基于混合采樣策略的改進隨機森林不平衡數據分類算法
2019-08-17 07:59:08鄭建華劉雙印賀超波符志強
重慶理工大學學報(自然科學) 2019年7期
關鍵詞:分類
鄭建華,劉雙印,賀超波,符志強
(1.仲愷農業工程學院 信息科學與技術學院, 廣州 510225;2.廣東省高校智慧農業工程技術研究中心, 廣州 510225)
1 研究背景
分類是機器學習中的一種重要手段,常見的分類算法有樸素貝葉斯算法、決策樹、KNN、支持向量機等。現有的分類算法通常假定數據集中各類別的樣本數基本相等,即數據集是平衡的,但現實中如網絡入侵檢測[1]、金融欺詐[2]、醫療診斷[3]中異常類數量非常少,正常類數量非常多,即數據集是不平衡的。傳統分類算法以降低總體分類誤差為目標。為了提高分類的整體精度,分類器會減少對少數類的關注,偏向多數類,使少數類的分類性能下降[4]。假設數據集不平衡比例為99∶1(即多數類樣本數量與少數類樣本數量之比),則即使分類器將所有的樣本都看作是多數類,整體分類精度依然可以達到99%,但是這樣顯然不是一個好的分類效果,因此傳統的分類算法難以滿足不平衡數據的分類要求[5]。
近年來,大量學者對于不平衡數據分類問題提出許多解決方案,主要集中在以下類型[6]:改變數據分布和算法層面改進。
在改變數據分布方面,各種過采樣算法和欠采樣算法一直是研究熱點和重點,典型的有SMOTE、Safe-level SMOTE、ADASYN[7]、Borderline-SMOTE、SOMO[8]、MAHAKIL[9]等過采樣算法,以及NearMiss、Tomek Links、隨機欠采樣技術(RUS)等欠采樣算法。對于過采樣,需要生成新樣本,如果數據集不平衡比例過大,則需要生成較多新樣本從而容易導致分類器過擬合。對于欠采樣,由于需要舍棄大量多數類樣本,因此分類器并沒有能學習到所有的樣本特征,容易導致在測試集上分類效果不好[6]。特別是當不平衡比例較大時,不管何種采樣技術,其弊端更加明顯。
算法層面上的改進主要有代價敏感方法[10],其核心思想是對不同類的分類錯誤賦予不同的代價,對原本是少數類而被誤分為多數類的樣本賦予更高的誤分代價,但是精準確定錯誤分類的代價因子是一個難點[11]。
算法層面上的改進的另一種方式是集成學習。集成學習是使用某種規則把多個學習器進行組合,獲得比單個學習器更好的學習效果的一種機器學習方法,常用的集成方法主要有Bagging和Boosting。將集成學習應用于不平衡數據處理時,主要有代價敏感的集成分類算法和數據處理的集成分類算法[12]兩大類。由于代價函數不容易定義,只能主觀給出,因此基于數據處理的集成分類算法是廣大學者的研究重點,其可分為以下幾種類型:① 過采樣與Boosting結合。