深度學習下大學生資助管理模式創新研究
2019-08-17 07:39:54勝獻利
重慶理工大學學報(自然科學) 2019年7期
勝獻利
(河南大學 濮陽工學院, 河南 濮陽 457000)
高校學生資助具有公益性、選擇性、幫扶性,因此選拔資助對象時需要保證公平、公正和公開。在現實工作實踐中,由于人的認知能力有限,高校學生資助工作運行得并非一帆風順,時常遇到各類型因素影響和阻礙學生資助工作,在學生家庭情況調研、貧困生等級認定和過程性評價時均存在一定問題[1]。由于學生家庭調研成本較高,因此尚無高校采用家庭訪談形式開展貧困學生實際情況調查工作,籠統地要求貧困生填寫家庭情況調查表,由生源地的鄉村街道辦事處或民政局加蓋公章。但以此種方式認定的貧困生真實情況得不到確認。即便有些學生通過抽樣調查方式,由于成本高、覆蓋面窄等情況也無法起到應有的效果。隨著家庭調研方式的改革,一些學校認定貧困生時開始綜合考慮日常因素,比如學生的一卡通消費、日常的穿著打扮、手機電腦品牌價格等,但是由于這些數據斷斷續續,所以收效甚微。部分學校別出心裁地采取一些方法,比如讓學生自己拍攝家庭生活視頻照片資料、提供死亡證明、低保證、殘疾證等,公開實施“比慘大賽”,既影響了學生的心理健康,又讓本是扶危救困的學生資助政策在大學生中產生不良影響。學生困難等級認定也較為困難,由于學生家庭數據采集不準確,生活水平不能準確判定,因此無法準確地認定學生困難等級,學生資助無法準確實施[2]。學生生活狀況評定完成之后就固定不變,影響資助政策的有效實施。學生資助過程性管理弱,許多學校采用年度審核制度,每年的評價方式都一成不變,因此學生資助評價固化滯后,無法反映多變的貧困生活狀況,影響學生受資助的情況。大學生學習和成長過程中,學生資助是一個剛性支出,需要給予足夠的關注,但是這些剛性支出已經成為學生評價的生活瓶頸,如果不使用動態的評估過程就無法適應學生資助模式[3]。
