基于Naive Bayes 的P2P 平臺評論研究
2019-08-20 07:25:48曾政多
現(xiàn)代計算機 2019年20期
曾政多
(佛山科學技術(shù)學院自動化學院,佛山528000)
0 引言
P2P 金融是近幾年來較為火熱的一個關(guān)鍵詞,P2P(Peer to Peer)網(wǎng)貸模式指的是個體和個體之間通過互聯(lián)網(wǎng)平臺來實現(xiàn)直接借款與貸款,它也是互聯(lián)網(wǎng)金融(ITFIN)行業(yè)的一個子分類。我國的P2P 平臺數(shù)量自2012 年開始,增長的較為迅速,迄今為止已經(jīng)有數(shù)千家平臺可供投資人選擇。由于投資回報率過高,參與其中的投資者與日俱增。為數(shù)眾多的P2P 平臺魚龍混雜,企業(yè)數(shù)量增速過快,而政府的監(jiān)管卻沒有跟上發(fā)展的速度,從中出現(xiàn)了大量的問題,自2018 年6 月各大平臺相繼“暴雷”之后,于2018 年8 月開始,國家對互聯(lián)網(wǎng)金融進行了整治。
即便是具有高風險,在可觀的收益率下,還是有著數(shù)量龐大的投資者群體會選擇P2P 平臺進行投資,伴隨著各類平臺網(wǎng)站用戶的持續(xù)增長,人們已經(jīng)從過去的口頭相傳或者是通過平臺的宣傳廣告等簡單信息獲取方式轉(zhuǎn)變?yōu)橄蚧ヂ?lián)網(wǎng)傳輸自己的觀點看法,從而每天可以產(chǎn)生很多對于各種平臺的評論。這些呈指數(shù)增長的評論發(fā)生在各種相關(guān)平臺如微博、貼吧、股吧論壇等各大地方,數(shù)量龐大,難以梳理。但是對于其文本是很有研究價值的。通過分析用戶對不同平臺不同特征的情感傾向,從而指導用戶的投資行為,是很有意義的一項研究。
1 數(shù)據(jù)獲取和預處理
1.1 數(shù)據(jù)獲取
本文所述研究所選用的數(shù)據(jù)集是DataFoutain 中的“互聯(lián)網(wǎng)金融平臺用戶評價提取”賽題中的數(shù)據(jù)集,數(shù)據(jù)中包含平臺評論數(shù)據(jù)集、投資公告數(shù)據(jù)集、論壇數(shù)據(jù)集等,本研究使用了其中的評論數(shù)據(jù)集用于分析和訓練。
1.2 文本去重處理
文本數(shù)據(jù)在分析之前通常要進行一些預處理,特別是在諸如此類的競賽平臺數(shù)據(jù)集中,主辦方肯定會通過復制同類數(shù)據(jù)使得數(shù)據(jù)變得冗雜,那么在開始就需要對數(shù)據(jù)集使用去重處理,本文使用Python 語言中的xlrd 與xlwt 庫對表格數(shù)據(jù)進行處理。如圖1 所示,通過建立一個新的list 表,往里加入數(shù)據(jù),通過遍歷數(shù)據(jù)集與list 表中的進行比對,沒有重復則加入list 的方法來進行去重處理,實現(xiàn)了數(shù)據(jù)清洗的過程。
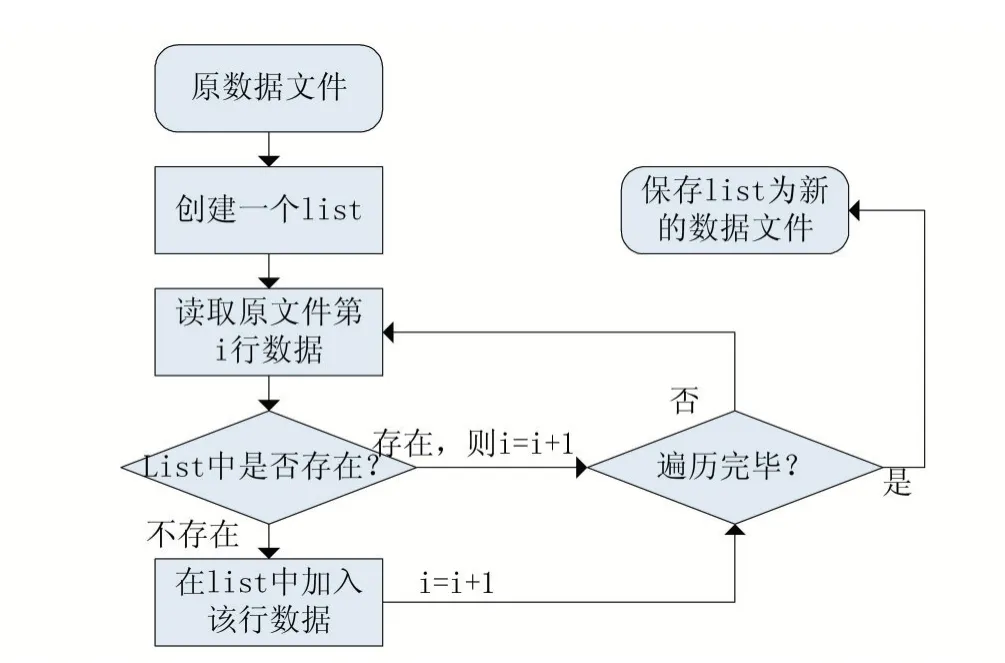
圖1 數(shù)據(jù)去重流程圖
