不平衡分類的數據采樣方法綜述
2019-08-17 08:00:26劉定祥喬少杰張永清魏軍林張榕珂
重慶理工大學學報(自然科學) 2019年7期
劉定祥,喬少杰,張永清,韓 楠,魏軍林,張榕珂,黃 萍
(1.成都信息工程大學 a.網絡空間安全學院; b.軟件工程學院; c.計算機學院; d.管理學院, 成都 610225;2.西部戰區總醫院, 成都 610083)
1 研究背景
針對現實生活中產生的大量數據,人們通過傳感器等數據采集設備將其收集、整理,形成了計算機能夠批量處理的數據。通過對數據的學習分析,挖掘潛藏在數據背后深層的知識和規律,可提升人們對外界事物的感知和理解能力[1-2]。然而,現實中這些數據大都比例不平衡。例如,癌癥基因檢測數據[3]中,在幾百萬個樣本基因里可能僅有一個基因是癌癥基因;電信通訊中只有少數通訊是具有欺詐行為的通訊記錄[4-5];軟件檢測中也只有不到10%的軟件是具有缺陷的[6]。
不平衡數據普遍存在于人類生活的方方面面,不僅數據分布廣泛,而且數據比例不均衡。在不平衡數據中數量多的樣本稱為負樣本,數量少的樣本稱為正樣本。正負樣本擁有較大的比例差距,例如:全國1年中雷電天氣(正樣本)天數占全年天數的比例不到10%;新生體檢中患肺結核疾病的學生人數占比不到1‰。
在數據分類評價指標中,全局分類正確率是指分類正確的正樣本與負樣本數量之和除以總的正樣本與負樣本的數量。正樣本分類正確率是指分類正確的正樣本數量除以總的正樣本數量。同理可得負樣本分類正確率。通過上述定義可以知道:不平衡數據中,由于負樣本數量遠多于正樣本,少數正樣本被錯分并不會大幅度地降低全局分類正確率,但正樣本分類正確率會下降。
機器學習[7]利用訓練數據對模型進行訓練,使模型能夠學習到樣本數據特征,實現機器對樣本數據的自動分類。精準分類一直是機器學習發展所必需的,但絕大多數流行的分類器是根據平衡數據進行設計,不平衡數據不能夠充分訓練分類模型,導致分類性能下降[8]。現階段,機器學習大多通過梯度下降[9]方法訓練模型參數,不平衡數據訓練分類模型會導致分類模型的參數過多向負樣本(majority class)傾斜,從而極大地降低了模型對正樣本(minority class)的分類正確率。例如:對于同一分類方法,利用平衡數據集對分類模型進行訓練時,分類模型能夠較好地識別正負樣本,獲得較高的正負樣本分類正確率;利用不平衡數據集對分類模型進行訓練時,分類模型對正樣本識別能力弱,降低了正樣本分類正確率。
為了解決數據不平衡問題,許多數據不平衡處理方法被提出[10]。Anand等[11]早在1993年就對不平衡數據做了比較深入的研究,發現神經網絡反向轉播收斂速度慢,其原因是訓練集中多數樣本均屬于同一類。與此同時,Krawczyk等[12]針對不平衡問題總結了不平衡數據主要應用領域,如表1所示,其中括號內數字表示統計應用的次數。表1充分說明了不平衡數據應用在各個領域,其分布廣,使用頻率高,是機器學習中普遍存在和亟待解決的問題。