目前,隨著人工智能、深度學習、云計算、互聯網等技術的發展,公安、民政、銀行、高校等機構已經開發了自動化軟件,積累了大量的數據資源,覆蓋了每一個家庭,因此可以利用深度學習構建一個關聯分析模式,將多個部門的數據整合在一起,分析學生家庭經濟生活狀態,從而準確判定大學生資助情況,動態管理大學生資助過程。
1 深度學習
深度學習算法是一種先進的前饋型人工神經網絡,其包括兩個卷積層,分別是特征提取層和特征映射層[4]。特征提取層的輸入神經元與前一層局部連接,可以提取局部特征,確定特征與特征位置關系。特征映射層將特征映射到一個平面上,每一個平面上的神經元擁有相同的權值[5]。卷積神經網絡利用Sigmoid函數作為激活函數,使得特征及其映射具有位移不變性,從而大幅度減少設置的自有參數數量[6]。深度學習概念源于人工神經網絡,是一種包含多個隱藏層的深度學習結構,能夠通過組合底層特征形成更加抽象的高層類別或特征,以便發現數據的分布式特征表示[7]。深度指的是神經網絡學習得到的函數中非線性運算組合水平的數量,當前神經網絡多是較低水平的網絡結構,比如1個輸入層、1個隱藏層和1個輸出層。深度學習則是非線性運算組合水平較高的神經網絡,比如1個輸入層、3個隱藏層和1個輸出層[8]。深度學習可以表示高階抽象概念的復雜函數,解決目標識別、語音感知和語言理解等人工智能相關的任務。研發發現:可以使用多種方式描述深度學習的觀測值,比如特征向量、輪廓區域等,更容易從海量數據中進行實例學習,生成一個準確的網絡結構,提高機器學習的準確度[9-10]。
深度學習經過多年研究,已經得到了極大的改進,引入了形狀建模[11]、模糊數學、因子分析、信息論等技術,準確度和魯棒性均有提升。深度學習利用形狀建模技術,可以提高圖像識別、特征檢測的準確度,進一步提高圖像處理和識別的有效性。深度學習可以利用模糊數學和因子分析技術,強化卷積神經網絡求解空間的啟發式規則,提高深度學習的處理速度和效率。利用信息論等技術,深度學習可提高數據度量的有效性,進一步提高數據相似性度量準確度。目前,深度學習已經在很多領域取得了顯著的應用成效,比如置信神經網絡等,同時也廣泛應用于圖像識別[12]、語音識別[13]、基因識別、視覺導航等領域,并吸引了谷歌、百度、騰訊、微軟、阿里巴巴、英特爾等公司的關注,獲得了越來越多的研究成果[14]。
