基于Faster R-CNN的田間西蘭花幼苗圖像檢測方法
2019-08-13 01:42:30張春龍葛魯鎮譚豫之
農業機械學報 2019年7期
孫 哲 張春龍 葛魯鎮 張 銘 李 偉 譚豫之
(中國農業大學工學院, 北京 100083)
0 引言
中國是西蘭花生產大國,總產量約150萬t,占全球7%左右,隨著種植面積的不斷擴大,西蘭花除草工作量逐年增大[1-2]。目前,我國除草作業主要采用化學除草與人工除草,在食品安全意識與勞動力成本提高的背景下[3],發展智能除草裝備具有廣闊的應用前景[4-6]。作為智能除草裝備的核心技術之一[7],快速精準的作物識別是影響除草質量的關鍵因素。
近年來,科研工作者對自然環境下作物識別進行了深入研究[8-13]。陳樹人等[14]提出基于顏色特征的棉花與雜草識別技術,采用R分量與B分量的標準差小于5作為判斷苗草的閾值,對棉花識別的總體準確率為82.1%。HERRMANN等[15]利用高光譜成像技術獲取麥田圖像,并設計基于最小二乘法的分類器,分割小麥與雜草,對田間作物的分類準確率為72%。GARCIA等[16]在分割植物與土壤背景后,利用Otsu自動閾值分割法區分作物和雜草,該方法對作物的正確識別率為86.3%。張志斌等[17]研究了基于快速SURF特征的提取算法,該方法中立體視覺系統的左、右目作物圖像正確匹配率分別為94.8%和92.4%。NIEUWENHUIZEN等[18]結合顏色與紋理特征,采用自適應貝葉斯分類器進行分類,該方法對固定光照和變化光照條件下甜菜的正確分類率分別為89.8%和67.7%。
上述傳統識別方法主要根據經驗,易受小樣本和人為主觀因素影響[19],無法找到通用特征模型,魯棒性不強,很難用一種方法對復雜田間環境下的作物進行有效識別。相比傳統方法,深度學習采用數據本身特征進行自我學習,對圖像具有極強的表征能力,可以克服傳統方法的不足。彭紅星等[20]利用改進SSD模型,對自然環境下的荔枝、皇帝柑、臍橙和蘋果進行檢測,平均檢測精度為89.53%。周云成等[21]提出一種基于深度卷積神經網絡的番茄器官分類識別方法,分類錯誤率低于6.39%。
基于深度學習準確度高、普適性強的特點,本文采用Faster R-CNN[22]模型對自然環境下的西蘭花幼苗進行識別。依據田間環境下西蘭花幼苗圖像特點,優化特征提取網絡與超參數,建立一種基于深度卷積神經網絡的西蘭花幼苗圖像識別模型。
1 數據材料
1.1 數據采集
試驗圖像于2018年4—5月采集自北京國際都市農業科技園,采集設備為Canon SX730 HS型相機,圖像分辨率為1 600像素×1 200像素,共采集圖像樣本6 230幅。為保證圖像樣本的多樣性,針對3塊不同播種時間的試驗田,分別采集西蘭花幼苗除草期的作物圖像。圖像樣本包含不同光照強度、不同地面含水率和不同雜草密度等情況,部分樣本示例如圖1所示。

圖1 部分樣本示例Fig.1 Examples of sample diversity
1.2 數據集建立
