基于信息披露文本的上市公司財務困境預測:以中文年報管理層討論與分析為樣本的研究
2019-08-19 11:51:12陳藝云
中國管理科學 2019年7期
陳藝云
(華南理工大學經濟與貿易學院,廣東 廣州 510006)
1 引言
近年來,隨著我國經濟步入新常態,增長速度放緩,不少公司企業經營業績下滑,債務償還能力下降,信用違約事件不斷增多,以信用債為例,根據Wind資訊的統計數據,2014年以前,中國債券市場未發生過實質性違約,而從2014年3月“11超日債”違約開始,當年有6只債券違約,2015年為23只,到2016年進一步增加到79只,涉及34家公司企業,違約總金額高達403億元,信用風險對我國金融市場和宏觀經濟提出了嚴峻挑戰,準確預測公司企業的財務困境對于強化信用風險管理,有效防范信用危機和債務危機具有重要的理論和現實意義。
一直以來,對于公司企業財務困境預測的研究都是以會計信息和市場信息為基礎的,如Altman基于財務數據的Z評分模型[1]、Merton基于市場數據的結構模型[2]、Shumway結合兩者提出的風險模型(Hazard Model)[3]等,這些方法在國內對上市公司財務困境預測的研究中都有普遍應用[4-8],不過這些研究存在著一個共同的缺陷,都是以定量數據為基礎,忽視了定性的文本信息,而標準普爾在2003年的報告中就曾指出,“定性信息中包含著區分信用風險的重要信息”[9]。
從公司信息披露的角度來看,定量數據直觀的反映了公司的經營和財務狀況,而描述性文本信息是相應的具體說明和分析,也是與潛在股東和債權人溝通的重要機會,是對定量數據的有效補充,由此可以吸引讀者的注意,促使投資者購買更多的股票或將更多資金放貸給企業,抑制出售公司股票和債權的沖動[10]。當公司財務狀況開始惡化時,管理層的這種激勵就會更為強烈,公司信息披露文本的措辭與風格就會隨著經營和財務狀況的變化而不同,這樣以來,這些文本內容就可能為判斷經理人與公司的違約傾向提供重要線索。Tennyson等通過對比23家破產企業和正常企業年報董事長致辭以及管理層討論與分析部分的文本內容發現其主題會隨著企業財務狀況的惡化而變化[10],而Cecchini等對78家破產企業和正常企業年報管理層討論與分析文本內容本體的分析得到了類似的結論[11]。
國內不少學者對我國上市公司年報管理層討論與分析(Management Discussion & Analysis, MD&A)有用性的研究表明MD&A能為預測公司未來經營業績提供增量信息[12-14],不過在研究方法上,大多采用人工閱讀分析或打分的方法,采用自動文本分析的研究不多,如蔣艷輝等采用余弦相似度檢驗了創業板上市公司MD&A文本是否隨時間和經營情況的變化進行更新和變換[15],蔣艷輝等在語句層面從可讀性、業績自利性歸因、匹配信息密度、自我指涉度、前瞻性深度來衡量MD&A言語的有效性[16],而在財務困境預測或信用風險評價領域還鮮見考慮MD&A或其他信息披露文本的研究。
近年來,在公司金融領域,有不少研究通過對公司信息披露文本內容的自動分析,以正面和負面的情感表達來衡量其傳遞的管理層語調,并從實證角度對管理層語調的信息價值進行了檢驗[17-21]。基于這些研究,本文試圖通過對中文年報MD&A的自動文本分析,以特定情感詞典為基礎來衡量管理層語調,檢驗管理層語調能否為財務困境預測提供增量信息,并提高預測的準確性。本文可能的研究貢獻主要有:一是從財務困境預測的角度拓展了對MD&A信息價值的研究;二是在衡量管理層語調時,充分考慮情感詞典、分詞方法、權重設置、語調計算方法等因素的影響,有助于拓展中文文本分析在公司金融領域的應用;三是研究結果表明管理層語調是對財務數據的重要補充,而且負面語調具有更高的信息價值。