2 基于深度學習的大學生資助管理模式研究
大學生資助管理利用深度學習可以實現精準化、動態化、實時化、共享化和智能化管理模式,以適應高等教育改革的發展需要,促進各地區發展,滿足大學生成長成才的需求。深度學習在大學生資助管理模式中的應用架構如圖1所示。
大學生資助管理模式采集的數據來源于公安、民政、銀行和高校。利用先進的企業服務總線技術,可從多個源頭獲取數據信息,這些數據包括家庭生活數據、民政生活數據、高校生活數據、銀行存貸數據等。利用先進的深度學習技術,針對抓取的數據進行模式分析,實現學生家庭經濟標準評估、學生貸款使用跟蹤、學生信用追蹤評估,這樣就可以動態、靈活地增強大學生資助管理能力。基于深度學習的大學生資助管理模式業務處理流程如下:
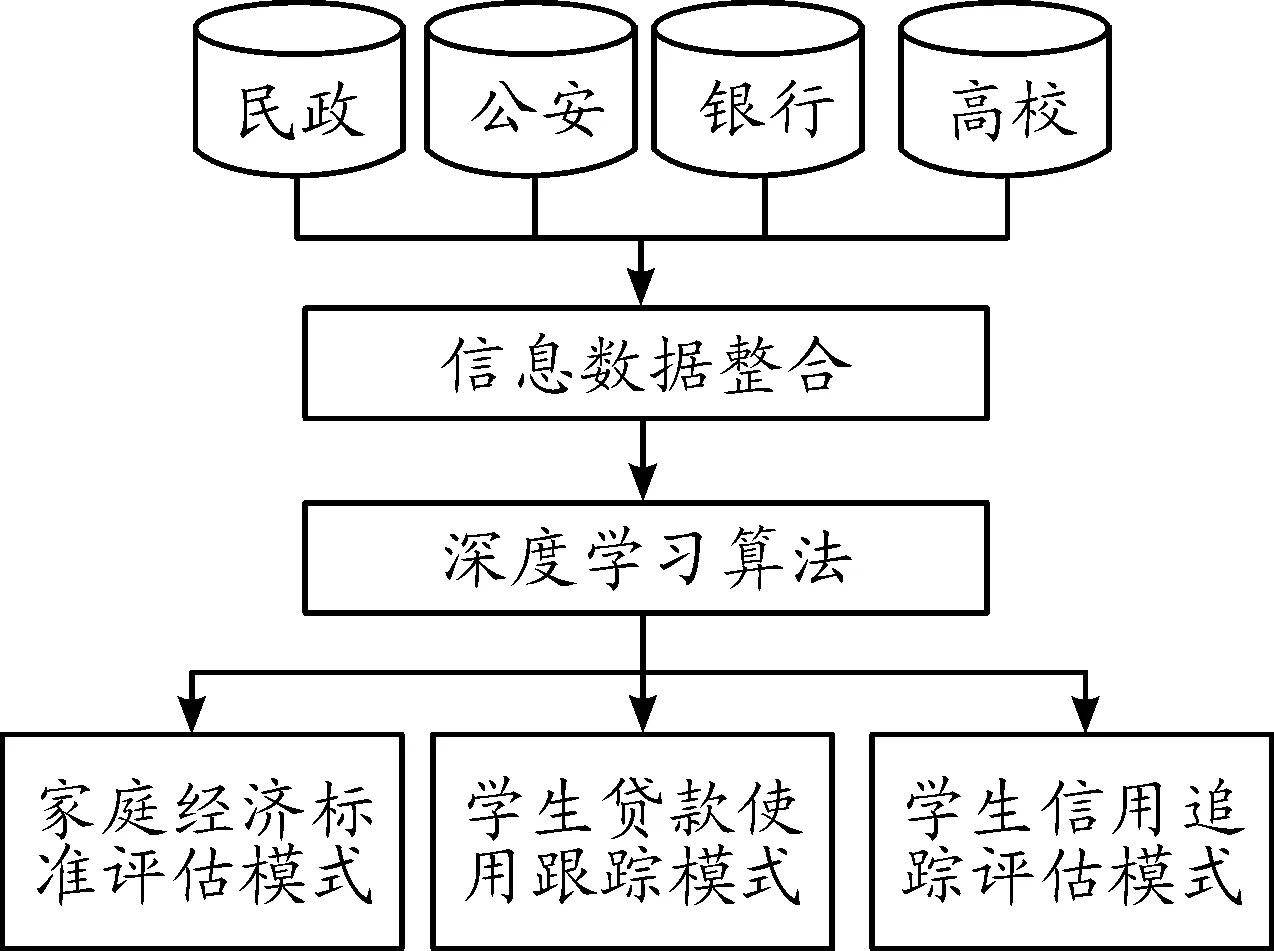
圖1 大學生資助管理模式
1) 數據采集。從公安、民政、銀行和高校等機構的分布式管理系統采集數據,這些數據覆蓋了學生家庭的經濟收入、工作職業、存貸信用、資助記錄、學習成績等。然后針對這些數據進行處理,實現數據的連接、融合,將其存儲到大學生資助管理數據庫中。
2) 信息數據整合。使用歸一化工具處理采集到的所有數據,刪除稀疏數據和噪聲數據,然后生成一個數據集。該數據集中包含600萬條大學生數據,數據的屬性包括個人信息、學習成績、家庭信息、金融銀行存貸信息等,然后形成一個數據矩陣。
3) 深度學習算法挖掘分析。在大學生資助管理模式構建和分析時,本文使用ReLU激活函數加快深度學習算法的收斂速度,減少卷積神經網絡設置參數。卷積層Conv1由20個4×4的卷積核與輸入數據進行卷積,卷積步長為2,得到20個13×13的特征數據;卷積層Conv2的卷積核大小為3×3,卷積步長為2,卷積后得到50個6×6的特征數據;卷積層Conv3的卷積核大小為3×3,卷積步長為1,卷積后生成60個4×4的特征數據;池化層步長為2,采樣后可以獲取80個2×2的特征數據;全連接層1神經元個數為100;全連接層2的神經元個數為10。Conv1、Conv2、Conv3、池化層1、全連接層1的激活函數均為ReLU函數,全連接層2的激活函數為sigmoid激活函數。