如Chawla等[13]將SMOTE與AdaBoostM2結合構建了SMOTEBoost算法,這種結合方式是在每一輪迭代中采用過采樣算法生成部分少數類樣本,但問題在于每輪的訓練樣本集并非平衡。② 欠采樣與Boosting結合。如Seiffert等[14]提出的RUSBoost 算法是在AdaBoost算法的迭代過程中采用RUS算法從多數類中隨機選擇樣本,為每次迭代構建一個平衡的數據集,這種模式可取得較好的效果。③ 過采樣與Bagging結合。這種模式主要是對少數類樣本過采樣從而實現整體數據平衡,如Wang S等[15]提出的基于隨機過采樣的OverBagging算法和基于SMOTE過采樣的SMOTEBagging算法。④ 欠采樣和Bagging結合。這種模式主要是對多數類樣本欠采樣實現數據集平衡,但是如前所述,欠采樣策略可能忽略有用的多數類樣本,造成分類結果的不精確。⑤ 混合采樣與Bagging結合。為了避免單一采樣方式的不足,張明等[16]針對少數類樣本采用SMOTE過采樣,為多數類樣本設計了一種欠采樣方法,從而構建平衡訓練數據集,然后再采用Bagging集成學習方式。
除上述方式外,EasyEnsemble[17]是一種同時融合Bagging和Boosting的混合集成分類算法,其基本思想是隨機采樣生成多數類樣本的若干個與少數類樣本數相等的子集,每個多數類樣本子集和少數類樣本構成若干個“平衡數據包”,然后采用AdaBoost算法訓練生成若干個基分類器,最后進行集成。
集成學習是一種有效的學習方法,但是現有基于數據處理的集成策略除欠采樣與Boosting結合外,其他4種均存在一定不足,如采用Bagging集成方式時,是對原始整體數據集做過采樣、欠采樣或者混合采樣,從而形成平衡數據集,這樣處理并沒有解決過采樣或者欠采樣帶來的不足,特別是對于不平衡比例較大的數據集效果不佳。而對于過采樣與Boosting結合方式,實際上每一輪迭代過程中數據并不是平衡的,并且整個迭代過程需要生成大量少數類樣本。
針對現有不平衡數據分類算法的不足,本文提出一種基于混合采樣策略的改進隨機森林不平衡數據分類算法。該方法以隨機森林作為基礎分類算法,對隨機森林中的每棵子樹采用小量過采樣和欠采樣的混合采樣策略生成平衡的訓練子集,通過提升每棵子樹訓練子集的差異性來提高隨機森林中基分類器的多樣性,最終達到提升集成分類器分類效果的目的。最后在多種公開數據集上進行實驗,對比本文方法與其他不平衡分類算法的分類性能。
2 隨機森林理論
隨機森林是Leo Breiman[18]提出的以決策樹為基分類器的一個集成學習分類模型,它通過自助法(bootstrap)重采樣技術從原始數據集中有放回地重復隨機抽取有差異的n個樣本生成新的訓練樣本集合訓練決策樹,重復以上步驟,并將生成的多棵決策樹集成。隨機森林實際上是采用Bagging集成策略對多棵決策樹的集成,而測試數據的分類結果按各決策樹結果投票多少形成的分數而定,采用隨機森林的方式主要是通過降低估計的偏差和方差來提高預測的精準性。目前隨機森林算法被廣泛用于各種應用領域[19-20]。算法過程為:
1) 通過自助法重采樣技術從訓練集中有放回地隨機采樣選擇n個樣本;
2) 從特征集中選擇d個特征,利用這d個特征和1)中所選擇的n個樣本建立決策樹;
3) 不斷重復步驟1)和2),直至生成所需的Ntree棵決策樹,形成隨機森林;
4) 對于測試數據,經過每棵樹決策判斷,最后投票確認分到哪一類。
隨機森林算法具有以下優點:
1) 各子樹的訓練相對獨立,效率較高;
2) 各子樹都選擇部分樣本及部分特征,一定程度上避免了過擬合,受噪聲影響較小;
3) 由于各子樹都是部分選擇特征,因此適用于高維特征情況。
考慮到隨機森林算法在處理非平衡數據集上表現不佳[21],馬海榮等[22]采用隨機森林模型進行預訓練,然后根據投票熵與基于樣本特征參數的廣義歐幾里得距離逐步構建訓練集,以此方式處理不平衡數據集。但是該方法需要通過多次迭代不斷添加訓練樣本,效率較低。
3 基于混合采樣隨機森林不平衡數據分類算法
3.1 隨機森林子樹的混合采樣策略機理
提高基分類器的多樣性是Bagging集成學習算法獲得較好性能的關鍵因素[23]。經典的隨機森林模型中,每棵樹應用重采樣技術和隨機選擇不同特征[18]以保證基分類器的多樣性。但是面對不平衡數據集時,因為每一子樹樣本分布與原始數據集的樣本分布仍然一致,故經典的隨機森林模型仍然難以勝任。當前研究者主要還是對原始整體訓練集進行過采樣或者欠采樣以構造平衡訓練集,比如文獻[24-25]通過SMOTE對原始整體數據進行過采樣,構建一個平衡的訓練集,然后將該訓練集再應用到隨機森林模型中。但是這種處理模式仍未擺脫過采樣或者欠采樣帶來的不足,特別是當不平衡比例較大時,如果采用過采樣則過擬合較嚴重,如果采用欠采樣則丟失的信息較多,分類準確性都會下降。
對于隨機森林算法,基分類器的多樣性將決定最終分類效果,也是隨機森林泛化性能比較好的主要原因,為此本文不針對整體訓練數據集進行平衡處理,而是對隨機森林中的每一棵子樹采用混合采樣策略來構建不同的平衡訓練子集,以此提高基分類器的多樣性,從而提升分類器效果。為了保證每棵樹訓練子集的差異性,本文做兩點處理:① 引入過采樣因子,該因子采用隨機方式生成,保證每棵子樹的訓練子集大小不完全一致,但須注意該因子不能太大,以避免生成太多的新樣本;② 引入隨機欠采樣,使得每棵子樹的多數類樣本不一致。通過這兩種措施可以保證每棵子樹的訓練子集的差異性。而過采樣和欠采樣除了被本文作為數據平衡處理的手段外,同時成為保證不同子樹訓練子集差異的重要手段。
3.2 基于混合采樣策略的改進隨機森林分類算法設計