圖像采集過程中雖然已考慮樣本所處環境的多樣性,但西蘭花幼苗葉和莖的生長以及成像角度具有隨機性,因此本文采用圖像旋轉0°、90°、180°和270°的方法進行數據增強,將總樣本數擴大至4倍,提高訓練模型的泛化能力。受樣本集規模與訓練次數的影響,深度卷積神經網絡會對圖像樣本的高頻特征進行學習,導致過擬合的出現。本文在圖像樣本上添加零均值特性的高斯噪聲,使圖像樣本在所有頻率上都產生數據點,可有效抑制高頻特征,減小其對模型的影響。
將整體樣本按照PASCAL VOC數據集格式進行劃分,試驗樣本數據集包括訓練集圖像17 440幅,測試集圖像7 480幅,總樣本數為24 920。訓練集從整體樣本中隨機選出,且與測試集互斥。為保證所得模型的可靠與穩定,訓練過程中將訓練集平均劃分為n份,每次選取n-1份作為訓練集,另外1份作為驗證集,驗證集上n次誤差的平均值作為該模型的誤差,最后采用測試集評估模型的泛化能力。
2 檢測方法
2.1 Faster R-CNN模型框架
Faster R-CNN模型是對R-CNN[23]和Fast R-CNN[24]的改進,通過卷積神經網絡提取候選框,同時加入多任務學習,使得網絡訓練過程中能夠同時獲得物體所屬類別和位置。基于Faster R-CNN的西蘭花幼苗檢測步驟如下:
(1)利用特征提取網絡提取圖像的特征圖,該特征圖被后續候選區域(RPN)網絡與Fast R-CNN網絡共享。
(2)RPN網絡通過Softmax分類器執行二分類任務,判斷錨點(anchors)屬于前景還是背景,并通過錨點回歸得到候選框位置。
(3)Fast R-CNN綜合特征圖與候選框信息,判別前景所屬類別,并生成最終檢測框的精確位置。
Faster R-CNN模型結構如圖2所示,Faster R-CNN用RPN網絡代替Fast R-CNN中Selective Search方法實現候選框的提取,提高了檢測的精度與速度。

圖2 Faster R-CNN模型結構Fig.2 Faster R-CNN architecture
2.2 RPN網絡
使用RPN網絡提取候選框,使Faster R-CNN實現了端到端的物體檢測。RPN網絡是一個全卷積網絡,在特征圖傳入RPN后,使用3×3的滑窗生成一個n維長度的特征向量,然后將此特征向量分別傳入分類層與回歸層。在分類層中,使用Softmax分類器對錨點進行前景與背景的判斷。在回歸層中,通過調整錨點邊框的中心坐標與長寬,擬合出候選框位置。在訓練過程中,RPN網絡的損失函數[22]、分類層損失函數[22]與回歸層損失函數[24]如下
(1)
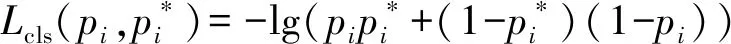
(2)
(3)
(4)
(5)
式中L——RPN網絡損失
Lcls——分類層損失
Lreg——回歸層損失
i——錨點索引
ti——預測邊界框坐標向量

Ncls——分類樣本數
Nreg——回歸樣本數
pi——目標的預測概率

λ——權重參數
smoothL1——平滑函數
2.3 特征共享
RPN與Fast R-CNN為兩個獨立的網絡,分別進行單獨訓練無法獲得收斂結果。本文采用交替訓練方法對網絡進行訓練。首先采用ImageNet的預訓練模型對RPN網絡中的卷積層進行參數初始化,獲得圖像通用特征,并生成候選區域框。其次,利用RPN網絡輸出的候選框對Fast R-CNN進行訓練。然后,用Fast R-CNN卷積層參數訓練RPN網絡,僅更新RPN中特有網絡層參數。最后固定共享卷積層,微調Fast R-CNN的全連接層,將RPN與Fast R-CNN統一起來,實現兩個網絡共享相同的卷積層。