當前,提升分類器在不平衡數據中的學習效果主要采用兩種方法:
1) 對不平衡數據分類算法的優化。由于現階段的分類算法主要是根據平衡數據集進行設計的,故優化不平衡分類算法不僅難度大,且在正樣本分類正確率上提升不顯著。
2) 對不平衡數據采樣算法的優化。采樣算法著手于數據層面,能夠有效地解決不平衡數據正負樣本分布不平衡的問題,且采樣算法的優化設計相對容易,在正樣本分類正確率方面性能可得到顯著提升。研究不平衡數據采樣算法能夠有效地提升正樣本分類正確率。本文著重從數據采樣的角度介紹如何對不平衡數據進行處理。
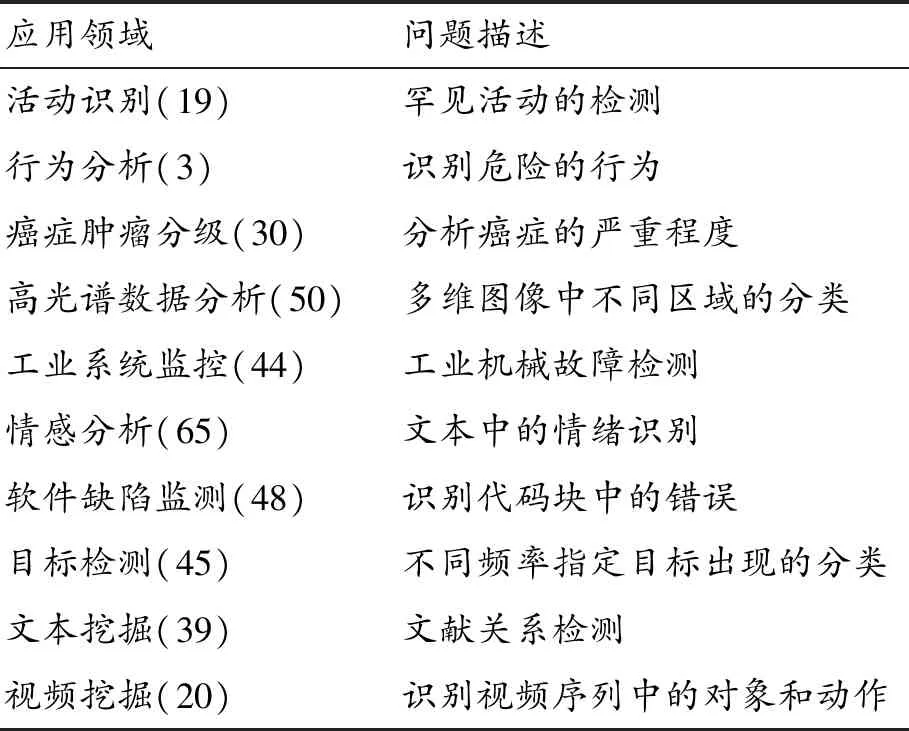
表1 不平衡數據的典型應用
當前,采樣方法主要有以下3類:欠采樣[13-20]、過采樣[21-40]、混合采樣[41-51],這三類方法都有各自的優缺點。
1) 欠采樣方法指篩選一些具有代表性的負樣本,使負樣本和正樣本達到比例相當,即所謂的“數據平衡”。其優點是訓練集達到了平衡,提升了正樣本分類正確率,缺點是丟失了大量的負樣本特征,模型不能充分地學習到負樣本的樣本特征,降低了負樣本分類正確率,欠采樣過程如圖1(a)所示。
2) 過采樣方法是時下比較流行的方法,其工作原理和欠采樣相反,目的是將現有的少數正樣本通過模型生成新的正樣本,使數據集中正負樣本達到平衡。其優點是增加了正樣本數量和正樣本的多樣性,提升了模型對正樣本的學習量。缺點是生成的正樣本不是真正采集獲得的正樣本,在增加樣本數量和多樣性的同時帶來了樣本噪聲(樣本不具有的特征)。模型學習樣本噪聲,降低了模型對正樣本的分類正確率。過采樣思想如圖1(b)所示。
3) 混合采樣是指將欠采樣和過采樣結合,正樣本通過某種樣本生成模型生成一部分新的正樣本,負樣本通過樣本篩選模型篩選一部分具有代表性的負樣本,達到正負樣本數量平衡。混合采樣旨在減少負樣本的特征丟失,同時減少正樣本的噪聲生成,達到正負樣本數量平衡,混合采樣過程如圖1(c)所示。
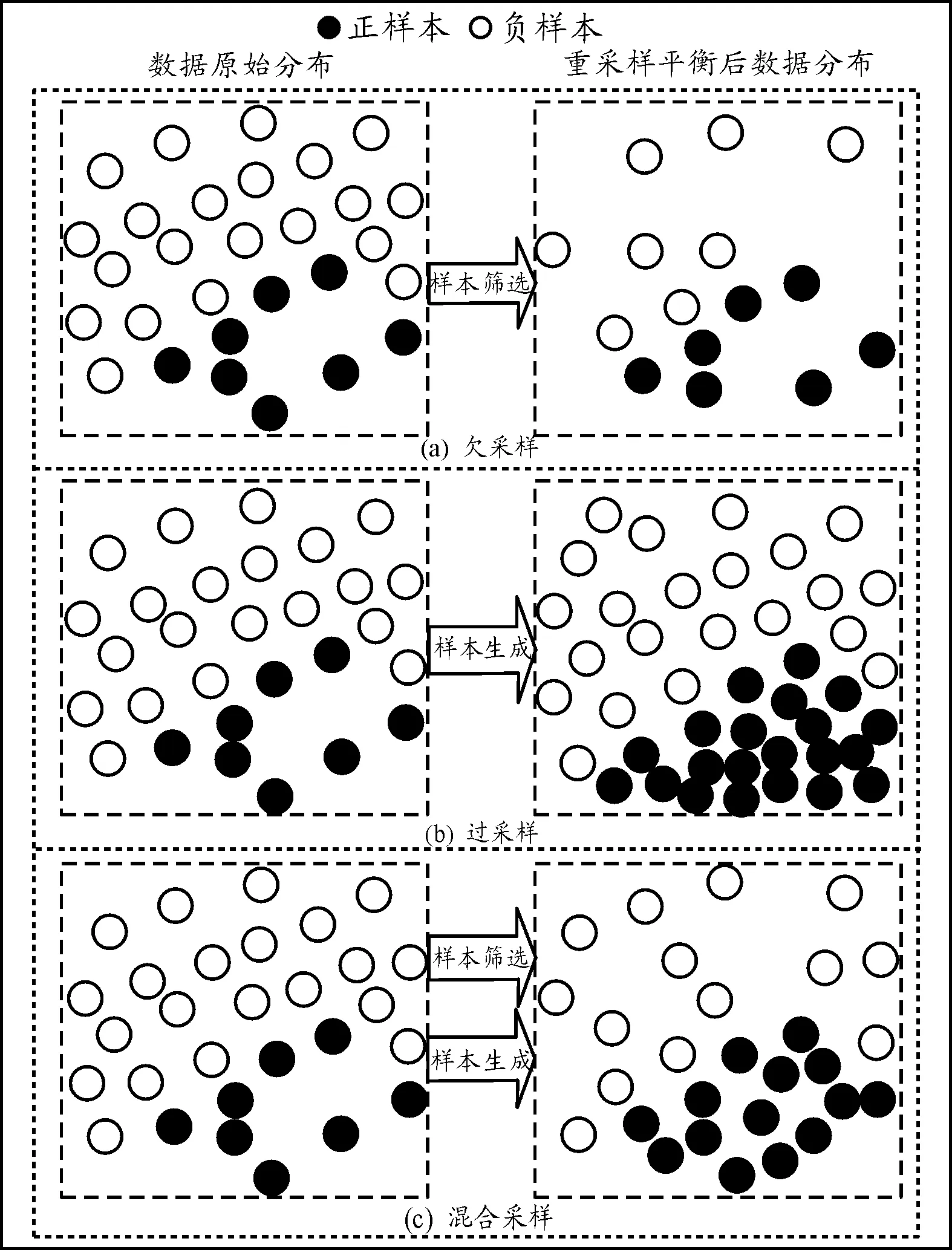
圖1 不同采樣算法工作原理
本文通過對當前國內外具有代表性的不平衡分類學習中的采樣研究進行統計發現:其19%是欠采樣的研究,52%是過采樣的研究,29%是混合采樣的研究。單從統計數據上可以發現,不平衡數據采樣研究中過采樣的研究較多。通過整理,將本文討論的研究內容匯總如表2所示。
2 欠采樣方法