基于以上混合采樣策略,本文設計了改進隨機森林分類算法,算法流程如圖1所示。算法分為訓練階段和測試階段。在訓練階段,將原來的自助法(bootstrap)重采樣技術替換為本文提出的混合采樣策略,混合采樣策略為每棵子樹生成平衡訓練子集,然后再用該子集生成不剪枝的多棵決策樹。在測試階段,直接用訓練階段得到的各決策樹判斷測試數據的結果,最終采用投票方式確定最終分類結果。
本算法除了具有經典隨機森林算法的優點外,還具有以下特點:
1) 采用較小的過采樣因子能避免生成大量少數類樣本,使算法能適用于不平衡比例較高的場合。
2) 隨機過程采樣因子和隨機欠采樣方法的引入使得不同子樹訓練數據集不一致,進一步提升了基分類器的多樣性。
訓練和測試過程算法偽代碼如下:
輸入:1、 訓練集
S={(x1,y1),(x2,y2),…,(xm,ym)}
2、待測試樣本
3、隨機森林子樹個數Ntree
輸出:1、集成分類器H(x),測試數據結果
算法過程:
統計數據集特征:
n表示少數類樣本數量,p表示多數類樣本數量,整個訓練集數量m=n+p。
Fori= 1,2,3,…,Ntree
1) 生成平衡的訓練子集
① 隨機生成過采樣因子α
② 采用過采樣算法生成nα個少數類樣本,合并原有的n個少數類樣本,構成新的少數類樣本集合;
③ 采用隨機欠采樣算法,從p個多數類樣本里隨機采樣n(1+α)個樣本,構成新的多數類樣本集合;
④ 將步驟②和步驟③得到的樣本進行融合、混洗后得到新的平衡訓練子集Si。
2) 使用Si生成一棵不剪枝的樹Hi
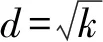
② 在每個節點從d個特征中選擇基于式(2)得到的最小基尼指數的特征作為分裂特征
(1)
其中D表示當前數據集。
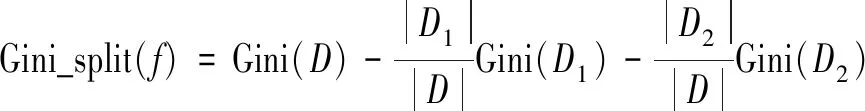
(2)
D1和D2分別表示特征f將D劃分的左右2個子集。
③ 分裂直到樹生長到最大
輸出: 子樹的集合{Hi,i=1,2,….Ntree}
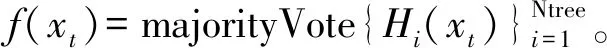
4 實驗與分析
4.1 實驗設計
本文選擇CART決策樹(CTree)、ADASYN+決策樹(ADASYNTree)、SMOTEENN+決策樹(SmoteENNTree)、EasyEnsemble、ADASYNBoost、RUSBoost、隨機森林(RF)、ADASYN +隨機森林方法(ADASYNRF)、SMOTE+RUS+隨機森林(SRRF)9種不同的不平衡數據處理模式分類算法作為本文對照算法。