3 試驗設計與結果分析
3.1 試驗平臺
試驗處理平臺為臺式計算機,處理器為Intel Core i7-8700k,主頻3.7 GHz, 16 GB內存,500 GB固態硬盤, GPU采用NVIDIA 1080Ti,運行環境為Windows 10(64位)系統,Python 3.5.4,Tensorflow 1.8.0,CUDA 9.0.176版并行計算架構與cuDNN 9.0版深層神經網絡庫。
3.2 試驗評價指標
采用平均精度(Average precision)作為目標檢測的評價指標。平均精度與精確率、召回率有關,精確率和召回率的計算方法為
(6)
(7)
式中Pre——精確率Rec——召回率
TP——被正確劃分為正樣本的數量
FP——被錯誤劃分為正樣本的數量
FN——被錯誤劃分為負樣本的數量
繪制精確率-召回率曲線,曲線的橫軸召回率反映了分類器對正樣本的覆蓋能力,縱軸精確率反映了分類器預測正樣本的精準度。平均精度是對精確率-召回率曲線進行積分,積分公式為
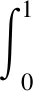
(8)
式中AP——平均精度
平均精度體現模型識別效果,其值越大效果越好,反之越差。
3.3 試驗設計
在模型訓練中,特征提取器的選擇可影響模型的檢測精度與速度,隨著特征提取器層數的增加,網絡能夠提取更高維度的樣本特征,檢測準確度應該同步增加,但是網絡深度的增加會對各層更新信號造成影響,由于采用誤差反向傳播的方式,網絡深度增加后,前層網絡梯度變化非常緩慢,產生梯度消失問題。并且在網絡層數增加的同時,模型的參數空間也隨之擴張,巨大的參數量使得優化問題變得更加復雜,單純地堆疊網絡深度反而會出現更高的訓練誤差。
在訓練一個深層網絡時,假設存在一個性能最佳網絡N,整體網絡與網絡N相比會存在多余層,訓練結果希望這些多余層是恒等變換,即讓一些層擬合恒等映射函數H(x)=x,其中x為輸入變量,此時整體網絡為最優網絡。HE等[25]根據恒等變換的映射關系,提出殘差網絡(ResNet)結構。此模型使用殘差塊,如圖3所示,通過加入殘差通路,學習殘差函數F(x)=H(x)-x。求解F(x)=0時,網絡多余層實現恒等映射,H(x)-x過程可以去掉相同的主體部分,從而突出微小的權重變化。
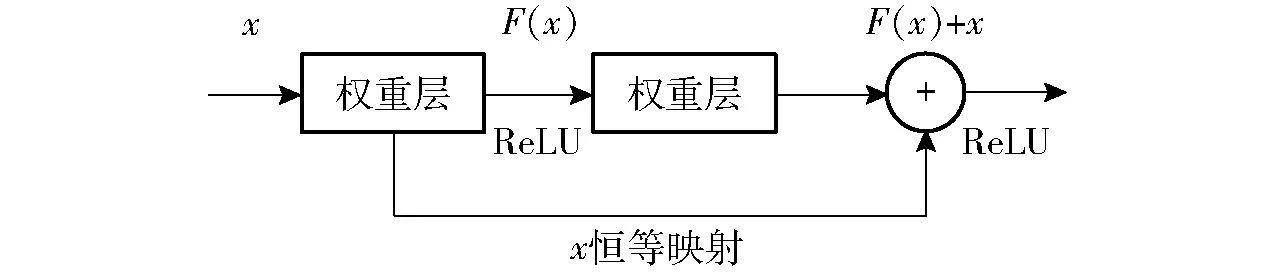
圖3 殘差塊Fig.3 ResNet block
這種改進能夠有效解決梯度消失與訓練退化問題,因此本試驗采用ResNet50網絡、ResNet101網絡與經典的VGG16網絡進行對比試驗,結果如表1所示。
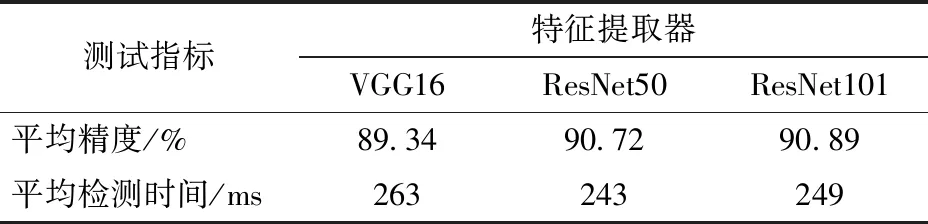
表1 特征提取器對比試驗結果Tab.1 Comparison test result of feature extractor