解決數據不平衡問題,最簡單的欠采樣方法是隨機欠采樣[13]。它通過隨機丟棄一部分負樣本使正負樣本達到平衡。但這種做法具有很大的缺陷,因為隨機丟失了大量的負樣本特征,隨機欠采樣不能大幅度地提升模型的正樣本分類正確率。
欠采樣主要分為兩類:① 基于聚類的欠采樣(clustering based under-sampling):通過對負樣本進行聚類,并在每一個類中選取具有代表性特征的樣本作為負樣本訓練集;② 通過整合的思想,將負樣本分成很多份,利用每一份負樣本和唯一一份正樣本對多個分類器進行訓練,最后對多個結果進行集成。
表2 典型采樣方法及采樣策略
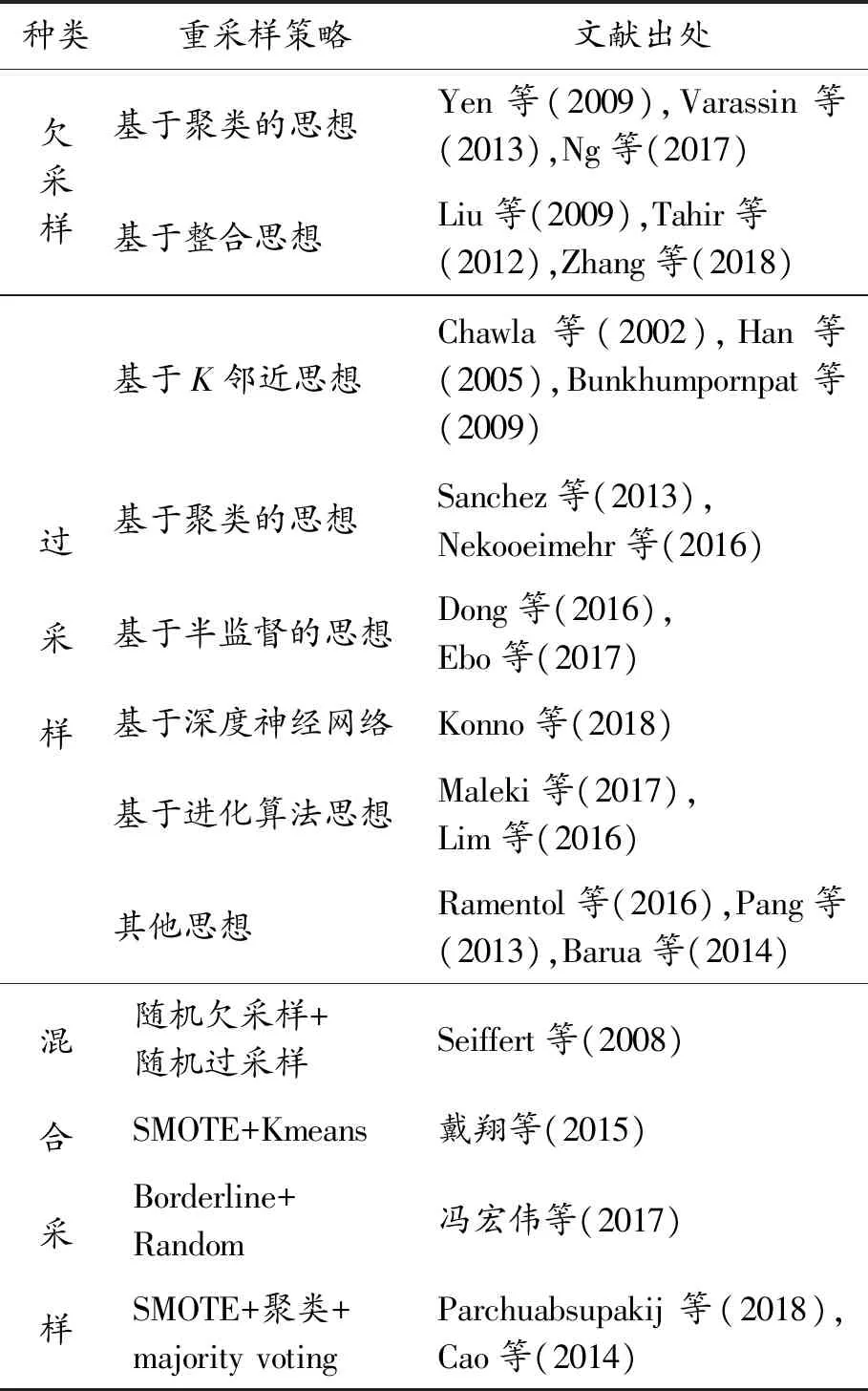
種類重采樣策略文獻出處欠采樣基于聚類的思想Yen等(2009),Varassin等(2013),Ng等(2017)基于整合思想Liu等(2009),Tahir等(2012),Zhang等(2018)過采樣基于K鄰近思想Chawla等(2002),Han等(2005),Bunkhumpornpat等(2009)基于聚類的思想Sanchez等(2013),Nekooeimehr等(2016)基于半監督的思想Dong等(2016),Ebo等(2017)基于深度神經網絡Konno等(2018)基于進化算法思想Maleki等(2017),Lim等(2016)其他思想Ramentol等(2016),Pang等(2013),Barua等(2014)混合采樣隨機欠采樣+隨機過采樣Seiffert等(2008)SMOTE+Kmeans戴翔等(2015)Borderline+Random馮宏偉等(2017)SMOTE+聚類+majority votingParchuabsupakij等(2018),Cao等(2014)
2.1 基于聚類的欠采樣方法
為了解決欠采樣的隨機性問題,Yen等[14-15]將負樣本進行聚類,選取有代表性的樣本作為訓練集,以盡可能地提取具有代表性的負樣本特征,減少負樣本的特征丟失,優化訓練效果,在提升對正樣本識別率的同時減少負樣本的錯分率。雖然通過聚類使得訓練集包含了更加全面的特征,但依然無法避免樣本特征丟失的缺陷。Ng等[16]認為樣本的分布信息有助于代表性樣本的選取,通過對負樣本進行聚類獲取其分布信息,選取每一個類中具有代表性的樣本,計算樣本的敏感度,再根據敏感度選取k個負樣本和k個正樣本,將這2k個樣本作為訓練集。Varassin等[17]將欠采樣的方法運用到DNA剪切位點的預測中,通過對負樣本進行聚類,選取距聚類中心最近的樣本作為代表性的負樣本。
2.2 基于整合的欠采樣方法
