基于稀疏自編碼器-支持向量機(jī)的空調(diào)制冷系統(tǒng)故障診斷
2019-08-14 03:06:18王志毅鐘加晨夏翠李靜凡
制冷技術(shù) 2019年3期
王志毅,鐘加晨,夏翠,李靜凡
(浙江理工大學(xué)建筑工程學(xué)院,浙江杭州 310018)
0 引言
隨著社會的發(fā)展,建筑能耗逐年增加,其中空調(diào)系統(tǒng)能耗約占建筑總能耗的40%~50%[1]。空調(diào)制冷系統(tǒng)長時間運行后不可避免地會出現(xiàn)故障,這些故障導(dǎo)致設(shè)備能耗的增加。在系統(tǒng)出現(xiàn)運行故障之前進(jìn)行故障診斷,可以節(jié)省能源,降低停機(jī)成本,具有一定的現(xiàn)實意義[2-3]。空調(diào)制冷系統(tǒng)通常發(fā)生的故障具有如下特點:不確定性、延時性、相關(guān)性、層次性以及復(fù)雜性。系統(tǒng)常見故障包括制冷劑過少、制冷劑過多、潤滑油過多、蒸發(fā)側(cè)水流量不足、冷凝側(cè)結(jié)垢、有非凝性氣體以及冷凝器水流量不足等。
系統(tǒng)故障診斷方法包括基于物理模型的方法和基于數(shù)據(jù)的方法。基于物理模型的方法需要建立系統(tǒng)正常運行的定量物理模型或是定性物理模型,根據(jù)參考模型的預(yù)測值與實測值的偏差來進(jìn)行故障的分析與診斷。例如參數(shù)估計法等定量物理模型,符號有向圖、專家系統(tǒng)、故障樹等定性物理模型。基于數(shù)據(jù)的方法不需要構(gòu)建準(zhǔn)確的物理模型,但需要構(gòu)建灰箱或黑箱模型。灰箱模型例如灰色理論中的關(guān)聯(lián)分析和聚類分析。黑箱模型包括人工神經(jīng)網(wǎng)絡(luò)等模式識別方法、貝葉斯網(wǎng)絡(luò)等統(tǒng)計學(xué)方法、小波分析等信號處理方法。模式識別方法的診斷思路一般分為3部分:數(shù)據(jù)采集、特征提取和分類器判斷。數(shù)據(jù)采集是指用數(shù)據(jù)采集設(shè)備對溫度、壓力、流量等物理量進(jìn)行采集。考慮到制冷機(jī)組故障現(xiàn)場數(shù)據(jù)采集的全面性和經(jīng)濟(jì)性,通常采用ASHRAE 1043-RP制冷機(jī)組故障模擬實驗提供的數(shù)據(jù)進(jìn)行研究。特征提取方法包括遺傳算法[4]、多尺度主元分析[5]、互信息[6]、內(nèi)蘊(yùn)模式函數(shù)[7]、順序向前選擇算法[8]以及粒子群算法[9]等。分類器判斷方法包括樸素貝葉斯模型[10]、支持向量機(jī)[11]、K最鄰近分類算法[12]、隨機(jī)森林[13]以及神經(jīng)網(wǎng)絡(luò)[14]等。
深度學(xué)習(xí)是機(jī)器學(xué)習(xí)中一種新興的學(xué)習(xí)方法,近年來被人們在學(xué)術(shù)界以及工業(yè)界深入研究。深度學(xué)習(xí)通過模擬人腦的深度框架在文本處理、語音識別及計算機(jī)視覺等方面應(yīng)用廣泛,在復(fù)雜工業(yè)系統(tǒng)的特征提取方面也有著一定的應(yīng)用潛力[15]。主流的深度學(xué)習(xí)框架包括玻爾茲曼機(jī)[16]、自編碼器以及卷積神經(jīng)網(wǎng)絡(luò)[17]。本文利用稀疏自編碼器構(gòu)建特征學(xué)習(xí)模型,對樣本數(shù)據(jù)進(jìn)行重構(gòu),然后在支持向量機(jī)中進(jìn)行故障診斷,改善空調(diào)制冷系統(tǒng)由于多參數(shù)間復(fù)雜的耦合性引起的診斷困難等問題。通過優(yōu)化稀疏自編碼器的隱藏層層數(shù)和節(jié)點數(shù),能夠自動尋找到較好表達(dá)原始樣本數(shù)據(jù)的特征。采用稀疏自編碼器有效提取的信息作為支持向量機(jī)的輸入向量,提高了故障診斷效率,在空調(diào)制冷系統(tǒng)故障診斷領(lǐng)域顯示出一定的應(yīng)用潛力。
1 基本原理
1.1 自編碼器
自編碼器是一種人工神經(jīng)網(wǎng)絡(luò),以無監(jiān)督的方法學(xué)習(xí)有效的數(shù)據(jù)編碼。自編碼器的原理如圖1所示,包括輸入層、隱藏層和輸出層。隱藏層相當(dāng)于一個編碼器和解碼器,數(shù)據(jù)通過輸入層進(jìn)入隱藏層,在隱藏層中進(jìn)行編碼和解碼,最后由輸出層輸出。隱藏層的作用是盡可能確保輸出的數(shù)據(jù)和輸入的數(shù)據(jù)一致。隱藏層盡量用少的維度來提取輸入數(shù)據(jù)中有用的主要特征,同時要降低編碼前數(shù)據(jù)和解碼前數(shù)據(jù)之間的重構(gòu)誤差。自編碼器的重構(gòu)誤差如圖2所示。