為了降低模型的泛化誤差,通常采用訓練幾個不同模型,然后讓所有模型表決測試樣例的輸出,但當模型是一個龐大的神經網絡時,會消耗大量的運行時間與內存。因此本文采用Dropout方式,在每個訓練批次中,通過隨機忽略一定比例的隱含層節點,來降低運行時間。由于被忽略隱含層節點是隨機選取的,因此每個批次都在訓練不同的網絡參數,最后通過參數共享使模型的泛化誤差降低。并且Dropout在網絡訓練過程中,可有效減少神經元之間的相互依賴,從而提取出獨立的重要特征,抑制網絡過擬合。
在網絡訓練過程中,通常隨機忽略一半的神經元[26],即Dropout設置為0.5。但Dropout對平均精度的影響與數據集規模和訓練次數有關,在本試驗中,通過設置間隔的Dropout值來尋找最高的平均精度,如表2所示。
3.4 結果與分析
由表1可知,基于本文所用試驗平臺,使用網絡層數最深、參數空間較小的ResNet101網絡作為特征提取器時,可以保證在較快的檢測速度下獲得最佳的檢測效果,其平均精度為90.89%,平均耗時249 ms。由表2可知,在使用ResNet101網絡作為特征提取網絡的基礎上,設置Dropout值為0.6時,可以取得最佳的西蘭花幼苗識別效果,其平均精度為91.73%,平均耗時248 ms。
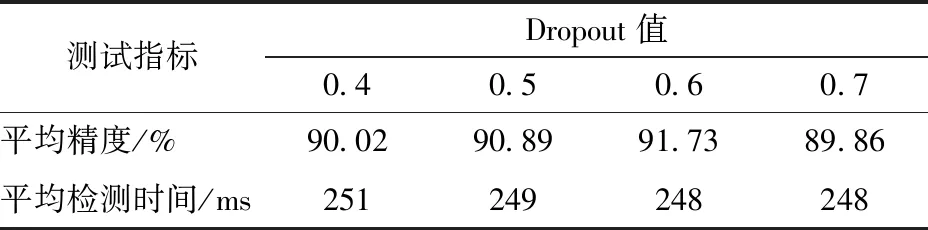
表2 參數優化試驗Tab.2 Parameters optimization test
為更好地顯示卷積神經網絡的運作流程,將特征提取的部分中間過程進行可視化操作,并將圖像統一尺寸以便觀察。如圖4所示,隨著網絡深度的增加,特征圖顆粒度增強,高維特征逐步凸顯。可以看出淺層網絡的特征,圖4b~4e包括邊緣和線條等細節,凸顯局部信息。網絡深層的特征是一種全局信息,圖4g~4i具有更強的語義特征。經過卷積網絡的多層特征表達,能夠有效提取西蘭花幼苗特征,降低噪聲干擾,強化目標學習。

圖4 卷積層特征圖Fig.4 Feature maps of convolution layer
使用訓練好的網絡模型對復雜自然環境下的西蘭花幼苗進行識別,結果如圖5所示。針對葉片完整的西蘭花幼苗具有良好的檢測效果,但在檢測蟲蝕作物樣本時,出現定位不準的情況,如圖5i所示,降低了整體的平均檢測精度。原因是圖像采集過程中,田間的蟲蝕作物較少,蟲蝕樣本占總樣本的比例低,因此訓練模型對其識別敏感度不足,可通過增加此類圖像數量,提高本方法對蟲蝕類型的包容性。

圖5 測試結果Fig.5 Test results
綜上可知,本文采用的Faster R-CNN模型具有較高的檢測精度,對光照強度、地面含水率和雜草密度變化具有較好的魯棒性,能夠有效識別自然環境下的西蘭花幼苗,且耗時較短,可滿足智能除草裝備對作物識別的要求。
4 結論
(1)提出了一種基于Faster R-CNN的自然環境下西蘭花幼苗檢測方法,通過卷積神經網絡對數據本身特征進行非線性表達,能夠從復雜數據中學習到西蘭花幼苗的特征,增強了模型的魯棒性。
(2)以ResNet50網絡、ResNet101網絡和VGG16網絡作為特征提取器進行對比試驗,確定了ResNet101網絡為最佳特征提取器,并在該網絡下,設Dropout值為0.6,使西蘭花幼苗檢測的平均精度達到91.73%,平均耗時為248 ms。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