其中:① CART決策樹代表了不做任何數據處理的分類器算法;② ADASYN+決策樹(ADASYNTree)代表了對于原始數據集采用某種過采樣算法得到平衡數據集,然后再將平衡數據集應用到決策樹算法,這種模式被廣泛應用,主要差別是所應用的過采樣算法不一致,本文主要選擇ADASYN作為過采樣算法;③SMOTEENN+決策樹(SmoteENNTree)主要是首先采用SMOTE進行過采樣,然后再應用EditedNearestNeighbours算法進行欠采樣,達到去除噪聲目的,這代表了對數據集進行混合采樣處理,然后再進行分類處理模式;④ EasyEnsemble代表了混合集成策略;⑤ ADASYNBoost代表了在Boosting集成迭代的過程中采用ADASYN過采樣算法進行平衡處理模式;⑥ RUSBoost表示在Boosting集成迭代的過程中采用RUS隨機欠采樣算法進行平衡處理模式;⑦ Random Forest是不做任何處理的隨機森林算法;⑧ ADASYN+隨機森林方法(ADASYNRF)代表對原始整體數據集進行平衡處理,再采用隨機森林算法進行分類處理模式;⑨ SMOTE+RUS+隨機森林(SRRF)代表對原始整體數據集進行過采樣和欠采樣混合采樣平衡處理,再應用到隨機森林分類處理模式;⑩ 在本文所提出的混合采樣策略中,過采樣采用ADASYN算法,欠采樣采用RUS算法,算法簡寫為ARIRF(ADASYN RUS Improved Random Forest)。另外,在過采樣時,用過采樣因子α來控制少數類樣本生成數量。為研究過采樣因子對分類結果的影響,本文設定α為固定值和在某個區間取隨機值兩種模式。
4.2 評價指標
對于二分類,一般使用總的準確率作為評價指標,但對于不平衡數據集的分類性能評價,總的精確率并不合適。在實際應用中,對于不平衡數據往往更關注少數類分類的準確率和召回率,故本文選擇G-mean和AUC作為衡量算法性能的評價指標。
本文假設少數類是負類,并傾向于關注負類的性能指標,負類的準確率和召回率分別表示為(各值含義參考表1混淆矩陣所列):
(3)
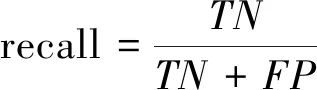
(4)
Kubat[26]提出的G-mean是一種魯棒性較好的不平衡數據分類方法的評價指標,其定義如下:

(5)
G-mean綜合表示了正類、負類召回率情況,只有二者召回率值都高時,G-mean值才會高,表明分類器性能較好。
AUC:ROC受試者工作特征曲線描述了分類器在不同判別閾值時的分類性能,在實際應用中常用ROC曲線與坐標軸圍成的區域面積AUC值表示分類器性能優劣,AUC值越大,則分類器的預測性能越好。
4.3 實驗數據集
為了評估本論文所設計算法,選擇UCI和LIBSVM中具有不同實際應用背景的13組公開數據集進行實驗,具體信息如表2所示。
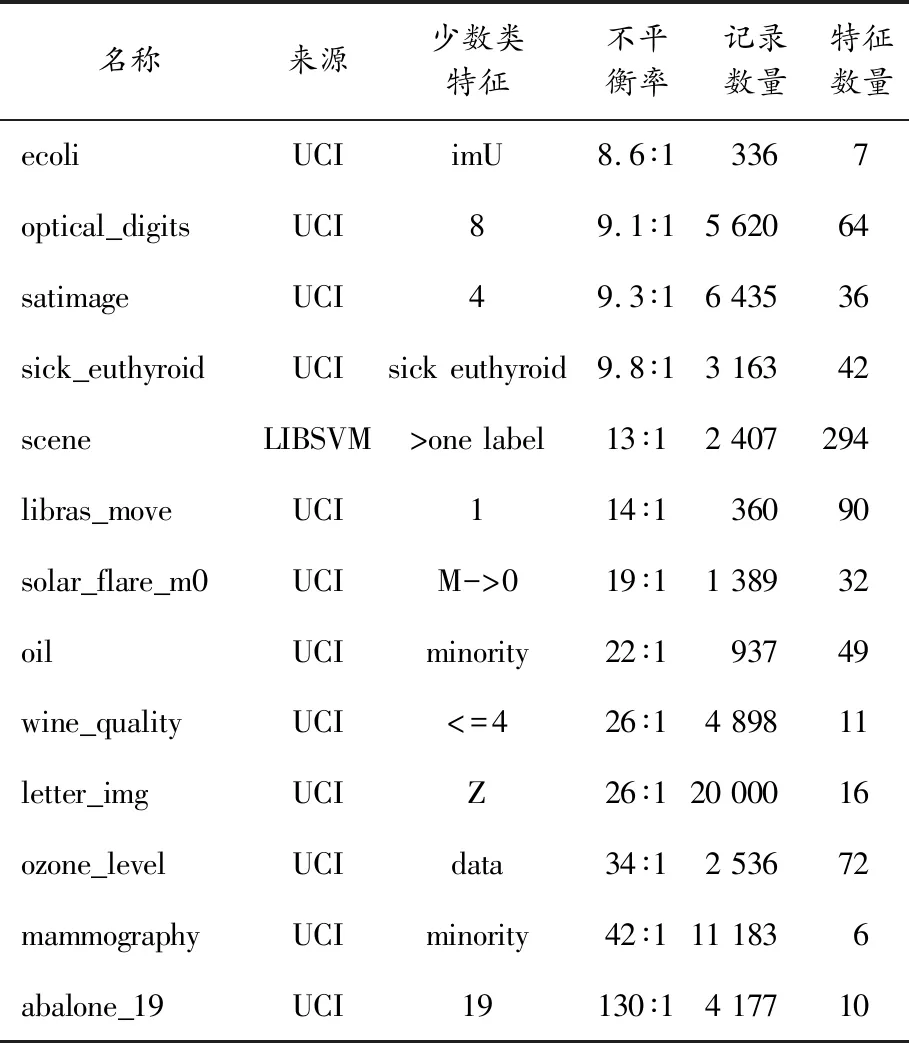
表2 實驗數據集
4.4 實驗過程與結果
為增加實驗結果的客觀性,所有實驗采用十折交叉驗證得到結果,最后用10次測試結果的平均值作為1次十折交叉驗證的結果。
