路徑也越短,因此,將其應用于索引結構構建方案中會極大地提高檢索效率。以權值分別為1、2、3、4、5的節點為例,Huffman樹的構造過程如下:
1)將這5個權值節點作為5棵只有根節點的二叉樹,左右子樹均為空;
2)選取權值最小的兩棵二叉樹即1、2節點,將其作為左右子樹構造成一棵新二叉樹,其權值為左右子樹節點的權值之和即3;
3)刪除已用的1、2節點,并將新構造的3節點作為一棵新的二叉樹;
4)重復2)和3),直至用完所有的權值節點,最終構造成Huffman樹。
對Huffman樹進行二進制編碼時通常用0表示左分支、1表示右分支,則圖2中1~5節點的編碼分別為010、011、00、10、11。
3.1.2 Bloom-Filter(布隆過濾器)


圖2 Huffman樹形結構
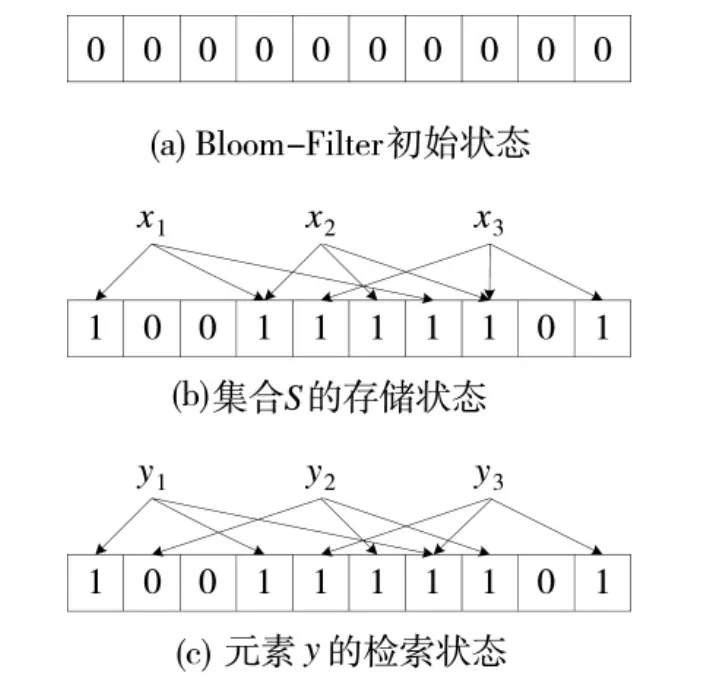
圖3 Bloom-Filter存儲及檢索示意圖
如圖3所示,根據判定原則,y1極有可能屬于集合S,但也存在誤判的情況;y2不屬于S;雖然y3對應的值全為1,但是位置不對,因此,也不屬于S,而是假陽性元素[13,15]。
3.1.3 TF-IDF規則
TF-IDF規則是一種基于權值的評分排序機制。在整個文檔集中,關鍵詞與指定文檔的關聯程度與該關鍵詞在指定文檔中的頻率成正比,與該關鍵詞檢索命令中的文檔數成反比。針對關鍵詞wi,文檔Fi的評分為:

其中,TF指關鍵詞wi在指定文檔Fi中的詞頻;指文檔Fi在整個文檔集中的頻率,N表示文檔總數,DF表示關鍵詞wi命中的文檔數。
3.2 基于Huffman樹和Bloom-Filter的安全密文模糊檢索方案
方案主要分為關鍵詞模糊集生成、Huffman樹形索引結構構建、陷門生成及檢索和密文文檔排序4個部分。
3.2.1 關鍵詞模糊集生成
對字符串的操作通常有字符刪除、插入和替換3種,本文采用基于通配符和編輯距離的關鍵詞模糊集生成方法。其中,通配符“*”表示對關鍵詞任一位置上的操作,編輯距離D(w,w')表示由關鍵詞w生成模糊關鍵詞w'的最小字符操作次數,Sw,D表示對關鍵詞w至多操作D次得到的關鍵詞模糊集合。
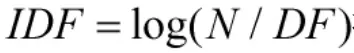

3.2.2 Huffman樹形索引結構構建
方案以關鍵詞頻率為權值構建Huffman樹形索引結構,并通過高效的Bloom-Filter實現模糊集的存儲和檢索。

2)TTP將這n個帶權節點構造成一棵Huffman樹;
3)如圖4所示,根據關鍵詞模糊集編輯距離的不同,將Sw,D分為相應的集合,如當D=3時,Sw,3分別為Sw_1、Sw_2、Sw_3。分別對集合進行加密,然后映射到布隆過濾器BFw_1、BFw_2、BFw_3中,并將過濾器作為索引樹的葉子節點。