3 深度學習應用實驗及結果分析
3.1 實驗環境
大學生資助管理模式采用深度學習作為數據挖掘算法,這樣就可以利用大數據分析技術,提高大學生經濟生活狀況的評估準確度。本文為了能夠更好地分析深度學習的應用效果,對其進行了實驗驗證。實驗環境:實驗平臺的軟件操作系統為Windows7,編譯軟件采用Matlab10.1軟件,編程使用的語音為Matlab語言,硬件采用Intel 第8代 酷睿 i5-8300H 2.3 GHz,內存為4G。
3.2 實驗數據
采集了600萬條大學生資助數據,數據的類別包括重點貧困、中度貧困和一般貧困,每一個類別包括200萬條數據。類別是指具有相同貧困程度的學生信息集合,具有類似的結構。數據集合中單個對象之間的相似性非常高,但是類別之間的非相似性很高。本文將這些數據混合在一起,構建了低維度數據集和高維度數據集。
1) 低維度數據集。低維度數據集經過預處理后,保護20個關鍵屬性,利用這些屬性的共享對數據進行排序和篩選,分成3個子數據集。基于這些數據集進行實驗,低維度數據集類別如表1所示。
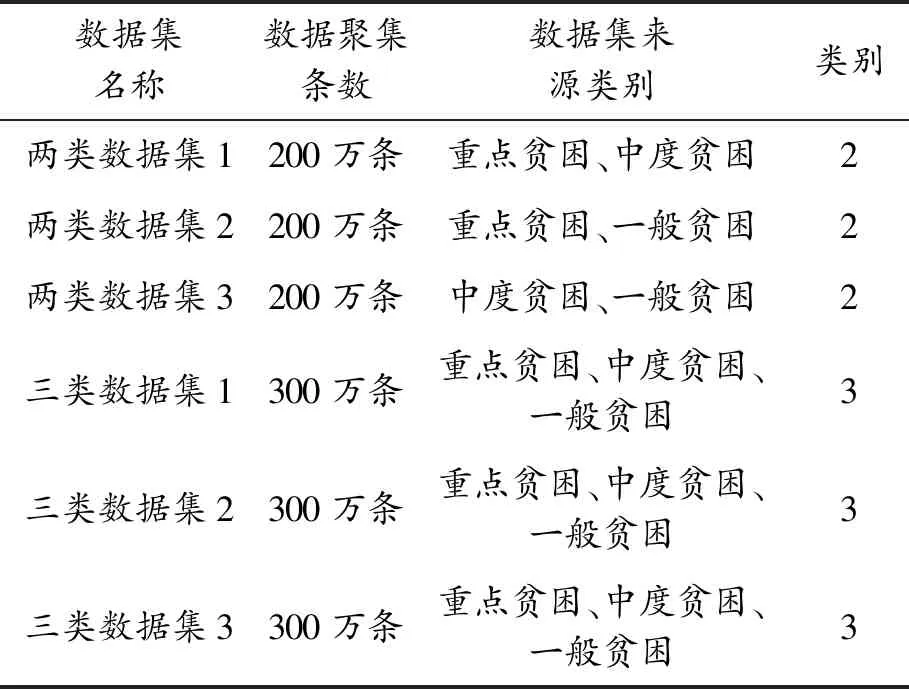
表1 低維度數據集類別
2) 高維度數據集。高維度數據集經過預處理后,包含100個關鍵屬性,利用這些屬性的共享對數據進行排序和篩選,分成3個子數據集。基于這些數據集進行實驗,高維度數據集類別如表2所示。
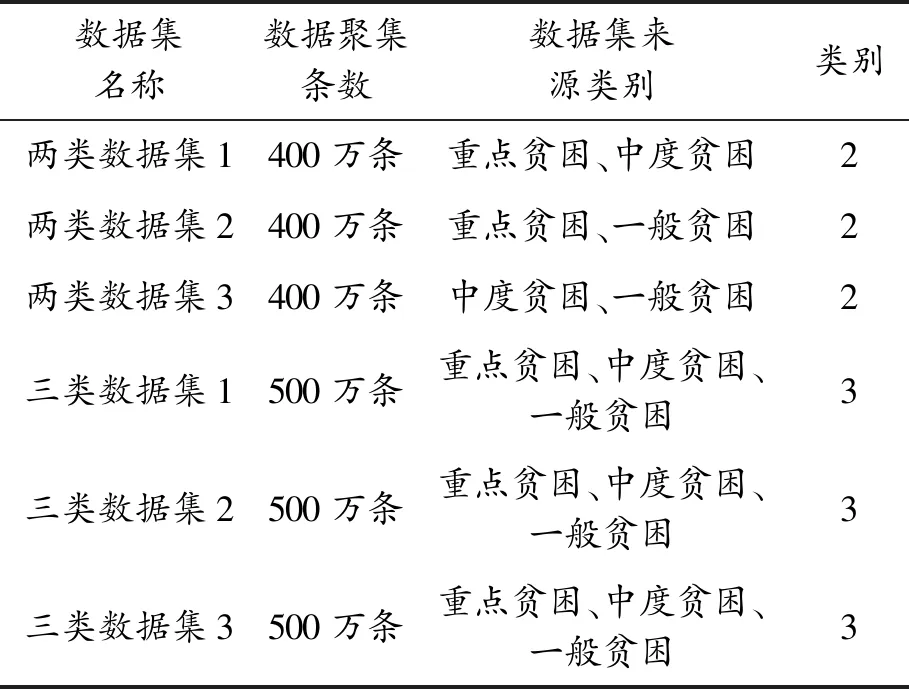
表2 高維度數據集類別
3.3 算法實驗評價標準
為了驗證深度學習算法的有效性,同時引入了關聯規則算法、K-means算法,在同樣的實驗環境進行操作和分析。本文指定每一個數據集的真實歸類,以便更好地驗證算法運行的準確度[11]。算法實驗過程中,本文針對算法實驗效果進行準確評估,使用準確度評估每一個算法執行結果的可靠度。正確率標準規定第i個簇的類標是由該簇中最多數對象的類標決定,并統計這些對象的個數為n,共有k個簇。算法準確度計算公式如式(1)所示。