4.4.1過采樣因子取固定值分類性能影響
本文主要通過過采樣因子和隨機欠采樣來保證隨機森林子樹訓練子集的差異性。為了觀察不同大小過采樣因子對分類性能的影響,實驗將所有子樹的過采樣因子都取為固定相同值,然后逐步改變過采樣因子大小,分別取值為0.2、0.5、1、1.5、2、2.5、 3、3.5、4,測試不同數據集在不同過采樣因子下的G-mean值,測試結果如圖2所示。圖2顯示:對于當過采樣因子為0.2且G-mean值為0.75左右的數據集,G-mean值隨著過采樣因子增加而減小,這說明生成樣本太多造成了數據集的過擬合;對于當過采樣因子為0.2且G-mean大于0.8的數據集,G-mean隨著過采樣因子增加雖然具有遞減趨勢,但是變動比較小,同時也出現了libras_move數據集在過采樣因子取值為3.5時 G-mean值變大的情況。
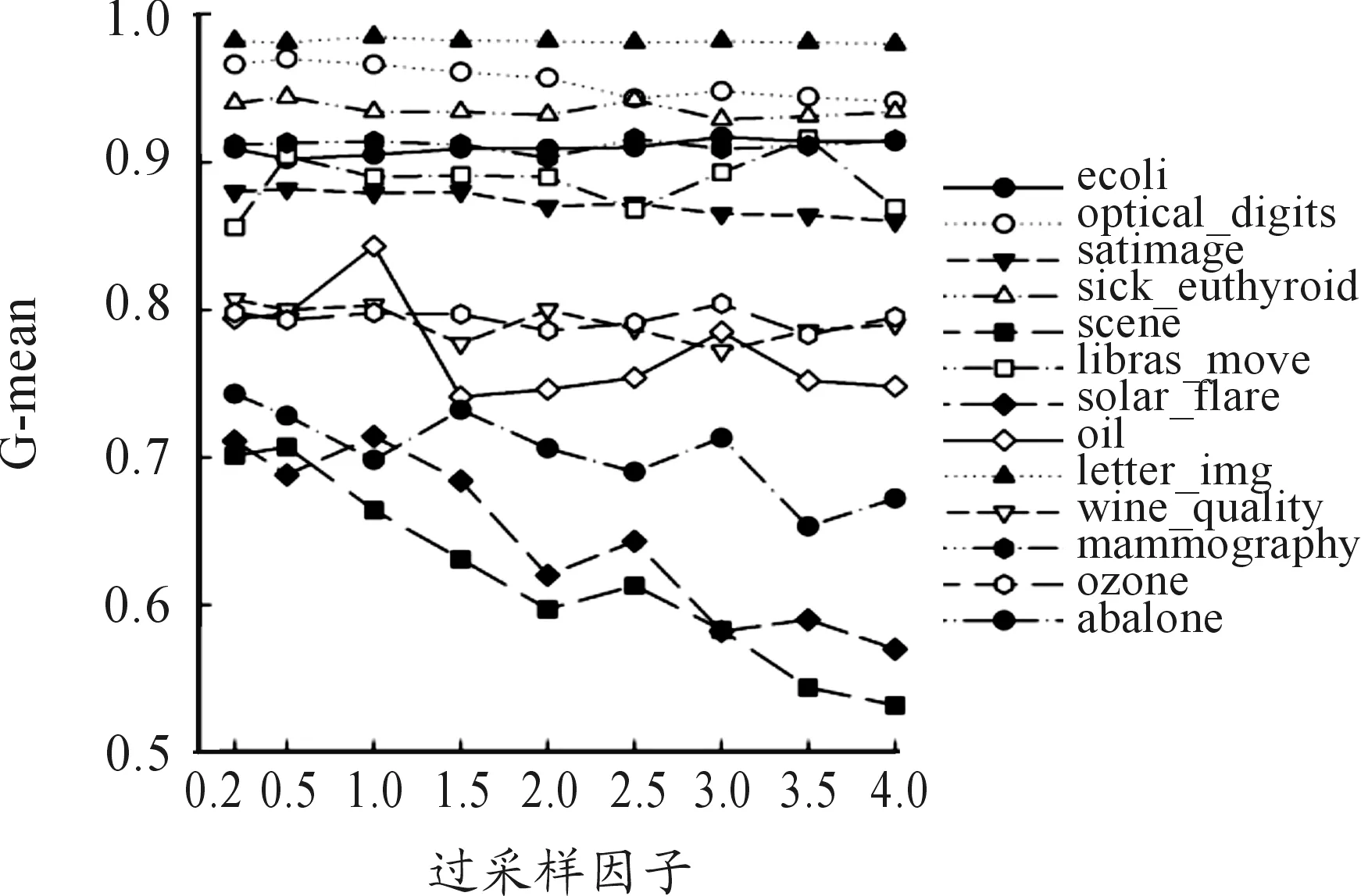
圖2 過采樣因子取固定值分類性能
以上結果表明:不同數據集對過采樣因子的敏感性不一樣,多數數據集對應的G-mean值隨過采樣因子增大而減小,但是也有少數數據集對應的G-mean值隨過采樣因子增大出現增大或者減小的不規則變化趨勢。圖2中“letter_img”數據集對應的G-mean值比較大,隨過采樣因子增大而變化不大。圖2中“scene”數據集對應的G-mean值較小,對過采樣因子敏感,隨過采樣因子增大而明顯變小。圖2中“libras_move”數據集對應的G-mean值對過采樣因子的變化則呈現不規則變化趨勢。造成這種現象的原因是這3個數據集的數據分布不一致,代表了3種典型的數據分布情況,3個數據集的二維分布如圖3所示。從圖3(a)表示的letter_img數據二維分布情況可以發現:正類和負類邊界非常明顯,這種數據集的可分類性好,G-mean值高,達到0.98(見表3),當過采樣時新生成的負樣本也都是標準負樣本,因此過采樣因子增加時G-mean值變化不大。圖3(b)表示的scene數據集數據二維分布是一種典型的正類和負類數據重疊情況[12],在這種分布情況下數據集的G-mean值比較低,當過采樣時新生成的負樣本難以保證屬于標準負樣本,因此過采樣因子越大則出錯概率越大,故G-mean值隨過采樣因子增大而減小。圖3(c)表示的libras_move數據集的數據二維分布中負類樣本呈現多個小的分離項[12]。這種分布數據集情況較為復雜,圖3(c)的1、2號圈中的負樣本與正樣本重疊較少,而3、4號圈中負樣本與正樣本重疊較多,因此當過采樣時,如果依據1號圈的負樣本來生成新負樣本,則新生成的負樣本基本為標準負樣本,有助于減小整體數據集的不平衡性,此時G-mean值會增加,但是如果依據4號圈的負樣本來生成新負樣本,則新生成的負樣本可能出錯概率較大,此時G-mean值會減少。故當過采樣因子增加時,需要采樣的樣本較多,G-mean值的變化則呈現不規則變化趨勢。假如過采樣時都選擇1號圈,則G-mean值增加明顯。因此,對于這種不規則變化的數據集可以通過參數調整來選擇最優的過采樣因子。