圖1 自編碼器的原理

圖2 自編碼器的重構(gòu)誤差
1.2 稀疏自編碼器
自編碼器中僅通過隱藏層簡單的數(shù)據(jù)表達(dá)難以達(dá)到理想的效果,同時缺乏實際意義。稀疏自編碼器由此被提出,在編碼過程中引入稀疏約束,限制隱藏層的數(shù)據(jù)表達(dá),強(qiáng)迫神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)對輸入量進(jìn)行降維表示。將稀疏懲罰項引入目標(biāo)函數(shù)中,以此僅允許個別神經(jīng)節(jié)點被激活,例如當(dāng)神經(jīng)節(jié)點偏離1時,節(jié)點不被激活。當(dāng)隱藏層節(jié)點數(shù)大于輸入層節(jié)點數(shù)時,被激活的節(jié)點數(shù)仍可能低于輸入層節(jié)點數(shù),此時達(dá)到了簡化數(shù)據(jù)和降維表示的目的。稀疏自編碼器訓(xùn)練如圖3所示。
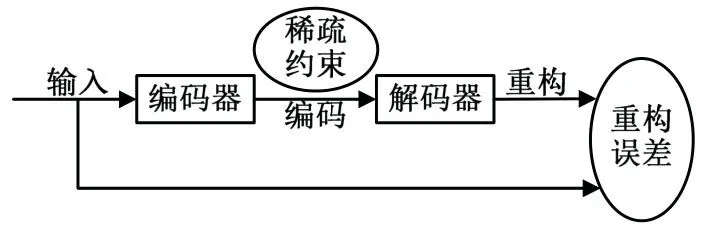
圖3 稀疏自編碼器訓(xùn)練
1.3 支持向量機(jī)
支持向量機(jī)是一種機(jī)器學(xué)習(xí)算法,能夠?qū)?shù)據(jù)進(jìn)行二元分類。對于數(shù)據(jù)線性可分的情況,通過邊距最大化來尋找最優(yōu)分類平面。支持向量機(jī)的最大邊緣構(gòu)造如圖4所示。對于線性不可分的情況,通過降噪忽略異常值或者是引入核函數(shù)將低維輸入空間轉(zhuǎn)換為高維輸入空間,線性不可分問題由此轉(zhuǎn)化為可分問題。支持向量機(jī)在非線性分類問題上有特定的優(yōu)勢,但泛化能力取決于核函數(shù)的優(yōu)化[18]。