2 研究設計
2.1 實證方法與思路
本文將采用Shumway[3]的離散時間風險模型(Discrete-time Hazard Model,DHM)來規避配對抽樣的研究設計導致的樣本量受限問題,同時考慮財務困境發生概率隨時間變化的情況,解決靜態模型估計的有偏性問題。公司i在t+1時刻陷入財務困境的離散概率滿足
(1)
其中Xi,t表示公司i在t時刻的協變量,αt表示時變的基準風險率,這樣就利用所有可觀測公司-年度樣本,消除靜態模型的選擇性偏誤問題。
在離散時間風險模型的基礎上,本文首先對公司年報文本的量化指標——管理層語調在預測上市公司財務困境中的作用進行單變量分析,然后以傳統會計信息和市場信息模型為基礎,加入管理層語調,比較加入前后模型的擬合效果,再對這些模型的預測結果以及由Merton違約距離模型得到的預期違約概率的信息含量進行檢驗,以確定管理層語調的信息增量價值,最后采用滾動窗口方法對管理層語調的預測能力進行檢驗。
2.2 主要變量
2.2.1 會計信息與市場信息變量的選擇
以往公司財務困境預測的相關研究中選擇的財務變量與市場變量非常多,而本文側重檢驗管理層語調在財務困境預測中的作用,為此根據Altman[1]、Shumway[3]、Campbell等[22](簡稱CHS模型)的研究選擇了四個模型:一是Altman財務比率模型,包括營運資本/總資產(WCTA)、留存收益/總資產(RETA)、息稅前利潤/總資產(EBIT)、權益市值/債務面值(MTL)和銷售收入/總資產(STA)五個變量;二是市場變量模型,包括波動率(SIGMA,股票市場日收益率的年化標準差)、超額收益率(EXCESS,年收益率與滬深300指數收益率之差)、股票價格(PRICE,年末股票價格的對數值)、相對規模(RSIZE,公司年末股票市值與滬深股市市值總和比值的對數值)和市值賬面比(MB,股票年末市值/賬面價值);三是Shumway模型,包括凈利潤/總資產(NITA)、總負債/總資產(TLTA)、波動率(SIGMA)、超額收益率(EXCESS)和相對規模(RSIZE);四是CHS模型,包括凈利潤/經市值調整的總資產(NIMTA)、總負債/經市值調整的總資產(TLMTA)、現金/經市值調整的總資產(CASHMTA)、波動率(SIGMA)、超額收益率(EXCESS)、股票價格(PRICE)、相對規模(RSIZE)和市值賬面比(MB),其中經市值調整的總資產等于股權市值與負債賬面價值之和。以上述四個模型為基礎,加入文本信息量化得到的管理層語調進行重新估計,對比前后模型的擬合情況,由此來檢驗管理層語調能否提供增量信息。
2.2.2 基于Merton違約距離模型的預期違約概率
以Merton(1974)為代表的結構模型以未定權益分析為基礎,通過計算違約距離來估計公司的預期違約概率[2],理論基礎更好,但需要對公司價值及其波動性進行估計。Bharath和Shumway指出基于Merton違約距離的預期違約概率模型的價值在于其函數形式和輸入變量,并非對公司價值及波動性的估計[23],因此本文采用他們的方法來計算預期違約概率:資產價值等于股權市值E與債務面值K之和,σV根據上一年股票收益率的波動率σE來計算:
(2)
根據違約距離模型,公司的預期違約概率為
(3)
其中σE根據觀測的日收益率計算并進行年化處理;債務面值K,設定為短期債務加長期債務的一半來確定;股權市場價值E以股票市價與普通股股數之積來直接計算;T設置為1年。在計算預期違約概率時,對r分別選取上一年度公司股票的超額收益率和無風險利率來計算,得到兩個預期違約概率pBS和pBSr。