1.3 文本的詞頻分析
TF-IDF 即“詞頻-逆文本頻率”,它由TF(Term Frequency)和IDF(Inverse Document Frequency)兩部分組成。
其中的TF 就是我們前面說到的詞頻(Term Frequency),文本向量化也就是做了文本中各個詞的出現(xiàn)頻率統(tǒng)計,并作為文本特征,后面的這個IDF,即“逆文本頻率”。在英文文本中,幾乎所有的文本里都會出現(xiàn)“to”和“and”,這類單詞的詞頻雖然高,但是重要性卻應該比詞頻低的“Naive”和“Investment”要低。IDF 的作用是用來反映這個詞的重要性,進而修正僅僅用詞頻表示的詞特征值。
概括來講,IDF 指的是某個詞在全部文本內(nèi)出現(xiàn)的頻率,如果某個詞在較多的文本內(nèi)都出現(xiàn)過,那么它的IDF 值是比較低的,例如上面說到的介詞“to”和連詞“and”。反而言之,某個詞語只在很少的文本中出現(xiàn)過,那么它的IDF 值應高。例如一些專業(yè)的名詞如“Deep Learning”。這樣的詞IDF 值應該高。一個極端的情況,在所有文本都出現(xiàn)的詞,IDF 值為零。
一個詞x 的IDF 的基本公式如下:
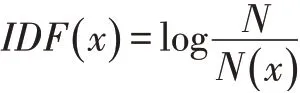
其中,N 代表語料庫中文本的總數(shù),而N(x)代表語料庫中包含詞x 的文本總數(shù)。
上述IDF 公式在大多數(shù)情況下適用,但是在一些特殊的情況則會出現(xiàn)一些小問題,例如遇到的某個詞語沒有出現(xiàn)在之前訓練好的語料庫中,這樣計算之后會使分母為0,IDF 會失去意義。因此通常我們在IDF計算時會做一些平滑處理,使某個詞語即使沒有在語料庫中出現(xiàn),在經(jīng)過計算之后也可以得到一個合適的IDF 值。平滑的方法有很多種,最常見的IDF 平滑后的公式之一為:
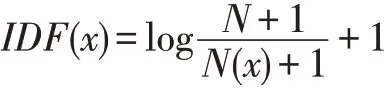
綜上所述,某一個詞的TF-IDF 值如下計算:
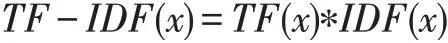
對于分詞,本研究用到的是Python 里的jieba 庫。jieba 分詞是一個完全開源,并且有集成的Python 庫,具有多種模式且使用起來較為簡單。jieba 在分詞的過程中可以添加自定義詞庫或者刪除“停用詞”(stopwords)。“停用詞”是指那些詞頻很高卻沒有情感特征的詞語,這些詞的TF-IDF 值可能非常高,需要主動刪除,以免引入噪聲。
詞云圖,也就是通常所說的文字云,是對文章中出現(xiàn)次數(shù)比較多的“關(guān)鍵詞”進行可視化,在詞云圖上,大量的低頻、低質(zhì)的文本信息會被過濾掉,使得瀏覽者只要看一眼詞云圖就可領(lǐng)會到文章主要想表達的意思。在Python 里現(xiàn)在有許多庫可以實現(xiàn)詞云圖,本文用到的Wordcloud 是詞頻分析的一個熱門庫,在代碼中可以自行設(shè)定背景和顯示的字體,顯示效果相比于其他的繪圖工具會更加直觀、具體。