圖4 支持向量機(jī)的最大邊緣構(gòu)造
2 數(shù)據(jù)來源及評價指標(biāo)
2.1 數(shù)據(jù)來源
ASHRAE項目1043-RP提供了全面的離心式冷水機(jī)組故障檢測與診斷研究的實驗數(shù)據(jù),其研究對象是一臺制冷量為90冷噸的離心式冷水機(jī)組。通過實驗研究生成數(shù)據(jù)庫,并將數(shù)據(jù)庫用于開發(fā)和評估冷水機(jī)組故障檢測和診斷方法。實驗平臺包括3個主要環(huán)路(制冷劑、冷凍水和冷卻水環(huán)路)和3個輔助環(huán)路(熱水、自來水和蒸汽環(huán)路)。通過調(diào)節(jié)機(jī)組運行容量、冷凍水出水溫度和冷凝水進(jìn)水溫度,實驗平臺能夠模擬27種典型工況;通過傳感器,實驗平臺能夠直接采集溫度、壓力、流量、閥位等48個參數(shù);通過專用軟件VisSim,實驗平臺能夠間接得到冷量、熱量等16個參數(shù)。通過調(diào)節(jié)系統(tǒng)中的相關(guān)設(shè)備,實驗平臺能夠模擬7種典型故障,每種故障設(shè)有4種故障程度。7種典型故障如表1所示,出現(xiàn)總頻率約占40%。4種故障程度分別命名為A、B、C和D,嚴(yán)重程度依次遞增。
2.2 評價指標(biāo)
采用機(jī)器學(xué)習(xí)方法解決某個二元分類問題時,通常采用準(zhǔn)確率來對比不同模型間的性能。準(zhǔn)確率即為正確分類總數(shù)目除以總樣本數(shù),其計算公式如式1所示。考慮到冷水機(jī)組故障間的誤報(誤診)、有故障被視為無故障(漏診)以及無故障卻被診斷為有故障(虛警)等情況,僅僅依靠準(zhǔn)確率評價模型的優(yōu)劣是不夠全面的。召回率和精確率由此提出。召回率可以反映系統(tǒng)的漏診情況,召回率越高,漏診率越低,計算公式如式2所示。精確度可以反映系統(tǒng)的虛警情況,精確度越高,虛警率越低,計算公式如式3所示。根據(jù)定義,召回率和精確率之間是相互影響的。一般來說,召回率較高時,精確率較低;精確率較高時,召回率較低。當(dāng)召回率和精確率都較低時,說明存在較大的問題。當(dāng)召回率和精確率都較高時,為了綜合考慮召回率和精確率,綜合評價指標(biāo)由此提出,計算公式如式(4)所示。

式中:
Q——準(zhǔn)確率;
R——召回率;
P——精確率;
F——綜合評價指標(biāo);
|TP|——實際為正類且被劃分為正類的個數(shù);
|TN|——實際為負(fù)類且被劃分為負(fù)類的個數(shù);
|FP|——實際為負(fù)類但被劃分為正類的個數(shù);
|FN|——實際為正類但被劃分為負(fù)類的個數(shù)。

表1 7種典型故障
3 基于稀疏自編碼器的故障診斷
3.1 不同隱藏層節(jié)點數(shù)對模型診斷準(zhǔn)確率的影響
先對數(shù)據(jù)庫中的數(shù)據(jù)進(jìn)行預(yù)處理,剔除無關(guān)變量。其中,測量時間與機(jī)組故障分類無關(guān),機(jī)組狀態(tài)及熱水閥狀態(tài)數(shù)據(jù)對于穩(wěn)態(tài)樣本而言均相同,故將其刪除,選取61個變量參數(shù)進(jìn)行建模。再從數(shù)據(jù)庫中隨機(jī)抽取A、B、C和D這4種故障程度數(shù)據(jù)為50,000組的實驗數(shù)據(jù),總計200,000組。隨機(jī)抽取潤滑油過多、故障程度為A的5,000組數(shù)據(jù),作為稀疏自編碼器和支持向量機(jī)的訓(xùn)練和測試數(shù)據(jù)。
稀疏自編碼器采取最簡單的3層神經(jīng)網(wǎng)絡(luò),對隱藏層節(jié)點數(shù)進(jìn)行調(diào)整,分別選取30、70、150、300、400、500、700和1,000進(jìn)行實驗。將稀疏自編碼器提取的特征輸入支持向量機(jī)進(jìn)行訓(xùn)練測試。隱藏層節(jié)點數(shù)與模型準(zhǔn)確率的關(guān)系如圖5所示。可知隨著隱藏層節(jié)點數(shù)的增加,模型診斷的準(zhǔn)確率也不斷提高。當(dāng)隱藏層節(jié)點數(shù)較小時,如低于輸入層節(jié)點數(shù),診斷準(zhǔn)確率較低。當(dāng)隱藏層節(jié)點數(shù)為700時,3層稀疏自編碼器的診斷準(zhǔn)確率達(dá)到最高,為95.47%。