2.4 文本分析方法與管理層語調的衡量
在分析金融文本的情感或語調時,一般有兩種方法:一種是基于詞典或詞表的方法,即詞袋方法,根據特定詞典或詞表對正面、負面、不確定等各類特征詞的劃分來對文本進行分類,對于特征詞詞典,可直接引入其他領域的成熟詞典,如哈佛GI詞典[24-25]、 Diction詞典[18]、知網Hownet詞典[26],這些詞典的詞語分類很成熟,但對金融領域詞語的特殊性往往考慮不足,如稅收、成本、資本、折舊等常見的負面情緒詞語在會計領域并沒有負面的含義,原油、癌癥、礦井等負面詞語僅代表著特定行業[17],因而一些學者以特定財經文本為基礎構建了專門用于財經文本情感或語調分析的詞表,如Henry[27]、Loughran和McDonald等[17],并得到了廣泛的應用,謝德仁和林樂在對國內上市公司年度業績說明會文本內容的分析中采用的就是他們所構建的詞表[21],在中文方面,You Jiaxing等以中文財經新聞報道內容為基礎構建了用以分析財經新聞媒體報道傾向的詞表[28];另一種是機器學習方法,以樸素貝葉斯、支持向量機等特定算法對預先選取的訓練集數據進行訓練,確定文本情緒分類的規則,再應用于全部文本[29-31]。機器學習方法需要預先選擇訓練樣本,而計算機在訓練中采用的樸素貝葉斯規則或過濾原則非常多,因而其結果很難應用于對其他類似文本的分析,而詞袋方法在選定詞典或詞表后,就可以避免研究者自身的主觀性[32]。因此,本文參照謝德仁和林樂的研究,采用詞袋方法來衡量管理層語調,在詞典或詞表的選取方面,由于分析對象為年報文本,故以LM詞表為基礎,并選取兩個詞表作為穩健性檢驗的詞表:一是You Jiaxing等[28]基于中文財經新聞文本的詞表(簡稱YZZ詞表);二是國內中文文本情感分析時經常采用的方法,以知網Hownet、臺大NTUSD情感詞典和學生褒貶義詞典的情感詞語為基礎,經過去重后所構建的情感詞典(簡稱綜合情感詞典)。
在以詞典或詞表為基礎計算文本的情感或語調值時,還需要設定情感詞的權重,最常用的方法就是簡單比例加權方法,假定各個情感詞的權重相同,而Loughran和McDonald指出情感詞權重的設定還需要考慮情感詞在全部文檔中的重要性[17]。本文以簡單比例加權方法來計算管理層語調,并以TFIDF(Term Frequency-Inverse Document Frequency,詞頻-逆向文檔頻率)進行穩健性檢驗。
在分詞方面,由于現有中文文本分詞技術較多,謝德仁和林樂采用了結巴中文分詞工具[21],本文為確保結果的穩健性,以R語言為基礎,在采用結巴中文分詞工具(JiebaR)的同時,以基于中科院ICTCLAS中文分詞算法的Rwordseg中文分詞工具進行穩健性檢驗。在完成中文自動分詞后,進行詞頻統計,利用R語言的文本挖掘工具TM創建文檔詞語矩陣,然后再利用LM詞表、YZZ詞表以及綜合情感詞典來統計正面和負面的情感詞語詞頻POS和NEG(分別表示該類詞語數量占全部詞語總數的比例)。由于財務困境是公司風險的體現,因而本文以負面詞語詞頻NEG來衡量管理層的負面語調,同時由POS和NEG來構建管理層的凈語調TONE:
(4)
由此共構建了18個管理層語調的衡量指標:JLMNEG、JLMTONE、JYNEG、JYTONE、JNEG、JTONE、RLMNEG、RLMTONE、RYNEG、RYTONE、RNEG、RTONE、JLMNEGTD、JNEGTD、JYNEGTD、JYTONETD、JLMTONETD、JTONETD,其中J和R分別代表結巴分詞和Rwordseg分詞工具,NEG和TONE分別表示負面語調和凈語調,TD表示按TFIDF權重計算,LM和Y表示分別按LM和YZZ詞表計算。