Liu等[18]針對欠采樣提出了一種將負樣本劃分為多份的思想對模型進行訓練,然后對結果進行集成,其基本思想為:隨機將負樣本分成和正樣本數量相當的若干份,然后對每一份負樣本和僅有的一份正樣本進行訓練,這樣可以訓練出若干個模型,再將每一個模型的分類結果進行集成得到最終結果。由于考慮了所有負樣本的特征,所以應用這一方法可以有效地提升正樣本與負樣本的分類正確率,其算法流程如下所示:

算法1 簡單集成欠采樣算法輸入:所有正樣本P,所有負樣本N,|p|<|N|,數據集個數T輸出:分類預測結果1.選擇合適的模型Xi,將N劃分為T個子數據集{N1,N2,N3,…,NT};2.For i=1,2,3,…,T 利用P和Ni對模型Xi進行訓練,得到結果Ri; EndFor3.將T個結果{R1,R2,R3,…,RT}進行集成,得到最終結果;
該方法考慮了所有負樣本的特征,能夠獲得較高的正樣本與負樣本分類正確率,但是對于一些處于樣本邊界的數據,并不能有效地提升分類性能。因為在沒有強化學習邊界樣本的情況下,分類器大概率會出現錯分的情況。Zhang等[19]提出了一種反向隨機欠采樣的方法,其思想是將負樣本分成比正樣本少的若干份,將每一份負樣本和正樣本作為訓練集,然后對多個結果進行集成得到最終結果。由于欠采樣后每一個訓練集中負樣本比正樣本少,所以稱為反向欠采樣。實驗結果表明:反向欠采樣具有一定的有效性與可靠性。Tahir等[20]針對上述問題提出了一種尋找正樣本和負樣本邊界的欠采樣方法。首先將負樣本進行反向欠采樣,產生若干個負樣本少于正樣本的訓練集;然后尋找每一個訓練集中正負樣本的邊界,將這些邊界進行擬合,得到最終的樣本邊界,進而通過邊界對樣本進行分類。實驗結果表明:此方法在二分類和多分類問題上均取得了較高的正樣本分類正確率。
3 過采樣方法
過采樣方法主要指通過數學模型或者方法合成正樣本。由于合成樣本的方法是人為設定的,使得生成的正樣本會包含一些原正樣本不具有的特征,即噪聲數據。該特征被分類器學習進而造成分類正確率下降。如何使生成的正樣本具有豐富多樣的正樣本特征,且使得正樣本均勻分布在樣本空間是過采樣方法研究的關鍵與核心[21]。已有過采樣方法較多,不同方法具有各自的優缺點。最簡單的過采樣方法是隨機過采樣[22],其思想是隨機復制正樣本,單純地使得正負樣本比例達到相對平衡。雖然模型對正樣本的分類正確率有一定的提高,但其最大的缺點在于生成的正樣本與初始正樣本一樣,不具有多樣性,并不能大幅度地提升正樣本的分類正確率。
3.1 基于K鄰近的過采樣方法
為了解決隨機過采樣的局限性,提升樣本的多樣性,Chawla等[23]提出了SMOTE方法。SMOTE算法的主要過程如下所示:

算法2 基于K鄰近的SMOTE過采樣算法輸入:原始樣本數據集N,采樣比率P輸出:新的平衡數據集Nnew1.對于每一個正樣本Xi,計算Xi到正樣本集合N中所有樣本的歐式距離,得到其K鄰近;2.根據采樣比率計算生成的正樣本數量,從其K鄰近中隨機選擇相應數量的鄰近配對;3.對每個配對的樣本(Xi,Xn)按照如下公式生成新的正樣本,直到達到采樣比率: Xnew=Xi+rand(0,1)?|Xi-Xn|;