4.4.2過采樣因子取隨機值分類性能影響(大范圍)
本小節實驗主要測試不同子樹取不同過采樣因子的情況,取值方式是在一定范圍內取隨機值。實驗測試了取值范圍從0.5~0.8到0.5~2.9的變化情況,實驗測試結果如圖4所示。圖4(b)放大顯示了G-mean值大于0.85時的數據集測試結果。從圖4(a)可以發現:過采樣因子取值范圍越大,過采樣因子的值就可能越大,G-mean值整體有遞減趨勢,特別對于G-mean值小于0.8的情況。這是因為G-mean值比較小,說明該數據集的少數類噪聲比較多,比較難以區分,如果過采樣因子變大,則生成的樣本屬于噪聲的可能性更大,導致分類出錯。而當G-mean值比較大,則說明該數據集可分性比較好,生成的少數類樣本同樣具有較好的可分性,因此過采樣因子對G-mean值影響不大。圖4(b)進一步顯示:對于libras_move數據集,當過采樣因子變化時,G-mean值呈現不規則變化,對于此類的數據集則需要進行參數調優。
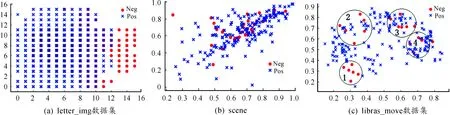
圖3 3個數據集的二維分布圖

圖4 過采樣因子取一定范圍內隨機值時的分類性能(大范圍)(部分)
4.4.3過采樣因子取隨機值分類性能影響(小范圍)
本小節實驗測試了當過采樣因子取隨機值,但取值范圍在小范圍內變化時的情況,其中取值范圍分別是0.2~0.5,0.5~0.8,0.8~1.1,1.1~1.4。實驗測試結果如圖5所示。
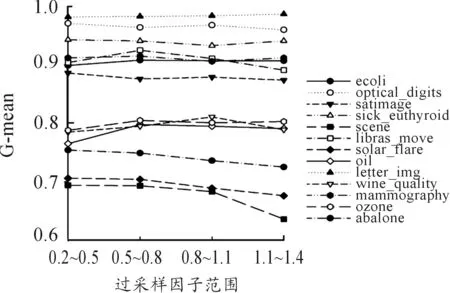
圖5 過采樣因子取一定范圍內隨機值時的分類性能(小范圍)
結果表明:scene對過采樣因子最為敏感,除了scene、solar_flare、mammography三個數據集外,其他數據集特別是對于G-mean值在0.9以上的數據集,在不同的過采樣因子范圍變化時G-mean值變化比較小。對比圖4和圖5,可以發現過采樣因子在小范圍內變化,且取值較小時有利于保證結果的穩定性。
4.4.4不同算法實驗結果比較
通過以上實驗結果可以發現:過采樣生成樣本容易導致分類算法過擬合,特別是當數據集可分性較差時,過擬合現象越來越嚴重。選擇較小的過采樣因子或者采用較小的過采樣因子范圍有助于得到較為穩定的分類算法。同時,考慮到不同數據分布的數據集對過采樣因子的敏感性不一致,因此本文采用過采樣因子為0.2,以及0.2~0.5、0.5~0.8的分類算法與其他分類算法進行比較。表3展示了13個數據集下9種對比算法和本文算法在不同參數下的G-mean值結果。