圖5 隱藏層節(jié)點數(shù)與準(zhǔn)確率的關(guān)系
3.2 不同訓(xùn)練樣本數(shù)對模型診斷準(zhǔn)確率的影響
針對潤滑油過多、故障程度為A的數(shù)據(jù),稀疏自編碼器模型采取3層神經(jīng)網(wǎng)絡(luò),隱藏層節(jié)點數(shù)選取700。訓(xùn)練樣本數(shù)分別取1,700、5,000、10,000和20,000,研究了不同訓(xùn)練樣本數(shù)對模型診斷率的影響,訓(xùn)練樣本數(shù)與準(zhǔn)確率的關(guān)系如圖6所示。由圖6可以看出,隨著訓(xùn)練樣本數(shù)的增加,準(zhǔn)確率也增加,但增加的幅度并不明顯。當(dāng)樣本數(shù)為20,000時,準(zhǔn)確率為96.12%;當(dāng)樣本數(shù)為1,700時,準(zhǔn)確率就有95.41%。可見針對少量的數(shù)據(jù)規(guī)模,稀疏自編碼器提取的特征性能較優(yōu),反映為對數(shù)據(jù)要求不高,并具有較好的診斷效果。
3.3 不同稀疏自編碼器結(jié)構(gòu)對模型診斷準(zhǔn)確率的影響
從數(shù)據(jù)庫中隨機(jī)提取每種故障程度為5,000組的實驗數(shù)據(jù),調(diào)整隱藏層層數(shù)(分別取1、2、3、4和5),在A、B、C和D等4種故障程度下測試不同稀疏自編碼器的準(zhǔn)確率。對于層數(shù)相同的稀疏自編碼器,繼續(xù)調(diào)整每層的節(jié)點數(shù),進(jìn)行對比分析,結(jié)果如表2所示。2(500-400)表示隱藏層層數(shù)為2,每層節(jié)點數(shù)分別為500和400。由表3分析可得:隨著稀疏自編碼器隱藏層層數(shù)的增加,模型準(zhǔn)確率先增加后減小。當(dāng)隱藏層層數(shù)為4時,模型準(zhǔn)確率最高,此時每層的節(jié)點數(shù)分別為600、500、400和300。伴隨著稀疏自編碼器層數(shù)的增加,提取特征信息的維度也增加,有利于模型故障敏感度的提高。當(dāng)隱藏層層數(shù)大于4,過多的特征信息之間會形成干擾,使診斷性能下降。

圖6 訓(xùn)練樣本數(shù)與準(zhǔn)確率的關(guān)系

表2 不同稀疏自編碼器結(jié)構(gòu)下的模型準(zhǔn)確率
3.4 主元分析與稀疏自編碼器的對比
從數(shù)據(jù)庫中隨機(jī)提取每種故障程度為14,000組的實驗數(shù)據(jù),將其作為主元分析模型和稀疏自編碼器模型的原始樣本,分別計算不同故障程度下兩種模型的準(zhǔn)確率,如圖7所示。可以看出,主元分析模型和稀疏自編碼器模型的故障診斷準(zhǔn)確率隨著故障程度的加深而提高,這是因為故障程度越深即偏離正常參數(shù)的距離越大,模型就越容易發(fā)現(xiàn)故障。但在故障程度為A的條件下,主元分析模型的準(zhǔn)確率為93.50%,稀疏自編碼器模型的準(zhǔn)確率為96.10%,高了2.6%。說明針對程度較低的故障,稀疏自編碼器具有更高的故障靈敏度,能更及時發(fā)現(xiàn)故障,減少損失。綜合而言,稀疏自編碼器對于不同故障程度的數(shù)據(jù),其提取特征的效果優(yōu)于主元分析,表現(xiàn)為故障識別準(zhǔn)確率更高。
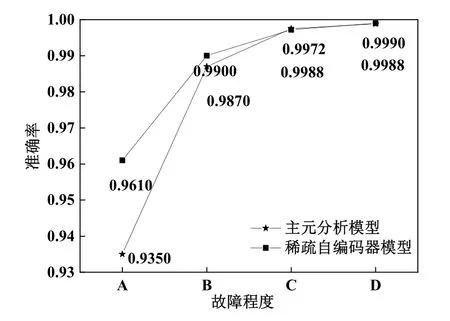
圖7 主元分析和稀疏自編碼器模型準(zhǔn)確率的對比
3.5 不同模型對不同故障類別的評判
建立支持向量機(jī)模型,記為M1;建立單層稀疏自編碼器和多層稀疏自編碼器模型,分別記為M2和M3,并將支持向量機(jī)作為分類器。對于7種典型的故障,3種模型的診斷準(zhǔn)確率如圖8所示。
由圖8可知,多層稀疏自編碼器模型診斷準(zhǔn)確率最高,單層稀疏自編碼器模型診斷準(zhǔn)確率次之,支持向量機(jī)模型準(zhǔn)確率最低。尤其是對于制冷劑過少故障,稀疏自編碼器模型的準(zhǔn)確率提高了1.2%。3種模型在各種故障下的綜合評價指標(biāo)如表3所示。
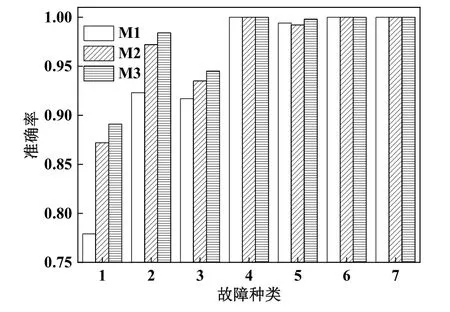
圖8 7種典型故障下的模型診斷準(zhǔn)確率