SMOTE方法是最具代表性的過采樣方法,其基本思想是在每一個正樣本和其K鄰近的樣本之間隨機地生成一個新的樣本。由于生成的樣本是兩個樣本之間的隨機值,所以該方法解決了樣本多樣性的問題。 Han等[24]分析了SMOTE方法的不足,提出了Borderline SMOTE方法,認為在正樣本的邊界區域樣本容易被分類器錯分,因而要強化邊界區域數據的訓練。算法思想:找到正樣本的邊界區域,對處于邊界區域的正樣本采用SMOTE方法進行樣本生成。由于增加了邊界樣本的數據量,強化了邊界樣本的學習,正樣本分類正確率相比SMOTE方法有一定的提升。但SMOTE和Borderline SMOTE方法均通過尋找K鄰近生成樣本,在選取K鄰近樣本時,均未考慮存在選取到負樣本的情況。Bunkhumpornpat 等[25]提出了Self-Level-SMOTE方法,通過計算K鄰近附近正樣本的權重來生成正樣本,避免了生成樣本跨越正樣本邊界的問題。
3.2 基于聚類的過采樣方法
基于聚類的過采樣方法思想是:為了將具有相同特征的正樣本聚在一起,在每一個類中通過樣本生成的方法生成樣本。由于對正樣本進行了聚類,所以處于每一個類中的樣本都會有新樣本生成,避免了生成樣本過于集中在某一個類中,使得生成的正樣本能夠均勻地分布在正樣本的樣本空間,提升了正樣本分類正確率。Sanchez等[26]將正樣本進行聚類,根據需要生成的樣本數量在每一個類中單獨進行過采樣。由于聚類后在同一個類中的樣本具有相似的屬性,新生成的樣本不會跨越類邊界,同時減少了樣本生成的盲目性,提升了采樣的效果。Nekooeimehr等[27]利用層次聚類對正樣本進行聚合,在每一個層內部進行過采樣,并對邊界樣本進行識別,對處于邊界的樣本不進行過采樣,避免了生成樣本跨越邊界的問題。
3.3 基于半監督學習的過采樣方法
不平衡數據集中有一些數據集不平衡比例較大,正樣本數量非常少,通過簡單地樣本生成不能有效地生成具有多樣性的樣本。Dong等[28]利用半監督的方法解決正樣本過于稀少的問題,不斷把新生成的樣本合并到原來的樣本中進行下一輪迭代,從而達到正負樣本平衡。Ebo等[6]認為:無論是SMOTE方法,還是通過高斯分布或者基于特征生成的模型都是基于K鄰近生成的,K鄰近生成的新樣本會跨越正樣本的邊界,如圖2所示。
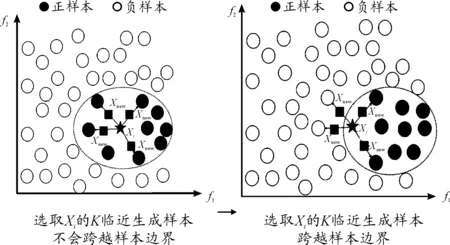
圖2 基于K鄰近(K=4)的樣本生成示意圖