(1)
其中:T描述劃分好的數據簇;C表示數據集中的真實的類標號;A1(c,T)表示屬于真實類別C的數據準確地劃分到簇T中的數量;A2(c,T)表示屬于真實類別C但是錯誤地劃分到簇T中的數據對象數量。聚類結果的正確率越高,代表聚類質量越佳。
3.4 算法實驗結果及分析
1)低維度數據實驗結果。關聯規則算法、K-means算法和深度學習算法的實驗環境完全相同。在同樣的實驗環境下進行實驗,實驗結果顯示深度學習算法的準確度較高,能夠分析不同學生貧困的類型,準確定位這些學生的資助檔次。將深度學習算法接入大學生資助管理系統中,可準確地根據學生的實際貧困需求進行分析,準確度達到了98.51%,提高了大學生資助管理的有效性。低維度數據實驗結果準確度對比如表3所示。
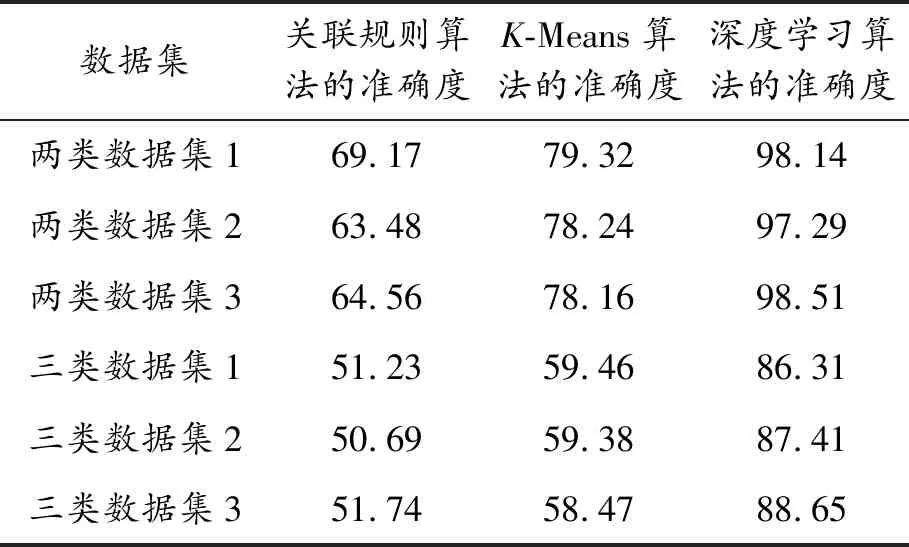
表3 低維度數據實驗結果準確度對比 %
在上述6個數據集上,當數據集的類別較少時,低維數據實驗結果的準確度達到了98.51%,遠高于傳統的關聯規則算法和K-Means推薦算法。因此可以獲知,如果高校的某個貧困類別的學生較少時,可以更加精準地判定學生的資助檔次,提高低維數據分析準確度,具有重要的作用和意義。
2) 高維數據實驗結果。本文提出的基于深度學習算法在分析高維學生資助數據時也具有很大的優勢。在高維數據集上進行同樣的實驗,分析3種算法的實驗結果,如表4所示。
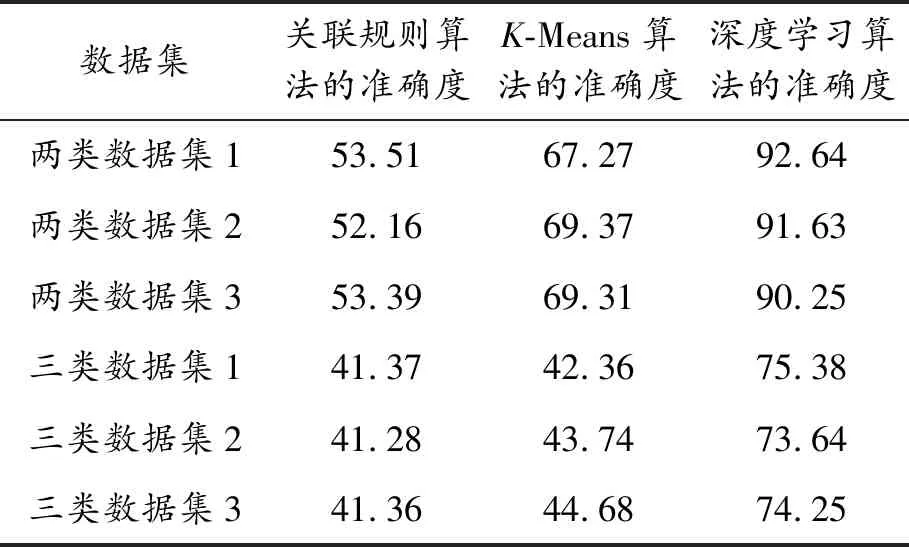
表4 高維數據實驗結果準確度對比 %
在高維大學生資助數據分析中,深度學習算法準確度雖然有所降低,但是與關聯規則算法和K-means算法相比,深度學習算法依然保持較高的準確度,說明利用深度學習算法可以更好地預估高維度貧困學生數據資源的內部結構。但是由于每一次數據簇心的選擇也是隨機的,因此難免存在一些問題,導致算法的準確度不穩定或降低。比如算法的簇心越多,算法執行的準確度越低。對于兩類數據集來講,深度學習算法的執行準確度為92.64%,但是在三類數據集上算法執行準確度卻下降。這說明深度學習算法面對較多的類別時無法取得最優化效果。