表3 7種典型故障下的綜合評判指標(biāo)
由表3可知,制冷劑和潤滑油相關(guān)的系統(tǒng)故障的綜合指標(biāo)較低,蒸發(fā)器側(cè)、冷凝器側(cè)以及不凝性氣體等局部故障的綜合指標(biāo)較高。尤其是針對水流量不足的故障,3種模型的準(zhǔn)確率均為1,這是由于閥門和水流量相關(guān)參數(shù)表征效果強(qiáng),可反映故障特征。制冷劑和潤滑油的故障涉及整個空調(diào)制冷系統(tǒng),影響因素很多,診斷難度比局部故障大得多[19-20]。對于制冷劑過少的故障,稀疏自編碼器模型的各項指標(biāo)均有提高,診斷效果最好。相比單層稀疏自編碼器,多層稀疏自編碼器提取故障特征的能力更強(qiáng),診斷性能更優(yōu)。
4 結(jié)論
本文提出一種基于稀疏自編碼器-支持向量機(jī)的空調(diào)制冷系統(tǒng)故障診斷方法,研究了在空調(diào)制冷系統(tǒng)故障診斷領(lǐng)域的應(yīng)用潛力,得到如下結(jié)論:
1)訓(xùn)練樣本數(shù)對稀疏自編碼器模型的影響較小,針對少量的數(shù)據(jù)規(guī)模,模型有較高的診斷準(zhǔn)確率。隱藏層層數(shù)和節(jié)點數(shù)對稀疏自編碼器模型的影響較大,本系統(tǒng)中隱藏層層數(shù)為4,節(jié)點數(shù)分別為600、500、400和300的多層稀疏自編碼器模型診斷性能最優(yōu);
2)對于單層稀疏自編碼器模型,當(dāng)隱藏層節(jié)點數(shù)為700時,故障診斷準(zhǔn)確率達(dá)到最高,為95.47%;對于制冷劑過少的故障,在故障程度最低的情況下,主元分析模型的準(zhǔn)確率為93.50%,稀疏自編碼器模型的準(zhǔn)確率為96.10%,提高了2.6%;稀疏自編碼器模型具有更高的故障靈敏度,能更及時地發(fā)現(xiàn)故障,減少損失;
3)相比于直接用原始數(shù)據(jù)進(jìn)行支持向量機(jī)方法的故障診斷,經(jīng)稀疏自編碼器提取故障特征,降低參數(shù)間相關(guān)性后的診斷方法精確度、召回率以及綜合評價指標(biāo)均有提高,表現(xiàn)為誤診、漏診和虛警等情況明顯減少;相比于單層稀疏自編碼器,多層稀疏自編碼器提取故障特征的能力更強(qiáng),診斷性能更優(yōu)。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
汽車維護(hù)與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學(xué)學(xué)報(自然科學(xué)版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(yǎng)(2015年6期)2015-04-17 03:31:50
汽車維護(hù)與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