通過圖2可以發現:正樣本(用實心五角星表示)被選取時,基于K鄰近方法生成的樣本有部分跨越了樣本邊界(虛線以外)。Ebo等[6]提出了一種染色體遺傳理論的過采樣方法MAHAKIL,通過計算每一個正樣本和正樣本中心的馬氏距離,按距離大小排序,將距離較大的一半和距離較小的一半分別作為父親樣本和母親樣本進行交配,生成新的樣本,然后利用半監督的思想迭代生成需要的樣本數量,具體過程如算法3所示。

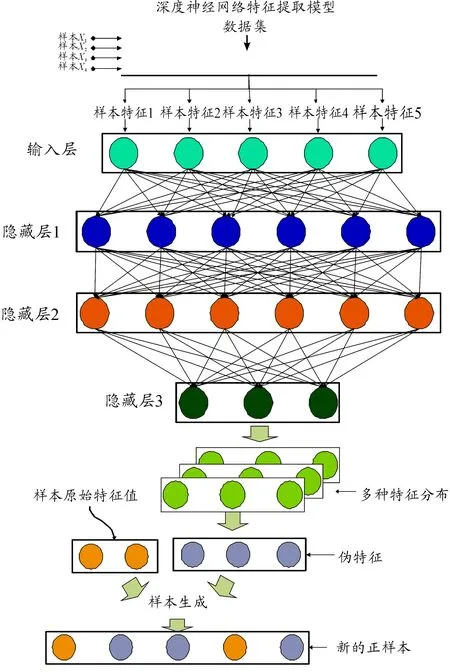
算法3 基于多樣性的MAHAKIL過采樣算法輸入:原始數據集N,生成比例P輸出:和生成比例P相當的數據集1.將數據集N分成正樣本Nmin和負樣本Nmaj,獲取正樣本的個數NNmin和負樣本的個數NNmaj;2.根據生成比例P得到樣本生成后總的正樣本數量NG=NNmaj?P;3.while NNmin MAHAKIL方法按照半監督的原理生成樣本,在增加樣本多樣性的同時不會降低樣本的有效性。算法實現簡單,生成的新樣本在多數數據集上不會跨越樣本邊界,且生成的樣本分布均勻,在計算成本、時間成本、采樣效果方面均取得較好的效果。由于MAHAKIL方法按照距離樣本中心的馬氏距離進行聚類,導致該方法在數據小析取項[29-31]的問題上存在缺陷。小析取項又稱為類內不平衡問題,是指正樣本分布并不都在一個連續的樣本空間,可能分布在兩個或者多個不連續的樣本空間,其結構如圖3所示。 圖3 正樣本類內分布不平衡的情況(數據小析取項) Konno等[32]將深度神經網絡技術應用于過采樣中,其思想是:通過深度神經網絡(DNN)提取正樣本特征作為樣本基本特征,在基本特征上加入一部分偽特征(pseudo feature)產生新的樣本。該方法的特點在于偽特征的加入能增加樣本的多樣性。通過深度神經網絡能夠有效地提取樣本特征,具有較好的普適性,但存在一些不足,例如:偽特征中仍會產生許多噪聲,特征提取過程中會有部分樣本特征丟失。算法思想如圖4所示。 樣本生成過程中減少噪聲是影響過采樣性能的關鍵因素之一。為了減少噪聲,同時提升生成樣本的多樣性,學者們提出了一些基于進化算法的過采樣方法[33-35]。進化算法的基本原理是通過選擇、交叉、變異等操作在問題空間尋找最優解,其主要步驟包括:首先,選擇合適的正樣本分別作為父親類和母親類;然后,父親類樣本和母親類樣本進行交叉生成新的樣本;最后,在新樣本上進行變異操作,增加樣本的多樣性。當前較新的進化算法是Lim等[36]提出的基于進化理論的過采樣算法ECO-Ensemble。該方法通過優化正樣本中的類內和類間的樣本生成比例,使得生成的樣本具有多樣性和均勻分布的特性。 圖4 基于深度神經網絡的過采樣模型 目前,將過采樣方法應用于機器學習技術的研究日益普及。Ramentol等[37]將模糊粗糙集的編輯技術應用于過采樣中,取得了較好的正樣本分類正確率。