3 樣本和數據
3.1 樣本
參照國內研究的一般做法,本文將因財務狀況異常而被特別處理(ST)作為上市公司陷入財務困境的標志。由于我國上市公司年度報告是在該會計年度結束之日起4個月內編制完成,因而上市公司t-1年年報公布與其在t年是否被特別處理這兩個時間是同時發生的,為此本文參照石曉軍等的做法[33],利用上市公司t- 2年的數據建立模型來預測其是否會在t年陷入財務困境。同時,部分市場信息變量以及預期違約概率模型的計算都需要上市公司股權的市場價值,為避免對非流通股價值的估計問題,本文選取了2006年以來,股改基本完成后的股票交易數據來衡量股權市值。結合這兩個條件,本文的樣本包括了2008年~2016年被特別處理的上市公司,對應的數據區間為2006年~2014年,并剔除了金融類上市公司、創業板上市公司以及跨市場在B股、H股上市的公司,在選擇特別處理樣本時,不考慮2008年以前已被特別處理的公司,以及被特別處理后的進一步降級或撤銷特別處理的問題,此外還剔除了一年交易日不足70天的公司,最后樣本中包括2024家上市公司,其中184家上市公司被特別處理,共11071個公司-年度觀測樣本。
3.2 分詞結果
在采用JiebaR和Rwordseg兩種中文分詞工具對公司年報管理層討論與分析分詞后,對LM詞表、YZZ詞表和綜合情感詞典中出現頻率最高的詞語進行了比較,結果顯示,不同分詞工具在采用同一詞表的差異很小,不過由于綜合情感詞典根據多個中文情感詞典綜合得到,是在其他領域應用比較成熟的中文情感詞詞典,但對金融領域的特殊性考慮不足,一些詞語,如“負債”、“集團”、“機械”、“競爭”、“利潤”等為會計或描述公司狀況時的常用詞語,并不能區分正面與負面的情感語調;YZZ詞表以新聞報道文本為基礎,一些詞語在年報文本中同樣不能區分正面與負面的情感語調,如“收入”、“負債”、“污染”等;而基于公司年報文本內容的LM詞表盡管是由Loughran和McDonald的研究根據中文年報內容翻譯得到,但相對綜合情感詞典和YZZ詞表而言可以更好的區分正面和負面的情感語調。
3.3 數據
本文利用非參數Wilcoxon Mann-Whitney檢驗對全部變量是否在財務困境和正常公司兩組樣本之間存在顯著性差異進行了檢驗,結果表明除市值賬面比(MB)以外,其他財務和市場變量以及由不同方法得到的管理層語調變量都存在顯著性差異,可以區分財務困境和正常公司。為避免極端值對實證分析的影響,參照一般做法,對財務變量、市場變量、管理層語調變量按1%的水平進行縮尾處理,對于預期違約概率pBS和pBSr則參照Hillegeist等的研究[34],將其取值限制在0.00001~0.99999之間,在進行信息含量檢驗時,將預期違約概率轉換為邏輯分值:
BS-score=ln[pBS/(1-pBS)]
(5)
BSR-score=ln[pBSr/(1-pBSr)]
(6)
其取值范圍為-11.51292~+11.51292。
4 實證結果與分析
4.1 基于離散時間風險模型的估計
4.1.1 基于單變量模型的比較分析