結果表明:當過采樣因子參數最佳時(ARIRF_max),本文算法在13個數據集中的9個數據集取得最優結果,在3個數據集上取得第2名的結果。表4展示了AUC的評測結果,結果表明:當過采樣因子參數最佳時,本文提出的算法在13個數據集中有10個取得最優結果,在2個數據集上取得第2名的結果。以上結果說明,本文提出的算法相比傳統的分類算法可獲得更好的分類性能。
由于與其他研究者所采用的數據集不完全一致,因此難以直接與一些最新的研究成果對比。王莉等[27]提出的NIBoost算法結合代價敏感和過采樣技術,使得最終訓練出來的強分類器對不平衡數據集有較好分類性能,在與本文一致的ecoli數據集上,NIBoost算法得到的AUC值為0.888 8,但是本文提出的算法可以達到0.912,較NIBoost算法提升達2.61%。

表3 G-mean實驗結果

表4 AUC實驗結果
表3、4同時表明:CTree 在letter_imgs和optical_digits數據集上取得了較好的結果,但是該算法在scene、oil、abalone_19又取得了最差的結果,這說明了該算法非常不穩定。而另外兩個對比算法RUSBoost和EasyEnsemble表現出較為穩定的結果,特別在oil數據集上分別取得最優結果和次優的結果。Galar[11]指出RUSBoost在其測試的眾多集成算法里雖然最簡單,但取得的效果最好。而本文提出的算法則相對于RUSBoost有全面的提升,比如在libras_move數據集上,RUSBoost的AUC值為0.87,而本文提出的算法AUC值為0.929,提升達6.78%。在abalone_19數據集上,本文提出的算法在AUC性能上也提升達6.42%,僅在oil和ozone_level數據集上劣于RUSBoost算法。
5 結論
為提高不平衡數據的分類算法性能,本文從數據分布入手,基于隨機森林算法,提出了過采樣與欠采樣的混合采樣策略。在多個數據集上進行實驗,取得以下結論:
1)本文提出的算法采用較小的過采樣因子同樣可以取得較好的分類效果,有利于將該算法應用于不平衡比例較大的數據集。
2)與9種對照算法相比,本文提出的算法在對比AUC值時獲得10個最優結果,在對比Gmean值時獲得9個最優結果。
本文算法優于RUSBoost說明了過采樣的必要性,但是如何在不引入噪聲的情況下生成真正的少數類樣本仍是一個難點問題。目前生成的對抗網絡在圖像生成領域取得巨大成功,因此在后期可以嘗試將生成對抗網絡引入到不平衡數據集的少數類樣本生成中,提高生成樣本質量。其次,在大數據時代,對于高維大規模不平衡數據集如何提高其分類性能目前研究不多,這也將是后期的一個主要研究方向。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