圖4 索引樹的葉子節點
4)如圖5所示,TTP構建Huffman樹形索引結構,并將其和加密后的密文文檔上傳至CSP。其中,1-3節點存儲加密后的關鍵詞,Bloom-Filter存儲加密后的模糊關鍵詞,兩者均指向密文文檔。

圖5 Huffman樹形索引結構
3.2.3 陷門生成及檢索
3.2.4 密文文檔排序
為給用戶提供最符合需求的Top-k個結果,本文采用改進的TF-IDF規則給檢索出的密文文檔評分排序。文檔排序不僅需要考慮關鍵詞與指定文檔的關聯程度,更要考慮與模糊關鍵詞的編輯距離,而且后者所占的權重比較大。因此,改進后的TF-IDF規則為:

4 方案分析
本節主要就方案的安全性、復雜度以及Bloom-Filter的誤判率和假陽性進行分析,并通過實驗測試進行性能對比分析。
4.1 安全性分析
方案安全性主要考慮用戶隱私敏感信息、索引結構以及檢索過程的安全性。
4.1.1 用戶信息及索引安全在本文方案中,用戶隱私敏感信息和關鍵詞都是采用經典的密碼學對稱算法——AES算法來實現加解密,因此,在保證密鑰長度合適的前提下,方案是安全可靠的。關鍵詞模糊集在加密之后通過Bloom-Filter來存儲,而過濾器通過一組獨立同分布的Hash函數進行映射,在理論上具有不可逆性,因此,攻擊者無法對其進行破譯。

4.1.2 檢索安全

4.2 復雜度分析

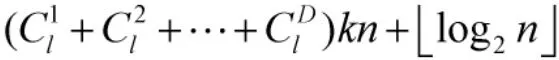
4.3 Bloom-Filter誤判率及假陽性分析
在Bloom-Filter的數據存儲及檢索中,存在著誤判和假陽性的情況。
4.3.1 Bloom-Filter誤判率分析
由于Hash函數不是一一映射,可能存在多對一的關系,因此,當Bloom-Filter的某一位設置為1后,其值不再改變,再次判定時可能存在誤判的情況。只有設置較長的Bloom-Filter向量才能減少這種碰撞,使誤判率較低,但是相應的存儲空間也會增大。
4.3.2 Bloom-Filter假陽性分析

4.4 實驗測試及性能分析
為對本文方案進行性能分析,選取1 000篇IEEE數據庫中計算機專業相關的英文論文作為測試文檔,大小約為700 MB。選取50個高頻且重復前綴較少的關鍵詞,平均長度為7.5,最大編輯距離設定為3。實驗平臺配置在一臺處理器為Intel(R)Core(TM)i5-2450M 2.50 GHz,RAM 4 GB的PC機上。本節主要在索引構建時間、索引規模、模糊檢索效率方面與文獻[13]方案進行性能對比分析。
4.4.1 索引構建時間

圖6 索引構建時間
如圖6所示,在本文方案和文獻[13]方案中,索引構建時間都隨著測試文檔數量的增加呈線性增加;由于本文方案以關鍵詞頻率為權值構建索引樹,而文獻[13]方案基于TFIDF規則對關鍵詞進行評分,并以此為權值構建索引樹,因此,與文獻[13]方案相比,本文方案的索引構建時間較少。
4.4.2索引規模
如下頁圖7所示,在本文的測試環境下,方案的索引規模為MB級,符合云存儲環境的要求。由于本文方案與文獻[13]方案都以關鍵詞信息構建Huffman索引樹,其索引規模相當。
4.4.3模糊檢索效率
由于本文方案與文獻[13]方案都是對索引樹進行遍歷查詢來實現模糊檢索,因此,基于關鍵詞信息的索引樹生成之后,測試文檔數量對模糊檢索效率的影響會比較小,而檢索請求數量對效率會產生線性的影響;由于方案對檢索請求的處理方式不同,文獻[13]方案中增加了DS的檢索關鍵詞加密和TTP的解密過程,因此,本文方案的模糊檢索效率提高了約10%。

圖7 索引規模

圖8 模糊檢索效率
5 結論
隨著軍事數據獲取方法的不斷發展,數據總量日益增長,這對涉密信息的安全性和檢索高效性提出了更高的要求[16]。本文通過分析傳統的明文模糊檢索技術,并結合密文檢索的特點及要求,提出了一種安全且高效的密文模糊檢索方案。方案以關鍵詞的頻率為權值構建Huffman樹形密文關鍵詞索引結構,并通過Bloom-Filter存儲關鍵詞的模糊集合,最后通過改進的TF-IDF規則對檢索出的密文文檔進行評分排序,以返回最符合用戶需求的Top-k結果。本文方案主要滿足單用戶的需求,對于多用戶需求的密文模糊檢索,將是下一步的主要研究重點。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