本文首先對語調變量是否具有預測上市公司財務困境的能力進行單變量檢驗,結果如表1所示。從離散時間風險模型的AUC(Area Under Curve,受試者工作特征曲線ROC下面積)、AIC(Akaike Information Criterion,最小信息準則)和Pseudo-R2來看,語調變量都具有一定的財務困境預測能力,JiebaR和Rwordseg兩種分詞工具的差別很小;在負面語調變量中,LM詞表效果最好,在凈語調變量中,YZZ詞表效果最好,而綜合情感詞典效果在兩種語調變量中都是最差的;在情感詞權重設置方面,以TFIDF來設置情感詞權重得到的結果比簡單比例加權方法要明顯更差。
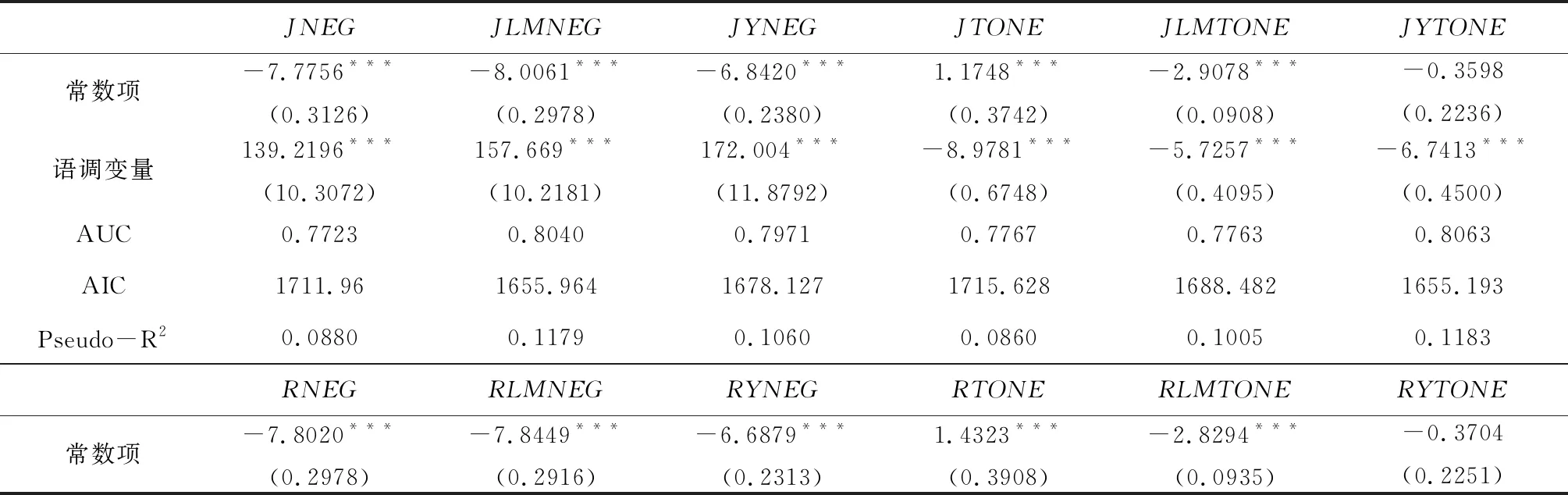
表1 語調變量對財務困境的預測能力:基于單變量的比較分析
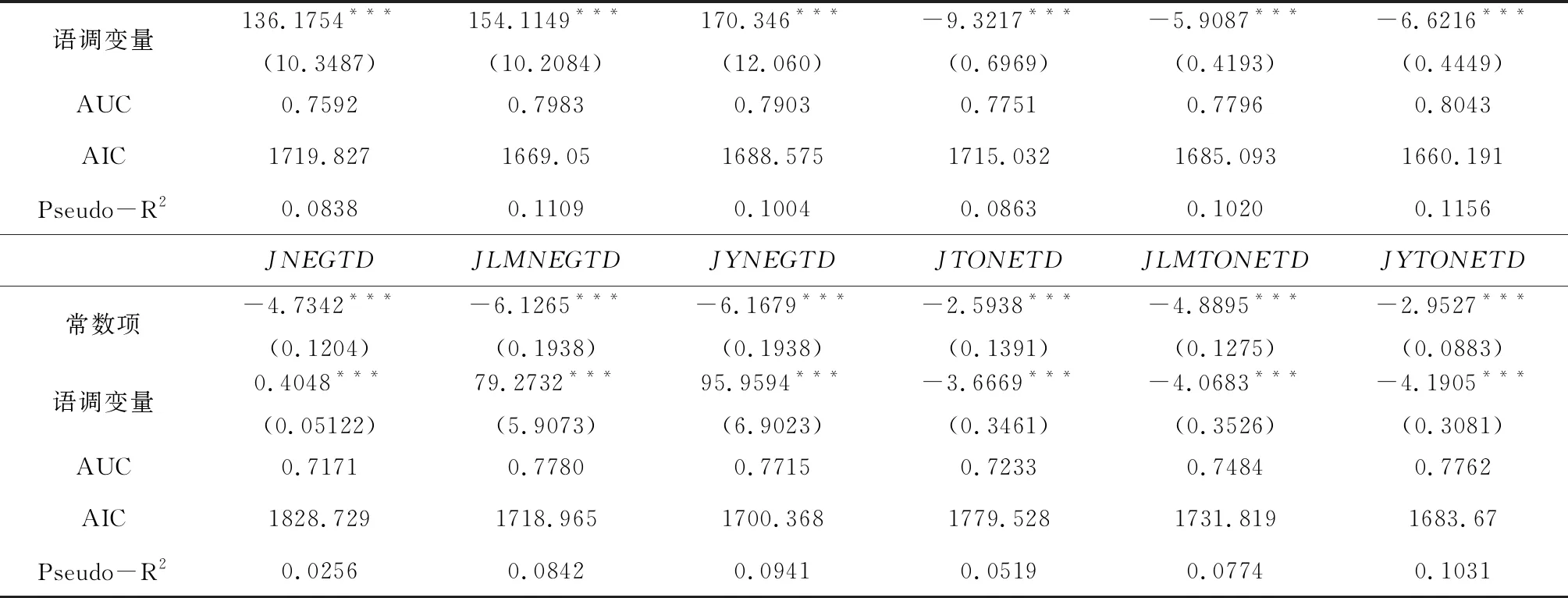
續表1 語調變量對財務困境的預測能力:基于單變量的比較分析
注:***、**、*分別表示1%、5%和10%水平下顯著;括號內為標準誤。
4.1.2 基于傳統模型的比較分析
以傳統會計信息模型(Altman財務比率模型)、市場變量模型、混合模型(Shumway模型和CHS模型)為基礎,對負面語調和凈語調變量加入前后模型的擬合情況進行比較,結果如表2:
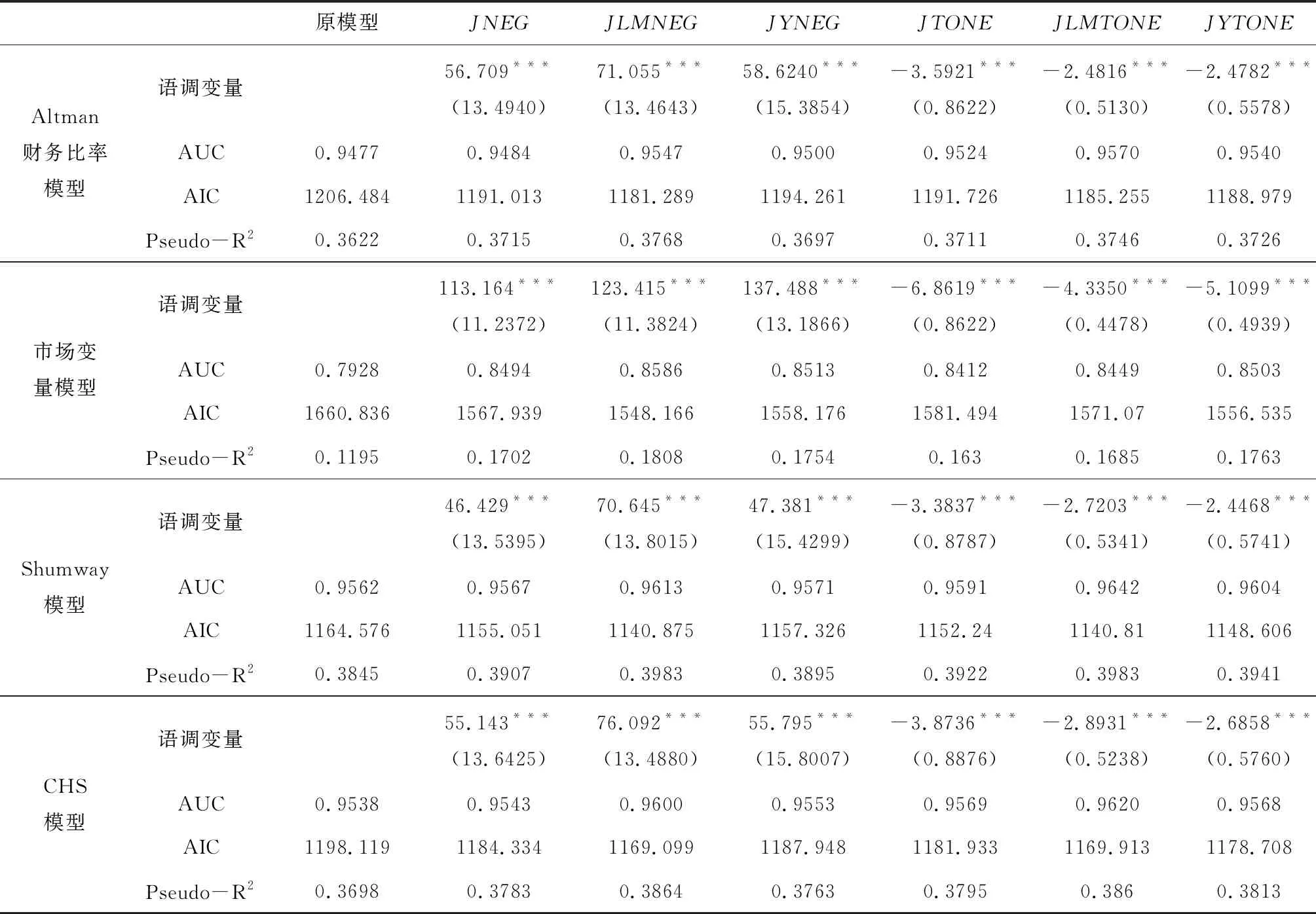
表2 基于JiebaR分詞工具的離散時間風險模型的估計結果
注:***、**、*分別表示1%、5%和10%水平下顯著,括號內為標準誤;本文側重分析管理層語調對財務困境預測的影響,故未給出對應財務變量和市場變量的估計結果,如有需要可向作者索取,這些變量的估計結果都符合理論預期。
首先,負面語調和凈語調變量在所有模型中都顯著,其中負面語調變量的系數顯著為正,表明文本內容傳遞的管理層語調越負面,上市公司陷入財務困境的可能性就越大,而凈語調變量的系數則顯著為負,表明管理層的凈語調越正面,上市公司陷入財務困境的可能性就越小;
其次,從模型的擬合情況來看,加入語調變量后,所有模型的AUC、AIC和Pseudo-R2都有一定的提高,其中市場變量模型最為顯著,Altman模型、Shumway模型和CHS模型擬合情況的改善相對要小一些,而這三個模型中都包含了財務變量,從這個角度來看,語調變量更多的是對會計信息的補充;
再次,在語調變量中,以LM詞表衡量語調時,模型的擬合程度最好,YZZ詞表次之,綜合情感詞典相對最差,這表明根據相關金融文本構建的詞表能更好的反映管理層語調,而且對于中文年報文本的分析還是應該以基于年報文本的情感詞表為基礎,LM詞表盡管是由英文根據中文年報內容翻譯得到,但效果依然要略優于YZZ詞表,而直接從其他領域引入的詞典,即綜合情感詞典在用于財經文本分析的效果要更差一些;最后,負面語調和凈語調的結果非常接近,差異很小。
4.1.3 穩健性檢驗
本文采用以下方法進行穩健性檢驗:一是以Rwordseg分詞工具重新計算管理層的負面語調和凈語調,以確保結果不受分詞工具的影響;二是在JiebaR分詞工具的基礎上,采用TFIDF來設定詞語的權重,重新計算負面語調和凈語調,以確保結果不受特征詞權重設置的影響。結果與表2保持一致,只是模型的擬合情況有細微的差別,管理層語調的加入在一定程度上可以提高財務困境預測模型的擬合度,而分詞工具、詞語權重設置都不會影響結果的穩健性,而且基于公司年報文本的LM詞表在衡量管理層語調時的效果相對更好,基于財經新聞文本的YZZ詞表次之,不過差異很小,而綜合情感詞典明顯更差。
4.2 基于信息含量檢驗的分析