Pang等[38]利用不平衡時間序列和稀疏混合的高斯模型對正樣本進行過采樣,降低了過采樣的隨機性。Moreo等[39]認為要提取樣本的分布特征,根據樣本分布特征生成新的正樣本,使生成的正樣本具有合理的分布,其缺點在于:不同的數據具有不同的分布特征,基于特征分布來生成新樣本的方法不具有普適性。Barua等[40]提出了一種根據樣本權重生成新樣本的過采樣方法MWMOTE。首先,算法識別一些分類器比較難識別的正樣本;然后計算這些正樣本和最近負樣本的歐式距離,根據距離大小賦予正樣本相應的權重,依照權重對正樣本進行聚類;最后在每一個類中應用SMOTE方法對樣本進行過采樣。該方法提升了比較難識別(權重較大)的樣本的學習效果。為了解決數據不平衡的問題,已有研究雖然取得了一些進展,提升了不平衡數據分類正確率,但仍存在諸多不足,典型過采樣研究方法簡介如表3所示。 表3 典型過采樣研究方法簡介 過采樣方法算法特點隨機過采樣平衡了正負樣本訓練集,產生的樣本不具有多樣性SMOTE過采樣方法生成樣本具有多樣性、但生成樣本有可能跨越邊界Borderline SMOTE強化了邊界樣本的學習基于聚類的過采樣方法生成樣本更符合樣本類內的分布基于深度神經網絡特征提取的過采樣方法具有很好的普適性,樣本特征容易丟失,產生噪聲較多基于半監督思想的過采樣方法解決樣本稀少問題,但新樣本噪聲較多基于樣本分布特征的過采樣方法樣本生成效果好,不具有普適性基于進化理論的過采樣方法樣本生成效果好,實現困難,代價大 混合采樣是將過采樣方法與欠采樣方法結合以達到平衡正負樣本的采樣方法,其主要從以下兩個方面提升正樣本與負樣本分類正確率[41]:① 不會造成大量的負樣本特征丟失,模型能學習到足夠多的負樣本特征;② 不會產生過多的噪聲,模型學習到的噪聲少。 為了驗證混合采樣的性能,Seiffert等[42]將隨機過采樣和隨機欠采樣技術結合,通過實驗驗證了混合采樣技術能夠顯著提升決策樹的正樣本分類正確率。戴翔等[43]綜合過采樣與欠采樣的優點,將SMOTE算法運用于少數類樣本的生成,利用K-means聚類對負樣本進行欠采樣,提升了正樣本與負樣本的分類正確率。Li等[44]將混合采樣技術運用于支持向量機SVM中,并利用K鄰近方法對混合采樣的結果做進一步約減,解決了數據混淆的問題,提高了支持向量機的泛化性能。Cervantes等[45]利用欠采樣和支持向量機得到初始SVs和超平面,將這些實例作為遺傳算法的初始種群。原始數據集包含生成和演化的數據,通過學習達到最小化不平衡數據的目的。該方法提高了支持向量機在不平衡數據集上的泛化能力。高鋒等[46]提出一種基于鄰域特征的混合采樣技術,根據樣本領域分布特征賦予采樣權重,利用局部置信度的動態集成方法對不同的數據選擇不同的分類器,并將不同分類器結果集成。