圖2 詞云圖
從詞云中可以看出網(wǎng)友們比較關(guān)注的關(guān)鍵詞有“收益”、“平臺”、“提現(xiàn)”、“活動”等,表明網(wǎng)友在金融平臺的評論時,重點關(guān)注的點還是在收益和提現(xiàn)上,由此可見收益的高低、提現(xiàn)的便捷程度與速度、是否定期有舉辦活動是影響用戶情感的關(guān)鍵因素。
2 數(shù)據(jù)挖掘分析
2.1 情感分析研究現(xiàn)狀
文本的情感分析在二十世紀九十年代末由國外開始,早期的研究是基于文本數(shù)據(jù)來構(gòu)建一個語義詞典。在McKeown 在對連詞開展研究之后,研究者們開始考慮特征詞和情感詞之間的關(guān)聯(lián)。從Pang 等研究者開始,機器學習的研究方法開始被應用,以消極和積極兩個方向維度對文本評論進行分類,取得了不錯的效果。由此可見機器學習在文本情感分析的方面有著比較理想的研究前景。基于機器學習的情感分析方法需要人工標注文本,將標注到的文本作為訓練集訓練模型,再對目標進行情感極性判斷,本研究用到的評論研究方法是屬于機器學習中的有監(jiān)督學習方法。
2.2 應用到的情感分析算法
目前對于單條語句的情感分析應用到的方法是通過上下文語義信息進行分析,上下文的信息將會直接影響到對于單條語句情感值判定的準確性。當前大多數(shù)基于機器學習方法的情感分析工具都需要經(jīng)過訓練這一階段,對待不同的樣本應當采用不同的訓練集進行訓練以提高模型的適應性。
本文對于情感分類的基本模型是貝葉斯模型Bayes,對于有兩個類別C1和C2的分類問題來說,其特征為w1,????,wn,特征之間是相互獨立的,屬于類別C1的貝葉斯模型的基本過程為:
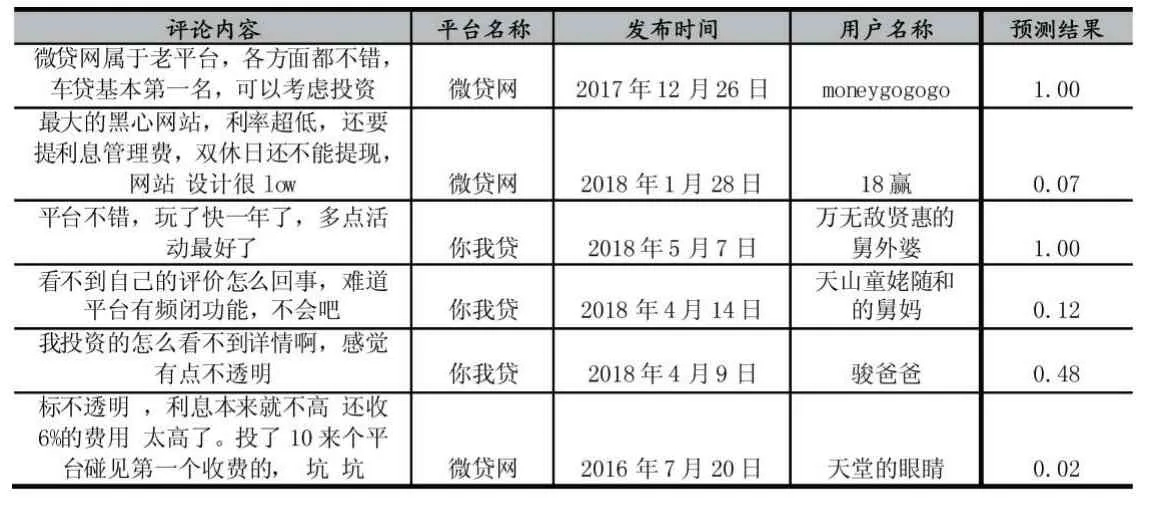
表1 預測結(jié)果表格
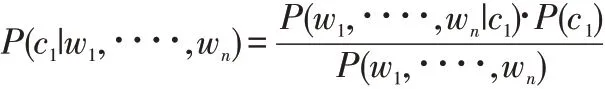
其中:
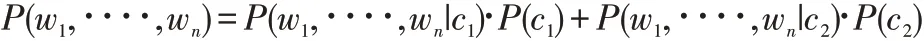
對上述公式進行簡化:

其中,分母1 可以改寫為:
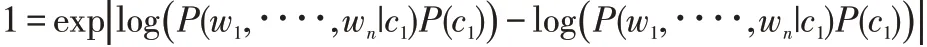
在Python 里的SnowNLP 庫的情感分析核心就是貝葉斯模型,自帶了電商評論的數(shù)據(jù)訓練集,因此在交易評論上效果較好,應用到金融平臺上也不需要做太大的修改。SnowNLP 庫是針對中文文本的自然語言處理工具,具有中文分詞、詞性標注、情感分析、文本分類、轉(zhuǎn)換拼音、提取摘要等等功能。
本研究在SnowNLP 自帶的正負預料樣本的基礎(chǔ)上,人工標注了部分評論并加入到訓練集中進行了再訓練,提高了預測結(jié)果的準確性。
3 實驗結(jié)果分析
通過調(diào)用Python 中的pandas 庫,讀取了評論數(shù)據(jù)集中的每段評論并且通過SnowNLP 逐句進行了情感值分析,生成了一個處于[0,1]區(qū)間的數(shù)值作為情感預測值,研究設(shè)定當?shù)玫降那楦兄荡笥?.5 時我們將評論定位為積極評論,情感值小于0.5 則認為是消極評論。