為進一步確認管理層語調能否帶來一定的信息增量,本文基于離散時間風險模型對不同財務困境預測模型、預期違約概率以及管理層語調的信息含量進行了檢驗。首先,由Altman模型、市場變量模型、Shumway模型和CHS模型的估計結果對各觀測樣本出現財務困境的邏輯分值進行預測;然后,將這些邏輯分值以及由預期違約概率pBS和pBSr得到的邏輯分值BS-score和BSR-score分別加入負面和凈語調變量單變量估計得到的邏輯分值進行估計;最后結合不同模型的邏輯分值并加入語調變量單變量估計得到的邏輯分值,對其信息增量進行檢驗。在進行信息含量檢驗時,加入上一年度上市公司出現財務困境的比率RATE作為基準風險率,根據前面的分析只加入了兩個基于LM詞表的負面和凈語調變量得到的邏輯分值JLMNEG-score和JLMTONE-score。
4.2.1 信息量檢驗
四個模型的預測結果A-score、M-score、S-score、CHS-score以及由預期違約概率得到的BS-score和BSR-score六個邏輯分值信息量檢驗的結果如表3所示,其中對每個邏輯分值的檢驗包括不加入語調變量的邏輯分值、加入負面語調變量的邏輯分值JLMNEG-score、加入凈語調變量的邏輯分值JLMTONE-score三個模型。由表3可見:
首先,四個模型和預期違約概率得到的邏輯分值都顯著為正,都包含預測上市公司財務困境的重要信息,從Log-likelihood(對數似然比)和Pseudo-R2來看,Shumway模型和CHS模型效果最好,市場變量模型及預期違約概率的效果最差;
其次,在加入負面語調和凈語調的邏輯分值后,JLMNEG-score和JLMTONE-score的估計系數都顯著為正,而且Log-likelihood和Pseudo-R2也都有一定程度的提高,尤其是在市場變量模型和預期違約概率模型中,可見管理層語調為預測公司財務困境提供了新的信息;
最后,在語調變量的邏輯分值中,加入負面語調邏輯分值JLMNEG-score對Log-likelihood和Pseudo-R2的提高要高于加入凈語調邏輯分值JLMTONE-score的結果,從這個角度來看,負面語調所包含的信息量要高于凈語調。
4.2.2 信息增量檢驗
以Altman財務比率模型、基于市場信息的預期違約概率模型和會計信息與市場信息相結合的Shumway模型得到的A-score、BS-score和S-score為基礎來對管理層語調的信息增量進行檢驗,先兩兩結合,再加入負面語調和凈語調變量的邏輯分值JLMNEG-score和JLMTONE-score,最后再將三者結合,并加入負面語調和凈語調變量的邏輯分值來進行檢驗,結果如表4所示。
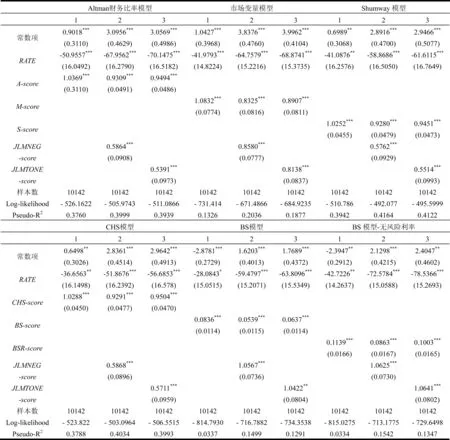
表3 信息量檢驗的估計結果
注:***、**、*分別表示1%、5%和10%水平下顯著;括號內為標準誤。
首先,在會計信息、市場信息以及兩者相結合的三類模型中,基于市場信息的預期違約概率模型的效果最差,估計系數都不顯著,且有多個系數為負;其次為Altman財務比率模型,而效果最好的為Shumway模型,從這個角度來看,在構建我國上市公司財務困境預測模型時,同時結合會計信息和市場信息的效果會更好。
其次,在加入負面語調和凈語調變量的邏輯分值后,JLMNEG-score和JLMTONE-score的估計系數都顯著為正,另一方面Log-likelihood和Pseudo-R2都有一定幅度的提高,可見管理層語調確實為預測公司財務困境提供了新的信息;而兩個語調變量的對比結果與信息量檢驗相同,加入JLMNEG-score對Log-likelihood和Pseudo-R2的提高要高于加入凈語調JLMTONE-score,即負面語調的信息增量同樣要高于凈語調。
4.3 基于預測能力的分析