4 大學生資助管理模式實際應用效果分析
與人工判定模式進行比較,可突出深度學習算法的自動化、高性能、高效率、高準確度。實驗結果顯示:大學生資助管理模式采用深度學習的準確度較高,能夠分析不同學生家庭經濟生活的類型,準確地定位這些學生的貧困程度。將應用效果進行量化分析,大學生資助管理模式應用準確度對比如表5所示。
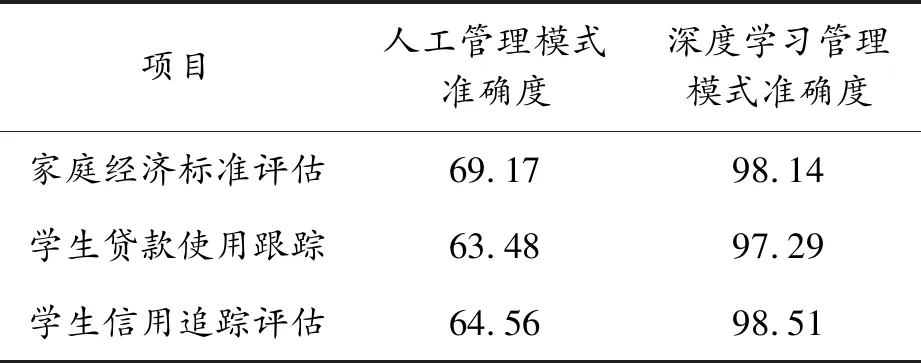
表5 大學生資助管理模式應用準確度對比 %
家庭經濟標準評估準確度采用人工管理模式時為69.17%,利用深度學習管理模式時則達到了98.14%,提高了28.97%;學生貸款使用跟蹤準確度采用人工管理模式時為63.48%,利用深度學習管理模式時則達到了97.29%,提高了33.81%;學生信用追蹤評估準確度采用人工管理模式時為64.56%,利用深度學習管理模式時則達到了98.51%,提高了33.95%。分析效率方面,人工分析1年1次,比較固定,而利用深度學習的結果則是實時的,可以根據需求隨時獲取大學生的資助數據。
5 結束語
深度學習是一種先進的大數據分析算法,利用深度學習建立大學生資助管理平臺,可從多個部門獲取大學生家庭狀況的數據,并基于“互聯網+”創新大學生資助管理模式整合現有資源提高數據利用率,從而進一步改進大學生資助成效。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
下一代英才(酷炫少年)(2019年3期)2019-03-25 02:34:18
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
黃河之聲(2017年14期)2017-10-11 09:03:59
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