實驗結果表明,在查全率和查準率上該混合采樣技術都有較大的提升。馮宏偉等[47]認為,位于邊界區域的樣本是最容易錯分的樣本,于是針對邊界樣本進行SMOTE過采樣以強化邊界樣本的學習,然后針對負樣本進行隨機欠采樣。該方法的正樣本與負樣本分類正確率較經典的采樣方法有較大的提升。Gazzah等[48]提出的方法不是單純地進行過采樣和欠采樣,進行過采樣時重點考慮具有代表性的正樣本,進行欠采樣時丟棄相關性較小的負樣本。Cao等[49]認為正負樣本比例大時,單純應用混合采樣的效果不理想,將混合采樣和集成的思想結合能夠有效地提升模型正樣本與負樣本的分類正確率。基于集成的混合采樣方法工作原理如圖5所示。 算法基本思想:首先,將正樣本進行一次過采樣,并隨機地將負樣本欠采樣成與正樣本相當的若干份;然后,將每一份負樣本和正樣本進行混合,形成多個訓練集,得到多個訓練好的分類器;最后,將不同分類器的結果進行集成,得到最終結果。模型通過該方法能夠充分學習負樣本特征,是目前比較流行的混合采樣方法[50-51]。 圖5 基于集成的混合采樣方法工作原理 不平衡數據分類問題是當前機器學習領域比較熱門的研究內容,已經吸引越來越多學術界和工業界專家對其進行廣泛和深入的研究。本文詳述了不平衡分類問題中采樣方法的研究現狀和發展趨勢,介紹了欠采樣、過采樣和混合采樣3大類采樣方法原理和典型算法。應用這些方法可以提高不平衡數據分類的正確率。 為了進一步研究更高效穩定的不平衡學習方法,未來可以從以下幾個方面展開研究: 1) 在樣本信息獲取中,樣本信息獲取不完善是導致不平衡分類學習性能下降的最根本原因。對樣本的物理、化學屬性進行分析,以便多角度、多方位獲取更多的樣本屬性,提升正負樣本的區分度,達到提升不平衡分類學習性能的目的。 2) 在樣本聚類中,通過單一的距離指標進行聚類不能全面地衡量樣本間的距離,應結合多個距離指標進行聚類,并引入普適高效的聚類方法提升聚類效果。 3) 在過采樣特征提取中,需要研究多層次的樣本特征提取模型,強化樣本特征的提取,生成噪聲量少、多樣性豐富的新樣本,提升過采樣的有效性。 4) 在強調邊界的采樣方法中,需要研究有效的邊界尋找方法,結合多個評價指標對樣本邊界進行擬合,并對樣本進行降噪處理,提升樣本邊界的有效性。 5) 基于進化算法的過采樣中引入更多參數,優化生成樣本的分布,提升生成樣本的多樣性與有效性。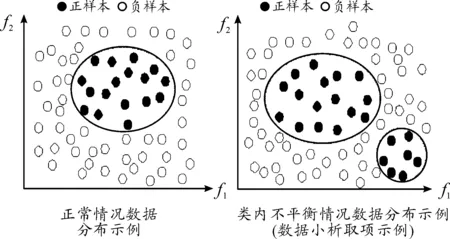
3.4 基于深度神經網絡的過采樣方法
3.5 基于進化算法的過采樣方法
3.6 其他過采樣方法

4 混合采樣方法

5 結束語
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