對于財務困境模型的預測能力,一般是從樣本內和樣本外兩個角度來進行檢驗。本文采用Shumway(2001)的十分位數檢驗方法,將財務困境模型預測的違約概率按照十分位數分成十等分,計算各十分位數中財務困境公司占總的財務困境公司數的比例。

表4 信息增量檢驗的估計結果
注:***、**、*分別表示1%、5%和10%水平下顯著;括號內為標準誤。
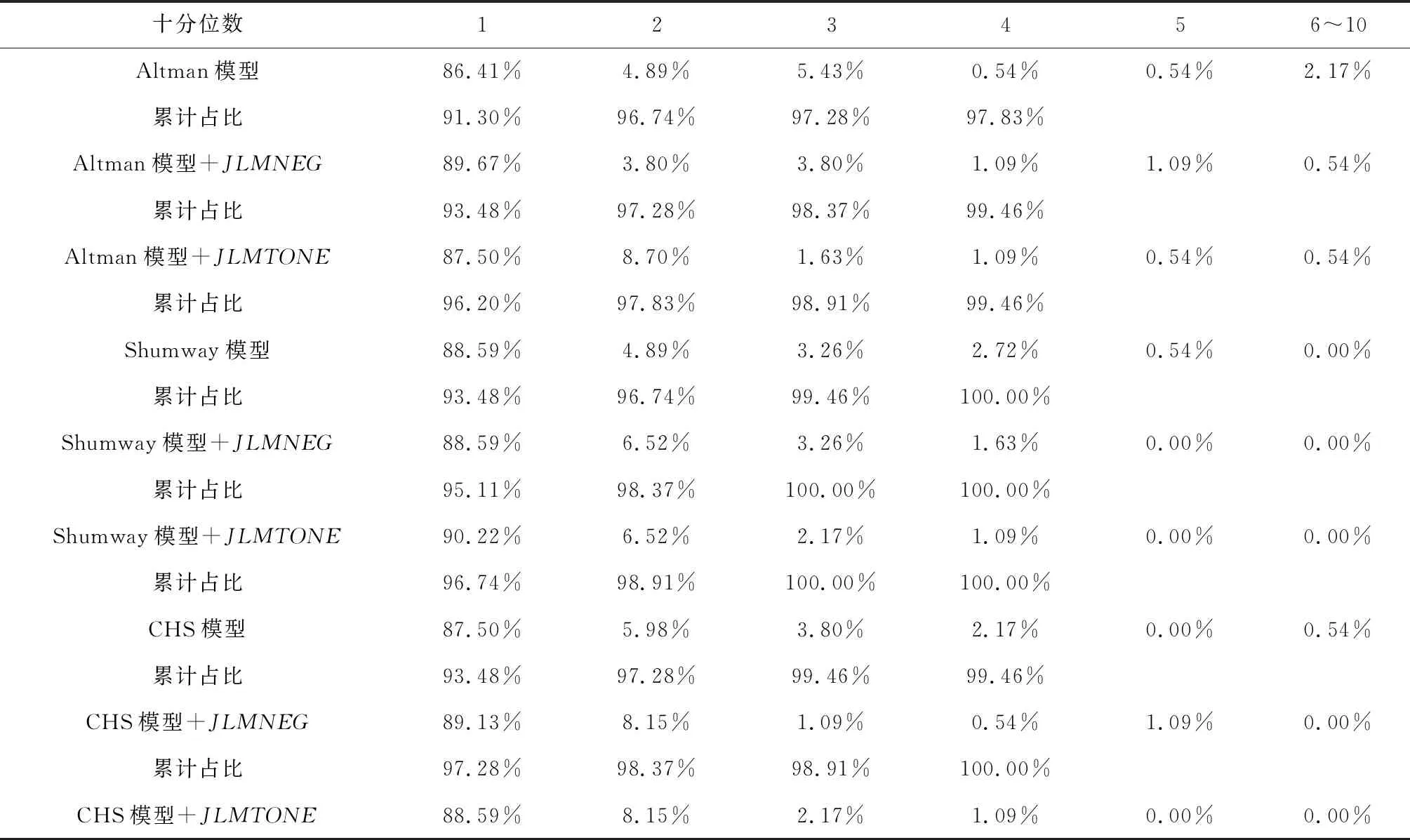
表5 樣本內預測的十分位數檢驗

續表5 樣本內預測的十分位數檢驗
4.3.1 樣本內預測
表5給出了四個模型以及加入JLMNEG和JLMTONE后預測的違約概率,作為比較,還給出了預期違約概率pBS和pBSr、以及JLMNEG和JLMTONE單變量模型預測的違約概率。
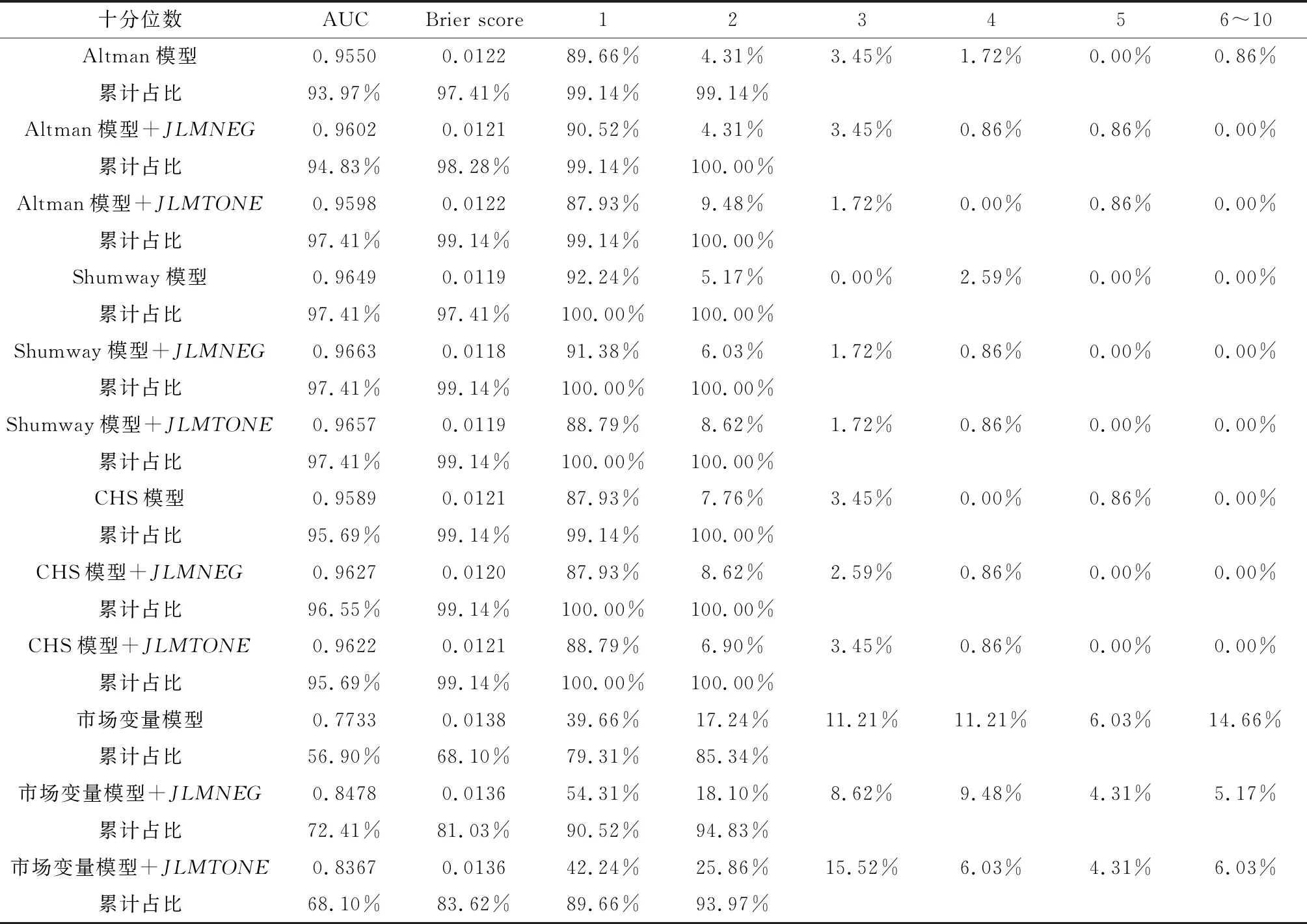
表6 樣本外預測的十分位數檢驗
首先,市場變量模型與預期違約概率的樣本內預測能力最差,結合了會計信息和市場信息的Shumway模型和CHS模型預測能力較好,這與之前模型估計以及信息量檢驗的結果一致;而在市場變量模型和預期違約概率模型中,后者的預測能力更差,表明在市場變量基礎上按照Merton違約距離模型計算得到的預期違約概率可能因為過于概括和簡化,反而遺漏了一些重要信息而導致更差的預測能力,這與國內近年的一些研究,如蔡玉蘭和崔毅的結論[35]是一致的;
其次,JLMNEG和JLMTONE單變量模型預測的違約概率對上市公司財務困境的預測能力比預期違約概率pBS和pBSr還要強,表明管理層語調確實具有一定的財務困境預測能力,而其中預測能力更好的JLMNEG單變量模型預測的違約概率甚至還要強于市場變量模型;
再次,在加入語調變量后,四個模型的預測能力都有一定的提高,其中市場變量模型預測能力的提高最為明顯,這與前面的分析一致;在四個模型中,除了Shumway模型外,其他三個模型在加入負面語調變量JLMNEG后,在第一個十分位數上預測能力的提高都明顯高于凈語調變量JLMTONE,由此可判斷負面語調在提高財務困境預測能力上要好于凈語調。
4.3.2 樣本外預測
對于樣本外預測,本文采用滾動窗口(Rolling Window)方法:首先以2008~2010年的樣本來估計模型,以此預測2011年的違約概率,然后再以2008~2011年的樣本重新估計模型,以此來預測2012年的違約概率,以此類推來對2011年~2016年116家上市公司被特別處理的情況進行預測,表6給出了樣本外預測十分位數檢驗的結果,并給出預測的AUC和Brier score(布萊爾分數)。
從預測準確的公司數量來看,語調變量的加入可以顯著提升市場變量模型的預測能力,但對其他三個模型的影響不太顯著,在第一個十分位數組上,JLMNEG提高了Altman模型的預測能力,對CHS模型沒有影響,而Shumway模型略有降低,JLMTONE提高了CHS模型的預測能力,而降低了Altman模型和Shumway模型的預測能力;進一步擴展到第二個十分位組后,可以發現不管是負面語調JLMNEG還是凈語調JLMTONE大多能提高,起碼不會降低模型的預測能力。
AUC和Brier score則可以清楚的反映語調變量在樣本外預測中的作用。首先,負面語調和凈語調兩個變量的加入可以大幅提高市場變量模型的AUC,而且Altman模型、Shumway模型和CHS模型也都有一定程度的提高,其中JLMNEG帶來AUC的提高更為明顯;其次,負面語調變量的加入降低了所有模型的Brier score,而凈語調變量的加入只對市場變量模型產生了一定的作用。由此可見,語調變量的加入確實在一定程度上提高了傳統模型對財務困境的預測能力,而其中負面語調帶來的信息增量價值會更大一些。