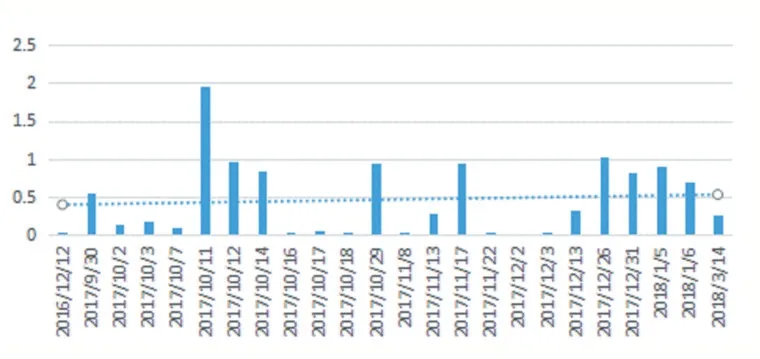
圖3“多融財富”的評論
由上述實證結(jié)果顯示,使用條件篩選于2018 年7月出現(xiàn)問題的“多融財富”平臺,發(fā)現(xiàn)其在2017 年10月就開始出現(xiàn)比較多的負面評論(低于0.5),數(shù)據(jù)集中存在的最后一條評論是2018 年3 月14 日的評論,在本研究模型上的預測結(jié)果也是比較消極的,因此可以得出該結(jié)果與本文模型比較契合,在其“暴雷”之前在評論上是有表現(xiàn)出將要出現(xiàn)問題的趨勢的。
使用條件篩選“微貸網(wǎng)”平臺的評論,出現(xiàn)的結(jié)果表明2018 年2 月8 日以前大多都是積極的正向結(jié)果。“微貸網(wǎng)”平臺目前還處于正常運轉(zhuǎn)的狀態(tài),通過本實驗數(shù)據(jù)集的預測結(jié)果也沒有出現(xiàn)過多的消極評論,表明該平臺的對于大部分用戶口碑較好,沒有出現(xiàn)太大的問題,短時間內(nèi)不會出現(xiàn)“暴雷”,是投資者可以作為選擇的網(wǎng)貸平臺之一。
4 結(jié)語
中文的自然語言處理技術(shù)是一項特別繁雜的工作,需要注意非常多的細節(jié),本文提出了使用Python 語言中的jieba 庫與WordCloud 庫結(jié)合進行詞頻分析的過程,并通過SnowNLP 庫分析情感極性,最后通過分析的結(jié)果來反饋到現(xiàn)實生活中的現(xiàn)象,評判一個平臺的好與壞,且通過實證以及模型檢驗得出的對投資者的建議以及未來的一些發(fā)展趨勢,為金融領(lǐng)域與自然語言處理學科的融合給出了初步的實驗基礎(chǔ)。
目前本研究的實驗還僅僅處于初步階段,只對評論數(shù)據(jù)進行了簡單處理與分析,在今后的工作當中還可以使用不同的機器學習庫進行處理,探尋如何讓機器對人類情感深入細致的把握和分析才是自然語言處理工作應當做的事情。以獲得更好的預測效果,同時受限于樣本數(shù)量沒有對單獨平臺進行評論分析,在今后評論數(shù)據(jù)充足的情況下可以針對單一平臺進行分析同時繪制情感極性變化曲線來預測平臺今后的發(fā)展情況。
對于數(shù)據(jù)集中的其他材料如新聞、股市公告等在本研究中并沒有應用到,情感分析是一個相對復雜的研究,統(tǒng)計和展示大量數(shù)據(jù)中隱含的情感特征才是真正要探索的問題,多維度的結(jié)合分析也是今后需要研究的方向。
猜你喜歡
民用飛機設(shè)計與研究(2020年4期)2021-01-21 09:15:02
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:24
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
山東工業(yè)技術(shù)(2016年15期)2016-12-01 05:31:22
小學教學參考(2015年20期)2016-01-15 08:44:38