5 結語
管理層討論與分析是上市公司信息披露的重要組成部分,對于分析上市公司的真實狀況以及經理人對未來的預期有著非常重要的價值。本文在離散時間風險模型的基礎上分析了中文年報管理層討論與分析部分文本內容所反映的管理層語調對于上市公司財務困境預測的信息價值進行了分析,主要結論如下:
(1)管理層語調確實可以提高上市公司財務困境模型的預測能力。在傳統的會計信息模型、市場信息模型以及兩者相結合的混合模型中加入語調變量后,上市公司財務困境預測模型的擬合程度都有一定的提高,而且不會因分詞工具、情感特征詞詞典以及特征詞權重設置方法的選擇而出現變化。信息量與信息增量檢驗的結果進一步確認了語調變量確實為預測財務困境提供了新的信息,而樣本內和樣本外的十分位數檢驗表明語調變量對于財務困境確實具有一定的預測能力。
(2)在各類模型中,語調變量的加入對于市場變量模型的擬合程度與預測能力有顯著的提高,而對于會計信息模型以及包含了會計信息的混合模型擬合程度與預測能力的改善則相對有限,這表明信息披露報告文本內容傳遞的語調信息是對定量財務數據的重要補充,而且這些信息并沒有在市場價格中得到充分反映。
(3)在衡量管理層語調時,負面語調的價值要高于凈語調,特別是在信息量與信息增量檢驗以及預測的十分位數檢驗中效果更為明顯,這表明對于中文信息披露報告的分析應該更著重于對負面語調的解釋與分析。
(4)在衡量管理層語調時,以特定財經文本為基礎的LM詞表和YZZ詞表的效果要好于沒有考慮金融領域詞語特殊性的綜合情感詞典,這表明在財經文本的挖掘分析中并不適合直接從其他領域引入成熟詞典來進行分析;而基于年報文本的LM詞表盡管是從英文翻譯根據中文年報內容得到,但整體效果要略優于YZZ詞表,這表明在分析不同來源的財經文本時,最好還是以該來源的文本為基礎構建相應的情感詞詞表。
由此可見,在分析和預測公司企業財務困境時,可通過對其信息披露文本的挖掘和分析來獲取有價值的信息,文本分析對于更好的強化信用風險管理有著重要意義。與此同時,本文基于財務困境預測的研究也可以很好的彌補以往更多從市場反應、公司披露業績等角度來分析信息披露文本內容的信息價值的研究,有助于拓展對公司信息披露,特別是對其描述性文本內容的研究。
當然,本文的研究還存在一定的局限性:一是現有中文分詞技術在切分文本時還存在一定的不足,有可能會對研究結論產生一定的影響;二是在文本內容傳遞的語調衡量時,不管是直接引入國內其他領域的成熟詞典,還是由國外年報文本內容構建的特征詞詞表,也都存在一定的局限性,前者對金融領域詞語的特殊性考慮不足,而后者則會對國內公司信息披露的文本內容考慮不足,因而可能最佳的解決方法還是如You Jiaxing在分析新聞媒體報道傾向時以新聞報道文本為基礎去構建情感詞詞典一樣,以國內上市公司披露的大量文本內容為基礎來構建相應的特征詞詞典,以更好的分析上市公司信息披露的文本內容。
猜你喜歡
文苑(2020年12期)2020-04-13 00:54:08
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
環境保護與循環經濟(2017年8期)2017-03-22 01:28:58
環境科技(2016年3期)2016-11-08 12:14:20
小學教學參考(2015年20期)2016-01-15 08:44:38
中國工程咨詢(2015年10期)2015-02-14 05:57:24
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
